| 编辑推荐: |
本文来自hahack,文章将介绍我们使用
Git 进行二进制文件的版本控制的多种方案,以及相关的踩坑之旅。 |
|
毫无疑问,Git 非常适合用于代码文件的版本控制。对于纯代码仓库,由于每次实际提交都是增量内容,即使仓库经历了几十次提交,整个仓库的大小往往都不会大幅增加。
而对于存在二进制文件的仓库,情况就变了:Git 并不能很好地支持二进制文件的增量提交,每次更新一个二进制文件,就相当于把这份文件的完整内容再往仓库里扔。久而久之,这个仓库就会变得非常大,影响代码拉取速度。
举一个实际的例子,为了加快应用的构建速度,我们团队的框架先会编译成
SDK ,再交由上层构建应用。框架 SDK 也是一个独立的 Git 仓库,里头包含了大量的二进制包:
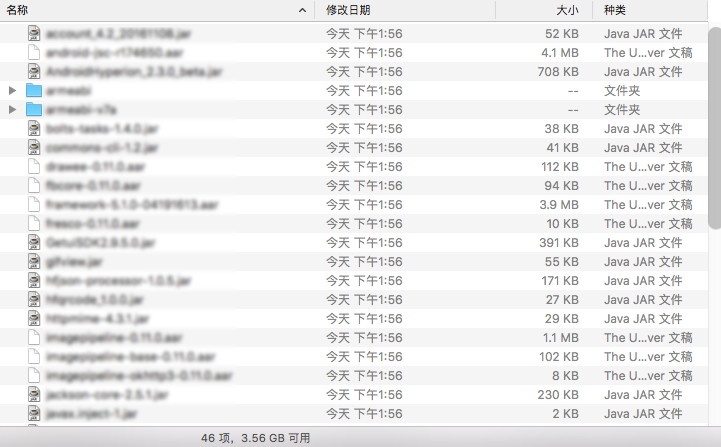
由于框架也有多个分支,每个分支的迭代速度比较快,SDK 仓库的体积在三个月的时间内就膨胀到了
1G 。
如此庞大的仓库体积让第一次拉代码的同事叫苦不迭。一次全新的 clone
,即使拉取速度达到了 5.01 MB/s,在 framework 这个模块上就需要花上大约 7 分钟的时间:

当很多人同时拉代码时,还有很大概率因为 HTTP 超时而拉取失败:

为了解决这个问题,我先后尝试了几种方案。
方案一:改用 SSH
第一个思路非常 intuitive :既然 HTTP 的拉取不稳定,那改成
SSH 如何呢?SSH 的长连接总比 HTTP 稳定吧?
$ git remote
remove origin # 删除原来的http仓库地址
$ git remote add origin git@your-site.com:your-group/your-repo.git
# 改成新的ssh仓库地址 |
这个思路被证实是有效的。通过修改这几个模块的仓库地址为 SSH ,仓库的拉取成功率提升了很多,出现
RPC Failed 的情况也变少了。
然而,这种方案依然无法解决拉取速度慢的问题,完整的拉取该模块的耗时并不比
HTTP 方式快(甚至可能更慢):

另外,这种方式要求每个人都配好 SSH Keys ,否则拉取仓库时也会直接报错。这对于刚接触
Git 的同事而言又增加了一点 cognitive load 。
方案二:单分支克隆
第二个思路是在初次拉取的时候不完整克隆整个工程,而是只克隆一个分支,这样也能减少
N 倍的时间。Git 允许带上 --single-branch -b <分支名> 选项,指定只拉取某一分支:
| $ git clone
--single-branch -b <分支名> http://your-site.com/your-group/your-repo.git |
用这种方法确实减少了一定的时间,但耗时依然可能很长。以我们的框架
SDK 仓库为例,单纯拉一个 master_dev 分支也要 3 分钟左右的时间。

没有数量级别的减少,也就意味着不久之后单个分支的拉取时间也会超过现在整个仓库的完整克隆时间。
方案三:浅克隆
大部分人使用 SDK 时并不需要检出历史版本,对这些人而言,只需要拿到需要的一个快照就可以满足构建需求了。因此方案三就是限定克隆时的深度来加快拉取速度。Git
允许带上 --depth <深度> 来指定拉取深度。例如只拉取分支最新的快照:
| $ git clone
--single-branch -b <分支名> --depth 1 http://your-site.com/your-group/your-repo.git |
由于只拉取最新快照,用这种方式的拉取速度就快了很多。以我们的框架
SDK 仓库为例,拉 master_dev 最新的快照只需要不到 6 秒的时间。

浅克隆虽然能够解决代码拉取的问题,但可想而知这样拉取下来的仓库是不完整的,它缺失了所有历史记录,也不能在这个仓库上提交新的内容。对于框架的开发人员,为了能够提交新内容,依然需要花长时间去克隆完整的仓库。因此浅克隆依然不是一个完美的方案。
方案四:使用 Git-LFS
虽然 Git 本身并不能很好地支持二进制大文件的版本控制,但幸运的是已经出现了一些扩展能够帮助
Git 胜任这些工作。我所选择的扩展就是由 Github 团队开发的 Git-LFS 。
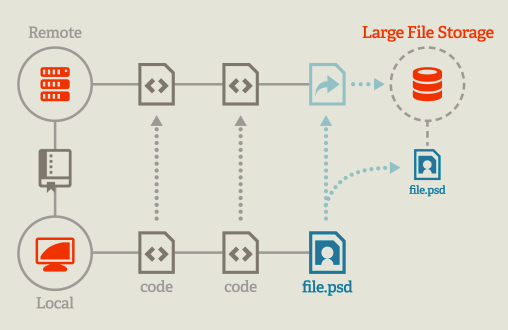
Git-LFS 的原理并不复杂:大文件不再支持添加到仓库中,而是存储到另外的
LFS 服务器上。仓库中只保留这些文件的文本链接。当拉取仓库时,Git-LFS 的钩子将自动把这些文本链接恢复成
LFS 中的实际内容。一图胜千言:
服务端配置
选择 Git-LFS 的一个首要原因是 Gitlab 原生提供了对
Git-LFS 的支持 。要在 Gitlab 中开启 Git-LFS 非常简单:
编辑 /opt/gitlab/gitlab.rb 文件,找到 Git
LFS 项目;
将 gitlab_rails['lfs_enabled'] 项目设置成
true;
将 gitlab_rails['lfs_storage_path']
项目设置为本地的一个已存在目录。这个目录就是实际的 LFS 存储目录。
执行 gitlab-ctl reconfigure 重新配置 Gitlab;
执行 gitlab-ctl restart 重启 Gitlab ,使配置生效。
至此服务端就配置完成了。
工具安装
下载
Git LFS 。解压完后执行:
完成工具的安装。这步骤只需要做一次。这个步骤实际做的事情是给 git
加上 lfs 命令,另外还创建了 post-checkout、post-commit、post-merge、pre-push
几个全局钩子。当我们在一个使用 LFS 的仓库执行诸如 checkout、commit、merge、push
的 Git 操作时,将触发这些钩子自动地维护用 LFS 管理的文件。
仓库改造
接下来就可以开始改造仓库,把大文件都改用 LFS 来管理。
$ git lfs track
"*.jar"
$ git lfs track "*.so"
$ git lfs track "*.aar" |
这几步执行完会在仓库中创建一个 .gitattribute 文件:
$ cat .gitattributes
*.jar filter=lfs diff=lfs merge=lfs -text
*.so filter=lfs diff=lfs merge=lfs -text
*.aar filter=lfs diff=lfs merge=lfs -text |
Git 的钩子就是根据这个文件来确定当前仓库是否有使用 LFS 管理的文件的。所以这个文件一定要确保添加进仓库中:
完成后像往常一样暂存和提交文件即可:
$ git add foo.jar
$ commit -m "Add jar file"
$ git push origin master |
要注意的是,这个改造过程只会把当前这次 commit 的指定类型文件改成用
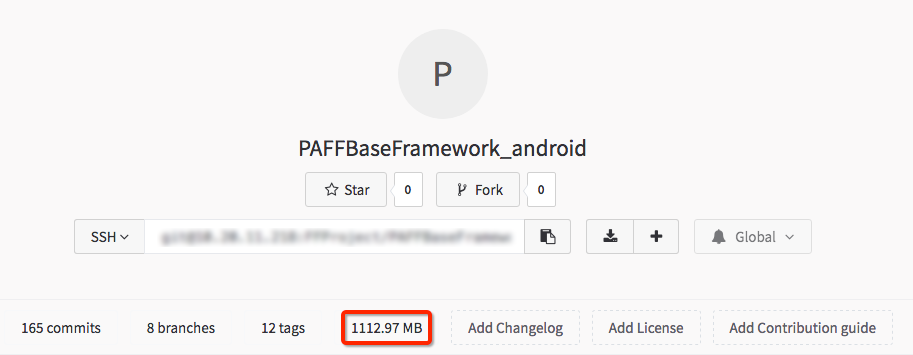
LFS 才存储,而不会影响所有历史记录。对于我们的 SDK 仓库,仓库本身已经非常庞大,直接这么改造是没有任何瘦身效果的。所以最好的做法就是重新创建一个仓库,把各个分支最新的快照同步过来。
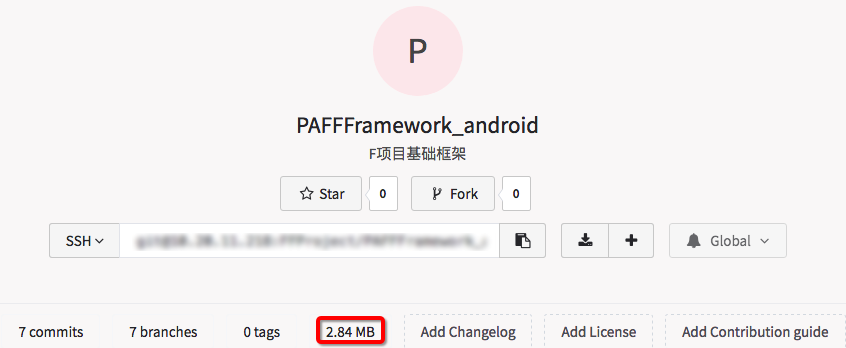
由图可以看出,重新创建的这个仓库,把大部分的二进制大文件都改用了 LFS
来存储,整个仓库的大小从 1G 减小到 3M 不到!
测试对这个新的仓库进行克隆,由于本身仓库很小,一下子就克隆下来了。之后
Git LFS 的全局钩子将自动将当前仓库里的 LFS 链接文件恢复成真正的文件:
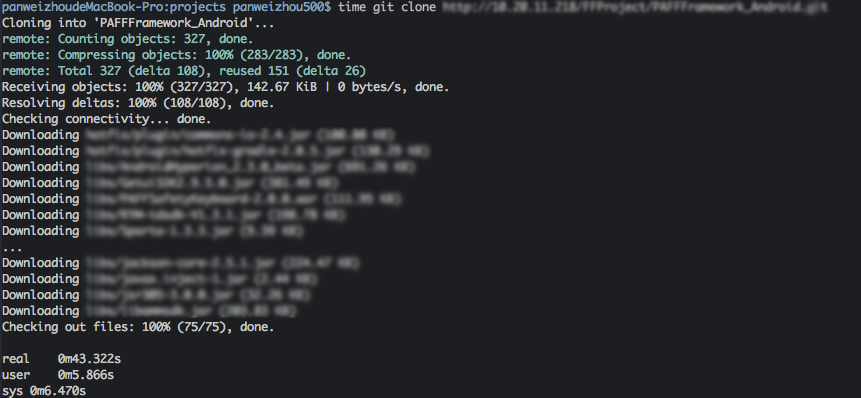
由于这个仓库的二进制包多达64个,整个克隆过程的时间主要花在下载这些二进制包,总耗时约为
43 秒。虽然没有浅克隆快,但这样的方式拉下来的仓库是完整的仓库,而且对普通开发者而言是完全透明的操作(他们甚至不需要知道
LFS 是什么),因此是更加理想的方案。
Git-LFS 的踩坑之旅
虽然 Git-LFS 很好地解决了大文件的版本控制问题,但实际应用到实际团队中时也不见得能顺风顺水。在我将它推广到团队的项目中时,就遇到了几个水土不服的问题。下面整理一下,方便后来人。
1. 警惕钩子覆盖
第一个遇到的问题就是钩子的覆盖问题。前面我们提到 Git-LFS
其实是利用全局钩子来关联 Git 与 LFS 的。当你的工程中也加了钩子时,这时候就要格外小心了。
以我们的工程为例,我给每个子模块都加了个 pre-push 钩子用来做
push 前检查:
如果子模块接入了 Code Review,检查要 push 的提交是否都经过了
Code Review;
如果是 React Native 子模块,检查本地的 React
Native 打包是否成功;
检查如果要推送到一个新分支,检查目标分支名是否包含非 ASCII
字符。
问题来了,这个 pre-push 钩子的优先级会高于全局的那个 Git
LFS 钩子,因此使得 Git LFS 的 pre-push 失去作用。而这个钩子非常重要:它的作用是在
push 的时候把用 Git LFS 跟踪管理的文件上传到 LFS 服务器上。如果这些文件没有上传成功,别人拉取仓库就会报如下错误:
Downloading
hotfix/plugin/commons-io-2.4.jar (180.80 KB)
Error downloading object: hotfix/plugin/commons-io-2.4.jar
(cc6a41dc3eaacc9e440a6bd0d2890b20d36b4ee408fe2d67122f32
8bb6e01581)
Errors logged to /Users/xxxx/Desktop/App_Android_master_dev/.git/modules
/framework/xxxx/xxxx/lfs/objects/logs/20170417T21
2952.282306976.log
Use `git lfs logs last` to view the log.
error: external filter git-lfs smudge -- %f failed
2
error: external filter git-lfs smudge -- %f failed
fatal: hotfix/plugin/commons-io-2.4.jar: smudge
filter lfs failed |
解决办法就是将 Git LFS 钩子的内容与自定义钩子相结合。这是我对
Git LFS 的 pre-push 钩子的改写:
#!/bin/sh
basepath=$(cd `dirname $0`; pwd)
command -v git-lfs >/dev/null 2>&1 ||
{ echo >&2 "\nThis repository is configured
for Git LFS but 'git-lfs' was not found on your
path. If you no longer wish to use Git LFS, remove
this hook by deleting .git/hooks/pre-push.\n";
exit 2; }
git lfs pre-push "$@" && $basepath/pre-push-custom |
最后一行的作用就是先执行 git lfs pre-push 确保正确上传
LFS tracking 的文件,然后再执行 hooks 中的 pre-push-custom 钩子进行其他自定义的检查。
2. zip 包下载的 bug
Gitlab 对 Git-LFS 也存在着不足。当我完成了几个大仓库的改造之后,我发现新的仓库在本地可以顺利编译,但在构建站却死活编译不了,报了类找不到的错误:
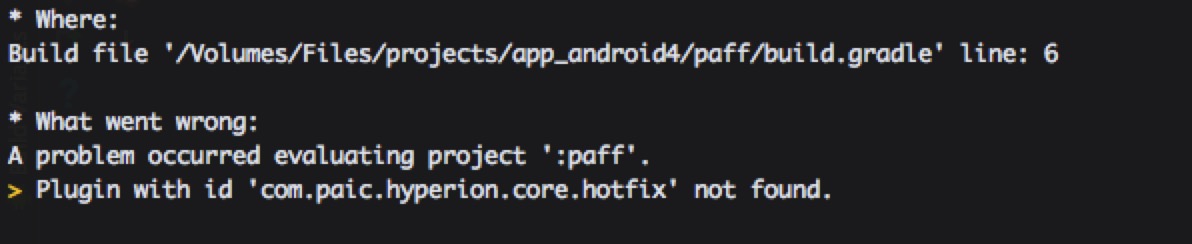
本地构建和构建站构建在代码拉取上面有一个区别:为了加快代码拉取速度,我们在构建站并不使用克隆仓库的方式来拉取代码,而是采用下载
Zip 包的方式。所以我把这个仓库的 Zip 包下载了下来:
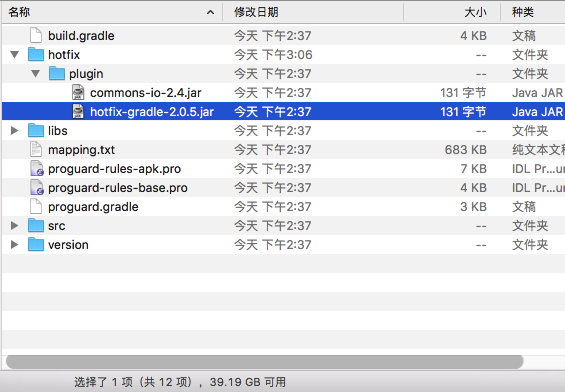
这个类是在其中一个 jar 包里定义的,而解压发现 jar 包明明已经下载下来了:
尝试使用 JD-Gui 打开这个 jar 包,发现这个包打不开。
那这个文件究竟是什么东西?打印它的内容,真相浮出水面:

这是个链接文件!说明 Gitlab 并没有将它恢复成实际的文件内容!仔细观察这些二进制文件,我发现它们的大小全部都在
130 字节左右,这意味着这些文件全都没有被恢复。
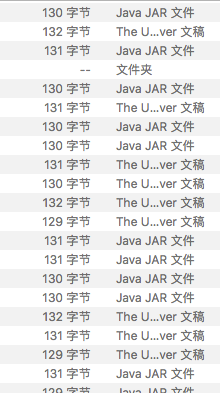
不幸的是,由于下载下来的内容不再是个 Git 仓库,这些链接文件已无法恢复成实际的文件内容。

我认为这个是 Gitlab 的问题,于是给 Gitlab 提了一个
bug ,而一个开发人员告诉我类似的问题在去年 3 月份已经有人提过,而目前还未修复 --bb 。
找到这个原因后,对症下药就简单了:既然下载 Zip 包的方式没法恢复大文件的内容,那就改成用浅克隆。于是我改写了下构建站的代码拉取脚本,将使用
Git LFS 管理大文件的几个模块由下载 zip 的方式改成浅克隆,终于解决了编译问题!
总结
本文列举了几种二进制大文件导致仓库过大的解决方案。其中,使用 Git-LFS
的方案是一种比较理想的选择。但在实际使用中,一定要小心处理 Git-LFS 可能带来的问题,希望本文的若干踩坑总结也能对读者有所帮助。 |









