| БрМЭЦМі: |
БОЮФРДздinfoqЃЌБОЮФНЋНщЩм
Twitter ЕФЖЏЬЌХфжУЯЕЭГ ConfigBusЁЃConfigBus АќРЈДцДЂХфжУЕФЪ§ОнПтЁЂНЋХфжУЗжЗЂЕН
Twitter Ъ§ОнжааФжаЕФЛњЦїЕФЙмЕРЁЂЖСШЁКЭИќаТХфжУЕФ API КЭЙЄОпЁЃ
|
|
ЖЏЬЌХфжУФмЙЛдкВЛжиаТЦєЖЏгІгУГЬађЕФЧщПіЯТИќИФе§дкдЫааЕФЯЕЭГЕФааЮЊКЭЙІФмЁЃРэЯыЕФЖЏЬЌХфжУЯЕЭГЪЙЗўЮёПЊЗЂШЫдБКЭЙмРэдБФмЙЛЗНБуЕиВщПДКЭИќаТХфжУЃЌВЂИпаЇПЩППЕиЯђгІгУГЬађЬсЙЉХфжУИќаТЁЃЫќЪЙзщжЏФмЙЛПьЫйЁЂДѓЕЈЕиЕќДњаТЬиадЃЌВЂЬсЙЉЙЄОпЃЌМѕЩйгыИќИФЯжгаЯЕЭГЯрЙиЕФЗчЯеЁЃ
дк Twitter ЕФдчЦкЃЌгІгУГЬађЙмРэВЂЗжЗЂздМКЕФХфжУЃЌЭЈГЃДцДЂдк
ZooKeeper жаЁЃЕЋЪЧЃЌЮвУЧвдЧАЪЙгУ ZooKeeper ЕФОбщБэУїЃЌЫќдкгУзїЭЈгУМќжЕДцДЂЪБВЛФмЩьЫѕЁЃЦфЫћЭХЖгзЊЖјЪЙгУ
Git НјааДцДЂЃЌВЂНсКЯздЖЈвхЕФЙЄОпРДИќаТЁЂЗжЗЂКЭжиаТМгдиХфжУЁЃЫцзХ Twitter ЕФЗЂеЙЃЌКмУїЯдашвЊвЛИіБъзМЕФНтОіЗНАИРДЬсЙЉПЩЩьЫѕЕФЛљДЁЩшЪЉЁЂПЩжигУЕФПтКЭгааЇЕФМрПиЁЃ
МмЙЙ
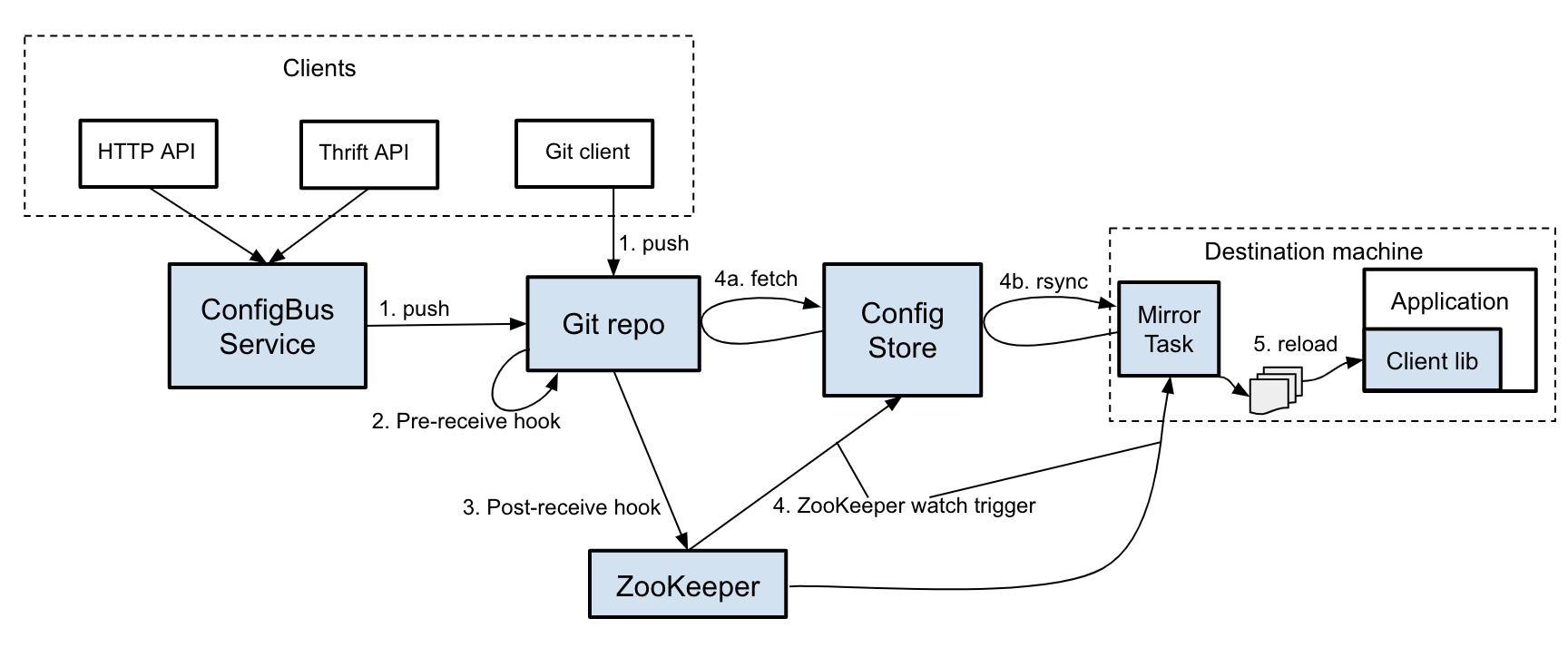
дквЛИіНЯИпЕФВуДЮЩЯЃЌФуПЩвдНЋ ConfigBus ПДзївЛИі Git ДцДЂПтЃЌЫќЕФФкШнБЛЭЦЫЭЕН Twitter
Ъ§ОнжааФЕФЫљгаЛњЦїЩЯЁЃХфжУИќИФОЙ§вЛЯЕСаВНжшЕНДяФПЕФЕиЃК
1.ПЊЗЂШЫдБЯђ Git ДцДЂПтЬсНЛИќИФЁЃОЙ§ЩэЗнбщжЄЕФгІгУГЬађвВПЩвдЭЈЙ§
ConfigBus ЗўЮёЬсНЛЕНДцДЂПтЁЃ
2.дЄНгЪеЙГзгбщжЄИќИФЁЃШчЙћбщжЄЭЈЙ§ЃЌдђдкЗўЮёЦїЩЯНгЪмВЂЬсНЛЭЦЫЭЁЃЃЈЮвУЧНЋдкЁАЬиЕуЁБВПЗжИќЯъЯИЕиЬжТлетжжбщжЄЁЃЃЉ
3.вЛЕЉЗўЮёЦїЩЯЕФЬсНЛЙ§ГЬЭъГЩЃЌGit НгЪеКѓЙГзгОЭЛсЪЙгУЬсНЛаХЯЂЃЈSHAЁЂЪБМфДСЕШЃЉИќаТ
ZooKeeper жаЕФЬиЖЈНкЕуЁЃ
НгЯТРДЛсДЅЗЂZooKeeper watchesЃЌв§ЗЂЯТгЮЙ§ГЬЕФЖЏзїЃК
a. дкзїЮЊХфжУзМБИЧјЕФЁАConfigStoreЁБЛњЦїЩЯЃЌwatch ЪТМўЛсЕїгУвЛИіЛиЕїЃЌДг Git
ЗўЮёЦїЛёШЁзюаТЬсНЛЁЃЫќЛЙгУЕБЧАЕФ SHA ИќаТ ZooKeeper жаЕФЬѕФПЁЃ
b. дкФПБъЛњЦїЩЯЃЌwatch ЪТМўДЅЗЂОЕЯёШЮЮёЃЌИУШЮЮёТжбЏ ZooKeeperЃЌевГігызюаТЬсНЛОпгаЯрЭЌ
SHA ЕФ ConfigStore ЛњЦїЁЃвЛЕЉевЕНдДЛњЦїЃЌОЕЯёШЮЮёНЋдЫаа rsync АбИќИФЭЌВНЕНБОЕиЛњЦїЩЯЁЃ
зюКѓЃЌЪЙгУетаЉХфжУЮФМўЕФгІгУГЬађНЋПДЕНЮФМўЯЕЭГЩЯЕФИќИФЃЈЭЈЙ§ ConfigBus ПЭЛЇЖЫПтЃЉЃЌВЂЦєЖЏНјГЬФкжиаТМгдиЁЃ
зюКѓЃЌЯЕЭГЭЃжЙЙЄзїЃЌвдБуАбЕк 1 ВНжаИќИФЕФЮФМўЭЌВНЕНЫљгаФПБъЛњЦїЃЌВЂгЩвРРЕетаЉЛњЦїЕФЫљгаПЭЛЇЖЫгІгУГЬађжиаТМгдиЁЃ
ЬиЕу
ХфжУМДДњТы
ЪЙгУ Git дЪаэПЊЗЂШЫдБжигУдДДцДЂПтЬсЙЉЕФаэЖрЯрЭЌЕФУќСюКЭЙЄзїСїЁЃGit МАЦфжмБпЕФЩњЬЌЯЕЭГжївЊЬсЙЉСЫвдЯТЙІФмЃК
ОпгаИќИФШежОЕФдДДњТыПижЦЃКФмЙЛМьВщЙ§ШЅЕФХфжУИќИФвдВщПДИќИФСЫЪВУДЃЈвдМАгЩЫИќИФЁЂКЮЪБИќИФЛђЮЊЪВУДИќИФЃЉЪЧЗЧГЃгаМлжЕЕФЁЃGit
здШЛдЪаэетбљзіЁЃПЊЗЂШЫдБЭъШЋгааХаФЃЌЕБЧАКЭЙ§ШЅЕФАцБОдкАцБОПижЦжаЪЧАВШЋЕФЁЃ
здЖЏВПЪ№ЃКConfigBus жаЕФХфжУЮФМўЛсздЖЏИДжЦЕНЫљгаФПБъЛњЦїЁЃФПЧАЃЌХфжУДЋВЅЕФЦНОљбгГйЮЊ 80-100
УыЃЌЖј p99 бгГйДѓдМЮЊ 300 УыЁЃ
ЗжЮібщжЄЃКConfigBus ЪЙгУдЄНгЪеЙГзгРДдЫаабщжЄГЬађЃЌЫќУЧПЩвдМьВщХфжУЮФМўжаЕФгяЗЈДэЮѓЃЌНјааФЃЪНбщжЄЃЌвдМАжДааШЮКЮРраЭЕФздЖЈвхбщжЄЁЃЫќеыЖд
JSON ЕШСїааХфжУИёЪНЮЊ Twitter ПЊЗЂШЫдБЬсЙЉСЫПЊЯфМДгУЕФгяЗЈбщжЄЁЃЫќЛЙЬсЙЉСЫжИЖЈФЃЪНКЭбщжЄМцШнадЕФФмСІЁЃгУЛЇЛЙПЩвдБраДздЖЈвхбщжЄЃЌВЂдк
Git жаЬэМгКЭИќаТХфжУЪБжДааетаЉбщжЄЁЃ
ДњТыЩѓКЫЃКШУХфжУИќИФЭЈЙ§ДњТыЦРЩѓгажњгкМѕЩйДэЮѓЃЌВЂдкНЋЦфЭЖШыЩњВњЛЗОГжЎЧАЗЂЯжЮЪЬтЁЃ
ACLЃКЮвУЧдк Git ДцДЂПтжаЧПжЦжДааХфжУЫљгаШЈЃЌвдШЗБЃХфжУЮФМўжЛБЛгІИУЙмРэЫќУЧЕФЭХЖгКЭгІгУГЬађаоИФЁЃЕБЭЦЫЭвЛИіИќИФЪБЃЌвЛИідЄНгЪеЙГзгЛсбщжЄЪЧЗёдЪаэжДааИУЭЦЫЭЕФгУЛЇЖдетаЉЮФМўНјааИќИФЁЃ
БрГЬЗУЮЪЃКConfigBus ЗўЮёжЇГжЖд ConfigBus ЕФБрГЬЗУЮЪЁЃИУЗўЮёЪЕЯжСЫGitЁАжЧФмЁБHTTP
авщЃЌВЂГфЕБХфжУДцДЂПтЕФЧАЖЫЁЃЫќЭЈЙ§ HTTP КЭ Thrift API ЬсЙЉЖСШЁКЭЁАcompare-and-setЁБаДШыЙІФмЁЃетЪЙЕУБраДЖргУЛЇгІгУГЬађЯђЕЅИіЮФМўЭЦЫЭИќИФБфЕУМђЕЅСЫЃЌВЛашвЊЫќУЧОпгаДцДЂПтЕФБОЕиПЫТЁЁЃИУЗўЮёЛЙФкжУСЫРжЙлВЂЗЂПижЦЃЌЕБЭЦЫЭгЩгкЖдДцДЂПтЕФВЂЗЂИќаТЖјЪЇАмЪБЛсздЖЏжиЪдЁЃ
ДѓЙцФЃГжајНЛИЖ
вЛЕЉХфжУБЛАВШЋДцДЂЃЌЮвУЧашвЊвЛжжЗНЗЈАбЫќУЧЬсЙЉИјдЫаадкTwitter ЛљДЁЩшЪЉЩЯЕФШэМўЃЌАќРЈдЫаадкMesosдЦвдМАжБНгдЫаадкТуЛњЩЯЕФЗўЮёЁЃетЪЧЭЈЙ§
rsync НЋЮФМўЭЦЫЭЕНЫљгаЕФЛњЦїЩЯРДЪЕЯжЕФЁЃашвЊЗУЮЪХфжУЕФгІгУГЬађжЛашДгБОЕиЮФМўЯЕЭГЖСШЁЁЃетбљзіЕФКУДІЪЧЃК
МђЕЅЃКЪЙгУЮФМўЯЕЭГзїЮЊ API ЪЙЕУШЮКЮгябдБраДЕФгІгУГЬађЖМПЩвдЪЙгУ ConfigBusЁЃПЩвддкБОЕиЮФМўЯЕЭГЖСШЁХфжУЛЙгажњгкМѕЩйЗўЮёЦєЖЏЪБМфЃЌЬиБ№ЪЧдкдЦЛЗОГжаЃЌгІгУГЬађЪЕР§ПЩвддквЛИіНкЕуЩЯхДЕєЃЌШЛКѓдкСэвЛИіНкЕуЩЯдЫааЁЃ
ПЩШнДэЃКНЋХфжУЪ§ОнЭЦЫЭЕНУПЬЈЛњЦїЩЯЕФБОЕиЮФМўЯЕЭГжаЃЌетбљЃЌМДЪЙ ConfigBus ЙмЕРЕФФГаЉВПЗжЪЇАмЃЌгІгУГЬађвВПЩвдМЬајдЫааЁЃР§ШчЃЌШчЙћ
Git ЗўЮёЦїхДЛњЃЌЭХЖгНЋЮоЗЈНјаааТЕФХфжУИќИФЃЌЕЋЪЧдЫаажаЕФгІгУГЬађВЛЛсЪмЕНЬЋДѓгАЯьЁЃЭЌбљЃЌШчЙћ ZooKeeper
ГіЯжЙЪеЯЃЌЗжЗЂЙмЕРвВЛсЪмЕНгАЯьЃЌЕЋЛњЦїЩЯЯжгаЕФХфжУШдШЛПЩгУЁЃЯрЗДЃЌШчЙћХфжУЛёШЁЗўЮёхДЕєЃЌашвЊАДашЛёШЁХфжУЪ§ОнЕФЯЕЭГНЋЛсЪЇАмЁЃ
ПЩРЉеЙЃКConfigBus ЕФЖрВуМмЙЙдЪаэЯЕЭГИљОнашЧѓЕФдіМгНјааЩьЫѕЁЃConfigStore ВуНЋ
Git ЗўЮёЦїгыжБНгСїСПИєРыПЊРДЁЃдкетвЛВудіМгШнСПвдЪЪгІ Twitter ВЛЖЯдіГЄЕФЛњЦїЪ§СПЫљДјРДЕФашЧѓдіМгЃЌетдкВйзїЩЯЪЧЗЧГЃМђЕЅЕФЁЃ
ЁАШШЁБжиди
ЖЏЬЌХфжУЯЕЭГЕФжївЊгХЕужЎвЛЪЧФмЙЛЖРСЂгкЪЙгУЫќЕФШэМўВПЪ№жиаТМгдиХфжУИќИФЁЃДЫЭтЃЌвЛИіЭъШЋЖЏЬЌЕФХфжУЯЕЭГгІИУФмЙЛдкВЛжиаТЦєЖЏгІгУГЬађНјГЬЕФЧщПіЯТжиаТМгдиИќИФЃЌДгЖјзюаЁЛЏЖдећИігІгУГЬађЕФгАЯьЁЃConfigBus
ЬсЙЉСЫвЛаЉПтЃЌдЪаэПЭЛЇЖЫЖЉдФЬиЖЈЕФЮФМўЃЌВЂдкетаЉЮФМўИќИФЪБЕїгУЛиЕїЁЃЫфШЛгІгУГЬађвВПЩвджБНгДгЮФМўЯЕЭГЖСШЁЃЌЕЋЪЧЪЙгУОЙ§СМКУВтЪдКЭЗтзАЕФПЭЛЇЖЫПтОпгавдЯТгХЕу:
БмУтМьВтХфжУИќИФВЂДЅЗЂжиаТМгдиЕФДњТыжиИДЃЛ
дЪаэЧЖШыЗЂВМХфжУаТЯЪЖШжИБъгУгкЮЪЬтМьВтЕФДњТыЁЃ
МрПи
ConfigBus ЪЧвЛИіИДдгЕФЗжВМЪНЯЕЭГЃЌгааэЖрЛюЖЏВПМўЁЃЮвУЧдкИїИіВуМЖЖдЯЕЭГНјааМрПиЃЌвдБуЪеМЏЭГМЦаХЯЂЃЌВЂдкЗЂЯжвьГЃааЮЊЪБЗЂГіОЏБЈЁЃ
ЖРСЂВПМўЃКЮвУЧМрПиИїИізгЯЕЭГЃЈШч Git КЭ ZooKeeper ЗўЮёЦїЃЉЕФНЁПЕзДПіЁЃР§ШчЃЌЮвУЧЪеМЏгы
Git ДцДЂПтЕФЙІФмКЭадФмЯрЙиЕФЭГМЦаХЯЂЃЈАќДѓаЁЁЂЬсНЛбгГйЁЂЙГзгбгГйЕШЕШЃЉЃЌВЂЗЂГіОЏБЈЁЃ
АцБОИњзйЃКGit ЗўЮёЦїНЋЦкЭћЕФХфжУАцБОЗЂВМЕН ZooKeeperЁЃЯТгЮЯћЗбепЪЙгУДЫАцБОМрПиХфжУЪ§ОнЕФаТЯЪЖШЁЃ

ЖЫЕНЖЫМрПиЃКдЫаадкПЭЛЇЖЫЛњЦїЩЯЕФМрПигІгУГЬађУПИєМИЗжжгОЭЛсИќаТХфжУДцДЂПтжаЕФЬиЖЈЮФМўЃЌВЂЕШД§ИќаТДЋВЅЕНЦфБОЕиЛњЦїЁЃетгажњгкЖШСП
ConfigBus ЙмЕРЕФЙиМќЬиеїЃЌР§ШчЬсНЛГЩЙІТЪЁЂЬсНЛбгГйКЭХфжУЭЌВНбгГйЁЃ
гУР§
СїСПТЗгЩЃКдк TwitterЃЌConfigBus гУгкДцДЂЗўЮёТЗгЩВЮЪ§ЁЃетПЩвдгУгкПижЦЧыЧѓТЗгЩТпМЃЈР§ШчЃЌШчЙћПЊЗЂШЫдБЯЃЭћНЋ
1% ЕФЗўЮёЧыЧѓТЗгЩЕНдЫааШэМўздЖЈвхАцБОЕФвЛзщЪЕР§ЃЉЁЃ
дЊЗўЮёЗЂЯжЃКдк TwitterЃЌЗўЮёЪЧЭЈЙ§вЛИіЗўЮёЗЂЯжЗўЮёЗЂЯжБЫДЫЁЃЕЋЪЧЃЌЫќУЧБиаыЪзЯШЗЂЯжЗўЮёЗЂЯжЗўЮёБОЩэЁЃетЪЧЭЈЙ§
ConfigBus ЪЕЯжЕФЁЃЪЙгУ ConfigBus гыРрЫЦгк ZooKeeper етбљЕФЖЋЮїЃЌЦфгХЕуЪЧЃЌдкУПЬЈЛњЦїЕФБОЕиЮФМўЯЕЭГЩЯЖМгаПЩгУЕФаХЯЂЃЌетЪЙЕУЯЕЭГИќФмЕжгљЙЪеЯЃЈвВОЭЪЧЫЕЃЌШчЙћ
ConfigBus Лђ ZooKeeper ГіЯжЙЪеЯЃЌЗўЮёЗЂЯжШдШЛПЩвддЫааЃЉЁЃ
DeciderЃКдк TwitterЃЌDecider ЪЧЗўЮёЪЙгУЕФЬиадБъЪЖЯЕЭГЃЌгУгкдкдЫааЪБЖЏЬЌЦєгУКЭНћгУЕЅИіЬиадЁЃИУЯЕЭГЮЛгк
ConfigBus жЎЩЯЁЃDecider ЪЧУцЯђМќ - жЕЕФЃЈЁАcool_new_feature ЕФжЕЪЧЖрЩйЃПЁБЃЉЃЌЖј
ConfigBus ЪЧУцЯђЮФМўЕФЃЈЁАЮФМўapplication/config.jsonЕФФкШнЪЧЪВУДЃПЁБЃЉЁЃЕЅИіЬиадЕФБъЪЖГЦЮЊЁАОіВпЦїЃЈdeciderЃЉЁБЁЃвЛЕЉЧЖШыЕНДњТыжаЃЌОіВпЦїОЭПЩвдИќИФе§дкдЫааЕФгІгУГЬађЕФааЮЊЃЌЖјВЛашвЊИќИФДњТыЛђжиаТВПЪ№ЁЃГ§ДЫжЎЭтЃЌОіВпЦїПЩвдгУРДЃК
габЁдёадЕиЦєгУДњТыЃКПЩвддкДњТыжаЪЙгУОіВпМќРДбЁдёадЕиЦєгУДњТыПщЁЃDecider ЬсЙЉЕФжївЊЗНЗЈЪЧЁАisAvailableЁБЃЌЫќНгЪмвЛИіОіВпМќВЮЪ§ЃЌШчЙћеыЖдЕБЧАЕФЕїгУДђПЊЬиадЃЌдђЗЕЛиЁАtrueЁБЃЛШчЙћеыЖдЕБЧАЕФЕїгУЙиБеЬиадЃЌдђЗЕЛиЁАfalseЁБ
ЁЃЁАisAvailableЁБЗНЗЈЪЙЕУПЊЗЂШЫдБПЩвдЯёЯТУцетбљЧаЛЛДњТыТЗОЖЃК
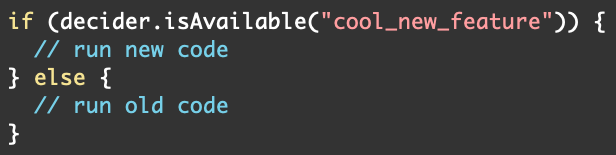
ЧаЛЛКѓЬЈДцДЂЯЕЭГЃКгааЉгІгУГЬађЪЙгУОіВпЦїбЁдёаДШыЛђЖСШЁЕФКѓЬЈДцДЂЯЕЭГЁЃР§ШчЃЌгІгУГЬађДгОЩЪ§ОнПтЧЈвЦЕНаТЪ§ОнПтЃЌЫќПЩФмЛсСйЪБНЋЪ§ОнаДШыСНИіЯЕЭГЃЌВЂдкЧЈвЦЭъГЩКѓЖЏЬЌЙиБеОЩЪ§ОнПтЁЃЛђепЃЌШчЙћаТЯЕЭГгаЮЪЬтЃЌгІгУГЬађПЩФмЛсбЁдёЙиБеЫќЁЃОіВпЦїЪЙЕУетаЉИќИФАВШЋЖјПьЫйЁЃ
зїЮЊжЙбЊДјЖЯПЊЙ§диЯЕЭГЃКдк TwitterЃЌМрПиЯЕЭГгаЪБЛсдкМьВтЕНИКдиЙ§жиЪБИќаТОіВпЦїЃЌвдБуНћгУФГаЉДњТыТЗОЖЁЃетПЩвдЗРжЙЯЕЭГЙ§диЃЌВЂдЪаэЫќУЧНјааЛжИДЁЃ
ЧјгђМфЙЪеЯзЊвЦЃКDecider гУгкДцДЂФГаЉТЗгЩВЮЪ§ЃЌетаЉВЮЪ§ПижЦзХ Twitter ЗўЮёПчЧјгђЕФСїСПЗжВМЁЃЦфжааэЖрЪЧЭЈЙ§МрПиШэМўздЖЏИќаТЕФЃЌКѓепПЩвдЙлВьУПИіЧјгђЕФЙЪеЯТЪЁЃ
ЁАЬиадЧаЛЛЃЈFeature SwitchesЃЉЁБЃКдк TwitterЃЌЬиадЧаЛЛЮЊПижЦгІгУГЬађЕФааЮЊЬсЙЉСЫвЛИіИДдгЖјЧПДѓЕФЛљгкЙцдђЕФЯЕЭГЁЃЬиадЧаЛЛПижЦЬиаддкГѕВНПЊЗЂЁЂЭХЖгВтЪдЁЂФкВПВтЪдЁЂAlpha
ВтЪдЁЂBeta ВтЪдЁЂЗЂВМвдМАзюжеЬдЬЕФЙ§ГЬжаЕФПЩгУадЁЃгы Decider ЕФХфжУвЛбљЃЌЬиадЧаЛЛХфжУДцДЂдк
ConfigBus жаЁЃВЛЙ§ЃЌдквЦЖЏЩшБИЩЯЃЌзюжеХфжУЛсгавЛИіЙиМќЧјБ№ЁЃдкЗЂВМЕФзюКѓвЛИіНзЖЮЃЌвЦЖЏгІгУГЬађЛсЭЈЙ§дЫаадк
Twitter Ъ§ОнжааФЕФЗўЮёЖЈЦкРШЁетаЉХфжУИќаТЁЃгы Decider ЯрБШЃЌЬиадЧаЛЛЛЙЬсЙЉИќЯИСЃЖШЕФПижЦЁЃЕфаЭЕФ
Decider ХфжУКмМђЕЅЃЌР§ШчЃЌЁАдЪаэЪ§ОнжааФ X жа 70% ЕФЧыЧѓаДШыаТЪ§ОнПтЁБЁЃЬиадЧаЛЛХфжУИќИпМЖЃЌвВИќИДдгЃЌР§ШчЃЌЁАЮЊ
X ЭХЖгжаЕФЫљгаШЫвдМАетИіЦНЬЈЩЯЕФетаЉЬиЖЈгУЛЇЦєгУетИіаТЬиадЁЃЁБ
ЁАПтЧаЛЛЃЈLibrary togglesЃЉЁБЃКЬиадЧаЛЛКЭ Decider ЪЧЮЊСЫАяжњгІгУГЬађПЊЗЂШЫдБАВШЋЗЂВМЬиадЖјЩшМЦЕФЁЃПтПЊЗЂШЫдБдкЭЦГіИќИФЪБгаЪБашвЊРрЫЦЕФПЊЙиЛњжЦЁЃFinagleЪЧ
Twitter УцЯђ JVM ЕФПЊдД RPC ПђМмЃЌЫќЬсЙЉСЫвЛжжЧаЛЛЛњжЦЃЌПтПЊЗЂШЫдБПЩвдЪЙгУИУЛњжЦАВШЋЕиЗЂВМИќИФЃЌЭЌЪБвВЮЊЗўЮёЫљгаепЬсЙЉСЫФГжжГЬЖШЕФПижЦЁЃTwitter
дкФкВПЪЕЯжетИі API ЪБЪЙгУ ConfigBus РДЖЏЬЌПижЦетаЉЧаЛЛЁЃ
жДаа A/B ВтЪдЃКвЊгааЇЕидЫааВњЦЗЪдбщашвЊПьЫйЕќДњКЭвзгкЕїећЕФЙІФмЁЃTwitter ЕФЪдбщПђМмЪЙгУСЫ
ConfigBusЃЌдЪаэгІгУГЬађПЊЗЂШЫдБЧсЫЩЕиЩшжУКЭРЉеЙЪдбщЃЌВЂдкашвЊЪБПьЫйЙиБеЫќУЧЁЃ
вЛАугІгУГЬађХфжУЃКConfigBus зюЕфаЭЕФгУЗЈЪЧДцДЂвЛАугІгУГЬађХфжУЮФМўЃЌВЂдкИќИФЬсНЛЪБЖЏЬЌЕижиаТМгдиЫќУЧЁЃ
ОбщНЬбЕ
ЮвУЧдкЩњВњЛЗОГжадЫаа ConfigBus вбОНЋНќЫФФъСЫЁЃвдЯТЪЧЮвУЧбЇЕНЕФвЛаЉЖЋЮїЁЃ
НќЪЕЪБЗжЗЂ
ОЁЙм ConfigBus ЕФФПБъЪЧНќЪЕЪБЗжЗЂЃЌЕЋЪЧЃЌЧЉШыДцДЂПтЕФдуИтХфжУИќИФЛсбИЫйДЋВЅЕНШЮКЮЕиЗНЁЃЮЊСЫзюаЁЛЏетжжИќИФЕФгАЯьЃЌConfigBus
зюНќЬэМгСЫвЛИіПЩбЁЬиадЃЌЬсЙЉСЫЁАЗжНзЖЮЃЈstaged ЃЉЁБЙіЖЏЙІФмЃЌДгЖјПЩвддіСПЕиЙіЖЏЭЦГіИќИФЁЃетЪЧЭЈЙ§ЭЌЪБЭЦЫЭаТОЩАцБОЕФХфжУвдМАвЛаЉЙигкЭЦГіНзЖЮЕФдЊЪ§ОнРДЪЕЯжЕФЁЃШЛКѓЃЌИїИігІгУГЬађЪЕР§ЪЙгУНзЖЮдЊЪ§ОнРДЖЏЬЌЕиМгдиКЯЪЪАцБОЕФХфжУЁЃ
Git ДцДЂПтЙцФЃ
ЫцзХ Git ДцДЂПтФъСфЕФдіГЄЃЌЫќЕФЙцФЃвВдкдіДѓЁЃНЯДѓЕФДцДЂПтЛсМѕТ§жюШчЁАgit cloneЁБКЭЁАgit
addЁБжЎРрЕФВйзїЁЃДцДЂПтДѓаЁВЛНіЪмМьШыЕФДѓЮФМўгАЯьЃЌЖјЧвЛЙЪмЕНжиДѓИќИФЕФгАЯьЁЃЯТУцЪЧЮвУЧгУРДНтОіетИіЮЪЬтЕФвЛаЉВпТдЁЃ
ЁАЧГЭЦЫЭЃЈShallow pushesЃЉЁБЃКЮвУЧЩ§МЖЕНвЛИіБШНЯаТЕФ Git АцБОЃЌИУАцБОдЪаэПЊЗЂШЫдБДгДцДЂПтЕФЧГПЫТЁАцБОЭЦЫЭИќИФЁЃетвтЮЖзХзюГѕЕФПЫТЁВйзївЊПьЕУЖрЃЌвђЮЊЫќжЛДЋЪф
HEAD ЬсНЛвдМАЬсНЛКЭЭЦЫЭИќИФЫљашЕФзюаЁдЊЪ§ОнЁЃ
ЙщЕЕЃКдкМЋЩйЪ§ЧщПіЯТЃЌЮвУЧЛсЖд Git ДцДЂПтНјааЙщЕЕЃЌНЋЫљгаРњЪЗМЧТМвЦЖЏЕНвЛИіЙщЕЕжаЃЌШЛКѓжиаТПЊЪМЁЃетЪЙЕУЮвУЧПЩвдЩОГ§ОЩЕФЁЂЧБдкЕФДѓЮФМўЃЌМѕЩйДцДЂПтЕФДѓаЁЁЃЮвУЧЛсБмУтОГЃетбљзіЃЌвђЮЊетЛсЦШЪЙПЊЗЂШЫдБжиаТПЫТЁДцДЂПтЁЃ
бгГЄ delta СДЃКЮвУЧФПЧАе§дкбаОПЃЌЪЧЗёвЊЛ§МЋЕиЖд Git ЖдЯѓНјаажиаТДђАќвдбгГЄ delta
СДЃЌДгЖјАяжњМѕЩйДцДЂПтЕФДѓаЁЃЌЭЌЪБгжБЃГжИќИФЬсНЛадФмВЛБфЁЃ
ЗжЧј
ЮвУЧВЛдЪаэ Git ДцДЂПтЩЯЕФЁАЗЧПьНјЃЈnon-fast-forwardЃЉЁБЭЦЫЭЃЌвдБЃЛЄжїЗжжЇжаЕФЬсНЛВЛЛсБЛЧПжЦЭЦЫЭИВИЧЁЃетЯюЩшжУЕФаЇЙћЪЧвЊЧѓЖдДцДЂПтЕФШЮКЮЭЦЫЭЖМБиаыЪЙгУДцДЂПтЕФзюаТИББОЁЃШчЙћСНИіЬсНЛепдкНЋЪ§ОнЭЦЫЭЕНДцДЂПтЪБВњЩњОКељЃЌФЧУДЦфжавЛИіНЋЪЄГіЃЌСэвЛИіНЋВЛЕУВЛРШЁзюаТЕФИќИФВЂжиЪдЁЃетЛсдіМгХфжУИќаТВйзїЕФбгГйЁЃЖдгкЦЕЗБЬсНЛепРДЫЕЃЌбгГйЕФдіМгДјРДСЫвЛИіОоДѓЕФЮЪЬтЁЃЮвУЧЪЧЭЈЙ§дкКѓЬЈНЋЦЕЗБИќаТЕФУћГЦПеМфЛЎЗжЕНЕЅЖРЕФзЈгУДцДЂПтРДНтОіетИіЮЪЬтЁЃЖдгкЪЙгУ
API НјааХфжУИќаТЕФПЭЛЇЖЫРДЫЕЃЌетУЛгаШЮКЮВювьЁЃ
ЮФМўМЖЯпадЛЏ
ЪЕМЪЩЯЃЌВЛдЪаэЗЧПьНјЭЦЫЭвтЮЖзХ ConfigBus дкДцДЂПтМЖЩЯЪЧЯпадЛЏЕФЁЃШчЙћСНИіПЊЗЂШЫдБвђЭЌЪБЭЦЫЭИќИФЖјЗЂЩњОКељЃЌдђЦфжавЛИіНЋЁАЛёЪЄЁБЃЌСэвЛИіБиаыРШЁзюаТЕФИќИФВЂжиЪдЁЃМДЪЙетСНИіПЊЗЂШЫдБе§дкИќаТЭъШЋВЛЭЌЕФЮФМўЃЌЧщПівВЪЧШчДЫЁЃЖдгкВЛЖЯИќаТЕФДцДЂПтЃЌетЛсИјПЭЛЇЖЫДјРДВЛБивЊЕФИКЕЃЁЃвђДЫЃЌЮвУЧАб
ConfigBus ЗўЮёЩшМЦГЩздЖЏРШЁИќаТЃЌВЂдкЪЇАмЪБжиЪдЭЦЫЭЁЃетЬсЙЉСЫБэУцЩЯЕФЮФМўМЖЯпадЛЏЃЌШЗБЃПЭЛЇЖЫжЛдкЮФМўМЖИќаТГхЭЛЪБВХПДЕНЪЇАмЁЃ
git fetchгыgit pull
ЁАgit pullЁБЪЕМЪЩЯЪЧЁАgit fetchЁБ+ЁАgit mergeЁБЁЃШчЙћ ConfigStore
ЛњЦїЩЯЕФПЫТЁеОЕуЫ№ЛЕЛђгыдЖГЬЗўЮёЦїВЛЭЌВНЃЌКЯВЂВНжшПЩФмЛсЪЇАмЁЃвдздЖЏЗНЪНДгЗўЮёЦїЛёШЁИќаТзюАВШЋЁЂзюМђНрЕФЗНЗЈЪЧдЫааЁАgit
fetchЁБ+ЁАgit resetЁЊЁЊhard FETCH_HEADЁБЃЌвдБуИВИЧПЫТЁеОЕуЩЯДцдкЕФШЮКЮБОЕизДЬЌЁЃ
rsync ЕМжТЕФЛКТ§
ЮвУЧбЁдёШУЩйСПЕФ ConfigStore ЛњЦїДг Git ЩЯЛёШЁаХЯЂЃЌВЂНЋЫќУЧзїЮЊЦфЫћЛњЦїЭЈЙ§ rsync
НјааЭЌВНЕФдДЁЃЮвУЧЪЙгУ -c бЁЯюдЫаа rsyncЃЌЦШЪЙЫќКіТдЪБМфДСЃЌВЂЮЊДѓаЁЯрЭЌЕФЮФМўМЦЫуаЃбщКЭЁЃетЪЧ
CPU УмМЏаЭЕФЃЌвђДЫЯожЦСЫУПЬЈ ConfigStore ЛњЦїПЩвдЬсЙЉЕФВЂЗЂ rsync ВйзїЕФЪ§СПЁЃЗДЙ§РДЃЌетгждіМгСЫећИіЖЫЕНЖЫДЋВЅЕФбгГйЁЃНЋУћГЦПеМфЗжЧјГЩЕЅЖРЕФДцДЂПтПЩвдМѕЩй
rsync дкУПДЮЬсНЛЪБашвЊБШНЯЕФЮФМўЪ§СПЁЃСэвЛжжПЩФмЕФбЁдёЪЧдкУПЬЈ ConfigStore ЛњЦїЩЯдЫаавЛИі
Git ЗўЮёЦїЃЌВЂШУЫљгаЕФФПБъЛњЦїдЫааЁАGit fetchЁБЃЌетжЛашвЊЯТдизюаТЕФЁАHEADЁБЃЌЖјВЛашвЊШЮКЮБШНЯПЊЯњЃЈвђЮЊ
Git ЗўЮёЦїШЗЧаЕижЊЕРЗЂЩњСЫЪВУДБфЛЏЃЉЁЃ
ЗЧдзгЭЌВН
ConfigBus ЪЙгУ rsyncЃЌетвтЮЖзХЮФМўПЩвдЕЅИіЕиЭЌВНЕНФПБъЛњЦїЩЯЁЃвђДЫЃЌШчЙћЬсНЛХіЧЩИќИФСЫЖрИіЮФМўЃЌФЧУДФПБъЛњЦїЩЯЕФЮФМўЯЕЭГПЩФмЛсднЪБАќКЌаТОЩЮФМўЕФЛьКЯЁЃвЛИіПЩФмЕФНтОіЗНАИЪЧЭЌВНЕНвЛИіСйЪБЮЛжУЃЌШЛКѓЪЙгУдзгжиУќУћВйзїРДЭъГЩИќИФЁЃЕЋЪЧЃЌгЩгкашвЊвдЯђКѓМцШнЕФЗНЪНжЇГжЗжЧјУћГЦПеМфЃЌВПЪ№ЮЛжУЩЯДцдкЗћКХСДНгЃЌетЪЙЕУЮЪЬтБфЕУИДдгЁЃвЛИіИќПЩааЕФНтОіЗНАИЪЧМЬајЯёЯждкетбљЗжЗЂжї
Git ДцДЂПтЃЌЕЋЪЧАбНЋРДЕФЗжЧјДцДЂПтЧаЛЛЕНдзгВПЪ№ЁЃ
ЮДРДеЙЭћ
дк TwitterЃЌЮвУЧЙЙНЈ ConfigBus ЪЧЮЊСЫЬсЙЉвЛИіНЁзГЕФЖЏЬЌХфжУЦНЬЈЁЃЫцзХЯжгагУР§ЕФЗЂеЙКЭаТгУР§ЕФГіЯжЃЌConfigBus
БиаыНјааИќИФвдЪЪгІЫќУЧЁЃвдЯТЪЧЮвУЧЬиБ№ЙизЂЕФМИИіСьгђЁЃ
Git
ЖдгкжеЖЫгУЛЇЖјбдЃЌGit гаКмЖргХЕуЃЌЕЋЪЧЃЌЫќДњБэСЫвЛИіГжајЕФВйзїЬєеНЁЃЮвУЧЖдЫќНёКѓЪЧЗёШдШЛЪЧе§ШЗЕФНтОіАьЗЈГжПЊЗХЬЌЖШЁЃЬцДњЗНЗЈАќРЈМќ
- жЕДцДЂЃЌШч ConsulЃЌЕЋЮвУЧБиаыНтОіРњЪЗЬЋЩйетИіЯрЗДЕФЮЪЬтЁЃ
жиаТЩшМЦЗжЗЂ
ЪЙгУ rsync ДгвЛИіКмаЁЕФ ConfigStore ЛњЦїГиНјааЗжЗЂЯожЦСЫЗжЗЂЙмЕРЕФЫйЖШЁЃЬНЫїЕуЖдЕуЗжЗЂФЃаЭНЋЪЧвЛМўКмгаШЄЕФЪТЧщЃЌдкетжжФЃаЭжаЃЌУПЬЈЛњЦїдкгЕгаВПЗжЛђШЋВПЪ§ОнКѓЖМГфЕБНјвЛВНДЋЪфЕФдДЁЃ
жЇГжДѓЖдЯѓ
ФПЧАЃЌЮвУЧВЛЙФРјЪЙгУ ConfigBus ДІРэДѓаЭ BlobЃЌетжївЊЪЧвђЮЊ GitЃЌвВвђЮЊдкУПЬЈЛњЦїЩЯДцДЂДѓаЭ
Blob ЕФаЇТЪКмЕЭЁЃвЛИіЧБдкЕФНтОіЗНАИЪЧНЋ Blob ДцДЂдквЛИіГЃЙцЕФ Blob ДцДЂжаЃЌВЂНЋЛюЖЏАцБОДцДЂдк
ConfigBus жаЃЌШЛКѓИљОнашвЊЯТдиЫќУЧЁЃ
|









