«Α―‘
…œΤΣΈ“ΨΆGit–≠“ιΫ≤ΝΥΝΫ¥σΒψΘ§GitΒΡΤπ≤ΫΘ§GitΒΡΜυ¥Γ≤ΌΉςΘ§Τδ÷–œξœΗΒΡ–ΓΜοΑιΩ…“‘œ»»Ξ‘ΡΕΝΈ“…œ“ΜΤΣΈΡ’¬http://www.uml.org.cn/pzgl/201708213.asp (“Μ»κ«ΑΕΥ…νΥΤΚΘΘ§¥”¥ΥΚλ≥Ψ «¬Ζ»ΥœΒΝ–ΒΎ °Β·÷°»γΚΈΚœάμάϊ”ΟGitΫχ––Ά≈Ε”–≠Ής(“Μ))ΓΘΫ”œ¬ά¥÷±Ϋ”ΚΆ¥σΦ“Ζ÷œμ”–ΙΊGitΖ÷÷ß“‘ΦΑ»γΚΈ≤ΌΉς‘Ε≥Χ≤÷ΩβΫχ––Ά≈Ε”–≠ΉςΓΘ
“ΜΓΔ‘Ε≥Χ≤÷ΩβΒΡ Ι”Ο
1ΓΔ≤ιΩ¥Β±«ΑΒΡ‘Ε≥Χ≤÷Ωβ
“Σ≤ιΩ¥Β±«Α≈δ÷Ο”–ΡΡ–©‘Ε≥Χ≤÷ΩβΘ§Ω…“‘”Ο git remote ΟϋΝνΘ§ΥϋΜαΝ–≥ωΟΩΗω‘Ε≥ΧΩβΒΡΦρΕΧΟϊΉ÷ΓΘ‘ΎΩΥ¬ΓΆξΡ≥ΗωœνΡΩΚσΘ§÷Ν…ΌΩ…“‘Ω¥ΒΫ“ΜΗωΟϊΈΣ origin ΒΡ‘Ε≥ΧΩβΘ§Git Ρ§»œ Ι”Ο’βΗωΟϊΉ÷ά¥±ξ ΕΡψΥυΩΥ¬ΓΒΡ‘≠ Φ≤÷Ωβ
# step 1
$ git clone https://github.com/xuqiang521/data-visualization.git
#Cloning into 'data-visualization'...
#remote: Counting objects: 38, done.
#remote: Compressing objects: 100% (29/29), done.
#remote: Total 38 (delta 7), reused 38 (delta 7), pack-reused 0
#Unpacking objects: 100% (38/38), done.
# step 2
$ cd data-visualization
# step 3
$ git remote
#origin |
“≤Ω…“‘Φ”…œ -v ―ΓœνΘ®“κΉΔΘΚ¥ΥΈΣ --verbose ΒΡΦρ–¥Θ§»Γ ΉΉ÷ΡΗΘ©Θ§œ‘ ΨΕ‘”ΠΒΡΩΥ¬ΓΒΊ÷ΖΘΚ
$ git remote -v
#origin https://github.com/xuqiang521/data-visualization.git (fetch)
#origin https://github.com/xuqiang521/data-visualization.git (push) |
»γΙϊ”–ΕύΗω‘Ε≥Χ≤÷ΩβΘ§¥ΥΟϋΝν“≤Ω…“‘ΫΪΤδ»Ϊ≤ΩΝ–≥ωΓΘ’β―υ“Μά¥Θ§Έ“ΨΆΩ…“‘Ζ«≥Θ«αΥ…ΒΊ¥”’β–©”ΟΜßΒΡ≤÷Ωβ÷–Θ§ά≠»ΓΥϊΟ«ΒΡΧαΫΜΒΫ±ΨΒΊΓΘ
2ΓΔΧμΦ”‘Ε≥Χ≤÷Ωβ
“ΣΧμΦ”“ΜΗω–¬ΒΡ‘Ε≥Χ≤÷ΩβΘ§Ω…“‘÷ΗΕ®“ΜΗωΦρΒΞΒΡΟϊΉ÷Θ§“‘±ψΫΪά¥“ΐ”ΟΘ§‘Υ–– git remote add [shortname] [url]ΘΚ
# step 1
$ git remote
#origin
# step 2
$ git remote add pb git://github.com/paulboone/ticgit.git
# step 3
$ git remote -v
#origin git://github.com/schacon/ticgit.git
#pb git://github.com/paulboone/ticgit.git |
œ÷‘ΎΩ…“‘”ΟΉ÷Ζϊ¥° pb ÷Η¥ζΕ‘”ΠΒΡ≤÷ΩβΒΊ÷ΖΝΥΓΘ±»»γΥΒΘ§“ΣΉΞ»ΓΥυ”– Paul ”–ΒΡΘ§ΒΪ±ΨΒΊ≤÷ΩβΟΜ”–ΒΡ–≈œΔΘ§Ω…“‘‘Υ–– git fetch pbΘΚ
$ git fetch pb
#remote: Counting objects: 58, done.
#remote: Compressing objects: 100% (41/41), done.
#remote: Total 44 (delta 24), reused 1 (delta 0)
#Unpacking objects: 100% (44/44), done.
#From git://github.com/paulboone/ticgit
#* [new branch] master -> pb/master
#* [new branch] ticgit -> pb/ticgit |
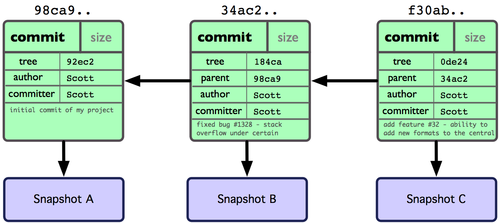
œ÷‘ΎΘ§Paul ΒΡ÷ςΗ…Ζ÷÷ßΘ®masterΘ©“―Ψ≠Άξ»ΪΩ…“‘‘Ύ±ΨΒΊΖΟΈ ΝΥΘ§Ε‘”ΠΒΡΟϊΉ÷ « pb/masterΘ§ΡψΩ…“‘ΫΪΥϋΚœ≤ΔΒΫΉ‘ΦΚΒΡΡ≥ΗωΖ÷÷ßΘ§Μρ’Ώ«–ΜΜΒΫ’βΗωΖ÷÷ßΘ§Ω¥Ω¥”––© ≤Ο¥”–»ΛΒΡΗϋ–¬ΓΘ
3ΓΔ¥”‘Ε≥Χ≤÷ΩβΉΞ»Γ ΐΨί
’ΐ»γ÷°«ΑΥυΩ¥ΒΫΒΡΘ§Ω…“‘”Οœ¬ΟφΒΡΟϋΝν¥”‘Ε≥Χ≤÷ΩβΉΞ»Γ ΐΨίΒΫ±ΨΒΊΘΚ
| $ git fetch [remote-name] |
¥ΥΟϋΝνΜαΒΫ‘Ε≥Χ≤÷Ωβ÷–ά≠»ΓΥυ”–Ρψ±ΨΒΊ≤÷Ωβ÷–ΜΙΟΜ”–ΒΡ ΐΨίΓΘ‘Υ––Άξ≥…ΚσΘ§ΡψΨΆΩ…“‘‘Ύ±ΨΒΊΖΟΈ ΗΟ‘Ε≥Χ≤÷Ωβ÷–ΒΡΥυ”–Ζ÷÷ßΘ§ΫΪΤδ÷–Ρ≥ΗωΖ÷÷ßΚœ≤ΔΒΫ±ΨΒΊΘ§Μρ’Ώ÷Μ «»Γ≥ωΡ≥ΗωΖ÷÷ßΘ§“ΜΧΫΨΩΨΙΓΘ
»γΙϊ «ΩΥ¬ΓΝΥ“ΜΗω≤÷ΩβΘ§¥ΥΟϋΝνΜαΉ‘Ε·ΫΪ‘Ε≥Χ≤÷ΩβΙι”Ύ origin Οϊœ¬ΓΘΥυ“‘Θ§git fetch origin ΜαΉΞ»Γ¥”Ρψ…œ¥ΈΩΥ¬Γ“‘ά¥±π»Υ…œ¥ΪΒΫ¥Υ‘Ε≥Χ≤÷Ωβ÷–ΒΡΥυ”–Ηϋ–¬Θ®Μρ «…œ¥Έ fetch “‘ά¥±π»ΥΧαΫΜΒΡΗϋ–¬Θ©ΓΘ”–“ΜΒψΚή÷Ί“ΣΘ§–η“ΣΦ«ΉΓΘ§fetch ΟϋΝν÷Μ «ΫΪ‘ΕΕΥΒΡ ΐΨίά≠ΒΫ±ΨΒΊ≤÷ΩβΘ§≤Δ≤ΜΉ‘Ε·Κœ≤ΔΒΫΒ±«ΑΙΛΉςΖ÷÷ßΘ§÷Μ”–Β±Ρψ»Ζ ΒΉΦ±ΗΚΟΝΥΘ§≤≈Ρή ÷ΙΛΚœ≤ΔΓΘ
»γΙϊ…η÷ΟΝΥΡ≥ΗωΖ÷÷ß”Ο”ΎΗζΉΌΡ≥Ηω‘ΕΕΥ≤÷ΩβΒΡΖ÷÷ßΘ§Ω…“‘ Ι”Ο git pull ΟϋΝνΉ‘Ε·ΉΞ»Γ ΐΨίœ¬ά¥Θ§»ΜΚσΫΪ‘ΕΕΥΖ÷÷ßΉ‘Ε·Κœ≤ΔΒΫ±ΨΒΊ≤÷Ωβ÷–Β±«ΑΖ÷÷ßΓΘ‘Ύ»’≥ΘΙΛΉς÷–Έ“Ο«Ψ≠≥Θ’βΟ¥”ΟΘ§Φ»Ωλ«“ΚΟΓΘ ΒΦ …œΘ§Ρ§»œ«ιΩωœ¬ git clone ΟϋΝν±Ψ÷ …œΨΆ «Ή‘Ε·¥¥Ϋ®ΝΥ±ΨΒΊΒΡ master Ζ÷÷ß”Ο”ΎΗζΉΌ‘Ε≥Χ≤÷Ωβ÷–ΒΡ master Ζ÷÷ßΘ®ΦΌ…η‘Ε≥Χ≤÷Ωβ»Ζ Β”– master Ζ÷÷ßΘ©ΓΘΥυ“‘“ΜΑψΈ“Ο«‘Υ–– git pullΘ§ΡΩΒΡΕΦ «“Σ¥”‘≠ ΦΩΥ¬ΓΒΡ‘ΕΕΥ≤÷Ωβ÷–ΉΞ»Γ ΐΨίΚσΘ§Κœ≤ΔΒΫΙΛΉςΡΩ¬Φ÷–ΒΡΒ±«ΑΖ÷÷ßΓΘ
4ΓΔΆΤΥΆ ΐΨίΒΫ‘Ε≥Χ≤÷Ωβ
œνΡΩΫχ––ΒΫ“ΜΗωΫΉΕΈΘ§“ΣΆ§±π»ΥΖ÷œμΡΩ«ΑΒΡ≥…ΙϊΘ§Ω…“‘ΫΪ±ΨΒΊ≤÷Ωβ÷–ΒΡ ΐΨίΆΤΥΆΒΫ‘Ε≥Χ≤÷ΩβΓΘ Βœ÷’βΗω»ΈΈώΒΡΟϋΝνΚήΦρΒΞΘΚ git push [remote-name] [branch-name]ΓΘ»γΙϊ“ΣΑ―±ΨΒΊΒΡ master Ζ÷÷ßΆΤΥΆΒΫ origin ΖΰΈώΤς…œΘ®‘Ό¥ΈΥΒΟςœ¬Θ§ΩΥ¬Γ≤ΌΉςΜαΉ‘Ε· Ι”ΟΡ§»œΒΡ master ΚΆ origin ΟϊΉ÷Θ©Θ§Ω…“‘‘Υ––œ¬ΟφΒΡΟϋΝνΘΚ
÷Μ”–‘ΎΥυΩΥ¬ΓΒΡΖΰΈώΤς…œ”––¥»®œόΘ§Μρ’ΏΆ§“Μ ±ΩΧΟΜ”–ΤδΥϊ»Υ‘ΎΆΤ ΐΨίΘ§’βΧθΟϋΝν≤≈Μα»γΤΎΆξ≥…»ΈΈώΓΘ»γΙϊ‘ΎΡψΆΤ ΐΨί«ΑΘ§“―Ψ≠”–ΤδΥϊ»ΥΆΤΥΆΝΥ»τΗ…Ηϋ–¬Θ§Ρ«ΡψΒΡΆΤΥΆ≤ΌΉςΨΆΜα±Μ≤ΒΜΊΓΘΡψ±Ί–κœ»Α―ΥϊΟ«ΒΡΗϋ–¬ΉΞ»ΓΒΫ±ΨΒΊΘ§Κœ≤ΔΒΫΉ‘ΦΚΒΡœνΡΩ÷–Θ§»ΜΚσ≤≈Ω…“‘‘Ό¥ΈΆΤΥΆΓΘ
5ΓΔ≤ιΩ¥‘Ε≥Χ≤÷Ωβ–≈œΔ
Έ“Ο«Ω…“‘Ά®ΙΐΟϋΝν git remote show [remote-name] ≤ιΩ¥Ρ≥Ηω‘Ε≥Χ≤÷ΩβΒΡœξœΗ–≈œΔΘ§±»»γ“ΣΩ¥ΥυΩΥ¬ΓΒΡ origin ≤÷ΩβΘ§Ω…“‘‘Υ––ΘΚ
$ git remote show origin
#* remote origin
#Fetch URL: https://github.com/xuqiang521/data-visualization.git
#Push URL: https://github.com/xuqiang521/data-visualization.git
#HEAD branch: master
#Remote branch:
# master tracked
#Local branch configured for 'git pull':
# master merges with remote master
#Local ref configured for 'git push':
# master pushes to master (up to date) |
≥ΐΝΥΕ‘”ΠΒΡΩΥ¬ΓΒΊ÷ΖΆβΘ§ΥϋΜΙΗχ≥ωΝΥ–μΕύΕνΆβΒΡ–≈œΔΓΘΥϋ”―…ΤΒΊΗφΥΏΡψ»γΙϊ «‘Ύ master Ζ÷÷ßΘ§ΨΆΩ…“‘”Ο git pull ΟϋΝνΉΞ»Γ ΐΨίΚœ≤ΔΒΫ±ΨΒΊΓΘΝμΆβΜΙΝ–≥ωΝΥΥυ”–¥Π”ΎΗζΉΌΉ¥Χ§÷–ΒΡ‘ΕΕΥΖ÷÷ßΓΘ
…œΟφΒΡάΐΉ”Ζ«≥ΘΦρΒΞΘ§ΕχΥφΉ≈ Ι”Ο Git ΒΡ…ν»κΘ§git remote show Ηχ≥ωΒΡ–≈œΔΩ…ΡήΜαœώ’β―υΘΚ
$ git remote show origin
#* remote origin
#URL: git@github.com:defunkt/github.git
#Remote branch merged with 'git pull' while on branch issues
#issues
#Remote branch merged with 'git pull' while on branch master
#master
#New remote branches (next fetch will store in remotes/origin)
#caching
#Stale tracking branches (use 'git remote prune')
#libwalker
#walker2
#Tracked remote branches
#acl
#apiv2
#dashboard2
#issues
#master
#postgres
#Local branch pushed with 'git push'
#master:master |
ΥϋΗφΥΏΈ“Ο«Θ§‘Υ–– git push ±»± ΓΆΤΥΆΒΡΖ÷÷ß « ≤Ο¥Θ®“κΉΔΘΚΉνΚσΝΫ––Θ©ΓΘΥϋΜΙœ‘ ΨΝΥ”–ΡΡ–©‘ΕΕΥΖ÷÷ßΜΙΟΜ”–Ά§≤ΫΒΫ±ΨΒΊΘ®“κΉΔΘΚΒΎΝυ––ΒΡ caching Ζ÷÷ßΘ©Θ§ΡΡ–©“―Ά§≤ΫΒΫ±ΨΒΊΒΡ‘ΕΕΥΖ÷÷ß‘Ύ‘ΕΕΥΖΰΈώΤς…œ“―±Μ…Ψ≥ΐΘ®“κΉΔΘΚStale tracking branches œ¬ΟφΒΡΝΫΗωΖ÷÷ßΘ©Θ§“‘ΦΑ‘Υ–– git pull ±ΫΪΉ‘Ε·Κœ≤ΔΡΡ–©Ζ÷÷ßΘ®“κΉΔΘΚ«ΑΥΡ––÷–Ν–≥ωΒΡ issues ΚΆ master Ζ÷÷ßΘ©ΓΘ
6ΓΔ‘Ε≥Χ≤÷ΩβΒΡ…Ψ≥ΐΚΆ÷ΊΟϋΟϊ
‘Ύ–¬Αφ Git ÷–Ω…“‘”Ο git remote rename ΟϋΝν–όΗΡΡ≥Ηω‘Ε≥Χ≤÷Ωβ‘Ύ±ΨΒΊΒΡΦρ≥ΤΘ§±»»γœκΑ― pb ΗΡ≥… paulΘ§Ω…“‘’βΟ¥‘Υ––ΘΚ
# step 1
$ git remote rename pb paul
# step 2
$ git remote
#origin
#paul |
ΉΔ“βΘ§Ε‘‘Ε≥Χ≤÷ΩβΒΡ÷ΊΟϋΟϊΘ§“≤Μα ΙΕ‘”ΠΒΡΖ÷÷ßΟϊ≥ΤΖΔ…ζ±δΜ·Θ§‘≠ά¥ΒΡ pb/master Ζ÷÷ßœ÷‘Ύ≥…ΝΥ paul/masterΓΘ
≈ωΒΫ‘ΕΕΥ≤÷ΩβΖΰΈώΤς«®“ΤΘ§Μρ’Ώ‘≠ά¥ΒΡΩΥ¬ΓΨΒœώ≤Μ‘Ό Ι”ΟΘ§”÷Μρ’ΏΡ≥Ηω≤Έ”κ’Ώ≤Μ‘ΌΙ±œΉ¥ζ¬κΘ§Ρ«Ο¥–η“Σ“Τ≥ΐΕ‘”ΠΒΡ‘ΕΕΥ≤÷ΩβΘ§Ω…“‘‘Υ–– git remote rm ΟϋΝνΘΚ
# step 1
$ git remote rm paul
# step 2
$ git remote
#origin |
ΕΰΓΔGitΖ÷÷ß
1ΓΔΚΈΈΣΖ÷÷ß
ΈΣΝΥάμΫβ Git Ζ÷÷ßΒΡ Βœ÷ΖΫ ΫΘ§Έ“Ο«–η“ΣΜΊΙΥ“Μœ¬ Git «»γΚΈ¥Δ¥φ ΐΨίΒΡΓΘΩ¥ΙΐΈ“…œ“ΜΤΣ≤©ΩΆΒΡ≈σ”―”ΠΗΟ÷ΣΒάΘ§Git ±Θ¥φΒΡ≤Μ «ΈΡΦΰ≤ν“λΜρ’Ώ±δΜ·ΝΩΘ§Εχ÷Μ «“ΜœΒΝ–ΈΡΦΰΩλ’’ΓΘ
‘Ύ Git ÷–ΧαΫΜ ±Θ§Μα±Θ¥φ“ΜΗωΧαΫΜΘ®commitΘ©Ε‘œσΘ§ΗΟΕ‘œσΑϋΚ§“ΜΗω÷Ηœρ‘ί¥φΡΎ»ίΩλ’’ΒΡ÷Η’κΘ§ΑϋΚ§±Ψ¥ΈΧαΫΜΒΡΉς’ΏΒ»œύΙΊΗΫ τ–≈œΔΘ§ΑϋΚ§ΝψΗωΜρΕύΗω÷ΗœρΗΟΧαΫΜΕ‘œσΒΡΗΗΕ‘œσ÷Η’κΘΚ Ή¥ΈΧαΫΜ «ΟΜ”–÷±Ϋ”Ήφœ»ΒΡΘ§Τ’Ά®ΧαΫΜ”–“ΜΗωΉφœ»Θ§”…ΝΫΗωΜρΕύΗωΖ÷÷ßΚœ≤Δ≤ζ…ζΒΡΧαΫΜ‘ρ”–ΕύΗωΉφœ»ΓΘ
ΈΣ÷±ΙέΤπΦϊΘ§Έ“Ο«ΦΌ…η‘ΎΙΛΉςΡΩ¬Φ÷–”–»ΐΗωΈΡΦΰΘ§ΉΦ±ΗΫΪΥϋΟ«‘ί¥φΚσΧαΫΜΓΘ‘ί¥φ≤ΌΉςΜαΕ‘ΟΩ“ΜΗωΈΡΦΰΦΤΥψ–Θ―ιΚΆΘ§»ΜΚσΑ―Β±«ΑΑφ±ΨΒΡΈΡΦΰΩλ’’±Θ¥φΒΫ Git ≤÷Ωβ÷–Θ®Git Ι”Ο blob άύ–ΆΒΡΕ‘œσ¥φ¥Δ’β–©Ωλ’’Θ©Θ§≤ΔΫΪ–Θ―ιΚΆΦ”»κ‘ί¥φ«χ”ρΘΚ
# step 1
$ git add README test.rb LICENSE
# step 2
$ git commit -m 'initial commit of my project' |
Β± Ι”Ο git commit –¬Ϋ®“ΜΗωΧαΫΜΕ‘œσ«ΑΘ§Git Μαœ»ΦΤΥψΟΩ“ΜΗωΉ”ΡΩ¬ΦΒΡ–Θ―ιΚΆΘ§»ΜΚσ‘Ύ Git ≤÷Ωβ÷–ΫΪ’β–©ΡΩ¬Φ±Θ¥φΈΣ ςΘ®treeΘ©Ε‘œσΓΘ÷°Κσ Git ¥¥Ϋ®ΒΡΧαΫΜΕ‘œσΘ§≥ΐΝΥΑϋΚ§œύΙΊΧαΫΜ–≈œΔ“‘ΆβΘ§ΜΙΑϋΚ§Ή≈÷Ηœρ’βΗω ςΕ‘œσΘ®œνΡΩΗυΡΩ¬ΦΘ©ΒΡ÷Η’κΘ§»γ¥ΥΥϋΨΆΩ…“‘‘ΎΫΪά¥–η“ΣΒΡ ±ΚρΘ§÷Ίœ÷¥Υ¥ΈΩλ’’ΒΡΡΎ»ίΝΥΓΘ
œ÷‘ΎΘ§Git ≤÷Ωβ÷–”–ΈεΗωΕ‘œσΘΚ»ΐΗω±μ ΨΈΡΦΰΩλ’’ΡΎ»ίΒΡ blob Ε‘œσΘΜ“ΜΗωΦ«¬ΦΉ≈ΡΩ¬Φ ςΡΎ»ίΦΑΤδ÷–ΗςΗωΈΡΦΰΕ‘”Π blob Ε‘œσΥς“ΐΒΡ tree Ε‘œσΘΜ“‘ΦΑ“ΜΗωΑϋΚ§÷Ηœρ tree Ε‘œσΘ®ΗυΡΩ¬ΦΘ©ΒΡΥς“ΐΚΆΤδΥϊΧαΫΜ–≈œΔ‘Σ ΐΨίΒΡ commit Ε‘œσΓΘΗ≈Ρν…œά¥ΥΒΘ§≤÷Ωβ÷–ΒΡΗςΗωΕ‘œσ±Θ¥φΒΡ ΐΨίΚΆœύΜΞΙΊœΒΩ¥Τπά¥»γΆΦ2-1Υυ ΨΘΚ
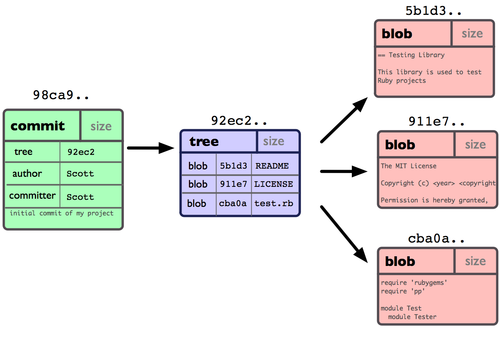
ΆΦ 2-1. ΒΞΗωΧαΫΜΕ‘œσ‘Ύ≤÷Ωβ÷–ΒΡ ΐΨίΫαΙΙ
Ής–©–όΗΡΚσ‘Ό¥ΈΧαΫΜΘ§Ρ«Ο¥’β¥ΈΒΡΧαΫΜΕ‘œσΜαΑϋΚ§“ΜΗω÷Ηœρ…œ¥ΈΧαΫΜΕ‘œσΒΡ÷Η’κΘ®“κΉΔΘΚΦ¥œ¬ΆΦ÷–ΒΡ parent Ε‘œσΘ©ΓΘΝΫ¥ΈΧαΫΜΚσΘ§≤÷Ωβάζ ΖΜα±δ≥…ΆΦ2-2ΒΡ―υΉ”ΘΚ
ΆΦ 2-2. ΕύΗωΧαΫΜΕ‘œσ÷°ΦδΒΡΝ¥Ϋ”ΙΊœΒ
œ÷‘Ύά¥ΧΗΖ÷÷ßΓΘGit ÷–ΒΡΖ÷÷ßΘ§Τδ Β±Ψ÷ …œΫωΫω «Ηω÷Ηœρ commit Ε‘œσΒΡΩ…±δ÷Η’κΓΘGit Μα Ι”Ο master ΉςΈΣΖ÷÷ßΒΡΡ§»œΟϊΉ÷ΓΘ‘Ύ»τΗ…¥ΈΧαΫΜΚσΘ§ΡψΤδ Β“―Ψ≠”–ΝΥ“ΜΗω÷ΗœρΉνΚσ“Μ¥ΈΧαΫΜΕ‘œσΒΡ master Ζ÷÷ßΘ§Υϋ‘ΎΟΩ¥ΈΧαΫΜΒΡ ±ΚρΕΦΜαΉ‘Ε·œρ«Α“ΤΕ·ΓΘ
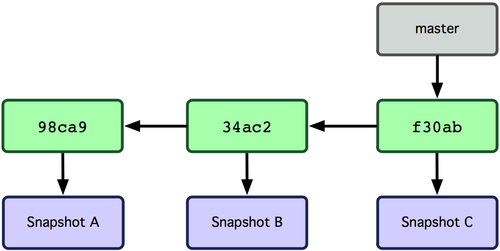
ΆΦ2-3.Ζ÷÷ßΤδ ΒΨΆ «¥”Ρ≥ΗωΧαΫΜΕ‘œσΆυΜΊΩ¥ΒΡάζ Ζ
Ρ«Ο¥Θ§Git ”÷ «»γΚΈ¥¥Ϋ®“ΜΗω–¬ΒΡΖ÷÷ßΒΡΡΊΘΩ¥πΑΗΚήΦρΒΞΘ§¥¥Ϋ®“ΜΗω–¬ΒΡΖ÷÷ß÷Η’κΓΘ±»»γ–¬Ϋ®“ΜΗω testing Ζ÷÷ßΘ§Ω…“‘ Ι”Ο git branch ΟϋΝνΘΚ
’βΜα‘ΎΒ±«Α commit Ε‘œσ…œ–¬Ϋ®“ΜΗωΖ÷÷ß÷Η’κΘ®ΦϊΆΦ2-4Θ©ΓΘ
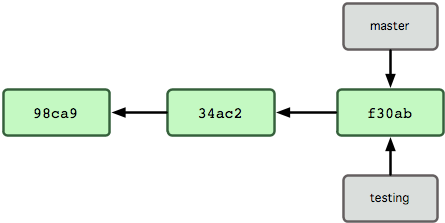
ΆΦ 2-4. ΕύΗωΖ÷÷ß÷ΗœρΧαΫΜ ΐΨίΒΡάζ Ζ
Ρ«Ο¥Θ§Git «»γΚΈ÷ΣΒάΡψΒ±«Α‘ΎΡΡΗωΖ÷÷ß…œΙΛΉςΒΡΡΊΘΩΤδ Β¥πΑΗ“≤ΚήΦρΒΞΘ§Υϋ±Θ¥φΉ≈“ΜΗωΟϊΈΣ HEAD ΒΡΧΊ±π÷Η’κΓΘ«κΉΔ“βΥϋΚΆΡψ λ÷ΣΒΡ–μΕύΤδΥϊΑφ±ΨΩΊ÷ΤœΒΆ≥Θ®±»»γ Subversion Μρ CVSΘ©άοΒΡ HEAD Η≈Ρν¥σ≤ΜœύΆ§ΓΘ‘Ύ Git ÷–Θ§Υϋ «“ΜΗω÷ΗœρΡψ’ΐ‘ΎΙΛΉς÷–ΒΡ±ΨΒΊΖ÷÷ßΒΡ÷Η’κΓΘ‘Υ–– git branch ΟϋΝνΘ§ΫωΫω «Ϋ®ΝΔΝΥ“ΜΗω–¬ΒΡΖ÷÷ßΘ§ΒΪ≤ΜΜαΉ‘Ε·«–ΜΜΒΫ’βΗωΖ÷÷ß÷–»ΞΘ§Υυ“‘‘Ύ’βΗωάΐΉ”÷–Θ§Έ“Ο«“ά»ΜΜΙ‘Ύ master Ζ÷÷ßάοΙΛΉςΘ®≤ΈΩΦΆΦ 2-5Θ©
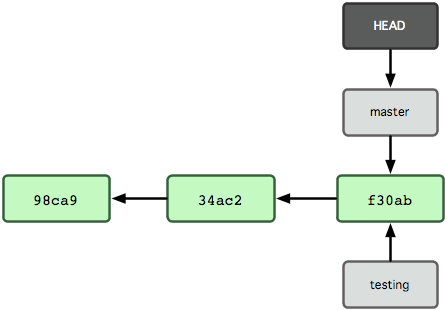
ΆΦ 2-5. HEAD ÷ΗœρΒ±«ΑΥυ‘ΎΒΡΖ÷÷ß
“Σ«–ΜΜΒΫΤδΥϊΖ÷÷ßΘ§Ω…“‘÷¥–– git checkout ΟϋΝνΓΘΈ“Ο«œ÷‘ΎΉΣΜΜΒΫ–¬Ϋ®ΒΡ testing Ζ÷÷ßΘΚ
’β―υ HEAD ΨΆ÷ΗœρΝΥ testing Ζ÷÷ßΘ®ΦϊΆΦ2-6Θ©ΓΘ

ΆΦ 2-6. HEAD ‘ΎΡψΉΣΜΜΖ÷÷ß ±÷Ηœρ–¬ΒΡΖ÷÷ß
’β―υΒΡ Βœ÷ΖΫ ΫΜαΗχΈ“Ο«¥χά¥ ≤Ο¥ΚΟ¥ΠΡΊΘΩΚΟΑ…Θ§œ÷‘Ύ≤ΜΖΝ‘ΌΧαΫΜ“Μ¥ΈΘΚ
# step 1
$ vim test.rb
# step 2
$ git commit -a -m 'made a change' |
ΆΦ 2-7 ’Ι ΨΝΥΧαΫΜΚσΒΡΫαΙϊ
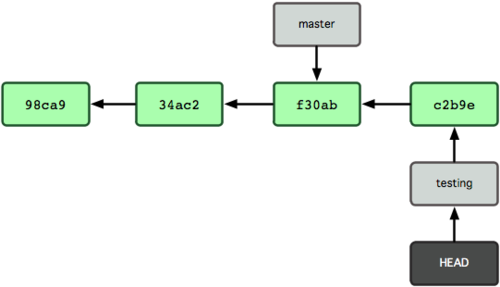
ΆΦ 2-7. ΟΩ¥ΈΧαΫΜΚσ HEAD ΥφΉ≈Ζ÷÷ß“ΜΤπœρ«Α“ΤΕ·
Ζ«≥Θ”–»ΛΘ§œ÷‘Ύ testing Ζ÷÷ßœρ«Α“ΤΕ·ΝΥ“ΜΗώΘ§Εχ master Ζ÷÷ß»‘»Μ÷Ηœρ‘≠œ» git checkout ±Υυ‘ΎΒΡ commit Ε‘œσΓΘœ÷‘ΎΈ“Ο«ΜΊΒΫ master Ζ÷÷ßΩ¥Ω¥ΘΚ
ΆΦ 2-8 œ‘ ΨΝΥΫαΙϊ
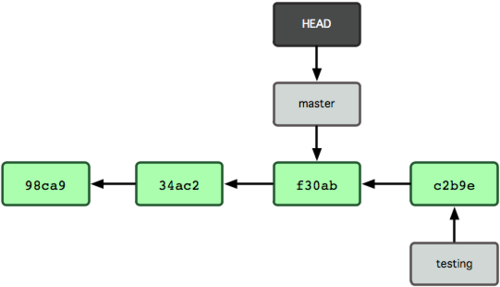
ΆΦ 2-8. HEAD ‘Ύ“Μ¥Έ checkout ÷°Κσ“ΤΕ·ΒΫΝΥΝμ“ΜΗωΖ÷÷ß
’βΧθΟϋΝνΉωΝΥΝΫΦΰ ¬ΓΘΥϋΑ― HEAD ÷Η’κ“ΤΜΊΒΫ master Ζ÷÷ßΘ§≤ΔΑ―ΙΛΉςΡΩ¬Φ÷–ΒΡΈΡΦΰΜΜ≥…ΝΥ master Ζ÷÷ßΥυ÷ΗœρΒΡΩλ’’ΡΎ»ίΓΘ“≤ΨΆ «ΥΒΘ§œ÷‘ΎΩΣ ΦΥυΉωΒΡΗΡΕ·Θ§ΫΪ Φ”Ύ±ΨœνΡΩ÷–“ΜΗωΫœάœΒΡΑφ±ΨΓΘΥϋΒΡ÷ς“ΣΉς”Ο «ΫΪ testing Ζ÷÷ßάοΉς≥ωΒΡ–όΗΡ‘ί ±»ΓœϊΘ§’β―υΡψΨΆΩ…“‘œρΝμ“ΜΗωΖΫœρΫχ––ΩΣΖΔΓΘ
Έ“Ο«Ής–©–όΗΡΚσ‘Ό¥ΈΧαΫΜΘΚ
# step 1
$ vim test.js
# step 2
$ git commit -a -m 'made other changes' |
œ÷‘ΎΈ“Ο«ΒΡœνΡΩΧαΫΜάζ Ζ≤ζ…ζΝΥΖ÷≤φΘ®»γΆΦ 2-9 Υυ ΨΘ©Θ§“ρΈΣΗ’≤≈Έ“Ο«¥¥Ϋ®ΝΥ“ΜΗωΖ÷÷ßΘ§ΉΣΜΜΒΫΤδ÷–Ϋχ––ΝΥ“Μ–©ΙΛΉςΘ§»ΜΚσ”÷ΜΊΒΫ‘≠ά¥ΒΡ÷ςΖ÷÷ßΫχ––ΝΥΝμΆβ“Μ–©ΙΛΉςΓΘ’β–©ΗΡ±δΖ÷±πΙ¬ΝΔ‘Ύ≤ΜΆ§ΒΡΖ÷÷ßάοΘΚΈ“Ο«Ω…“‘‘Ύ≤ΜΆ§Ζ÷÷ßάοΖ¥Η¥«–ΜΜΘ§≤Δ‘Ύ ±Μζ≥… λ ±Α―ΥϋΟ«Κœ≤ΔΒΫ“ΜΤπΓΘΕχΥυ”–’β–©ΙΛΉςΘ§ΫωΫω–η“Σbranch ΚΆ checkout ’βΝΫΧθΟϋΝνΨΆΩ…“‘Άξ≥…
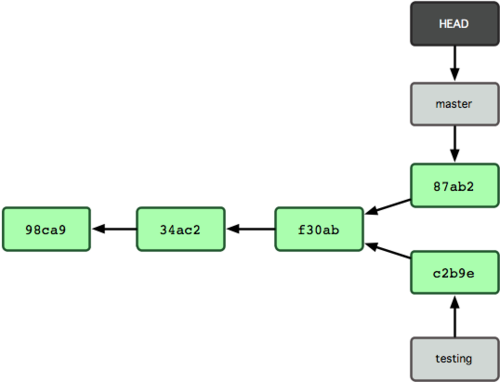
ΆΦ 2-9. ≤ΜΆ§ΝςœρΒΡΖ÷÷ßάζ Ζ
2ΓΔΖ÷÷ßΒΡ–¬Ϋ®”κΚœ≤Δ
œ÷‘Ύ»ΟΈ“Ο«ά¥Ω¥“ΜΗωΦρΒΞΒΡΖ÷÷ß”κΚœ≤ΔΒΡάΐΉ”Θ§ ΒΦ ΙΛΉς÷–¥σΧε“≤Μα”ΟΒΫ’β―υΒΡΙΛΉςΝς≥ΧΘΚ
ΩΣΖΔΡ≥ΗωΆχ’ΨΓΘ
ΈΣ Βœ÷Ρ≥Ηω–¬ΒΡ–η«σΘ§¥¥Ϋ®“ΜΗωΖ÷÷ßΓΘ
‘Ύ’βΗωΖ÷÷ß…œΩΣ’ΙΙΛΉςΓΘ
ΦΌ…η¥Υ ±Θ§ΡψΆΜ»ΜΫ”ΒΫ“ΜΗωΒγΜΑΥΒ”–ΗωΚή―œ÷ΊΒΡΈ Χβ–η“ΣΫτΦ±–ό≤ΙΘ§Ρ«Ο¥Ω…“‘Α¥’’œ¬ΟφΒΡΖΫ Ϋ¥ΠάμΘΚ
ΖΒΜΊΒΫ‘≠œ»“―Ψ≠ΖΔ≤ΦΒΫ…ζ≤ζΖΰΈώΤς…œΒΡΖ÷÷ßΓΘ
ΈΣ’β¥ΈΫτΦ±–ό≤ΙΫ®ΝΔ“ΜΗω–¬Ζ÷÷ßΘ§≤Δ‘ΎΤδ÷––όΗ¥Έ ΧβΓΘ
Ά®Ιΐ≤β ‘ΚσΘ§ΜΊΒΫ…ζ≤ζΖΰΈώΤςΥυ‘ΎΒΡΖ÷÷ßΘ§ΫΪ–ό≤ΙΖ÷÷ßΚœ≤ΔΫχά¥Θ§»ΜΚσ‘ΌΆΤΥΆΒΫ…ζ≤ζΖΰΈώΤς…œΓΘ
«–ΜΜΒΫ÷°«Α Βœ÷–¬–η«σΒΡΖ÷÷ßΘ§ΦΧ–χΙΛΉςΓΘ
a.Ζ÷÷ßΒΡ–¬Ϋ®”κ«–ΜΜ
Ήœ»Θ§Έ“Ο«ΦΌ…ηΡψ’ΐ‘ΎœνΡΩ÷–”δΩλΒΊΙΛΉςΘ§≤Δ«““―Ψ≠ΧαΫΜΝΥΦΗ¥ΈΗϋ–¬Θ®ΦϊΆΦ 2-10Θ©ΓΘ
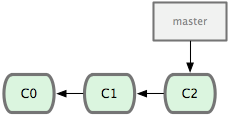
ΆΦ 2-10. “ΜΗωΦρΕΧΒΡΧαΫΜάζ Ζ
œ÷‘ΎΘ§ΡψΨωΕ®“Σ–ό≤ΙΈ ΧβΉΖΉΌœΒΆ≥…œΒΡ #53 Έ ΧβΓΘΥ≥¥χΥΒΟςœ¬Θ§Git ≤Δ≤ΜΆ§»ΈΚΈΧΊΕ®ΒΡΈ ΧβΉΖΉΌœΒΆ≥¥ρΫΜΒάΓΘ’βάοΈΣΝΥΥΒΟς“ΣΫβΨωΒΡΈ ΧβΘ§≤≈Α―–¬Ϋ®ΒΡΖ÷÷ß»ΓΟϊΈΣ iss53ΓΘ“Σ–¬Ϋ®≤Δ«–ΜΜΒΫΗΟΖ÷÷ßΘ§‘Υ–– git checkout ≤ΔΦ”…œ -b ≤Έ ΐΘΚ
$ git checkout -b iss53
#Switched to a new branch "iss53" |
’βœύΒ±”Ύ÷¥––œ¬Οφ’βΝΫΧθΟϋΝνΘΚ
# step 1
$ git branch iss53
# step 2
$ git checkout iss53 |
ΆΦ 2-11 Ψ“βΗΟΟϋΝνΒΡ÷¥––ΫαΙϊΓΘ
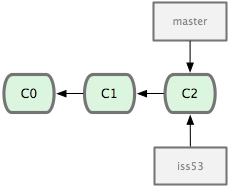
ΆΦ 2-11. ¥¥Ϋ®ΝΥ“ΜΗω–¬Ζ÷÷ßΒΡ÷Η’κ
Ϋ”Ή≈ΡψΩΣ Φ≥Δ ‘–όΗ¥Έ ΧβΘ§‘ΎΧαΫΜΝΥ»τΗ…¥ΈΗϋ–¬ΚσΘ§iss53 Ζ÷÷ßΒΡ÷Η’κ“≤ΜαΥφΉ≈œρ«ΑΆΤΫχΘ§“ρΈΣΥϋΨΆ «Β±«ΑΖ÷÷ßΘ®ΜΜΨδΜΑΥΒΘ§Β±«ΑΒΡ HEAD ÷Η’κ’ΐ÷Ηœρ iss53Θ§ΦϊΆΦ 2-12Θ©ΘΚ
# step 1
$ vim index.html
# step 2
$ git commit -a -m 'added a new footer [issue 53]' |
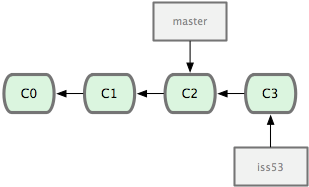
ΆΦ 2-12. iss53 Ζ÷÷ßΥφΙΛΉςΫχ’Ιœρ«ΑΆΤΫχ
œ÷‘ΎΡψΨΆΫ”ΒΫΝΥΡ«ΗωΆχ’ΨΈ ΧβΒΡΫτΦ±ΒγΜΑΘ§–η“Σ¬μ…œ–ό≤ΙΓΘ”–ΝΥ Git Θ§Έ“Ο«ΨΆ≤Μ–η“ΣΆ§ ±ΖΔ≤Φ’βΗω≤ΙΕΓΚΆ iss53 άοΉς≥ωΒΡ–όΗΡΘ§“≤≤Μ–η“Σ‘Ύ¥¥Ϋ®ΚΆΖΔ≤ΦΗΟ≤ΙΕΓΒΫΖΰΈώΤς÷°«ΑΜ®Ζ―¥σΝΠΤχά¥Η¥‘≠’β–©–όΗΡΓΘΈ®“Μ–η“ΣΒΡΫωΫω ««–ΜΜΜΊ master Ζ÷÷ßΓΘ
≤ΜΙΐ‘Ύ¥Υ÷°«ΑΘ§Ντ–ΡΡψΒΡ‘ί¥φ«χΜρ’ΏΙΛΉςΡΩ¬ΦάοΘ§Ρ«–©ΜΙΟΜ”–ΧαΫΜΒΡ–όΗΡΘ§ΥϋΜαΚΆΡψΦ¥ΫΪΦλ≥ωΒΡΖ÷÷ß≤ζ…ζ≥εΆΜ¥”ΕχΉη÷Ι Git ΈΣΡψ«–ΜΜΖ÷÷ßΓΘ«–ΜΜΖ÷÷ßΒΡ ±ΚρΉνΚΟ±Θ≥÷“ΜΗω«εΫύΒΡΙΛΉς«χ”ρΓΘ…‘ΚσΜαΫι…ήΦΗΗω»ΤΙΐ’β÷÷Έ ΧβΒΡΑλΖ®Θ®Ζ÷±πΫ–Ήω stashing ΚΆ commit amendingΘ©ΓΘΡΩ«Α“―Ψ≠ΧαΫΜΝΥΥυ”–ΒΡ–όΗΡΘ§Υυ“‘Ϋ”œ¬ά¥Ω…“‘’ΐ≥ΘΉΣΜΜΒΫ master Ζ÷÷ßΘΚ
$ git checkout master
#Switched to branch "master" |
¥Υ ±ΙΛΉςΡΩ¬Φ÷–ΒΡΡΎ»ίΚΆΡψ‘ΎΫβΨωΈ Χβ #53 ÷°«Α“ΜΡΘ“Μ―υΘ§ΡψΩ…“‘Φ·÷–ΨΪΝΠΫχ––ΫτΦ±–ό≤ΙΓΘ’β“ΜΒψ÷ΒΒΟάΈΦ«ΘΚGit ΜαΑ―ΙΛΉςΡΩ¬ΦΒΡΡΎ»ίΜ÷Η¥ΈΣΦλ≥ωΡ≥Ζ÷÷ß ±ΥϋΥυ÷ΗœρΒΡΡ«ΗωΧαΫΜΕ‘œσΒΡΩλ’’ΓΘΥϋΜαΉ‘Ε·ΧμΦ”ΓΔ…Ψ≥ΐΚΆ–όΗΡΈΡΦΰ“‘»Ζ±ΘΡΩ¬ΦΒΡΡΎ»ίΚΆΡψΒ± ±ΧαΫΜ ±Άξ»Ϊ“Μ―υΓΘ
Ϋ”œ¬ά¥Θ§ΡψΒΟΫχ––ΫτΦ±–ό≤ΙΓΘΈ“Ο«¥¥Ϋ®“ΜΗωΫτΦ±–ό≤ΙΖ÷÷ß hotfix ά¥ΩΣ’ΙΙΛΉςΘ§÷±ΒΫΗψΕ®Θ®ΦϊΆΦ 2-13Θ©
# step 1
$ git checkout -b 'hotfix'
#Switched to a new branch "hotfix"
# step 2
$ vim index.html
# step 3
$ git commit -a -m 'fixed the broken email address'
#[hotfix]: created 3a0874c: "fixed the broken email address"
#1 files changed, 0 insertions(+), 1 deletions(-) |
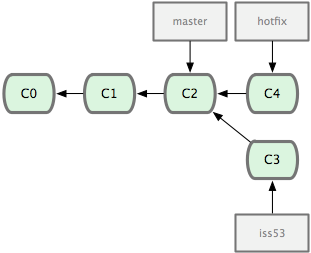
ΆΦ 2-13. hotfix Ζ÷÷ß «¥” master Ζ÷÷ßΥυ‘ΎΒψΖ÷Μ·≥ωά¥ΒΡ
”–±Ί“ΣΉς–©≤β ‘Θ§»Ζ±Θ–ό≤Ι «≥…ΙΠΒΡΘ§»ΜΚσΜΊΒΫ master Ζ÷÷ß≤ΔΑ―ΥϋΚœ≤ΔΫχά¥Θ§»ΜΚσΖΔ≤ΦΒΫ…ζ≤ζΖΰΈώΤςΓΘ”Ο git merge ΟϋΝνά¥Ϋχ––Κœ≤ΔΘΚ
# step 1
$ git checkout master
# step 2
$ git merge hotfix
#Updating f42c576..3a0874c
#Fast forward
#README | 1 -
#1 files changed, 0 insertions(+), 1 deletions(-) |
«κΉΔ“βΘ§Κœ≤Δ ±≥ωœ÷ΝΥΓΑFast forwardΓ±ΒΡΧα ΨΓΘ”…”ΎΒ±«Α master Ζ÷÷ßΥυ‘ΎΒΡΧαΫΜΕ‘œσ «“Σ≤Δ»κΒΡ hotfix Ζ÷÷ßΒΡ÷±Ϋ”…œ”ΈΘ§Git ÷Μ–ηΑ― masterΖ÷÷ß÷Η’κ÷±Ϋ””““ΤΓΘΜΜΨδΜΑΥΒΘ§»γΙϊΥ≥Ή≈“ΜΗωΖ÷÷ßΉΏœ¬»ΞΩ…“‘ΒΫ¥οΝμ“ΜΗωΖ÷÷ßΒΡΜΑΘ§Ρ«Ο¥ Git ‘ΎΚœ≤ΔΝΫ’Ώ ±Θ§÷ΜΜαΦρΒΞΒΊΑ―÷Η’κ”““ΤΘ§“ρΈΣ’β÷÷ΒΞœΏΒΡάζ ΖΖ÷÷ß≤Μ¥φ‘Ύ»ΈΚΈ–η“ΣΫβΨωΒΡΖ÷ΤγΘ§Υυ“‘’β÷÷Κœ≤ΔΙΐ≥ΧΩ…“‘≥ΤΈΣΩλΫχΘ®Fast forwardΘ©ΓΘ
œ÷‘ΎΉν–¬ΒΡ–όΗΡ“―Ψ≠‘ΎΒ±«Α master Ζ÷÷ßΥυ÷ΗœρΒΡΧαΫΜΕ‘œσ÷–ΝΥΘ§Ω…“‘≤Ω πΒΫ…ζ≤ζΖΰΈώΤς…œ»ΞΝΥΘ®ΦϊΆΦ 2-14Θ©ΓΘ
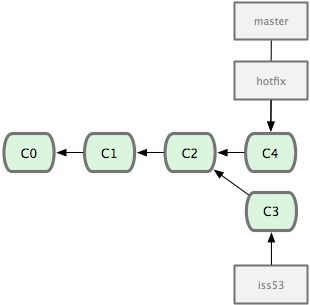
ΆΦ 2-14. Κœ≤Δ÷°ΚσΘ§master Ζ÷÷ßΚΆ hotfix Ζ÷÷ß÷ΗœρΆ§“ΜΈΜ÷ΟΓΘ
‘ΎΡ«Ηω≥§ΦΕ÷Ί“ΣΒΡ–ό≤ΙΖΔ≤Φ“‘ΚσΘ§Ρψœκ“ΣΜΊΒΫ±Μ¥ρ»≈÷°«ΑΒΡΙΛΉςΓΘ”…”ΎΒ±«Α hotfix Ζ÷÷ßΚΆ master ΕΦ÷ΗœρœύΆ§ΒΡΧαΫΜΕ‘œσΘ§Υυ“‘ hotfix “―Ψ≠Άξ≥…ΝΥάζ Ζ ΙΟϋΘ§Ω…“‘…ΨΒτΝΥΓΘ Ι”Ο git branch ΒΡ -d ―Γœν÷¥––…Ψ≥ΐ≤ΌΉςΘΚ
$ git branch -d hotfix
#Deleted branch hotfix (3a0874c). |
œ÷‘ΎΜΊΒΫ÷°«ΑΈ¥Άξ≥…ΒΡ #53 Έ Χβ–όΗ¥Ζ÷÷ß…œΦΧ–χΙΛΉςΘ®ΆΦ 2-15Θ©ΘΚ
# step 1
$ git checkout iss53
#Switched to branch "iss53"
# step 2
$ vim index.html
# step 3
$ git commit -a -m 'finished the new footer [issue 53]'
#[iss53]: created ad82d7a: "finished the new footer [issue 53]"
#1 files changed, 1 insertions(+), 0 deletions(-) |
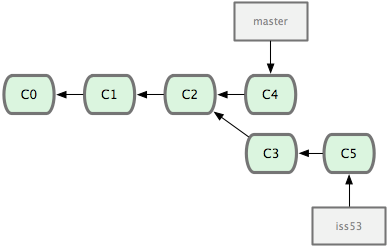
ΆΦ 2-15. iss53 Ζ÷÷ßΩ…“‘≤Μ ή”ΑœλΦΧ–χΆΤΫχΓΘ
≤Μ”ΟΒΘ–Ρ÷°«Α hotfix Ζ÷÷ßΒΡ–όΗΡΡΎ»ί…–Έ¥ΑϋΚ§ΒΫ iss53 ÷–ά¥ΓΘ»γΙϊ»Ζ Β–η“ΣΡ…»κ¥Υ¥Έ–ό≤ΙΘ§Ω…“‘”Ο git merge master Α― master Ζ÷÷ßΚœ≤ΔΒΫ iss53ΘΜΜρ’ΏΒ» iss53 Άξ≥…÷°ΚσΘ§‘ΌΫΪ iss53 Ζ÷÷ß÷–ΒΡΗϋ–¬≤Δ»κ masterΓΘ
b.Ζ÷÷ßΒΡΚœ≤Δ
‘ΎΈ Χβ #53 œύΙΊΒΡΙΛΉςΆξ≥…÷°ΚσΘ§Ω…“‘Κœ≤ΔΜΊ master Ζ÷÷ßΓΘ ΒΦ ≤ΌΉςΆ§«ΑΟφΚœ≤Δ hotfix Ζ÷÷ß≤ν≤ΜΕύΘ§÷Μ–ηΜΊΒΫ master Ζ÷÷ßΘ§‘Υ––git merge ΟϋΝν÷ΗΕ®“ΣΚœ≤ΔΫχά¥ΒΡΖ÷÷ßΘΚ
# step 1
$ git checkout master
# step 2
$ git merge iss53
#Merge made by recursive.
#README | 1 +
#1 files changed, 1 insertions(+), 0 deletions(-) |
«κΉΔ“βΘ§’β¥ΈΚœ≤Δ≤ΌΉςΒΡΒΉ≤ψ Βœ÷Θ§≤Δ≤ΜΆ§”Ύ÷°«Α hotfix ΒΡ≤Δ»κΖΫ ΫΓΘ“ρΈΣ’β¥ΈΡψΒΡΩΣΖΔάζ Ζ «¥”Ηϋ‘γΒΡΒΊΖΫΩΣ ΦΖ÷≤φΒΡΓΘ”…”ΎΒ±«Α master Ζ÷÷ßΥυ÷ΗœρΒΡΧαΫΜΕ‘œσΘ®C4Θ©≤Δ≤Μ « iss53 Ζ÷÷ßΒΡ÷±Ϋ”Ήφœ»Θ§Git ≤ΜΒΟ≤ΜΫχ––“Μ–©ΕνΆβ¥ΠάμΓΘΨΆ¥ΥάΐΕχ―‘Θ§Git Μα”ΟΝΫΗωΖ÷÷ßΒΡΡ©ΕΥΘ®C4 ΚΆ C5Θ©“‘ΦΑΥϋΟ«ΒΡΙ≤Ά§Ήφœ»Θ®C2Θ©Ϋχ––“Μ¥ΈΦρΒΞΒΡ»ΐΖΫΚœ≤ΔΦΤΥψΓΘΆΦ 2-16 ”ΟΚλΩρ±ξ≥ωΝΥ Git ”Ο”ΎΚœ≤ΔΒΡ»ΐΗωΧαΫΜΕ‘œσΘΚ
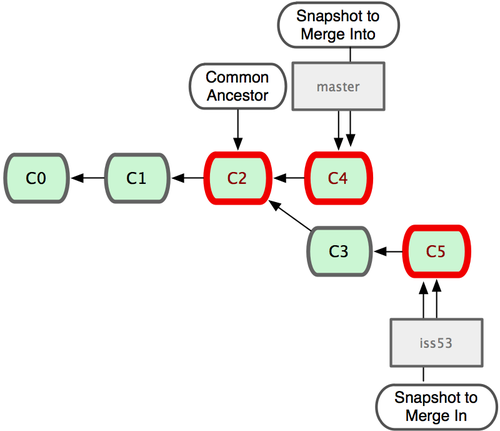
ΆΦ 2-16. Git ΈΣΖ÷÷ßΚœ≤ΔΉ‘Ε· Ε±π≥ωΉνΦ―ΒΡΆ§‘¥Κœ≤ΔΒψΓΘ
’β¥ΈΘ§Git ΟΜ”–ΦρΒΞΒΊΑ―Ζ÷÷ß÷Η’κ”““ΤΘ§Εχ «Ε‘»ΐΖΫΚœ≤ΔΚσΒΡΫαΙϊ÷Ί–¬Ήω“ΜΗω–¬ΒΡΩλ’’Θ§≤ΔΉ‘Ε·¥¥Ϋ®“ΜΗω÷ΗœρΥϋΒΡΧαΫΜΕ‘œσΘ®C6Θ©Θ®ΦϊΆΦ 2-17Θ©ΓΘ’βΗωΧαΫΜΕ‘œσ±»ΫœΧΊ βΘ§Υϋ”–ΝΫΗωΉφœ»Θ®C4 ΚΆ C5Θ©ΓΘ
÷ΒΒΟ“ΜΧαΒΡ « Git Ω…“‘Ή‘ΦΚ≤ΟΨωΡΡΗωΙ≤Ά§Ήφœ»≤≈ «ΉνΦ―Κœ≤ΔΜυ¥ΓΘΜ’βΚΆ CVS Μρ SubversionΘ®1.5 “‘ΚσΒΡΑφ±ΨΘ©≤ΜΆ§Θ§ΥϋΟ«–η“ΣΩΣΖΔ’Ώ ÷ΙΛ÷ΗΕ®Κœ≤ΔΜυ¥ΓΓΘΥυ“‘¥ΥΧΊ–‘»Ο Git ΒΡΚœ≤Δ≤ΌΉς±»ΤδΥϊœΒΆ≥ΕΦ“ΣΦρΒΞ≤Μ…ΌΓΘ
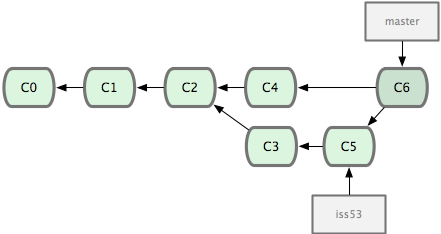
ΆΦ 2-17. Git Ή‘Ε·¥¥Ϋ®ΝΥ“ΜΗωΑϋΚ§ΝΥΚœ≤ΔΫαΙϊΒΡΧαΫΜΕ‘œσΓΘ
Φ»»Μ÷°«ΑΒΡΙΛΉς≥…Ιϊ“―Ψ≠Κœ≤ΔΒΫ master ΝΥΘ§Ρ«Ο¥ iss53 “≤ΨΆΟΜ”ΟΝΥΓΘΡψΩ…“‘ΨΆ¥Υ…Ψ≥ΐΥϋΘ§≤Δ‘ΎΈ ΧβΉΖΉΌœΒΆ≥άοΙΊ±’ΗΟΈ ΧβΓΘ
c.”ωΒΫ≥εΆΜ ±ΒΡΖ÷÷ßΚœ≤Δ
”– ±ΚρΚœ≤Δ≤ΌΉς≤Δ≤ΜΜα»γ¥ΥΥ≥άϊΓΘ»γΙϊ‘Ύ≤ΜΆ§ΒΡΖ÷÷ß÷–ΕΦ–όΗΡΝΥΆ§“ΜΗωΈΡΦΰΒΡΆ§“Μ≤ΩΖ÷Θ§Git ΨΆΈόΖ®Η…ΨΜΒΊΑ―ΝΫ’ΏΚœΒΫ“ΜΤπΓΘ»γΙϊΡψ‘ΎΫβΨωΈ Χβ #53 ΒΡΙΐ≥Χ÷––όΗΡΝΥ hotfix ÷––όΗΡΒΡ≤ΩΖ÷Θ§ΫΪΒΟΒΫάύΥΤœ¬ΟφΒΡΫαΙϊΘΚ
$ git merge iss53
#Auto-merging index.html
#CONFLICT (content): Merge conflict in index.html
#Automatic merge failed; fix conflicts and then commit the result. |
Git ΉςΝΥΚœ≤ΔΘ§ΒΪΟΜ”–ΧαΫΜΘ§ΥϋΜαΆΘœ¬ά¥Β»ΡψΫβΨω≥εΆΜΓΘ“ΣΩ¥Ω¥ΡΡ–©ΈΡΦΰ‘ΎΚœ≤Δ ±ΖΔ…ζ≥εΆΜΘ§Ω…“‘”Ο git status ≤ι‘ΡΘΚ
[master*]$ git status
# index.html: needs merge
# On branch master
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
# (use "git checkout -- <file>..." to discard changes in working directory)
#
# unmerged: index.html
# |
»ΈΚΈΑϋΚ§Έ¥ΫβΨω≥εΆΜΒΡΈΡΦΰΕΦΜα“‘Έ¥Κœ≤ΔΘ®unmergedΘ©ΒΡΉ¥Χ§Ν–≥ωΓΘGit Μα‘Ύ”–≥εΆΜΒΡΈΡΦΰάοΦ”»κ±ξΉΦΒΡ≥εΆΜΫβΨω±ξΦ«Θ§Ω…“‘Ά®ΙΐΥϋΟ«ά¥ ÷ΙΛΕ®ΈΜ≤ΔΫβΨω’β–©≥εΆΜΓΘΩ…“‘Ω¥ΒΫ¥ΥΈΡΦΰΑϋΚ§άύΥΤœ¬Οφ’β―υΒΡ≤ΩΖ÷ΘΚ
<<<<<<< HEAD:index.html
<div id="footer">contact : email.support@github.com</div>
=======
<div id="footer">
please contact us at support@github.com
</div>
>>>>>>> iss53:index.html |
Ω…“‘Ω¥ΒΫ ======= ΗτΩΣΒΡ…œΑκ≤ΩΖ÷Θ§ « HEADΘ®Φ¥ master Ζ÷÷ßΘ§‘Ύ‘Υ–– merge ΟϋΝν ±Υυ«–ΜΜΒΫΒΡΖ÷÷ßΘ©÷–ΒΡΡΎ»ίΘ§œ¬Ακ≤ΩΖ÷ «‘Ύ iss53Ζ÷÷ß÷–ΒΡΡΎ»ίΓΘΫβΨω≥εΆΜΒΡΑλΖ®ΈόΖ« «Εΰ’Ώ―ΓΤδ“ΜΜρ’Ώ”…Ρψ«ΉΉ‘’ϊΚœΒΫ“ΜΤπΓΘ±»»γΡψΩ…“‘Ά®ΙΐΑ―’βΕΈΡΎ»ίΧφΜΜΈΣœ¬Οφ’β―υά¥ΫβΨωΘΚ
<div id="footer">
please contact us at email.support@github.com
</div> |
’βΗωΫβΨωΖΫΑΗΗς≤…Ρ…ΝΥΝΫΗωΖ÷÷ß÷–ΒΡ“Μ≤ΩΖ÷ΡΎ»ίΘ§Εχ«“Έ“ΜΙ…Ψ≥ΐΝΥ <<<<<<<Θ§======= ΚΆ >>>>>>> ’β–©––ΓΘ‘ΎΫβΨωΝΥΥυ”–ΈΡΦΰάοΒΡΥυ”–≥εΆΜΚσΘ§‘Υ–– git add ΫΪΑ―ΥϋΟ«±ξΦ«ΈΣ“―ΫβΨωΉ¥Χ§Θ® ΒΦ …œΨΆ «ά¥“Μ¥ΈΩλ’’±Θ¥φΒΫ‘ί¥φ«χ”ρΘ©ΓΘ“ρΈΣ“ΜΒ©‘ί¥φΘ§ΨΆ±μ Ψ≥εΆΜ“―Ψ≠ΫβΨωΓΘ
‘Ό‘Υ––“Μ¥Έ git status ά¥»Ζ»œΥυ”–≥εΆΜΕΦ“―ΫβΨωΘΚ
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# modified: index.html
# |
»γΙϊΨθΒΟ¬ζ“βΝΥΘ§≤Δ«“»Ζ»œΥυ”–≥εΆΜΕΦ“―ΫβΨωΘ§“≤ΨΆ «Ϋχ»κΝΥ‘ί¥φ«χΘ§ΨΆΩ…“‘”Ο git commit ά¥Άξ≥…’β¥ΈΚœ≤ΔΧαΫΜΓΘΧαΫΜΒΡΦ«¬Φ≤ν≤ΜΕύ «’β―υΘΚ
# Merge branch 'iss53'
# Conflicts:
# index.html
#
# It looks like you may be committing a MERGE.
# If this is not correct, please remove the file
# .git/MERGE_HEAD
# and try again.
# |
»γΙϊœκΗχΫΪά¥Ω¥’β¥ΈΚœ≤ΔΒΡ»Υ“Μ–©ΖΫ±ψΘ§Ω…“‘–όΗΡΗΟ–≈œΔΘ§ΧαΙ©ΗϋΕύΚœ≤ΔœΗΫΎΓΘ±»»γΡψΕΦΉςΝΥΡΡ–©ΗΡΕ·Θ§“‘ΦΑ’βΟ¥ΉωΒΡ‘≠“ρΓΘ”– ±Κρ≤ΟΨω≥εΆΜΒΡάμ”…≤Δ≤Μ÷±Ϋ”ΜρΟςœ‘Θ§”–±Ί“Σ¬‘Φ”ΉΔΫβΓΘ
3ΓΔΖ÷÷ßΒΡΙήάμ
ΒΫΡΩ«ΑΈΣ÷ΙΘ§Ρψ“―Ψ≠―ßΜαΝΥ»γΚΈ¥¥Ϋ®ΓΔΚœ≤ΔΚΆ…Ψ≥ΐΖ÷÷ßΓΘ≥ΐ¥Υ÷°ΆβΘ§Έ“Ο«ΜΙ–η“Σ―ßœΑ»γΚΈΙήάμΖ÷÷ßΘ§‘Ύ»’ΚσΒΡ≥ΘΙφΙΛΉς÷–ΜαΨ≠≥Θ”ΟΒΫœ¬ΟφΫι…ήΒΡΙήάμΟϋΝνΓΘ
git branch ΟϋΝν≤ΜΫωΫωΡή¥¥Ϋ®ΚΆ…Ψ≥ΐΖ÷÷ßΘ§»γΙϊ≤ΜΦ”»ΈΚΈ≤Έ ΐΘ§ΥϋΜαΗχ≥ωΒ±«ΑΥυ”–Ζ÷÷ßΒΡ«εΒΞΘΚ
$ git branch
# iss53
# * master
# testing |
ΉΔ“βΩ¥ master Ζ÷÷ß«ΑΒΡ * Ή÷ΖϊΘΚΥϋ±μ ΨΒ±«ΑΥυ‘ΎΒΡΖ÷÷ßΓΘ“≤ΨΆ «ΥΒΘ§»γΙϊœ÷‘ΎΧαΫΜΗϋ–¬Θ§master Ζ÷÷ßΫΪΥφΉ≈ΩΣΖΔΫχΕ»«Α“ΤΓΘ»τ“Σ≤ιΩ¥ΗςΗωΖ÷÷ßΉνΚσ“ΜΗωΧαΫΜΕ‘œσΒΡ–≈œΔΘ§‘Υ–– git branch -vΘΚ
$ git branch -v
#iss53 93b412c fix javascript issue
#* master 7a98805 Merge branch 'iss53'
#testing 782fd34 add qiangdada to the author list in the readmes |
“Σ¥”ΗΟ«εΒΞ÷–…Η―Γ≥ωΡψ“―Ψ≠Θ®Μρ…–Έ¥Θ©”κΒ±«ΑΖ÷÷ßΚœ≤ΔΒΡΖ÷÷ßΘ§Ω…“‘”Ο --merge ΚΆ --no-merged ―ΓœνΘ®Git 1.5.6 “‘…œΑφ±ΨΘ©ΓΘ±»»γ”Ο git branch --merge ≤ιΩ¥ΡΡ–©Ζ÷÷ß“―±Μ≤Δ»κΒ±«ΑΖ÷÷ß
$ git branch --merged
# iss53
# * master |
÷°«ΑΈ“Ο«“―Ψ≠Κœ≤ΔΝΥ iss53Θ§Υυ“‘‘Ύ’βάοΜαΩ¥ΒΫΥϋΓΘ“ΜΑψά¥ΥΒΘ§Ν–±μ÷–ΟΜ”– * ΒΡΖ÷÷ßΆ®≥ΘΕΦΩ…“‘”Ο git branch -d ά¥…ΨΒτΓΘ‘≠“ρΚήΦρΒΞΘ§Φ»»Μ“―Ψ≠Α―ΥϋΟ«ΥυΑϋΚ§ΒΡΙΛΉς’ϊΚœΒΫΝΥΤδΥϊΖ÷÷ßΘ§…ΨΒτ“≤≤ΜΜαΥπ ß ≤Ο¥ΓΘ
ΝμΆβΩ…“‘”Ο git branch --no-merged ≤ιΩ¥…–Έ¥Κœ≤ΔΒΡΙΛΉςΘΚ
$ git branch --no-merged
# testing |
ΥϋΜαœ‘ ΨΜΙΈ¥Κœ≤ΔΫχά¥ΒΡΖ÷÷ßΓΘ”…”Ύ’β–©Ζ÷÷ß÷–ΜΙΑϋΚ§Ή≈…–Έ¥Κœ≤ΔΫχά¥ΒΡΙΛΉς≥…ΙϊΘ§Υυ“‘ΦρΒΞΒΊ”Ο git branch -d …Ψ≥ΐΗΟΖ÷÷ßΜαΧα Ψ¥μΈσΘ§“ρΈΣΡ«―υΉωΜαΕΣ ß ΐΨίΘΚ
$ git branch -d testing
# error: The branch 'testing' is not an ancestor of your current HEAD.
# If you are sure you want to delete it, run 'git branch -D testing'. |
≤ΜΙΐΘ§»γΙϊΡψ»Ζ Βœκ“Σ…Ψ≥ΐΗΟΖ÷÷ß…œΒΡΗΡΕ·Θ§Ω…“‘”Ο¥σ–¥ΒΡ…Ψ≥ΐ―Γœν -D «Ω÷Τ÷¥––Θ§ΨΆœώ…œΟφΧα Ψ–≈œΔ÷–Ηχ≥ωΒΡΡ«―υΓΘ
4ΓΔάϊ”ΟΖ÷÷ßΫχ––ΩΣΖΔΒΡΙΛΉςΝς≥Χ
a.≥ΛΤΎΖ÷÷ß
”…”Ύ Git Ι”ΟΦρΒΞΒΡ»ΐΖΫΚœ≤ΔΘ§Υυ“‘ΨΆΥψ‘ΎΫœ≥Λ“ΜΕΈ ±ΦδΡΎΘ§Ζ¥Η¥Εύ¥ΈΑ―Ρ≥ΗωΖ÷÷ßΚœ≤ΔΒΫΝμ“ΜΖ÷÷ßΘ§“≤≤Μ « ≤Ο¥Ρ― ¬ΓΘ“≤ΨΆ «ΥΒΘ§ΡψΩ…“‘Ά§ ±”Β”–ΕύΗωΩΣΖ≈ΒΡΖ÷÷ßΘ§ΟΩΗωΖ÷÷ß”Ο”ΎΆξ≥…ΧΊΕ®ΒΡ»ΈΈώΘ§ΥφΉ≈ΩΣΖΔΒΡΆΤΫχΘ§ΡψΩ…“‘Υφ ±Α―Ρ≥ΗωΧΊ–‘Ζ÷÷ßΒΡ≥…Ιϊ≤ΔΒΫΤδΥϊΖ÷÷ß÷–ΓΘ
–μΕύ Ι”Ο Git ΒΡΩΣΖΔ’ΏΕΦœ≤ΜΕ”Ο’β÷÷ΖΫ Ϋά¥ΩΣ’ΙΙΛΉςΘ§±»»γΫω‘Ύ master Ζ÷÷ß÷–±ΘΝτΆξ»ΪΈ»Ε®ΒΡ¥ζ¬κΘ§Φ¥“―Ψ≠ΖΔ≤ΦΜρΦ¥ΫΪΖΔ≤ΦΒΡ¥ζ¬κΓΘ”κ¥ΥΆ§ ±Θ§ΥϊΟ«ΜΙ”–“ΜΗωΟϊΈΣ develop Μρ next ΒΡΤΫ––Ζ÷÷ßΘ§Ή®Ο≈”Ο”ΎΚσ–χΒΡΩΣΖΔΘ§ΜρΫω”Ο”ΎΈ»Ε®–‘≤β ‘ ΓΣ Β±»Μ≤Δ≤Μ «ΥΒ“ΜΕ®“ΣΨχΕ‘Έ»Ε®Θ§≤ΜΙΐ“ΜΒ©Ϋχ»κΡ≥÷÷Έ»Ε®Ή¥Χ§Θ§±ψΩ…“‘Α―ΥϋΚœ≤ΔΒΫ master άοΓΘ’β―υΘ§‘Ύ»Ζ±Θ’β–©“―Άξ≥…ΒΡΧΊ–‘Ζ÷÷ßΘ®ΕΧΤΎΖ÷÷ßΘ§±»»γ÷°«ΑΒΡ iss53 Ζ÷÷ßΘ©ΡήΙΜΆ®ΙΐΥυ”–≤β ‘Θ§≤Δ«“≤ΜΜα“ΐ»κΗϋΕύ¥μΈσ÷°ΚσΘ§ΨΆΩ…“‘≤ΔΒΫ÷ςΗ…Ζ÷÷ß÷–Θ§Β»¥ΐœ¬“Μ¥ΈΒΡΖΔ≤ΦΓΘ
±Ψ÷ …œΈ“Ο«Η’≤≈ΧΗ¬έΒΡΘ§ «ΥφΉ≈ΧαΫΜΕ‘œσ≤ΜΕœ”““ΤΒΡ÷Η’κΓΘΈ»Ε®Ζ÷÷ßΒΡ÷Η’κΉή «‘ΎΧαΫΜάζ Ζ÷–¬δΚσ“Μ¥σΫΊΘ§Εχ«Α―ΊΖ÷÷ßΉή «±»ΫœΩΩ«ΑΘ®ΦϊΆΦ 2-18Θ©ΓΘ

ΆΦ 2-18. Έ»Ε®Ζ÷÷ßΉή «±»ΫœάœΨ…ΓΘ
Μρ’ΏΑ―ΥϋΟ«œκœσ≥…ΙΛΉςΝςΥ°œΏΘ§Μρ–μΗϋΚΟάμΫβ“Μ–©Θ§Ψ≠Ιΐ≤β ‘ΒΡΧαΫΜΕ‘œσΦ·Κœ±Μεύ―ΓΒΫΗϋΈ»Ε®ΒΡΝςΥ°œΏΘ®ΦϊΆΦ 2-19Θ©ΓΘ
ΆΦ 2-19. œκœσ≥…ΝςΥ°œΏΩ…ΡήΜα»ί“ΉΒψΓΘ
ΡψΩ…“‘”Ο’β’–Έ§ΜΛ≤ΜΆ§≤ψ¥ΈΒΡΈ»Ε®–‘ΓΘΡ≥–©¥σœνΡΩΜΙΜα”–Ηω proposedΘ®Ϋ®“ιΘ©Μρ puΘ®proposed updatesΘ§Ϋ®“ιΗϋ–¬Θ©Ζ÷÷ßΘ§ΥϋΑϋΚ§Ή≈Ρ«–©Ω…ΡήΜΙΟΜ”–≥… λΒΫΫχ»κ next Μρ master ΒΡΡΎ»ίΓΘ’βΟ¥ΉωΒΡΡΩΒΡ «”Β”–≤ΜΆ§≤ψ¥ΈΒΡΈ»Ε®–‘ΘΚΒ±’β–©Ζ÷÷ßΫχ»κΒΫΗϋΈ»Ε®ΒΡΥ°ΤΫ ±Θ§‘ΌΑ―ΥϋΟ«Κœ≤ΔΒΫΗϋΗΏ≤ψΖ÷÷ß÷–»ΞΓΘ‘Ό¥ΈΥΒΟςœ¬Θ§ Ι”ΟΕύΗω≥ΛΤΎΖ÷÷ßΒΡΉωΖ®≤ΔΖ«±Ί–ηΘ§≤ΜΙΐ“ΜΑψά¥ΥΒΘ§Ε‘”ΎΧΊ¥σ–ΆœνΡΩΜρΧΊΗ¥‘”ΒΡœνΡΩΘ§’βΟ¥Ήω»Ζ ΒΗϋ»ί“ΉΙήάμΓΘ
b.ΧΊ–‘Ζ÷÷ß
‘Ύ»ΈΚΈΙφΡΘΒΡœνΡΩ÷–ΕΦΩ…“‘ Ι”ΟΧΊ–‘Θ®TopicΘ©Ζ÷÷ßΓΘ“ΜΗωΧΊ–‘Ζ÷÷ß «÷Η“ΜΗωΕΧΤΎΒΡΘ§”Οά¥ Βœ÷ΒΞ“ΜΧΊ–‘Μρ”κΤδœύΙΊΙΛΉςΒΡΖ÷÷ßΓΘΩ…ΡήΡψ‘Ύ“‘«ΑΒΡΑφ±ΨΩΊ÷ΤœΒΆ≥άο¥”Έ¥ΉωΙΐάύΥΤ’β―υΒΡ ¬«ιΘ§“ρΈΣΆ®≥Θ¥¥Ϋ®”κΚœ≤ΔΖ÷÷ßœϊΚΡΧΪ¥σΓΘ»ΜΕχ‘Ύ Git ÷–Θ§“ΜΧλ÷°ΡΎΫ®ΝΔΓΔ Ι”ΟΓΔΚœ≤Δ‘Ό…Ψ≥ΐΕύΗωΖ÷÷ß «≥ΘΦϊΒΡ ¬ΓΘ
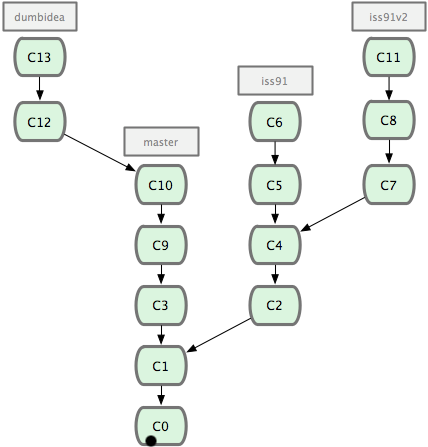
œ÷‘ΎΈ“Ο«ά¥Ω¥“ΜΗω ΒΦ ΒΡάΐΉ”ΓΘ«κΩ¥ΆΦ 2-20Θ§”…œ¬Άυ…œΘ§Τπœ»Έ“Ο«‘Ύ master ΙΛΉςΒΫ C1Θ§»ΜΚσΩΣ Φ“ΜΗω–¬Ζ÷÷ß iss91 ≥Δ ‘–όΗ¥ 91 Κ≈»±œίΘ§ΧαΫΜΒΫ C6 ΒΡ ±ΚρΘ§”÷ΟΑ≥ω“ΜΗωΫβΨωΗΟΈ ΧβΒΡ–¬ΑλΖ®Θ§”Ύ «¥”÷°«Α C4 ΒΡΒΊΖΫ”÷Ζ÷≥ω“ΜΗωΖ÷÷ß iss91v2Θ§Η…ΒΫ C8 ΒΡ ±ΚρΘ§”÷ΜΊΒΫ÷ςΗ… master ÷–ΧαΫΜΝΥ C9 ΚΆ C10Θ§‘ΌΜΊΒΫ iss91v2 ΦΧ–χΙΛΉςΘ§ΧαΫΜ C11Θ§Ϋ”Ή≈Θ§”÷ΟΑ≥ωΗω≤ΜΧΪ»ΖΕ®ΒΡœκΖ®Θ§¥” master ΒΡΉν–¬ΧαΫΜ C10 ¥ΠΩΣΝΥΗω–¬ΒΡΖ÷÷ß dumbidea Ήω–© ‘―ιΓΘ
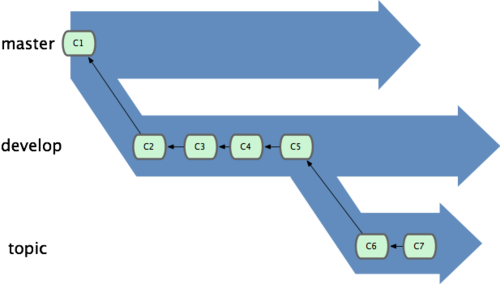
ΆΦ 2-20. ”Β”–ΕύΗωΧΊ–‘Ζ÷÷ßΒΡΧαΫΜάζ ΖΓΘ
œ÷‘ΎΘ§ΦΌΕ®ΝΫΦΰ ¬«ιΘΚΈ“Ο«Ήν÷’ΨωΕ® Ι”ΟΒΎΕΰΗωΫβΨωΖΫΑΗΘ§Φ¥ iss91v2 ÷–ΒΡΑλΖ®ΘΜΝμΆβΘ§Έ“Ο«Α― dumbidea Ζ÷÷ßΡΟΗχΆ§ ¬Ο«Ω¥ΝΥ“‘ΚσΘ§ΖΔœ÷ΥϋΨΙ»Μ «ΗωΧλ≤≈÷°ΉςΓΘΥυ“‘Ϋ”œ¬ά¥Θ§Έ“Ο«ΉΦ±Η≈ΉΤζ‘≠ά¥ΒΡ iss91 Ζ÷÷ßΘ® ΒΦ …œΜαΕΣΤζ C5 ΚΆ C6Θ©Θ§÷±Ϋ”‘Ύ÷ςΗ…÷–≤Δ»κΝμΆβΝΫΗωΖ÷÷ßΓΘΉν÷’ΒΡΧαΫΜάζ ΖΫΪ±δ≥…ΆΦ 2-21 ’β―υΘΚ
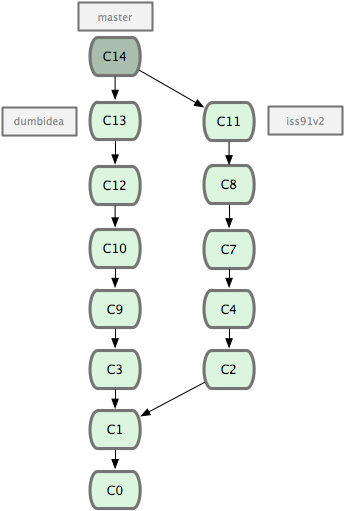
ΆΦ 2-21. Κœ≤ΔΝΥ dumbidea ΚΆ iss91v2 ΚσΒΡΖ÷÷ßάζ ΖΓΘ
«κΈώ±ΊάΈΦ«’β–©Ζ÷÷ß»Ϊ≤ΩΕΦ «±ΨΒΊΖ÷÷ßΘ§’β“ΜΒψΚή÷Ί“ΣΓΘΒ±Ρψ‘Ύ Ι”ΟΖ÷÷ßΦΑΚœ≤ΔΒΡ ±ΚρΘ§“Μ«–ΕΦ «‘ΎΡψΉ‘ΦΚΒΡ Git ≤÷Ωβ÷–Ϋχ––ΒΡ ΓΣ Άξ»Ϊ≤Μ…φΦΑ”κΖΰΈώΤςΒΡΫΜΜΞΓΘ
5ΓΔ‘Ε≥ΧΖ÷÷ß
‘Ε≥ΧΖ÷÷ßΘ®remote branchΘ© «Ε‘‘Ε≥Χ≤÷Ωβ÷–ΒΡΖ÷÷ßΒΡΥς“ΐΓΘΥϋΟ« «“Μ–©ΈόΖ®“ΤΕ·ΒΡ±ΨΒΊΖ÷÷ßΘΜ÷Μ”–‘Ύ Git Ϋχ––Άχ¬γΫΜΜΞ ±≤≈ΜαΗϋ–¬ΓΘ‘Ε≥ΧΖ÷÷ßΨΆœώ « ι«©Θ§Χα–―Ή≈Ρψ…œ¥ΈΝ§Ϋ”‘Ε≥Χ≤÷Ωβ ±…œΟφΗςΖ÷÷ßΒΡΈΜ÷ΟΓΘ
Έ“Ο«”Ο (‘Ε≥Χ≤÷ΩβΟϊ)/(Ζ÷÷ßΟϊ) ’β―υΒΡ–Έ Ϋ±μ Ψ‘Ε≥ΧΖ÷÷ßΓΘ±»»γΈ“Ο«œκΩ¥Ω¥…œ¥ΈΆ§ origin ≤÷ΩβΆ®―Ε ± master Ζ÷÷ßΒΡ―υΉ”Θ§ΨΆ”ΠΗΟ≤ιΩ¥origin/master Ζ÷÷ßΓΘ»γΙϊΡψΚΆΆ§Αι“ΜΤπ–όΗ¥Ρ≥ΗωΈ ΧβΘ§ΒΪΥϊΟ«œ»ΆΤΥΆΝΥ“ΜΗω iss53 Ζ÷÷ßΒΫ‘Ε≥Χ≤÷ΩβΘ§Υδ»ΜΡψΩ…Ρή“≤”–“ΜΗω±ΨΒΊΒΡ iss53 Ζ÷÷ßΘ§ΒΪ÷ΗœρΖΰΈώΤς…œΉν–¬Ηϋ–¬ΒΡ»¥”ΠΗΟ « origin/iss53 Ζ÷÷ßΓΘ
Ω…Ρή”–Βψ¬“Θ§Έ“Ο«≤ΜΖΝΨΌάΐΥΒΟςΓΘΦΌ…ηΡψΟ«Ά≈Ε””–ΗωΒΊ÷ΖΈΣ http://git.ourcompany.com ΒΡ Git ΖΰΈώΤςΓΘ»γΙϊΡψ¥”’βάοΩΥ¬ΓΘ§Git ΜαΉ‘Ε·ΈΣΡψΫΪ¥Υ‘Ε≥Χ≤÷ΩβΟϋΟϊΈΣ originΘ§≤Δœ¬‘ΊΤδ÷–Υυ”–ΒΡ ΐΨίΘ§Ϋ®ΝΔ“ΜΗω÷ΗœρΥϋΒΡ master Ζ÷÷ßΒΡ÷Η’κΘ§‘Ύ±ΨΒΊΟϋΟϊΈΣ origin/masterΘ§ΒΪΡψΈόΖ®‘Ύ±ΨΒΊΗϋΗΡΤδ ΐΨίΓΘΫ”Ή≈Θ§Git Ϋ®ΝΔ“ΜΗω τ”ΎΡψΉ‘ΦΚΒΡ±ΨΒΊ master Ζ÷÷ßΘ§ Φ”Ύ origin …œ master Ζ÷÷ßœύΆ§ΒΡΈΜ÷ΟΘ§ΡψΩ…“‘ΨΆ¥ΥΩΣ ΦΙΛΉςΘ®ΦϊΆΦ 2-22Θ©ΘΚ
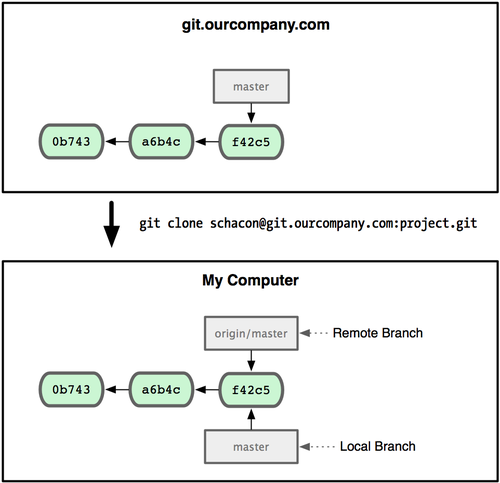
ΆΦ 2-22. “Μ¥Έ Git ΩΥ¬ΓΜαΫ®ΝΔΡψΉ‘ΦΚΒΡ±ΨΒΊΖ÷÷ß master ΚΆ‘Ε≥ΧΖ÷÷ß origin/masterΘ§≤Δ«“ΫΪΥϋΟ«ΕΦ÷Ηœρ origin …œΒΡ master Ζ÷÷ßΓΘ
»γΙϊΡψ‘Ύ±ΨΒΊ master Ζ÷÷ßΉωΝΥ–©ΗΡΕ·Θ§”κ¥ΥΆ§ ±Θ§ΤδΥϊ»Υœρ http://git.ourcompany.com ΆΤΥΆΝΥΥϊΟ«ΒΡΗϋ–¬Θ§Ρ«Ο¥ΖΰΈώΤς…œΒΡ master Ζ÷÷ßΨΆΜαœρ«ΑΆΤΫχΘ§Εχ”Ύ¥ΥΆ§ ±Θ§Ρψ‘Ύ±ΨΒΊΒΡΧαΫΜάζ Ζ’ΐ≥·œρ≤ΜΆ§ΖΫœρΖΔ’ΙΓΘ≤ΜΙΐ÷Μ“ΣΡψ≤ΜΚΆΖΰΈώΤςΆ®―ΕΘ§ΡψΒΡ origin/master ÷Η’κ»‘»Μ±Θ≥÷‘≠ΈΜ≤ΜΜα“ΤΕ·Θ®ΦϊΆΦ 2-23Θ©ΓΘ
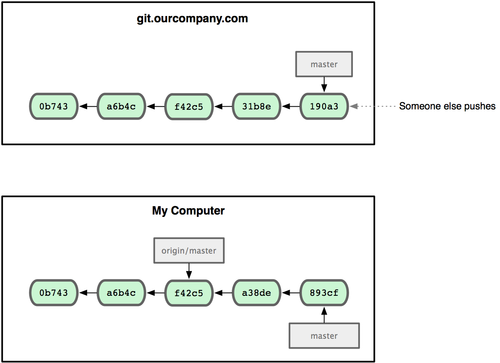
ΆΦ 2-23. ‘Ύ±ΨΒΊΙΛΉςΒΡΆ§ ±”–»Υœρ‘Ε≥Χ≤÷ΩβΆΤΥΆΡΎ»ίΜα»ΟΧαΫΜάζ ΖΩΣ ΦΖ÷ΝςΓΘ
Ω…“‘‘Υ–– git fetch origin ά¥Ά§≤Ϋ‘Ε≥ΧΖΰΈώΤς…œΒΡ ΐΨίΒΫ±ΨΒΊΓΘΗΟΟϋΝν Ήœ»’“ΒΫ origin «ΡΡΗωΖΰΈώΤςΘ§¥”…œΟφΜώ»ΓΡψ…–Έ¥”Β”–ΒΡ ΐΨίΘ§Ηϋ–¬Ρψ±ΨΒΊΒΡ ΐΨίΩβΘ§»ΜΚσΑ― origin/master ΒΡ÷Η’κ“ΤΒΫΥϋΉν–¬ΒΡΈΜ÷Ο…œΘ®ΦϊΆΦ 2-24Θ©
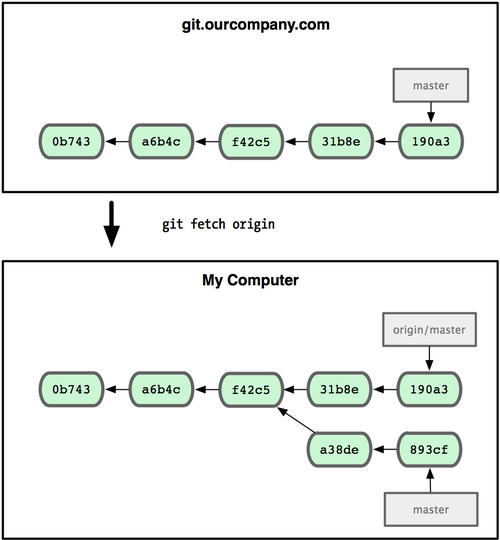
ΆΦ 2-24. git fetch ΟϋΝνΜαΗϋ–¬ remote Υς“ΐΓΘ
ΈΣΝΥ―ί Ψ”Β”–ΕύΗω‘Ε≥ΧΖ÷÷ßΘ®‘Ύ≤ΜΆ§ΒΡ‘Ε≥ΧΖΰΈώΤς…œΘ©ΒΡœνΡΩ «»γΚΈΙΛΉςΒΡΘ§Έ“Ο«ΦΌ…ηΡψΜΙ”–Νμ“ΜΗωΫωΙ©ΡψΒΡΟτΫίΩΣΖΔ–ΓΉι Ι”ΟΒΡΡΎ≤ΩΖΰΈώΤς http://git.team1.ourcompany.comΓΘΩ…“‘”ΟΈ“…œΟφΧαΒΫΒΡ git remote add ΟϋΝνΑ―ΥϋΦ”ΈΣΒ±«ΑœνΡΩΒΡ‘Ε≥ΧΖ÷÷ß÷°“ΜΓΘΈ“Ο«Α―ΥϋΟϋΟϊΈΣ teamoneΘ§“‘±ψ¥ζΧφΆξ’ϊΒΡ Git URL “‘ΖΫ±ψ Ι”ΟΘ®ΦϊΆΦ 2-25Θ©
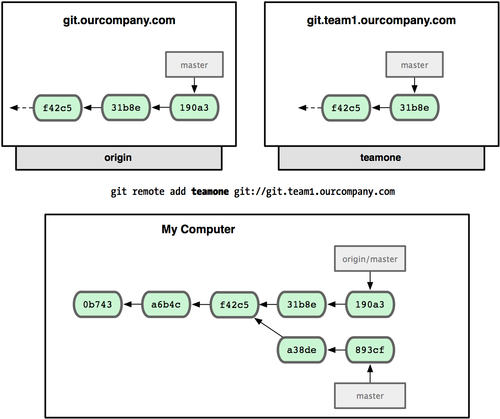
ΆΦ 2-25. Α―Νμ“ΜΗωΖΰΈώΤςΦ”ΈΣ‘Ε≥Χ≤÷Ωβ
œ÷‘ΎΡψΩ…“‘”Ο git fetch teamone ά¥Μώ»Γ–ΓΉιΖΰΈώΤς…œΡψΜΙΟΜ”–ΒΡ ΐΨίΝΥΓΘ”…”ΎΒ±«ΑΗΟΖΰΈώΤς…œΒΡΡΎ»ί «Ρψ origin ΖΰΈώΤς…œΒΡΉ”Φ·Θ§Git ≤ΜΜαœ¬‘Ί»ΈΚΈ ΐΨίΘ§Εχ÷Μ «ΦρΒΞΒΊ¥¥Ϋ®“ΜΗωΟϊΈΣ teamone/master ΒΡ‘Ε≥ΧΖ÷÷ßΘ§÷Ηœρ teamone ΖΰΈώΤς…œ master Ζ÷÷ßΥυ‘ΎΒΡΧαΫΜΕ‘œσ31b8eΘ®ΦϊΆΦ 2-26Θ©ΓΘ
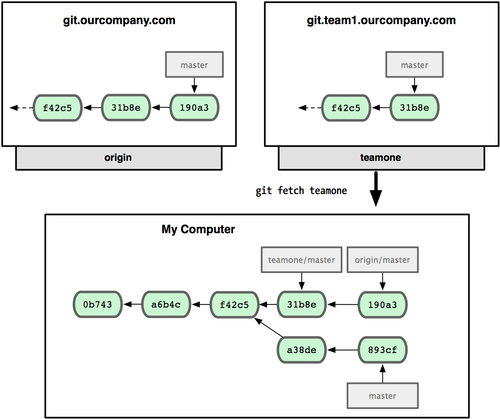
ΆΦ 2-26. Ρψ‘Ύ±ΨΒΊ”–ΝΥ“ΜΗω÷Ηœρ teamone ΖΰΈώΤς…œ master Ζ÷÷ßΒΡΥς“ΐΓΘ
6ΓΔΆΤΥΆ±ΨΒΊΖ÷÷ß
“ΣœκΚΆΤδΥϊ»ΥΖ÷œμΡ≥Ηω±ΨΒΊΖ÷÷ßΘ§Ρψ–η“ΣΑ―ΥϋΆΤΥΆΒΫ“ΜΗωΡψ”Β”––¥»®œόΒΡ‘Ε≥Χ≤÷ΩβΓΘΡψ¥¥Ϋ®ΒΡ±ΨΒΊΖ÷÷ß≤ΜΜα“ρΈΣΡψΒΡ–¥»κ≤ΌΉςΕχ±ΜΉ‘Ε·Ά§≤ΫΒΫΡψ“ΐ»κΒΡ‘Ε≥ΧΖΰΈώΤς…œΘ§Ρψ–η“ΣΟς»ΖΒΊ÷¥––ΆΤΥΆΖ÷÷ßΒΡ≤ΌΉςΓΘΜΜΨδΜΑΥΒΘ§Ε‘”ΎΈό“βΖ÷œμΒΡΖ÷÷ßΘ§ΡψΨΓΙή±ΘΝτΈΣΥΫ»ΥΖ÷÷ßΚΟΝΥΘ§Εχ÷ΜΆΤΥΆΡ«–©–≠Ά§ΙΛΉς“Σ”ΟΒΫΒΡΧΊ–‘Ζ÷÷ßΓΘ
»γΙϊΡψ”–ΗωΫ– serverfix ΒΡΖ÷÷ß–η“ΣΚΆΥϊ»Υ“ΜΤπΩΣΖΔΘ§Ω…“‘‘Υ–– git push (‘Ε≥Χ≤÷ΩβΟϊ) (Ζ÷÷ßΟϊ)ΘΚ
$ git push origin serverfix
# Counting objects: 20, done.
# Compressing objects: 100% (14/14), done.
# Writing objects: 100% (15/15), 1.74 KiB, done.
# Total 15 (delta 5), reused 0 (delta 0)
# To git@github.com:schacon/simplegit.git
# * [new branch] serverfix -> serverfix |
’βάοGit ΜαΉ‘Ε·Α― serverfix Ζ÷÷ßΟϊά©’ΙΈΣ refs/heads/serverfix:refs/heads/serverfixΘ§“βΈΣΓΑ»Γ≥ωΈ“‘Ύ±ΨΒΊΒΡ serverfix Ζ÷÷ßΘ§ΆΤΥΆΒΫ‘Ε≥Χ≤÷ΩβΒΡ serverfix Ζ÷÷ß÷–»ΞΓ±ΓΘ“≤Ω…“‘‘Υ–– git push origin serverfix:serverfix ά¥ Βœ÷œύΆ§ΒΡ–ßΙϊΘ§ΥϋΒΡ“βΥΦ «ΓΑ…œ¥ΪΈ“±ΨΒΊΒΡ serverfix Ζ÷÷ßΒΫ‘Ε≥Χ≤÷Ωβ÷–»ΞΘ§»‘Ψ…≥ΤΥϋΈΣ serverfix Ζ÷÷ßΓ±ΓΘΆ®Ιΐ¥Υ”οΖ®Θ§ΡψΩ…“‘Α―±ΨΒΊΖ÷÷ßΆΤΥΆΒΫΡ≥ΗωΟϋΟϊ≤ΜΆ§ΒΡ‘Ε≥ΧΖ÷÷ßΘΚ»τœκΑ―‘Ε≥ΧΖ÷÷ßΫ–Ής awesomebranchΘ§Ω…“‘”Ο git push origin serverfix:awesomebranch ά¥ΆΤΥΆ ΐΨίΓΘ
Ϋ”œ¬ά¥Θ§Β±ΡψΒΡ–≠Ής’Ώ‘Ό¥Έ¥”ΖΰΈώΤς…œΜώ»Γ ΐΨί ±Θ§ΥϊΟ«ΫΪΒΟΒΫ“ΜΗω–¬ΒΡ‘Ε≥ΧΖ÷÷ß origin/serverfixΘ§≤Δ÷ΗœρΖΰΈώΤς…œ serverfix Υυ÷ΗœρΒΡΑφ±ΨΘΚ
$ git fetch origin
# remote: Counting objects: 20, done.
# remote: Compressing objects: 100% (14/14), done.
# remote: Total 15 (delta 5), reused 0 (delta 0)
# Unpacking objects: 100% (15/15), done.
# From git@github.com:schacon/simplegit
# * [new branch] serverfix -> origin/serverfix |
÷ΒΒΟΉΔ“βΒΡ «Θ§‘Ύ fetch ≤ΌΉςœ¬‘ΊΚΟ–¬ΒΡ‘Ε≥ΧΖ÷÷ß÷°ΚσΘ§Ρψ»‘»ΜΈόΖ®‘Ύ±ΨΒΊ±ύΦ≠ΗΟ‘Ε≥Χ≤÷Ωβ÷–ΒΡΖ÷÷ßΓΘΜΜΨδΜΑΥΒΘ§‘Ύ±Ψάΐ÷–Θ§Ρψ≤ΜΜα”–“ΜΗω–¬ΒΡ serverfix Ζ÷÷ßΘ§”–ΒΡ÷Μ «“ΜΗωΡψΈόΖ®“ΤΕ·ΒΡ origin/serverfix ÷Η’κΓΘ
»γΙϊ“ΣΑ―ΗΟ‘Ε≥ΧΖ÷÷ßΒΡΡΎ»ίΚœ≤ΔΒΫΒ±«ΑΖ÷÷ßΘ§Ω…“‘‘Υ–– git merge origin/serverfixΓΘ»γΙϊœκ“Σ“ΜΖίΉ‘ΦΚΒΡ serverfix ά¥ΩΣΖΔΘ§Ω…“‘‘Ύ‘Ε≥ΧΖ÷÷ßΒΡΜυ¥Γ…œΖ÷Μ·≥ω“ΜΗω–¬ΒΡΖ÷÷ßά¥ΘΚ
$ git checkout -b serverfix origin/serverfix
# Branch serverfix set up to track remote branch refs/remotes/origin/serverfix.
# Switched to a new branch "serverfix" |
’βΜα«–ΜΜΒΫ–¬Ϋ®ΒΡ serverfix ±ΨΒΊΖ÷÷ßΘ§ΤδΡΎ»ίΆ§‘Ε≥ΧΖ÷÷ß origin/serverfix “Μ÷¬Θ§’β―υΡψΨΆΩ…“‘‘ΎάοΟφΦΧ–χΩΣΖΔΝΥΓΘ
7ΓΔΗζΉΌ‘Ε≥ΧΖ÷÷ß
¥”‘Ε≥ΧΖ÷÷ß checkout ≥ωά¥ΒΡ±ΨΒΊΖ÷÷ßΘ§≥ΤΈΣ ΗζΉΌΖ÷÷ß (tracking branch)ΓΘΗζΉΌΖ÷÷ß «“Μ÷÷ΚΆΡ≥Ηω‘Ε≥ΧΖ÷÷ß”–÷±Ϋ”ΝΣœΒΒΡ±ΨΒΊΖ÷÷ßΓΘ‘ΎΗζΉΌΖ÷÷ßάο δ»κ git pushΘ§Git ΜαΉ‘––ΆΤΕœ”ΠΗΟœρΡΡΗωΖΰΈώΤςΒΡΡΡΗωΖ÷÷ßΆΤΥΆ ΐΨίΓΘΆ§―υΘ§‘Ύ’β–©Ζ÷÷ßάο‘Υ–– git pull ΜαΜώ»ΓΥυ”–‘Ε≥ΧΥς“ΐΘ§≤ΔΑ―ΥϋΟ«ΒΡ ΐΨίΕΦΚœ≤ΔΒΫ±ΨΒΊΖ÷÷ß÷–ά¥ΓΘ
‘ΎΩΥ¬Γ≤÷Ωβ ±Θ§Git Ά®≥ΘΜαΉ‘Ε·¥¥Ϋ®“ΜΗωΟϊΈΣ master ΒΡΖ÷÷ßά¥ΗζΉΌ origin/masterΓΘ’β’ΐ « git push ΚΆ git pull “ΜΩΣ ΦΨΆΡή’ΐ≥ΘΙΛΉςΒΡ‘≠“ρΓΘΒ±»ΜΘ§ΡψΩ…“‘Υφ–ΡΥυ”ϊΒΊ…ηΕ®ΈΣΤδΥϋΗζΉΌΖ÷÷ßΘ§±»»γ origin …œ≥ΐΝΥ master ÷°ΆβΒΡΤδΥϋΖ÷÷ßΓΘΗ’≤≈Έ“Ο«“―Ψ≠Ω¥ΒΫΝΥ’β―υΒΡ“ΜΗωάΐΉ”ΘΚgit checkout -b [Ζ÷÷ßΟϊ] [‘Ε≥ΧΟϊ]/[Ζ÷÷ßΟϊ]ΓΘ»γΙϊΡψ”– 1.6.2 “‘…œΑφ±ΨΒΡ GitΘ§ΜΙΩ…“‘”Ο --track ―ΓœνΦρΜ·ΘΚ
$ git checkout --track origin/serverfix
# Branch serverfix set up to track remote branch refs/remotes/origin/serverfix.
# Switched to a new branch "serverfix" |
“ΣΈΣ±ΨΒΊΖ÷÷ß…ηΕ®≤ΜΆ§”Ύ‘Ε≥ΧΖ÷÷ßΒΡΟϊΉ÷Θ§÷Μ–η‘ΎΒΎ“ΜΗωΑφ±ΨΒΡΟϋΝνάοΜΜΗωΟϊΉ÷ΘΚ
$ git checkout -b sf origin/serverfix
# Branch sf set up to track remote branch refs/remotes/origin/serverfix.
# Switched to a new branch "sf" |
œ÷‘ΎΡψΒΡ±ΨΒΊΖ÷÷ß sf ΜαΉ‘Ε·ΫΪΆΤΥΆΚΆΉΞ»Γ ΐΨίΒΡΈΜ÷ΟΕ®ΈΜΒΫ origin/serverfix ΝΥΓΘ
8ΓΔ…Ψ≥ΐ‘Ε≥ΧΖ÷÷ß
»γΙϊ≤Μ‘Ό–η“ΣΡ≥Ηω‘Ε≥ΧΖ÷÷ßΝΥΘ§±»»γΗψΕ®ΝΥΡ≥ΗωΧΊ–‘≤ΔΑ―ΥϋΚœ≤ΔΫχΝΥ‘Ε≥ΧΒΡ master Ζ÷÷ßΘ®Μρ»ΈΚΈΤδΥϊ¥φΖ≈Έ»Ε®¥ζ¬κΒΡΖ÷÷ßΘ©Θ§Ω…“‘”Ο’βΗωΖ«≥ΘΈόάεΆΖΒΡ”οΖ®ά¥…Ψ≥ΐΥϋΘΚgit push [‘Ε≥ΧΟϊ] :[Ζ÷÷ßΟϊ]ΓΘ»γΙϊœκ‘ΎΖΰΈώΤς…œ…Ψ≥ΐ serverfix Ζ÷÷ßΘ§‘Υ––œ¬ΟφΒΡΟϋΝνΘΚ
$ git push origin :serverfix
# To git@github.com:schacon/simplegit.git
# - [deleted] serverfix |
ΏΥΘΓΖΰΈώΤς…œΒΡΖ÷÷ßΟΜΝΥΓΘΡψΉνΚΟΧΊ±πΝτ–Ρ’β“Μ“≥Θ§“ρΈΣΡψ“ΜΕ®Μα”ΟΒΫΡ«ΗωΟϋΝνΘ§Εχ«“ΡψΚήΩ…ΡήΜαΆϋΒτΥϋΒΡ”οΖ®ΓΘ”–÷÷ΖΫ±ψΦ«“δ’βΧθΟϋΝνΒΡΖΫΖ®ΘΚΦ«ΉΓΈ“Ο«≤ΜΨΟ«ΑΦϊΙΐΒΡ git push [‘Ε≥ΧΟϊ] [±ΨΒΊΖ÷÷ß]:[‘Ε≥ΧΖ÷÷ß] ”οΖ®Θ§»γΙϊ Γ¬‘ [±ΨΒΊΖ÷÷ß]Θ§Ρ«ΨΆΒ»”Ύ «‘ΎΥΒΓΑ‘Ύ’βάοΧα»ΓΩ’ΑΉ»ΜΚσΑ―Υϋ±δ≥…[‘Ε≥ΧΖ÷÷ß]Γ±ΓΘ
9ΓΔΖ÷÷ßΒΡ―ήΚœ
Α―“ΜΗωΖ÷÷ß÷–ΒΡ–όΗΡ’ϊΚœΒΫΝμ“ΜΗωΖ÷÷ßΒΡΑλΖ®”–ΝΫ÷÷ΘΚmerge ΚΆ rebaseΓΘ
a.Μυ±ΨΒΡ―ήΚœ≤ΌΉς
«κΜΊΙΥΈ“…œΟφΫ≤ΒΫΒΡΚœ≤ΔΘ®ΦϊΆΦ 2-27Θ©Θ§ΡψΜαΩ¥ΒΫΩΣΖΔΫχ≥ΧΖ÷≤φΒΫΝΫΗω≤ΜΆ§Ζ÷÷ßΘ§”÷ΗςΉ‘ΧαΫΜΝΥΗϋ–¬ΓΘ
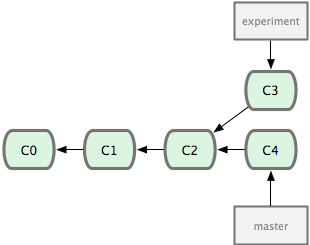
ΆΦ 2-27. Ήν≥θΖ÷≤φΒΡΧαΫΜάζ ΖΓΘ
«ΑΟφΫι…ήΙΐΘ§Ήν»ί“ΉΒΡ’ϊΚœΖ÷÷ßΒΡΖΫΖ® « merge ΟϋΝνΘ§ΥϋΜαΑ―ΝΫΗωΖ÷÷ßΉν–¬ΒΡΩλ’’Θ®C3 ΚΆ C4Θ©“‘ΦΑΕΰ’ΏΉν–¬ΒΡΙ≤Ά§Ήφœ»Θ®C2Θ©Ϋχ––»ΐΖΫΚœ≤ΔΘ§Κœ≤ΔΒΡΫαΙϊ «≤ζ…ζ“ΜΗω–¬ΒΡΧαΫΜΕ‘œσΘ®C5Θ©ΓΘ»γΆΦ 2-28 Υυ ΨΘΚ
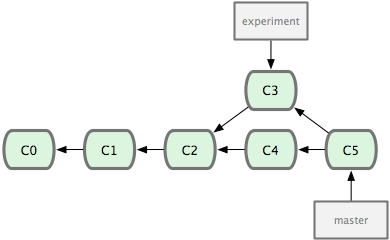
ΆΦ 2-28. Ά®ΙΐΚœ≤Δ“ΜΗωΖ÷÷ßά¥’ϊΚœΖ÷≤φΝΥΒΡάζ ΖΓΘ
Τδ ΒΘ§ΜΙ”–ΝμΆβ“ΜΗω―Γ‘ώΘΚΡψΩ…“‘Α―‘Ύ C3 άο≤ζ…ζΒΡ±δΜ·≤ΙΕΓ‘Ύ C4 ΒΡΜυ¥Γ…œ÷Ί–¬¥ρ“Μ±ιΓΘ‘Ύ Git άοΘ§’β÷÷≤ΌΉςΫ–Ήω―ήΚœΘ®rebaseΘ©ΓΘ”–ΝΥ rebase ΟϋΝνΘ§ΨΆΩ…“‘Α―‘Ύ“ΜΗωΖ÷÷ßάοΧαΫΜΒΡΗΡ±δ“ΤΒΫΝμ“ΜΗωΖ÷÷ßάο÷ΊΖ≈“Μ±ιΓΘ
‘Ύ…œΟφ’βΗωάΐΉ”÷–Θ§‘Υ––ΘΚ
$ git checkout experiment
# $ git rebase master
# First, rewinding head to replay your work on top of it...
# Applying: added staged command |
ΥϋΒΡ‘≠άμ «ΜΊΒΫΝΫΗωΖ÷÷ßΉνΫϋΒΡΙ≤Ά§Ήφœ»Θ§ΗυΨίΒ±«ΑΖ÷÷ßΘ®“≤ΨΆ «“ΣΫχ––―ήΚœΒΡΖ÷÷ß experimentΘ©Κσ–χΒΡάζ¥ΈΧαΫΜΕ‘œσΘ®’βάο÷Μ”–“ΜΗω C3Θ©Θ§…ζ≥…“ΜœΒΝ–ΈΡΦΰ≤ΙΕΓΘ§»ΜΚσ“‘ΜυΒΉΖ÷÷ßΘ®“≤ΨΆ «÷ςΗ…Ζ÷÷ß masterΘ©ΉνΚσ“ΜΗωΧαΫΜΕ‘œσΘ®C4Θ©ΈΣ–¬ΒΡ≥ωΖΔΒψΘ§÷πΗω”Π”Ο÷°«ΑΉΦ±ΗΚΟΒΡ≤ΙΕΓΈΡΦΰΘ§ΉνΚσΜα…ζ≥…“ΜΗω–¬ΒΡΚœ≤ΔΧαΫΜΕ‘œσΘ®C3'Θ©Θ§¥”ΕχΗΡ–¥ experiment ΒΡΧαΫΜάζ ΖΘ§ ΙΥϋ≥…ΈΣ master Ζ÷÷ßΒΡ÷±Ϋ”œ¬”ΈΘ§»γΆΦ 2-29 Υυ ΨΘΚ
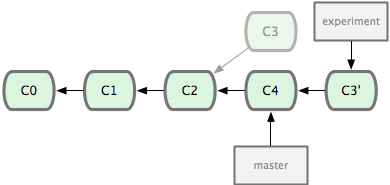
ΆΦ 2-29. Α― C3 άο≤ζ…ζΒΡΗΡ±δΒΫ C4 …œ÷Ί―ί“Μ±ιΓΘ
œ÷‘ΎΜΊΒΫ master Ζ÷÷ßΘ§Ϋχ––“Μ¥ΈΩλΫχΚœ≤ΔΘ®ΦϊΆΦ 2-30Θ©ΘΚ
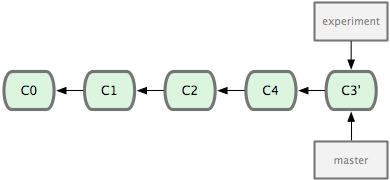
ΆΦ 2-30. master Ζ÷÷ßΒΡΩλΫχΓΘ
œ÷‘ΎΒΡ C3' Ε‘”ΠΒΡΩλ’’Θ§Τδ ΒΚΆΤ’Ά®ΒΡ»ΐΖΫΚœ≤ΔΘ§Φ¥…œΗωάΐΉ”÷–ΒΡ C5 Ε‘”ΠΒΡΩλ’’ΡΎ»ί“ΜΡΘ“Μ―υΝΥΓΘΥδ»ΜΉνΚσ’ϊΚœΒΟΒΫΒΡΫαΙϊΟΜ”–»ΈΚΈ«χ±πΘ§ΒΪ―ήΚœΡή≤ζ…ζ“ΜΗωΗϋΈΣ’ϊΫύΒΡΧαΫΜάζ ΖΓΘ»γΙϊ ”≤λ“ΜΗω―ήΚœΙΐΒΡΖ÷÷ßΒΡάζ ΖΦ«¬ΦΘ§Ω¥Τπά¥ΜαΗϋ«ε≥ΰΘΚΖ¬ΖπΥυ”––όΗΡΕΦ «‘Ύ“ΜΗυœΏ…œœ»ΚσΫχ––ΒΡΘ§ΨΓΙή ΒΦ …œΥϋΟ«‘≠±Ψ «Ά§ ±≤Δ––ΖΔ…ζΒΡΓΘ
“ΜΑψΈ“Ο« Ι”Ο―ήΚœΒΡΡΩΒΡΘ§ «œκ“ΣΒΟΒΫ“ΜΗωΡή‘Ύ‘Ε≥ΧΖ÷÷ß…œΗ…ΨΜ”Π”ΟΒΡ≤ΙΕΓ ΓΣ ±»»γΡ≥–©œνΡΩΡψ≤Μ «Έ§ΜΛ’ΏΘ§ΒΪœκΑοΒψΟΠΒΡΜΑΘ§ΉνΚϔϯήΚœΘΚœ»‘ΎΉ‘ΦΚΒΡ“ΜΗωΖ÷÷ßάοΫχ––ΩΣΖΔΘ§Β±ΉΦ±Ηœρ÷ςœνΡΩΧαΫΜ≤ΙΕΓΒΡ ±ΚρΘ§ΗυΨίΉν–¬ΒΡ origin/master Ϋχ––“Μ¥Έ―ήΚœ≤ΌΉς»ΜΚσ‘ΌΧαΫΜΘ§’β―υΈ§ΜΛ’ΏΨΆ≤Μ–η“ΣΉω»ΈΚΈ’ϊΚœΙΛΉςΘ® ΒΦ …œ «Α―ΫβΨωΖ÷÷ß≤ΙΕΓΆ§Ήν–¬÷ςΗ…¥ζ¬κ÷°Φδ≥εΆΜΒΡ‘π»ΈΘ§Μ·ΉΣΈΣ”…ΧαΫΜ≤ΙΕΓΒΡ»Υά¥ΫβΨωΘ©Θ§÷Μ–ηΗυΨίΡψΧαΙ©ΒΡ≤÷ΩβΒΊ÷ΖΉς“Μ¥ΈΩλΫχΚœ≤ΔΘ§Μρ’Ώ÷±Ϋ”≤…Ρ…ΡψΧαΫΜΒΡ≤ΙΕΓΓΘ
«κΉΔ“βΘ§Κœ≤ΔΫαΙϊ÷–ΉνΚσ“Μ¥ΈΧαΫΜΥυ÷ΗœρΒΡΩλ’’Θ§Έό¬έ «Ά®Ιΐ―ήΚœΘ§ΜΙ «»ΐΖΫΚœ≤ΔΘ§ΕΦΜαΒΟΒΫœύΆ§ΒΡΩλ’’ΡΎ»ίΘ§÷Μ≤ΜΙΐΧαΫΜάζ Ζ≤ΜΆ§Α’ΝΥΓΘ―ήΚœ «Α¥’’ΟΩ––ΒΡ–όΗΡ¥Έ–ρ÷Ί―ί“Μ±ι–όΗΡΘ§ΕχΚœ≤Δ «Α―Ήν÷’ΫαΙϊΚœ‘Ύ“ΜΤπΓΘ
b.”–»ΛΒΡ―ήΚœ
―ήΚœ“≤Ω…“‘Ζ≈ΒΫΤδΥϊΖ÷÷ßΫχ––Θ§≤Δ≤Μ“ΜΕ®Ζ«ΒΟΗυΨίΖ÷Μ·÷°«ΑΒΡΖ÷÷ßΓΘ“‘ΆΦ 2-31 ΒΡάζ ΖΈΣάΐΘ§Έ“Ο«ΈΣΝΥΗχΖΰΈώΤςΕΥ¥ζ¬κΧμΦ”“Μ–©ΙΠΡήΕχ¥¥Ϋ®ΝΥΧΊ–‘Ζ÷÷ß serverΘ§»ΜΚσΧαΫΜ C3 ΚΆ C4ΓΘ»ΜΚσ”÷¥” C3 ΒΡΒΊΖΫ‘Ό‘ωΦ”“ΜΗω client Ζ÷÷ßά¥Ε‘ΩΆΜßΕΥ¥ζ¬κΫχ––“Μ–©œύ”Π–όΗΡΘ§Υυ“‘ΧαΫΜΝΥ C8 ΚΆ C9ΓΘΉνΚσΘ§”÷ΜΊΒΫ server Ζ÷÷ßΧαΫΜΝΥ C10ΓΘ
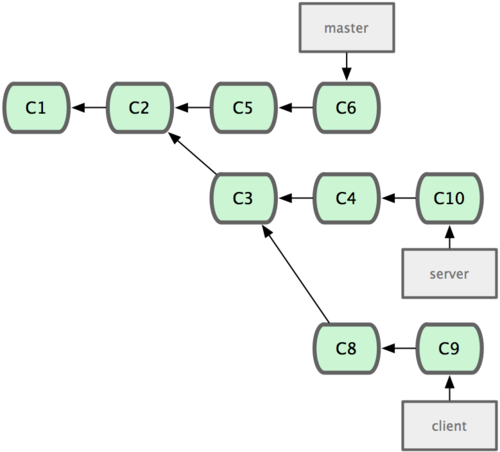
ΆΦ 2-31. ¥”“ΜΗωΧΊ–‘Ζ÷÷ßάο‘ΌΖ÷≥ω“ΜΗωΧΊ–‘Ζ÷÷ßΒΡάζ ΖΓΘ
ΦΌ…η‘ΎΫ”œ¬ά¥ΒΡ“Μ¥Έ»μΦΰΖΔ≤Φ÷–Θ§Έ“Ο«ΨωΕ®œ»Α―ΩΆΜßΕΥΒΡ–όΗΡ≤ΔΒΫ÷ςœΏ÷–Θ§Εχ‘ίΜΚ≤Δ»κΖΰΈώΕΥ»μΦΰΒΡ–όΗΡΘ®“ρΈΣΜΙ–η“ΣΫχ“Μ≤Ϋ≤β ‘Θ©ΓΘ’βΗω ±ΚρΘ§Έ“Ο«ΨΆΩ…“‘Α―Μυ”Ύ server Ζ÷÷ßΕχΖ« master Ζ÷÷ßΒΡΗΡ±δΘ®Φ¥ C8 ΚΆ C9Θ©Θ§ΧχΙΐ server ÷±Ϋ”Ζ≈ΒΫ master Ζ÷÷ß÷–÷Ί―ί“Μ±ιΘ§ΒΪ’β–η“Σ”Ο git rebase ΒΡ --onto ―Γœν÷ΗΕ®–¬ΒΡΜυΒΉΖ÷÷ß masterΘΚ
| $ git rebase --onto master server client |
’βΚΟ±»‘ΎΥΒΘΚΓΑ»Γ≥ω client Ζ÷÷ßΘ§’“≥ω client Ζ÷÷ßΚΆ server Ζ÷÷ßΒΡΙ≤Ά§Ήφœ»÷°ΚσΒΡ±δΜ·Θ§»ΜΚσΑ―ΥϋΟ«‘Ύ master …œ÷Ί―ί“Μ±ιΓ±ΓΘΥϋΒΡΫαΙϊ»γΆΦ 2-32 Υυ ΨΘ®“κΉΔΘΚΥδ»Μ client άοΒΡ C8, C9 ‘Ύ C3 ÷°ΚσΘ§ΒΪ’βΫω±μΟς ±Φδ…œΒΡœ»ΚσΘ§ΕχΖ«‘Ύ C3 –όΗΡΒΡΜυ¥Γ…œΫχ“Μ≤ΫΗΡΕ·Θ§“ρΈΣ server ΚΆ client ’βΝΫΗωΖ÷÷ßΕ‘”ΠΒΡ¥ζ¬κ”ΠΗΟ «ΝΫΧΉΈΡΦΰΘ§Υδ»Μ’βΟ¥ΥΒ≤Μ «Κή―œΗώΘ§ΒΪ”ΠάμΫβΈΣ‘Ύ C3 ±ΦδΒψ÷°ΚσΘ§Ε‘ΝμΆβΒΡΈΡΦΰΥυΉωΒΡ C8Θ§C9 –όΗΡΘ§Ζ≈ΒΫ÷ςΗ…÷Ί―ίΓΘΘ©ΘΚ
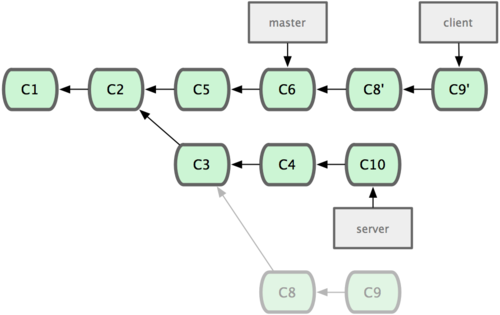
ΆΦ 2-32. ΫΪΧΊ–‘Ζ÷÷ß…œΒΡΝμ“ΜΗωΧΊ–‘Ζ÷÷ß―ήΚœΒΫΤδΥϊΖ÷÷ßΓΘ
œ÷‘ΎΩ…“‘ΩλΫχ master Ζ÷÷ßΝΥΘ®ΦϊΆΦ 2-33Θ©ΘΚ
# step 1
$ git checkout master
# step 2
$ git merge client |
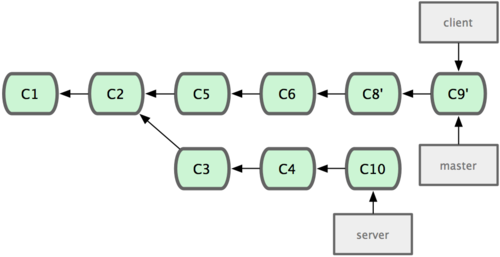
ΆΦ 2-33. ΩλΫχ master Ζ÷÷ßΘ§ Ι÷°ΑϋΚ§ client Ζ÷÷ßΒΡ±δΜ·ΓΘ
œ÷‘ΎΈ“Ο«ΨωΕ®Α― server Ζ÷÷ßΒΡ±δΜ·“≤ΑϋΚ§Ϋχά¥ΓΘΈ“Ο«Ω…“‘÷±Ϋ”Α― server Ζ÷÷ß―ήΚœΒΫ masterΘ§Εχ≤Μ”Ο ÷ΙΛ«–ΜΜΒΫ server Ζ÷÷ßΚσ‘Ό÷¥––―ήΚœ≤ΌΉς ΓΣ git rebase [÷ςΖ÷÷ß] [ΧΊ–‘Ζ÷÷ß] ΟϋΝνΜαœ»»Γ≥ωΧΊ–‘Ζ÷÷ß serverΘ§»ΜΚσ‘Ύ÷ςΖ÷÷ß master …œ÷Ί―ίΘΚ
| $ git rebase master server |
”Ύ «Θ§server ΒΡΫχΕ»”Π”ΟΒΫ master ΒΡΜυ¥Γ…œΘ§»γΆΦ 2-34 Υυ ΨΘΚ
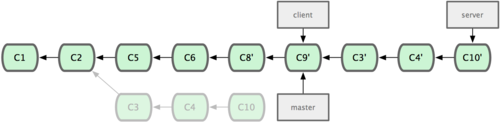
ΆΦ 2-34. ‘Ύ master Ζ÷÷ß…œ―ήΚœ server Ζ÷÷ßΓΘ
»ΜΚσΨΆΩ…“‘ΩλΫχ÷ςΗ…Ζ÷÷ß master ΝΥΘΚ
# step 1
$ git checkout master
# step 2
$ git merge server |
œ÷‘Ύ client ΚΆ server Ζ÷÷ßΒΡ±δΜ·ΕΦ“―Ψ≠Φ·≥…ΒΫ÷ςΗ…Ζ÷÷ßά¥ΝΥΘ§Ω…“‘…ΨΒτΥϋΟ«ΝΥΓΘΉν÷’Έ“Ο«ΒΡΧαΫΜάζ ΖΜα±δ≥…ΆΦ 2-35 ΒΡ―υΉ”ΘΚ
# step 1
$ git branch -d client
# step 2
$ git branch -d server |

ΆΦ 2-35. Ήν÷’ΒΡΧαΫΜάζ Ζ
’βάο–η“Σ«ΩΒς“ΜΒψΒΡ «Θ§ Ι”Ο―ήΚœΒΡ ±Κρ±Ί–κΉώ Ί“ΜΧθΉΦ‘ρΘΚ
“ΜΒ©Ζ÷÷ß÷–ΒΡΧαΫΜΕ‘œσΖΔ≤ΦΒΫΙΪΙ≤≤÷ΩβΘ§ΨΆ«ßΆρ≤Μ“ΣΕ‘ΗΟΖ÷÷ßΫχ––―ήΚœ≤ΌΉςΓΘ
»ΐΓΔ–ΓΫα
ΕΝΒΫ’βάοΘ§ Ήœ»Έ“±μ ΨΕ‘ΡψΒΡΡΆ–ΡΗ–ΒΫ‘ό–μΘ§Εχ’βΗω ±ΚρΒΡΡψ”ΠΗΟ“―Ψ≠―ßΜαΝΥ»γΚΈ¥¥Ϋ®Ζ÷÷ß≤Δ«–ΜΜΒΫ–¬Ζ÷÷ßΘ§‘Ύ≤ΜΆ§Ζ÷÷ßΦδΉΣΜΜΘ§Κœ≤Δ±ΨΒΊΖ÷÷ßΘ§Α―Ζ÷÷ßΆΤΥΆΒΫΙ≤œμΖΰΈώΤς…œΘ§ Ι”ΟΙ≤œμΖ÷÷ß”κΥϊ»Υ–≠ΉςΘ§“‘ΦΑ‘ΎΖ÷œμ÷°«ΑΫχ––―ήΚœΓΘ |









