1. Git 的玩法
欢迎来到 Coding 技术小馆,我叫谭贺贺,目前我在 Coding.net 主要负责 WebIDE 与 Codeinsight 的开发。我今天带来的主要内容是 Git 的原理与使用。
谈起 git,大家的第一印象无非是和 svn 一样的版本控制系统,但其实,他们有着非常大的不同,至少 svn 没有像 git 一样这么多的玩法。下面我举几个例子,简略的说一下。
1.1 搭建博客
阮一峰将写 blog 的人分成三个阶段
使用免费空间,比如 CSDN、博客园。
发现免费空间限制太多,于是自己购买域名和空间,搭建独立博客。
独立博客管理太麻烦,最好在保留控制权的前提下,让别人来管,自己负责写文章。
其实第三种阶段指的就是使用 Pages 服务。很多公司比如 Coding、Github 等代码托管平台都推出了 Pages 服务,可以用来搭建个人博客。Pages 服务不需要复杂的配置,就可以完成博客的搭建。
在使用 Pages 的过程中,通过使用标记语言(Markdown)完成博客的编写,推送到服务器上,就可以看到新发布的博客了。
不需要管理服务器,降低了搭建博客的门槛,同时又保持了用户对博客的高度定制权。
1.2 写书
很多牛人喜欢写博客,博客写多了,然后汇集起来就出了本书。比如 Matrix67《思考的乐趣》、阮一峰《如何变得有思想》就是这样的例子。
其实出书距离我们也并不遥远,为什么?因为有 gitbook 这类服务。
对于 git + Pages 服务的用户,gitbook 很容易上手,因为使用 gitbook 就是使用 git 与 markdown。
你完全可以将你 markdown 的博客 copy,汇集起来,形成一本书籍。内容的排版 gitbook 会帮你做,我们只负责内容就可以了。编写好内容,我们就能立刻获得 html、pdf、epub、mobi 四个版本的电子书。这是 html 版的预览:

在 gitbook 上有 explore 频道,上面列出了所有公开的书籍(当然也可以直接搜索)。

实际上,除了写书,还可以连同其他人一起进行外文资料的翻译,举个例子《The Swift Programming Language》中文版,将英文版分成几个部分,然后在开源项目中由参与者认领翻译,每个人贡献一份自己的力量,完成了这样以非常快的相应速度跟随官方文档更新的操作。如果你喜欢的一门语言,或者技术,中文资料缺乏,大家可以发起这样的活动,完成外文资料的翻译。
1.3 人才招聘
人才招聘这一块,至今还并没有形成一定的规模。但仍旧有很多的公司选择在代码托管平台上(比如 Coding、Github)上寻找中意的开发者。
有一些开发者看准了这一块,专门开发了这样的网站,比如 githuber.cn、github-awards.com。
拿 githuber 举例,该网站主要提供两个功能,第一个是星榜,说白了将所有所有用户按照语言分类,然后根据粉丝数(star)排序。
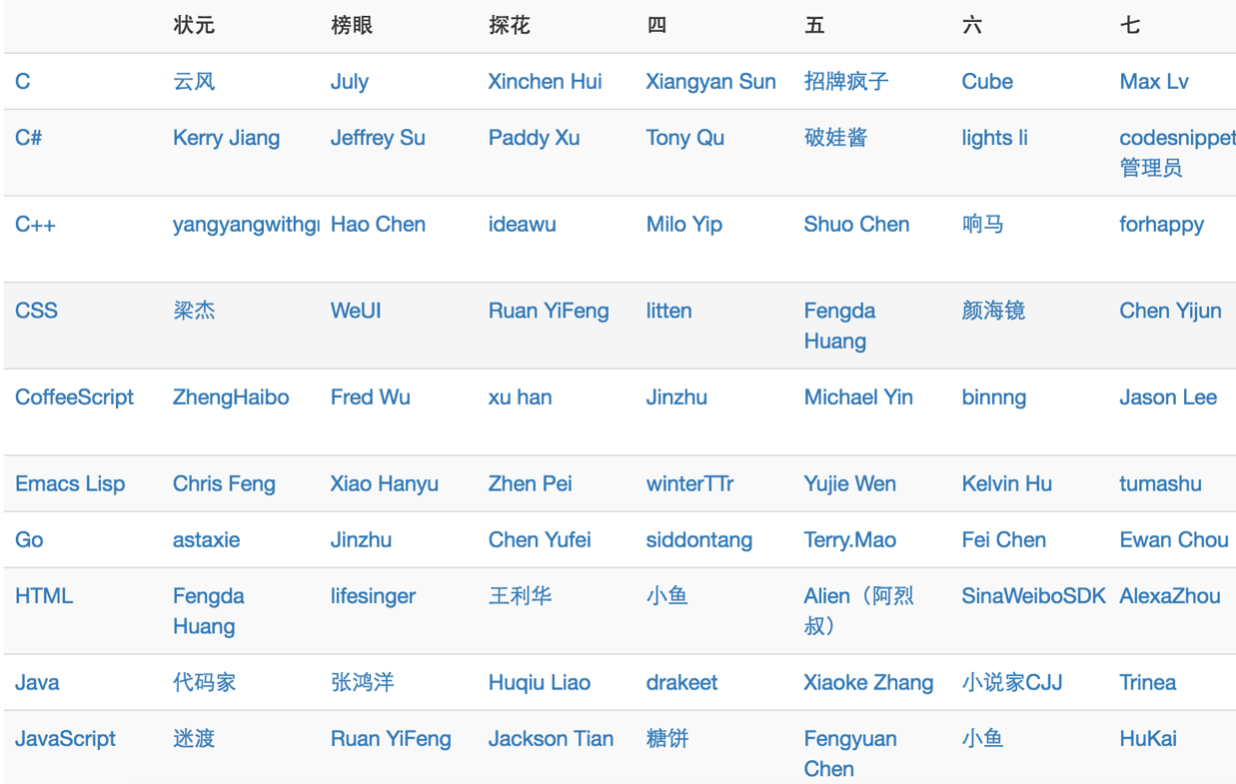
我们可以很容易的看到排行榜上前几位的用户,他们的开源项目,这在一定程度上能代表这门语言的发展趋势。比如我对java比较感兴趣,然后我看了一下前十名,发现大部分都是 android 开发,由此可见android开发的火爆程度。
当然你也可以看到你的排名,会让你有打怪升级的快感。
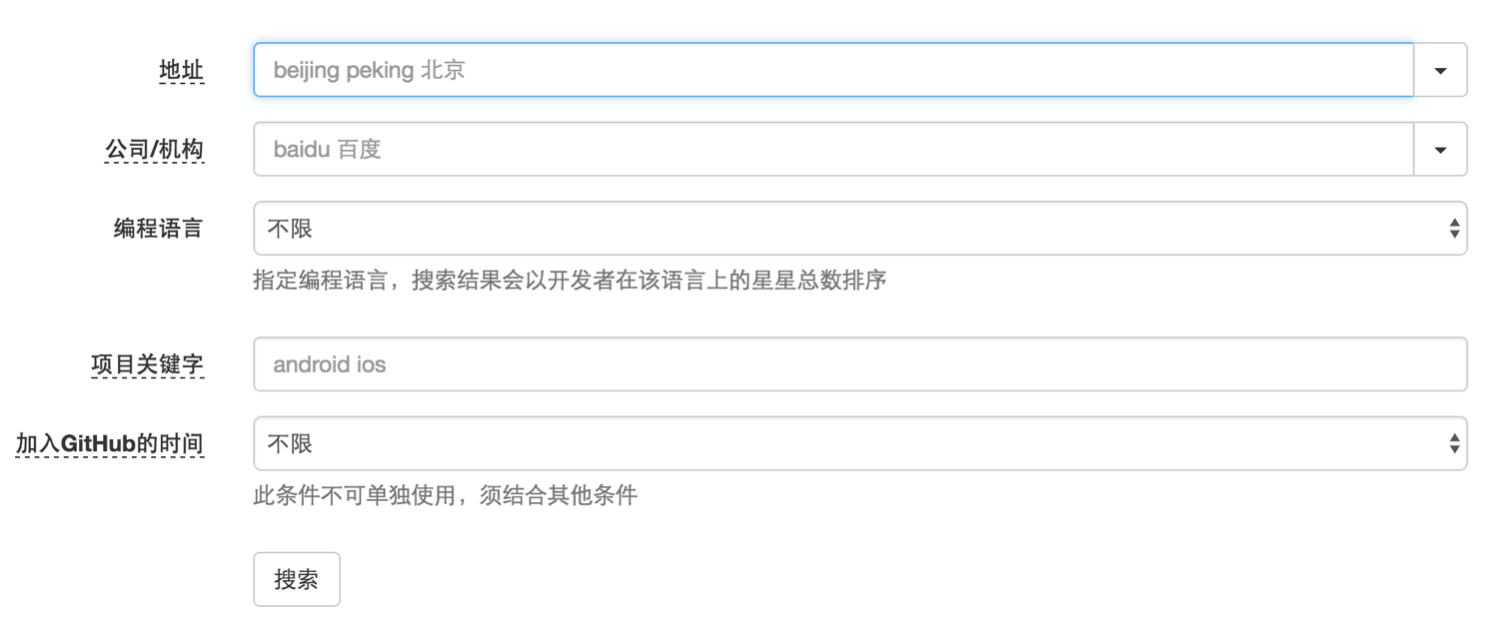
第二个功能是搜索,输入筛选条件,搜搜程序员!
1.4 WebIDE
Coding WebIDE 是 Coding 自主研发的在线集成开发环境 (IDE)。只要你的项目在代码托管平台存放,就可以导入到 WebIDE。之后就可以在线开发。
WebIDE 还提供 WebTerminal 功能,用户可以远程操作Docker容器,自由安装偏好的软件包、方便折腾。
看起来是不是还挺好玩的,如果想把这些都玩转,git 是肯定要好好学的。接下来,我们就看一下 git 的基本原理。
2. Git 原理
我们可以现在想一下,如果我们自己来设计,应该怎么设计。
传统的设计方案我们可以简单的分成两块:工作目录,远程仓库。

但是作为一个目标明确的分布式版本控制系统,首先要做的就是添加一个本地仓库。

接着我们选择在工作目录与远程仓库中间加一个缓冲区域,叫做暂存区。

加入暂存区的原因有以下几点:
为了能够实现部分提交
为了不再工作区创建状态文件、会污染工作区。
暂存区记录文件的修改时间等信息,提高文件比较的效率。
至此就我们本地而言有三个重要的区域:工作区、暂存区、本地仓库。
接下来我们想一下本地仓库是如何存放项目历史版本。
2.1 快照

这是项目的三个版本,版本1中有两个文件A和B,然后修改了A,变成了A1,形成了版本2,接着又修改了B变为B1,形成了版本3。
如果我们把项目的每个版本都保存到本地仓库,需要保存至少6个文件,而实际上,只有4个不同的文件,A、A1、B、B1。为了节省存储的空间,我们要像一个方法将同样的文件只需要保存一份。这就引入了Sha-1算法。
可以使用git命令计算文件的 sha-1 值。
echo 'test content' | git hash-object --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4
SHA-1将文件中的内容通过通过计算生成一个 40 位长度的hash值。
Sha-1的非常有特点:
由文件内容计算出的hash值
hash值相同,文件内容相同
对于上图中的内容,无论我们执行多少次,都会得到相同的结果。因此,文件的sha-1值是可以作为文件的唯一 id 。同时,它还有一个额外的功能,校验文件完整性。
有了 sha-1 的帮助,我们可以对项目版本的存储方式做一下调整。

2.1.1 数据库中存储的数据内容
实际上,现在就与git实际存储的结构一致了。我们可以预览一下实际存储在 .git 下的文件。
我们可以看到,在 objects 目录下,存放了很多文件,他们都使用 sha-1 的前两位创建了文件夹,剩下的38位为文件名。我们先称呼这些文件为 obj 文件。
对于这么多的 obj 文件,就保存了我们代码提交的所有记录。对于这些 obj 文件,其实分为四种类型,分别是 blob、tree、commit、tag。接下来,我们分别来看一下。
blob
首先 A、A1、B、B1 就是 blob 类型的 obj。
blob: 用来存放项目文件的内容,但是不包括文件的路径、名字、格式等其它描述信息。项目的任意文件的任意版本都是以blob的形式存放的。
tree
tree 用来表示目录。我们知道项目就是一个目录,目录中有文件、有子目录。因此 tree 中有 blob、子tree,且都是使用 sha-1值引用的。这是与目录对应的。从顶层的 tree 纵览整个树状的结构,叶子结点就是blob,表示文件的内容,非叶子结点表示项目的目录,顶层的 tree 对象就代表了当前项目的快照。
commit
commit: 表示一次提交,有parent字段,用来引用父提交。指向了一个顶层 tree,表示了项目的快照,还有一些其它的信息,比如上一个提交,committer、author、message 等信息。
2.2 暂存区
暂存区是一个文件,路径为: .git/index
它是一个二进制文件,但是我们可以使用命令来查看其中的内容。
这里我们关注第二列和第四列就可以了,第四列是文件名,第二列指的是文件的blob。这个blob存放了文件暂存时的内容。
第二列就是sha-1 hash值,相当于内容的外键,指向了实际存储文件内容的blob。第三列是文件的冲突状态,这个后面会讲,第四列是文件的路径名。
我们操作暂存区的场景是这样的,每当编辑好一个或几个文件后,把它加入到暂存区,然后接着修改其他文件,改好后放入暂存区,循环反复。直到修改完毕,最后使用 commit 命令,将暂存区的内容永久保存到本地仓库。
这个过程其实就是构建项目快照的过程,当我们提交时,git 会使用暂存区的这些信息生成tree对象,也就是项目快照,永久保存到数据库中。因此也可以说暂存区是用来构建项目快照的区域。
2.3 文件状态
有了工作区、暂存区、本地仓库,就可以来定义文件的状态了。

文件的状态可以分为两类。一类是暂存区与本地仓库比较得出的状态,另一类是工作区与暂存区比较得出的状态。为什么要分成两类的愿意也很简单,因为第一类状态在提交时,会直接写入本地仓库。而第二种则不会。一个文件可以同时拥有两种状态。
比如一个文件可能既有上面的 modified 状态,又有下面 modified 状态,但其实他们表示了不同的状态,git 会使用绿色和红色把这两中 modified 状态区分开来。
2.4 分支
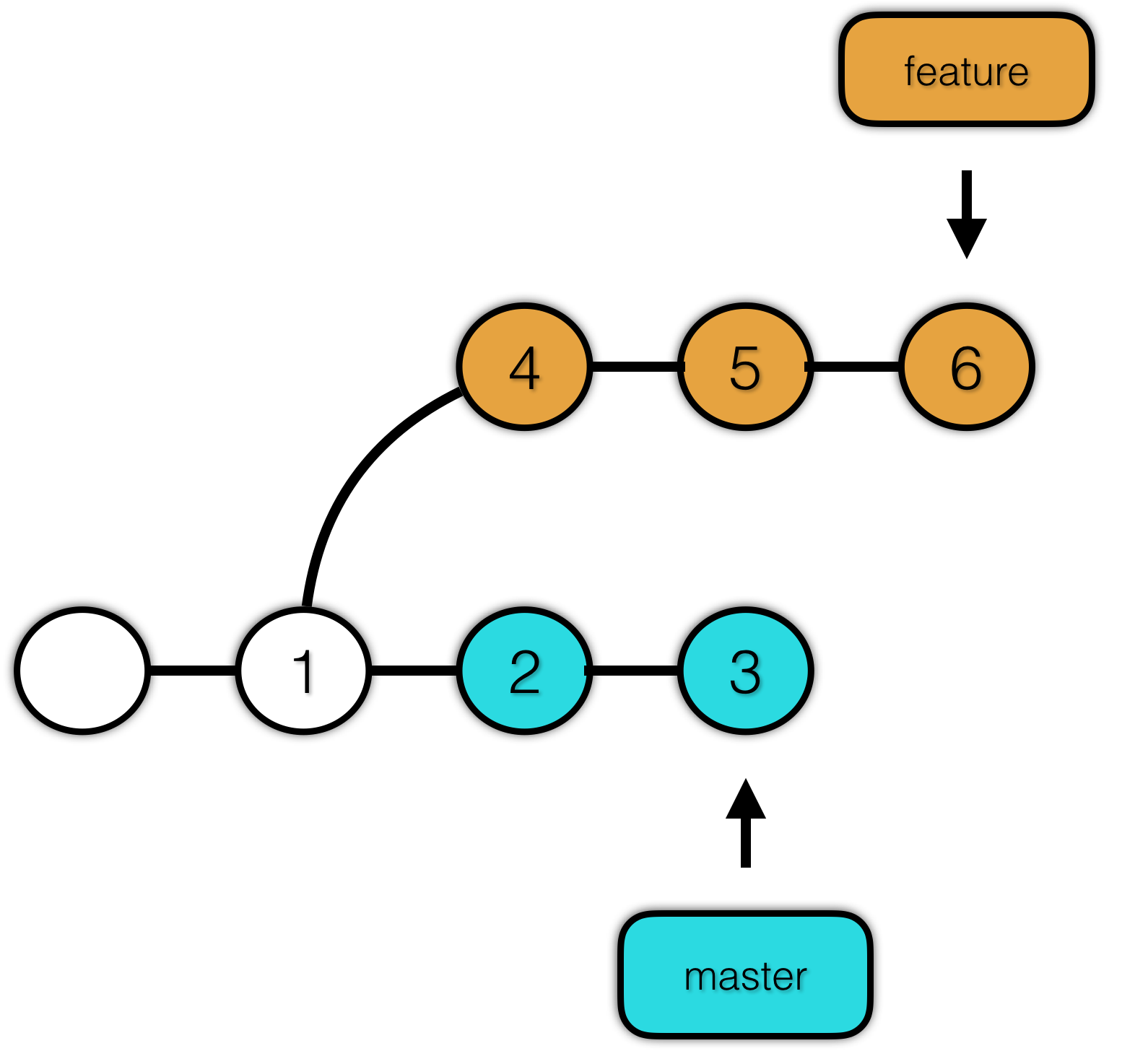
接下来,看一个很重要的概念,分支。
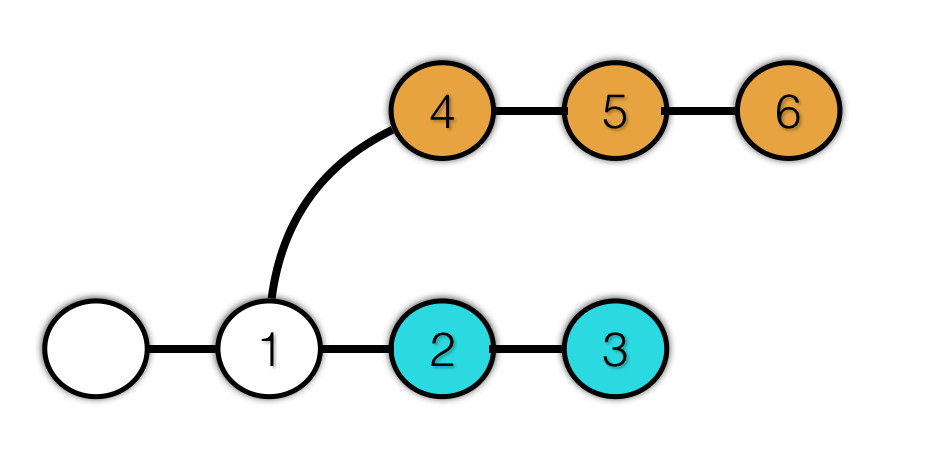
分支的目的是让我们可以并行的进行开发。比如我们当前正在开发功能,但是需要修复一个紧急bug,我们不可能在这个项目正在修改的状态下修复 bug,因为这样会引入更多的bug。
有了分支的概念,我们就可以新建一个分支,修复 bug,使新功能与 bug 修复同步进行。
分支的实现其实很简单,我们可以先看一下 .git/HEAD 文件,它保存了当前的分支。
cat .git/HEAD
=>ref: refs/heads/master
其实这个 ref 表示的就是一个分支,它也是一个文件,我们可以继续看一下这个文件的内容:
cat .git/refs/heads/master
=> 2b388d2c1c20998b6233ff47596b0c87ed3ed8f8
可以看到分支存储了一个 object,我们可以使用 cat-file 命令继续查看该 object 的内容。
git cat-file -p 2b388d2c1c20998b6233ff47596b0c87ed3ed8f8
=> tree 15f880be0567a8844291459f90e9d0004743c8d9
=> parent 3d885a272478d0080f6d22018480b2e83ec2c591
=> author Hehe Tan <xiayule148@gmail.com> 1460971725 +0800
=> committer Hehe Tan <xiayule148@gmail.com> 1460971725 +0800
=>
=> add branch paramter for rebase
从上面的内容,我们知道了分支指向了一次提交。为什么分支指向一个提交的原因,其实也是git中的分支为什么这么轻量的答案。
因为分支就是指向了一个 commit 的指针,当我们提交新的commit,这个分支的指向只需要跟着更新就可以了,而创建分支仅仅是创建一个指针。
3. 高层命令
在 git 中分为两种类型的命令,一种是完成底层工作的工具集,称为底层命令,另一种是对用户更友好的高层命令。一条高层命令,往往是由多条底层命令组成的。
不知道的人可能一听高层感觉很厉害的样子,其实就是指的是那些我们最常使用的git命令。
3.1 Add & Commit
add 和 commit 应该可以说是我们使用频率最高的高层命令了。
touch README.md
git add README.md
git commit -m "add readme”
touch 指的是创建一个文件,代表了我们对项目文件内容的修改,add 操作是将修改保存到暂存区,commit 是将暂存区的内容永久保存到本地仓库。
每当将修改的文件加入到暂存区,git 都会根据文件的内容计算出 sha-1,并将内容转换成 blob,写入数据库。然后使用 sha-1 值更新该列表中的文件项。在暂存区的文件列表中,每一个文件名,都会对应一个sha-1值,用于指向文件的实际内容。最后提交的那一刻,git会将这个列表信息转换为项目的快照,也就是 tree 对象。写入数据库,并再构建一个commit对象,写入数据库。然后更新分支指向。
3.2 Conflicts & Merge & Rebase
3.2.1 Conflicts
git 中的分支十分轻量,因此我们在使用git的时候会频繁的用到分支。不可不免的需要将新创建的分支合并。
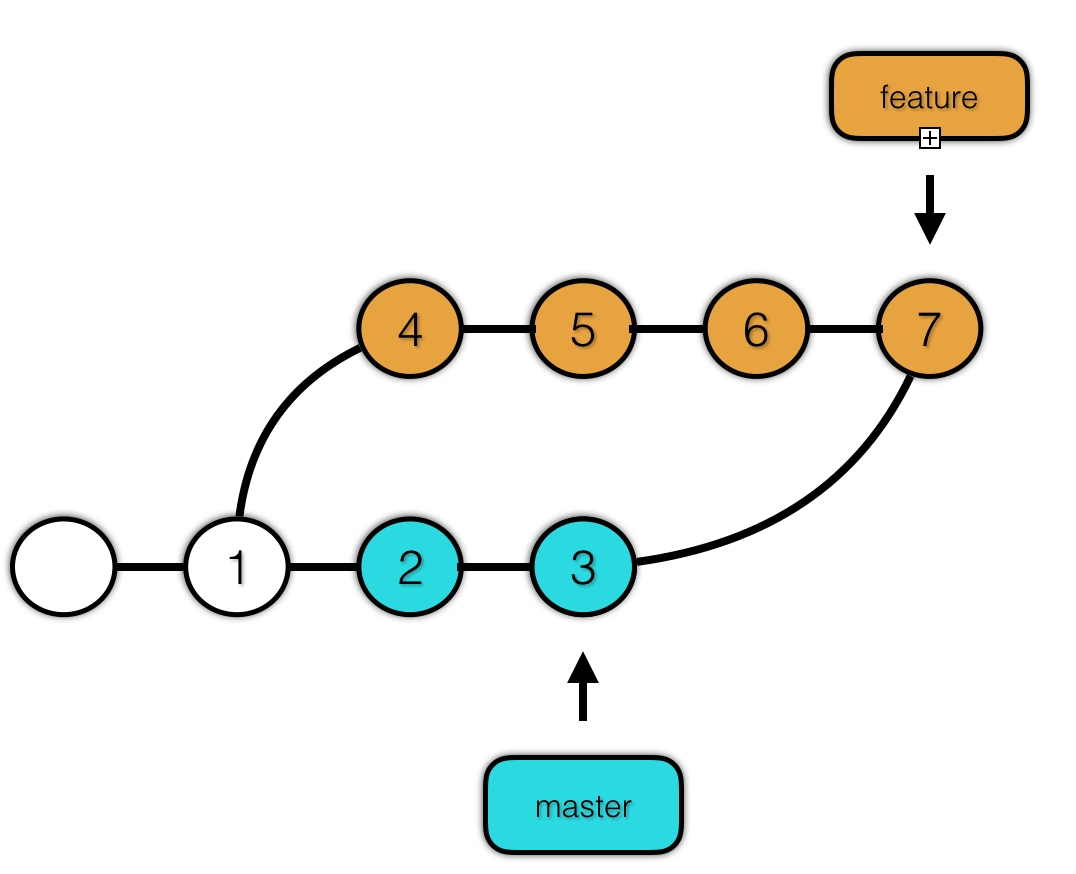
在 git 中合并分支有两种选择:merge 和 rebase。但是,无论哪一种,都有可能产生冲突。因此我们先来看一下冲突的产生。
图上的情况,并不是移动分支指针就能解决问题的,它需要一种合并策略。首先,我们需要明确的是谁和谁的合并,是 2,3 与 4,5,6的合并吗?说到分支,我们总会联想到线,就会认为是线的合并。其实不是的,真实合并的是 3 和 6。因为每一次提交都包含了项目完整的快照,即合并只是 tree 与 tree 的合并。
我们可以先想一个简单的算法。用来比较3和6。但是我们还需要一个比较的标准,如果只是3和6比较,那么3与6相比,添加了一个文件,也可以说成是6与3比删除了一个文件,这无法确切表示当前的冲突状态。因此我们选取他们的两个分支的分歧点(merge base)作为参考点,进行比较。
比较时,相对于 merge base(提交1)进行比较。
首先把1、3、6中所有的文件做一个列表,然后依次遍历这个列表中的文件。现在我们拿列表中的一个文件进行举例,把在提交1、3、6中的该文件分别称为版本1、版本3、版本6。
版本1、版本3、版本6的 sha-1 值完全相同,这种情况表明没有冲突
版本3或6至少一个与版本1状态相同(指的是sha-1值相同或都不存在),这种情况可以自动合并。比如1中存在一个文件,3对该文件进行修改,而6中删除了这个文件,则以6为准就可以了
版本3或版本6都与版本1的状态不同,情况复杂一些,自动合并策略很难生效,需要手动解决。我们来看一下这种状态的定义。
冲突状态定义:
1 and 3: DELETED_BY_THEM;
1 and 6: DELETED_BY_US;
3 and 6: BOTH_ADDED;
1 and 3 and 6: BOTH_MODIFIED
我们拿第一种情况举例,文件有两种状态 1 和 3,1 表示该文件存在于 commit 1(也就是MERGE_BASE),3 表示该文件在 commit 3 (master 分支)中被修改了,没有 6,也就是该文件在 commit 6(feature 分支)被删除了,总结来说这种状态就是 DELETED_BY_THEM。
可以再看一下第四种情况,文件有三种状态 1、3、6,1 表示 commit 1(MERGE_BASE)中存在,3 表示 commit 3(master 分支)进行了修改,6 表示(feature 分支)也进行了修改,总结来说就是 BOTH_MODIFIED(双方修改)。
遇到不可自动合并冲突时,git会将这些状态写入到暂存区。与我们讨论不同的是,git使用1,2,3标记文件,1表示文件的base版本,2表示当前的分支的版本,3表示要合并分支的版本。
3.2.2 Merge
在解决完冲突后,我们可以将修改的内容提交为一个新的提交。这就是 merge。
merge 之后仍可以做出新的提交。
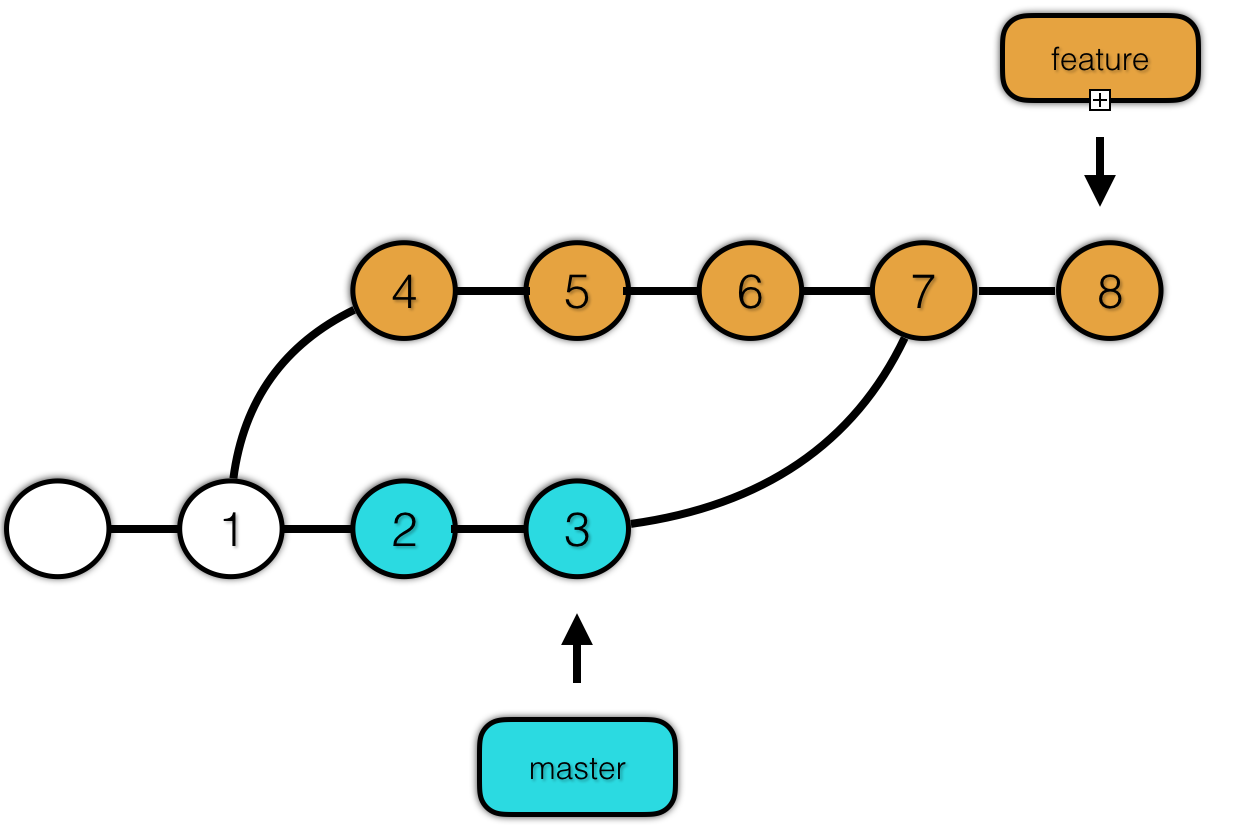
可以看到 merge 是一种不修改分支历史提交记录的方式,这也是我们常用的方式。但是这种方式在某些情况下使用 起来不太方便,比如当我们创建了 pr、mr 或者 将修改补丁发送给管理者,管理者在合并操作中产生了冲突,还需要去解决冲突,这无疑增加了他人的负担。
使用 rebase 可以解决这种问题。
3.2.3 Rebase
假设我们的分支结构如下:
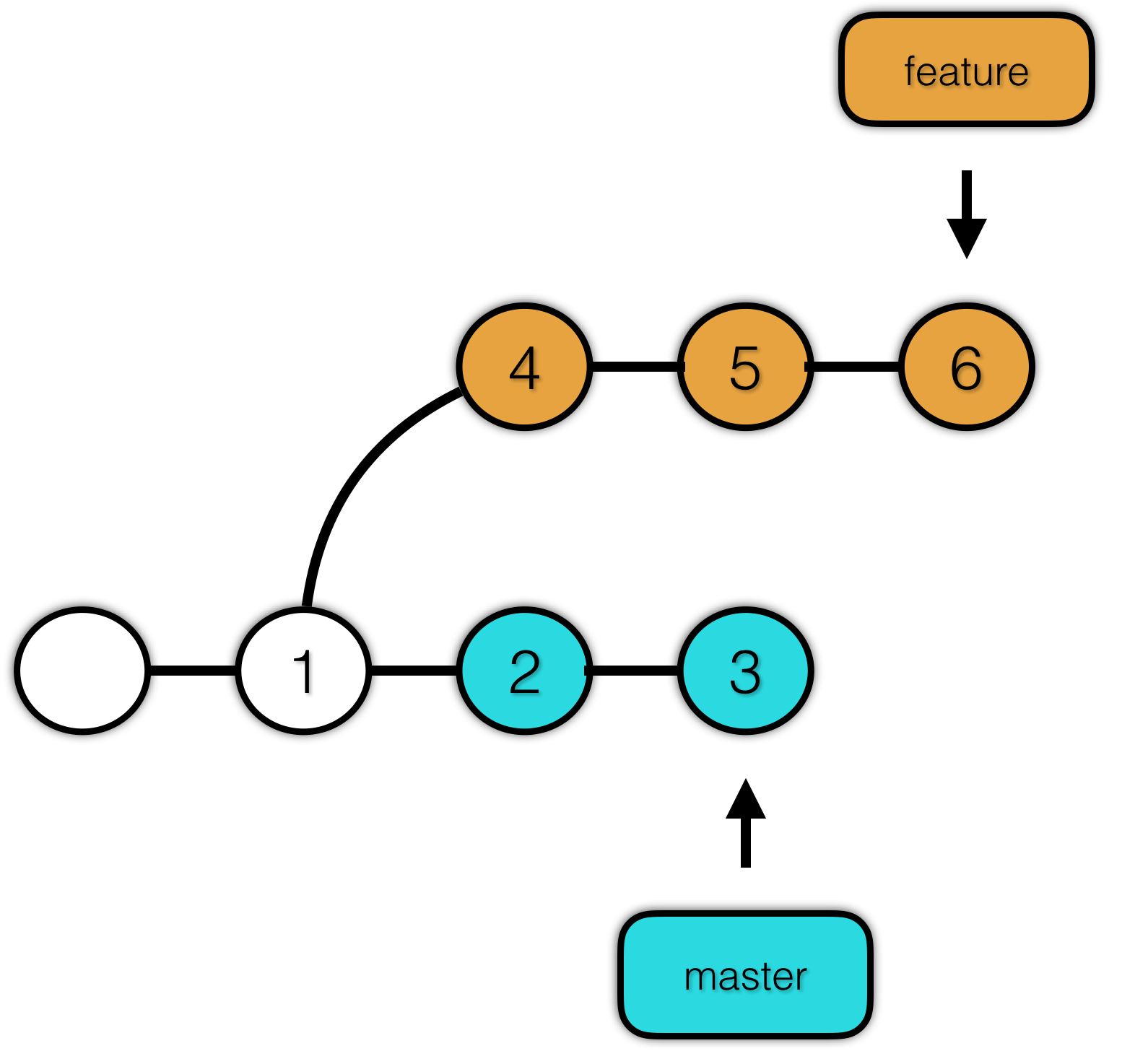
rebase 会把从 Merge Base 以来的所有提交,以补丁的形式一个一个重新达到目标分支上。这使得目标分支合并该分支的时候会直接 Fast Forward,即不会产生任何冲突。提交历史是一条线,这对强迫症患者可谓是一大福音。
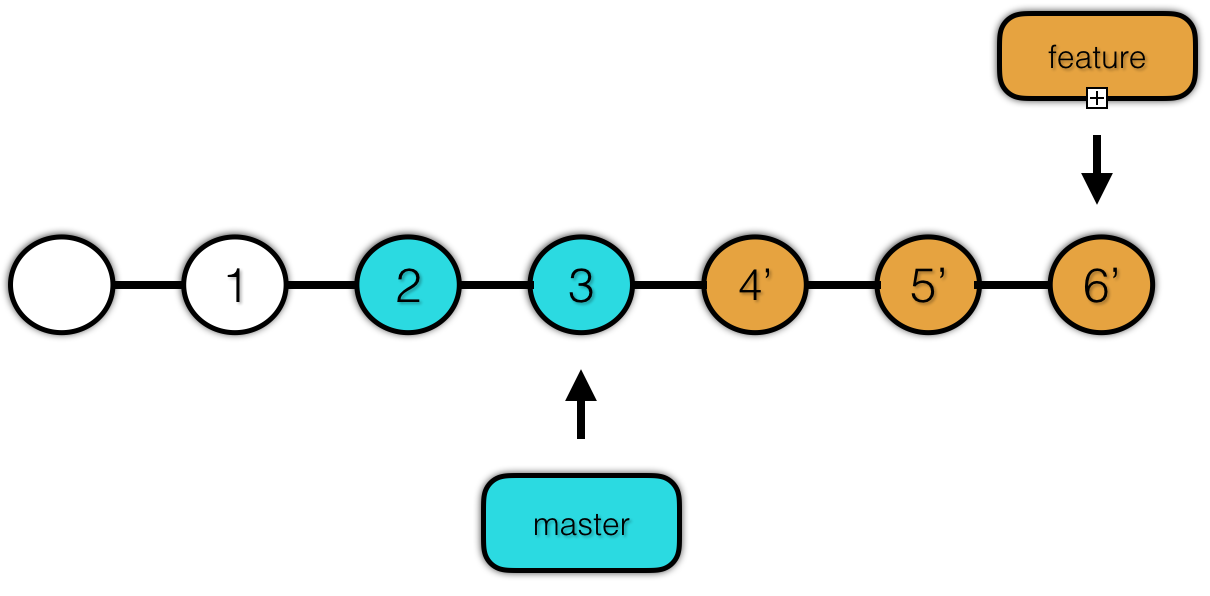
如果我们想要看 rebase 实际上做了什么,有一个方法,那就是用“慢镜头”来看rebase的整个操作过程。rebase 提供了交互式选项(参数 -i),我们可以针对每一个patch,选择你要进行的操作。
通过这个交互式选项,我们可以”单步调试”rebase操作。
经过测试,其实 rebase 主要在 .git/rebase-merge 下生成了两个文件,分别为 git-rebase-todo 和 done 文件,这两个文件的作用光看名字就可以看得出来。git-rebase-todo 存放了 rebase 将要操作的 commit。而 done 存放正在操作或已经操作完毕的 commit。比如我们这里,git-rebase-todo 存放了 4、5、6,三个提交。
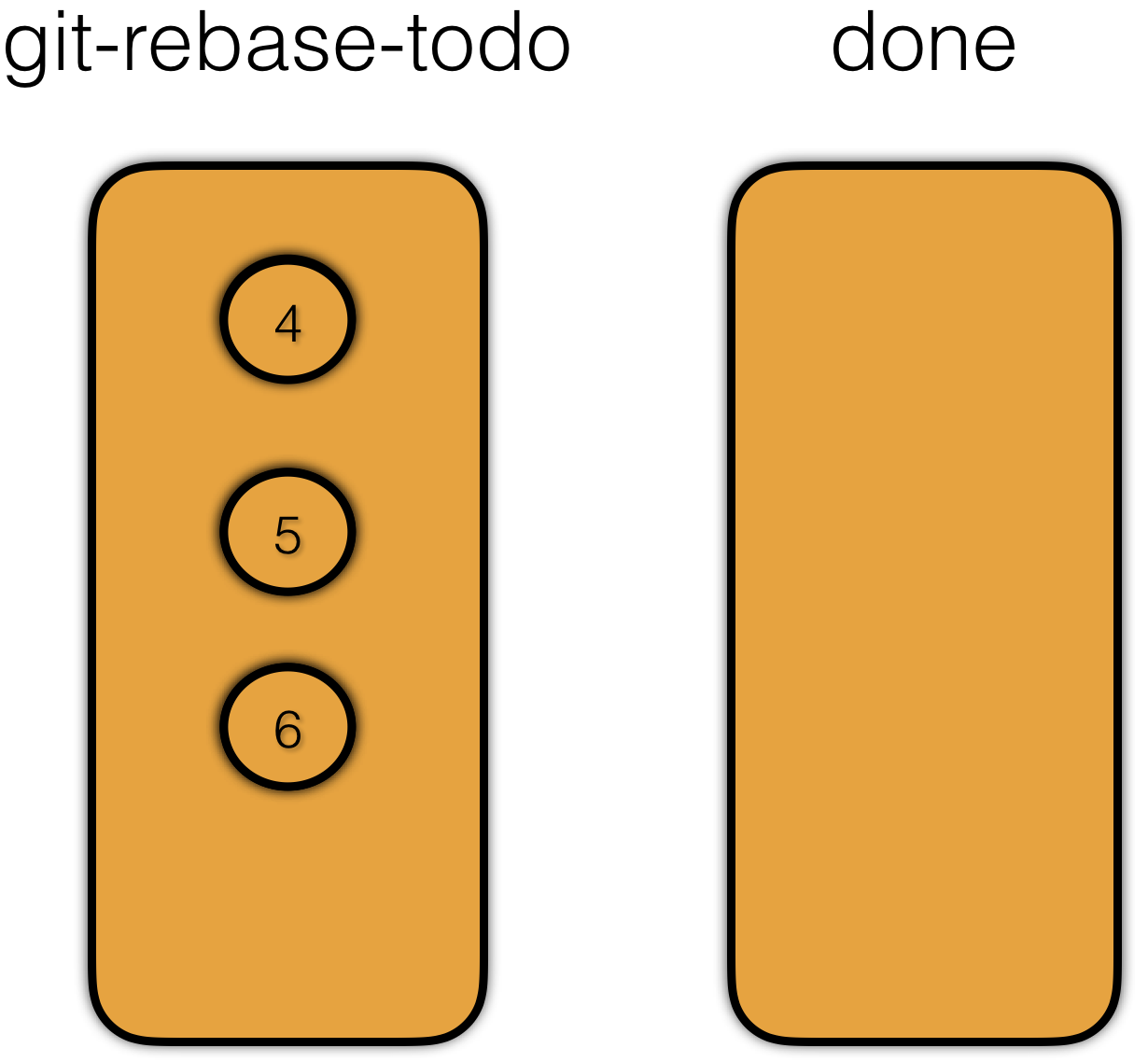
首先 git 将 sha-1 为 4 的 commit 放入 done。表示正在操作 4,然后将 4 以补丁的形式打到 3 上,形成了新的提交 4’。这一步是可能产生冲突的,如果有冲突,需要解决完冲突之后才能继续操作。
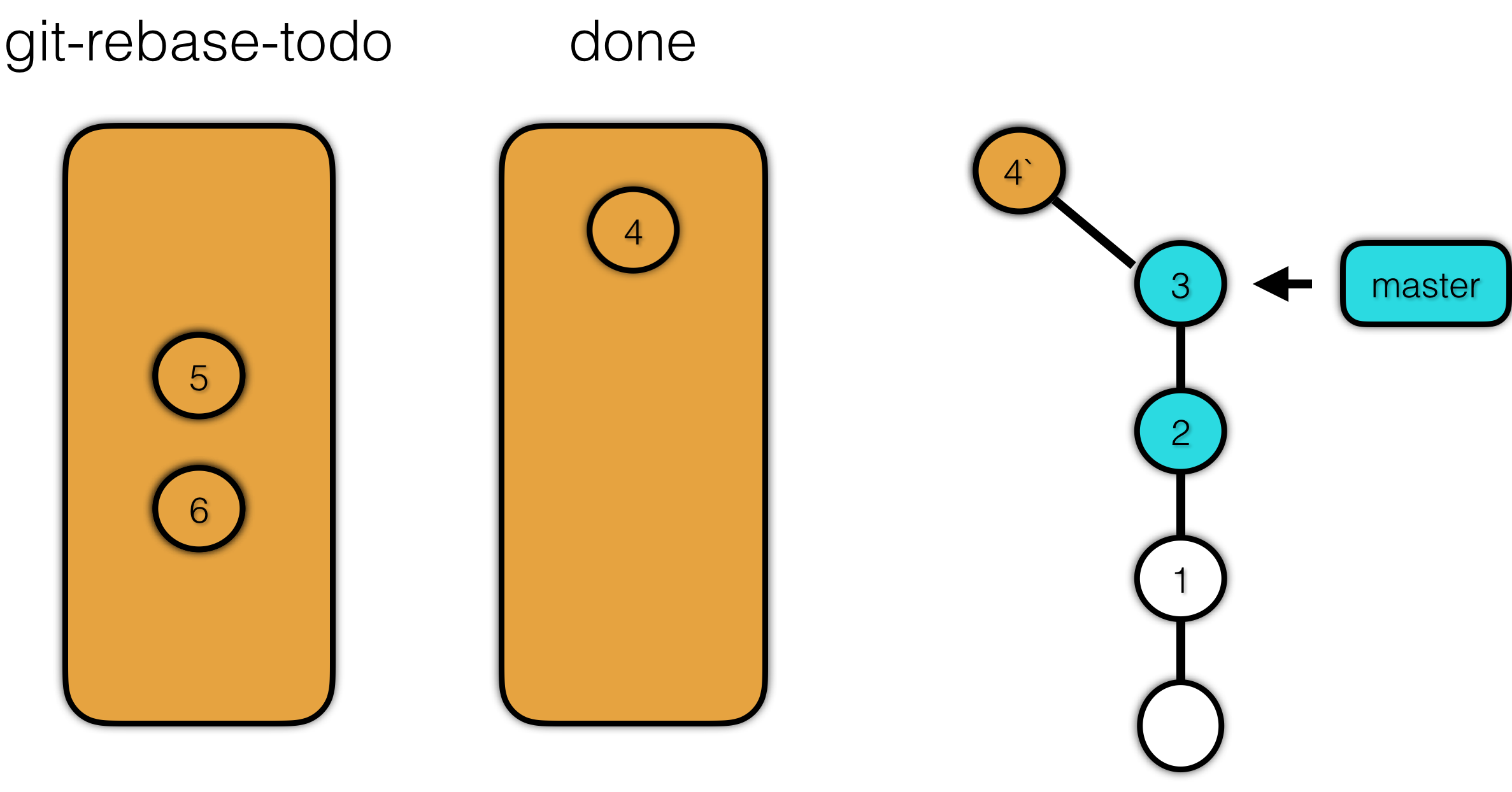
接着讲 sha-1 为 5 的提交放入 done 文件,然后将 5 以补丁的形式打到 4’ 上,形成 5’。
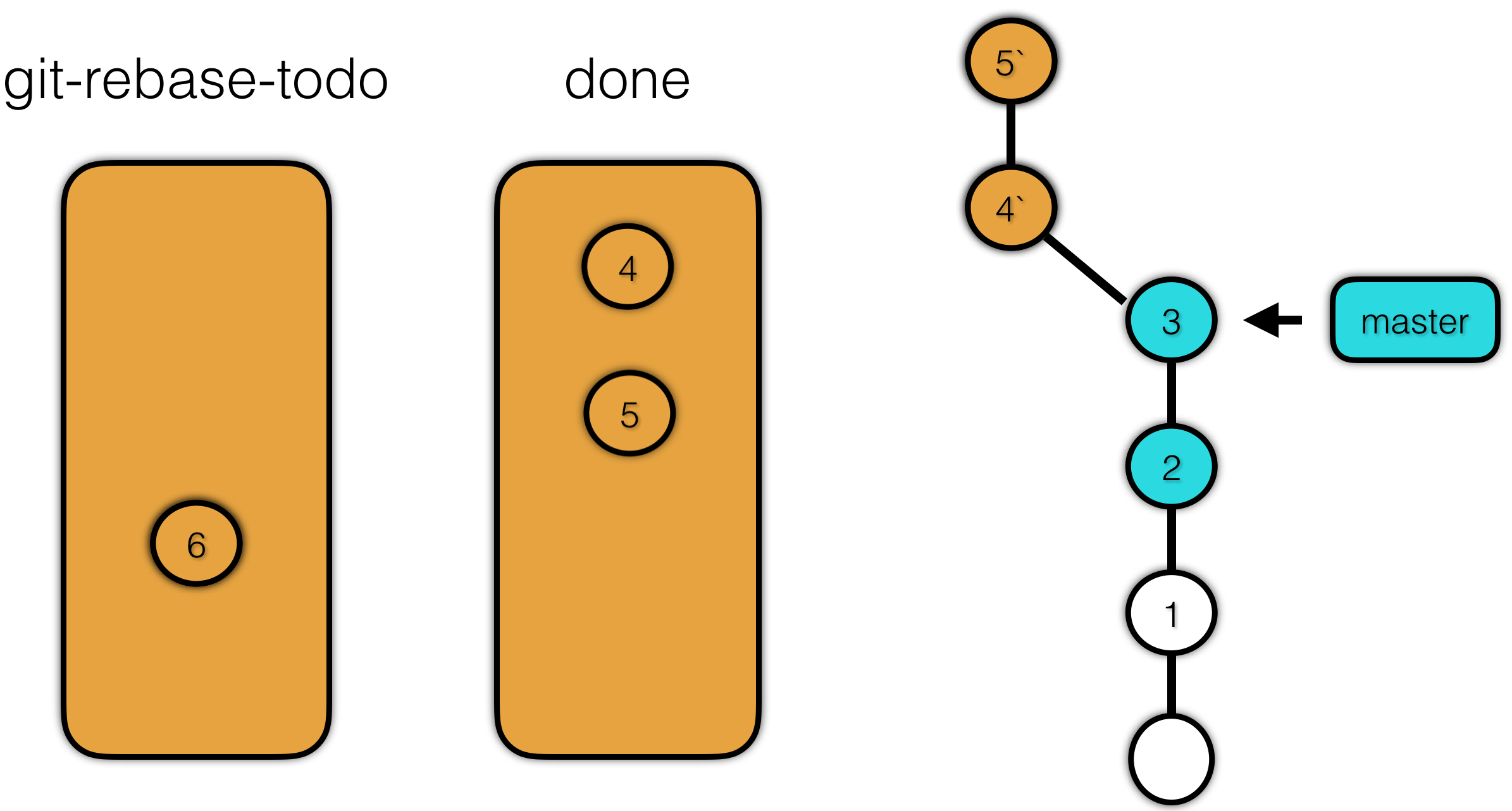
再接着将 sha-1 为 6 的提交放入 done 文件,然后将 6 以补丁的形式打到 5’ 上,形成 6’。最后移动分支指针,使其指向最新的提交 6’ 上。这就完成了 rebase 的操作。
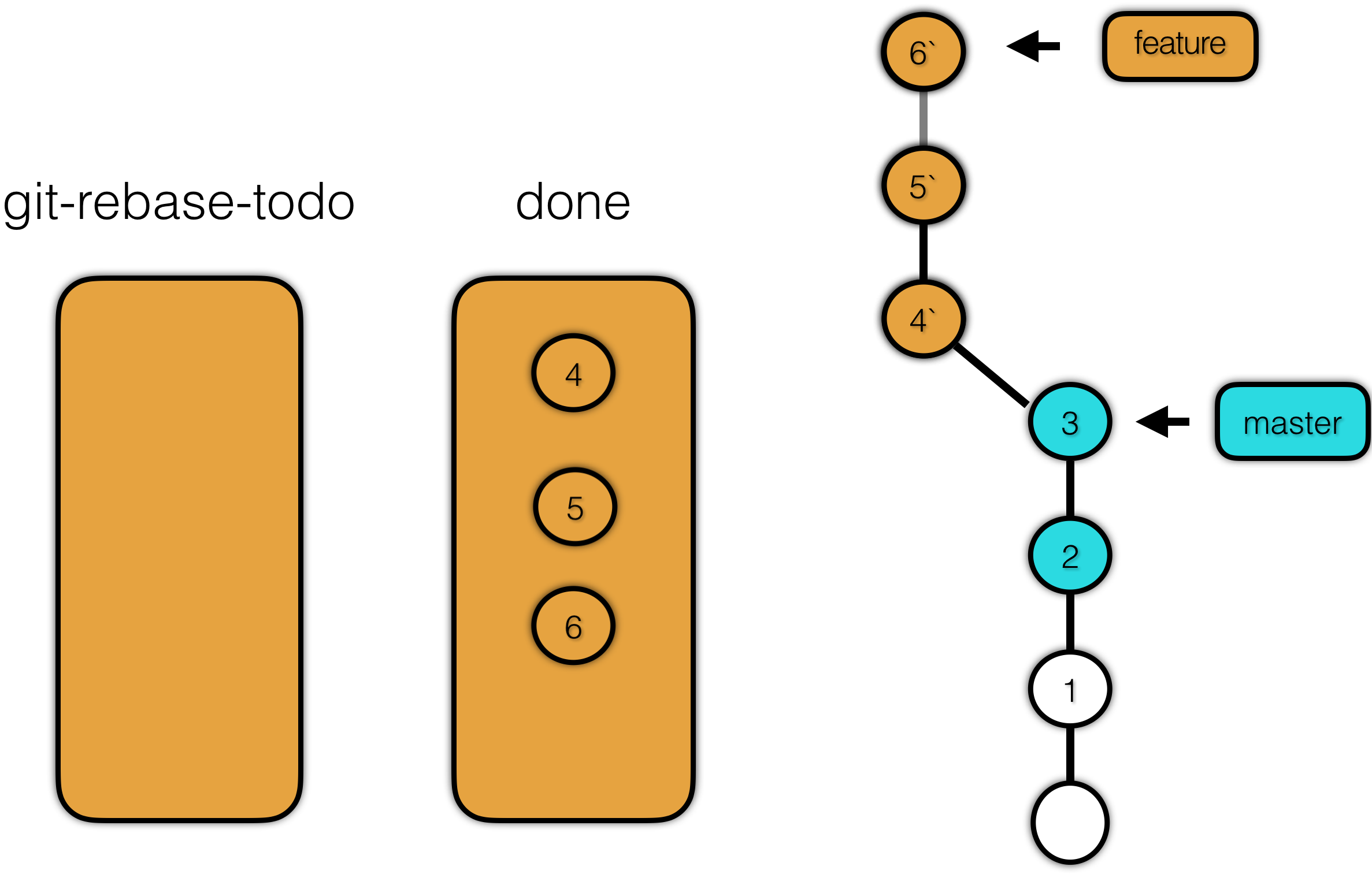
我们看一下真实的 rebase 文件。
pick e0f56d9 update gitignore
pick e370289 add a
# Commands:
# p, pick = use commit
# r, reword = use commit, but edit the commit message
# e, edit = use commit, but stop for amending
# s, squash = use commit, but meld into previous commit
# f, fixup = like "squash", but discard this commit's log message
# x, exec = run command (the rest of the line) using shell
# d, drop = remove commit
该文件一共有三列,第一列表示要进行的操作,所有可以进行的操作,在下面注释里都列了出来,比如 pick 表示使用该提交,reword 表示使用该提交,但修改其提交的 message,edit 表示使用该提交,但是要对该提交进行一些修改,其它的就不一一说了。
而 done 文件的形式如下,和 git-rebase-todo 是一样的:
pick e0f56d9 update gitignore
pick e370289 add a
从刚才的图中,我们就可以看到 rebase 的一个缺点,那就是修改了分支的历史提交。如果已经将分支推送到了远程仓库,会导致无法将修改后的分支推送上去,必须使用 -f 参数(force)强行推送。
所以使用 rebase 最好不要在公共分支上进行操作。
3.3 Checkout、Revert、Reset
3.3.1 Checkout
对于 checkout,我们一般不会陌生。因为使用它的频率非常高,经常用来切换分支、或者切换到某一次提交。
这里我们以切换分支为例,从 git 的工作区、暂存区、本地仓库分别来看 checkout 所做的事情。Checkout 前的状态如下:
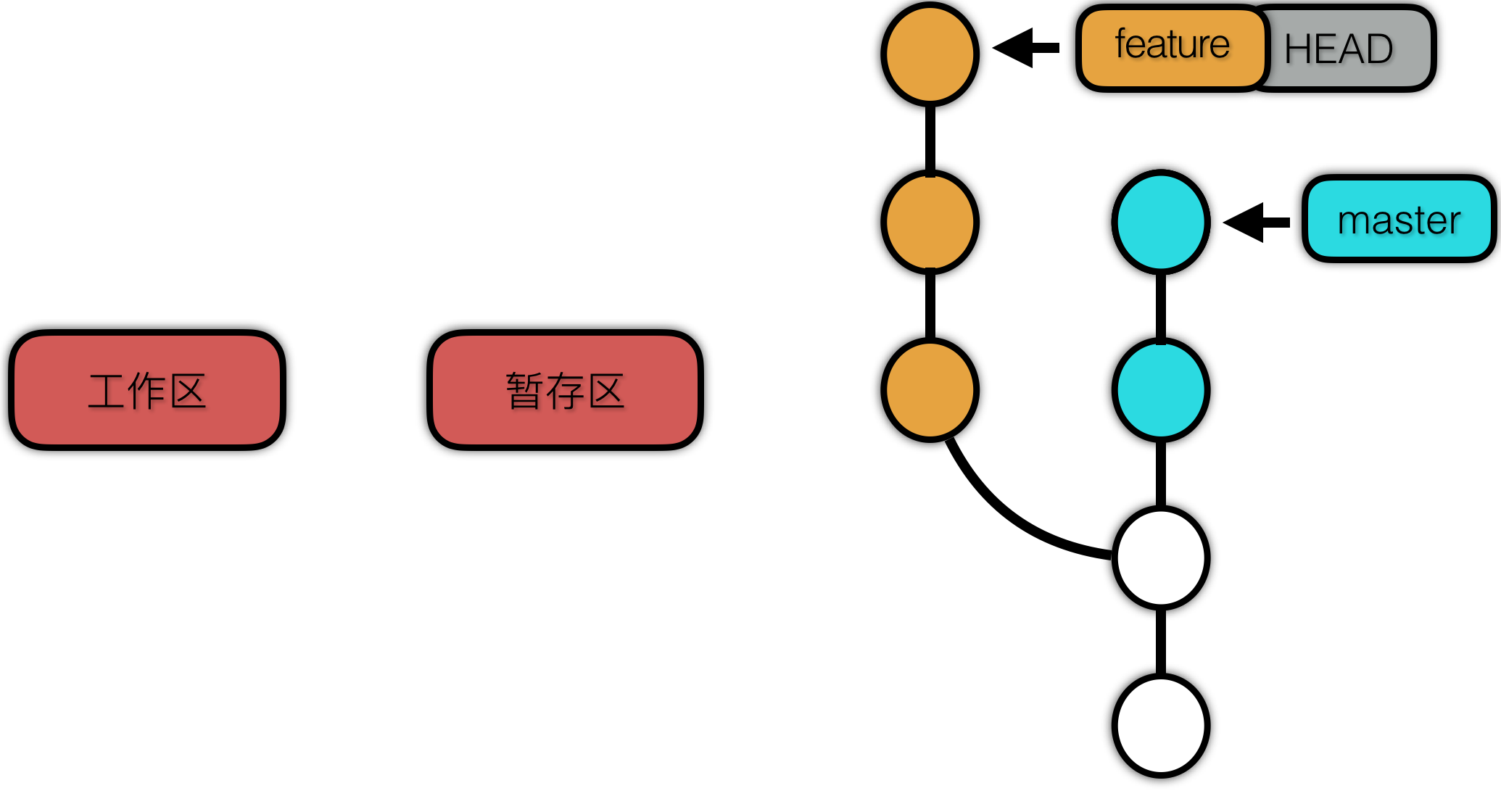
首先 checkout 找到目标提交(commit),目标提交中的快照也就是 tree 对象就是我们要检出的项目版本。
checkout 首先根据tree生成暂存区的内容,再根据 tree 与其包含的 blob 转换成我们的项目文件。然后修改 HEAD 的指向,表示切换分支。
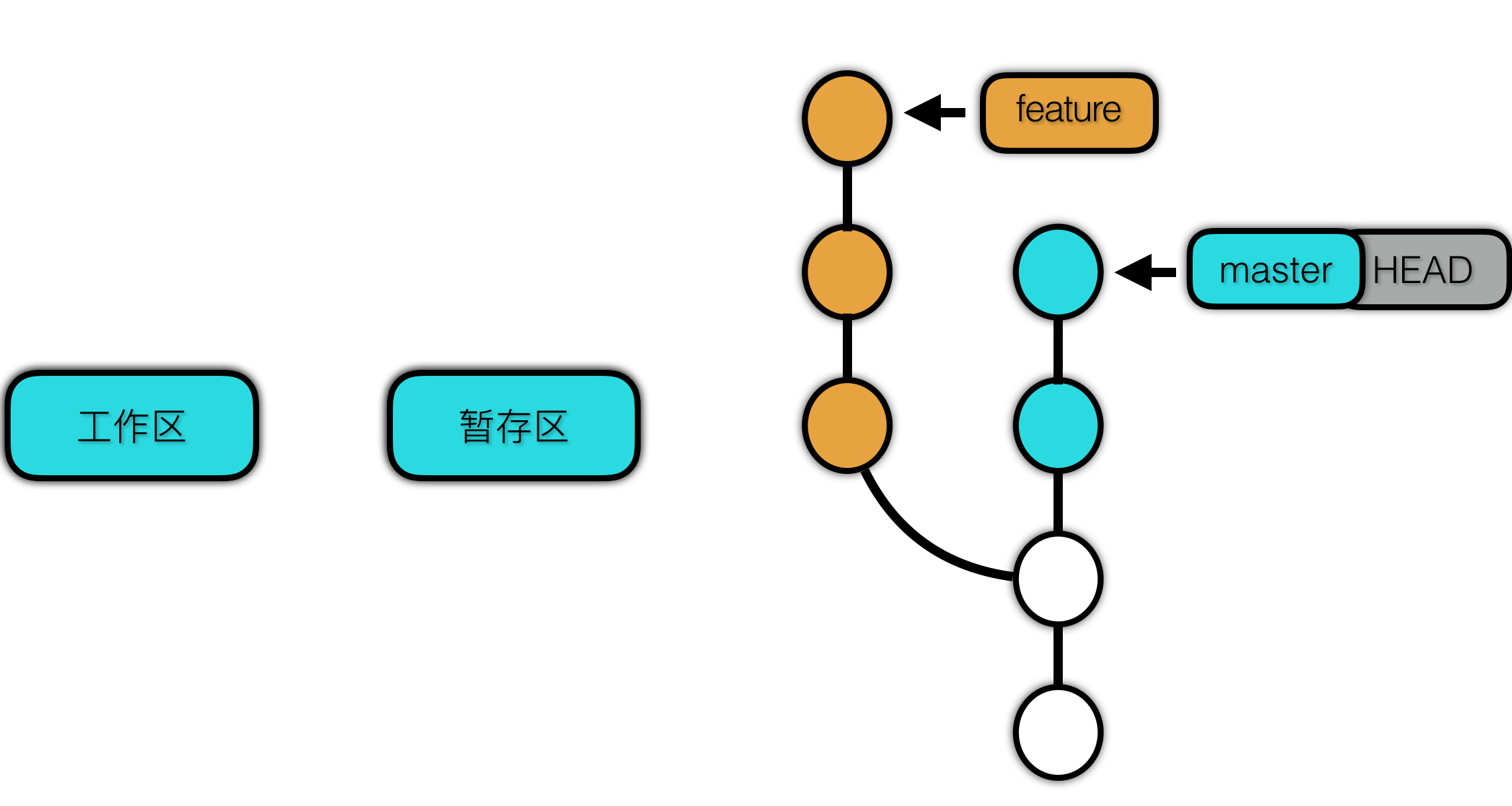
可以看到 checkout 并没有修改提交的历史记录。只是将对应版本的项目内容提取出来。
3.3.2 Revert
如果我们想要用一个用一个反向提交恢复项目的某个版本,那就需要 revert 来协助我们完成了。什么是反向提交呢,就是旧版本添加了的内容,要在新版本中删除,旧版本中删除了的内容,要在新版本中添加。这在分支已经推送到远程仓库的情境下非常有用。
Revert 之前:
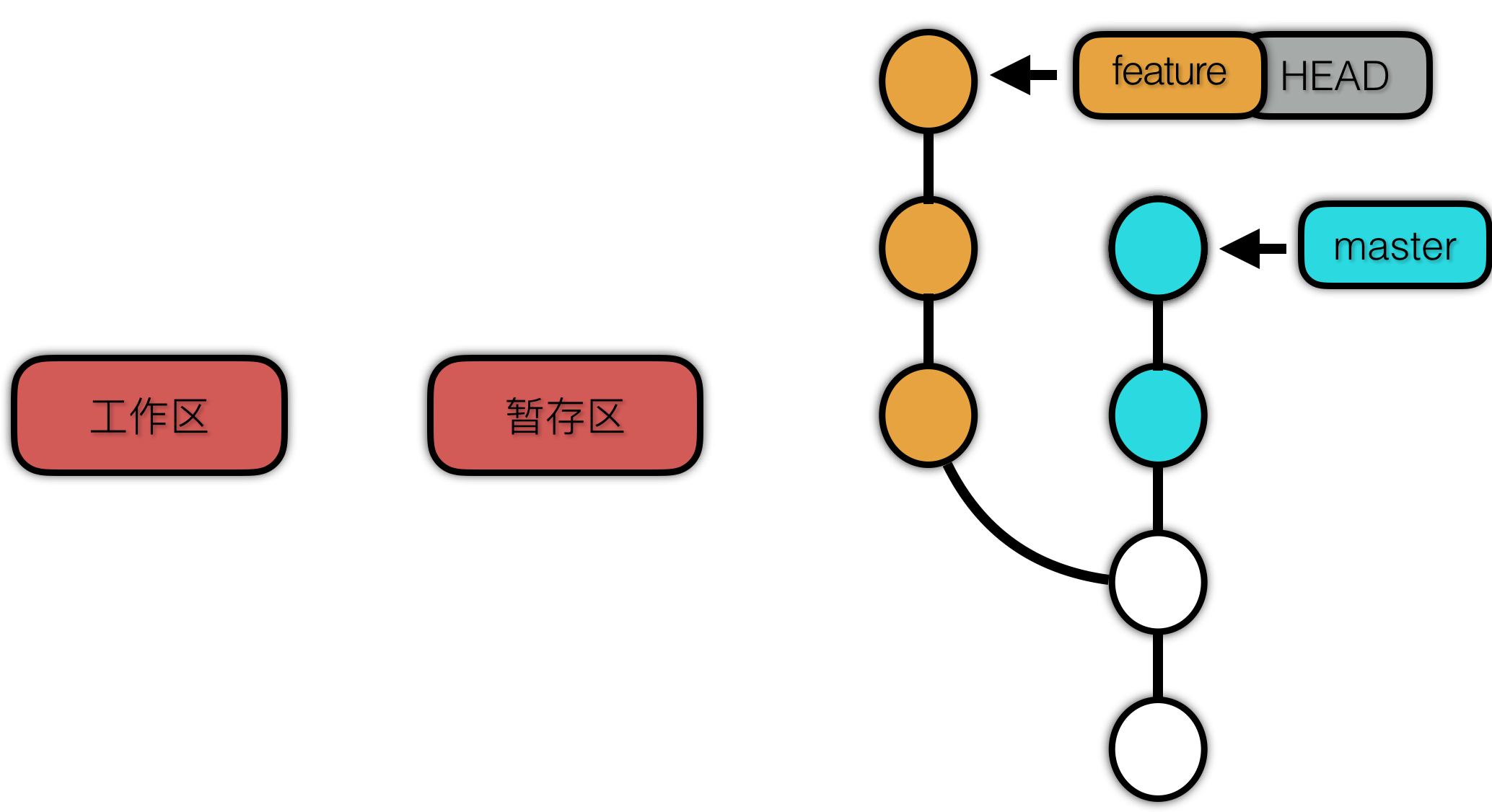
revert 也不会修改历史提交记录,实际的操作相当于是检出目标提交的项目快照到工作区与暂存区,然后用一个新的提交完成版本的“回退”。
Revert 之后:
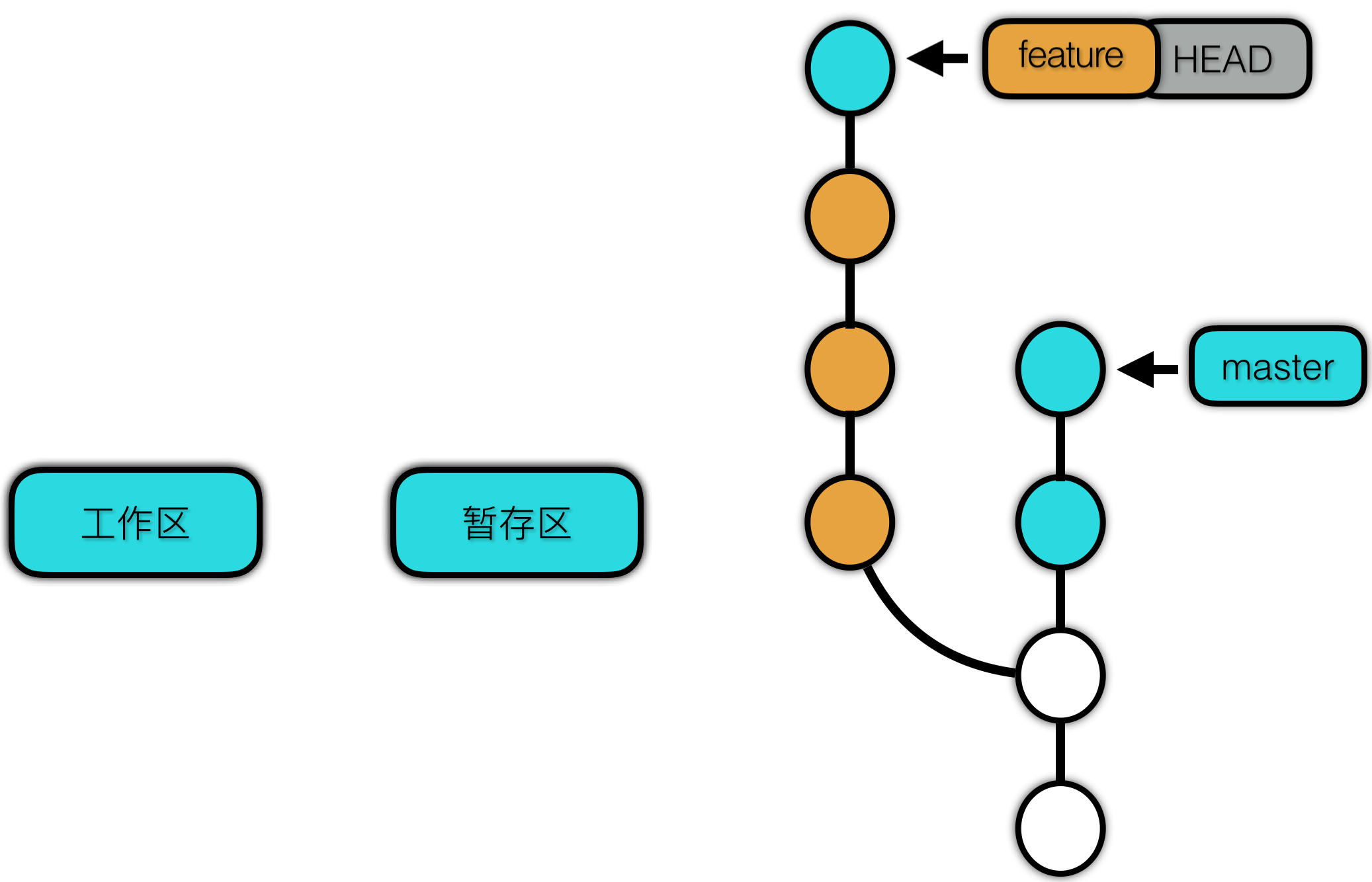
Reset
reset 操作与 revert 很像,用来在当前分支进行版本的“回退”,不同的是,reset 是会修改历史提交记录的。
reset 常用的选项有三个,分别是 ―soft, ―mixed, ―hard。他们的作用域依次增大。
我们分别来看。
soft 会仅仅修改分支指向。而不修改工作区与暂存区的内容,我们可以接着做一次提交,形成一个新的 commit。这在我们撤销临时提交的场景下显得比较有用。
使用 reset --soft 前:
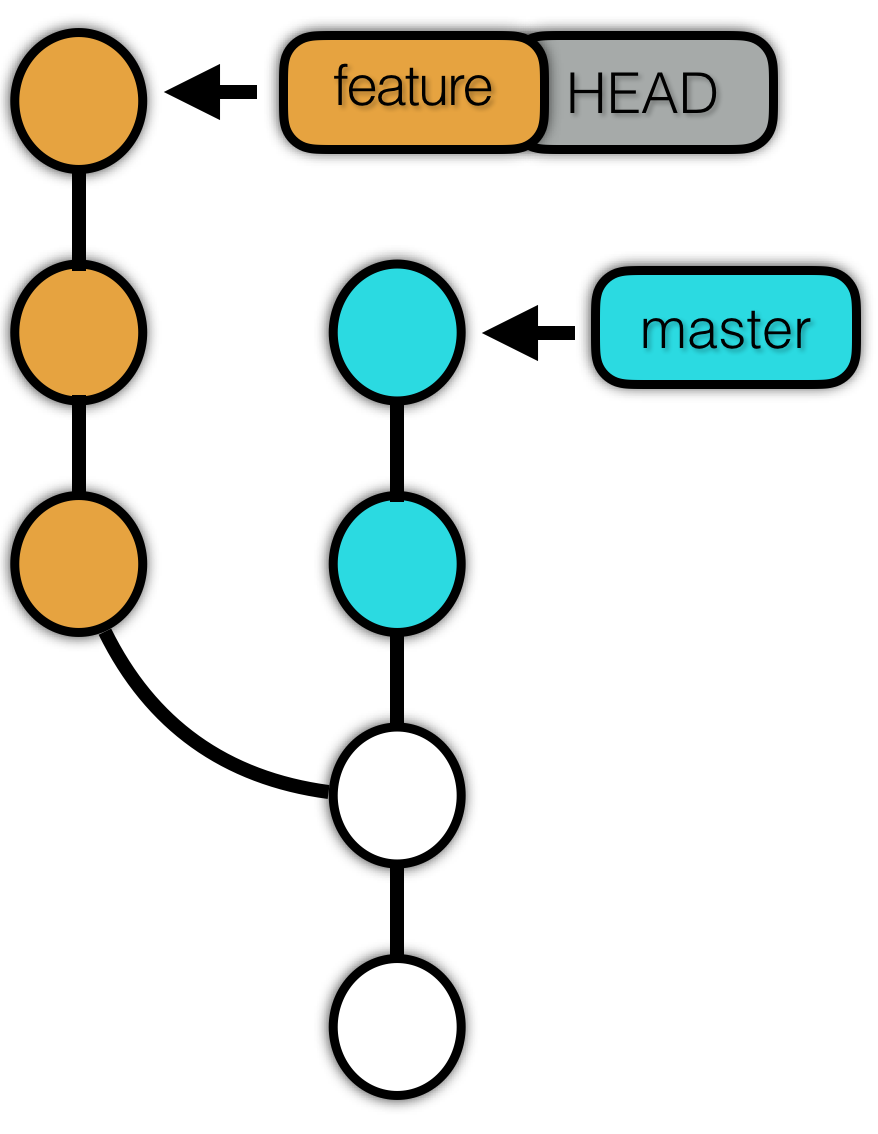
使用 reset --soft 后:
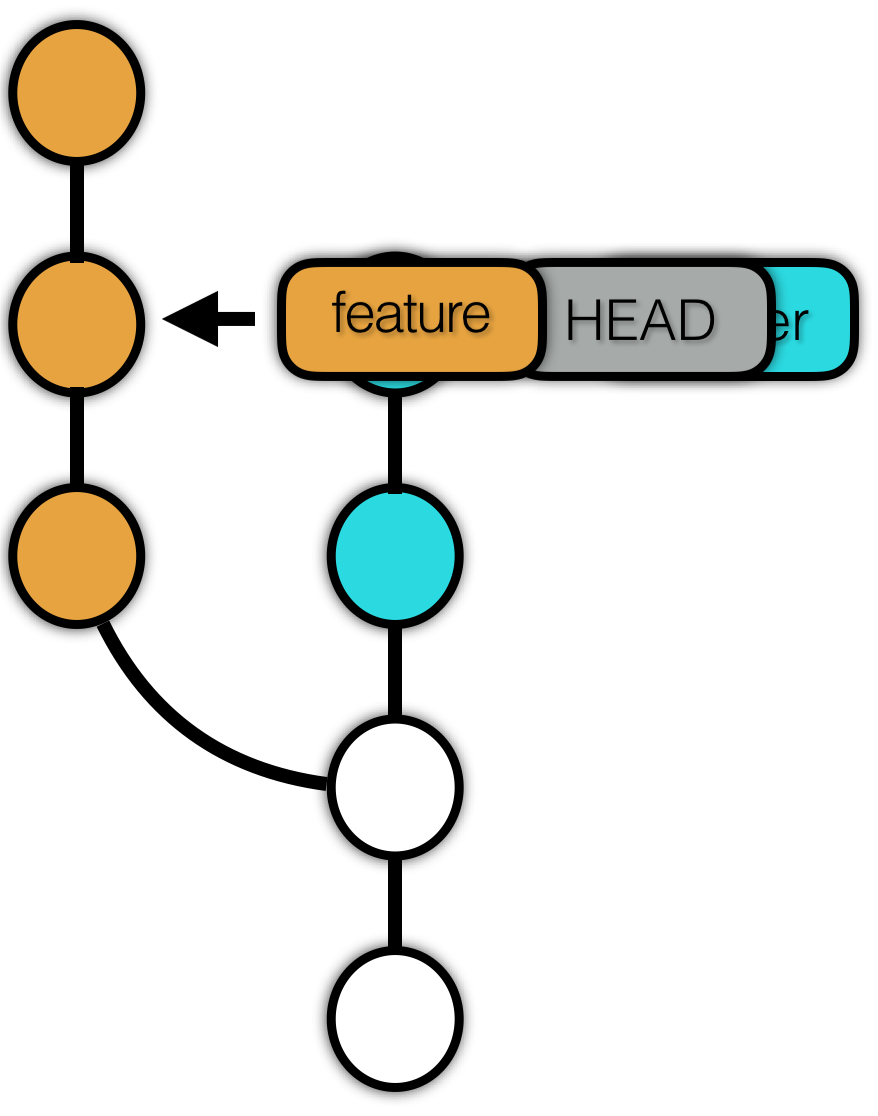
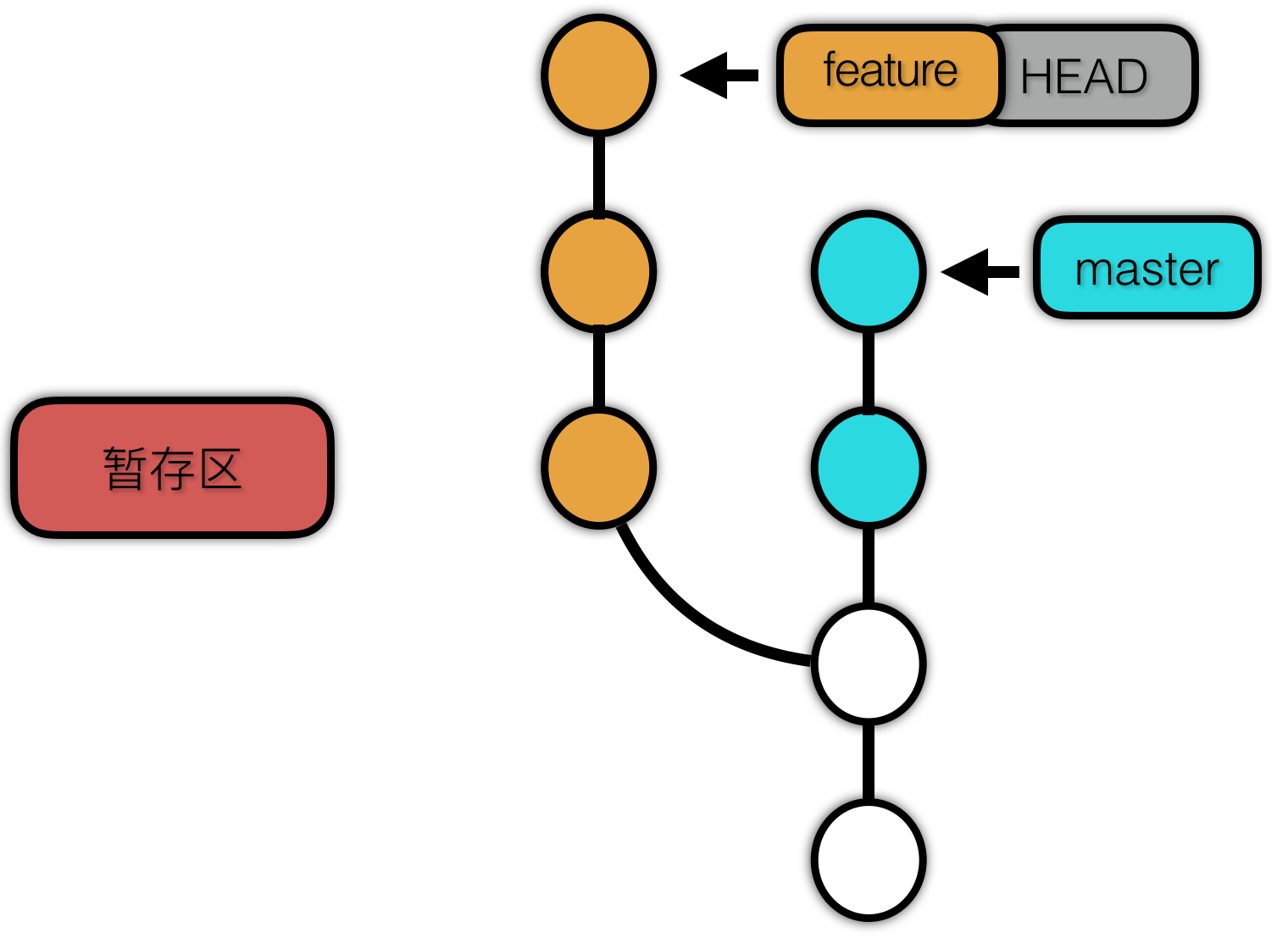
mixed 比 soft 的作用域多了一个 暂存区。实际上 mixed 选项与 soft 只差了一个 add 操作。
使用 reset --mixed 前:
使用 reset --mixed 后:
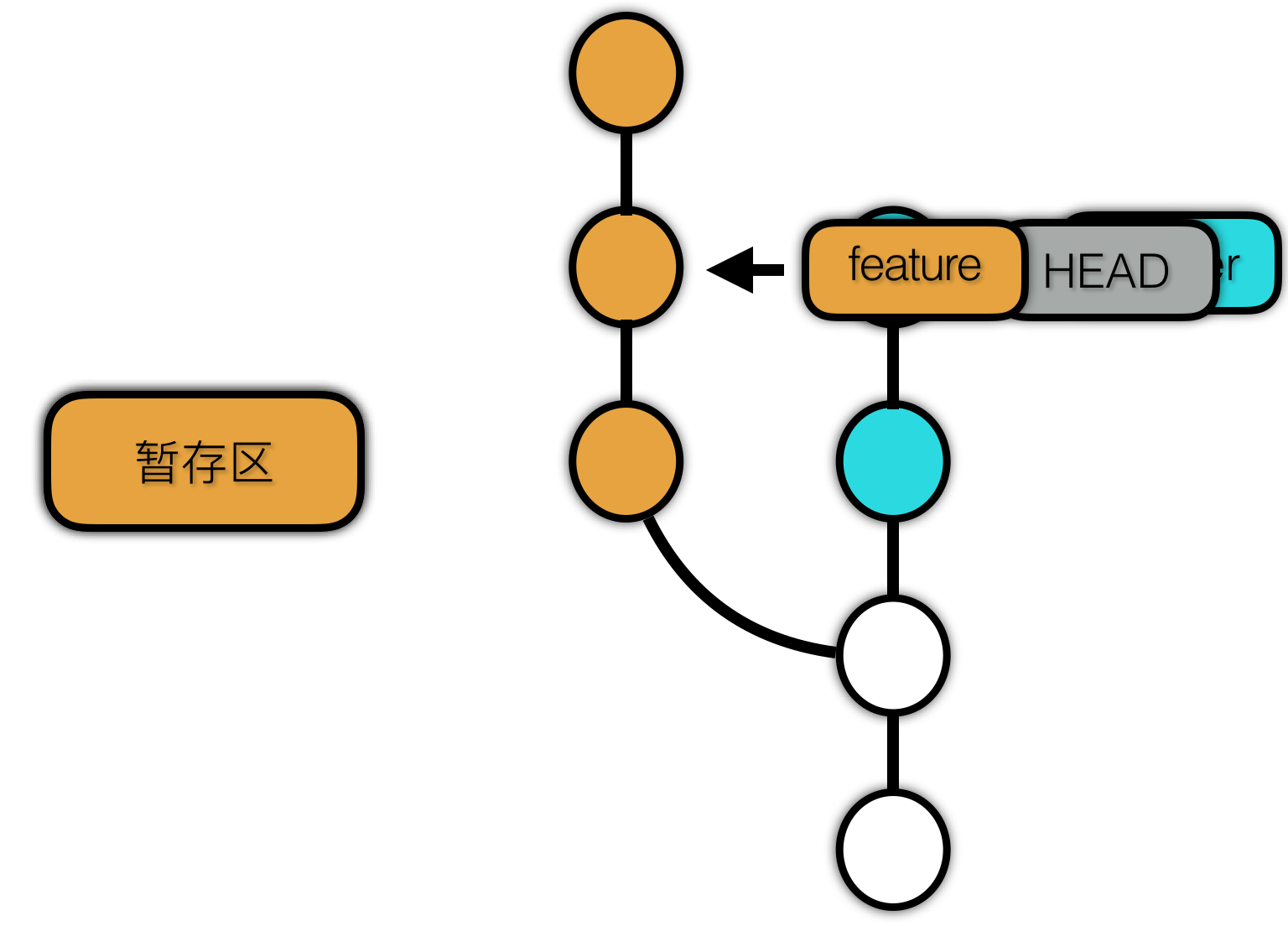
hard 会作用域又比 mixed 多了一个 工作区。
使用 reset --hard 前:
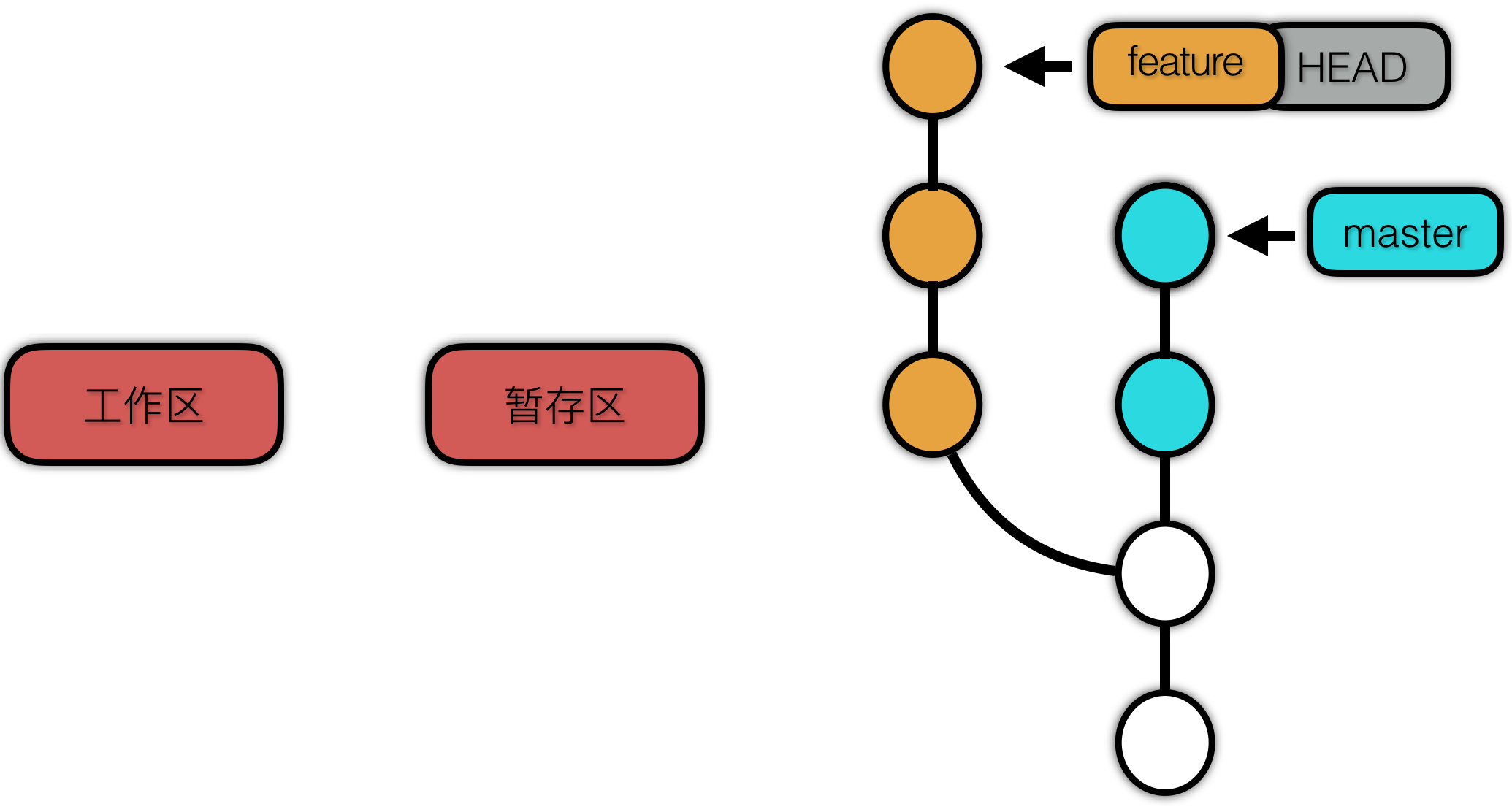
使用 reset --hard 后:
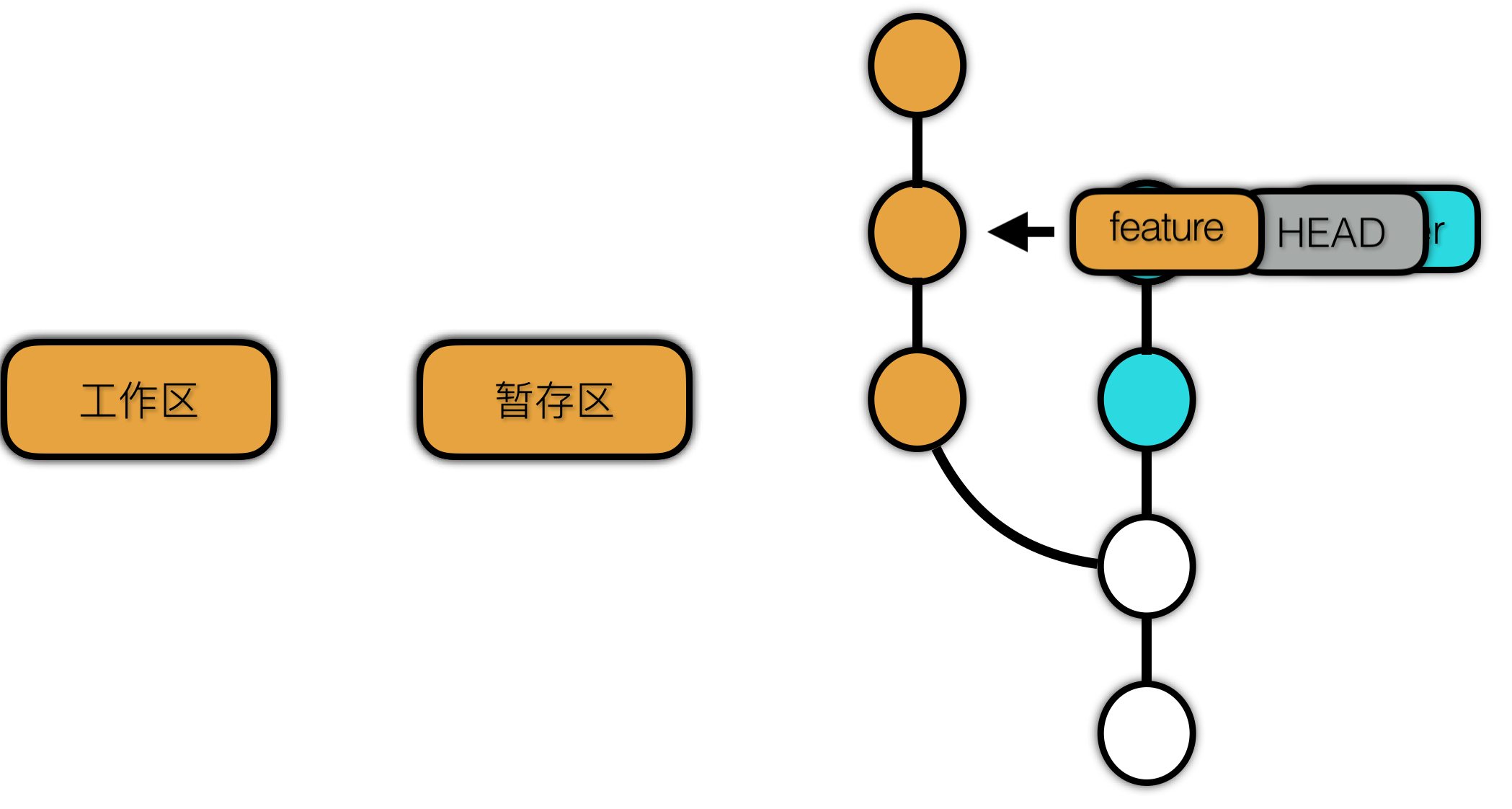
hard 选项会导致工作区内容“丢失”。
在使用 hard 选项时,一定要确保知道自己在做什么,不要在迷糊的时候使用这条选项。如果真的误操作了,也不要慌,因为只要 git 一般不会主动删除本地仓库中的内容,根据你丢失的情况,可以进行找回,比如在丢失后可以使用 git reset --hard ORIG_HEAD 立即恢复,或者使用 reflog 命令查看之前分支的引用。
3.4 stash
有时,我们在一个分支上做了一些工作,修改了很多代码,而这时需要切换到另一个分支干点别的事。但又不想将只做了一半的工作提交。在曾经这样做过,将当前的修改做一次提交,message 填写 half of work,然后切换另一个分支去做工作,完成工作后,切换回来使用 reset ―soft 或者是 commit amend。
git 为了帮我们解决这种需求,提供了 stash 命令。
stash 将工作区与暂存区中的内容做一个提交,保存起来,然后使用reset hard选项恢复工作区与暂存区内容。我们可以随时使用 stash apply 将修改应用回来。
stash 实现思路将我们的修改提交到本地仓库,使用特殊的分支指针(.git/refs/stash)引用该提交,然后在恢复的时候,将该提交恢复即可。我们可以更进一步,看看 stash 做的提交是什么样的结构。
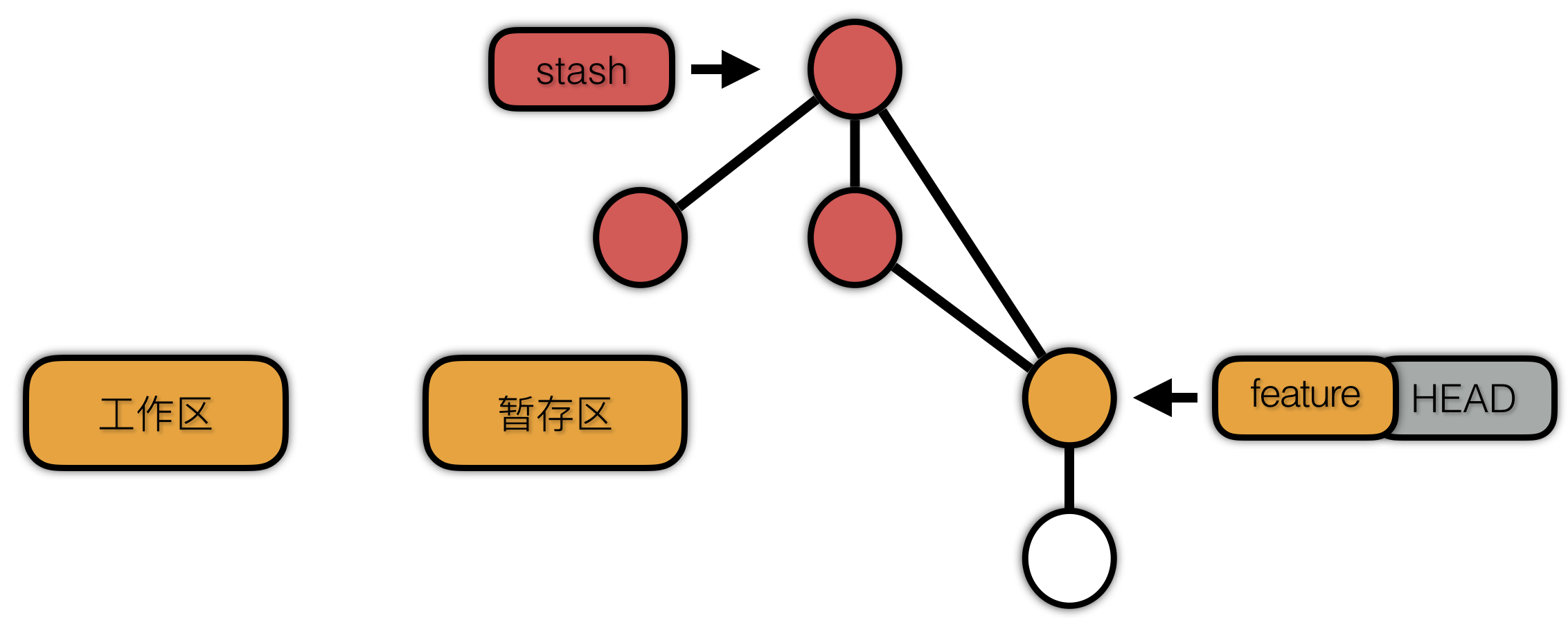
如图所示,如果我们提供了 ―include-untracked 选项,git 会将 untracked 文件做一个提交,但是该提交是一个游离的状态,接着将暂存区的内容做一个提交。最后将工作区的修改做一个提交,并以untracked 的提交、暂存区 的提交、基础提交为父提交。
搞这么复杂,是为了提供更灵活地选项,我们可以选择性的恢复其中的内容。比如恢复 stash 时,可以选择是否重建 index,即与 stash 操作时完全一致的状态。
3.5 bisect
最后要讲到一个曾经把我从“火坑”中救出来的功能。
项目发布到线上的项目出现了bug,而经过排查,却找不到问 bug 的源头。我们还有一种方法,那就是先找到上一次好的版本,从上一次到本次之间的所有提交依次尝试,一一排查。直到找到出现问题的那一次提交,然后分析 bug 原因。
git 为我们想到了这样的场景,同样是刚才的思路,但是使用二分法进行查找。这就是 bisect 命令。
使用该命令很简单,
git bisect start
git bisect bad HEAD
git bisect good v4.1
git 会计算中间的一个提交,然后我们进行测试。
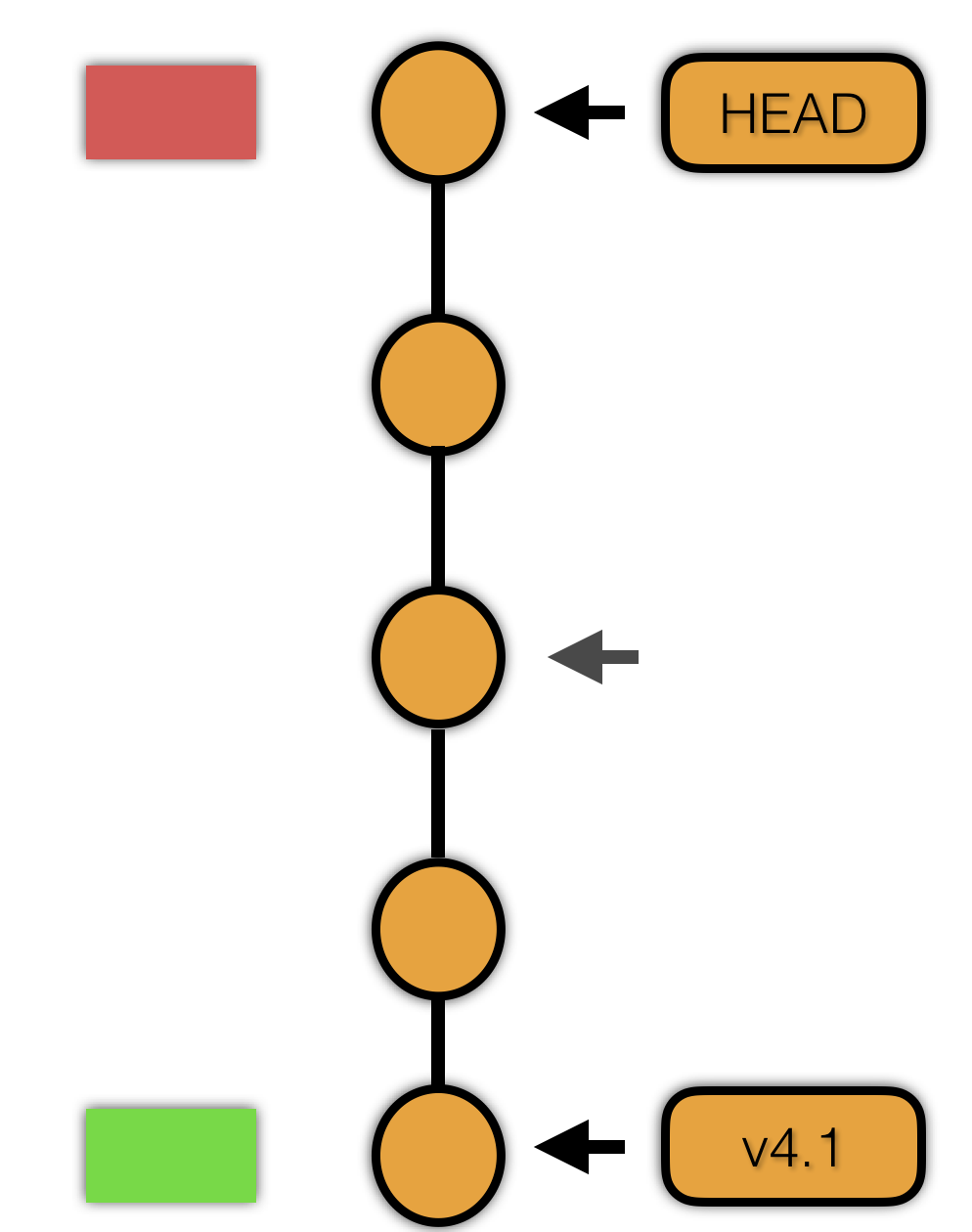
根据测试结果,使用 git bisect good or bad 进行标记,git 会自动切换到下一个提交。不断的重复这个步骤,直到找到最初引入 bug 的那一次提交。
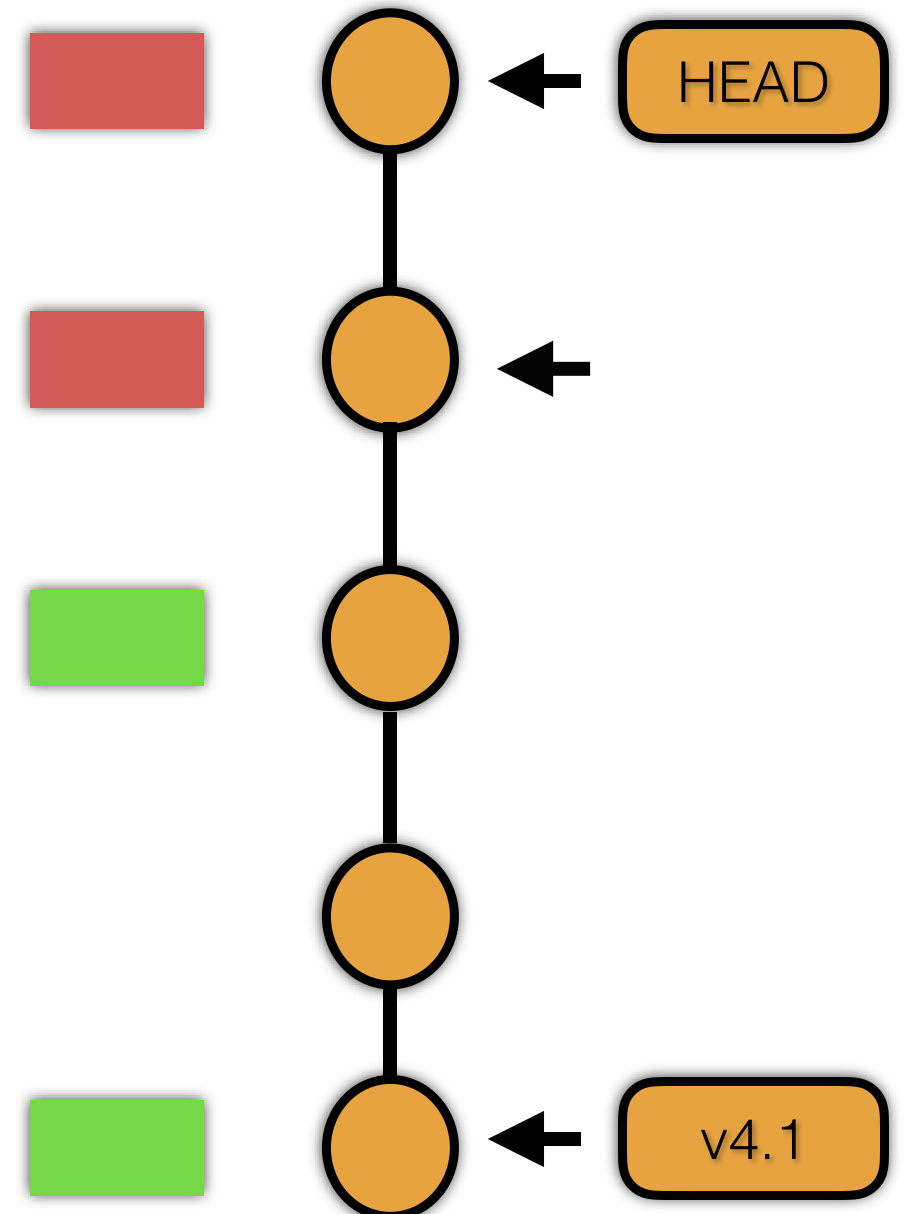
我们知道二分法的效率是很高的,2的10次方就已经1024了,因此我们测试一般最多是10次,再多就是11次、12次。其实这就要求我们优化测试的方法,使得简单的操作就能使 bug 重现。如果重新的操作非常简单,简单到我们可以使用脚本就能测试,那就更轻松了,可以使用 git bisect run ./test.sh,一步到位。
如果某一个提交代码跑不起来,可以使用 git bisect skip 跳过当前提交或者使用 visualize 在 git 给出的列表中手动指定一个提交进行测试。
|






