| 本文不仅仅详细讲述了
IBM InfoSphere DataStage 集群的构建与配置,同时,也以几种典型的应用场景为例,为用户提供了详细而全面的参考价值。并且指导开发人员设计和构建更为高效和可扩展性的
DataStage 数据处理环境。
前言
在开始之前,下面列出了准备以及配置 DataStage 集群环境(在这里以
Linux 环境为例)我们要做的主要步骤,作者可以参考下面的步骤来阅读本文:
1.准备集群环境机器,包括 NAS Server、Domain Server、Engine
Server、Client Server
2.为所有集群节点创建 dsadm 用户、包括主导节点以及普通计算节点
3.在所有集群节点上配置无密码 SSH
4.在前面准备好的机器中安装 Information Server
5.导出、导入 Information Server Engine 的安装目录
6.节点配置及场景应用
IBM InfoSphere DataStage 集群简介
现代集群技术
众所周知,集群计算机的能力可以在 IT 组织架构中最大限度的提高和利用系统资源。现代信息系统的集成解决方案建立在集群技术之上可以大大降低计算能力的成本。
InfoSphere DataStage 集群与 Grid 的区别
InfoSphere DataStage 提供了两种技术来实现一个作业能够并发的运行在不同的计算节点上,第一种是
DataStage 集群,第二种是 DataStage Grid。下面我们来看一下两者的主要区别。首先,DataStage
集群建立在包含多个计算处理节点的网络之上,在这样一个网络结构中,作业的运行资源由配置文件来明确指定,即配置文件中的资源配置信息指明了作业会运行在这些资源上。而在
DataStage Grid 中,采用资源管理器软件 (WLM) 的动态检查和分配资源,使得作业的运行无须依赖手工设置,从而在信息技术中利用最少的资源来获得最大的投资。常用的
WLM 有 Tivoli Workload Scheduler LoadLeveler 和 Platform
LFS 等 . 而无论 DataStage 集群还是 DataStage Grid,都可以使用户可以在一个网络系统中并行运行作业(Job)。如果作者想要了解更多有关
DataStage Grid 配置的信息,可以向 IBM Service 提出咨询。
作业的并行处理及其系统的拓扑结构
为了最大限度的提高 IBM InfoSphere Information
Server 引擎的数据处理效率,用户可以采用作业的并行处理以及系统的集群技术。而在 DataStage
集群网络拓扑中,每个作业的工作负载会在运行时被分配到不同的处理器中进行处理。这些处理器可能位于相同的计算机上,也可能位于由计算机网络连接在一起的不同的计算机上。InfoSphere
Information Server 引擎会使用这些处理器和其它的计算机资源并发的完成这些作业。而这个并行引擎和
InfoSphere Information Server 引擎共同组成了引擎拓扑层。
IBM InfoSphere DataStage 系统集群以引擎节点为主导节点(Conductor
Node),同时由它向集群中的普通节点(Compute Node)发送数据处理指令。以此为特征的 DataStage
集群也极大的提高了数据处理速度和能力。此外,InfoSphere DataStage 还具有高可扩展性,可以非常容易的集成更多的系统节点。
在本文中,我们将重点介绍 IBM InfoSphere DataStage
中提供的用于在分布式网格环境中对数据进行管理和处理的技术。
下图是基于多个物理计算机实体的集群系统拓扑结构,这些处理节点通过网络连接在一起,共同组成了
DataStage 的集群环境。
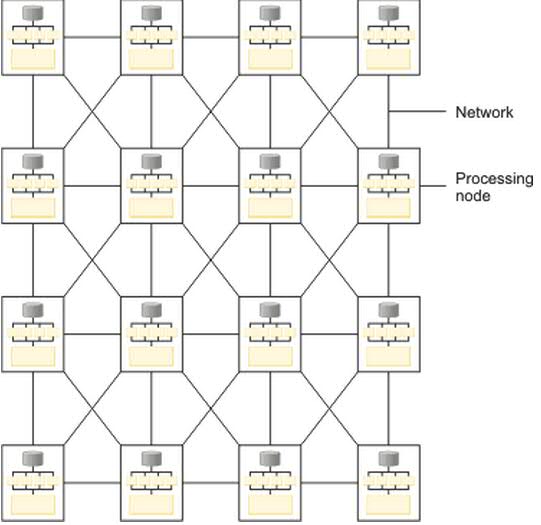
图 1. 基于多个物理计算机实体的集群系统拓扑结构
初始环境准备
在详细介绍如何配置具有多个节点的 DataStage 集群环境之前,有一些必要的初始环境准备工作需要完成。
搭建环境所需要的机器资源
假设我们的集群环境中 InfoSphere? Information Server
的每个层都独立占用一个计算机资源,以在 Linux OS 上搭建一个 DataStage 的集群环境为例子,那么我们至少需要下面的资源:
1.NAS Server:Linux OS,Host Name 假设为
iisperfblade0,用于提供 Information Server 的 Engine 安装目录以导出到主导节点和其它的普通节点中。
2.Domain 层 : Linux OS,Host Name 假设为
iisperfblade_domain,用于安装 Information Server 的 Services
tier( 服务 ) 以及 Metadata repository tier ( 存储数据库 )
3.Engine 层:Linux OS,Host Name 假设为 iisperfblade11,用于安装
Information Server 的 DataStage Server 以及处理引擎
4.Client 层:Windows OS,Host Name 假设为
iisperfblade_client,用于安装 Information Server 的客户端软件
普通节点:Linux OS,普通计算节点的个数要求并没有限制,但是要组成集群至少需要一个普通计算节点。在我们下面的例子中,假设还有另外的三个计算节点,Host
Name 分别为 iisperfblade12,iisperfblade13,和 iisperfblade14。
对于每个机器以及资源的操作系统,由于 Information Server
的 Client 层用于安装 DataStage 的客户端软件,只能安装在 Windows 上面,所以
Client 层必须为 Windows 操作系统。而 DataStage 的集群需要建立在 Linux
环境中,那么 Information Server Domain 层、Engine 层以及所有的普通计算节点都要求为
Linux 操作系统。
为 DataStage 节点资源创建管理员用户
对于每一个 InfoSphere DataStage 引擎都需要一个操作系统用户,一般情况下会使用
dsadm。用户可以选择在安装的过程中创建这个用户,也可以在安装之前手工创建好这个用户,然后在安装过程中选择它。
这个用户会用来做一些管理性的任务,例如:创建新的项目、定义项目属性、编译运行作业等。下面给出了在准备
DataStage 集群环境过程中创建用户的步骤。
1.以 root 用户登录每一个 DataStage 节点(包括主导节点以及其它所有的普通计算节点)。
2.如果用户希望在安装 DataStage Engine 的时候让安装程序自动创建管理员用户,读者可以跳过在主导节点上手工创建的步骤。
3.添加用户组:/usr/sbin/groupadd dstage
4.添加用户:/usr/sbin/useradd -g dstage -d
/home/dsadm dsadm
5.为用户设置密码:/usr/sbin/passwd dsadm
注意:默认情况下,我们一般为 InfoSphere DataStage
创建的用户名是 dsadm,如果是在 AIX 系统上使用自定义用户名称,请不要超过 8 个字符。
无密码的 SSH 服务
IBM InfoSphere DataStage 系统集群中由主导节点(Conductor
Node)向集群中的普通节点(Compute Node)发送数据处理指令,这个过程需要主导节点和普通节点的通信。在
DataStage 系统集群网络中,通过 SSH(Secure Shell)进行通信。
InfoSphere DataStage 集群中主导节点和普通节点的通信是通过无密码的
SSH 服务来完成的。普通计算节点上的用户通过它的共有密钥来进行认证。在主导节点和所有的普通计算节点上进行无密码
SSH 服务的配置方法我们将在下一小节中详细讲述。
DataStage 集群环境构建与配置
本小节接下来的几个部分将以一种典型的网络拓扑结构:单 DataStage
服务器引擎即单集群环境为例,详细讲述 InfoSphere DataStage 集群的构建与配置方法。
InfoSphere Information Server 服务器安装与配置
InfoSphere Information Server 提供了多种用户安装方式,它可以分为单层安装、双层安装、三层安装以及多引擎节点的多层安装等。下图就是一种
Information Server 三层安装方式的总体拓扑结构图。下面我们将使用第二小节中所列出的资源以一个单服务器引擎节点的安装方式为例来介绍
InfoSphere DataStage 集群的构建与配置方法。
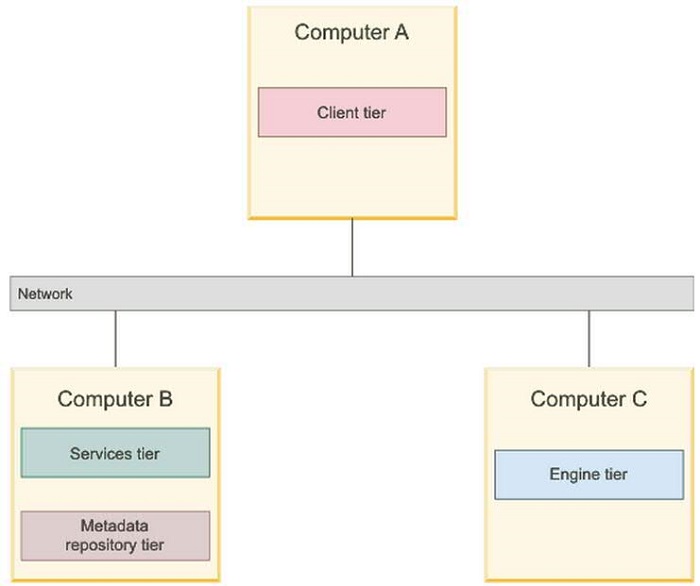
图 2. Information Server
三层安装方式的总体拓扑结构
单服务器引擎
首先,我们介绍最简单的一种 DataStage 集群构建方式,具有单个服务器引擎的网络拓扑来构建我们的集群环境。DataStage
是 InfoSphere Information Server 产品的重要组成部分 . 构建 DataStage
集群首先要安装 InfoSphere Information Server。InfoSphere Information
Server 的安装方式采用三层安装,即客户端软件一个层次,Information Server 服务软件和存储数据库
(XMETA) 一个层次 , 以及 Information Server Engine 一个层次,如下图所示。在
Information Server Engine 这一层,有一个主导节点 (Head Node) 和三个普通计算节点
(Compute Node),其中,由主导节点来与 Information Server 服务层进行通信,同时,由主导节点来与其它的普通节点进行通信
, 及普通节点间的通讯。
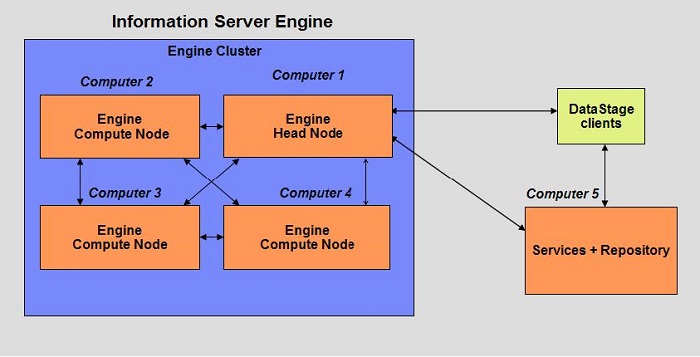
图 3. 具有单服务器引擎的集群环境
多服务器引擎
此处,我们介绍另外一种安装拓扑结构,即有两个服务器引擎即双集群环境的网络拓扑。同样,我们把
Information Server 的总体拓扑结构分为三个层次:一是客户端层,用于安装 Information
Server 的客户端软件。一是 Information Server 引擎层。在这个拓扑中有两个引擎层,在每个引擎层中各有一个引擎实例,因此又两个主导节点。最后一个是
Information Server 的服务及 XMETA 数据库层,用于安装能够提供各种服务的软件系统。同单服务器引擎一样,各引擎由主导节点来与
Information Server 服务层进行通信,同时,在同一引擎内主导节点与其它的普通节点进行通信
, 及普通节点间的通信。下图显示了此网络拓扑的详细架构图。
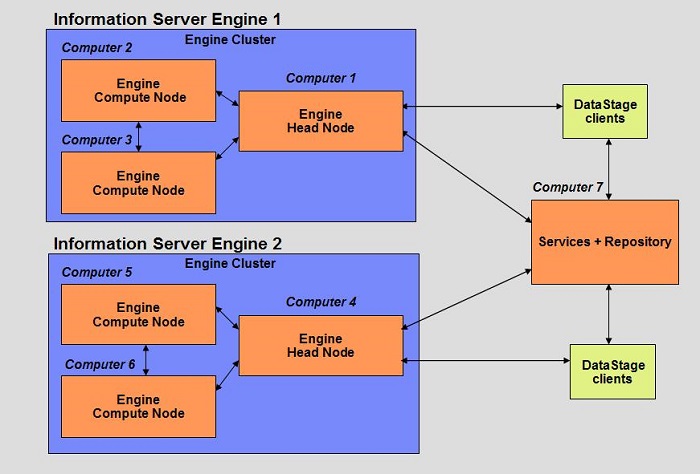
图 4. 具有双服务器引擎的集群环境拓扑图
Secure Shell 服务(SSH)配置
在上一小节中讲述了两种 DataStage 集群架构,同时分别提供了它们的网络拓扑结构。本小节集群配置中,我们按照第二节中提供的计算机资源,以一个
DataStage 集群为例详细讲述其环境配置方式。
根据上述资源,对 Information Server 进行三层安装,对于每个层上的安装步骤都比较典型,在这里不再赘述,作者可以参考
Information Server 信息中心上的安装文档
http://publib.boulder.ibm.com/infocenter/iisinfsv/v8r5/index.jsp
。 在完成上述配置安装完成之后,为了构建一个集群环境,我们需要为这个环境添加新的普通计算节点。而这些节点中的通信是通过
SSH 来完成的,接下来我们来讲述如何在这些节点中配置无密码 SSH 服务。
在开始之前,我们来了解下集群环境中各节点间的 SSH 通信方式及原理。InfoSphere
DataStage 集群中普通计算节点上的用户通过它的共有密钥来进行认证。而这是在每个需要运行作业的计算节点上都必须要进行的一个认证处理过程。
假设 DataStage 主导节点是 iisperfblade11,需要向这个环境中添加一个普通计算节点
iisperfblade14。下面是在主导节点以及普通计算节点上配置无密码的 SSH 的详细方式:
1. 在主导节点上生成本身的共有和私有密钥对(RSA key pair):
清单 1. 在主导节点上生成本身的共有和私有密钥对
[dsadm@iisperfblade11 ~]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/dsadm/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/dsadm/.ssh/id_rsa.
Your public key has been saved in /home/dsadm/.ssh/id_rsa.pub.
The key fingerprint is:
d0:dc:31:0c:76:04:ab:46:c4:01:bd:00:e6:2e:43:92 dsadm@iisperfblade11
[dsadm@iisperfblade11 ~]$ |
2. 在上述命令运行中,系统提示输入密码设置,连续按回车(enter)两次,即设置一个空的密码。上述命令需要以
InfoSphere DataStage 用户(一般情况下是 dsadm)执行,产生的共有和私有密钥对会在
dsadm 用户的 home 目录中的 ~/.ssh/id_rsa 下面。
3. 把主导节点 iisperfblade11 上产生的共有密钥发送给普通计算节点(以
iisperfblade14 为例):
清单 2. 把主导节点 iisperfblade11 上产生的共有密钥发送给普通计算节点
cd /home/dsadm/.ssh/
[dsadm@iisperfblade11 .ssh]$ ssh-copy-id -i dsadm/.ssh/id_rsa.pub dsadm@iisperfblade14
27 The authenticity of host 'iisperfblade14 (192.168.1.12)' can't be established.
RSA key fingerprint is e2:f9:98:cc:a5:2a:19:c5:c9:d4:ec:e6:47:1a:c3:a0.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'iisperfblade14, ' (RSA) to the list of known hosts.
dsadm@iisperfblade11's password:
Now try logging into the machine, with "ssh 'dsadm@iisperfblade11'", and check in:
.ssh/authorized_keys
to make sure we haven't added extra keys that you weren't expecting.
[dsadm@iisperfblade11 ~]$ |
4. 如果上述命令无法正确执行,作者可以登录到普通计算节点 iisperfblade14
上,把这个共有密钥添加到自身的授权密钥列表中,同时修改这个授权文件的权限:
清单 3. 把共有密钥添加到自身的授权密钥列表中
cd .ssh
cat id_rsa.pub >>authorized_keys
chmod 640 authorized_keys
rm -f id_rsa.pub |
5. 结果验证:
现在你可以从 InfoSphere DataStage 的主导节点上可以通过无密码的
SSH 连接到普通计算节点上了。
清单 4. 结果验证
[dsadm@iisperfblade11 .ssh]$ ssh iisperfblade14
Last login: Sun Jun 26 23:03:09 2011 from iisperfblade11.svl.ibm.com
IISPERFBLADE14
Security level of data on this Machine,
Use of this system is subject to audit at any time by management.
Last APAR security update: Sun Aug 8 12:09:08 PDT 2010
[dsadm@iisperfblade14 ~]$ |
结果显示主导节点与普通计算节点通信成功。按照此配置方法,在其它的计算节点
iisperfblade12, iisperfblade13 上也配置上无密码的 SSH。
InfoSphere DataStage 主导节点(Conductor
Node)构建
1. 通过 NFS Server iisperfblade0 导出 NAS
上的共享目录 /install
在这里我们需要把 NAS 上的目录共享给主导节点 iisperfblade11
和普通计算节点 iisperfblade12, iisperfblade13, iisperfblade14。修改
/etc 目录下的 exports 文件,对于每一个节点分别添加一行 :
/install hostname(rw,no_root_squash,async)
rw 允许这些节点对这个共享目录可读可写,no_root_squash
允许 NFS 的客户端可以以 root 用户连接。添加后的文件如下:
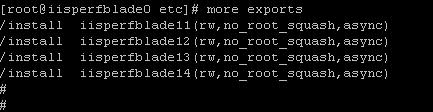
图 5. 添加 DataStage 节点后的
exports 文件
2. 重启 NFS Server 使得导出生效
清单 5. 重启 NFS Server
# /etc/init.d/nfs stop
# /etc/init.d/nfs start
或者
# /etc/init.d/nfs restart |
3. 在 DataStage 节点上导入共享目录
上述操作的目的是把 NAS 上的 /install 目录共享给 DataStage
节点(包括主导节点和普通节点),使它们能够对这一目录可读可写,并且确保 NFS 的客户端可以用 root
用户连接。完成上述配置之后,我们登录到 iisperfblade11 上面,把这个目录导入进来。具体步骤如下:
3.1 以 root 用户登录 iisperfblade11
3.2 修改 /etc 目录下的 fstab 文件,添加下面一行到这个文件:
iisperfiisperfblade0:/install /install
nfs rw,nolock 0 0
添加后的 /etc/fstab 文件如下:
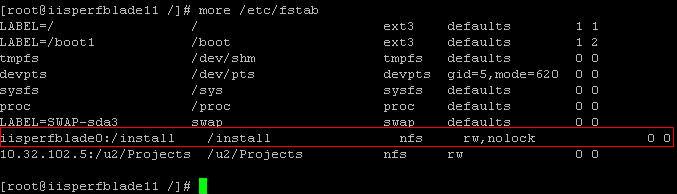
图 6. 添加后的 /etc/fstab
文件
3.3 在 iisperfblade11 根目录下创建 /install
目录
3.4 使用 mount 命令导入 iisperfblade0 上的目录
/insall:mount /install。导入后的文件系统如下:
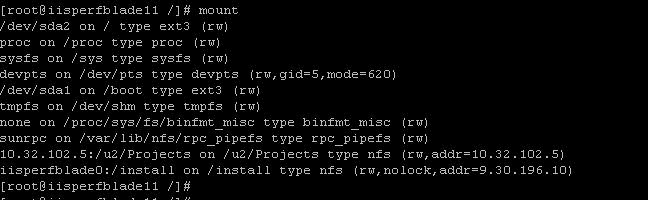
图 7. 导入后的 iisperfblade11
文件系统
4. 在主导节点 blade11 上安装 Information Server
Engine
对于 Information Server Engine 的安装,每个步骤都比较典型,在这里不再赘述,作者可以参考
Information Server 信息中心上的安装文档 http://publib.boulder.ibm.com/infocenter/iisinfsv/v8r5/index.jsp
。 在安装过程中,需要注意的是安装目录要选择已经配置好的 /install 目录。
InfoSphere DataStage 普通节点(Compute
Node)配置
到目前为止,我们已经在主导节点 iisperfblade11 上安装了
Information Server Engine。同时也配置好了主导节点和其它的三个普通节点 iisperfblade12,
iisperfblade13, iisperfblade14 无密码的 SSH 通信。接下来我们需要把
Information Server Engine 的安装目录导出(export)到普通节点上。
具体的导出步骤和主导节点上的做法类似,作者可以参考上一小节中的步骤。
系统构建小节
按照上述方式配置好系统环境后,Datastage 集群环境中的主节点以及普通节点就通过计算机网络连接在一起,并且可以通过无密码
SSH 进行通信。
注意: 如果在 DataStage 的作业中使用到了 Oracle 数据库连接
Stage,那么需要做如下配置:
1.找到 $APT_ORCHHOME/etc 目录
2.把 remsh.example 重命名为 remsh
3.修改 remsh 文件,把 rsh 改为 ssh
4.把 remcp.example 重命名为 remcp
系统负载管理与分配
本小节重点讲述如何在一个集群环境中根据项目的实际运行需要,权衡系统的负载,进行正确的分配以及管理。
DataStage 节点配置文件创建和作用
DataStage 的节点配置文件用来定义普通节点和主导节点用以运行作业的计算机资源,在配置文件中每个节点都有它自己的实体用来定义它的逻辑上的节点名字,一般情况下是它的
hostname,配置文件中叫做 fastname。
在配置文件中包含多个节点块,每个节点块定义了它本身逻辑上节点的名字,机器的
host name,节点 pool 的名字以及存储资源等。下面是一个包含多个节点的配置文件示例:
清单 6. 节点配置文件示例
{
node "CONDUCTOR"
{
fastname "production_conductor_node"
pools "conductor"
resource disk "/u1/Datasets" {pools ""}
resource scratchdisk "/u1/Scratch" {pools ""}
}
node "COMPUTERNODE1"
{
fastname "production_node1"
pools ""
resource disk "/u1/Datasets" {pools ""}
resource scratchdisk "/u1/Scratch" {pools ""}
}
node "COMPUTERNODE2"
{
fastname "production_node2"
pools ""
resource disk "/u1/Datasets" {pools ""}
resource scratchdisk "/u1/Scratch" {pools ""}
}
node "COMPUTERNODE3"
{
fastname "production_node3"
pools ""
resource disk "/u1/Datasets" {pools ""}
resource scratchdisk "/u1/Scratch" {pools ""}
}
} |
node: 节点的逻辑名称,通常情况下根据此节点本身具有的功能来定义。配置文件中不能包含多个相同的节点名字。
Fastname: 机器的 host name
Pools: 定义了这个节点被分配到的节点 pool 的名称,一个节点可以分配到多个节点
pool 中。因此这里的 pools 可以有多个值。如果这个值为空,那么将使用默认 pool,默认 pool
对所有的 stage 都是可用的
resource disk: 定义了这个节点用来存储持久数据的存储资源
resource scratchdisk: 定义了这个节点用来存储临时数据的存储资源
性能优化提示:在上面的示例配置中,每个节点都使用了相同的 scratchdisk
/u1/Scratch,这并不是一个好的实践。出于性能的考虑,一般情况下并不建议这么做,而是针对每一个节点都使用一个本身专用的
resource scratchdisk。
DataStage 配置文件设计与管理
在本小节中我们可以使用 InfoSphere DataStage 客户端和
InfoSphere Administrator 客户端来设计项目配置文件,根据集群环境中的资源情况,为
DataStage 项目定义使用资源。
用户可以根据实际需要为每个项目创建一个配置文件,那么定义之后这个项目中的所有的作业运行时都会选择这个项目的配置文件。下面我们来讲述怎么为项目定义配置文件。
为整个项目定义配置文件步骤如下:
1.使用 InfoSphere DataStage Design 客户端,根据实际需要创建和修改配置文件
2.进入 DataStage Design 客户端选择 Tools 菜单
.
3.选择 Configurations 选项,出现配置窗口,选择新建,如下图所示:
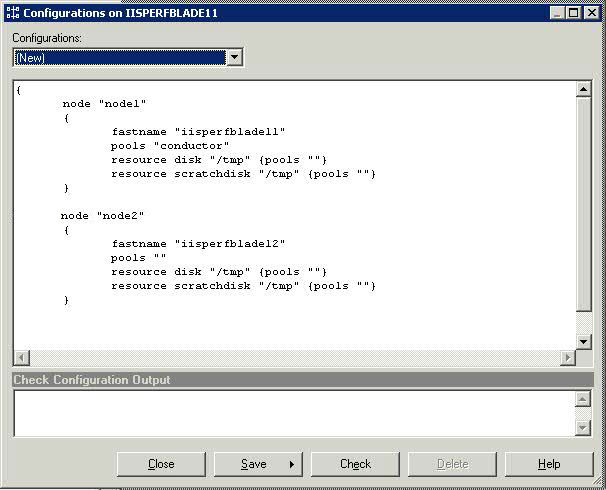
图 8. 新建配置窗口
4.根据实际的计算机资源修改此配置文件
5.修改完成后,点击 Check 以验证这个配置文件,然后点击保存并关闭主配置文件修改窗口
6.然后打开 Administrator 客户端,选择一个你需要管理的项目

图 9. 选择需要管理的项目
7.选择 Properties->Environment->Parallel
8.找到 APT_CONFIG_FILE 参数,输入或者双击选择前面定义好的配置文件
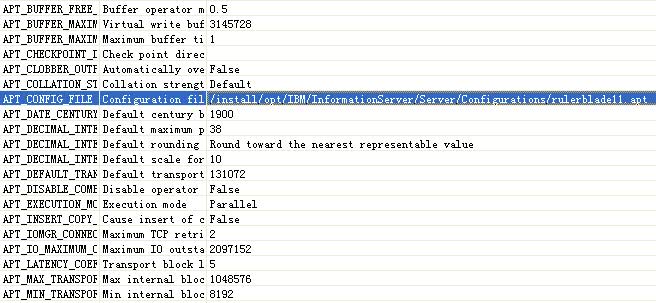
图 10. 输入或者选择前面定义好的配置文件
在完成上述操作之后,这个项目下的所有的作业在运行时都会使用这个配置文件中的资源。此中配置方式的优点是简单方便,但是不能为特殊的作业指定集群中的资源。下面讲述为项目中特定的作业定义配置文件。
为特定作业定义配置文件步骤如下:
1.使用 InfoSphere DataStage Design 客户端,选择进入作业所在的项目
2.选择此作业,然后右击单击属性,然后选择 Parameters->Add
Environment Variables,如下图所示:
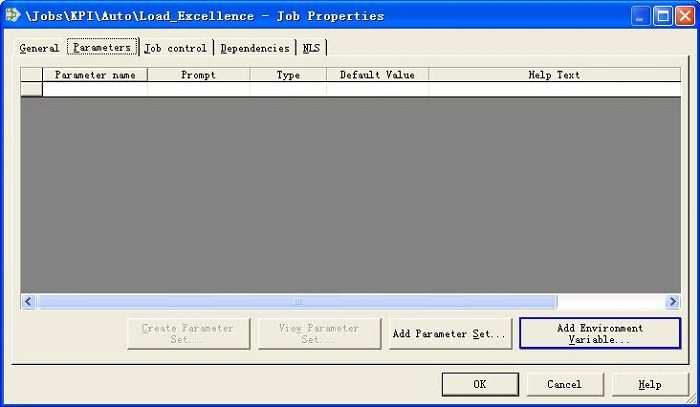
图 11. 选择 Add Environment
Variables
3.选择 Configuration file,如下图所示:
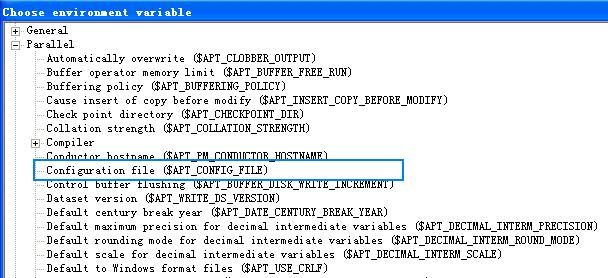
图 12. 选择 Configuration
file
4.选择一个已经定义好的配置文件,如下图所示:
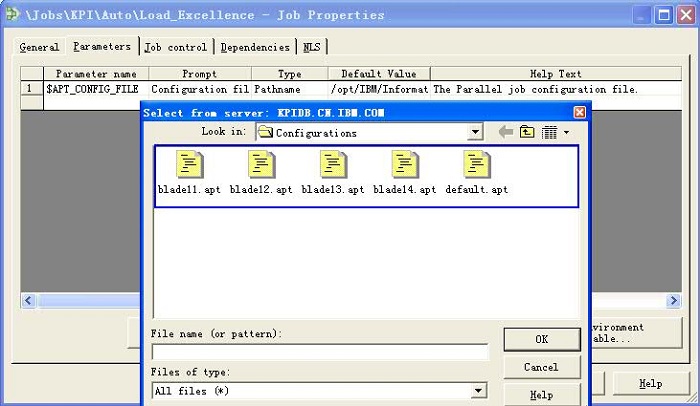
图 13. 选择一个已经定义好的配置文件
在完成上述操作之后,这次作业在运行的时候会选择这个配置文件。
DataStage 节点配置文件分配
到目前为止,我们可以根据集群环境中的资源使用 InfoSphere DataStage
Design 客户端创建配置文件,可以使用 InfoSphere Administrator 客户端为项目指定配置文件,同时还可以使用
DataStage Design 客户端定义特殊作业配置文件。那么下面接下来我们将讲述他们之间的分配关系以及优先级顺序。
集群的配置文件定义了系统中可用的资源,这些资源包括固定的名称,如数据库服务器,SAN
服务器,SAS 服务器,远程存储磁盘服务器。
那么,对于集项目配置文件以及作业配置文件,他们的关系和优先级顺序如下:在一个作业运行的过程中,如果为这个作业定义了作业配置文件,那么
InfoSphere DataStage 引擎会优先选择作业上的配置文件,使用这个配置文件里面的资源运行这个作业。如果没有为这个作业定义作业配置文件,那么
InfoSphere DataStage 引擎会选择作业所在的项目配置文件,使用项目配置文件中的资源运行这个作业,如果没有为作业所在的项目定义配置文件,那么
InfoSphere DataStage 引擎会使用默认的配置文件 default.apt。
DataStage 集群应用实践
在本文第三小节以及第四小节中,详细讲述了 DataStage 集群构建配置和系统负载管理与分配,本节在三、四节的基础上着重论述
DataStage 集群在实际产品环境中的应用。对于集群环境中实际的资源情况和系统运行需求,用户可以修改和指定配置文件,以使得它们能够和实际的系统资源相匹配。然后,以两种典型的应用:侧重处理器(CPU)
或者是系统内存(Memory) 的应用以及侧重硬盘读写(Disk IO) 的应用为例,指导用户根据对性能的需求以及软硬件资源的拥有情况合理选择适合的方法并应用于实际项目中。
首先,假设我们已经有了在前面章节中搭建好的 DataStage 的集群环境,同时设定整个集群环境中主导节点为
iisperfblade11,三个普通的计算节点 iisperfblade12, iisperfblade13,
iisperfblade14。而这些计算节点计算能力和数据处理性能又各不相同,例如有些具有很强的处理器运算速度,有些具有很快的数据读写能力,有些具有很大的系统内存等。
应用场景一:不同项目中的作业运行在不同资源节点中
集群的最大的作用就是分散系统负载到集群中的各个资源上,使得每个节点都承担工作负载。假设我们根据项目需求,需要在绝大多数时间里并发运行一百个作业,由于单个机器的资源有限,例如不具有强大的处理器来并发执行这么多作业。那么我们现在就需要把这些工作负载分配到集群中的所有节点上。
首先,根据集群的四个资源节点创建四个不同的配置文件,以下提供了各个节点配置供作者参考,具体的创建步骤可以参考前面小节中的创建方式。
主导节点 iisperfblade11 配置文件示例如下:
清单 7. 主导节点 iisperfblade11 配置文件示例
{
node "node1"
{
fastname "iisperfblade11"
pools "conductor"
resource disk "/tmp" {pools ""}
resource scratchdisk "/tmp" {pools ""}
}
node "node2"
{
fastname "iisperfblade11"
pools ""
resource disk "/tmp" {pools ""}
resource scratchdisk "/tmp" {pools ""}
}
node "node3"
{
fastname "iisperfblade11"
pools ""
resource disk "/tmp" {pools ""}
resource scratchdisk "/tmp" {pools ""}
}
node "node4"
{
fastname "iisperfblade11"
pools ""
resource disk "/tmp" {pools ""}
resource scratchdisk "/tmp" {pools ""}
}
node "node5"
{
fastname "iisperfblade11"
pools ""
resource disk "/tmp" {pools ""}
resource scratchdisk "/tmp" {pools ""}
}
} |
普通节点 iisperfblade12 配置文件示例如下:
清单 8. 普通节点 iisperfblade12 配置文件示例
{
node "node1"
{
fastname "iisperfblade11"
pools "conductor"
resource disk "/tmp" {pools ""}
resource scratchdisk "/tmp" {pools ""}
}
node "node2"
{
fastname "iisperfblade12"
pools ""
resource disk "/tmp" {pools ""}
resource scratchdisk "/tmp" {pools ""}
}
node "node3"
{
fastname "iisperfblade12"
pools ""
resource disk "/tmp" {pools ""}
resource scratchdisk "/tmp" {pools ""}
}
node "node4"
{
fastname "iisperfblade12"
pools ""
resource disk "/tmp" {pools ""}
resource scratchdisk "/tmp" {pools ""}
}
node "node5"
{
fastname "iisperfblade12"
pools ""
resource disk "/tmp" {pools ""}
resource scratchdisk "/tmp" {pools ""}
}
} |
普通节点 iisperfblade13 和 iisperfblade14
的配置文件与 iisperfblade12 的相似,读者可以参考进行配置。
其次,为不同的项目指定其运行所需要的配置资源,分散工作负载。具体的指定步骤作者可以参考
DataStage 配置文件设计与管理小节中的方法。在这一过程中,我们可以尽量把所有的作业平均分配到集群中所有资源节点上。其中,有一点需要注意:三个普通计算节点的配置文件都需要包含主导节点信息,以让
DataStage 去识别出主导节点。例如,在这里我们包含了一个名称为 conductor 的 node
pool,它的 fastname 为主导节点 iisperfblade11。如果在配置文件中确少了这个主导节点的信息,那么项目中的作业将无法运行。当这一过程完成之后,就实现了不同项目中的作业运行在了集群环境中的不同资源上。
从这里可以看出,这种方式配置比较方便,只需要简单的几个步骤就可以把系统负载分担到不同的集群节点上。但是对于某些特殊的作业需要运行在特定的资源节点上,这中配置方法就无能为力了。下面我们讲述如何配置特定的作业运行到特定的资源节点上的应用。
应用场景二:特定的作业 Stage 运行到特定的资源节点上
如果一个项目的配置文件能够适合这个项目中的绝大多数作业运行,例如这些作业都需要占用很多的系统内存,而配置文件中的资源都具有很大的内存。但对于某些特殊的
Stage 不需要很大的系统内存而仅仅需要很快的 Disk I/O 速度。配置文件中的资源都不具有快速的
Disk I/O 读写能力,那么我们可以按照下面的方式进行配置,以适用这样的特殊的需求。
假设集群中的一个节点 iisperfblade12 具有快速的 Disk
I/O 读写能力,我们可以在配置文件中添加这个节点,配置如下:
清单 9. 配置文件中添加节点 iisperfblade12 示例
{
node "node1"
{
fastname "iisperfblade11"
pools "conductor"
resource disk "/tmp" {pools ""}
resource scratchdisk "/tmp" {pools ""}
}
node "node2"
{
fastname "iisperfblade14"
pools ""
resource disk "/tmp" {pools ""}
resource scratchdisk "/tmp" {pools ""}
}
node "node3"
{
fastname "iisperfblade14"
pools ""
resource disk "/tmp" {pools ""}
resource scratchdisk "/tmp" {pools ""}
}
node "node4"
{
fastname "iisperfblade14"
pools ""
resource disk "/tmp" {pools ""}
resource scratchdisk "/tmp" {pools ""}
}
node "node5"
{
fastname "iisperfblade12"
pools "io"
resource disk "/tmp" {pools ""}
resource scratchdisk "/tmp" {pools ""}
}
} |
在上面的配置中,我们添加了一个新的节点,然后把它的 fastname 定义为具有快速
Disk I/O 读写能力的 iisperfblade12 节点。同时,为了仅仅使作业中的某些特殊的 Stage
使用这个资源,需要为它的 node pools 定义一个名字,在这里定义为“io”,然后为这些特殊的 Stage
显式的指定节点。使用 Designer 客户端打开需要处理的作业,选择作业属性,然后打开 Advantage
页面,选择 Node pool and resource constraint, 同时选择我们在配置文件中配置好的
IO pool,具体方法如下图所示:
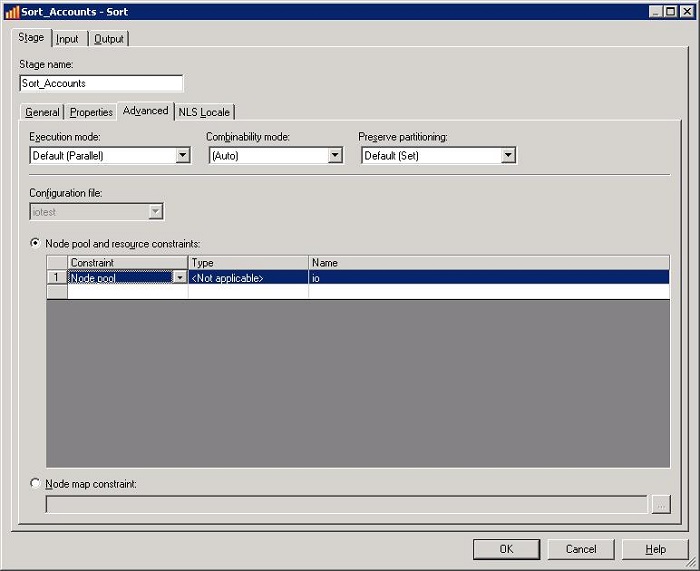
图 14. 为特殊的 Stage 显式指定
node pools
完成上述操作之后,DataStage 就会把这些特殊的 Stage 运行在集群中的这个节点上,同时其它的作业仍然运行在其它的合适的节点资源上。这就使得作业在运行时能选择更适合于它运行的计算机资源,大大的增快了数据处理速度。
Job 负载均衡优化与总结
1. 为了最大可能的提高 DataStage 作业的处理效率,请为每个项目单独的创建一个配置文件,为特殊的作业设置特殊的集群资源。
2. 通常情况下的系统都会有不同的生命周期,如果是在集群环境中,最佳实践是需要把生命周期中的每个阶段,例如开发、测试和生产系统处于不同的物理环境中。基于效率和安全等因素,不要把三者置于同一个物理集群中。
3. 集群的优点就是集群环境中的节点数目越多,就具有越好的系统性能。在
DataStage 集群中,计算节点的数目越多,系统吞吐量就越大即更好的数据处理能力。下图展示了集群环境中节点的数目与系统吞吐量的关系。用户可以根据实际需要来确定集群的节点数目。
注:下图数据仅共读者参考,性能测试所得到的数据一般使用特定的计算机或者组件,任何硬件或者软件设计、配置上的不同都会影响实际所取得的性能数据。读者应该咨询资源中心来评估正在使用的计算机及其组件性能。
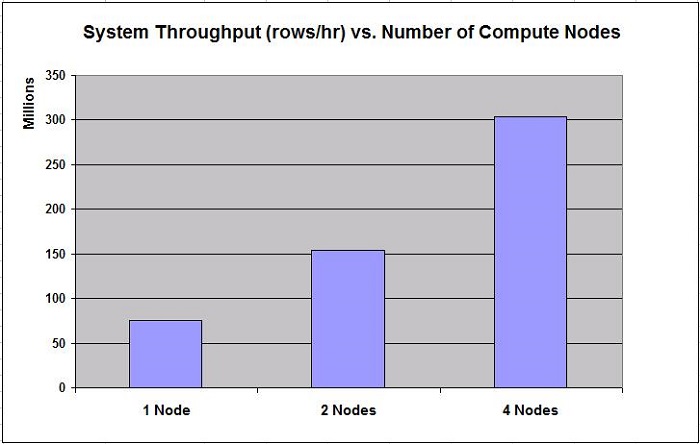
图 15. 集群环境中节点的数目与系统吞吐量的关系
总结
本文不仅详细讲述了 IBM InfoSphere DataStage 集群的构建与配置,同时,也以几种典型的应用场景为例,为用户提供了详细而全面的参考价值。并且指导开发人员设计和构建更为高效和可扩展性的数据处理环境。
|






