| ЯЕСаЮФеТЃК
ЙЙНЈИпадФмASP.NETеОЕу ПЊЦЊ
ЙЙНЈИпадФмASP.NETеОЕужЎвЛ ЦЪЮівГУцЕФДІРэЙ§ГЬЃЈЧАЖЫЃЉ
ЙЙНЈИпадФмASP.NETеОЕужЎЖў гХЛЏHTTPЧыЧѓ(ЧАЖЫ)
ЙЙНЈИпадФмASP.NETеОЕужЎШ§ ЯИНкОіЖЈГЩАм
ЙЙНЈИпадФмASP.NETеОЕу ЕкЮхеТЁЊадФмЕїгХзлЪіЃЈЧАЦЊЃЉ
ДѓаЭИпадФмASP.NETЯЕЭГМмЙЙЩшМЦ
ЙЙНЈИпадФмASP.NETеОЕу ЕкЮхеТЁЊадФмЕїгХзлЪіЃЈжаЦЊЃЉ
ЙЙНЈИпадФмASP.NETеОЕу ЕкЮхеТЁЊадФмЕїгХзлЪіЃЈКѓЦЊЃЉ
ЙЙНЈИпадФмASP.NETеОЕу ЕкСљеТЁЊадФмЦПОБеяЖЯгыГѕВНЕїгХЃЈЩЯЦЊЃЉЁЊЪЖБ№адФмЦПОБ
ЙЙНЈИпадФмASP.NETеОЕу ЕкСљеТЁЊадФмЦПОБеяЖЯгыГѕВНЕїгХЃЈЯТЧАЦЊЃЉЁЊМђЕЅЕФгХЛЏДыЪЉ
ЙЙНЈИпадФмASP.NETеОЕу ЕкСљеТЁЊадФмЦПОБеяЖЯгыГѕВНЕїгХЃЈЯТКѓЦЊЃЉЁЊМѕЩйВЛБивЊЕФЧыЧѓ
ЙЙНЈИпадФмASP.NETеОЕу ЕкЦпеТ ШчКЮНтОіФкДцЕФЮЪЬт(ЧАЦЊ)ЁЊЭаЙмзЪдДгХЛЏЁЊРЌЛјЛиЪеЛњжЦЩюЖШЦЪЮі
ЙЙНЈИпадФмASP.NETеОЕу ЕкЦпеТ ШчКЮНтОіФкДцЕФЮЪЬт(ЧАжаЦЊ)ЁЊЭаЙмзЪдДгХЛЏЁЊМрВтCLRадФм
БОЮФЪЧЯЕСаЮФеТЃЌЕквЛЦЊНщЩмСЫПЊЦЊМАЙЙНЈИпадФмЕФЧАЖЫМАЧАЦЊЁЃ
ЙЙНЈИпадФмASP.NETеОЕу ПЊЦЊ
ЭјеОгХЛЏашвЊПМТЧЕФЗНУц дкгУASP.NETПЊЗЂЭјеОЕФЪБКђ,адФмЪЧгРдЖашвЊПМТЧКЭЙизЂЕФЮЪЬт,адФмВЛНіНіжЛЪЧГЬађДњТыжДааЪБКђЕФЫйЖШЃЌЖјЪЧЩцМАЕНЗНЗНУцУцЕФЖЋЮїЁЃ ОЭФУASP.NETЕФвЛИіЧыЧѓРДНВЃЌДгфЏРРЦїЯђЗўЮёЦїЕФASP.NETЭјеОЗЂЫЭЧыЧѓПЊЪМвЛжБЕНзюКѓећИівГУцГЪЯждкЮвУЧУцЧАЃЌЦфжаЧыЧѓОЙ§ЕФУПвЛИіВНжшЃЌЖМЪЧгаВЛЭЌЕФЕїгХЗНЪНЕФЃЌЖјЧвЕїгУЕФЗНЗЈвВКмЖрЃЌВЛНіНіжЛЪЧГЃМћЕФЃКЛКДцЃЌЖрЯпГЬЃЌвьВНЕШЁЃ БОЯЕСаЕФЮФеТОіЖЈДгСНИіДѓЕФЗНУцРДНВЪіЕїгХЃК ЧАЬЈЕїгХЃКжївЊАќКЌШчКЮОЁСПЕФМѕЩйhttpЧыЧѓЃЌДгhttpЧыЧѓПЊЪМЃЌЕНШчКЮМгдиjs, cssЃЌШчКЮбЙЫѕДЋЪфЕФЪ§ОнЕШЁЃ КѓЬЈЕїгХЃКЗжЮіASP.NETЧыЧѓЕФДІРэЙ§ГЬЃЌВЂдкУПвЛВНИјГіЯргІЕФЕїгХЗНЗЈЃЌЖјЧвдкДњТызщжЏЃЌМмЙЙКЭЪ§ОнПтЕФВйзїЩЯУцИјГіЕїгХЕФЗНЗЈЁЃ МЧЕУдкИеИеПЊЗЂЭјеОЕФЪБКђЃЌвЛЬсЕНЬсИпадФмЃЌзюШнвзвВЪЧзюПьЯыЕНЕФОЭЪЧЛКДцЃЌЖјЧвдкЮЂШэЙйЗНЕФBest PracticeЕФвЛаЉЮФЕЕжавВЪЧНЈвщЃКВуВуЛКДц(дкЪ§ОнДцДЂВуЃЌDAL,BLL,UIЕШЖМвЊЛКДц)ЁЃШЛКѓдкЭјеОжаОЭЁБЛКДцБщЕиПЊЛЈЁБЃЌзюКѓЕФШЗЪЕВЛОЁШЫвтЁЃ СэЭтЕФвЛИіГЃМћЕФгХЛЏеыЖдЪ§ОнПтЕФЃКШчОЁСПМѕЩйзгВщбЏЃЌЪЙгУjoinСЊНгЃЛдкГЃГЃашвЊВщбЏЕФзжЖЮЩЯУцНЈСЂЫїв§ЁЃШЗЪЕЃЌетаЉЪЧКмЭЈгУЃЌвВВЛДэЕФвЛаЉЙцдђЁЃ ЖјЧвЛЙгавЛИіЬхЛсОЭЪЧЃЌдкгХЛЏадФмЕФЪБКђЃЌШчЙћбЁдёгХЛЏДњТыКЭЪ§ОнПтЃЌЭљЭљгХЛЏЪ§ОнПтЕФвЛаЉВйзїДјРДЕФаЇЙћЛсИќМгЕФКУЃЌКмПЩЯЇЕФЪЧЃКдкЯюФПжа(жСЩйдкЮвПЊЗЂЕФвЛаЉЯюФПжа)ЃЌЪ§ОнПтНіНіОЭжЛЪЧвЛИіЪ§ОнЕФДцДЂЩшБИЖјвбЃЌНіДЫЖјвбЃЌУЛгаЗЂЛгГіЪ§ОнПтЕФЧПДѓзїгУЁЃЫљвдЛЙЪЧНЈвщЖдЪ§ОнПтЕФФкВПВщбЏКЭДцДЂЕФЛњжЦвЊЪьЯЄЃЌБЯОЙКмЖрЪБКђПЊЗЂШЫдБвВЕЃШЮСЫDBAЕФЙЄзїЃЈКмЖрЙЋЫОУЛгае§ЪНЕФDBAЃЉЁЃ ЖјЧвдкЯюФПжаЮвУЧЩшМЦЪ§ОнПтЕФЪБКђЃЌЬиБ№ЪЧБэзжЖЮЕФЪБКђЃЌЪЧашвЊгааЉПМТЧЕФЃЌКмЖрШЫНЈвщБэзжЖЮЕФГЄЖШВЛвЊЬЋГЄЃЌетвВЪЧДѓМвГЃМћЕФНЈвщЃЌЕЋЪЧЮЊЪВУДЃПЦфЪЕЃЌетОЭашвЊЖЎЕУвЛаЉЪ§ОнПтЕФФкВПДцДЂЛњжЦСЫЃКдкЪ§ОнПт(SQL
SERVER )БЃДцЕФЪБКђЃЌЪ§ОнЪЧвдЁБвГЁБЮЊзюаЁЕФЕЅЮЛЕФЃЌУПвЛвГга8KЕФДѓаЁЃЌШчЙћФуЕФвЛИіБэжаЕФЪ§ОнГЌЙ§8KЃЌФЧУДетИіБэЕФЪ§ОнОЭвЊЗжМИИівГУцБЃДцЃЌетбљдкЖдЪ§ОнНјааВщбЏЕФЪБКђЃЌОЭвЊПчвГВщбЏСЫЃЌПчвГЪЧашвЊадФмЯћКФЕФЃЌШчЙћЪ§ОнЖМдквЛИівГУцЩЯЃЌФЧУДЫйЖШПЯЖЈПьаЉЁЃ ЫљвдЃЌвЊгХЛЏЭјеОЃЌОЭЕУжЊЕРадФмЯћКФдкФФРяЁЃ ЕБгХЛЏЕФвЛИіЭјеОЕФЪБКђЃЌВЛЪЧУЄФПЕФвЛИХЖјТлЕФЃЌвЛАуРДЫЕгаСНжжЧщПіЃК 1ЃЎ ЭјеОвбОДцдкСЫЃЌВЂЧвдЫааСЫЃЌЯждквЊгХЛЏЁЃ 2ЃЎ е§дкДгЭЗПЊЗЂвЛИіаТЕФЭјеОЁЃ ШчЙћЪЧЕквЛжжЧщПіЃЌФЧУДЪзЯШвЊевГіЭјеОадФмЕФЦПОБЃЌДгЧАЬЈЕФЧыЧѓЕФЕНКѓЬЈЕФЧыЧѓДІРэЃЌвЛжБЕНзюКѓвГУцЕФГЪЯжЃЌЖМвЊвЛВНВНЕФЩѓВщЁЃ ШчЙћЪЧЕкЖўжжЧщПіЃЌПЩФмЧщПіОЭЩдЮЂКУвЛЕуЃЌВЂЧвЭјеОЯждкЭъШЋгЩЮвУЧПижЦЃЌЫљгадкПЊЗЂКЭЩшМЦЕФЙ§ГЬжаОЭПЩвдВЩгУКмЖрЕФгХЛЏддђРДгХЛЏЁЃ гХЛЏВЛвЛЖЈОЭЪЧДњТыжиаДЛђепзіаЉКмДѓЕФИФЖЏЃЌгХЛЏЪБвЛЕуЕуЕФРлЛ§ЕФЃЌОЭКУБШДњТыЕФжиЙЙвЛбљЃЌЖМЪЧвЛИіЛ§РлЕФаЇЙћЁЃБШШчЃЌЪЧдквГУцвЛПЊЪМЕФЪБКђдиШыjsНХБОЃЌЛЙЪЧдкећИівГУцЕФзюКѓдиШыjsНХБОЃЌгаЪБКђЭљЭљОЭжЛЪЧМђЕЅЕФЕїећвЛЯТдиШыЕФЮФМўЃЌЛђепвьВНЕФдиШыНХБОЃЌЛђепЭЈЙ§CDNДЋЪфНХБОЕШЕШЗНЗЈЃЌадФмОЭЬсЩ§СЫЁЃадФмЕФЬсЩ§вВВЛЪЧУЛгаДњМлЕФЃЌгаЕФДњМлКмаЁЃЌР§ШчжЛЪЧАбНХБОЕФдиШыЗХдквГУцзюКѓЃЌДѓЕФДњМлОЭЪЧЃЌР§ШчТђаЉЗўЮёЦїЩшБИЃЌШчContent
Delivery Network(CDN)РДАбОВЬЌЕФЮФМў(js,css,image)ДЋЫЭЕНПЭЛЇЖЫЁЃЫљвдЫЕЃЌгХЛЏашвЊШЈКтВпТдЁЃ
ВЛжЊЕРДѓМвЪЧЗёгаЙ§етбљЕФЬхЛсЃКЕБПДзХздМКПЊЗЂГіРДЕФЯЕЭГадФмКмКУЕФЪБКђЃЌздМКЪЧКмздаХЕФЃЌЯрЗДЃЌШчЙћЯЕЭГКмТ§ЃЌгаЪБецВЛЯыЫЕетИіЯЕЭГЪЧздМКзіЕФЁЃ
ЙЙНЈИпадФмASP.NETеОЕужЎвЛ ЦЪЮівГУцЕФДІРэЙ§ГЬЃЈЧАЖЫЃЉ
вщЬтШчЯТЃК
ЦЪЮівГУцЕФНтЮіЙ§ГЬ
ЗжЮіГіПЩФмДцдкЕФгХЛЏЕу
ЦЪЮівГУцЕФНтЮіЙ§ГЬ
вГУцЕФНтЮіЙ§ГЬЃЌетРяЫЕЕФЙ§ГЬВЛЪЧЮвУЧГЃЫЕЕФASP.NETвГУцЕФЩњУќжмЦкЕФЙ§ГЬЃЌЖјЧвфЏРРЦїЧыЧѓвЛИівГУцЃЌШЛКѓфЏРРЦїГЪЯжвГУцЕФЙ§ГЬЁЃ
дкБОЦЊЕФЮФеТжаЃЌЮвЛсЯШВћЪівГУцЕФНтЮіЙ§ГЬЃЌЯдЪОДгећЬхЩЯВћЪіЃЌШЛКѓдкУПвЛИіЕуЩЯЬсГігХЛЏЕФЗНЗЈЁЃЯШећЬхЃЌКѓОжВПЁЃ
ЕБфЏРРЦїдкЧыЧѓвЛИіWebвГУцЪЧДгURLПЊЪМЕФЁЃЯТУцОЭЪЧЙ§ГЬУшЪіЃК
1ЃЎ ЪфШыURLЕижЗЛђепЕуЛїURLЕФвЛИіСДНг 2ЃЎ фЏРРЦїИљОнURLЕижЗЃЌНсКЯDNSЃЌНтЮіГіURLЖдгІЕФIPЕижЗ 3ЃЎ ЗЂЫЭHTTPЧыЧѓ 4ЃЎ ПЊЪМСЌНгЧыЧѓЕФЗўЮёЦїВЂЧвЧыЧѓЯрЙиЕФФкШнЃЈжСгкЧыЧѓЪБдѕУДБЛДІРэЕФЃЌЮвУЧетРяднЪБВЛЬжТлЃЌжЛЪЧКѓУцЕФЮФеТвЊЬжТлЕФЮЪЬтЃЉ 5ЃЎ фЏРРЦїНтЮіДгЗўЮёЦїЖЫЗЕЛиЕФФкШнЃЌВЂЧвАбвГУцЯдЯжГіРДЃЌЭЌЪБвВМЬајНјааЦфЫћЕФЧыЧѓЁЃ
ЩЯУцЛљБОЩЯОЭЪЧвЛИівГУцБЛЧыЧѓЕНЯжЪЕЕФЙ§ГЬЁЃЯТУцЮвУЧОЭПЊЪМЦЪЮіетИіЙ§ГЬЁЃ
ЕБЪфШыURLжЎКѓЃЌфЏРРЦїОЭвЊжЊЕРетИіURLЖдгІЕФIPЪЧЪВУДЃЌжЛгажЊЕРСЫIPЕижЗЃЌфЏРРЦїВХФмзМБИЕФАбЧыЧѓЗЂЫЭЕНжИЖЈЕФЗўЮёЦїЕФОпЬхIPКЭЖЫПкКХЩЯУцЁЃ
фЏРРЦїЕФDNSНтЮіЦїИКд№АбURLНтЮіЮЊе§ШЗЕФIPЕижЗЁЃетИіНтЮіЕФЙЄзїЪЧвЊЛЈЪБМфЕФЃЌЖјЧветИіНтЮіЕФЪБМфЖЮФкЃЌфЏРРЦїВЛЪЧФмДгЗўЮёЦїФЧРяЯТдиЕНШЮКЮЕФЖЋЮїЕФЁЃЕЋЪЧетИіНтЮіЕФЙ§ГЬЪЧПЩвдгХЛЏЕФЁЃЪдЯыЃЌШчЙћУПДЮфЏРРЦїУПДЮЧыЧѓвЛИіURLЖМашвЊНтЮіЃЌФЧУДУПДЮЕФЧыЧѓЖМгавЛЕуЕФЪБМфЯћКФЃЌПЩФметИіЪБМфЯћКФКмЖЬЃЌЕЋЪЧадФмЕФЬсЩ§ОЭЪЧвЛЕуЕуЕФЁАЕїЁБГіРДЕФЁЃШчЙћАбЖдгІURLКЭIPЕижЗЛКДцЦ№РДЃЌФЧУДЕБдйДЮЧыЧѓЯрЭЌЕФURLЪБЃЌфЏРРЦїОЭВЛгУШЅНтЮіЃЌЖјЪЧжБНгЖСШЁЛКДцЃЌетбљЪЦБиЛсПьвЛЕуЁЃ
ЦфЪЕфЏРРЦїКЭВйзнЯЕЭГЪЧЬсЙЉСЫетбљЕФжЇГжЕФЁЃ
ЕБЛёЕУСЫIPЕижЗжЎКѓЃЌФЧУДфЏРРЦїОЭЯђЗўЮёЦїЗЂЫЭHTTPЕФЧыЧѓЃЌЯТУцЮвУЧОЭЩдЮЂПДЯТетИіЗЂЫЭЧыЧѓЪЧдѕУДбљБЛЗЂЫЭЕФЃК
1ЃЎ фЏРРЦїЭЈЙ§ЗЂЫЭвЛИіTCPЕФАќЃЌвЊЧѓЗўЮёЦїДђПЊСЌНг 2ЃЎ ЗўЮёЦївВЭЈЙ§ЗЂЫЭвЛИіАќРДгІД№ПЭЛЇЖЫЕФфЏРРЦїЃЌИцЫпфЏРРЦїСЌНгПЊСЫЁЃ 3ЃЎ фЏРРЦїЗЂЫЭвЛИіHTTPЕФGETЧыЧѓЃЌетИіЧыЧѓАќКЌСЫКмЖрЕФЖЋЮїСЫЃЌР§ШчЮвУЧГЃМћЕФcookieКЭЦфЫћЕФheadЭЗаХЯЂЁЃ
етбљЃЌвЛИіЧыЧѓОЭЫуЪЧЗЂЙ§ШЅСЫЁЃ
ЧыЧѓЗЂЫЭШЅжЎКѓЃЌжЎКѓОЭЪЧЗўЮёЦїЕФЪТЧщСЫЃЌЗўЮёЦїЖЫЕФГЬађЃЌР§ШчЃЌфЏРРЦїЧхГўЕФЮФМўЪЧвЛИіASP.NETЕФвГУцЃЌФЧУДЗўЮёЦїЖЫОЭАбЧыЧѓЭЈЙ§IISНЛИјASP.NET
дЫааЪБЃЌзюКѓНјаавЛЯЕСаЕФЛюЖЏжЎКѓЃЌАбзюКѓЕФНсЙћЃЌЕБШЛЃЌвЛАуЪЧвдЪЧвдhtmlЕФаЮЪНЗЂЫЭЕНПЭЛЇЖЫЁЃ
ЦфЪЕЪзЯШЕНДяфЏРРЦїЕФОЭЪЧhtmlЕФФЧаЉЮФЕЕЃЌЫљЮНЕФhtmlЕФЮФЕЕЃЌОЭЪЧДПДтЕФhtmlДњТыЃЌВЛАќКЌЪВУДЭМЦЌЃЌНХБОЃЌcssЕШЕФЁЃвВОЭЪЧвГУцЕФhtmlНсЙЙЁЃвђЮЊДЫЪБЗЕЛиЕФжЛЪЧвГУцЕФhtmlНсЙЙЁЃетИіhtmlЮФЕЕЕФЗЂЫЭЕНфЏРРЦїЕФЪБМфЪЧКмЖЬЕФЃЌвЛАуЪЧеМећИіЯьгІЪБМфЕФ10%зѓгвЁЃ
етбљжЎКѓЃЌФЧУДвГУцЕФЛљБОЕФЙЧМмОЭдкфЏРРЦїжаСЫЃЌЯТвЛВНОЭЪЧфЏРРЦїНтЮівГУцЕФЙ§ГЬЃЌвВОЭЪЧвЛВНВНДгЩЯЕНЯТЕФНтЮіhtmlЕФЙЧМмСЫЁЃ
ШчЙћДЫЪБдкhtmlЮФЕЕжаЃЌгіЕНСЫimgБъЧЉЃЌФЧУДфЏРРЦїОЭЛсЗЂЫЭHTTPЧыЧѓЕНетИіimgЯьгІЕФURLЕижЗШЅЛёШЁЭМЦЌЃЌШЛКѓГЪЯжГіРДЁЃШчЙћдкhtmlЮФЕЕжагаКмЖрЕФЭМЦЌЃЌflashЃЌФЧУДфЏРРЦїОЭЛсвЛИіИіЕФЧыЧѓЃЌШЛКѓГЪЯжЁЃ
ЕНетРяЃЌДѓМввВаэИаОѕЕНетжжЗНЪНгаЕуТ§СЫЁЃШЗЪЕетИіЭМЦЌЕШзЪдДЮФМўЕФЧыЧѓЕФВПЗжвВЪЧПЩвдгХЛЏЕФЁЃднВЛЫЕБ№ЕФЃЌШчЙћУПИіЭМЦЌЖМвЊЧыЧѓЃЌФЧУДОЭвЊНјаажЎЧАЫЕЕФФЧаЉВНжшЃКНтЮіurlЃЌДђПЊtcpСЌНгЕШЕШЁЃПЊСЌНгвВЪЧвЊЯћКФзЪдДЕФЃЌОЭЯёЮвУЧдкНјааЪ§ОнПтЗУЮЪвЛбљЃЌЮвУЧвВЪЧОЁПЩФмЕФЩйПЊЪ§ОнПтСЌНгЃЌЖргУСЌНгГижаЕФСЌНгЁЃЕРРэвЛбљЃЌtcpСЌНгвВЪЧПЩвджигУЕФЁЃЕЋЪЧжигУвВгаЮЪЬтЃКШчЙћСНИіЭМЦЌЫќУЧЕФurlЕижЗШчЯТЃК
| <img src="q1.gif"
height="16" width="16" />
<img src="q2.gif" height="16"
width="16" />
<img src="q3.gif" height="16"
width="16" />
<img src="q4.gif" height="16"
width="16" />
<img src="q5.gif" height="16"
width="16" />
<img src="q6.gif" height="16"
width="16" />
<img src="q7.gif" height="16"
width="16" />
<img src="q8.gif" height="16"
width="16" />
<img src="q9.gif" height="16"
width="16" />
<img src="q10.gif" height="16"
width="16" /> |
ЧыЧѓетаЉЭМЦЌЕФЪБМфЯћКФШчЯТЭМЃК

ДѓМвЪзЯШПДЕНзюЩЯУцЕФЛЦЯпЕФВПЗжЃЌетИіЛЦЯпОЭДњБэСЫфЏРРЦїДђПЊСЌНгЃЌЛЦЯпЕФКѓАыВПЗжЮЊРЖЩЋЃЌОЭБэЪОфЏРРЦїЧыЧѓЕНСЫhtmlЕФЮФЕЕЁЃ
зюЩЯУцЕФЕкЖўЬѕРЖЯпОЭБэЪОЕквЛИіЭМЦЌвбОЧыЧѓЕНСЫЃЌДЫЪБЧыЧѓетИіЭМЦЌЪЙгУЛЙЪЧжЎЧАЕФвЛИіtcpЕФСЌНгЁЃ
ДѓМвдкПДЕНЕкШ§ЬѕЯпЃЌЧАВПЗжЪЧЛЦЩЋЕФЃЌБэЪОЧыЧѓЕкЖўИіЭМЦЌЕФЪБКђгжПЊСЫвЛИіtcpЕФСЌНгЃЌетЬѕЯпЕФКѓАыВПЗжЮЊРЖЩЋЃЌБэЪОЭМЦЌвбОЧыЧѓЕНСЫЁЃ
ЪЃЯТЕФвЊЧыЧѓЕФвЛаЉЭМЦЌЖМЪЙгУЩЯвЛИіtcpСЌНгЁЃ
ШЗЪЕЃЌtcpЕФСЌНгЪБГфЗжЕФБЛЪЙгУСЫЃЌЕЋЪЧЭМЦЌЯТдиЕФЫйЖШШЗЪЕТ§СЫЃЌДгЭМжаПДГіЃЌЭМЦЌЪЧвЛИіИіЕФЫГађЕФЯТдиЯТРДЕФЁЃећИівГУцЕФЯьгІЪБМфПЩЯыЖјжЊЁЃ
ШчЙћВЩгУЯТвЛжжЗНЪНЃЌШчЃК
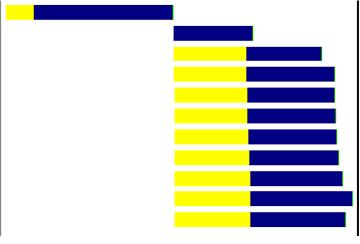
ПЩвдПДГіСЌНгЪБЖрСЫЃЌЕЋЪЧЭМЦЌЕФМИКѕЖМЪЧВЂааЯТдиЯТРДЕФЃЌЯрБШЖјбдОЭПьЖрСЫЁЃ
ЦфЪЕетОЭЪЧвЛИіШЈКтЕФЮЪЬтСЫЁЃ
ЪЕМЪЩЯфЏРРЦївВЪЧФкжУСЫвдвЛаЉгХЛЏЗНЪНЕФЃЌР§ШчЛКДцЭМЦЌЃЌНХБОЕШЁЃЛђепВЩгУВЂааЯТдиЭМЦЌЕФЗНЪНЃЌЬИЕНВЂааЯТдиЃЌОЭШчЩЯЭМЫљПДЕНЕФЃЌЪЦБиЛсЯћКФИќЖрЕФСЌНгзЪдДЁЃ
НёЬьжївЊЖдвГУцЕФЙ§ГЬНјааСЫГѕВНЕФЦЪЮіЃЌЪЧЕФДѓМвгаИізмЬхЕФАбЮеЃЌЯТвЛЦЊЮвУЧОЭПЊЪМж№ВНгХЛЏЃЌОДЧыЙизЂЃЌвВЯЃЭћДѓМвЖрЖрЬсГівтМћКЭЗДРЁЁЃЯШаЛЙ§СЫАЁЃЁ
ЃКЃЉ
ЙЙНЈИпадФмASP.NETеОЕужЎЖў гХЛЏHTTPЧыЧѓ(ЧАЖЫ)
HTTPЧыЧѓЕФгХЛЏ
дквЛИіЭјвГЕФЧыЧѓЙ§ГЬжа,ЦфЪЕећИівГУцЕФhtmlНсЙЙ(ОЭЪЧвГУцЕФФЧаЉhtmlЙЧМм)ЧыЧѓЕФЪБМфЪЧКмЖЬЕФ,вЛАуЪЧеМећИівГУцЕФЧыЧѓЪБМфЕФ10%-20%.дквГУцМгдиЕФЦфгрЕФЪБМфЪЕМЪЩЯОЭЪЧдкМгдивГУцжаЕФФЧаЉflash,ЭМЦЌ,НХБОЕФзЪдД.
вЛжБЕНЫљгаЕФзЪдДдиШыжЎКѓ,ећИівГУцВХФмЭъећЕФеЙЯждкЮвУЧУцЧА.
ЯТУц,ЮвУЧОЭДгвЛИівГУцПЊЪМНВЪі:
| <!DOCTYPE
html PUBLIC " -//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> 2 <html xmlns="http://www.w3.org/1999/xhtml"> 3 <head> 4 <title>аЁбѓ,брбѓЬь</title> 5 6 <script type="text/javascript"
src="../demo.js"> 7 </script> 8 9 </head> 10 <body> 11 <div> 12 <img src="../images/1.gif" /> 13 <img src="../images/2.gif" /> 14 <img src="http://yanyangtian.cnblogs.com/image/3.gif"
/> 15 <img src="http://yanyangtian.cnblogs.com/image/4.gif"
/> 16 <img src="http://yanyangtian.cnblogs.com/image/5.gif"
/> 17 <img src="http://yanyangtian.cnblogs.com/image/6.gif"
/> 18 <img src="http://yanyangtian.cnblogs.com/image/7.gif"
/> 19 <img src="http://yanyangtian.cnblogs.com/image/8.gif"
/> 20 <img src="http://yanyangtian.cnblogs.com/image/7.gif"
/> 21 <img src="http://yanyangtian.cnblogs.com/image/8.gif"
/> 22 </div> 23 </body> 24 </html> |
ШчЙћЮвУЧЯђЗўЮёЦїЧыЧѓетИівГУц,ПЭЛЇЖЫЕФфЏРРЦїЪзЯШЧыЧѓЕНЕФЪ§ОнОЭЪЧhtmlЙЧМм,МД:
| <!DOCTYPE
html PUBLIC " -//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> 2 <html xmlns="http://www.w3.org/1999/xhtml"> 3 <head> 4 <title>аЁбѓ,брбѓЬь</title> 5 6 <script type="text/javascript"
src="../demo.js"> 7 </script> 8 9 </head> 10 <body> 11 <div> 12 <img src="../images/1.gif" /> 13 <img src="../images/2.gif" /> 14 <img src="http://yanyangtian.cnblogs.com/image/3.gif"
/> 15 <img src="http://yanyangtian.cnblogs.com/image/4.gif"
/> 16 <img src="http://yanyangtian.cnblogs.com/image/5.gif"
/> 17 <img src="http://yanyangtian.cnblogs.com/image/6.gif"
/> 18 <img src="http://yanyangtian.cnblogs.com/image/7.gif"
/> 19 <img src="http://yanyangtian.cnblogs.com/image/8.gif"
/> 20 <img src="http://yanyangtian.cnblogs.com/image/7.gif"
/> 21 <img src="http://yanyangtian.cnblogs.com/image/8.gif"
/> 22 </div> 23 </body> 24 </html> |
дкДЫжЎЧА,ЪзЯШРДЦеМАвЛЯТвГУцМгдиЕФаЁжЊЪЖ:
ЕБвГУцЕФhtmlЙЧМмдиШыСЫжЎКѓ,фЏРРЦїОЭПЊЪМНтЮівГУцжаБъЧЉ,ДгЩЯЕНЯТПЊЪМНтЮі.
ЪзЯШЪЧheadБъЧЉЕФНтЮі,ШчЙћЗЂЯждкheadжагавЊв§гУЕФjsНХБО,ФЧУДфЏРРЦїДЫЪБОЭПЊЪМЧыЧѓНХБО,ДЫЪБећИівГУцЕФНтЮіЙ§ГЬОЭЭЃСЫЯТРД,вЛжБЕНjsЧыЧѓЭъБЯ.
жЎКѓвГУцНгзХЯђЯТНтЮі,ШчНтЮіbodyБъЧЉ,ШчЙћдкbodyжагаimgБъЧЉ,ФЧУДфЏРРЦїОЭЛсЧыЧѓimgЕФsrcЖдгІЕФзЪдД,ШчЙћгаЖрИіimgБъЧЉ,ФЧУДфЏРРЦїОЭвЛИіИіЕФНтЮі,НтЮіВЛЛсЯёjsФЧбљЕШД§ЕФ,ШчЙћЗЂЯжimgЕФurlЕижЗЪЧЭЌвЛИіЕижЗ,ФЧУДфЏРРЦїОЭЛсГфЗжЕФРћгУетИівбОДђПЊЕФtcpСЌНгЫГађЕФШЅвЛИіИіЕФЧыЧѓЭМЦЌ,ШчЙћЗЂЯжгаЕФimgЕФurlЕижЗВЛЭЌ,ФЧУДфЏРРЦїОЭСэПЊtcpСЌНг,ЗЂЫЭhttpЧыЧѓ.
зЂвтжЎЧАЧыЧѓjsЕФЧјБ№:ЧыЧѓашвЊjs,фЏРРЦїЛсвЛжБЕШД§,ВЛдкНтЮіЯТУцЕФhtmlБъЧЉ
ЕЋЪЧНтЮіЕНimgЕФЪБКђ,ОЁЙмДЫЪБашвЊМгдиЭМЦЌ,ЕЋЪЧвГУцЕФНтЮіЙ§ГЬЛЙЪЧЛсМЬајЯТШЅЕФ,ШЛКѓОіЖЈЪЧЗёЗЂЫЭаТЕФtcpСЌНгМгдизЪдД.
ДѓМвПЩФмОѕЕУетИіжЎЧАЕФДњТыЦЌЖЮвЛбљ,ШЗЪЕДњТыЪЧвЛбљЕФ,ЕЋЪЧ,дкзюПЊЪМЕФЪБКђ,ЗЂЫЭЕНфЏРРЦїжаЕФжЛЪЧФЧаЉhtmlЕФДњТы,ШЮКЮЕФjsНХБОКЭЭМЦЌЛЙУЛгаЗЂЫЭЙ§РД.
ЕБhtmlДњТыЕНСЫфЏРРЦїжа,ФЧУДфЏРРЦїОЭПЊЪМвЛВНВНЕФНтЮіетаЉДњТыСЫ,жЛвЊгіЕНСЫашвЊМгдиЕФзЪдД,фЏРРЦїОЭЯђЗўЮёЦїЗЂГіhttpЧыЧѓ,ЧыЧѓЫљашЕФзЪдД.
ећИівГУцЕФМгдиЪБМфЭМШчЯТ:

ДѓМвДгЭМжаПЩвдПДГі:
ЕквЛЬѕЯпжаЗжЮЊвЛАыЛЦЩЋКЭвЛАыРЖЩЋ,ЦфЪЕЛЦЩЋЕФВПЗжОЭДњБэСЫДђПЊвЛИіtcpСЌНгЛЈЕФЪБМф,ЖјКѓУцЕФРЖЩЋЕФВПЗжОЭЪЧЧыЧѓећИіhtmlЙЧМмЮФЕЕЕФЪБМф.ПЩвдПДГі,ЧыЧѓhtmlЙЧМмЕФЪБМфЪЧКмЖЬЕФ.ЦфгрРЖЩЋЕФЯпОЭБэЪОСЫЭМЦЌ,НХБОзЪдДМгдиЫљЛЈЕФЪБМф.
КмЯдШЛ,етбљвГУцЕФећИіМгдиЪБМфОЭКмГЄСЫ.вђЮЊвГУцЕФМгдиМИКѕЪЧЫГађЕФдиШы,ЪБМфОЭЪЧЫљгазЪдДМгдиЪБМфЕФзмКЭ.
ЯТУцЮвУЧАбЩЯУцЕФвГУцДњТыДњЮЊШчЯТ:
| <!DOCTYPE
html PUBLIC " -//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <title>аЁбѓ,брбѓЬь</title>
<script type="text/javascript"
src="../demo.js"> </script>
</head> <body> <div> <img src="http://demo1.com/images/1.gif"
/> <img src="http://demo1.com/images/2.gif"
/> <img src="http://demo2.com/image/3.gif"
/> <img src="http://demo2.com/image/4.gif"
/> <img src="http://demo3.com/image/5.gif"
/> <img src="http://demo3/image/6.gif"
/> <img src="http://demo4.com/image/7.gif"
/> <img src="http://demo4.com/image/8.gif"
/> <img src="http://yanyangtian.cnblogs.com/image/7.gif"
/> <img src="http://yanyangtian.cnblogs.com/image/8.gif"
/> </div> </body> </html> |
ЮвУЧдйРДПДПДвГУцЕФМгдиЪБМфЭМ
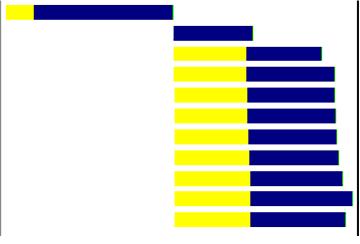
етОЭЪЧЫљЮНЕФЁБВЂааЁБдиШыСЫ.
БШНЯвЛЯТСНЖЮДњТыЕФВЛЭЌ:ЦфЪЕОЭдкimgЕФsrcЪєадЩЯУц:
ЕквЛЖЮвГУцЕФДњТы:imgЕФsrcЪєадЖМЪЧжИЯђвЛИігђУћЕФ.
ЕкЖўЖЮвГУцЕФДњТы:imgЕФsrcЪєаджИЯђСЫВЛЭЌЕФгђУћ
етбљзіЕФНсЙћЪЧЪВУД?
ЧыДѓМвзЂвтБШНЯimgЕФsrcЕФВЛЭЌ.
НтЪЭжЎЧА,ЪзЯШРДПДвЛИіаЁЕФГЃЪЖ(дкЩЯЦЊЮФеТжавВЬсЙ§):
ЕБвГУцЧыЧѓЯђЗўЮёЦїЧыЧѓзЪдДЕФЪБКђ,ШчЙћфЏРРЦївбОдкПЭЛЇЖЫКЭЗўЮёЦїжЎЧАДђПЊСЫвЛИіtcpСЌНг,ЖјЧвЧыЧѓЕФзЪдДвВдкПЊСЫСЌНгЕФЗўЮёЦїЩЯ,ФЧУДвдКѓзЪдДЕФЧыЧѓОЭЛсГфЗжЕФРћгУетИіСЌНгШЅЛёШЁзЪдД.
етбљвВОЭЪЧЕквЛИіЪБМфЭМЕФгЩРД.
ШчЙћЧыЧѓЕФЭМЦЌЗжБ№ЮЛгкВЛЭЌЕФЗўЮёЦїЭјеО,ЛђепФЧИіЧыЧѓЕФЗўЮёЦїЭјеОгаЖрИігђУћ,ФЧУДвђЮЊфЏРРЦїОЭЛсЮЊУПвЛИігђУћШЅПЊвЛИіtcpСЌНг,ЗЂЫЭhttpЧыЧѓ,етбљ,НсЙћОЭЪЧЭЌЪБПЊСЫЖрtcpСЌНг,етвВЪЧЕкЖўИіЪБМфЭМЕФгЩРД.
ЫфШЛЫЕВЂааМгди,ШЗЪЕЪЙЕУвГУцЕФдиШыПьСЫВЛЩй,ЕЋЪЧвВВЛЪЧУПвЛИіЭМЦЌЛђепЦфЫћЕФзЪдДЖМШЅИувЛИіВЛЭЌЕФгђУћ,ЯёжЎЧАЕФЕкЖўИіВЂаадиШыЭМЦЌЕФР§зг,вВЪЧШУСНИіЭМЦЌРћгУвЛИіtcpСЌНг.ШчЙћУПИіЭМЦЌЖМШЅПЊвЛИіСЌНг,етбљфЏРРЦїОЭПЊСЫКмЖрИіСЌНг,вВЪЧКмЗбзЪдДЕФ,ЖјЧвфЏРРЦїЛЙПЩФмЛсЁБНЉЫРЁБ.ЖјЧвгаЪБЛЙЛсбЯжиЕФгАЯьадФм.
Ыљвд,етЪЧашвЊШЈКтЕФ.
Г§СЫЩЯУцЕФгХЛЏЗНЪН,ЛЙгаЦфЫћЕФЭМЦЌгХЛЏЕФМгдиЗНЪН.жївЊЪЧЭЈЙ§МѕЩйhttpЕФЧыЧѓДяЕНгХЛЏ
ДѓМвЖМжЊЕРЭјеОЕФвЛИіmenuВЫЕЅ,гааЉВЫЕЅОЭЪЧгУЭМЦЌзїГіРДЕФ.Шч

ШчЙћЩЯУцЕФЭМЦЌвЛИіИідиШы,ЪЦБигАЯьЫйЖШ,ШчЙћПЊЖрКЭЧыЧѓ,гаЕуЕУВЛГЅЪЇ.ЖјЧвЭМЦЌвВВЛЪЧКмДѓ,ФЧУДОЭвЛДЮАбећИіmenuашвЊЕФЭМЦЌзїЮЊећИіЭМЦЌ,вЛДЮМгди,ШЛКѓЭЈЙ§mapЕФЗНЪН,ПижЦЕуЛїЭМЦЌЕФЮЛжУРДДяЕНЕМКНЕФаЇЙћ.
етбљвЛИіЮЪЬтОЭЪЧ:ЫуГіЭМЦЌЕФзјБъ,ВЛФмЕуЛїСЫЁБжївГЁБЭМЦЌ,ШЛКѓШДЬјЕНСЫЁБАяжњЁБвГУцСЫ.
ЙЙНЈИпадФмASP.NETеОЕужЎШ§ ЯИНкОіЖЈГЩАм
БОЦЊЕФвщЬтШчЯТЃК
ЮЪЬтЕФУшЪі
ЯИНкЕФживЊад
ЮЪЬтЕФУшЪі
ЪзЯШЃЌУшЪівЛЯТЙЪЪТЕФБГОАЃКЃЈЯЃЭћДѓМвФЭаФЕФЙЪЪТЖСЭъЃЉ
дкЭјеОжаЃЌЭјвГжаЕФЗжвГПиМўУПДЮЯдЪО10ЬѕЪ§ОнЃЌУПДЮЕуЛїЯТвЛвГЃЌОЭдйДЮШЅШЁЯТвЛИі10ЬѕЪ§ОнЁЃжСгкЗжвГЕФЗНЗЈдѕбљзіЃЌЗНЗЈгаКмЖрЃЌЯраХетЕуДѓМвЖМжЊЕРЁЃ
Й§ГЬЪЧетбљЕФЃКдкгУЛЇЧыЧѓЪ§ОнЕФЪБКђЃЈПМТЧЕНСЫгУЛЇЕФВйзїКЭЭјеОЕФЗУЮЪСПЃЉЮвЛсЕквЛДЮШЁГі500ЬѕЪ§ОнЃЌШЛКѓАбЪ§ОнЗХдкЛКДцжаЃЌвВОЭЪЧЫЕЃЌЮвШЁГіСЫ50вГЕФЪ§ОнЃЌЗХдкЛКДцжаЃЌетбљШчЙћЃЌвдКѓгУЛЇЧыЧѓЕквЛвГЕНЕк49вГЕФЪБКђЃЌОЭжБНгДгЛКДцжаФУЪ§ОнЁЃ
ШчЯТЭМЃК

ЕквЛИіЪ§ОнПщЃК
ВЩгУМќжЕЖдЕФаЮЪНЃКзжЕфБЃДц
ШчЙћгУЛЇЧыЧѓЕНСЫ49вГвдКѓЃЌФЧУДОЭдйДЮДгЪ§ОнПтжаШЁГіЯТвЛИіЪ§ОнПщЃЈАќКЌ501ЕН1000Ъ§ОнЃЉЃЌШЛКѓЃЌЯждкФкДцжаОЭгаСЫ1000ЬѕЪ§ОнЁЃ
жСгкЛКДцЖрОУЃЌЪ§ОнЪВУДЪЇаЇЃЌЪЇаЇКѓдѕУДзіЃЌетРяднВЛЬИТлЁЃЃЈЭјеОдкетжжЛКДцВпТдЯТдЫааЕФКмКУЃЉЁЃ
ДњТыШчЯТЃК
| List<Product>
products = GetDataFromCacheOrDatabase (condition,pageIndex,countЁ.); |
ДњТыЕФвтЫМКмЧхГўЃЌДгЛКДцжаФУЪ§ОнЃЌШчЙћЛКДцжаУЛгаЖдгІЕФЪ§ОнЃЌФЧУДОЭЯШДгЪ§ОнПтжаФУ500ЬѕЪ§ОнЃЌШЛКѓЗХдкЛКДцжаЃЌзюКѓЗЕЛи10ЬѕЪ§ОнЁЃ
КѓРДЃЌвђЮЊФГаЉЙІФмЕФашвЊЃЌашвЊЗЕЛиЕБЧАвГЕФЧА6вГЪ§ОнКЭКѓ6вГЕФЪ§ОнЃЌР§ШчЃКШчЙћЕБЧАвГЪЧЕк12вГЃЌФЧУДОЭвЊЗЕЛи12вГжЎЧА6вГProductЃЈвВОЭЪЧЕк6,7,8,9,10,11вГЕФЪ§ОнЃЉЃЌКЭЕк12вГКѓЕФвГЕФProductЃЈЕк13,14,15,16,17,18вГЕФЪ§ОнЃЉЁЃ
ШчЯТЃК

ЕБШЛЃЌШчЙћЕБЧАвГЪЧЕк5вГЃЌФЧУДОЭАбжЎЧАЫљга5вГЕФЪ§ОнЖМЗЕЛиЃЌСэЭтдйМгЩЯЕк5вГжЎКѓЕФ6вГЪ§ОнЁЃ
етРяОЭПЩФмЩцМАЕНПчПщЛёШЁЪ§ОнЃЌШчЃК
ШчЙћЕБЧАвГЪЧЕк48вГЕФЪБКђЃЌФЧУДЗЕЛиЧА6вГЪ§ОнЪЧУЛгаЪВУДЮЪЬтЕФЃЌФЧУДКѓ6вГЕФЪ§ОнОЭВЛзуСЫЃЌвђЮЊ49,40вВЕУЪ§ОнПЩвдДгЛКДцЕФЪ§ОнПщжаШЁЕНЃЌжСгк51,52,53,54вГЕФЪ§ОнЃЌОЭашвЊдйДЮДгЪ§ОнПтжаЖСШЁЃЌШЛКѓдйДЮЛКДцЃЈШчЙћЪТЯШУЛгаБЛЛКДцЃЉЁЃ

зюКѓдкЛКДцжаЕФЪ§ОнШчЯТЃК

ШЛКѓЕїгУЗНЗЈЃКЃЈЮБТыЃЉ
| List<Product>
products = GetDataFromCacheOrDatabase (condition,42,
126Ё.); |
ЩЯУцДЋШыЕФЪЧДгЕк42вГПЊЪМЕФЪ§ОнЃЌвВОЭЪЧЕк48вГЕФЧА6вГКЭКѓ6вГЕФЪ§ОнЁЃ
етИіЗНЗЈЕФФкВПЪЕЯжЪЧетбљЕФЃК
1ЃЎ ЪзЯШДгЕквЛИіЪ§ОнПщжаШЁГі42вГЕН50вГЕФЪ§Он ШЁГіЪ§ОнКѓБЃДцдквЛИіList<Product> firstProductList; 2ЃЎ ДгЕкЖўИіЪ§ОнПщжаШЁГіДг51вГЕН54вГЃЈШчЙћЕкЖўИіЪ§ОнПщдкЛКДцВЛДцдкЃЌОЭШЅЪ§ОнПтжаШЁ501-1000ЬѕЃЌШЛКѓдйЗХдкЛКДцЕФЕкЖўИіЪ§ОнПщжаЃЉЁЃ БЃДцдкЕкЖўИіList<Product> secondProductList 3. ШЛКѓАбСНИіlistКЯВЂЃЌЗЕЛиНсЙћЁЃР§Шч
secondProductList.Foreach(u=>firstProductList.Add(u));
ЛљБОЕФЪЕЯжОЭЪЧетбљЃЌПДЦ№РДЛЙааЃЌвВБШНЯЕФКЯРэЃЌЕЋЪЧОЭЪЧвђЮЊетИіВйзїЃЌДгЖјЕМжТЗўЮёЦїФкДцвчГіЁЃ
ДѓМвЯыЯыПДЪЧЪВУДдвђЁЃ
ЯИНкЕФживЊад
ЦфЪЕЛКДцЕФЪ§ОнВЛЪЧКмЖрЃЌЪЧВЛзувдШУЗўЮёЦїФкДцвчГіЕФЃЌЕЋЪЧЗўЮёЦїЛЙЪЧГіЯжСЫout of memoryЕФвьГЃЁЃжЎЧАвЛжБХмЕФКмКУЃЌОЭЪЧИФСЫДњТыжЎКѓВХГіЯжЮЪЬтЕФЁЃ
ЦфЪЕетОЭЪЧгЩгквЛИізюЛљБОЕФДэЮѓВњЩњЕФЃКв§гУРраЭЁЃ
ЯТУцОЭРДЗжЮіЯТЃК
ЪзЯШЪЧДгЕквЛИіЪ§ОнПщжаШЁГіЪ§ОнЃЌШЛКѓгУ
List<Product> firstProductList в§гУжИЯђШЁГіЕФЪ§Он
ШЛКѓДгЕкЖўИіЪ§ОнПщжаШЁГіЪ§ОнЃЌгУ
List<Product> secondProductListжИЯђЪ§ОнЕФв§гУ
ШчЯТЭМ
дкЕкШ§ВНжаВЩгУ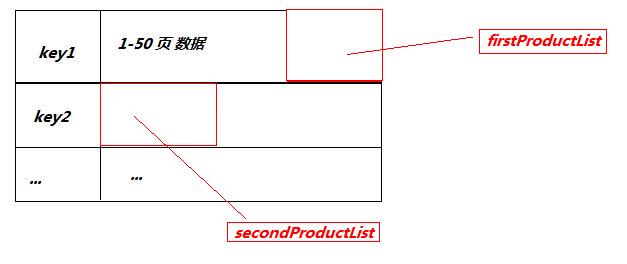
secondProductList.Foreach(u=>firstProductList.Add(u));
АбsecondProductListжаЕФЪ§ОнМгШыЕНfirstProductListжаЃЌОЭвђЮЊЪЧв§гУРраЭЃЌЦфЪЕЪЕМЪВйзїЕФНсЙћЪЧЃКВЛЖЯЕФдкИФБфЕквЛИіЪ§ОнПщжаЕФЪ§ОнЃЌЪЙЕУЕквЛИіЪ§ОнПщжаЕФЪ§Онж№НЅЕФБфЖрЁЃ
ЯждкЕБЧАвГЪЧ48вГЃЌВЩгУЩЯУцЕФВйзїЃЌжТЪЙЕквЛИіЪ§ОнПщжаЕФЪ§ОндіМгСЫ60ЬѕЃЌ
ШчЙћгУЛЇдйДЮЗвГЃЌЕНСЫ49вГЃЌФЧУДЕквЛИіЪ§ОнПщжаЕФЪ§ОнгждіЖрСЫ60Ьѕ
вРДЫРрЭЦЃЌзюКѓЕМжТСЫЗўЮёЦїФкДцЕФВЛзуЃЌжТЪЙЗўЮёЦїБРРЃСЫЁЃдБОЕФЁАЙІГМЁБ----ЛКДцШДГЩЮЊСЫзяП§ЛіЪзЁЃ
ЦфЪЕетИіЮЪЬтЕФНтОіЃЌжЛвЊИФБфвЛЕуЕуЕФДњТыОЭааСЫЃК
List<Product> firstProductListЃЛ
List<Product> secondProductListЃЛ
ШЛКѓ
List<Product> resultProductList=new List<Product>ЃЈЃЉЃЛШЛКѓЗжБ№АбfirstProductListЃЌsecondProductListБщРњЃЌМгШыЕНresultProductListОЭааСЫЁЃ
ОЭетУДМђЕЅЁЃ
вЛИіаЁЕФЯИНкЃЌЕМжТСЫДѓЕФЮЪЬтЁЃ
ВЛвЊКіЪгУПвЛИіЯИНкЁЃВЛвЊзіУЛгаБШНЯЕФбЛЗЕШВйзїЃЌвЛЖЈвЊЩѓЪгДњТыЃЌжиЙЙДњТыЁЃ
ЙЙНЈИпадФмASP.NETеОЕу ЕкЮхеТЁЊадФмЕїгХзлЪіЃЈЧАЦЊЃЉ
БОеТЕФвщЬтШчЯТЃК
адФмЕїгХЕФвЛАуЙ§ГЬ
РћгУЗжЮіЙЄОпЗжЮівГУцМгдиаХЯЂ
РћгУЗжЮіЙЄОпЗжЮіадФмЦПОБ
адФмЕїгХЕФвЛАуЙ§ГЬ
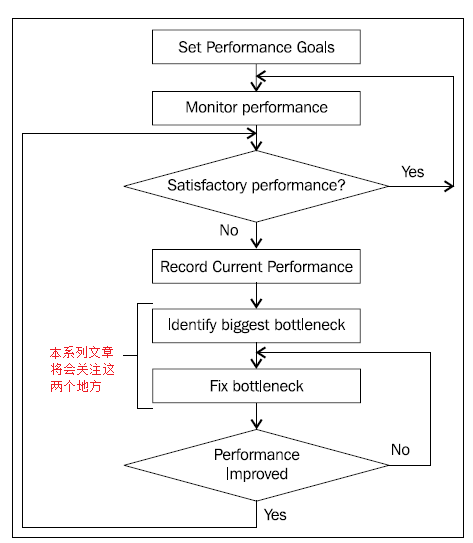
дкНтОіадФмЮЪЬтжЎЧАЪзЯШвЊШЗШЯЮЪЬтЕФЫљдкЃЌЪзЯШОЭРДПДПДШЗБЃИпадФмЕФвЛАуЙ§ГЬЃК
1. ГжајМрПи 2. ЩшЖЈадФмФПБъ 3. ГжајИФНј
1ЃЎ ГжајМрПи ЭјеОЕФадФмзмЬхРДЫЕЪмСНИіЗНУцЕФгАЯьЃК вЛЃЌЮвУЧПЩвдПижЦЕФЃЌР§ШчДњТыЃЛ ЖўЃЌЮвУЧВЛФмПижЦЕФЃЌР§ШчЗУЮЪгУЛЇЕФЪ§СПЃЌЛђепЗўЮёЦїБОЩэ ЬиБ№ЪЧЫцзХеОЕуЕФЗУЮЪСПдіДѓЕФЪБКђЃЌдРДУЛгаГіЯжЕФЮЪЬтЃЌЯждкПЩФмГіРДСЫЃЌВЛЭЌЕФНзЖЮвЊНтОіЕФЮЪЬтвВЪЧВЛвЛбљЕФЁЃЫљвдКмгаБивЊЖдЭјеОНјааГжајЕФМрПиЃЌ
ГУдчЗЂЯжЭјеОБфТ§ЕФдвђЁЃБОЦЊЕФКѓУцВПУХЛсНщЩмвЛаЉЮвУЧПЩвдЪЙгУЕФМрПиЗўЮёЃЌРДАяжњЮвУЧзіетаЉЪТЧщЁЃ
2ЃЎ ЩшЖЈадФмФПБъ ЭјеОЕФадФмШчКЮЃЌвЛИізюжБЙлЕФИаЪмОЭЪЧЃКДђПЊетИіеОЕужЎКѓЃЌвГУцМгдиЕФЪБМфЃЌетвВЪЧЫЕЪЧЗУЮЪепзюжБНгЕФЬхбщЁЃКмЖрЕФгХЛЏЙЄзїЃЈВЛЙмЪЧЧАЬЈЕФгХЛЏЛЙЪЧКѓЬЈЕФгХЛЏЃЉЖМЪЧЮЊСЫШУгУЛЇИќПьЕФПДЕНЫљЯыПДЕФвГУцКЭаХЯЂЁЃЮвУЧКѓУцЕФЬжТлКмЖрЪБКђЖМЪЧвдетИіЮЊФПБъЕФЁЃ
ЪзЯШБиаывЊУїАзЁАПьЁБЕФКЌвхЃКвЛИіЭјеОЕФЯьгІЫйЖШЖрПьВХЫуЪЧЁАПьЁБЃПвђЮЊгХЛЏЭјеОашвЊЛЈЗбКмДѓЕФЪБМфКЭОЋСІЃЌШчЙћЭјеОБОЩэвбОКмПьСЫЃЌР§ШчЭјвГГЪЯжЕНгУЛЇблЧАЕФЪБМфЪЧКСУыМЖБ№ЕФЃЌЮвУЧШЗЪЕПЩвддйЛЈЪБМфШУЫќИќПьЃЌЕЋЪЧетбљзіЦ№РДГЩБОЛсИќИп!
3ЃЎГжајИФНј
дкНјааадФмгХЛЏЕФЪБКђЃЌвЊЩцМАЕНКмЖрЕФЖЋЮїЃЌЫљвддкНјаагХЛЏЕФЪБКђБиаыШЗШЯЃКНјааЕФгХЛЏДыЪЉШЗЪЕЕФЬсИпСЫеОЕуЕФадФмЁЃЮЊСЫДяЕНетИіФПЕФЃЌгаМИИіЙцдђПЩвдзёбЃК
1. УПДЮгХЛЏжЛИФЖЏвЛДІЁЃШчЙћИФЖЏСЫКмЖрДІЃЌФЧУДетаЉИФЖЏжЎМфПЩФмЯрЛЅЕФгАЯьЃЌзюКѓВњЩњвЛаЉЦцЦцЙжЙжЕФЯжЯѓЃЌгаЪБКђетаЉ"гХЛЏДыЪЉ"ЗДЖјЪЙЕУЭјеОадФмНЕЕЭЁЃЖјЧвШчЙћвЛДЮИФЖЏЖрДЮЃЌвВВЛРћгкКтСПФЧаЉ"гХЛЏДыЪЉ"ецеце§е§ЬсЩ§СЫЭјеОЕФадФмЁЃ
2. ВЛЖЯЕФВтЪдЁЃУПДЮНјааСЫЫљЮНЕФ"гХЛЏ"жЎКѓЃЌвЛЖЈвЊВтЪдвЛЯТЃЌетИі"гХЛЏ"ЪЧЗёецЕФЬсЩ§СЫадФмЃЌШчЙћУЛгаЬсЩ§ЃЌФЧУДОЭЛиЙіетИіВйзїЁЃ
вЛАуНјаагХЛЏЕФВНжшШчЯТЃК
1. МЧТМЯждкЭјеОЕФадФмжИЪ§КЭвЛаЉЯрЙиЕФЪ§Он(КѓУцЛсИцЫпДѓМвШчКЮЛёШЁетаЉадФмжИЪ§Ъ§Он)
2. еяЖЯеОЕуЕФадФмЙЪеЯЕу.ПЩФмгаМИИіЕиЗНЖМгАЯьСЫеОЕуЕФадФмЃЌЕЋЪЧЃЌДЫЪБЮвУЧжЛЪЧбЁдёгАЯьзюДѓЕФФЧИівђЪ§НјаагХЛЏЁЃ
3. НтОіевГіЕФадФмЙЪеЯЕуЁЃ
4. ВтЪдЁЃЪеМЏЪ§ОнЃЌКЭгХЛЏЧАНјааБШНЯЃЌПДПДЪЧЗёЬсЩ§СЫадФмЁЃ
5. жиИД1ЕН4ВНжшЁЃ
ЩЯУцЫфШЛЬсГіСЫвЛаЉЙцдђЃЌЕЋЪЧЮвУЧПЩвдСщЛюДІРэФГаЉЧщПіЃКдкЮвУЧВщевгАЯьадФмЕФЮЪЬтЕФЪБКђЃЌЮвУЧЗЂЯжЖрИіЮЪЬтЃЌЖјЧветаЉЮЪЬтИљОнЮвУЧЕФОбщХаЖЯЛсгАЯьадФмЃЌФЧУДЮвУЧПЩвдЭЌЪБаоИФДЫДІЁЃ
ЮвУЧгУвЛИіСїГЬЭМРДзмНсЩЯУцЕФгХЛЏВНжшЁЃШчЯТЃК
ЮДЭъД§ај......
|









