|
前几天给部门内部做了一个DDD方面的培训,这篇文章就记录一下培训的主要内容。
一 软件的目标是什么
软件的目标是快速地响应客户的需求变更,传统的软件开发方式割裂了软件的功能性需求和非功能性需求,首先业务人员分析好需求以后,拿给开发人员进行开发,这样就使得软件的功能性需求是依赖于某一种技术了,甚至有时候还会造成软件系统离开一两个开发人员就不能维护了,这其实都是将功能性需求和非功能性需求分离造成的后果。
采用领域驱动的开发方式,最终系统形成了一个通用的模型,这个模型是完全面向业务的,这个模型是业务人员和开发人员都能容易理解的,同时这个模型也是如实的反映了领域实质的,这样以来软件不是依赖于某种技术,同一个模型可以用不同的技术来实现。与此同时,采用领域模型以后,领域模型是一个对象模型,而这个对象模型是容易理解,容易维护,容易复用,同时加入分布式缓存系统以后,对象模型是具有伸缩性的,因此领域模型在分析之初就将功能性需求和非功能性需求统一在了一起。采用领域驱动设计以后,软件系统的功能性需求和非功能性需求完美的统一了,那么具体都有哪些非功能性的需求呢?
1 Extendability(扩展性)
任何事物都处于一种发展变化当中,软件当然也不例外,因此一个软件系统必须要良好的可扩展性,当新的需求出现了,或者需求发生变化了,软件如何能跟的上变化,如何能更快的加入新的功能,这些都是一个良好设计的软件应该具有的性质。
2 Maintainability (维护性)
从哲学的角度来说,任何一种事物都是有生命的,软件也不例外,在软件的生命周期当中,难免会出现要对软件进行维护,而一些软件系统由于文档,代码,注释等等的原因,造成了软件的维护下很差,维护成本很高,因此一个好的软件系统必须要要具有良好的维护性。
3 Reuseability (复用性)
复用的概念可以说已经充斥在我们每个人的日常的生活当中,同样的软件系统也应该有复用性,一个设计良好的软件系统,它的内部各种组件都是良好复用的,在需要一些功能的时候,可以通过已经存在的组件来构造,而不是每个功能都重头来做一遍,这样不仅增大了开发成本,减低了开发的效率,同时这个软件系统的复用性就降得很低。
4 Scalability(伸缩性){垂直,水平}
软件的可伸缩性是指在软件系统负载变大的时候,软件系统只需要增加更多的资源就可以应对更大的负载,响应更多用户的请求。而软件的伸缩有方向性,通常有横向的和纵向的,横向就是指水平的伸缩性,在负载增多的时候,我们增加更多的逻辑单元,让这些逻辑单元就像是同一个单元一样,比如我们增加更多的Jboss的实例,增加多个PC
server等。而纵向来说,就是指垂直伸缩性,垂直伸缩式指对同一个逻辑单元进行增强,比如增加CPU,增加内存,增加更快速的磁盘等等。
在软件的的伸缩性中,垂直伸缩性往往是受限制比较大的,并且成本也比较高的,一个普通的Server,你不可能无限的增加CPU,增加内存等,因此总是有个限制,而水平伸缩,限制就会小很多。但是如何设计我们的软件系统使其更加具有伸缩性,这也是一个大的挑战。而采用领域驱动设计和缓存的方式,就可以提高软件的可伸缩性,更准确来说就是提高软件系统的水平伸缩性。
5 Performance(性能){多快,多大}
通常我们在理解一个软件系统的性能的时候,我们第一时间都会想到,这个软件系统快不快,好像一个软件系统只要速度快就是性能好,其实这样理解软件系统的性能,存在一定的偏差,速度快只是性能的“多快”的方面,性能还有很重要的一个方面,那就是“多大”,软件系统能支持多少用户,软件系统在支持多少用户量的时候还能保持某一个响应的速度,这就是性能的“多大”的方面。因此在考虑系统的性能的时候,需要从“多快”和“多大”两个方面来考虑。
二 Domain Driven Design(领域驱动设计)
1 领域驱动设计的概念
1.1 What is the domain model?
首先软件是什么?在人们的脑海中,软件好像就是一种计算的工具,但是这是软件刚刚出现的时候的概念。现在的软件已经不仅仅是一种计算工具,它代表的是一种针对某一个领域的解决方案,软件可以帮助某一个领域来完成特定的工作,软件可以帮助我们处理现代生活中复杂的工作。
理解了软件是什么以后,我们需要清楚一个软件的核心是什么?也许有人会说软件的核心是实现软件的技术,是的,我也承认,软件必须通过某一种技术来实现,但是我这里想说的软件的核心应该是一个模型,是一个与具体技术无关的模型,因为技术的发展日新月异,并且我们的客户也是看不到你到底用了哪种技术来构建软件的,客户关心的是你有没有真正的实现软件的需求,你的软件有没有如实的完成了符合某一个特定领域的工作。而生活中某一个领域相对来说是稳定的,从而某一个领域所对应的模型也应该是相对稳定的。
理解了软件的核心是一个忠实反映软件所解决问题的领域模型后,我们再来说说什么是领域模型。软件的领域模型可以通过好多种方式来描述,而在面向对象的技术变得越来越流行的当今社会,领域模型最合适的描述方式就是通过一个对象模型来描述领域模型。因此就目前来说,领域模型可以理解为反映一个领域实质的对象模型。
因此软件设计是一个艺术的过程,软件设计不能从数学的角度去思考,软件不能通过定理通过公式来表达,软件需要通过一个模型来表达。
1.2 Ubiquitous Language(通用语言)
领域驱动设计引入了Ubiquitous Language的概念,UL是业务专家或者领域专家和开发者采用的通用语言,在讨论中,开发者和领域专家都通过UL进行讨论,这样就避免了领域专家和开发者用不同的术语描述的是同样的概念,从而引起的混淆。
Ubiquitous Language更加侧重于业务和领域方面的术语,而不是技术术语,我们作为开发人员,经常讨论中会引入一些技术方面的术语,这应该是所有开发者的通病,在领域驱动设计中,所有参与项目的人共用统一的通用语言。无论是BA,PL,PM,SE还是开发人员,在讨论的过程统一使用通用语言。
1.3 Bounded Context(边界上下文)
在进行DDD实践的过程中,我们完全可以将系统所有的对象都建模为一个模型,这个模型中包含了系统中所有的对象,这样做可以,但是这样以来就会使得领域模型变得非常的大,同时也增加了领域模型维护和改进的难度,因此需要一种机制来使得领域模型能划分的更细一点,这就是所谓的“Bounded
Context"。
边界上下文将领域模型划分为一个边界子领域,这样使得大的领域模型划分小的子领域,这样在扩展维护的时候或者在对领域模型进行重构的时候,影响就会变的小。拿大家熟悉的电子商务领域来说,在一个电子商务领域,整个领域模型是很庞大的,因此有必要将其划分为小的子领域,比如在购物的时候,我们有个Shopping的概念,在下订单的时候有"Order"的概念,这些其实就是一个不同子边界上下文,Shopping
Context和Order Context.
2 为什么要引入领域驱动设计?
2.1 目前项目中存在的问题
2.1.1 不注重软件的生命周期
任何一种事物都是有生命的,这种朴素的哲学观也可以映射到软件系统当中。系统初期也许负载量小,系统运行良好,但是随着用户量的增大,系统的负载也变的越来越大,这个时候如果在系统设计初期没有注重软件的生命周期的话,那么系统就很容易随着负载的增加而宕掉,同时软件的追究不在于满足当前的客户需求,软件更应该追求一如既往的满足客户的需求,如何使得软件能够在新的需求出现的时候快速的响应,并且以较小的成本来完成需求变更响应,这就要求在软件在设计初期就考虑到软件的生命周期。因此如果想让我们的系统能平滑的应对大负载,同时能快速的跟上需求变化,这个时候就需要合适的架构和真正符合领域实质的领域模型。
2.1.2 过分依赖数据库编程
目前很多J2EE的系统都存在过分依赖数据这种现象,每次业务操作都是直接调用dao来完成,这样其实和以前那种存储过程是差不多的,通过这种方式开发,无形中给数据库造成了相当大的压力,而项目伸缩性的最大的敌人也正是数据库。过分依赖数据库最终就造成整个系统压力跑到了数据库里面,随着系统负载的不断增加,数据库的压力将越来越大,最终数据库因不堪重负而宕掉。因此如果过分依赖数据库,那么我还用那些中间件服务器做什么?还用Java做什么?所以一个系统要想有一个好的伸缩性,第一步就是要打破依赖数据库这个盒子,打破数据库这个盒子的目前最合适的方式就是采用领域模型的方式。
2.1.3 面向过程思维
Java是一门面向对象的语言,那么是不是用了Java就表面是面向对象了?完全不是一个概念!目前的很多项目中,其实都是面向过程式开发,大量的业务逻辑都在Service里实现,而领域对象其实完全都是贫血的,没有行为,仅仅是一种数据容器,这样以来每次业务操作都是action-->service-->dao,这其实就是一种面向过程的思维,专业一点,这说白了就是POEAA中的事务脚本模式,这种方式只适用于小项目,大型项目就需要采用领域模型的方式进行。
2.1.4 不能快速响应需求变化
软件的需求是多变的,如何应对这种多变的需求,这对软件开发来说是个大的挑战。而如何应对这种变化呢?我们在具体的开发当中就应该采用敏捷迭代,持续重构和改善的方式来进行,而不能采用传统软件工程中“瀑布式的”这种软件工程方法。在我们公司的价值观里面有一条“拥抱变化,学习成长”,这个拥抱变化的思想非常重要,它正面面对了一个软件开发当中不可避免的问题。
在采用了敏捷迭代,持续重构、改善和拥抱变化的开发方式和思想以后,相当于我们确定了一个总体的软件开发的方式,但是这样还不够,到底我们迭代什么,持续重构和改善什么还没确定,这个时候就正是领域模型发挥作用的时候。在软件需求发生变化的时候,我们积极主动的去拥抱了需求的变化,而同时我们将这种变化如实的反映在领域模型当中,这种改善和重构是为以后更快速的开发做准备,因为随着项目的进行,领域模型已经能越来越真实的反映领域的实质,这样就软件开发速度就会越来越快,因为很多功能在领域模型里面已经完成了,需要的时候只需要复用就可以了。
2.1.5 需求分析和设计不匹配
需求分析人员或者业务人员的职责重点就是从客户那里挖掘出需求,真正理解客户需要什么,客户需要我们的系统是个什么样子,等业务人员提炼需求以后,设计人员根据需求分析文档进行软件的设计,初看这也许没什么问题,但是深入的想下去,我们就会发现这个环节缺乏一个良性的互动,缺乏一个统一的语言。缺乏互动和缺乏统一的语言最终就造成分析和设计脱节,从而延缓了项目开发进度。
所以要想真正跨越分析和设计之间的鸿沟,目前领域建模是非常合适的方式。通过领域模型,分析人员和设计人员在一起讨论,形成一个初步的领域模型,这个过程中,分析人员和业务人员就有一个统一的语言,这样分析人员和设计人员也能更加的理解客户的需求,同时形成的领域模型也能更忠实的反映领域的本质,这样的领域模型的复用性是非常高的,这也就显著的提高了项目开发效率。
2.1.6 不重视对象的生命周期
Java是一门伟大的语言,它内置了垃圾收集器机制,这样是不是就说明我们不需要关注内存中对象的管理了呢?其实我们还是要关注对象的生命周期,系统中的一些对象如果用完了就扔给垃圾收集器,这样势必会造成垃圾收集器的频繁启动,而垃圾收集器的启动在采用不同的垃圾收集策略的情况下是具有非常不同的区别的。因此对象生命周期管理也是开发一个优良的面向对象的软件系统很重要的一项任务。
3 领域模型和架构的关系
在目前J2EE项目中,软件架构主要采用分层架构的思想,而分层带来的好处就是提高软件的可扩展性,可维护以及可伸缩性。J2EE项目传统上划分为3层:表现出,业务层,持久层。
3.1 DDD中分层标准
3.1.1 Presentation Layer(表现层)
表现层负责提供用户的接口,它和传统的表现层的概念是一致的。表现层仅仅是负责接受用户的请求,然后调用应用层层获取领域对象来渲染结果视图,最终进行视图的展现。表现层主要采用MVC模式。
3.1.2 Application Layer (应用层)
应用层定义了软件系统所能做的事情,但是它不负责怎么做,也就是说应用层只定义了"what
to do",而不关注"How to do".应用层负责调用具有丰富业务逻辑的领域对象来完成某一次的业务操作。同时应用层还需要负责提供与其它系统进行交互的接口。
应用层不负责保存与业务有关系的状态,它仅仅只是将工作委托给领域对象来完成,虽然应用层不包含业务规则和状态,但是应用层可以包含操作过程的状态,比如事务状态等。
3.1.3 Domain or Model Layer(领域或模型层)
领域层是系统的核心,领域层实现了软件的核心的业务逻辑和业务规则,领域模型就属于这一层。
领域层具体会包括很多重要的对象,这部分将在“领域驱动设计中的关键角色”部分说明。
3.1.4 Infrastructure Layer(基础结构层)
Infrastructure Layer提供了系统技术性的支持,比如持久化访问数据库,消息发送,邮件发送等。
3.2 领域模型在架构中的地位
架构是整个系统骨架,架构是一个水环境,而领域模型是鱼。领域模型即独立于架构又服务于架构的。独立性体现在领域模型可以用于不同的架构环境中,就好像把一条鱼从一个水域移到另外一个水域,它照样可以存活一样,而服务于架构体现在领域模型需要融入具体的架构中,才能构成完整的系统。
架构关注与系统的整体的结构,这个结构不仅会涉及到系统本身的业务,比如系统主要有那些业务模块构成,而且也会涉及到具体的技术实现,比如业务层是采用spring,EJB还是Jdon,持久层是采用hibernate,JPA,IBATIS还是JDBC。而领域模型是完全面向业务的,它不会与具体的技术耦合。因此领域模型和架构的分离还体现了一种思想:分析和设计的时候分离,实现的时候粘合,而到真正运行的时候完全统一的思想。(领域模型在分析和设计的时候是独立于架构,而实现的时候会和具体的架构进行粘合,而真正运行的时候会和具体的架构进行完全的统一),这样EJB分布式组件当初的思想(编码时分离,部署时粘合,运行时真正统一是一致的)。
领域模型是针对于某一个特定领域的,因此每一个不同的领域都会具有不同的领域模型,但是对于相同领域的不同项目,我们可以采用一套相同的领域模型来进行开发。而软件架构是可以在不同的领域进行复用的,比如struts,spring等框架,以及分层的思想等,这些都是可以在不同的领域进行复用,因此领域模型是面向领域的复用,是一种针对特定领域的复用,而软件架构是一种更加宽泛的,更加偏向于技术方面的复用。
4 领域驱动设计中的关键角色
4.1 Entity(实体)
实体具有一个显著的特征,那就是实体都是有(Identity)标识的,我们判断两个实体到底是不是一样的,我们只是根据实体的Identity,两个实体即使其它的属性都一样,但是只要标识不一样,那么这两个实体也是不一样的,比如在软件系统中,有两个Customer对象,这个对象的其它属性都一样(名字,性别,年龄等),但是他们的Identity不一样,那么这两实体就是不一样的。
DDD中的实体和我们一般的软件系统中的实体有什么区别呢?那就是DDD中的Entity是具有丰富的业务行为的,是充血模型的,而不是贫血模型的,像一般的软件系统中,实体往往都只是数据库表中数据容器,没有任何行为,所有的业务逻辑的实现都跑到了service层,而Service不能如实的映射到领域中,因此用它来表达业务也是不适合的。
充血模型和贫血模型,我们在判断实体到底是充血模型还是贫血模型的时候,不能仅仅只从单一实体的行为上来看,要从一个整体的角度来看,单单看一个实体,它是无行为的,但是这个实体属于一个聚合边界的时候,整个这个边界是充血的,因此我们判断到底是充血还是贫血的时候,应该有一个边界的概念,只要边界里面的实体对象整体上业务行为丰富就OK。
4.2 Value object (值对象)
J2EE中各种O的概念太多了,比如PO,VO等等,DDD中的值对象与以前的值对象是有区别的。在EJB2.X中有Entity
bean的概念,因为Entity bean也是以一种分布式组件,一次每次远程调用都是有开销的,因此SUN公司的工程师们创造了一个值对象的概念,值对象就是Entity
bean的数据,它仅仅起到了在系统各层之间传递数据的功能。
DDD中的VO有它自己的含义。DDD中的VO一般都是一些描述性的对象,通常都是对Entity的描述,比如一个SNS型网站,它有PersonalPage(个人主页)的概念,PersonalPage有一些状态,比如最近访客列表,好友列表,新鲜事等等,这些其实都是一种状态信息,我们就可以将其做为PersonalPage的状态,还比如论坛帖子,它也有一些状态信息,比如帖子的回复有多少,最近一次回复是什么时间等,这些也可以封装到一个VO里,当做是帖子的状态对象。
DDD中的VO还有一些不可变的对象,比如软件系统中的Money,Address等对象,这些对象都只是根据值来确定的,只要两个Money对象的值一样,我们就可以在不同的实体里使用,而不需要区分这个Money到底是那个实体的Money.
4.3 Aggregate(聚合)
DDD中的聚合有点类似UML中聚合的概念,聚合代表一些逻辑上联系比较紧密的对象的集合,每一个聚合都有一个Aggregate
Root(聚合根)对象,聚合根控制了对聚合内部对象的访问,聚合外部要想访问聚合内部的对象,必须通过聚合根对象来访问。
拿Order和OrderLine来说,订单Order是聚合根,而Orderline是聚合内部的子对象,聚合外部要想获取Orderline的信息必须通过Order来获取,同时Orderline也是完全属于Order的,Orderline不能独立于Order而存在,系统中不能存在没有Order的Orderline,因此一般在删除Order的时候,Orderline也需要进行删除。
聚合还有一个重要的特性,那就是不变量的约束,聚合根对象要保证自己聚合内部的不变量是一致的,聚合根提供给外界的方法都必须有前置条件和后验条件的约束,比如Order的总价格必须要和每个Orderline加起来的总价格是一致的,而不能发现不一致的状态,这个一致性的维护都要通过Order来进行。
因此聚合最重要的两个特点就是聚合提供了一种组织逻辑上联系紧密对象的一种方式,同时聚合还要保证聚合内部对象生命周期以及聚合不变量的约束。
4.4 Repository(资源库)
Repository(资源库)顾名思义,它代表的是放资源的一个仓库,那么它里面到底放什么东西呢?这就是系统的领域模型对象。
Repository提供了访问领域模型对象接口,领域层通过Repository来获取领域对象。
在传统的开发当中,我们非常熟悉Dao的概念,DDD中的Repository和Dao是不同的概念,DDD的Repository是完全面向领域对象的,领域层从Repository获得的对象是符合不变量约束的对象,往往这个对象就是Aggregate
Root对象,当系统从Repository拿出领域对象的时候,不用再考虑这个对象是不是完整的,它里面的子对象有没有嵌入,它的不变量有没有得到保证,这些在从Repository拿出领域对象之前,Repository都已经帮我们做好了。
Repository还屏蔽了系统底层具体的持久化技术,无论我们底层采用什么样子的存储方式,比如RDBMS,XML,File
System,Repository都提供一致的接口给领域层使用。
4.5 Factory(工厂)
Factory和GOF设计模式中的工厂是类似的,采用DDD后,系统会形成一个完整的领域模型,领域模型里面包含的丰富的领域对象,这些领域对象往往都包含丰富的行为,同时也包含自己的不变量的约束,因此我们可以通过Factory封装领域模型对象创建过程,Factory封装了领域对象的创建逻辑,同时Factory还会保证领域对象创建以后是完整的,是符合不变量约束的。
Factory的引入主要是为了控制领域对象的生命周期,Factory控制了领域对象生命周期的开始,而Repository控制了从创建以后到最后消亡的生命周期。
4.6 Service(服务)
Service是一种大家比较熟悉的概念,在传统的开发方式中,我们的系统中业务逻辑的载体就是它了。但是在DDD中,Service的概念和传统的概念是不同的。
DDD中的Service可以分为两种类型,一种是Application
Service(应用层服务),另外一种是Domain Service(领域层服务).
Application Service(应用层服务)关注点不在于系统的业务逻辑,应用层的关注点主要在于系统功能的定义,也就是说应用层服务一般定义了What
to do,而不关注“how to do",应用层服务要想完成某一次的业务操作,需要调用领域模型对象来完成。应用服务还涉及到一些与系统级状态有关系的信息,比如应用层服务一般都会涉及到事务控制,安全访问控制以及日志记录等功能。
Domain Service(领域层服务)是属于领域模型中的,它关注与业务逻辑的实现,在系统中有一些行为可能不属于Entity(实体),Value
Object(值对象),那么这些行为就要划分到Domain Service里面。
比如在电子商务系统中一般都有ShoppingCart(购物车)的概念,当用户需要查看本次购物的总价格的时候,这个getShoppingCosting职责的实现就不能由ShoppingCart来实现,而相应的会由PriceService和ShopcostingService来实现,因为这些行为会涉及到与系统其它部分或者外部系统的交互,比如PriceService会涉及到与外部价格系统的交互等等。
Domain Service使得Entity和Value object对象更加的高内聚和低耦合,这其实也反映了面向对象的设计原则,为了让Entity和Value只包含自己应该包含的职责,对于一些本不属于自己的职责,则有专门的Domain
Service来实现。
4.7 Domain Event(领域事件)
Domain Event是一种使得领域模型更加高内聚,松耦合的机制,通过引入领域事件,使得核心的领域模型和Service和Repository解耦,这样使得领域模型能更加真实的反映领域的实质。
<!--EndFragment-->
5 领域驱动设计实战
5.1传统的开发方式和领域驱动设计对比
传统的软件一般是action->service->dao,系统大部分的业务逻辑都在service,没有一个核心领域的概念,这样整个软件系统在扩展起来就是通过在Service里面增加方法或者继续增加更多的Service,这样以来,随着系统开发过程的不断演进,这个service层也就变的非常庞大,这个时候已经完全丧失了领域的概念,业务逻辑的复用性变的很低,有时候为了实现某种功能,自己都很难发现到底这个功能再哪个Service里已经实现了,即使自己知道实现相同的功能的那个service,为了实现某个功能,你需要把其它的Service整个注入进来,这样不仅破坏了封装性而且也更不容易维护。
传统的开发方式的架构图如图5-1 所示:
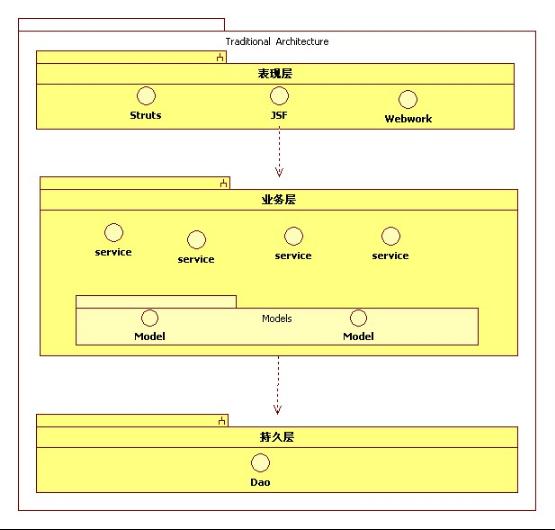
图5-1 贫血模型架构图
采用传统的开发方式,系统调用的序列图如图5-2所示:
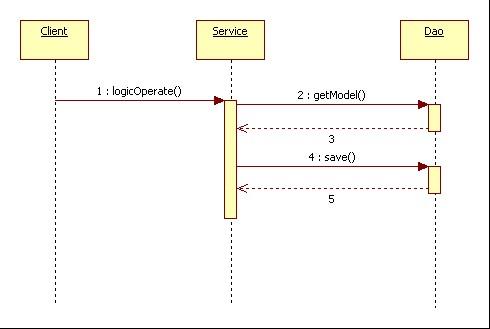
图5-2 贫血模型序列图
采用领域驱动开发的方式以后,也许刚开始项目会进展慢一点,因为毕竟要从需求中提炼出领域,而领域模型也不能一下子就形成,这需要一个过程,但是随着软件项目开发进程的不断推进,等领域模型慢慢建立起来以后,我们就会发现速度越来越快,因为领域模型经过迭代和重构,已经与真实的领域形成了共振,这个时候需要实现什么功能,我们只需要调用有丰富业务逻辑的领域对象来完成,而不是重新开发出一套接口。
采用领域驱动设计以后,整个系统的架构图如图5-3所示:
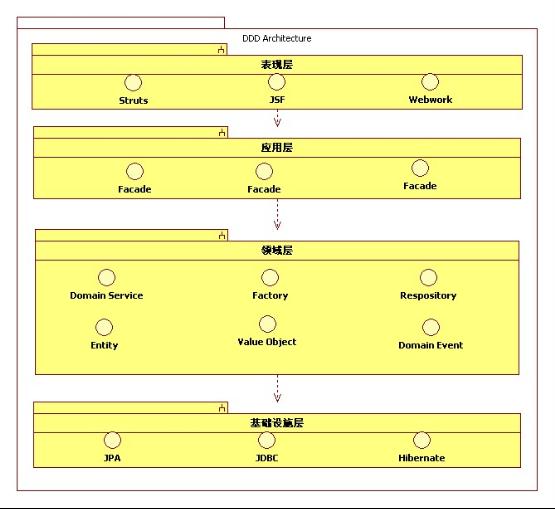
图5-3 DDD architecture
采用DDD以后,系统调用的序列图如图5-4所示:
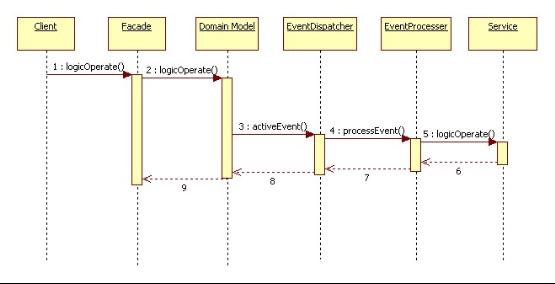
图5-4 DDD sequence
6 领域驱动设计实战总结
6.1 Extendability(扩展性)
采用DDD以后,随着系统的开发不断继续,领域模型也逐渐形成,同时领域模型也逐渐的反映了领域的实质,这样系统需要新的功能的时候,领域模型已经完成了很多业务逻辑操作,我们需要做的仅仅是指导已经存在的领域模型对象来实现新增加的功能。如果领域模型里面没有完成新功能所需要的逻辑,那么此时就需要将新增加的功能增加到领域模型中,这个增加不是随便的增加,一定要增加到合适的领域模型对象里面,这样以来越到开发后期,因为领域模型越来越完善,这样增加新功能所需要的工作量也将越少。
6.2 Reuseability(复用性)
采用DDD以后,因为领域模型已经实现了很多的业务逻辑,并且这些业务逻辑都是可以在不同的业务操作期间复用的,而不像传统的那种方式一样,要想复用就需要将其它Service注射到当前完成业务操作的Service中来,这样就造成Service的业务逻辑封装性降低,并且使得Service越来越多,复用性越来越低。
6.3 Maintainability(维护性)
采用传统的开发方式,业务逻辑通过Service实现,这样就会造成非常多的Service,这样在维护的时候,也相应的增加维护的工作量,从而增加维护成本,更糟糕的是Service没有领域的概念在里面,在维护的时候,我们没有办法按照领域实际的概念去理解它,比如上面的ForumThread例子,维护人员在维护的时候,找到FroumThread就可以找到与ForumThread的一些行为,而这些行为在论坛这个真实的领域中也是确实存在的。
三 领域驱动设计和缓存
1 重视对象的生命周期
1.1 什么是对象的生命周期
任何事物都有生命,当然系统中的对象也不例外,一个对象从创建到最终从系统中消失这整个过程就是领域对象的生命周期,对象的生命周期如果控制不好,将会对系统带来很大的负面影响。
1.2 为什么重视对象的生命周期
为什么会出现Spring/Jdon这样的IOC容器,为什么会出现一些中间件服务器?IOC容器和中间件服务器到底为系统带来了什么好处?这里面其实就包含着对象生命周期的思想。在系统中,有很多无状态的线程安全的组件,通俗点说也可以理解为Service,这些组件我们通过IOC容器来进行管理,IOC容器其实主要就是管理了这些组件的生命周期。还比如Jboss等中间件服务器,它们也提供了对EJB组件的生命周期管理。
无状态的那些组件我们通过容器的概念进行了管理,那么我们系统中模型对象怎么管理呢?这个地方就要用到缓存了。
拿Java语言来说,JAVA具有垃圾收集器,但是有了垃圾收集器,我们是不是就不需要考虑对象的生命周期了呢?不是,一个对象new出来以后,如果使用完了就扔掉,那么势必会造成越来越多的垃圾对象,这样也就会使得垃圾收集器频繁的启动,而垃圾收集器的算法是依赖于不同的JVM版本,以及JVM启动时候,你自己设置的JVM参数,因此如果不注重对象的生命周期,那么就会引起垃圾收集器不要的启动,这对"stop-the-whole-world"的次要GC来说,将会极大的影响到系统的性能。因此我们需要引入一种能复用对象的机制,而这种机制目前最合适的就是通过缓存。
2.领域模型为什么需要缓存?
为什么会在领域驱动设计里面涉及缓存?经过领域建模以后,整个模型对象都是完全面向业务的,并且具有丰富的行为,而对象和数据库之间又存在天然的矛盾,这种矛盾主要体现在领域对象保存到数据库时,需要把其一层层打开,然后放入数据库,而从数据库里生成领域对象有需要将裸体的数据穿上衣服,最终形成领域对象,这个过程非常的麻烦,因此我们为什么不在领域对象用完以后放到某一种地方,而这种地方可以方便快捷的取出对象和放入对象,这个地方其实就是缓存。
缓存是领域对象在内存中的生存场所,是一种面向业务的存储方式,而同时我们的领域模型也是一种面向业务的模型,有了面向业务的存储以后,我们就可以进行面向业务的运算,而正是这种面向业务的运算使得我们的系统具有更好的伸缩性和扩展性。因为此时的领域对象通过缓存都是跑在J2EE中间件中,而在负载增多的时候,通过水平的增加中间件服务器来进行水平伸缩。
缓存+领域模型是面向业务的对象模型,面向业务的存储,面向业务的运算结合的基础,而数据库则是一种完全面向数据的存储方式,因此数据库思维和对象模型思维是不匹配的。
3 缓存概述
3.1 缓存定义
缓存是计算机领域非常重要的一个概念,它是介于应用程序和永久性的存储系统(比如数据库,文件系统等)之间一种媒介。缓存降低了应用程序对持久性数据源的访问,从而使得应用程序具有更好的性能。
3.2 缓存种类
3.2.1 按照缓存中的元素划分
缓存按照缓存中存储的内容来划分可以划分为:
数据缓存(比如数据库中内置的缓存)
文件缓存(比如文件系统的缓存,浏览器的缓存js,css文件等)
对象缓存
对象缓存是这次交流的重点,采用了DDD以后,系统会有一个完整的领域模型,这个领域模型一般目前都是通过对象模型来实现的,那么这个对象模型的就要用到对象缓存了。
4) 其它缓存(比如CPU内部的高速缓存等等)
3.2.2 按照缓存和应用程序的耦合度划分
Local Cache
Local Cache是指应用程序与缓存运行在统一进程中,比如目前J2EE界流行的OScache,Ehcache,jbosscache等。这一类型的缓存离应用程序近,因此效果也比较好,但是无法应对分布式和集群情况下的缓存要求,因为local
Cache多数都是采用了广播机制来对各个节点进行更新,这样在集群环境下,当节点个数比较多的时候,广播通信就会对系统带来很大的开销,甚至这种开销抵消了缓存带来的性能方面的提升。
Remote Cache
Remote Cache是指应用程序与缓存运行在不同的进程中,这种类型的缓存的代表是著名的Memcached,Remote
Cache是一种分布式和集群级别的缓存,这种情况下,应用程序一般通过缓存系统的协议与缓存系统进行交互。
3.2.3 按照缓存的生命周期划分
按照缓存的生命周期来划分,缓存可以分为以下几种类型:
Request或者事务级别
Request级别的缓存一般存在于单个的Request生命周期里面,当一个Request结束的时候,缓存也就消失了。Request级别的缓存的代表是Hibernate的一级缓存。Request级别的缓存也可以叫作事务级别的,因为每次事务结束的时候,缓存也随之消失。
Session级别
Session级别的缓存一般是扩展到了整个Session期间,它存活于整个Session周期中,当Session结束时,Session级别的缓存也随之结束。这方面的缓存比如Httpsession或者Statefull
session bean 扩展持久化上下文。
Application级别
Application级别的缓存存在一个整个Application的生命周期之中,当应用程序启动的时候,缓存生命周期开始,当应用程序结束的时候,缓存的生命周期结束。
在采用了DDD建模以后形成了领域模型,这个领域模型需要缓存,此时主要是指Applicaiton级别的缓存,是整个应用程序级别的缓存。
3.3 缓存的清除策略
当缓存中的元素超过缓存的限制的时候,缓存系统就会采用一定的缓存策略将缓存中的元素从缓存中移除,缓存的清除策略主要有以下3种:
FIFO (First In First Out)
这种缓存策略表示当缓存清除缓存元素的时候,缓存系统会清除在缓存中时间最长的元素。
LRU (Least Recently Use)
这种缓存策略表示当缓存清除缓存元素的时候,缓存系统首先清除最近最少使用的元素,这种情况下,一般缓存元素都会有一个时间戳,缓存系统会选择清除时间戳离当前时间最远的元素。
LFU (Less Frequently Use)
这种缓存策略表示当缓存清除缓存元素的时候,缓存系统首先选择缓存中一直以来最少使用的元素,这种情况下,缓存元素一般都会有个hits属性,每次命中以后,hits都会加一,当要清除的时候,缓存系统选择hits最小的元素清除。
在选择缓存清除策略的时候,我们根据当前业务系统的特点来进行选择,每一种缓存清除策略都有它自己的优点。一般情况下推荐使用LRU。
4 领域模型和缓存如何配合?
4.1 对底层缓存系统进行封装
采用DDD建模和缓存以后,首先我们面临的问题就是如何对缓存系统进行封装的问题,因为缓存系统是一种技术的时候,同时也有好多种选择,我们不能让领域模型依赖于具体的缓存技术,这个时候就需要进行缓存的封装。而在本次CBB
LPQ的设计中,我们的团队也对底层缓存系统进行了封装,具体在封装的时候,我们可以通过图4-1所示的方式进行封装:
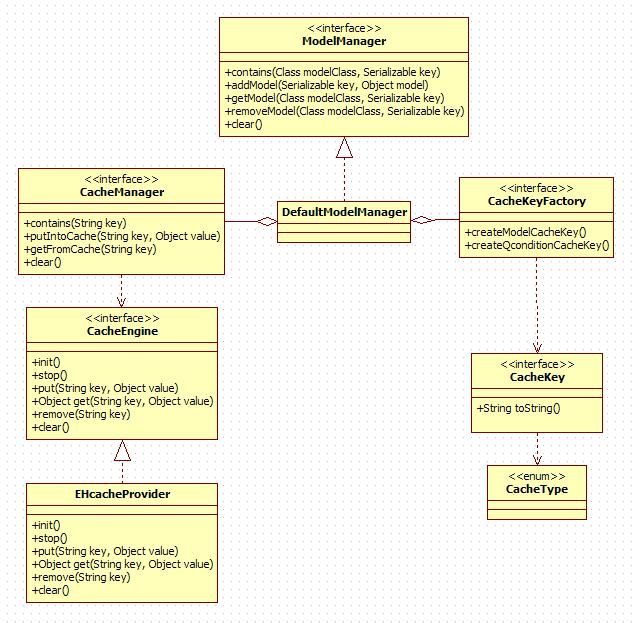
图4-1 Cache 类图
4.2 提供统一的缓存入口
在系统中引入缓存之后,我们需要提供一个统一的缓存入口,系统的其它部分要想通过缓存来获取领域对象都必须通过统一的缓存入口。通过提供统一的缓存入口使得缓存的管理更加方面。如果不提供一个统一的缓存入口,这样整个缓存的逻辑就散落在了系统的不同部分,这样维护起来就比较麻烦。
4.2 Factory与Cache的结合
采用DDD建模以后,系统中会形成很多领域对象,当需要创建一个领域对象的时候,因为领域对象涉及到很多状态,要构建一个状态非常多的领域对象非常复杂,因此有必要通过工厂来封装,在工厂创建领域对象的时候,因为领域对象聚合了很多的子对象,同时还关联了了其它的聚合根对象,因此当创建一个聚合根的时候,当需要另外的领域对象的时候,首先从缓存中取,如果有就直接返回,没有再查询DB获取,最终形成一个完整的领域对象返回。举个例子,比如创建一个论坛帖子的时候,我们需要获得是谁发帖子,因此在创建帖子的时候,我们需要得到Account(用户)对象,而此时就需要首先从缓存中获取Account对象,如果存在就直接返回,不存在再查数据库。
5 领域模型和缓存总结
经过领域建模以后,系统形成了良好的领域模型,在这个领域模型真正与架构融合,并且跑起来之后,领域模型需要一个生存的场所,领域模型需要在这个生存的场所里面完成它的生命周期,这个生存场所就是缓存。领域模型+缓存是一种面向业务的分析、设计和面向业务的存储结合的结果,这种结合的结果就是能方便的进行面向业务的内存计算。
目前key-value存储系统正处在不断的快速发展过程当中,等以后key-value存储系统真正普及以后,我们可以通过key-value存储系统来作为领域模型的生存场所,这样整个系统也将完全是一种:面向业务分析、设计,面向业务的存储,面向业务内存计算的结合体,这将是非常完美的一个新世界。
5.1 Scalability(伸缩性)
通过将领域模型放入缓存,使得领域模型能够真正的以业务形态存在于内存中,能真正以业务形态进行内存的运算,这样以来,系统负载增多的时候,我们可以采用分布式和集群级别的缓存,这样就增强了系统的水平伸缩性。如果采用传统的那种方式,大部分业务逻辑都与数据耦合,这样当系统负载增多时候,数据库就成为了最不具伸缩性的一层。5.2
Performance(性能)
这也是Hibernate创始人所描述的:数据库成为了大多数企业应用的主要瓶颈,也成为了运行环境中最不具伸缩性的层。
系统性能方面,因为引入了缓存,这样当每次用户请求来的时候,系统将用更少的时间来完成对用户请求的响应,这样也将提高性能“多快”的方面,同时因为通过缓存降低了对数据库的压力,从而使得系统能应对更多的访问量,这也就增加性能“多大”的方面。同时在性能“多大”方面,通过引入分布式和集群缓存,甚至是引入key-value存储系统,我们的系统能平滑的过渡到一种分布式和集群环境中,这样也使得系统能应对更大负载,从而提升了性能“多大”的方面。
四 总结
采用DDD以后,系统形成了完整的领域模型,这个领域模型已经如实的反映了我们领域的实质,这样领域模型的可扩展性,可维护性和可复用性就非常高,而通过将领域模型和缓存结合以后,整个系统变成了一种:面向业务分析、设计,面向业务的存储和面向业务运算结合的一种更加具有良好性能表现和伸缩性的系统。
因此领域模型和缓存使得系统在可扩展性,可维护下,可复用性,可伸缩性以及性能方面都有良好的改进和提高。
结论:
1. 软件不是计算工具,软件帮助人们解决某一领域的复杂问题
2. 软件的核心是领域模型,而不是技术
3. 领域模型是一种面向业务的模型
4. 领域模型更加忠实地反映了软件实质
5. 领域模型+缓存=面向业务的分析和设计+面向业务的存储
6. 领域模型+RDBMS=面向业务的分析和设计+面向关系的存储,不匹配,矛盾!
7. 领域模型使得系统在满足功能的同时,具有可扩展性,可 维护性,可复用性
8. 领域模型和缓存使得系统具有更好的伸缩性和性能
9. 领域模型使得系统天然的具有功能性和非功能性的血统
10.领域模型和架构的关系:分析设计的时候领域模型独立于架构,而实现的时候,领域模型和架构粘合,真正运行的时候,领域模型和架构完全统一(是不是类似于EJB中,编程时分离,部署时粘合,运行时真正统一的思想)
|


