| 编辑推荐: |
本文主要介绍了ROS2
在自动驾驶项目中应该怎么用等相关内容。希望对你的学习有帮助。
本文来自于微信公众号智驾芯视野,由火龙果软件Alice编辑,推荐。 |
|
上个月在内蒙古一个露天矿待了一周。
不是去参观的那种待,是蹲在现场看车跑。矿卡从装载区到排土场,单程两公里多,重载下坡和空车上坡交替,路面上全是碎石和碾压出来的车辙。旁边还有洒水车、推土机、加油车在作业,你根本不知道下一分钟会不会有个推土机突然横穿过来。
这种环境里,坐在矿卡驾驶室看着方向盘自己转,跟你说内心毫无波澜那是假的。
但真正让我印象深刻的不是矿卡能自己跑,而是整个系统的工程切割方式。感知、定位、规划、控制、通信、数据闭环……每一层都有自己的边界,而这些边界恰好就是
ROS2 在工程上最能发挥价值的地方。
这篇文章不讲 ROS2 的基础概念,也不教你装 ROS2 Humble 或者写第一个节点。我想聊的是:当你的项目不是一个教学
Demo,而是每天要跑 20 小时、一年出勤 350 天的矿卡,ROS2 在每一个模块里到底应该怎么用,以及哪些地方你会踩坑。
ROS2 在自动驾驶里的角色,不是你想的那样
图 1:ROS2 三层架构与自动驾驶模块映射
很多人对 ROS2 的理解还停留在「机器人中间件」上。这个理解没错,但只理解到这一层不够。
自动驾驶系统说到底是分布式实时计算系统。车上有激光雷达、摄像头、毫米波雷达、IMU、GPS-RTK
多个传感器,每个传感器有自己的数据频率和处理链路。感知算法跑在 GPU 上,规划和控制跑在 CPU
上,它们之间需要低延迟、高可靠的数据通道。
ROS2 在这个体系里做的事情,拆开来看是三层。
第一层是通信层。ROS2 基于 DDS(Data Distribution Service)做节点间通信,支持
publish/subscribe、service/client、action 三种模式。DDS 本身是一个工业级的实时数据分发标准,提供了
QoS(Quality of Service)控制——你可以指定某个 topic 的可靠性是 RELIABLE
还是 BEST_EFFORT,持久性是 TRANSIENT_LOCAL 还是 VOLATILE,延迟
deadline 是多少。
对自动驾驶来说有什么实际影响?比方说激光雷达点云数据,丢了半帧不影响核心安全,你可以用 BEST_EFFORT,减少重传开销。但车辆控制指令,比如期望方向盘角度和油门开度,那必须是
RELIABLE,丢一个包都不行。QoS 策略的精细控制是 ROS2 相比 ROS1 最大的进步,也是为什么
Autoware.Auto 从 ROS1 迁到 ROS2 的核心原因。
第二层是计算调度层。ROS2 的 executor 支持单线程、多线程和静态调度,你可以把高优先级的控制节点放到一个
dedicated executor 上,避免被点云处理这种重计算拖慢。ROS2 还提供了 lifecycle
node 的状态机管理——每个节点有 Unconfigured、Inactive、Active、Finalized
等状态,你可以精确控制系统启动和关闭的顺序。这个特性在功能安全场景下极其重要:你不会希望感知还没初始化完,规划就开始跑。
第三层是工具链层。ROS2 提供了 rosbag2 做数据录制和回放,rviz2 做可视化,ros2cli
做命令行调试。对于自动驾驶来说,数据闭环的起点就是 rosbag2——你在车上录下所有 topic
的原始数据,回到办公室回放、复现问题、训练模型,这套链路 ROS2 已经帮你搭好了基础。
但这里有一个非常重要的工程判断,很多人搞错了:ROS2 不应该渗透进你的核心算法内部。
核心算法和 ROS2 的边界在哪
我见过不少项目把感知模型推理、轨迹优化求解器直接写成 ROS2 node 的回调函数。这样做短期内确实跑得快,一个
node 搞定一切,demo 很好看。
但工程上这是自找麻烦。
你的点云检测模型说穿了就是一个纯函数,输入是 N 帧点云,输出是检测框列表。它不关心数据是通过 DDS
过来的、共享内存过来的还是从磁盘读的。如果你把模型推理跟 ROS2 的 subscription callback
绑死,你就没法单独对这个模型做单元测试、性能 profiling,也没法轻松换到不同的通信中间件上做对比测试。
工程上正确的做法是:核心算法做成独立的 C++ library(或者 Python package),输入输出是纯数据结构(struct、numpy
array、protobuf 等),然后在外面包一层 thin ROS2 wrapper。wrapper
只做三件事——从 ROS2 topic 收数据、调算法库的核心函数、把结果发到下游 topic。
这样做的好处不仅仅是解耦。更重要的是,你的算法库可以在 ROS2、eCAL、CyberRT 甚至非
ROS 环境里复用。矿卡项目里,我们经常要把同一套规划控制算法在云端仿真环境(非 ROS)和车端实时环境(ROS2)里跑,如果算法跟
ROS2 绑定,你就得维护两套代码。
大厂的实际工程里,ROS2 只是中间件之一,算法核心是中间件无关的。这个架构思路值得每一个做自动驾驶工程的人记住。
感知:什么时候用 ROS2 topic,什么时候绕过它
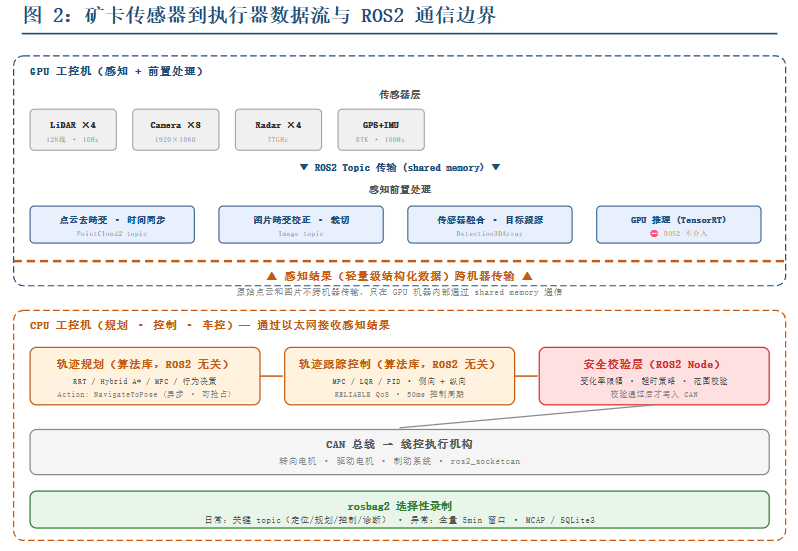
图 2:矿卡传感器到执行器数据流与 ROS2 通信边界
矿卡上的传感器配置和乘用车不太一样。
乘用车一般有多个摄像头、多个毫米波、1-2 个激光雷达,传感器分布在车身四周。矿卡因为体积大、盲区大,通常会在前保险杠、两侧后视镜位置、后方各布一组传感器,总共有
4-6 个激光雷达、8-12 个摄像头、4-6 个毫米波。
这么多传感器同时发数据,topic 的带宽压力是真实存在的。
一个 128 线激光雷达,10Hz 频率,单帧点云大约 30 万点,每个点包含 x、y、z、intensity
四个 float32,算下来一帧点云大约 4.8MB,带宽约 384Mbps。如果有 4 个激光雷达同时跑,光点云数据就超过
1.5Gbps。
ROS2 的 DDS 通信在 localhost 上走的是 shared memory(具体看 RMW
实现,Fast-DDS 和 CycloneDDS 都支持),所以车内同一台工控机上节点间点云传输不会真正占网络带宽。但跨机器的场景就不一样了。
如果你把 GPU 工控机(跑感知)和 CPU 工控机(跑规划控制)分成两台设备,中间走以太网,那点云数据跨机器传输就必须压缩。这时候
ROS2 的 topic 就不一定是最优方案了——你可能需要一个专门的数据压缩和传输层,而不是直接用
ROS2 的原生 pub/sub。
工程上比较务实的选择是:
传感器驱动节点和感知算法前置处理(去畸变、时间同步、坐标变换)放在同一台 GPU 机器上,通过 ROS2
topic 在 localhost(shared memory)内通信。感知结果(检测框、可行驶区域、跟踪轨迹)是轻量级的结构化数据,再通过
ROS2 topic 跨机器发给下游。原始点云不跨机器传。
感知模块内部的深度学习推理,GPU 显存之间用 CUDA IPC 或者直接走 TensorRT 的
inference engine,ROS2 就别掺和了。ROS2 的 callback 只负责触发推理,不负责搬运数据。
NVIDIA 官方有一篇博客讲得不错:用 ROS2 封装 TAO-PointPillars 做点云
3D 检测。做法就是 ROS2 node 收到点云后调模型推理,推理结果转成 Detection3DArray
消息发给下游。这种「ROS2 负责调度、算法核心独立」的模式就是标准做法。
定位:ROS2 擅长的事情,和它不擅长的事情
矿卡定位和乘用车定位面临的核心挑战不一样。
乘用车的挑战是场景复杂——城市峡谷、高架桥下、隧道里 GPS 信号弱,需要靠视觉和激光匹配来补。矿卡的环境倒是开阔,GPS-RTK
信号很好,但路面会变——今天挖了一车碎石,路面高度掉了半米,昨天建的高精地图直接失效。
所以矿卡定位的核心技术路线是:RTK-GPS 做全局定位基准,激光里程计和 IMU 做短时推算,定期用实时点云和离线地图做匹配修正。三套机制互相校验。
ROS2 在这个定位架构里最合适的角色是数据汇集和算法调度,而不是替代定位算法本身。
具体来说:GPS driver node 发布 NavSatFix,IMU node 发布 Imu,激光雷达发布
PointCloud2,这三个 topic 的数据在时间和空间上对齐后,输入给定位融合算法。ROS2
的 message_filters 提供了时间同步的 ApproximateTime 和 ExactTime
策略,tf2 提供坐标变换管理——传感器之间的外参标定结果存到 tf2 的 static transform
里,定位结果也通过 tf2 发布 odom→base_link 和 map→odom 的变换。
SLAM 算法方面,ROS2 生态里有两个主流选择:slam_toolbox 适合在线建图和定位,Cartographer
适合离线建图和在线定位,两个都原生支持 ROS2。但矿卡场景有一个坑:矿区是动态变化的,你不可能每天重跑一遍
SLAM 建图。
实际做法是:在矿区运营初期用一个配备高精度 GPS+激光的标定车跑一遍 SLAM,生成一份基准地图存盘。日常运营时,矿卡的定位模块加载这份基准地图,用
NDT 或者 ICP 做 scan-to-map 的实时匹配,输出修正后的定位结果。slam_toolbox
的 lifelong mapping 模式支持地图增量更新,但增量更新的频率和时机需要根据矿区的变化速度来调,不能全自动。
有一个重要但容易被忽略的工程细节:定位频率。
矿卡重载下坡时速大概 25-30 km/h,150ms 的定位延迟就意味着车辆位置偏差约 1.2
米。如果你的规划控制周期是 50ms,那定位就必须小于 50ms。ROS2 的 topic 通信延迟在
localhost shared memory 下通常可以做到微秒级,但定位算法本身的计算延迟才是瓶颈——NDT
匹配 30 万点云到地图可能耗时 30-80ms。
这时候工程上常用的优化是:定位算法每 200ms 跑一次 scan-to-map 匹配做全局修正,中间的
4 个周期(50ms 一个)用 IMU+轮速的航位推测做插值输出。ROS2 的 tf2 提供 lookupTransform
接口,规划控制节点可以按任意时间戳查询定位结果,不用关心背后的插值逻辑。
规划和控制:ROS2 的 action 机制是最佳匹配
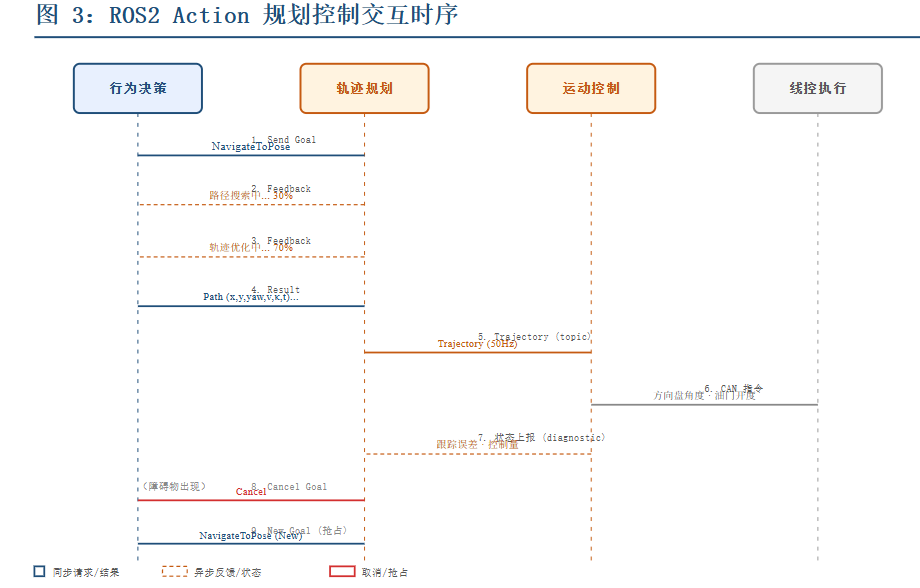
图 3:ROS2 Action 规划控制交互时序
规划和控制是自动驾驶里对实时性要求最高的两个模块,也是最能体现 ROS2 架构优势的部分。
ROS2 的 action 机制非常适合规划控制场景。一个典型的路径规划 action:上游行为决策
node 发送一个 NavigateToPose 的 action goal,规划 node 收到后开始计算全局路径和局部轨迹,计算过程中持续反馈规划进度(feedback),完成后返回最终轨迹(result)。这个过程中如果上游检测到障碍物需要取消或更新目标,可以用
cancel 或新的 goal 来抢占。
Action 比 service 的优势在于:service 是同步阻塞的,调用方等结果回来才能继续。Action
是异步的,计算过程中有 feedback,可以被抢占。自动驾驶的规划控制在绝大多数情况下都需要异步、可抢占的通信模式。
工程实现上,规划控制的核心算法同样是通信无关的。
轨迹规划——不管是基于采样的 RRT、基于优化的 MPC 还是基于搜索的 Hybrid A*——核心函数输入是起点、终点、障碍物列表、车辆运动学约束,输出是一条轨迹(位姿+速度+曲率+时间戳的序列)。这个函数里面没有
ROS2 的影子。
控制——不管是 PID、LQR 还是 MPC 跟踪控制器——输入是参考轨迹和当前状态,输出是方向盘、油门、刹车指令。同样跟
ROS2 解耦。
ROS2 的 wrapper 做的事情是:从 topic 收障碍物和定位结果,拼成算法库需要的输入格式,调核心函数,把输出轨迹点转成
ROS2 的 Path 消息发给控制 node。控制 node 拿到路径后跟踪执行,把实际方向盘角度和速度偏差通过
diagnostic topic 上报给系统监控。
还有一个工程上很关键但讨论不多的问题:控制指令的安全校验。
矿卡的线控执行机构(转向电机、驱动电机、制动系统)有自己的控制器,通过 CAN 总线接收指令。ROS2
控制 node 算出期望方向盘角度和油门开度后,通过 ros2_socketcan 或者自定义 CAN
driver 下发指令。
但这里不能直接透传。你需要在控制 node 和 CAN driver 之间加一层安全校验:指令变化率超过物理限幅(比如方向盘不能在一帧内从
-30° 跳到 +30°)、指令值超出安全范围(比如下坡时油门不能大于某个阈值)、通信超时后的安全策略(比如连续
200ms 没收到新指令就触发紧急制动)。这些校验逻辑放在 ROS2 node 里做,校验通过后才写入
CAN。
数据闭环:ROS2 最大的工程价值可能在这
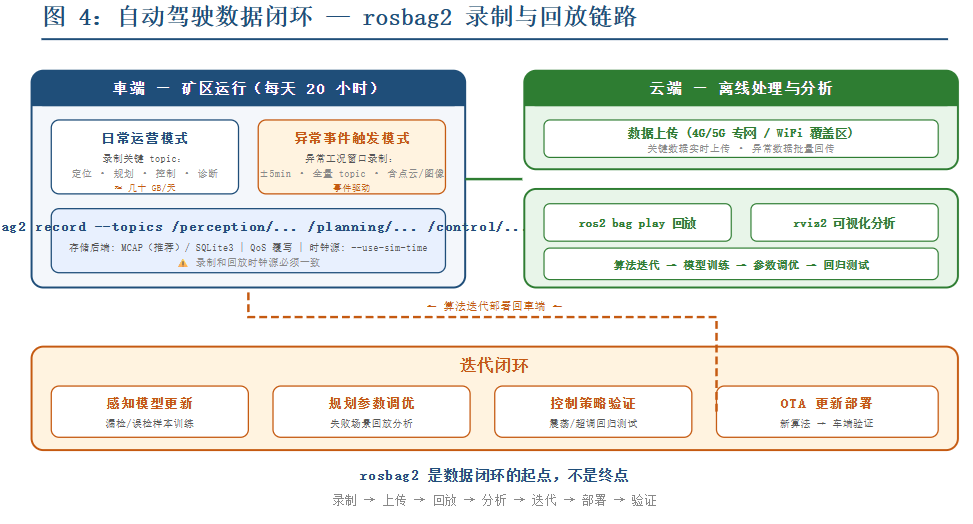
图 4:自动驾驶数据闭环 — rosbag2 录制与回放链路
很多人聊 ROS2 都在聊通信、调度、实时性,但我觉得 ROS2 最被低估的能力其实是 rosbag2
和相关的数据闭环支持。
自动驾驶是一个数据驱动的系统。感知模型需要数据训练,规划参数需要数据调优,控制策略需要数据验证。所有这些的前提是你能把车上的数据完整、准确、高效地录下来,然后能方便地回放和分析。
rosbag2 就是做这个的。相比 rosbag1,rosbag2 最大的改进是支持了存储后端的插件化——你可以存
SQLite3(默认),也可以换 MCAP 格式。MCAP 是一个专门为机器人数据设计的序列化容器,支持按
topic 和时间的随机访问、压缩、append-only 写入,比 SQLite3 更适合长时间高频率的录制场景。
矿卡每天运行 20 小时,如果全量录制所有 topic,一天的存储量大约是——
等一下,你可以不算得很精确,但大体上:4 个激光雷达 × 4.8MB/帧 × 10Hz × 20h
≈ 13TB,加上摄像头数据就更大。实际工程中全量录制不现实,需要选择性录制。
rosbag2 支持 topic 过滤和录制策略配置。工程上常见的做法是分两种模式:
日常运营模式:只录制关键 topic——定位结果、规划轨迹、控制指令、车辆状态、诊断信息。这些数据量很小,一天也就几十
GB,但足够做自动化的性能监控和异常检测。如果控制误差持续偏大或者规划失败次数增多,运维人员能第一时间发现。
问题复现模式:当出现异常工况(比如感知漏检、规划超时、控制震荡)时,触发一个事件录制——把异常发生前后
5 分钟的所有 topic 全量录下来,包括原始点云和图像。这就能支持离线的问题分析和算法迭代。
rosbag2 的回放能力同样重要。你可以在本地用 ros2 bag play 把录下来的数据按原始时间戳重放给算法节点,模拟车上的真实时序。这样你就能在办公室里复现矿区的具体场景,调整算法参数,重新跑一遍看效果。很多自动驾驶公司的「数据闭环」就建立在
rosbag2 录制→云端上传→离线回放→算法迭代→OTA 更新这条链路上。
有一个容易踩的坑:rosbag2 录制时的时间戳。
ROS2 默认使用系统时钟(system clock),但自动驾驶系统通常使用仿真时钟(simulation
clock)或者传感器硬件时钟。如果录制和回放时的时钟源不一致,时间戳会错位,回放出来的时序就跟真实场景对不上。工程上应该在
rosbag2 录制配置里显式指定 `--use-sim-time` 或者自定义 `/clock`
topic,确保录制和回放的时钟一致性。
矿卡特有的几个工程坑
前面讲的都是通用自动驾驶工程实践,但矿卡有一些特有的问题,ROS2 用得不对会直接导致系统不稳定。
第一个坑是震动。
矿区的路面条件比公路差得多,矿卡的振动频率和幅度都远超乘用车。ROS2 的 DDS discovery
机制在震动环境下有一定概率出现节点短暂掉线后重新发现的情况——这不是 DDS 的 bug,而是网络层面的瞬时抖动被震动放大了。如果你用了
Fast-DDS 的默认配置,discovery 超时和重试参数可能不够鲁棒。
解决办法不是换 RMW 实现,而是调整 discovery 相关的 QoS 参数——增大 lease
duration、缩短 announcement period——让系统对短暂的通信中断更宽容。车载以太网的物理接口也要加固,矿卡上松一个网线接头是常有的事。
第二个坑是温度。
内蒙古露天矿夏天驾驶室温度能到 50°C 以上,工控机散热是个大问题。ROS2 节点在这种温度下,如果
executor 配置不当(比如用了默认的单线程 executor 导致 CPU 核心长期满载),容易触发温度保护降频,延迟毛刺就出来了。
工控机选型和 executor 配置要一起考虑。建议用多线程 executor 把不同优先级的节点分散到不同
CPU 核心上,留 1-2 个核心给系统进程和散热管理。ROS2 的 CPU affinity 配置可以显式绑定节点到指定核心。
第三个坑是远程操作。
矿卡虽然是无人驾驶,但不是完全不依赖人。异常工况下需要远程安全员接管。ROS2 的通信链路从车端延伸到远程操控台,中间可能经过
4G/5G 专网或者 WiFi 覆盖区。
远程接管对通信延迟的要求是 200ms 以内。ROS2 的 DDS 在局域网内可以做到微秒级延迟,但跨
4G/5G 就完全是另一回事。一个可行的方案是在远程操控台也部署一套 ROS2 系统,与车端做 topic
bridge——车端选择性桥接关键 topic(车辆状态、前视摄像头压缩图像、诊断信息)到云端,远程操控指令(方向盘、油门、刹车)桥接回车端。
ros2_router 或者 Zenoh 桥接是 ROS2 生态里做这件事的两个主流方案。Zenoh
的 DDS bridge 可以在保持 ROS2 原生 API 不变的前提下,把通信协议从 DDS 换成更适合广域网的
Zenoh 协议,同时保留 QoS 语义。
回到那个矿
那天下午,矿卡在装载区自动对位,电铲把 60 吨矿石倒进车斗,整个过程不到三分钟。然后矿卡自己起步,沿着规划好的路线往排土场开。
坐在旁边的安全员跟我说了一句话:这套系统上了之后,他每天的工作从「开了八个小时车累得要死」变成了「盯着屏幕看八个小时参数」。
ROS2 在其中的位置,不是那个台前表演的主角,而是幕后把传感器数据、算法推理、控制指令、远程通信、数据回传这些环节串联起来的管道。一个自动驾驶系统能做到什么程度,很大程度上取决于这个管道的可靠性、实时性和可维护性。
ROS2 不是万能的,但在自动驾驶工程里,它确实是把那些「能用」和「能跑五年不出大问题」区分开的关键基础设施。
理解它的边界,知道什么时候用它,什么时候绕过它,比学会一百个 ROS2 命令更重要。
| 






 订阅
订阅