| 编辑推荐: |
本文介绍了自动驾驶的预测逻辑相关内容。希望对您的学习有所帮助。
本文来自于微信公众号linux源码阅读,由火龙果软件Alice编辑、推荐。
|
|
1、简介
在自动驾驶系统中,感知模块提供了当前环境的状态信息(如车辆、行人、交通信号灯等),但要做出最优决策,还需要理解这些物体的未来行为。这就是预测模块的核心任务:基于当前状态和历史数据,预测其他移动物体的行为轨迹,帮助无人车做出安全、高效的驾驶决策。
Apollo 的预测模块通过实时性、准确性以及自适应学习能力,实现了对复杂动态环境的理解与应对。
预测模块的重要性
1. 实时性要求
在高速行驶环境中(如60 km/h ≈ 16.67 m/s),每0.25秒车辆就会前进约4.17米;
为了确保安全,必须在短时间内(如每0.1秒)更新预测结果,避免碰撞风险;
实时预测让无人车能够快速响应周围物体的变化,保持行车安全。
2. 准确性需求
如果预测一辆车即将并入本车道,则需提前减速避让;
若预测对方车辆将继续保持原车道行驶,则可维持当前速度或加速超车;
准确的预测有助于减少不必要的减速或变道操作,提升行驶效率。
预测的基本方式:生成未来路径
Apollo系统通过为每个动态障碍物生成一条或多条可能的未来轨迹(预测路径) 来表达其行为预测。
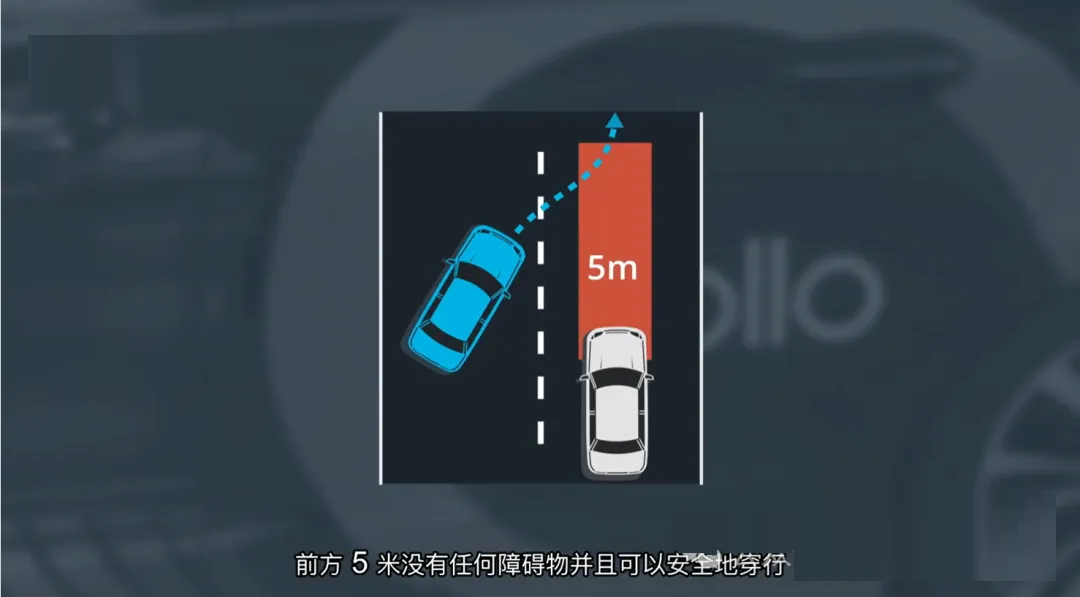
示例
:一辆前方车辆正在向右变道并驶向匝道,同时开始减速。
系统会基于其当前状态(位置、速度、加速度、航向角等)以及道路结构信息(如车道线、匝道位置),预测出一条符合右转+减速行为的轨迹。
这条轨迹代表了该车辆在未来几秒内可能的行驶路径。
预测的时间维度与动态更新
预测不是一次性的,而是在时间上连续进行。
在每一个控制周期(例如每100ms或200ms),系统都会:
获取最新的感知数据;
重新评估每个动态物体的状态;
重新计算并更新其未来的预测路径。
这种实时更新机制确保了预测结果能紧跟实际交通变化,提高系统的响应能力与安全性。
多物体协同预测
系统不会只预测单一车辆,而是对环境中所有可感知的动态障碍物并行进行预测。
所有障碍物的预测路径共同构成一个动态的未来场景模型,即“我们预计接下来几秒内,各个物体将如何移动”。
学习新行为的能力
现实路况复杂多变,静态模型难以覆盖所有场景;
预测模块应具备自适应学习能力,通过不断积累数据,提升对新情况的处理能力;
多元数据训练使得算法能够随着时间推移而改进,增强系统的鲁棒性和泛化能力
预测模块是连接感知与规划决策的关键桥梁。
Apollo通过实时、动态地为周围每一个移动物体生成未来路径,构建出一个“未来几秒内的交通演化图景”,从而使无人车能够在复杂动态环境中做出合理、安全的驾驶决策。
关键词:行为预测、轨迹预测、动态障碍物、实时更新、多目标预测、决策支持
2、不同的预测方式
基于模型预测(Model-based Prediction)和数据驱动预测(Data-driven
Prediction)
一、两种预测方法的对比总结
二、例子分析(T型路口)
非常经典:
“无人车在T型路口,看到左侧来车,不确定是右转还是直行。”
基于模型预测的做法:
构建两个候选行为模型:
模型A:右转 → 生成一条绿色弧形轨迹
模型B:直行 → 生成一条蓝色直线轨迹
初始时,假设两个模型先验概率相等
随着观测:
若车辆向右偏移、打转向灯、进入右转车道 → 绿色轨迹匹配度上升 → 更新为右转概率更高
若车辆保持直行方向、速度不变 → 蓝色轨迹更匹配 → 倾向于直行
使用贝叶斯滤波(如IMMPF,交互式多模型粒子滤波)动态更新各模型的置信度
优势体现:逻辑清晰、符合人类推理、易于集成交通规则(如“右转让直行”)
三、数据驱动预测如何处理这个场景?
不显式定义“右转”或“直行”模型
使用历史轨迹序列(位置、速度、加速度)作为输入
训练一个神经网络(如LSTM或Transformer),直接输出未来5秒的轨迹分布
网络可能自动学到:
“如果车靠近路口中心且减速 → 更可能右转”
“如果车保持车道中心 → 更可能直行”
优势体现:能捕捉细微驾驶习惯(如某些司机右转前会先左偏)
四、到底哪种更好?
答案:没有绝对的“更好”
3、基于车道的预测(Lane Sequence-based Prediction)
Apollo 基于车道序列(Lane Sequence)的预测方法 非常关键,这是百度 Apollo
在结构化城市道路中实现高效、可解释行为预测的核心技术之一。
一、核心思想
Apollo 认为:在结构化道路(如城市道路、高速公路)中,车辆的宏观行为主要由其行驶的“车道路径”决定。
因此,预测 = 推断目标车辆未来将经过哪些车道 → 即“车道序列”(Lane Sequence)
这种方法将复杂的连续轨迹预测问题,转化为一个离散的路径选择问题,大大降低了计算复杂度,并增强了可解释性。
二、车道序列预测的基本流程
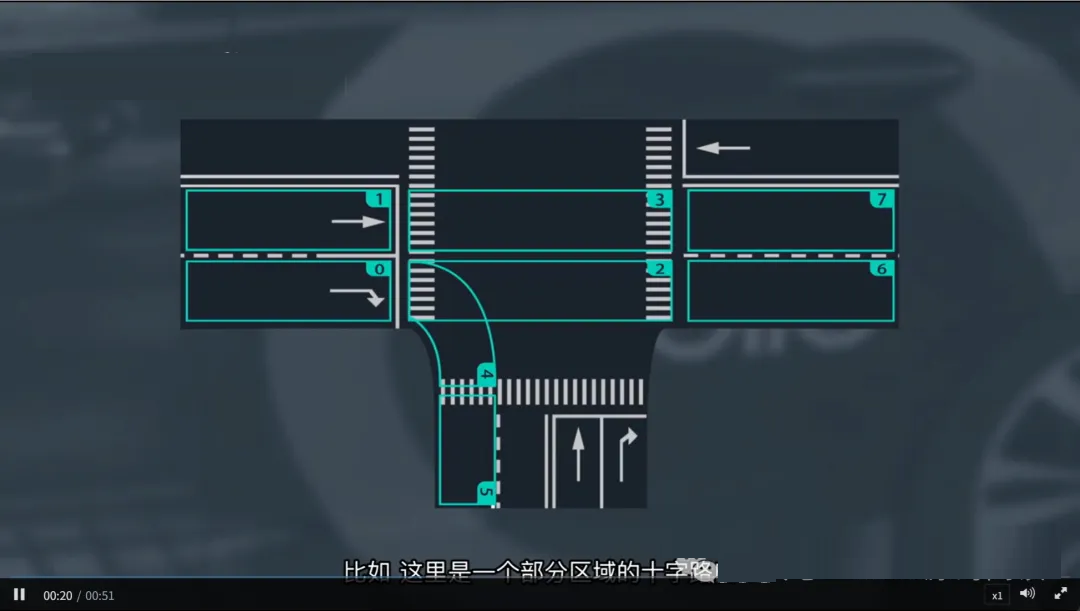
1. 道路分段与拓扑建模(Road Segmentation & Topology)
将整个道路网络划分为多个逻辑区域(segments),每个区域对应一段具有明确语义的道路单元。
例如:直行段、左转车道、右转匝道、交叉口内部区域等。
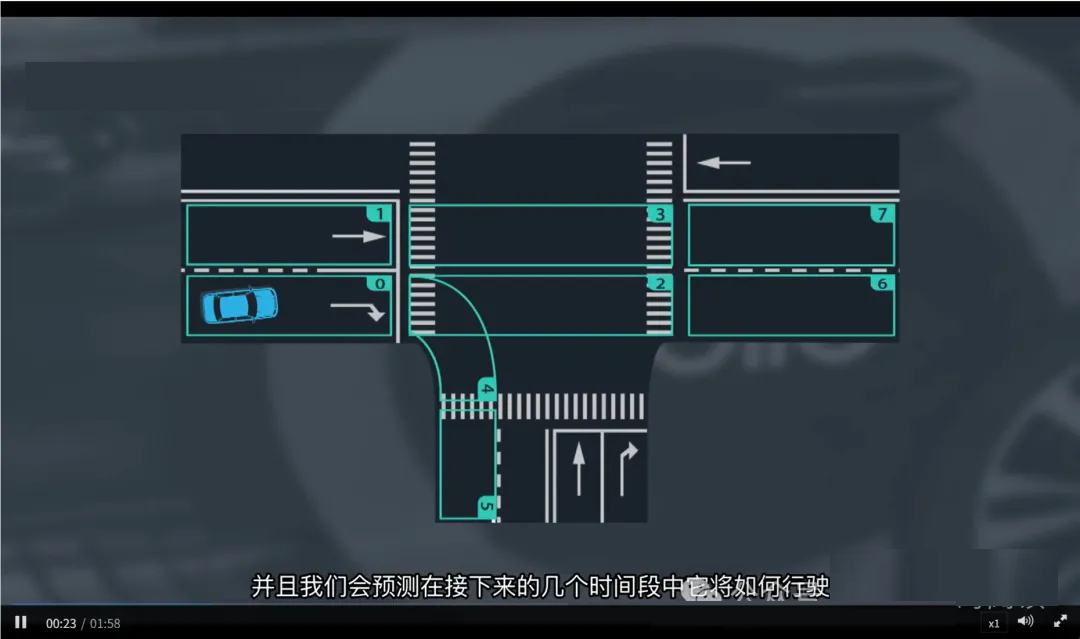
每个车道都有唯一 ID(如 Lane ID: 0, 1, 2, ...),并构建车道拓扑图(Lane
Graph),记录车道之间的连接关系(前驱/后继)。
例子:“0 → 1 → 3 → 7” 就是一条合法的车道序列,表示车辆从 Lane 0 出发,依次经过
Lane 1、3,最终进入 Lane 7。
2. 枚举候选车道序列(Candidate Lane Sequences)
对于目标车辆当前所在车道,系统根据拓扑图枚举所有可能的后续车道路径。
例如:一辆车在直行车道接近十字路口,可能的车道序列有:
直行:Lane_A → Lane_B → Lane_C
右转:Lane_A → Lane_D → Lane_E
左转:Lane_A → Lane_F → Lane_G
每个车道序列代表一种宏观行为模式(behavioral mode):
直行、右转、左转、掉头、变道、停车等
这正是我们之前学到的“基于模型预测”的体现:每个车道序列就是一个“行为模型”!
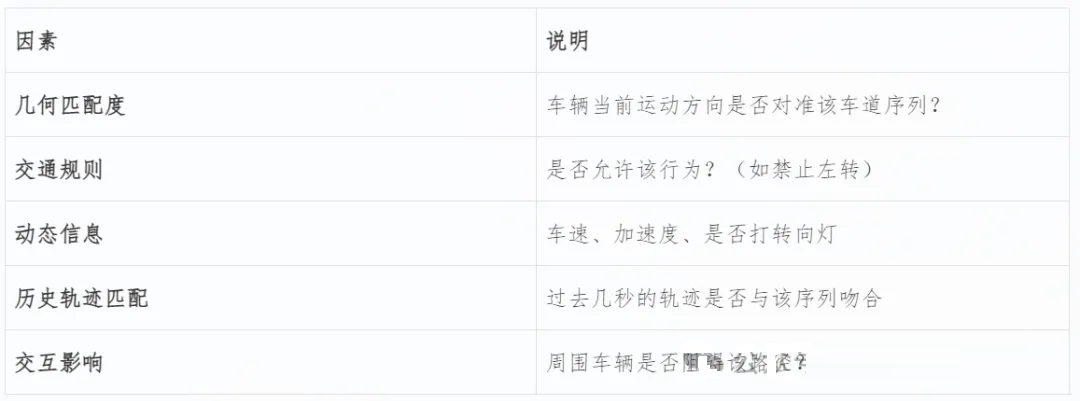
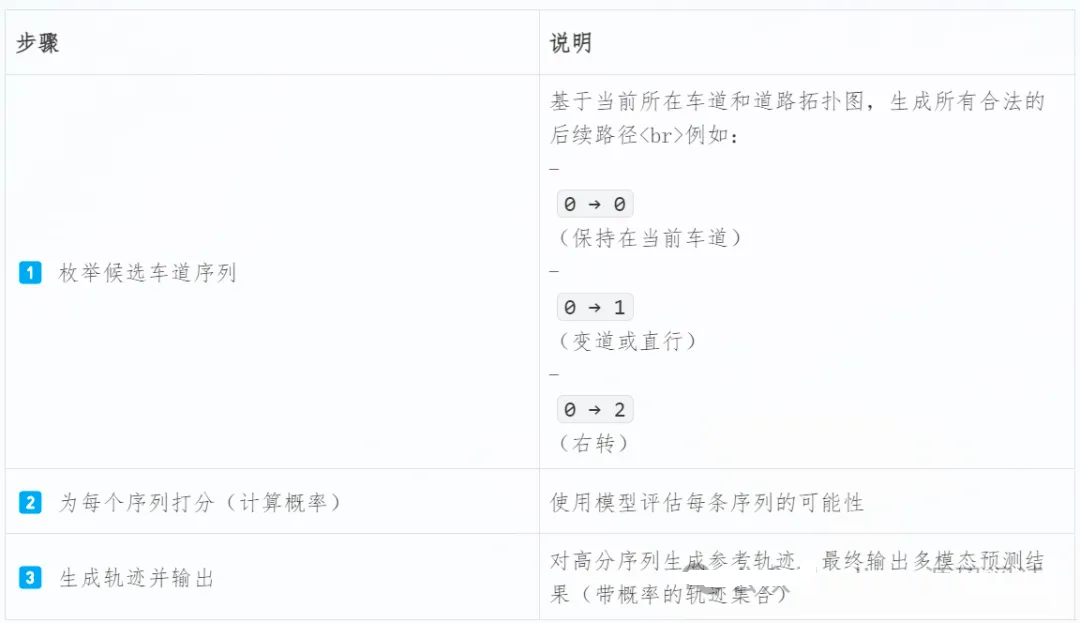
3. 给每个车道序列打分(Scoring)
系统会为每个候选车道序列计算一个置信度分数,综合考虑以下因素:
初始时所有序列概率相同,随着观测更新,某一条序列的得分逐渐升高。
4. 生成预测轨迹(Trajectory Generation)
对每个高分车道序列,生成一条参考中心线(reference line)
在该中心线上,结合车辆动力学模型(如 bicycle model)生成一条平滑的未来轨迹(如 5 秒内的位置序列)
最终输出:多模态预测结果(Multiple hypotheses),每条轨迹对应一个车道序列 + 概率值
例如:
轨迹 A(蓝色):车道序列 0→1→3→7,概率 60% → 直行
轨迹 B(绿色):车道序列 0→2→5,概率 35% → 右转
轨迹 C(橙色):车道序列 0→4,概率 5% → 停车
4、障碍物状态(Obstacle State)
预测的本质是“根据当前和历史状态,推断未来行为”
因此,精准、丰富、语义化的状态描述 是高质量预测的前提。
一、什么是“障碍物状态”?
在 Apollo 或其他自动驾驶系统中,“障碍物”泛指所有动态交通参与者:
车辆(cars, trucks)
行人(pedestrians)
非机动车(bicycles, electric scooters)
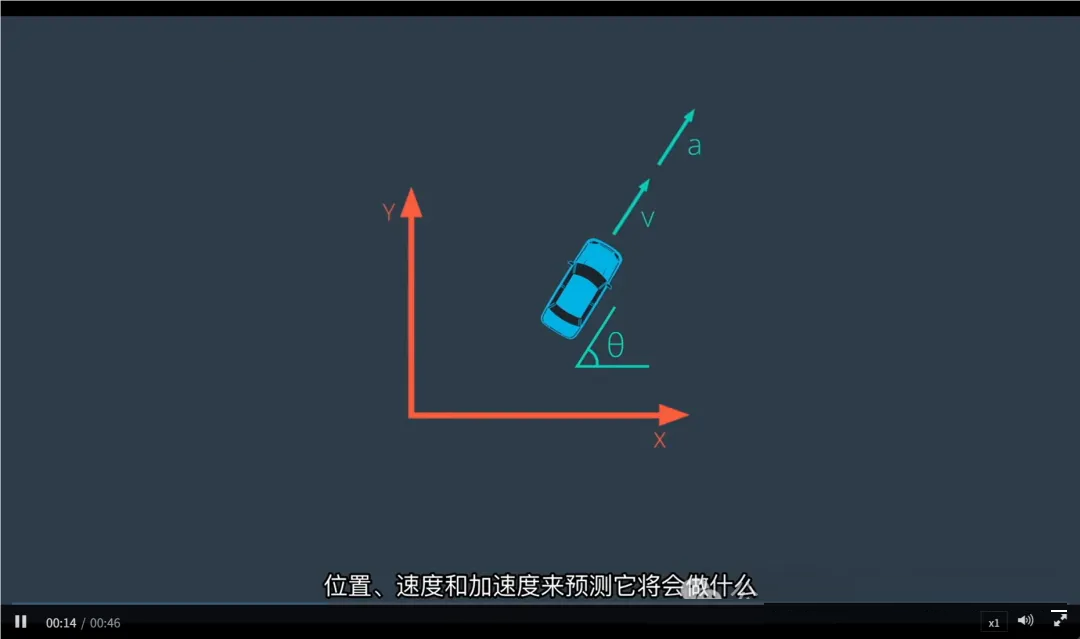
障碍物状态(Obstacle State) 就是用来描述这些物体在某一时刻的运动学 + 几何 + 语义信息的向量集合。
二、障碍物状态的核心维度
三、为什么需要这些额外的状态信息?—— 结合你的例子深入理解
场景举例:一辆车在主干道上行驶,接近十字路口
所以:状态是输入,车道序列是假设,打分是推理过程
5、预测目标车道
百度 Apollo 预测系统中从 行为建模 → 序列选择 → 模型训练 是一个完整闭环逻辑。
核心思想:将复杂的轨迹预测问题,转化为“车道序列选择 + 概率排序”的离散决策问题。
一、问题分解:从“轨迹预测”到“车道选择”
原始问题(复杂):
“这辆车未来5秒会走哪条轨迹?”
输出是无限维的连续空间(无数种可能的曲线)
难以保证符合交通规则
计算成本高
转化后的问题(简化)
“这辆车接下来会经过哪些车道?即它的车道序列是什么?”
输出是有限个候选路径(如:直行、右转、左转)
每个路径对应一条语义明确的行为模式
可结合地图拓扑约束,排除非法路径
二、车道序列选择的三步法
这是一个闭环反馈过程:随着车辆移动,状态更新,序列概率也动态调整。
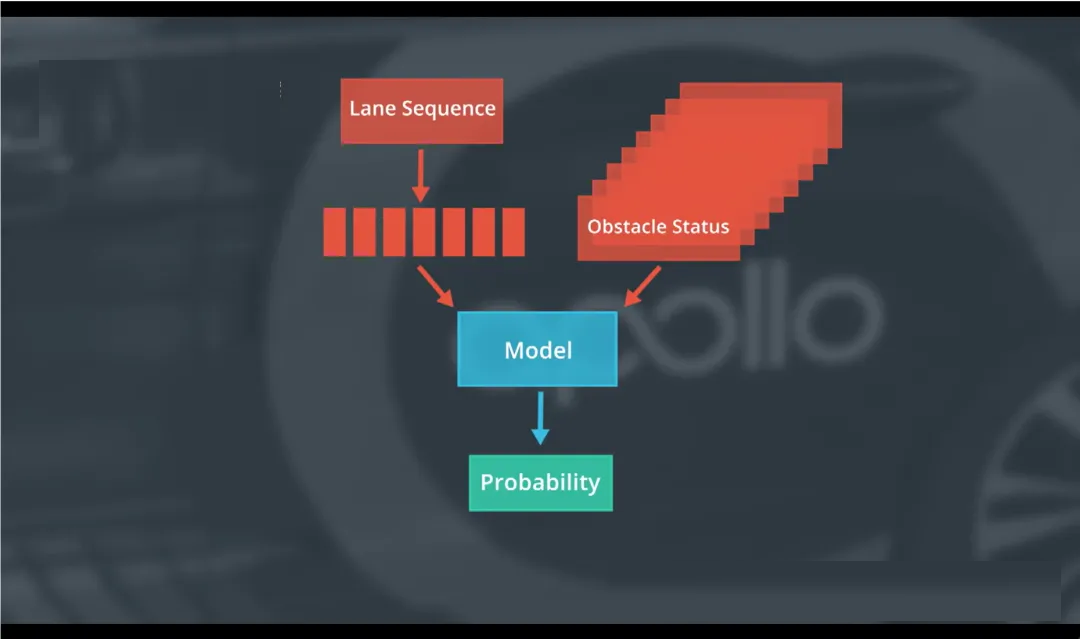
三、如何计算每个车道序列的概率?—— 构建预测模型
你需要一个评分模型(Scoring Model),其输入和输出如下:
输入(Input Features):
输出(Output):
每个候选车道序列的概率分布:
P([0→1→3]) = 0.65 → 直行
P([0→2→5]) = 0.30 → 右转
P([0→4]) = 0.05 → 停车
四、模型如何学习?—— 经验性训练(Data-Driven Training)
我们希望模型能够学习新的行为,因此应该使用观测数据对模型进行经验性训练。
训练目标:
让模型学会:
给定当前状态 + 历史行为 → 输出最接近真实行为的车道序列概率分布
常用方法:
分类模型:将每个车道序列视为一个类别,训练 softmax 分类器
排序学习(Learning to Rank):让正确序列得分最高
深度模型:使用 LSTM / Transformer 编码历史状态,MLP 或 GNN 处理车道图
五、模型如何迭代更新?—— 持续学习闭环
随着记录随着时间的增加,模型可以自我迭代更新,精确度不断提升。
自动驾驶系统的数据飞轮:
[真实世界驾驶]
↓
收集大量“状态 + 实际行为”样本
↓
标注真实车道序列(通过高精地图+轨迹对齐)
↓
训练/微调预测模型
↓
新模型上线 → 更准确预测
↓
收集更多高质量数据 → 再训练
6、递归神经网络(RNN)
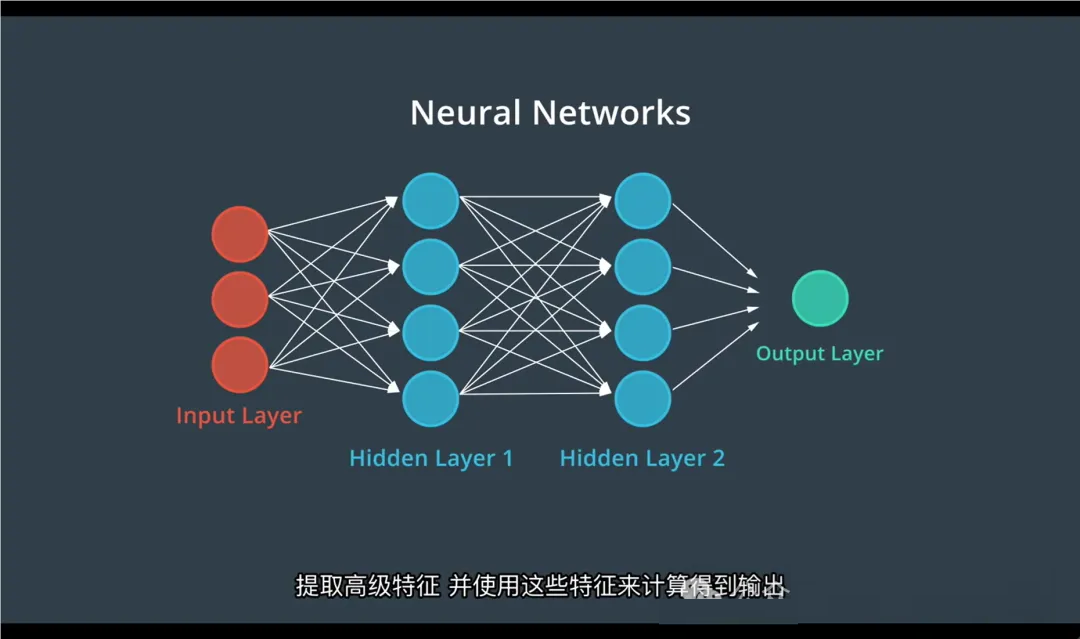
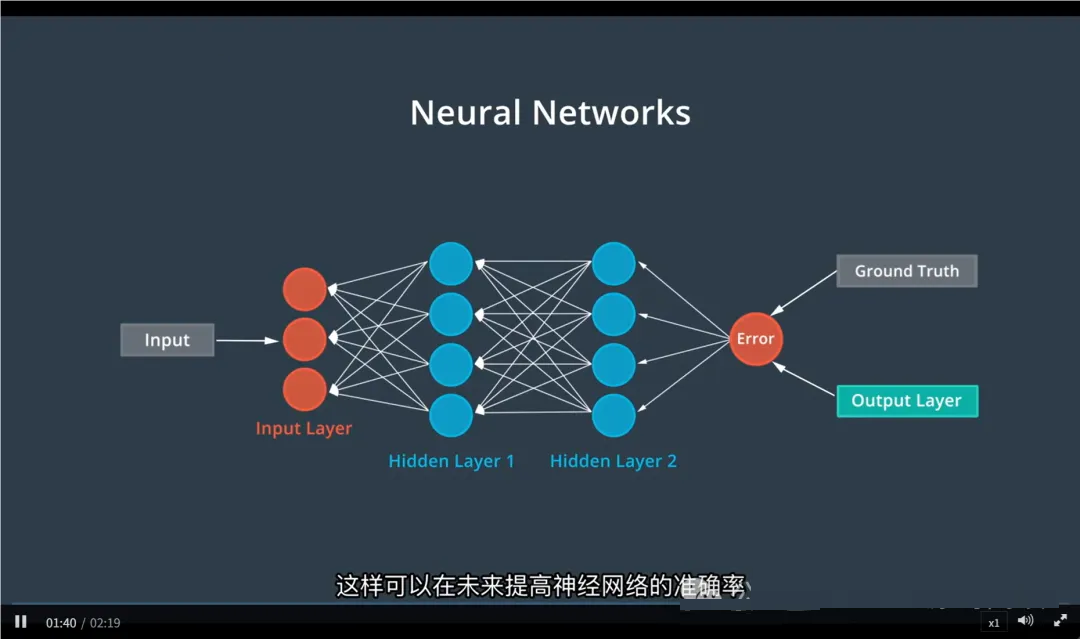
一、神经网络回顾
神经网络是一种可以自动学习数据规律的模型。
它由多层结构组成:输入层 → 隐藏层(提取特征) → 输出层。
例如:
给一张图片,判断是否包含汽车。
神经网络会在中间层自动识别出“车轮”“车窗”等特征,最终给出判断结果。
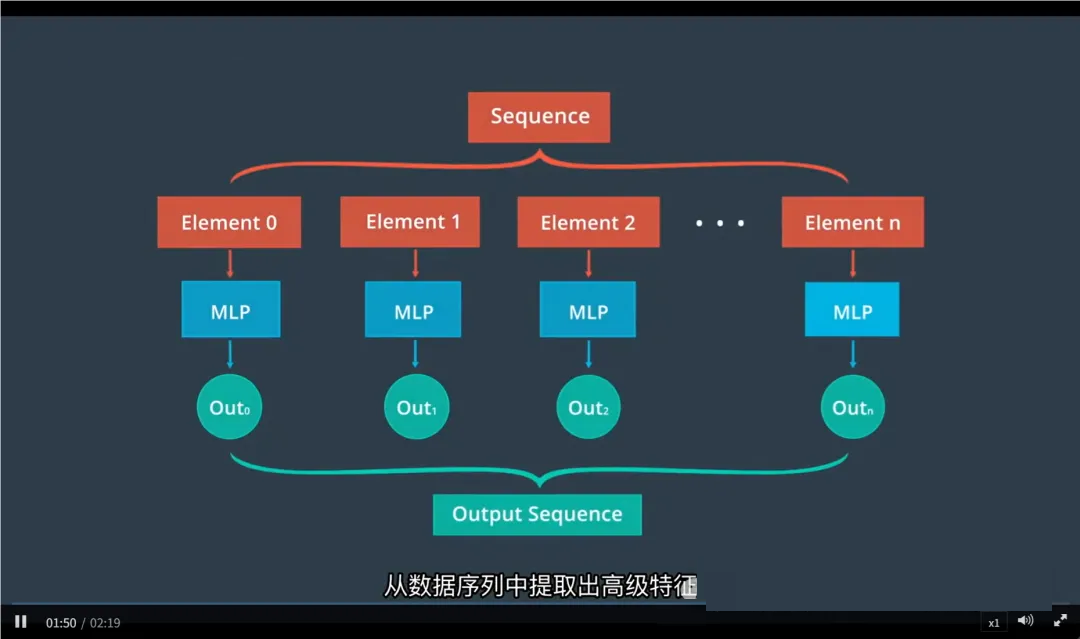
这种基本结构叫做多层感知机(MLP),它处理的是独立的数据,比如单张图像。
二、时间序列数据的挑战
有些数据是按时间顺序排列的,比如:
一段语音
一段文字
车辆连续的位置记录
这类数据的特点是:前后有关联。
只看当前时刻,无法准确理解整体行为。
普通神经网络(如MLP)无法记住“之前发生了什么”,因此不适合处理这类任务。
三、RNN:会“记忆”的神经网络
递归神经网络(RNN,Recurrent Neural Network)就是为了解决这个问题而设计的。
它的核心特点是:具有记忆能力。
RNN通过一个特殊的连接,把当前步骤的处理结果传递到下一步,使得网络在处理当前数据时,也能参考之前的信息。
RNN的基本工作方式:
每个时间步输入一个数据(如车辆当前位置);
RNN单元结合当前输入和上一步的记忆,进行计算;
输出当前预测,并更新记忆,传给下一步。
这个过程像“走一步看一步”,同时记住历史。
四、RNN的结构特点
RNN由多个相同的“单元”重复组成,每个单元处理序列中的一个元素。
关键设计:
在单元之间增加一条反馈连接,把上一步的输出(记忆)传给下一步。
这样,整个网络就能捕捉序列中的时间依赖关系。
五、RNN如何学习?
和其他神经网络一样,RNN通过训练来学习。
训练过程包括:
输入一段序列数据(如车辆过去几秒的运动);
网络输出预测结果;
将预测结果与真实结果比较,计算误差;
使用反向传播算法,把误差逐层传回,调整网络中的参数。
经过大量数据训练,RNN就能学会从历史数据中预测未来行为。
简单说:RNN = 普通神经网络 + 记忆功能,专门用来处理有时间顺序的数据。
7、递归神经网络(RNN)在目标车道预测中的应用
一、目标车道预测的任务
在自动驾驶中,我们需要预测其他车辆未来会行驶在哪条车道上。
这被称为目标车道预测,它是轨迹预测的关键一步。
百度 Apollo 采用一种结合车道序列与历史状态的方法,并使用递归神经网络(RNN)
来建模车辆的行为趋势。
二、RNN 为什么适合这个任务?
车辆的行驶意图不是凭空决定的,而是由过去一段时间内的运动状态逐步体现出来的。
例如:
一辆车连续向右偏移
速度逐渐降低
靠近右转车道
这些随时间变化的状态构成了一个时间序列。
RNN 擅长处理这类数据,因为它能“记住”过去的信息,从而判断车辆是否准备变道或转弯。
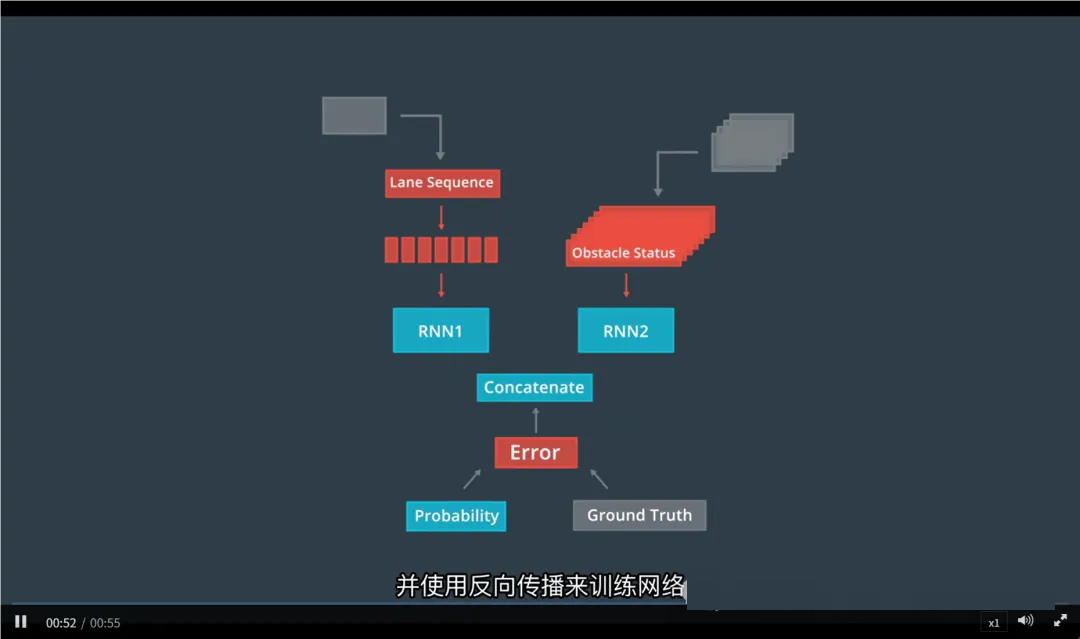
三、Apollo 的 RNN 预测模型结构
Apollo 使用两个并行的 RNN 分支,分别处理不同类型的信息,最后融合输出预测结果。
1. 车道序列 RNN
输入:车辆过去依次经过的车道 ID 序列(如:Lane 0 → Lane 1 → Lane 2)
作用:学习车辆在道路网络中的行驶路径模式
2. 对象状态 RNN
输入:车辆过去多个时刻的状态,包括:
位置、速度、加速度
朝向
到车道线的距离
作用:学习车辆的运动行为趋势
两个 RNN 都能捕捉“时间依赖性”——即当前行为受过去状态影响。
3. 融合与打分
将两个 RNN 的输出连接(concatenate) 在一起
输入到一个全连接神经网络(或其他分类器)
输出:每个候选车道序列的概率
# 最终,概率最高的车道序列被选为预测结果。
[车道序列历史] → RNN-A ┐
→ 拼接 → 全连接网络 → 各车道序列概率 → 选择最高者
[状态历史] → RNN-B
|
四、模型如何训练?
训练数据来自真实驾驶记录,每条数据包含:
训练过程:
将输入送入模型,得到预测的概率分布;
将预测结果与真实标签比较,计算误差;
使用反向传播(Backpropagation)调整网络参数;
重复多次,直到模型能准确预测车道选择。
随着数据不断积累,模型的预测能力持续提升。
8、轨迹生成:预测的最后一步
在自动驾驶预测系统中,轨迹生成是整个流程的最后一步。
它的任务是:
根据前面预测出的“目标车道序列”,生成一条车辆最可能行驶的未来轨迹。
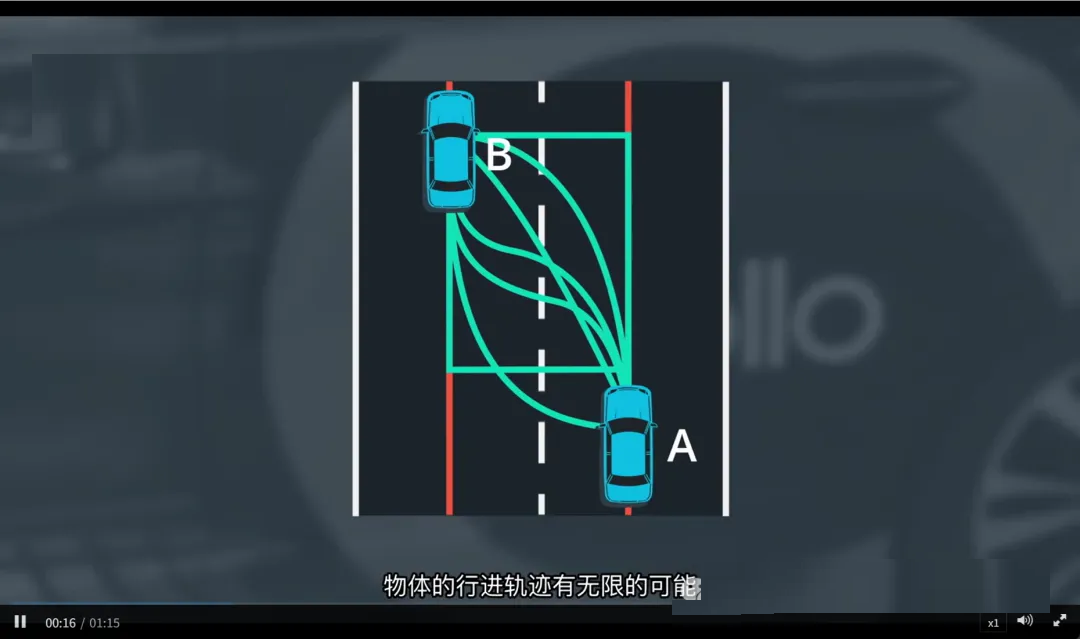
一、问题的复杂性
在空间中任意两个点 A 和 B 之间,理论上存在无限多条可能的路径:
可以是直线、曲线、急弯、绕行……
每条路径都是一条“候选轨迹”。
如果逐个列举再筛选,计算量巨大,不现实。
因此,我们需要一种高效且符合物理规律的方法,来生成合理且平滑的轨迹。
二、轨迹生成的核心思路
不是“枚举所有轨迹”,而是:
通过设置合理的约束条件,直接构造出最可能的轨迹。
这些约束帮助我们“缩小范围”,只保留物理可执行、符合驾驶习惯的轨迹。
三、关键约束条件
1. 与车道中心对齐
假设车辆在行驶过程中会尽量保持在车道中央。
轨迹应贴近目标车道的参考中心线(Reference Line)。
这大大减少了不合理偏移的可能。
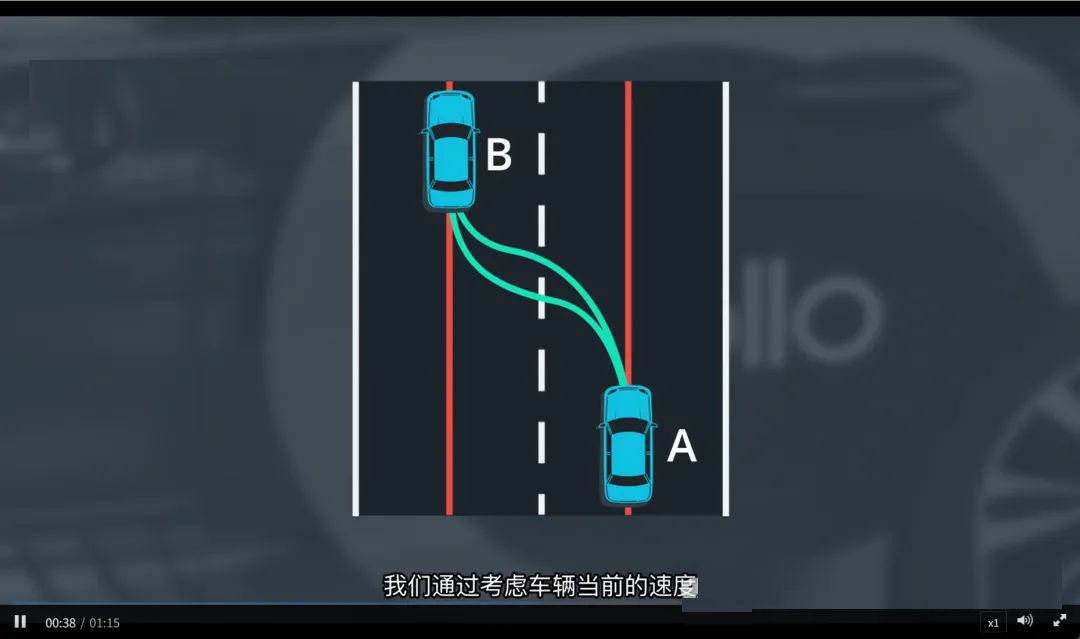
2. 符合车辆动力学
考虑车辆当前的:
位置
速度
加速度
朝向(航向角)
生成的轨迹必须是车辆能够实际执行的,不能出现瞬间转向或急停。
3. 起止状态匹配
初始状态:车辆当前的位置和朝向(称为“姿态”,Pose)
终止状态:预测在目标车道上的预期位置和朝向
轨迹必须从初始状态平滑过渡到终止状态
四、如何生成轨迹?—— 多项式拟合
实际中,Apollo 等系统采用数学建模的方法,而不是枚举。
常用方法:多项式曲线拟合
常见模型:五次多项式(Quintic Polynomial)
形式:s(t) = a₀ + a₁t + a₂t² + a₃t³ + a₄t⁴ + a₅t⁵
其中 s(t) 表示横向或纵向位移,t 是时间
为什么用五次多项式?
可以精确匹配6个边界条件:
初始位置
初始速度
初始加速度
终止位置
终止速度
终止加速度
生成的轨迹平滑、连续、无突变,适合车辆行驶
这就像画一条“自然过渡”的曲线,起点和终点都完美贴合车辆状态。
五、轨迹生成流程总结
1. 输入:预测出的目标车道序列
2. 确定终点:在目标车道上设定合理的终点位置和朝向
3. 提取起止状态:当前状态(起点) + 预期状态(终点)
4. 应用约束:贴合车道中心、符合动力学
5. 数学拟合:使用多项式(如五次多项式)生成平滑轨迹
6. 输出:一条未来3~5秒内的连续轨迹点序列 | 






 订阅
订阅