| 编辑推荐: |
文章主要介绍了ECU应用层代码编译全流程相关内容。希望对您的学习有所帮助。
本文来自于微信公众号汽车电子工程圈,由火龙果软件Alice编辑、推荐。 |
|
当我在做软件集成时,看见build一条一条log往下走,我就特别好奇这背后都在做什么。
于是问了下Deepseek:ECU应用层软件编译成可执行文件都需要经历哪些过程?得到的回答很满意,本回答虽然有非常多的专业术语,但是作为一篇类似于综述的文章,还是一个不错的引导。
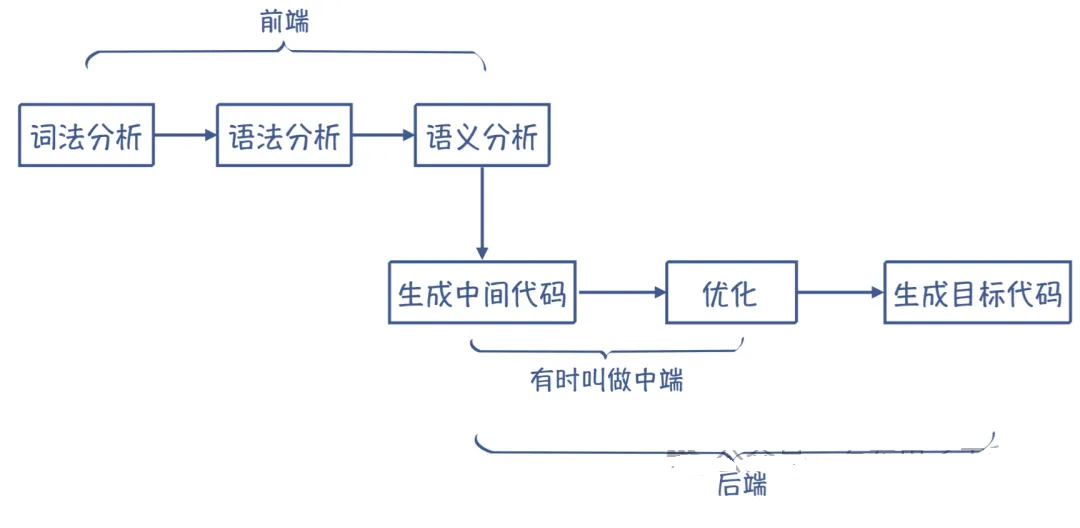
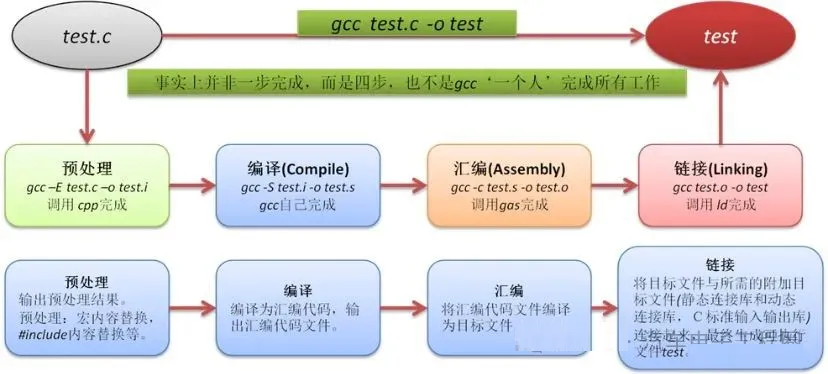
ECU(电子控制单元)应用层Simulink模型产生的代码,要最终变成可以在目标微控制器上运行的可执行文件,需要经过一个标准的软件编译流程。这个流程通常称为Build过程,主要包含以下几个核心步骤:预处理,编译,汇编和链接,如下所示:

1. 预处理
预处理是指在编译器正式处理源代码之前,对源代码进行文本级别的处理和修改,其主要操作包括:
宏展开,即将源代码中定义的宏替换为其定义的内容。
头文件包含,即将 `#include` 指令指定的头文件内容插入到源文件中。
条件编译,根据 `#if`, `#ifdef`, `#ifndef`, `#else`, `#elif`,
`#endif` 等指令,决定哪些代码块被包含在后续编译中。
删除注释,移除源代码中的注释。
特殊指令处理,即处理其他预处理器指令(如 `#pragma`, `#line`, `#error`)

预处理的输入的是模型生成的 .c 和 .h源代码文件,其输出是经过文本替换和修改后的“预处理过的”源代码(通常是
.i文件,但其输出通常是临时的,对用户不可见)。
2. 编译
编译是指将预处理后的高级语言源代码(C/C++)翻译成目标处理器架构的汇编语言代码。其主要操作包括:
词法分析,即将源代码字符流分解成有意义的词法单元。
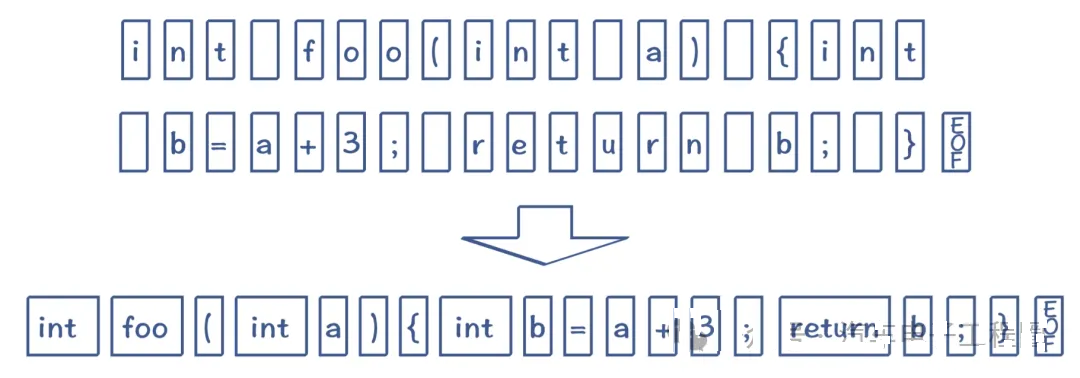
语法分析,根据语法规则将词法单元组合成语法结构(如表达式、语句、函数、模块),构建抽象语法树。
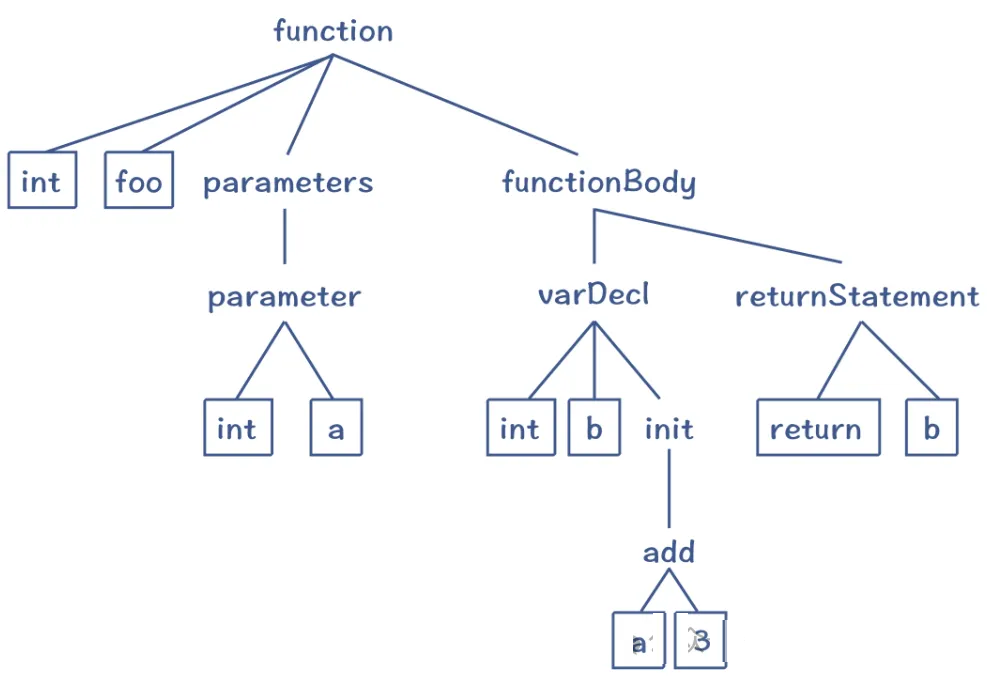
语义分析,即检查程序的语义正确性(如类型检查、变量声明检查、函数调用匹配)。
中间代码生成,生成一种与机器无关的中间表示形式。
代码优化,在中间代码层面进行各种优化(如常量折叠、公共子表达式消除、死代码消除、循环优化等),以提高生成代码的效率(执行速度或大小)。
目标代码生成,将优化后的中间代码转换成特定处理器架构的汇编语言代码
编译的输入是预处理后的源代码。编译的输出是针对每个 .c文件生成的汇编语言文件(通常是.s或.asm文件)。
3. 汇编
汇编是将汇编语言代码翻译成机器可以识别的目标文件。汇编的主要操作有:
将汇编指令逐条翻译成对应的机器指令(二进制操作码)。
处理汇编器指令(如定义数据段、代码段、符号标签)。
解析符号引用(函数名、变量名),但此时地址通常是临时的或未解析的。
生成可重定位的目标文件。这意味着文件中的代码和数据地址还不是最终在内存中运行的地址,还需要链接器来最终确定。

汇编的输入是编译器生成的汇编语言文件(.s/ .asm)。输出是目标文件(通常是.o或.obj文件)。每个.c文件经过编译和汇编后产生一个.o文件,这个文件包含机器码、数据、符号表(函数和变量名及其属性)和重定位信息(哪些地址需要链接时修正)等。
4. 链接
链接是将多个目标文件以及所需的库文件组合起来,解析它们之间的相互引用(函数调用、变量访问),并分配最终的运行内存地址,生成一个完整的可执行文件。
链接的主要操作有:
符号解析,链接器扫描所有输入的目标文件和库文件,构建一个全局符号表。对于每个符号引用(如调用的函数名、引用的变量名),查找其定义(符号的值/地址)。如果找不到定义,会报告“未定义引用”错误。
重定位:合并所有输入目标文件的代码段到一个代码区域(如 `.text`),合并所有输入目标文件的数据段到一个或多个数据区域(如
`.data` - 初始化数据, `.bss` - 未初始化数据),根据最终分配的内存布局(由链接器脚本定义),计算并修正所有目标文件中的地址引用(跳转指令地址、数据加载地址等),这些地址在之前的汇编阶段是临时的或基于0的。
库处理:链接器从指定的库文件(静态库.a/.lib或链接时动态库)中提取需要的目标模块(满足未解析符号的目标文件),将其加入到链接过程中。静态库的代码会被复制到最终的可执行文件中;动态库则只记录依赖关系,运行时才加载。
生成可执行文件格式:将链接好的代码、数据、符号表、重定位信息、程序头信息等,按照目标操作系统或加载器要求的格式(如
ELF、Intel HEX、S-Record)打包成最终的可执行文件(如 `.elf`, `.hex`,
`.s19`, `.bin`)。

链接的输入是所有模型生成代码对应的.o/.obj文件;其他必要的用户代码.o/.obj文件,比如底层软件的目标文件或库(如AUTOSAR的MCAL、CDD、服务层等),RTE生成的目标文件或库(提供应用层与BSW的接口)等,以及编译器运行时库(如
`libc`, `libm` - 提供标准C函数实现)和其他第三方库。
链接器脚本, 它定义了目标处理器的内存布局(Flash/RAM 的起始地址和大小),各个段(`.text`,
`.data`, `.bss`, `.rodata`, `.stack`, `.heap` 等)应该放置在内存中的什么位置。堆栈的起始地址和大小,入口点(程序开始执行的地址,通常是
`_start` 或 `Reset_Handler`)。
链接的输出可执行文件,比如.elf (包含丰富的调试信息、符号表、段信息), .hex或.s19`(用于Flash烧写)和.map(链接映射文件,详细描述内存分配情况、各个符号的最终地址、各个段的大小和位置)。
5. 总结流程图
以上就是ECU应用层软件编译成可执行文件都需要经历的整体过程。
这里,在ECU开发中还有几个关键点要注意:
1. 交叉编译:编译过程是在开发主机上进行的,但生成的可执行文件是运行在目标ECU的特定微控制器上的。因此使用的是交叉编译工具链。
2. 链接器脚本:对于嵌入式系统至关重要,它精确地控制了代码和数据在有限的Flash和RAM资源中的布局,直接影响程序的运行和性能。它需要与目标硬件和软件架构(如AUTOSAR内存分区)紧密匹配。
3. 底层软件集成:模型生成的代码(应用层)必须与复杂的底层软件(BSW,如驱动、通信栈、诊断协议栈、OS、RTE)正确链接在一起。这通常通过AUTOSAR配置工具生成的代码和库来实现。
4. 优化:编译器优化选项(如 `-O1`, `-O2`, `-Os`)对生成代码的性能(速度)和大小有巨大影响。在资源受限的ECU上,代码大小优化
`-Os` 通常非常重要。优化也可能影响代码的可调试性。
5. 调试信息:编译和链接时加入调试信息(如 `-g` 选项)会生成包含源代码行号、变量名等信息的
`.elf` 文件,这对于使用调试器进行源代码级调试至关重要。
6. 后处理:生成的可执行文件(如 `.elf`)通常还需要经过一些后处理步骤才能用于生产:
将 .elf转换成更适合烧录工具使用的格式(如 .hex, .s19, .bin)。
校验和计算:为整个镜像或特定内存区域计算校验和(如CRC),存储在固定位置,用于ECU启动时的完整性验证。
安全签名:对镜像进行加密签名,确保软件的来源可信和完整性(安全启动)。
因此,从模型生成代码到最终的可执行文件,是一个涉及预处理、编译、汇编、链接等多个步骤的严谨过程,需要精确配置工具链(尤其是链接器脚本)并正确集成所有必要的软件组件。 | 






 订阅
订阅