| 编辑推荐: |
本文主要介绍从计算机视觉的基本应用入手,系统讲解机器学习、神经网络及CNN的基础原理,希望对您的学习有所帮助。
本文来自于linux源码阅读,由火龙果软件Linda编辑、推荐。 |
|
感知简介
自动驾驶感知是赋予车辆“眼睛”和“大脑”的关键技术,旨在通过传感器(如摄像头、激光雷达、毫米波雷达)实时理解周围环境。其核心任务包括障碍物检测与分类(如车辆、行人)、车道线识别、交通信号灯判断等,为决策规划和控制模块提供关键信息。目前,卷积神经网络(CNN)作为最广泛使用的方法,在图像特征提取和目标识别方面展现出强大能力。
本课程将从计算机视觉的基本应用入手,系统讲解机器学习、神经网络及CNN的基础原理。在此基础上,深入探讨感知模块在无人驾驶中的具体任务,并解析百度Apollo平台感知模块的体系结构,最后介绍多传感器融合技术,以提升环境感知的鲁棒性与准确性,为构建安全可靠的自动驾驶系统奠定基础。
计算机视觉
在自动驾驶的感知系统中,计算机视觉(Computer Vision)是赋予车辆“眼睛”和“理解能力”的核心技术之一。它使车辆能够从摄像头捕获的图像中提取信息,并据此做出决策。
人类可以轻松识别图像中的物体、判断行为、理解场景关系——但对计算机而言,图像本质上只是由红(R)、绿(G)、蓝(B)三通道像素值组成的数字矩阵。如何让机器从这些数值中“看见”世界?这就是计算机视觉要解决的问题。

一、无人驾驶的四大核心视觉任务
自动驾驶中的计算机视觉主要围绕以下四个关键任务展开:
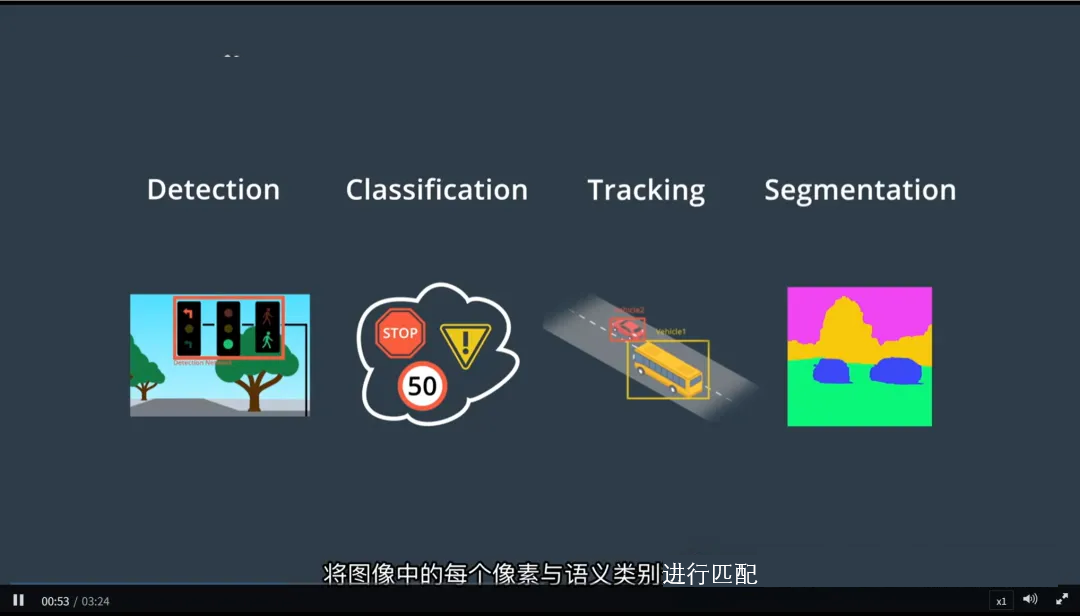
1. 检测(Detection)
- 目标:找出图像中物体的位置
- 输出:用边界框(Bounding Box)标出物体所在区域
- 示例:检测前方是否有行人、车辆、交通标志
2. 分类(Classification)
- 目标:判断检测到的物体属于哪一类
- 输出:类别标签(如“汽车”、“自行车”、“交通灯”)
- 扩展应用:行为识别(如“行人正在行走” vs “奔跑”)
3. 跟踪(Tracking)
- 目标:随时间推移持续观察移动物体
- 输出:同一物体在连续帧中的运动轨迹
- 作用:预测轨迹、判断速度、避免误检重复目标
4. 语义分割(Semantic Segmentation)
- 目标:为图像中的每个像素分配一个语义类别
- 输出:像素级分类图(如道路、车道线、天空、车辆、行人等)
- 优势:提供更精细的场景理解,尤其适用于自由空间检测
这四项任务通常协同工作:先检测 → 再分类 → 跟踪动态目标 →
分割背景环境,形成完整的视觉感知闭环。
二、以图像分类为例:计算机视觉的基本流程
图像分类是计算机视觉中最基础的任务之一,也是理解整个视觉处理流程的良好起点。
图像分类器的工作方式:
1.输入:一张图像(如摄像头拍摄的画面)
2.输出:一个类别标签(如“卡车”、“红绿灯”、“停止标志”)
虽然不同模型结构各异,但大多数视觉算法都遵循相似的处理流程:

步骤1:图像输入
- 来源:车载摄像头(单目、双目、环视等)
- 数据形式:三维数组(高度 × 宽度 × 通道数,如 H×W×3)
步骤2:预处理(Preprocessing)
在送入模型前,图像需进行标准化处理,以提升模型训练效率与泛化能力。
常见预处理操作包括:
- 调整尺寸:统一输入大小(如 224×224)
- 归一化:将像素值缩放到 [0,1] 或 [-1,1]
- 色彩空间转换:RGB → 灰度、HSV、YUV 等(根据任务需求)
- 数据增强(训练阶段):旋转、翻转、亮度调整等,增加鲁棒性
预处理的目的:让模型更快速、稳定地学习图像特征。
步骤3:特征提取(Feature Extraction)
这是视觉理解的核心环节。模型需要从原始像素中提取有意义的“特征”,用于区分不同物体。
什么是特征?
- 特征是图像中具有判别性的模式,例如:
- 边缘、角点、纹理
- 轮廓形状(圆形 vs 长方形)
- 颜色分布(红色八边形 → 停车标志)
- 传统方法:SIFT、HOG
- 深度学习方法:卷积神经网络(CNN)自动学习多层次特征(从边缘到部件再到整体)
举例:区分汽车和自行车的关键特征可能是“车轮数量”、“车身长度”、“是否有车门”。
步骤4:分类决策(Classification)
将提取出的特征输入分类模型(如全连接层、Softmax),输出每个类别的概率。
- 模型选择最可能的类别作为最终结果
- 例如:输入一张图像 → 输出 “汽车:95%”,“摩托车:3%”,“卡车:2%” → 判定为“汽车”
三、模型:让计算机“理解”图像的工具
在计算机视觉中,“模型”是指经过训练的数学函数或神经网络,它是实现上述任务的核心工具。
关键特点:
- 所有视觉模型的起点都是摄像头图像输入
- 模型通过大量标注数据进行训练,学会将像素模式与语义含义关联
- 无论执行检测、分类还是分割任务,现代视觉模型大多基于深度学习架构(如 ResNet、YOLO、EfficientNet、Mask
R-CNN)
模型的本质:从数据中学习“什么样的像素组合对应什么样的物体”。
摄像头图像:计算机如何“看”一张照片
在自动驾驶的感知系统中,摄像头图像是最常见、最丰富的数据来源之一。人类可以一眼识别图像中的物体(如“这是一辆汽车”),但对计算机而言,图像并不是“场景”,而是一组数学化的数字结构。理解这一点,是掌握计算机视觉的第一步。

一、图像的本质:像素与矩阵
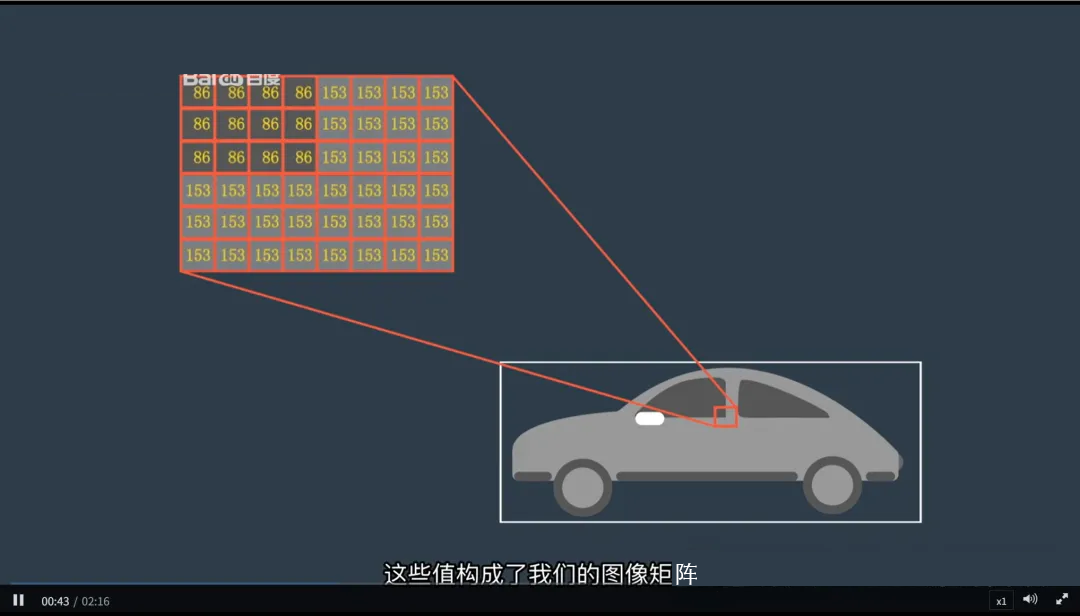
对计算机来说,一张图像就是一个二维数值网格,也称为矩阵(Matrix)。
- 网格中的每个小格子代表一个像素(Pixel),即“图像元素”;
- 每个像素包含一个数值,表示该点的亮度或颜色强度;
- 图像的分辨率就是这个矩阵的大小,例如:1920×1080 表示有 1920 列、1080 行像素。
图像 = 二维数字矩阵
我们可以对这个矩阵进行各种数学操作:
- 给所有像素值加一个数 → 图像变亮
- 减去一个数 → 图像变暗
- 移动像素位置 → 实现图像平移或旋转
- 这些操作构成了图像处理的基础
二、灰度图像:最简单的图像形式
最基础的图像是灰度图像(Grayscale Image):
- 每个像素值是一个 0 到 255 的整数:
- 0 表示黑色
- 255 表示白色
- 中间值表示不同灰度
- 整张图像就是一个二维矩阵,每个元素代表对应位置的亮度

三、彩色图像:RGB 三通道模型
现实中的摄像头大多采集彩色图像,其结构比灰度图像更复杂。

1. RGB 图像结构
大多数彩色图像采用 RGB 颜色模型(Red-Green-Blue):
- 图像不再是二维矩阵,而是一个三维数据立方体
- 三个维度分别是:
- 高度(Height)
- 宽度(Width)
- 通道数(Channels)——通常是 3
2. 三通道分层理解
可以把 RGB 图像想象成三个叠加的二维层:
- 红色层(R):记录每个像素的红色强度
- 绿色层(G):记录每个像素的绿色强度
- 蓝色层(B):记录每个像素的蓝色强度
最终的颜色由这三个通道的值共同决定。例如: (255, 0, 0)
→ 纯红色 (0, 255, 0) → 纯绿色 (255, 255, 255) → 白色 (0, 0,
0) → 黑色
四、图像的数学本质:一切皆可计算
正因为图像是由数字组成的矩阵(或立方体),我们可以通过数学运算来处理和分析它。
常见图像操作举例:
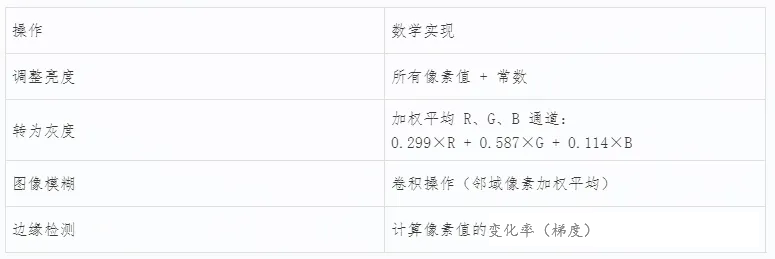
所有这些操作,本质上都是对像素矩阵进行逐元素或局部区域的数学计算。
五、为什么这很重要?——在自动驾驶中的意义
理解图像的数字本质,是实现以下任务的基础:
- 目标检测:从像素中识别出车辆、行人
- 车道线识别:提取特定颜色和形状的像素区域
- 语义分割:为每个像素打上类别标签
- 图像增强:在低光照条件下提升可视性
自动驾驶系统必须“读懂”这些像素背后的含义,才能做出正确决策。
Lidar图像:构建三维世界的“眼睛”
在自动驾驶感知系统中,除了摄像头提供的二维视觉信息外,激光雷达(Light
Detection and Ranging, LiDAR) 提供了难以通过摄像头获得的关键信息——如精确的距离和高度。LiDAR
通过发射激光脉冲并测量其反射时间来创建环境的三维点云表征,为车辆提供了丰富的空间感知能力。
一、LiDAR 工作原理
1. 发射与接收
- 发射激光脉冲:LiDAR 设备向周围环境发射高频率的激光脉冲;
- 测量反射时间:每个脉冲遇到物体后反射回传感器,LiDAR 测量这一往返时间;
- 计算距离:根据光速常数(约 3×10^8 m/s),通过公式 ( {距离} = {光速} *{往返时间}}/2),计算出物体到传感器的距离。
2. 构建点云
- 每个返回的激光脉冲对应一个三维坐标点(x, y, z),这些点共同构成了环境的点云图;
- 点云中的每个点代表一个被检测物体表面的位置,形成了对周围环境的详细描述。
点云 = 一系列三维坐标点的集合
二、点云数据的特点与优势
1. 提供精确的空间信息
- 相比于摄像头的二维图像,LiDAR 数据包含了距离和高度信息,能够生成三维模型;
- 可以直接用于判断物体之间的相对位置关系,例如识别前方是否有障碍物及其距离。
2. 不受光照条件影响
- LiDAR 使用的是激光而非可见光,因此在夜间、强光、雨雾等恶劣条件下依然有效;
- 对比摄像头,它具有更强的鲁棒性和一致性。
3. 丰富的几何特征
- 点云不仅反映了物体的存在,还能揭示其形状和表面纹理;
- 通过对点云进行聚类分析,可以提取出物体的轮廓和细节特征。
三、点云处理与应用
1. 对象检测与分类
- 聚类分析:将点云中的点按照密度或距离分组,形成不同的物体簇;
- 特征提取:从每个簇中提取几何特征(如边界、中心点、体积),用于识别物体类型;
- 分类结果:常见的分类包括行人(红色)、汽车(绿色)、建筑物(蓝色)等。
示例:
- 在点云图上,红色点标记为行人,绿色点表示其他车辆;
- 这些分类结果帮助车辆理解当前环境,并做出相应的驾驶决策。
2. 跟踪与运动估计
- 对于动态物体(如行人、车辆),可以通过连续帧间的点云匹配,追踪其运动轨迹;
- 计算速度、方向等参数,预测未来位置,避免碰撞风险。
3. 语义分割
- 类似于图像中的像素级分类,点云语义分割为每个点分配一个类别标签;
- 这有助于更精细地理解场景结构,特别是在复杂环境中区分不同类型的物体。

机器学习
机器学习(Machine Learning, ML) 是计算机科学的一个分支,专注于开发算法和模型,使计算机能够通过数据进行学习并做出预测或决策。随着计算能力的提升和大数据时代的到来,机器学习在过去二十年中得到了广泛应用,并在多个领域取得了显著成果。
一、机器学习的基本概念
1. 什么是机器学习?
1.定义:机器学习是从数据中自动提取知识的过程,其结果以模型的形式存储,该模型可用于理解和预测新数据。
2.应用场景:
- 金融:预测汇率波动和证券交易;
- 零售:需求预测;
- 医疗:辅助诊断;
- 自动驾驶:感知环境、路径规划等。
2. 模型是什么?
- 模型是经过训练的数据结构,它捕捉了输入数据(特征)与输出结果(标签)之间的关系;
- 训练过程涉及使用大量数据来调整模型参数,使其能够对新数据做出准确预测。
二、主要的机器学习类型
根据数据标注情况和学习方式的不同,机器学习可分为以下几种主要类型:
1. 监督学习(Supervised Learning)
1.定义:使用带有真值标记(标签)的数据集进行训练,目标是让模型学会从输入特征到输出标签的映射。
2.示例:
- 图像分类:给定一组车辆与行人的图像及其标签(如“车辆”、“行人”),训练模型区分这两类图像。
- 回归分析:预测房价,输入房屋的各种属性(面积、卧室数量等),输出价格。
3.关键点:
- 需要大量高质量的标注数据;
- 常用算法包括线性回归、支持向量机(SVM)、决策树、随机森林、神经网络等。

2、无监督学习(Unsupervised Learning)
1.定义:不依赖于真值标记,而是基于数据本身的内在结构进行学习,目的是发现数据中的模式或分组。
2.示例:
- 聚类分析:将未标记的车辆与行人图像分为若干相似的组(簇),无需事先知道哪些图像是车辆,哪些是行人;
- 降维:减少数据维度,保留重要信息,便于可视化或后续处理(如主成分分析 PCA)。
3.关键点:
- 适用于缺乏标签的数据集;
- 常用算法包括K均值聚类、层次聚类、自编码器等。
3. 半监督学习(Semi-Supervised
Learning)
1.定义:结合少量有标签数据和大量无标签数据进行训练,旨在利用有限的标注信息提高模型性能。
2.示例:
- 在图像分类任务中,可能只有少量图像被明确标注为“车辆”或“行人”,但有大量的未标注图像可供使用;
- 通过半监督方法,模型可以在未标注数据上进行预训练,再用标注数据进行微调。
3.关键点:
- 平衡有标签和无标签数据的利用;
- 常见方法包括自训练、协同训练、生成对抗网络(GAN)等。
4. 强化学习(Reinforcement Learning)
1.定义:智能体(Agent)通过与环境交互,尝试不同行为并接收反馈(奖励或惩罚),逐步优化策略以最大化累积奖励。
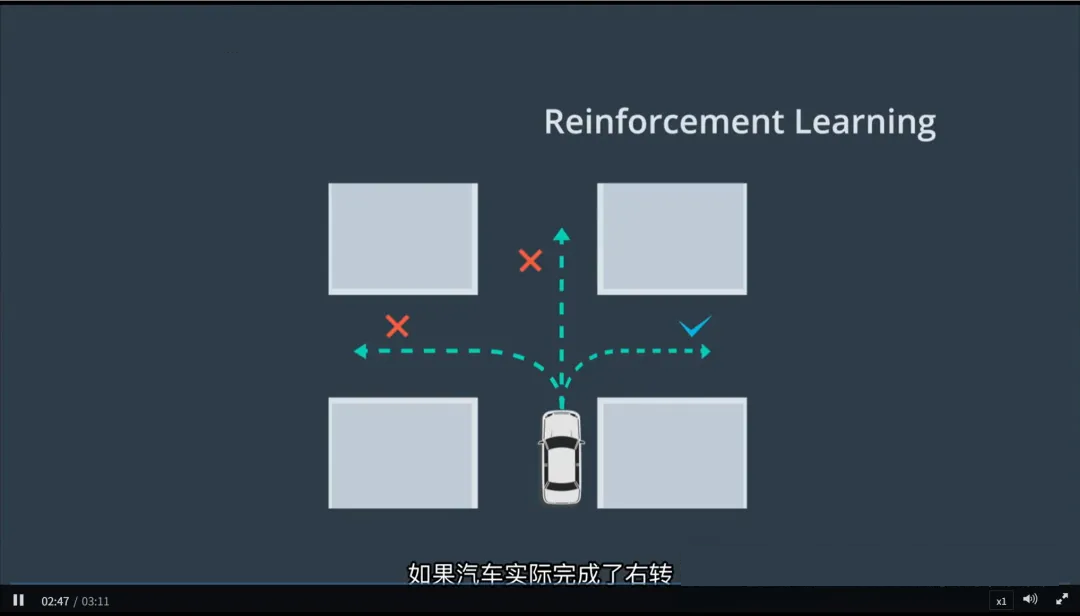
2.示例:
- 自动驾驶模拟:智能体控制虚拟汽车完成右转任务,初始阶段通过随机驾驶探索不同方向和速度组合;
- 如果成功完成转弯,智能体会获得正向奖励;否则,可能会得到负向反馈;
- 经过多次试验,智能体逐渐学会最优驾驶策略。
1.关键点:
- 强调长期回报而非短期收益;
- 常用算法包括Q-learning、深度Q网络(DQN)、策略梯度法等。
神经网络:从人脑到人工智能的桥梁
神经网络是现代机器学习的核心技术之一,尤其在自动驾驶的感知系统中发挥着关键作用。它的设计灵感来源于人类大脑中的生物神经系统,通过模拟神经元之间的连接与信息传递机制,构建出能够学习复杂模式的数学模型。
一、从生物神经元到人工神经网络
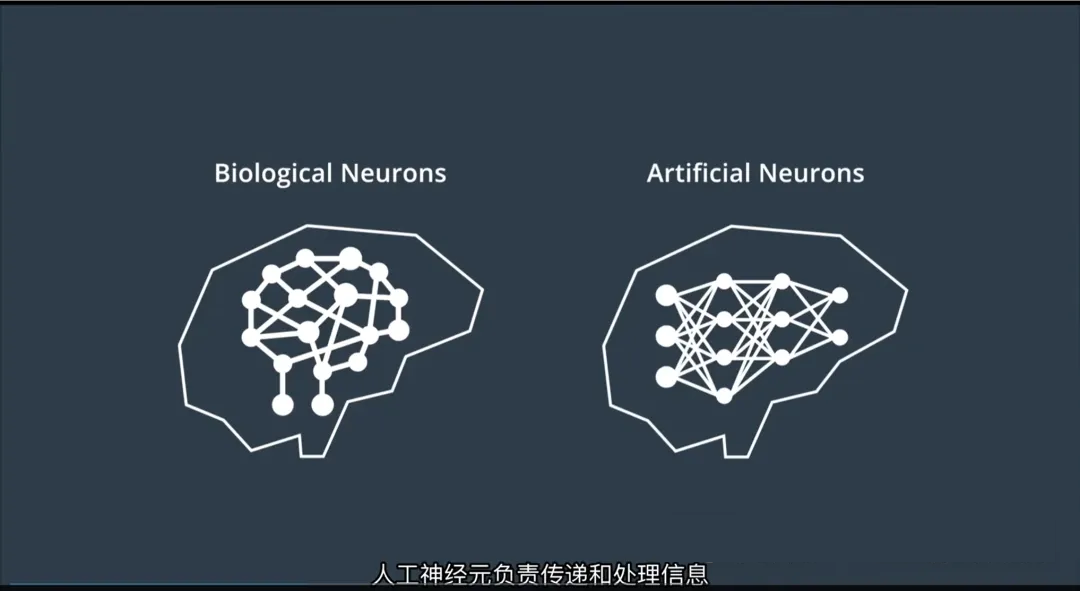
1. 生物神经元的启发
- 人类大脑由数十亿个生物神经元组成;
- 每个神经元通过突触与其他神经元相连,形成复杂的神经网络;
- 当接收到足够强的信号时,神经元会“激活”并传递信息,从而实现感知、思考和决策。
2. 人工神经网络(Artificial Neural Network, ANN)
- 受此启发,科学家构建了人工神经网络——一种由多层“人工神经元”组成的计算模型;
- 这些神经元按层次组织(输入层、隐藏层、输出层),并通过加权连接相互传递信息;
- 网络通过数据训练不断调整连接权重,以学习输入与输出之间的复杂映射关系。
人工神经网络 = 模拟人脑信息处理机制的数学系统
二、神经网络如何“看懂”图像?
人类可以轻松识别一辆车,无论它是黑色还是白色、大还是小,甚至说不清判断依据——这正是因为我们大脑在潜意识中提取了关键特征(如车窗、车轮、车身形状)并赋予不同权重。
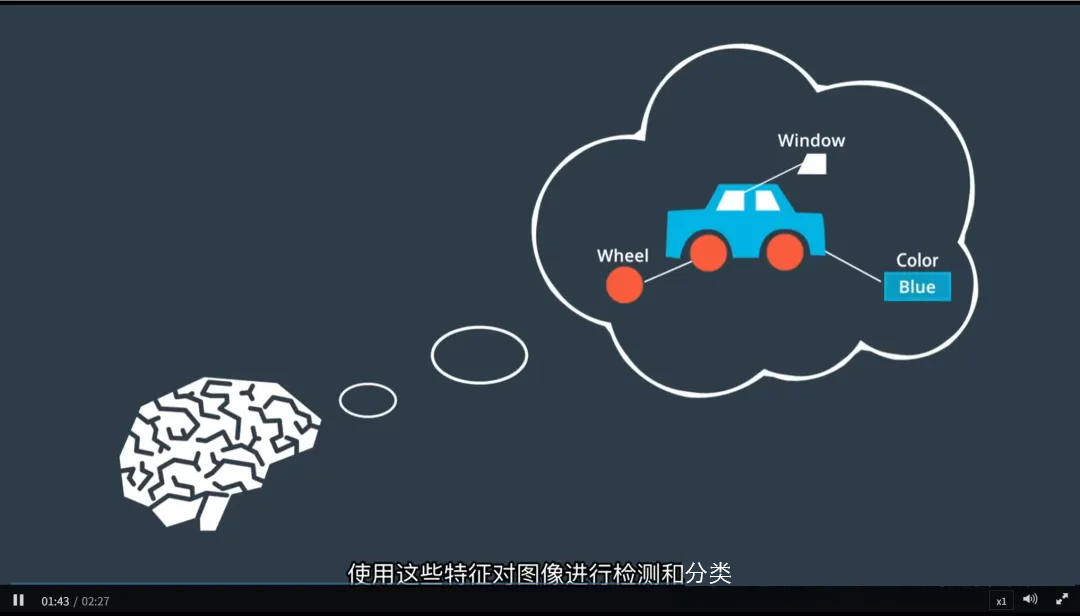
神经网络的工作方式与此极为相似:
1. 特征自动提取
- 输入一张图像后,神经网络不会直接“认出”是一辆车;
- 而是通过多层处理,逐步提取从低级到高级的特征:
- 第一层:边缘、角点、颜色对比
- 中间层:纹理、局部形状(如圆形轮胎)
- 深层:整体结构(如完整车辆轮廓)
2. 权重调节:学会“重视什么”
- 大脑知道“颜色”不是判断车辆的关键(因为车有各种颜色),所以会降低其权重;
- 同样,神经网络在训练过程中也会自动调整每个特征的权重(Weight):
- 对分类任务更重要的特征获得更高权重;
- 不重要的特征权重被削弱;
- 这个过程通过反向传播算法(Backpropagation)实现,基于预测误差不断优化模型参数。
关键洞见:神经网络不仅能识别我们能描述的特征,还能发现人类难以察觉甚至无法解释的“隐性特征”。
三、为什么我们“看不懂”神经网络?
尽管神经网络表现强大,但它常被称为“黑箱模型”——因为我们很难完全理解其内部决策过程。
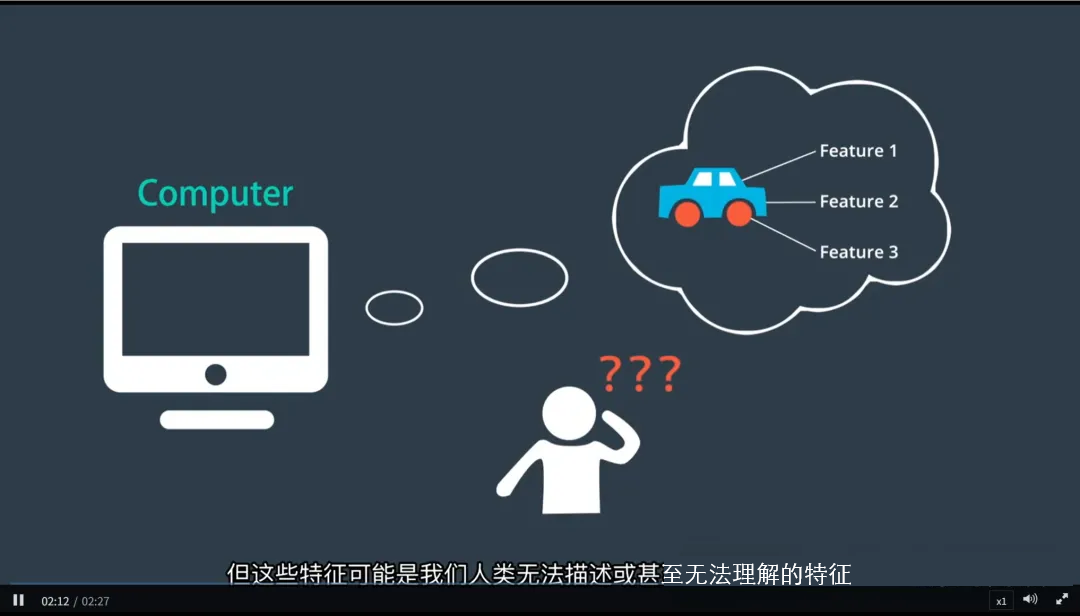
原因如下:
- 高度非线性:成千上万个神经元通过非线性函数连接,整体行为极其复杂;
- 抽象特征不可见:深层网络提取的特征往往是数学意义上的抽象表示,无法用人类语言直观描述;
- 权重分布庞大:一个典型深度网络可能包含数百万甚至上亿个参数,难以逐个解释。
举例:我们可以知道某个神经元对“车轮圆形”响应强烈,但无法解释整个网络是如何综合所有信号做出最终判断的。
四、神经网络在自动驾驶中的应用
在自动驾驶系统中,神经网络广泛应用于各类感知任务:
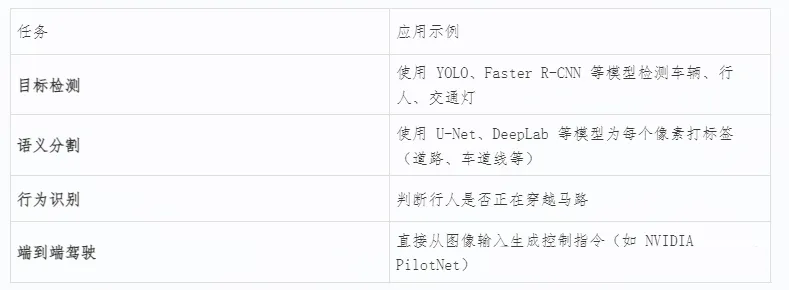
这些模型都依赖于大量标注数据进行训练,并在实际运行中展现出强大的泛化能力。
反向传播算法:神经网络如何从数据中学习
在深度学习中,反向传播算法(Backpropagation)是神经网络实现“学习”的核心机制。它使得模型能够从大量数据中自动调整内部参数,逐步提升预测准确性。这一过程也被称为模型训练。
整个训练流程由三个关键步骤组成:前馈(Forward Pass)→
误差测定(Error Calculation)→ 反向传播(Backward Pass),这三个步骤循环进行,直到模型收敛。
一、神经网络的训练流程
1. 初始化:随机权重分配
- 在训练开始前,神经网络中的所有连接权重(即人工神经元之间的连接强度)被随机初始化;
- 这些权重决定了输入信号在层间传递时的影响程度;
- 初始值通常较小且随机,以避免对称性问题,确保网络可以有效学习。
注意:此时的网络“无知”,输出完全不可靠。
2. 步骤一:前馈传播(Forward Propagation)
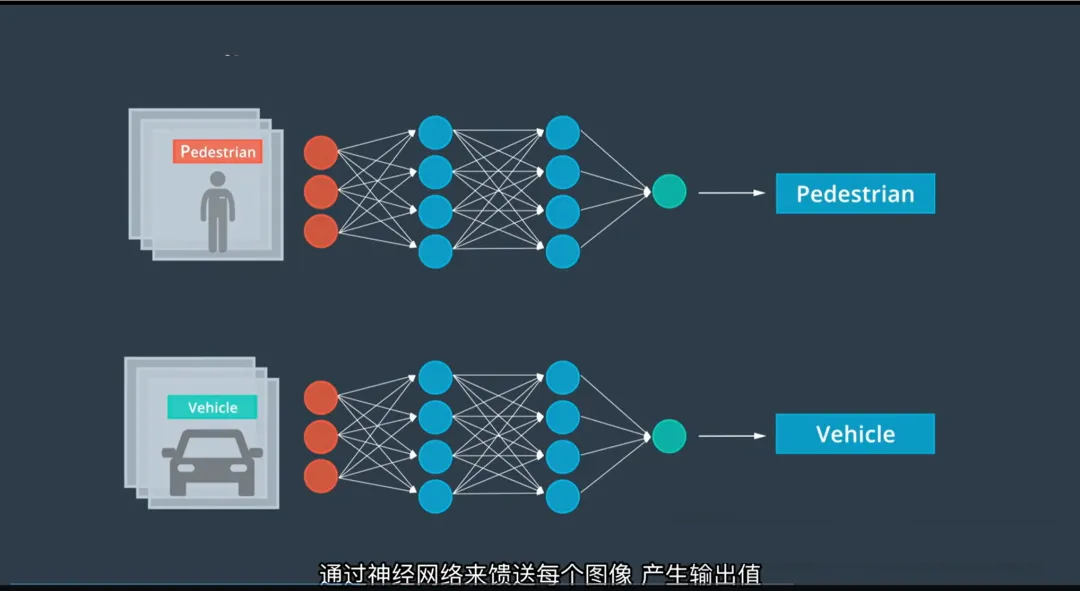
- 将输入数据(如图像)送入网络;
- 数据逐层向前传递,每一层神经元对输入进行加权求和,并通过激活函数(如ReLU、Sigmoid)产生输出;
- 最终在网络的输出层得到一个预测结果(例如:“这是汽车”的概率为70%)。
前馈过程是“推理”阶段:从输入到输出的正向计算。
3. 步骤二:误差测定(Error Calculation)
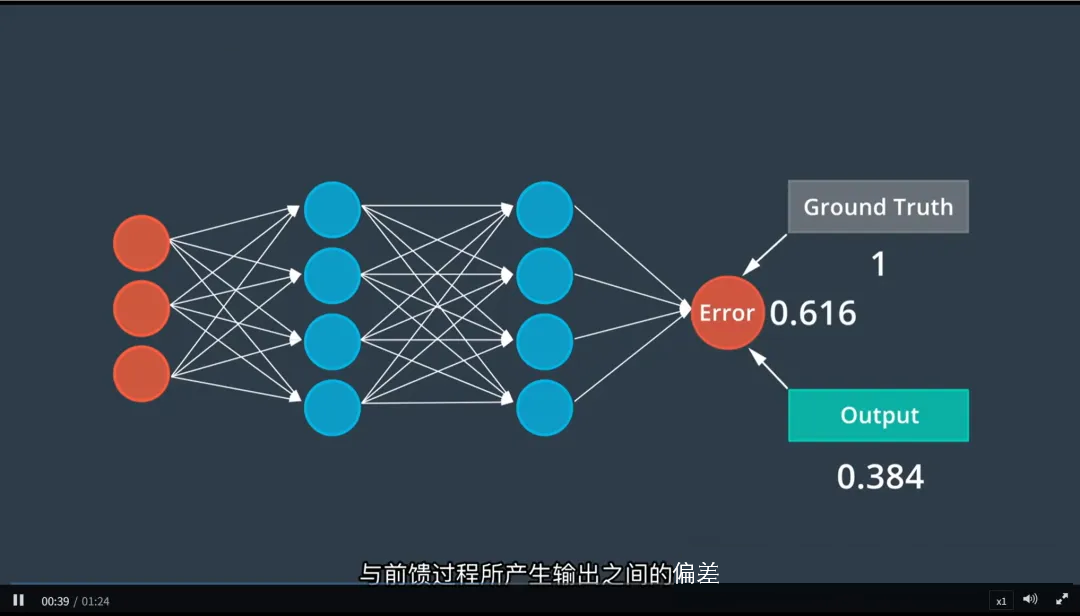
- 比较网络的预测输出与真实标签(Ground Truth)之间的差异;
- 使用损失函数(Loss Function)量化这种差异,常见的有:
- 分类任务:交叉熵损失(Cross-Entropy Loss)
- 回归任务:均方误差(Mean Squared Error, MSE)
- 误差值越大,说明模型预测越不准。
示例:若真实标签是“行人”,但模型输出“行人:20%”,则误差较大。
4. 步骤三:反向传播(Backward Propagation)
这是训练过程中最关键的一步。

核心思想:
- 将输出层的误差从后向前逐层传播回网络;
- 利用链式法则(Chain Rule)计算每个权重对总误差的贡献(即梯度);
- 根据梯度方向,使用优化算法(如梯度下降)微调每个权重,使下次预测更接近真实值。
具体过程:
- 从输出层开始,计算每个神经元的误差梯度;
- 逐层向前传播梯度,直到输入层;
- 更新每一层的权重:
反向传播是“学习”阶段:通过误差反馈调整模型参数。
二、训练是一个迭代过程
单次前馈 + 误差 + 反向传播仅完成一次训练迭代(Iteration),远远不足以让网络学会复杂任务。
实际训练包含:
- 成千上万次迭代
- 多轮遍历整个训练数据集(称为“Epoch”)
- 每一轮都持续缩小预测误差,提升模型性能
随着训练进行:
- 权重逐渐从随机值演变为有意义的模式;
- 网络逐步学会提取关键特征并做出准确判断;
- 最终达到“见过类似图像就能正确识别”的泛化能力。
卷积神经网络(CNN):专为感知而生的深度模型
卷积神经网络(Convolutional Neural Network, CNN)是一种特别适用于处理感知数据(如图像、点云、雷达图)的人工神经网络。它在图像分类、目标检测、语义分割等任务中表现出色,是自动驾驶视觉感知系统的基石。
与标准神经网络不同,CNN 能够保留输入数据的空间结构,从而更有效地提取局部特征并构建层次化表示。
一、传统神经网络的局限:图像“扁平化”的代价
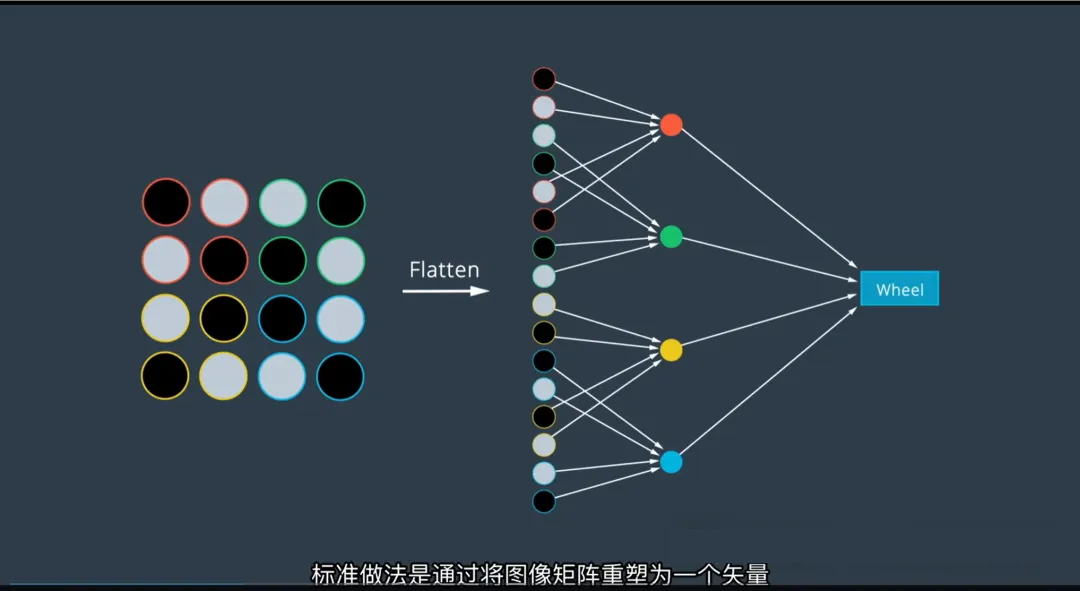
在标准全连接神经网络中,图像通常被重塑为一维向量作为输入:
- 例如:一张 28×28 的灰度图像 → 展开成长度为 784 的向量;
- 这种方法虽然技术上可行,但存在严重问题:
❌ 主要缺陷:
- 破坏空间结构:原本相邻的像素(如车轮上的连续弧线)被拆散到向量的不同位置;
- 丢失局部相关性:神经网络难以识别“哪些像素构成边缘”、“哪些组成形状”;
- 参数爆炸:全连接层需要大量权重,导致计算成本高且易过拟合。
结果:模型很难从被打乱的空间信息中识别出有意义的物体(如车轮、车门)。
二、CNN 的核心思想:保留空间关系,逐层提取特征
CNN 通过引入卷积操作,从根本上解决了上述问题。它的设计灵感来源于生物视觉皮层对局部区域的响应机制。
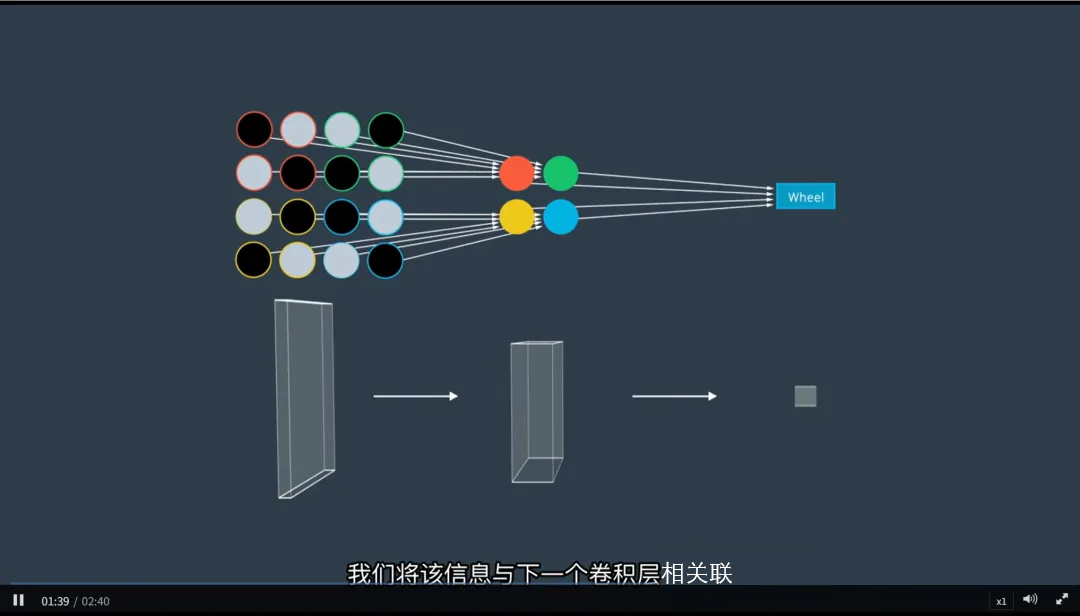
CNN 的优势:
- 接受多维输入(如二维图像、三维点云切片);
- 保持像素间的空间拓扑关系;
- 使用局部感受野和权值共享机制,高效提取特征。
三、CNN 的核心组件:卷积层如何工作?
1. 卷积操作(Convolution)
- 使用一个小型矩阵(称为卷积核或过滤器 Filter)在输入图像上滑动;
- 在每个位置,计算滤波器与图像局部区域的逐元素乘积和(即点积),生成一个输出值;
- 整个滑动过程产生一个新的二维特征图(Feature Map)。
举例:一个 3×3 的边缘检测滤波器可以在整幅图像中扫描,突出所有垂直或水平边缘。
2. 局部感知与权值共享
- 每个神经元只关注图像的一小块区域(感受野),模拟人眼对局部细节的关注;
- 同一滤波器在整个图像上共享参数,大幅减少模型参数量。
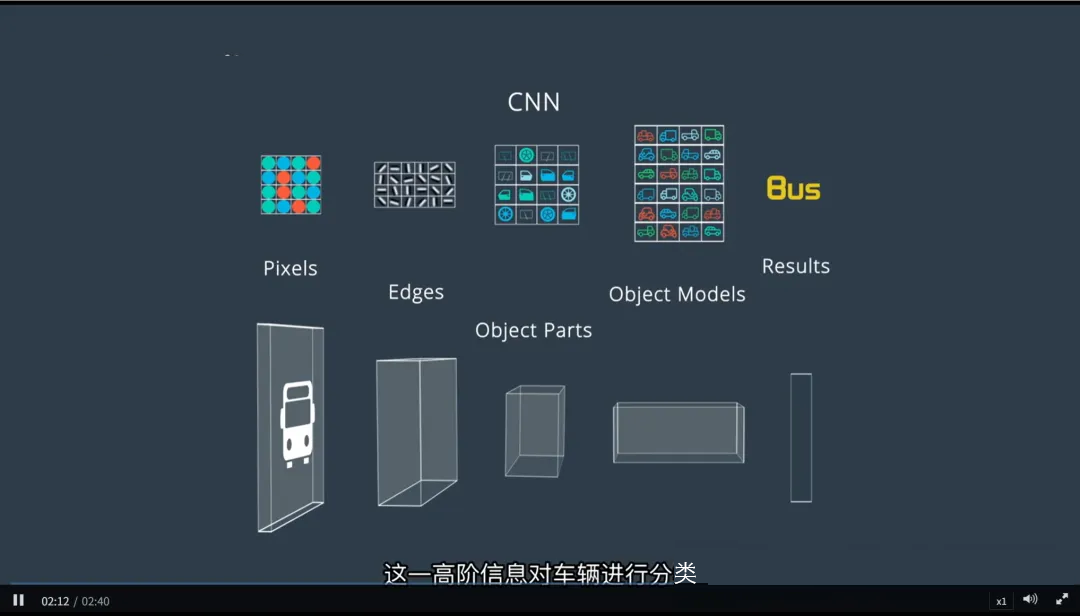
四、CNN 的层级结构
CNN 的强大之处在于其分层特征提取能力——每一层都在前一层的基础上构建更高级的抽象。
五、CNN 的“黑箱”特性:我们真的理解它吗?
尽管 CNN 性能卓越,但其决策过程常常难以解释:
- 关注区域出人意料:有时 CNN 会基于图像中我们意想不到的部分做出判断(如背景纹理、车牌文字);
- 任务驱动特征选择:CNN 并不关心“人类认为重要的特征”,而是学习对当前任务最有效的统计模式;
- 可解释性挑战:我们需要借助可视化工具(如 Grad-CAM)来观察哪些区域被激活。
但这正是它的优势:它能找到人类未曾察觉的判别性特征。
六、CNN 在自动驾驶中的典型应用
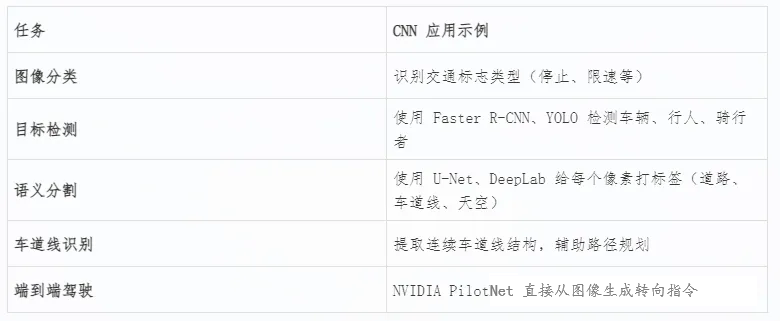
Apollo 感知系统:多传感器融合与任务协同的智能感知框架
Apollo 是百度开源的自动驾驶平台,其感知模块(Perception Module)通过融合摄像头、激光雷达(LiDAR)、高精度地图和车辆定位等多源信息,实现了对环境的全面、精确理解。它不仅能检测障碍物、交通信号灯和车道线,还能跨时间保持对象身份,为后续的规划与控制提供可靠输入。
Apollo 的感知系统采用任务驱动、分层过滤、多模态融合的设计思想,显著提升了检测效率与准确性。
一、三维对象检测:从点云到可追踪目标
Apollo 使用激光雷达点云与图像数据联合检测三维障碍物(如车辆、行人、骑行者),并通过高精度地图引导感知过程,提升效率。
1. 基于高精度地图的 ROI 过滤
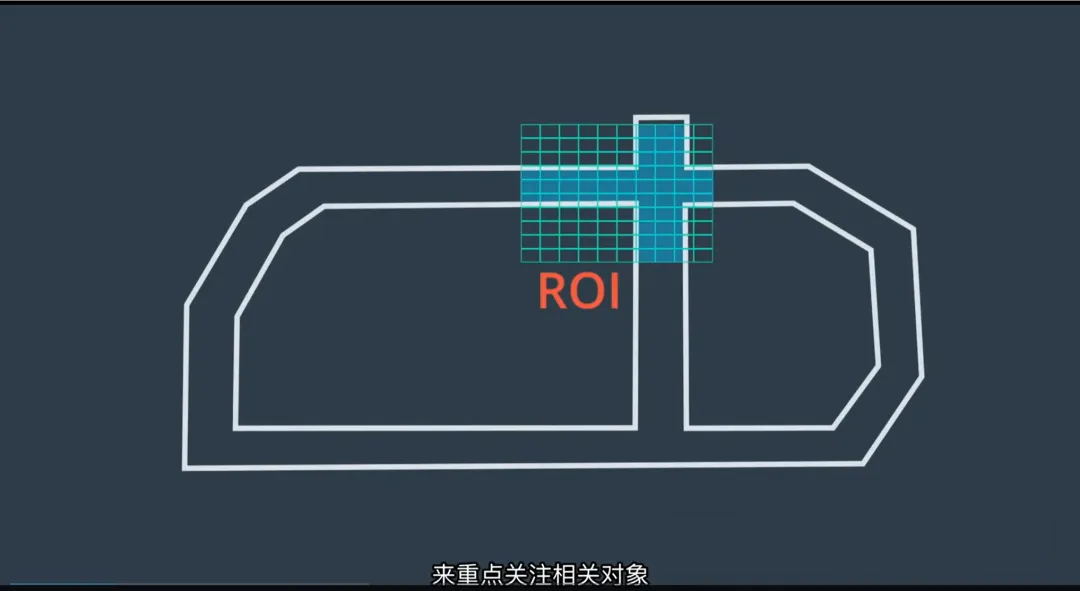
- ROI(Region of Interest,感兴趣区域):利用高精度地图预先确定当前车道周围可能存在障碍物的区域;
- 将点云和图像数据限制在 ROI 内进行处理,大幅缩小搜索范围;
- 优势:
- 减少计算量,加快感知速度;
- 避免在无关区域(如对向车道、建筑物后方)浪费资源。
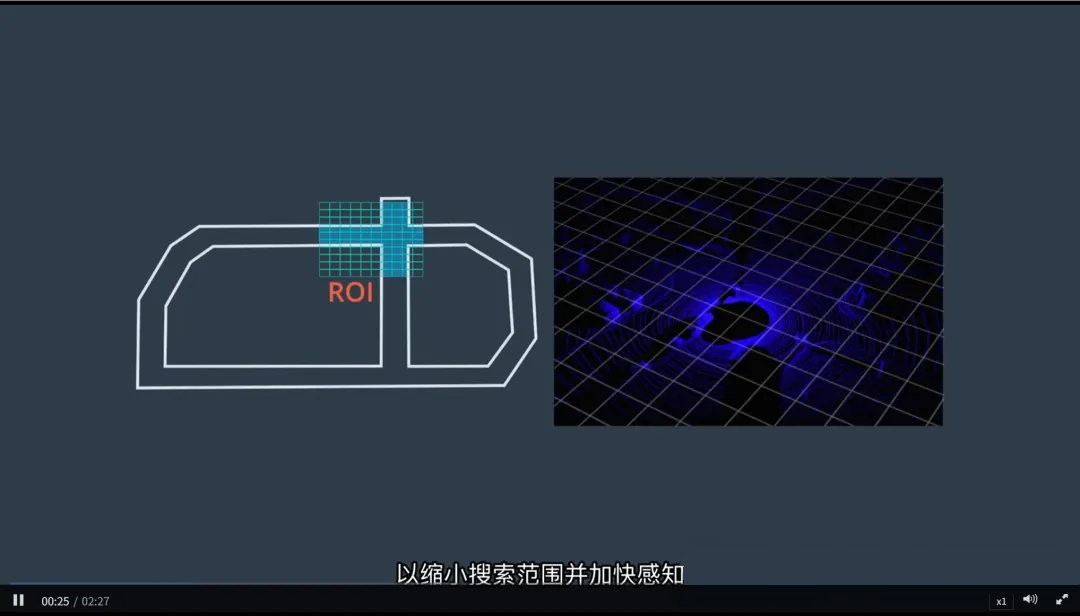
地图先验 = 智能“注意力机制”,让系统“知道该看哪里”。
2. 多模态数据过滤与输入
- 对激光雷达点云应用 ROI 过滤,保留关键区域的点;
- 同步对摄像头图像进行空间裁剪或注意力引导,聚焦于相同区域;
- 将过滤后的点云和图像送入3D 检测网络(如 PointPillars、CenterPoint)。
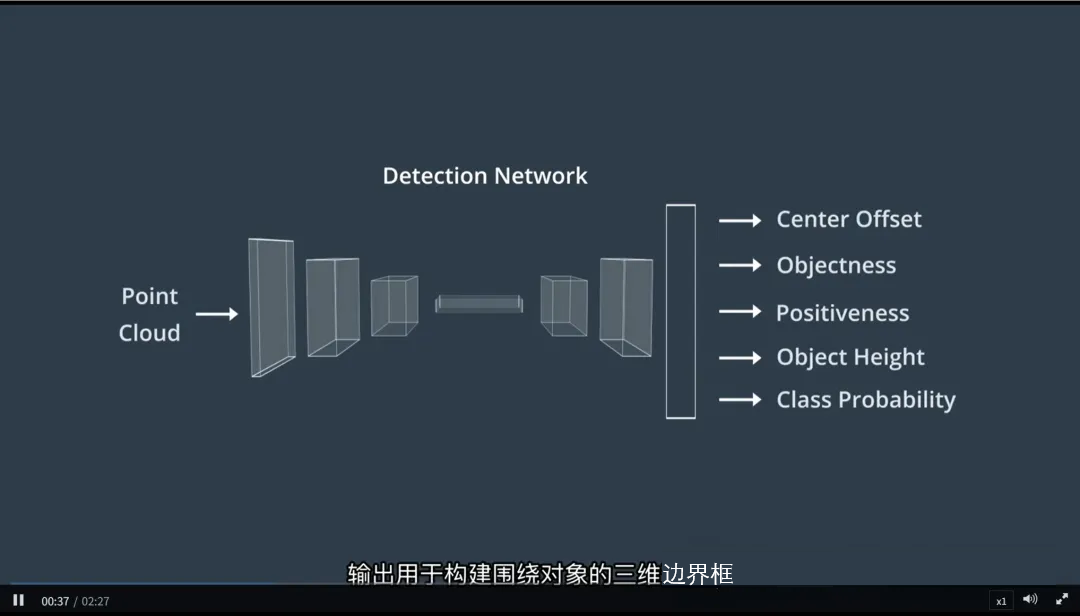
3. 生成 3D 边界框
1.检测网络输出每个障碍物的:
- 三维位置(x, y, z)
- 尺寸(长、宽、高)
- 方向角
- 类别(汽车、行人等)
2.构建三维边界框(3D Bounding Box),精确描述物体在空间中的姿态。
4. 检测-跟踪关联(Detection-to-Tracking Association)
为了实现跨帧一致性,Apollo 使用检测-跟踪关联算法来维持物体身份。

工作流程:
- 维护一个跟踪列表(Track List),记录每个已知对象的历史状态(位置、速度、ID);
在新一帧中,将当前检测结果与已有轨迹进行匹配;
- 匹配依据包括:
- 空间距离(IoU 或欧式距离)
- 运动一致性(速度、方向)
- 外观特征相似度(来自图像)
- 成功匹配则更新轨迹;未匹配的检测创建新轨迹;长时间未匹配的轨迹被删除。
实现“同一辆车”在多帧中的连续追踪,解决遮挡与抖动问题。
二、交通信号灯识别:地图引导 +
两阶段分类
交通信号灯是自动驾驶决策的关键输入。Apollo 采用地图引导 + 图像裁剪 + 分类网络的两阶段策略,确保准确识别灯色。
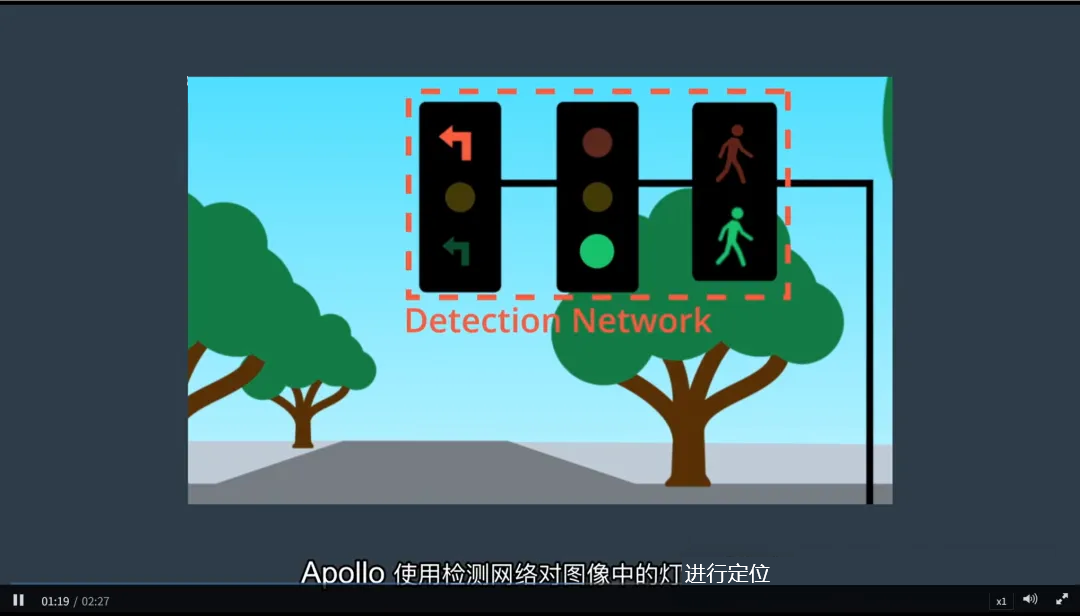
1. 地图预筛选
- 查询高精度地图:前方是否有交通信号灯?
- 若有,返回其精确地理位置和所属车道;
- 根据车辆当前位置与信号灯位置关系,确定摄像头应重点关注的区域。
提前锁定目标,避免盲目搜索整幅图像。
2. 图像检测与定位
- 使用检测网络(如 Faster R-CNN 或 YOLO)在摄像头图像中定位信号灯;
- 输出信号灯的边界框(2D Bounding Box);
- 若存在多个信号灯(如左转、直行、对向灯),根据地图信息选择与本车道相关的灯。
3. 灯色分类
- 从原始图像中裁剪出信号灯区域;
- 将裁剪后的图像送入分类网络(如 CNN 或 ResNet);
- 输出灯的颜色状态:红、黄、绿、灭;
- 结合时间序列滤波(如卡尔曼滤波)提高分类稳定性。
分阶段处理:先定位 → 再分类,提升准确率与鲁棒性。
三、车道线与动态物体检测:YOLO
+ 多传感器融合
Apollo 使用高效的深度学习模型检测车道线和动态障碍物,并通过多传感器融合提升结果精度。
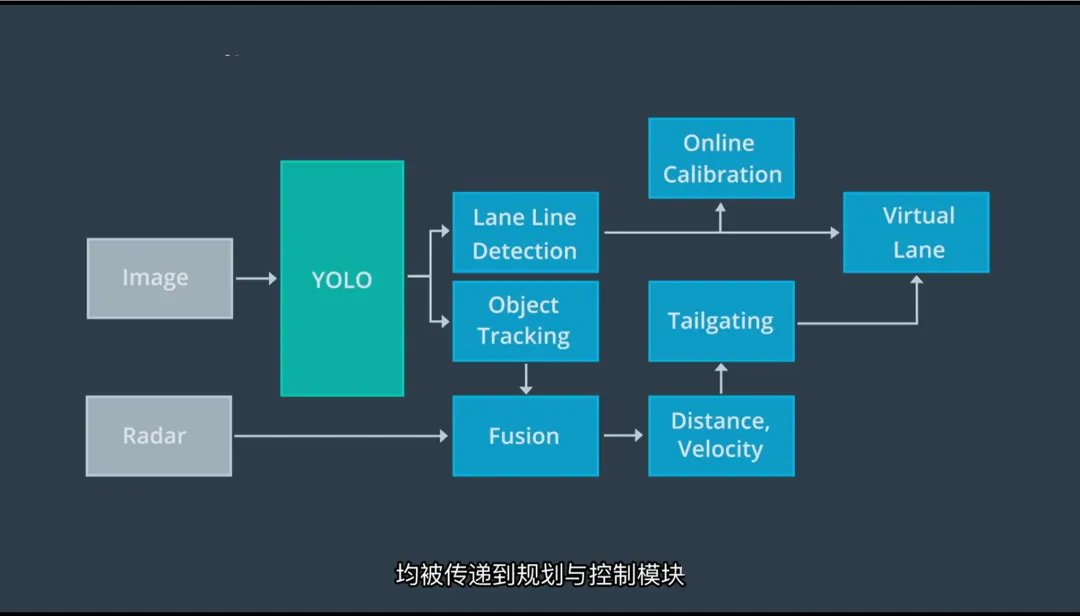
1. 使用 YOLO 进行实时检测
1.采用 YOLO(You Only Look Once)系列网络
同时检测:
- 车道线(虚线、实线、颜色)
- 动态物体:车辆、卡车、自行车、行人
2.YOLO 的优势:
- 单次前向传播完成检测,速度快,适合实时系统;
- 支持多类别同步识别。
2. 车道线融合:构建“虚拟车道”
1.YOLO 输出初步车道线位置;
2.融合其他传感器数据(如 LiDAR 强反射点、IMU 轨迹)进行校正;
3.将多源信息整合为一个统一的数据结构 —— 虚拟车道(Virtual Lane);
4.虚拟车道包含:
- 左右边界
- 可行驶区域
- 车道类型(直行、左转等)
- 连续性信息(是否中断)
“虚拟车道”是规划模块的核心输入,定义了车辆的合法行驶空间。
3. 动态物体状态估计
1.对 YOLO 检测到的每个动态对象:
- 融合 LiDAR 提供的精确距离与速度;
- 融合雷达的径向速度信息;
- 结合历史轨迹进行运动建模;
2.输出每个对象的完整状态:
- 类型
- 3D 位置
- 速度
- 运动方向(Heading)
- 加速度(可选)
多传感器融合 = 更稳定、更准确的动态世界模型。
四、感知输出:传递给规划与控制
所有感知结果最终被统一组织并传递给下游模块:
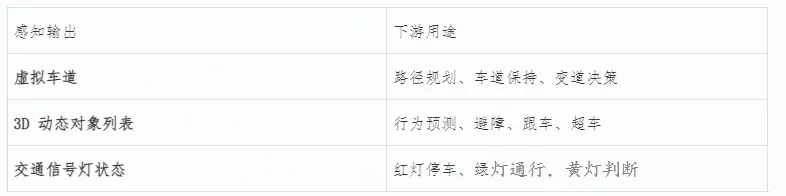
感知系统的目标不是“看到一切”,而是“输出对决策最有用的信息”。
| 






 订阅
订阅