| 编辑推荐: |
本文主要介绍了具有功能安全设计且符合ASIL-D的AI处理器相关内容。希望对您的学习有所帮助。
本文来自于微信公众号猿力部落,由火龙果软件Alice编辑、推荐。 |
|
摘要:本文提出的人工智能处理器架构具有较高的吞吐量,可加速神经网络运算,并降低神经网络处理过程中所需的外部存储器带宽。为实现高吞吐量,所提出的超线程核心(STC)包含128×128个纳米核心(NC),其工作时钟频率为1.2
GHz。该功能安全架构是为容错系统(如自动驾驶汽车电子系统)设计的。通用处理器(GPP)核心与超线程核心集成,用于控制超线程核心并处理人工智能算法。该通用处理器核心具备自恢复缓存和动态锁步(DLS)功能。经证实,该功能安全设计的故障性能达到了ISO
26262标准容错等级中的ASIL-D级。因此,整个人工智能处理器采用28纳米互补金属氧化物半导体(CMOS)工艺制成原型芯片。在1.1
V供电电压下,其在1.2 GHz频率下的峰值计算性能为40万亿次浮点运算(TFLOPS),实测能效为1.3万亿次运算每瓦(TOPS/W)。具有功能安全设计的控制用通用处理器,其单点容错率可达99.64%,符合ISO
26262 ASIL-D级标准要求。
01. 简介
目前,人们正致力于研究人工智能(AI)处理器以加速人工智能算法的运行,这类算法已应用于自动驾驶汽车的障碍物识别和姿态控制。因此,必须为自动驾驶汽车研发专用的人工智能处理器。特斯拉(Tesla)的全自动驾驶(FSD)芯片采用专用硬件设计,既能加速自动驾驶汽车中的目标识别人工智能算法,又具备功能安全设计,可在易出错的环境中运行。该系统采用两颗全自动驾驶芯片处理8路摄像头输入信号,每路输入信号用于识别周围环境及道路上的障碍物。
本文所提出的容错特性性能是依据ISO 26262标准进行分析的。ISO 26262标准旨在保障汽车电气系统因故障产生危害时,车辆不会面临不合理风险,从而确保功能安全。在汽车应用场景中,处理器需具备容错特性,以应对因电压波动、温度大范围变化以及粒子辐射暴露等因素引发的瞬时故障。此外,安装在车辆上的高级驾驶辅助系统(ADAS)处理器,其运行必须具备极高的稳定性和可靠性,以保障行车安全与便捷性。
具备容错能力的处理器,其功能安全需依据ISO 26262标准中的“脱离特定上下文的安全要素”(SEooC)进行分析。“脱离特定上下文的安全要素”是指不针对特定车辆级应用开发的安全要素。当该安全要素在集成过程中其设计假设的有效性能够得到验证时,可应用于多个项目中。在依据ISO
26262标准开发项目时,软硬件组件的认证需考虑已有要素的复用情况,这些组件并非一定要具备可复用性,也不一定是依据ISO
26262标准开发的。由于处理器无法直接结合车辆级应用进行分析,因此需在假设高级驾驶辅助系统(ADAS)系统级需求和功能安全需求(FSR)的前提下,将其作为
“脱离特定上下文的安全要素” 来分析其功能安全。
在失效模式与影响分析(FMEA)中,需明确失效模式及其产生的影响。失效模式指元件或项目发生故障的方式,可通过子模块确定;故障影响则可通过该区域的故障发生率来评估。因此,单点故障发生率与区域面积的乘积越大,故障发生的频率就越高。通过失效模式与影响分析确定故障监测系统,可降低处理器中失效模式的影响,从而保障安全机制(SM)的有效性。
单点故障指标(SPFM)这一硬件指标的计算,需用到基准故障率(BFR)、安全故障比例以及诊断覆盖率。其中,基准故障率依据IEC62380标准计算;诊断覆盖率指通过已实施的安全机制(SMs)能够检测或控制的硬件元件失效率比例。本研究假设子模块中不存在安全故障,在此假设下,单点故障指标会偏低。诊断覆盖率则通过故障注入实验来确定。
此外,ISO/PAS21448 标准用于规范自动驾驶系统的功能安全。ISO 26262 标准主要针对电气电子(E/E)系统故障导致车辆面临不合理风险的情况,保障车辆安全;该标准的其他部分还对如何避免和控制可能违反安全目标的随机硬件故障与系统性故障,提出了要求和指导意见。对于部分依赖环境感知的系统,即使系统本身无故障(符合ISO
26262标准定义),也可能因系统既定功能的局限性而出现安全问题,例如系统无法正确理解当前场景并安全运行。这类安全问题的规避被定义为
“预期功能安全”(SOTIF)。
由于系统在传感器输入变化或复杂环境条件下的鲁棒性不足,可通过采用机器学习算法等措施来降低既定功能安全风险,这些措施在设计、验证和确认阶段对于解决既定功能安全问题至关重要。
本文提出的人工智能处理器架构具有两大显著特点:一是具备较高的吞吐量,可加速神经网络运算;二是降低了神经网络处理过程中所需的外部存储器数据带宽。
为实现高吞吐量,该人工智能处理器配备了超线程核心(STC),该核心包含128×128个纳米核心(NC),工作时钟频率为1.2GHz。纳米核心是一种处理器核心,配备有执行单元,可处理卷积神经网络(CNNs)、循环神经网络(RNNs)和全卷积网络(FCNs)的运算。在超线程核心中,集成了16384个纳米核心,在正常工况下,这些纳米核心均以1.2
GHz的频率运行。
通常情况下,人工智能处理器在处理神经网络时,需反复从外部存储器中读取神经网络的核数据与特征数据,这意味着对外部存储器的高数据带宽有需求。因此,本文提出一种核与特征数据统一存储器,以降低所需的外部存储器数据带宽。
该存储器容量为40MB,配备3个256位AXI主端口、1个256位AXI从端口,以及256个用于超线程核心(工作频率1.2
GHz)的读写端口。该存储器的一个突出特点是可存储从外部存储器读取的特征数据和核数据,存储后的数据可直接复用,无需再次访问外部存储器,有助于提高运算强度。
此外,借助电源门控功能,该人工智能处理器可对正在运行的16384个纳米核心进行供电控制。当在统一存储器中进行数据和指令的读写操作时,可通过电源门控功能关闭所有纳米核心的电源。为降低峰值功耗,统一存储器采用4
MB分段电源门控设计,并支持32 KB粒度的休眠模式。
本文为容错系统(如自动驾驶汽车电子系统)设计了一种功能安全架构。通用处理器(GPP)核心与超线程核心集成,用于控制超线程核心并处理人工智能算法,该通用处理器核心具备自恢复缓存和动态锁步(DLS)功能。
动态锁步功能包含两种模式:一是锁步模式,用于超线程核心的容错控制以及人工智能算法的预处理和后处理;二是双核模式,用于实现高性能运算。自恢复缓存可检测缓存故障,并利用缓存的特性实现故障恢复。
本文通过采用ISO 26262第二版标准中推荐的故障注入系统验证表明,该功能安全架构的故障性能达到了ISO
26262标准汽车安全完整性等级(ASIL)中的D级要求。与传统的双模块冗余(DMR)和容错缓存相比,本文提出的架构具有更优的容错性能。在符合ISO/PAS21448标准且无此类安全违规问题的前提下,通过对设计方案进行功能调整,降低了既定功能安全(SOTIF)风险。本文设计了帧内和帧间安全措施(属于针对多种传感器技术的既定功能安全改进措施),并通过功能限制提高了识别与决策算法的性能,从而进一步降低既定功能安全风险。此外,本文还设计了基于深度学习算法的功能安全处理器,用于处理图像数据。
本文其余部分结构如下:第2节详细介绍所提出的处理器架构;第3节阐述其安全特性;第4节提供符合ISO
26262和ISO/PAS21448标准的故障分析及实现结果;第5节为结论部分。
02. 人工智能处理器
2.1 多核架构
如图1所示,该处理器包含一个具有128×128个纳米核心(NC)的超线程核心(STC)、40
MB的核与特征统一存储器、2个通用处理器(GPP)核心、2个功能安全处理器核心、1个16通道 PCI
Express(PCIE)第三代(Gen3)接口,以及1个双通道低功耗双倍数据速率4(LPDDR4)控制器。
图1:AI处理器的总体架构
为实现人工智能算法处理的高计算吞吐量,该人工智能处理器的超线程核心采用多核架构。超线程核心由128×128个被称为纳米核心(NC)的处理核心组成,每个处理核心的工作频率为1.2
GHz。该人工智能处理器包含核存储器和特征存储器(用于读取处理核心待运算的操作数),以及指令存储器(用于存储处理核心待执行的指令)。此外,处理器还设有一个流控制单元,用于控制核数据、特征数据和指令的流转。该流控制单元还可通过片上总线从外部存储器读取指令、特征数据和核数据,并借助直接存储器访问(DMA)控制器将其分别写入特征存储器、核存储器和指令存储器。
128×128个处理核心每时钟周期可执行两次16位浮点运算(乘法和累加),因此在半精度浮点运算下,其最大性能可达到40万亿次浮点运算(TFLOPS),计算过程如下:
此外,如图2所示,纳米核心(NC)这一处理核心具备多种运算能力,可执行核运算、批量归一化、偏置运算、缩放运算、池化运算(包括平均池化),以及激活函数运算(如修正线性单元(ReLU)、带泄漏的修正线性单元(Leaky
ReLU)、最大池化),还支持加载指令和重组层运算。采用28纳米工艺节点设计的16384个纳米核心处理核心,其芯片面积为20000微米×15000微米。
图2:纳米芯结构图
当处理核心访问特征存储器和核存储器时,数据和控制信号到达目标位置的布线延迟最大可达35000微米;流控制单元访问特征存储器和核存储器时,数据和控制信号同样存在较大的布线延迟。为避免因存储器与处理核心之间的通信延迟导致性能下降,特征存储器、核存储器、指令存储器与处理核心采用网格拓扑结构连接,并通过脉动方式实现数据和指令的传输。
2.2 可编程性
为说明处理核心的工作原理,图3展示了包含128×128个处理核心的人工智能处理器架构。
图3:超级螺纹芯结构图
处理核心的运算需要两个数据和一条指令,这两个数据分别为特征数据和核数据。处理核心附近并未设置专门存储这些指令和数据的存储器,所需的指令和数据由指令存储器、特征存储器和核存储器提供。在处理核心阵列中,每一行的左侧设有特征存储器;每一列的顶部设有核存储器,核数据从该核存储器传入。
每个时钟周期,传入的核数据会通过当前处理核心传递给下方的处理核心。因此,在同一列中,相邻的处理核心会依次接收相同的核数据,但存在一个时钟周期的延迟。同理,每个时钟周期,传入的特征数据会通过当前处理核心传递给右侧的处理核心,在同一行中,相邻的处理核心会依次接收相同的特征数据,同样存在一个时钟周期的延迟。
在128×128的超线程核心(STC)中,仅设有一个指令存储器。指令存储器中的指令首先传输到128×128超线程核心中最右上角的纳米核心(NC),之后每个时钟周期,指令会通过当前纳米核心分别传递给下方和右侧的纳米核心。因此,一条指令会传输到所有128×128个纳米核心,但每个纳米核心接收到指令的时间不同。此外,虽然执行指令时所用的核数据和特征数据各不相同,但所有纳米核心执行的指令是相同的。
为使所提出的人工智能处理器能够高效地进行卷积运算,本文对卷积神经网络(CNN)中典型的卷积矩阵运算进行了重构。如图4所示,输入特征图(IFM)的维度为H×W×N,核矩阵(K3D₀至K3Dₘ₋₁)为M个维度为K×K×N的三维核,二者进行卷积运算后,得到输出特征图(OFM)的维度为(W
/step)×(H /step)×M。输出特征图的一个像素,是由输入特征图中K×K×N个像素与M个核中的一个核进行卷积运算得到的结果。因此,卷积运算会在输出特征图的维度范围内重复进行。
图4:使用多核架构的卷积层专用矩阵
在这种专用矩阵运算中,由重复的输入特征图像素构成的(W/step ×H/step)×(K×K×N)维度矩阵,与由K3D₀至K3Dₘ₋₁构成的(K×K×N)×M维度矩阵相乘,得到的结果即为维度为(W/step×H/step)×M的输出特征图矩阵。
(W / step ×H / step)×(K×K×N)维度矩阵的一行,与(K×K×N)×M 维度矩阵的一列相乘,得到的结果对应输出特征图矩阵中的一个元素,其维度为(W/step×H/step)×M。
(W / step ×H / step)×(K×K×N)维度矩阵的一行是一个由K×K×N个元素组成的向量,该向量的数量等于单个核所能得到的输出特征图元素的数量。
03. 容错特性
3.1 通用处理器
超线程核心(STC)包含16384个纳米核心(NC)。若采用传统容错架构(如基于双模块冗余(DMR)的结构),需设置大量冗余核心,将导致芯片面积大幅增加。因此,考虑到执行神经网络算法时并非始终需要使用全部16384个纳米核心,本研究通过软件实现双模块冗余功能以达成容错目的。在确保性能不下降的前提下,两组纳米核心会运行相同的人工智能算法,从而实现双模块冗余特性。此外,该软件在通用处理器(GPP)中执行,使得通用处理器具备容错功能。
随着电压波动加剧、工作温度范围扩大及时钟频率提升,片上多核处理器(CMPs)面临的瞬时故障、永久故障、制造缺陷及工艺偏差问题愈发显著。为实现错误检测与恢复,基于双模块冗余的片上多核处理器会在另一核心上通过冗余执行来运行程序。此外,该技术通过以下方面的改进得到进一步发展:(a)将冗余执行与同时多线程(SMT)及恢复功能相结合,随着片上线程上下文数量的增加,支持线程技术的大型核心得以开发;(b)增加控制逻辑,用于比较先行线程与后续线程的运行结果;(c)弥补缓存在应对瞬时故障时的脆弱性。在本研究提出的方案中,缓存系统占据处理器面积的三分之二,在存在工艺、电压与温度(PVT)偏差的情况下,缓存系统是处理器中的脆弱模块,因此需为其设计容错特性。
设计容错缓存系统时,纠错码(ECC)是瞬时错误检测与纠正的常用方法。但纠错码所需的冗余存储器会显著增加成本,且因额外增加了存储错误码的存储器,芯片面积增大,可能导致瞬时错误率上升。
本研究开发了一款通用处理器(GPP),该处理器拥有13级流水线,采用双发射超标量架构;取指调度器最多可同时取8条指令;分支预测器采用带有分支历史寄存器的GSHARE算法,并配备分支目标缓冲区;加载存储单元采用2级流水线;指令缓存(I-Cache)与数据缓存(D-Cache)采用3级流水线;还设有指令/数据转换检测缓冲区(I/D
TLB)。该处理器基于28纳米工艺节点设计,工作频率为1.2GHz,能为人工智能应用提供充足的计算能力。在该处理器中,缓存系统占据高达
70% 的处理器面积,由于电压下降和高温可能引发瞬时错误,进而改变缓存中的存储内容,因此需为缓存系统设计容错特性。
本研究提出了一种适用于处理器的容错缓存系统。与相关文献提出的纠错码(ECC)方案相比,该缓存系统所需的冗余存储器更少,通过所提机制可降低瞬时错误率,同时提高错误恢复率。该机制结合数据缓存特性,对缓存中的存储器进行重新配置,无需采用文献中的地址交错技术,即可避免严重且永久性的故障。
此外,本研究提出的处理器采用双模块冗余(DMR)结构,配备独立的时钟和电源,与包含自恢复功能和错误预测功能的缓存协同工作。独立的时钟和电源可防止因单一特定事件或根本原因导致多个电路发生关联性故障。双模块冗余和自恢复功能能够检测并处理发生后随即消失的瞬时故障,而错误预测功能则可预防持续存在直至被排除或修复的永久性故障。
包含具备容错特性的通用处理器(GPP)的人工智能平台,克服了自检故障覆盖率低以及自检时间带来的性能开销问题。分析表明,所提出的容错处理器符合ISO
26262标准要求。该人工智能处理器系统级芯片(SoC)包含两个带有 32KB 缓存的核心,并通过动态锁步(DLS)和自恢复缓存实现功能安全,且该处理器可与128×128个处理核心协同工作。
所提出的容错处理器包含两大关键特性:(a)动态锁步(DLS)配备独立的时钟和电源,以减少关联性失效或实现高性能;(b)缓存具备自恢复功能,可减少瞬时故障的发生,同时具备可重构功能,以降低永久性故障的发生率。
如今,汽车应用领域的半导体必须符合ISO 26262标准以实现功能安全。ISO 26262标准通过规避汽车电气系统故障引发危害所导致的不合理风险,保障功能安全。辐射、噪声、电压与电流波动及温度变化都可能引发故障,而故障会导致半导体中的逻辑电路和触发器失效。因此,需要具备防止汽车故障和危害的处理器与缓存。
3.2 动态锁步
该设计支持两种工作模式:动态锁步(DLS)模式和非动态锁步模式,工作模式通过软件编程确定,如图5所示。当两个处理器的动态锁步寄存器均由软件使能时,处理器工作在动态锁步模式;当两个处理器的动态锁步寄存器均由软件或错误预测器禁用时,处理器则工作在非动态锁步模式。
图5:DLS的DLS模式和非DLS模式
在动态锁步模式下,一个处理器作为先行核心(leading core),另一个作为后续核心(trailing
core),且先行核心的工作频率高于后续核心。如图3所示,这种频率差异形成了临时冗余。
两个处理器通过故障检测与恢复模块(EFTM)控制核心 ID,从而执行相同任务。值得注意的是,当处理器核心请求向数据缓存写入数据时,故障检测与恢复模块会暂停数据缓存;若后续核心的缓存写入操作与先行核心一致,则故障检测与恢复模块会启动先行核心和后续核心的数据缓存;若不一致,则会生成故障信号。由于后续核心的数据仅写入数据缓存,不会改变同步动态随机存取存储器(SDRAM)中的数据,且后续核心数据缓存的脏位(dirty
bit)不会被使能。
相反,先行核心会改变数据,而后续核心仅能读取数据。通过缓存写入操作实现的检查点频率足以识别处理器的故障。此外,为使先行核心和后续核心保持相同状态,故障检测与恢复模块会接收核心0的中断信号,并根据每个处理器获取的指令计数,将中断信号发送至处于相同处理器状态的核心。重复访问不会改变外设状态,且只有先行核心能够读取外设并将数据传输给后续核心。
当动态锁步寄存器中存储非动态锁步模式值时,故障检测与恢复模块会将核心设置为非动态锁步模式。此时,每个核心的中断信号会直接传输至对应核心,且会为核心分配不同的ID,以便执行不同的软件。
在非动态锁步模式下,两个处理器的工作方式与传统双核处理器相同,通过在每个处理器上动态运行不同任务来提高吞吐量,如图3所示。
3.3 自恢复缓存
处理器通过故障检测模块(FTM)检测缓存中的瞬时故障并实现故障恢复。故障检测模块通过以下两种方式对处理器进行重构,以抵御永久性故障,并重启处理器实现故障恢复及避免永久性故障:1)运行恢复机制,利用低级缓存、同步动态随机存取存储器(SDRAM)及缓存特性恢复缓存中的数据,或重置系统;2)监控两个处理器核心的加载和存储单元,通过比较两个处理器核心的缓存写入操作来检测故障,并借助恢复模块实现恢复。
符合ISO 26262标准的半导体需具备针对永久性故障的容错设计,该设计包括磨损防护和内置自检功能(用于应对永久性故障)、多核锁步和部分检查器(用于应对瞬时故障),以及针对关联性故障的容错设计。通过失效模式与影响分析(FMEA)、故障树分析、定性分析及故障注入等方法,对针对瞬时故障、永久性故障和关联性故障的容错设计进行分析与验证。
为符合ISO 26262标准,本研究明确了危害分析与风险评估的内容,包括识别包含所提半导体的汽车系统中必须防范的危害和危害事件,为每个危害事件制定安全目标,并确定每个安全目标对应的汽车安全完整性等级(ASIL)。通过依据ISO
26262-10标准进行分析,证明了汽车系统的功能安全需求(FSR)和技术安全需求(TSR)符合相应汽车安全完整性等级的需求。
3.4 帧内、帧间特性
通用处理器(GPP)中针对128×128个处理核心的功能安全机制如图6所示。
图6:帧内安全框图
帧内安全机制要求在超线程核心(STC)中采用批处理模式,对同一帧进行两次处理以实现双模块冗余(DMR),从而检测该帧处理结果中的故障。Frame_0_s0是先行帧输入特征集对应的批处理数据,Frame_0_s1是后续帧输入特征集对应的批处理数据,且后续帧与先行帧的批处理数据量相同。若处于同一层,则先行帧和后续帧的核数据相同。将先行帧的YOLOv2算法计算结果与后续帧的结果进行比较,若二者存在差异,则需运行帧间安全机制以判断结果差异是否为可容忍故障。
当先行帧与后续帧的结果存在差异时,帧间安全机制会依据既定功能安全(SOTIF)策略,将当前帧的结果与前一帧的结果进行比较。若前一帧结果与当前帧结果的差异小于预设阈值,则采用先行帧与后续帧结果差异较小的那一帧的结果;若差异大于阈值,则不采用当前帧的结果。该阈值是根据每帧中汽车与障碍物之间的合理距离和速度计算得出的,同时还会比较识别目标的最大数量与识别百分比。
04. 验证
4.1 芯片实现
所提出的人工智能处理器如图7所示。AB9芯片采用28纳米12层金属互补金属氧化物半导体(CMOS)工艺制造,芯片面积为494平方毫米,包含10亿个两输入与非门等效逻辑门和40
MB(MB)的片上静态随机存取存储器(SRAM)。该芯片集成了一个具有128×128个纳米核心(NC)的超线程核心(STC)、40
MB的核与特征统一存储器、2个通用处理器(GPP)核心、2个功能安全处理器核心、1个16通道PCI
Express(PCIE)第三代(Gen3)接口,以及1个双通道低功耗双倍数据速率4(LPDDR4)控制器。下表总结了该芯片的规格参数:
图7:芯片占用面积
该人工智能处理器在供电电压为1.05V-1.15V、工作频率为600MHz-1.2GHz时,峰值功耗为30瓦(W)。在目标应用中,当处理器达到40万亿次浮点运算(TFLOPS)的峰值性能时,能效达到1.3万亿次运算每瓦(TOPS/W),面积效率达到65.8千兆次运算每平方毫米(GOPS/mm²)。
图中还展示了具备功能安全的神经网络计算性能。
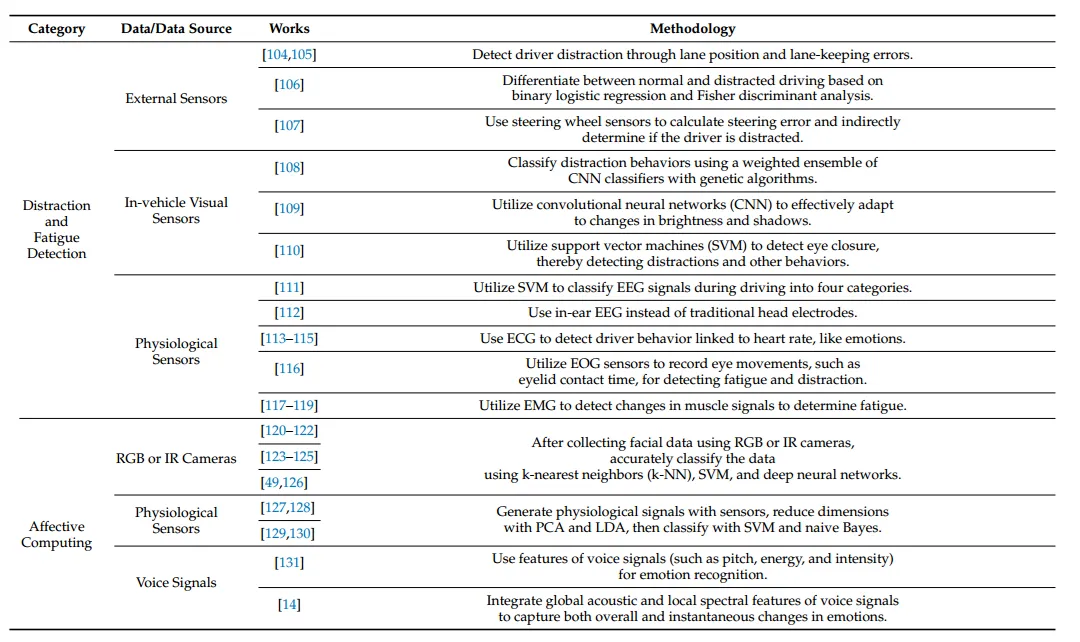
图8:故障注入的实验环境
下表对所提架构与谷歌(Google)第一代张量处理单元(TPU v1)的特性进行了比较:
下表对容错特性进行了比较:
图9:AI处理器的性能
4.2 实验板卡
如图8所示,该系统级芯片(SoC)板卡包含1个人工智能处理器、1个16通道PCI Express(PCIE)第三代(Gen3)接口、4个8
GB低功耗双倍数据速率4(LPDDR4)存储器、1个视频输入芯片和1个视频输出芯片。该板卡通过摄像头接收图像并进行识别,随后将识别结果输出至显示器。利用片上调试器(OCD)可下载由神经网络(NN)编译器生成的程序和核数据。
神经网络编译器用于生成包含神经网络描述和权重信息的超线程核心(STC)文件,以及包含硬件设置的配置(CFG)文件。使用通用处理器(GPP)编译器对包含超线程核心文件和配置文件的应用程序(如darknet.c)进行编译,并将编译后的程序下载到动态随机存取存储器(DRAM)中。之后,通过片上调试器运行通用处理器,该应用程序会接收摄像头输入的图像,并将其输出至显示器。随后,超线程核心的指令、特征数据和核数据会被传输至超线程核心中的指令存储器、特征存储器和核存储器,并运行YOLOv2算法。执行结果会在显示器上显示,包含目标定位、目标类别和置信度信息。YOLOv2算法的运行性能约为68帧/秒(fps)。
摄像头(索尼品牌)接收1280×720分辨率的视频输入,板卡内部的视频输入模块将其转换为416×416分辨率的图像,并存储到DDR4存储器中。此外,人工智能处理器通过PCI
Express接口进行通信,并通过主机(Host PC)进行控制和验证。
借助PCI Express接口,可实现两个分别包含1个人工智能处理器的板卡之间的通信,从而将YOLOv2算法拆分到两个板卡上执行。如图所示,YOLOv2算法的部分网络层在人工智能处理器板卡#0上执行,其余网络层在人工智能处理器板卡#1上执行。识别结果会在显示器上显示目标类别和置信度,供主机查看。
4.3 符合ISO 26262标准的性能
基于“脱离特定上下文的安全要素”(SEooC),通过符合ISO 26262标准的故障分析,本研究编制了安全手册,其中包括失效模式与影响分析(FMEA)、针对永久性故障的硬件指标、基于技术安全需求(TSR)的故障注入故障覆盖率,以及安全机制(SM)相关内容。
本研究中的安全机制为故障监测系统,应用该安全机制后,可通过故障注入器获取故障率。如图6所示,在包含故障监测系统的安全机制作用下,针对永久性故障的单点故障指标(SPFM)为99.64%,潜在故障指标(LFM)为93.23%。由于单点故障指标超过90%,本研究设计的处理器符合ISO
26262标准中的ASIL-D级需求。
图9展示了YOLOv2、YOLOv3、多层感知器(MLP)和长短期记忆网络(LSTM)等神经网络的性能。对于YOLOv2算法的conv1层,其输出特征矩阵维度为208×208×32,此时128×128个纳米核心(NC)会全部被激活;而YOLOv2算法的第30层,其输出特征矩阵维度为13×13×425,此时128×128个纳米核心不会全部被激活,因此YOLOv2算法运行时的有效性能仅为40万亿次浮点运算(TFLOPS)的32.8%。
图9还对比了所提架构与谷歌(Google)第一代张量处理单元(TPU v1)的性能。所提架构采用16位浮点运算结构,运算性能可达40万亿次浮点运算,其中激活运算器和归一化/池化运算器的性能为154
GFLOPS。从内部存储器到纳米核心的数据带宽为307 GB/s,与权重数据传输带宽相同;主机接口与内部存储器之间的数据带宽为22.4
GB/s;双通道LPDDR4的外部存储器带宽为41.6 GB/s。与谷歌第一代TPU相比,所提处理器的内部通信带宽更高;且当16位浮点运算量为8位整数运算量的4倍时,所提处理器的峰值性能也更具优势。
在系统级芯片板卡上通过故障注入实验对瞬时故障进行了分析。如图9所示,与以往研究相比,所提容错架构具有更高的故障覆盖率和更低的性能开销,容错性能更优。
05. 结论
本研究提出了一种人工智能处理器,该处理器采用超线程核心(STC)和核/特征统一存储器,在提高数据复用率的同时提升了运算吞吐量。此外,该人工智能处理器还融入了功能安全设计,配备自恢复缓存和动态锁步(DLS)功能,并通过运行帧内、帧间安全机制,保障超线程核心的功能安全。
该人工智能处理器采用28纳米互补金属氧化物半导体(CMOS)工艺制成原型芯片,并在现场可编程门阵列(FPGA)板卡上成功完成验证。该芯片的管芯面积为498平方毫米,包含10亿个逻辑门和40
MB的片上静态随机存取存储器(SRAM)。在供电电压为 1.1 V、工作频率为 1.2 GHz时,其峰值计算性能为
40 TFLOPS,能效为 1.3 TOPS/W。
所提人工智能处理器的核/特征统一存储器容量为40 MB,可存储核数据和特征数据,纳米核心的平均使用率为64%,有效运算性能为20.5万亿次浮点运算。与谷歌TPU相比,所提处理器具备更大的存储器容量,可同时存储核数据和特征数据,因此在运行多层感知器(MLP)和长短期记忆网络(LSTM)时,能显著提升有效性能。借助40
MB的存储器,可同时读取大量长短期记忆网络的输入特征数据,从而并行执行长短期记忆网络运算。通过提高数据复用率,可提升运算强度,进而降低外部存储器带宽需求;同时,具备功能安全设计的控制用通用处理器(GPP),其单点容错率可达99.64%。
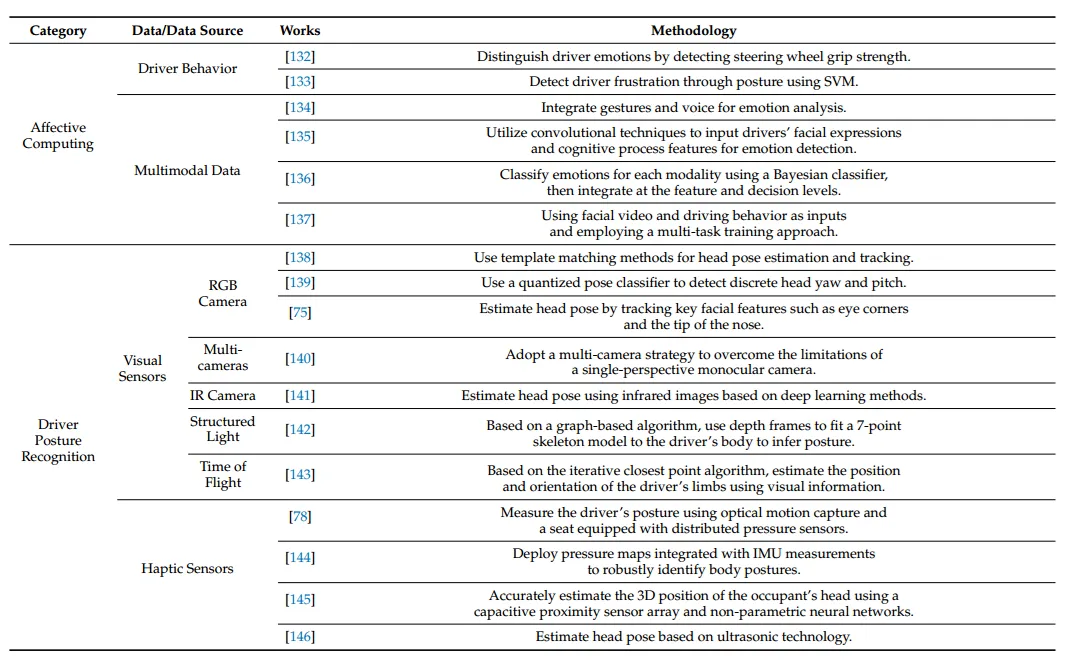
| 






 订阅
订阅