| 编辑推荐: |
|
本文主要介绍VLA和World Model世界模型的优缺点及互补性,继承与发展,希望对您的学习有所帮助。
本文来自于佐思汽车研究,由火龙果软件Linda编辑、推荐。 |
|
目前VLA占据主流地位,95%以上世界模型都是在生成视频用于自动驾驶训练而非直接用于自动驾驶,VLA已经可以量产上车。不过从理论上讲,世界模型拥有明显优势。VLA本质还是模仿学习,而世界模型是类脑学习。VLA最大的缺点是基于文字(语言),也就是离不开L,中间多了一个转接层,世界模型则是跳过这个L,直接到Action,这才是真正意义上的端到端。
世界模型的拥趸认为,仅凭文字与图像生成,AI无法真正「理解」世界。它们虽然能对提问给出看似合理的回答,却缺乏对物理现实的感知与推理能力。智慧的核心不在于对像素或文字的模仿,而在于抽象层级的理解与预测。人类开车不是基于语言或文字,而是基于对驾驶环境的理解与预测。与其预测影片中每个像素的变化,不如学会在抽象层面理解事件的因果与动态,这才是智能的基础。换句话说,VLA没有智慧,它只是在模仿,只是记忆力比较好,而世界模型拥有智慧,拥有对物理世界的理解,能够推导出因果关系,能做到零样本学习,无需标注的数据。
图片来源:网络
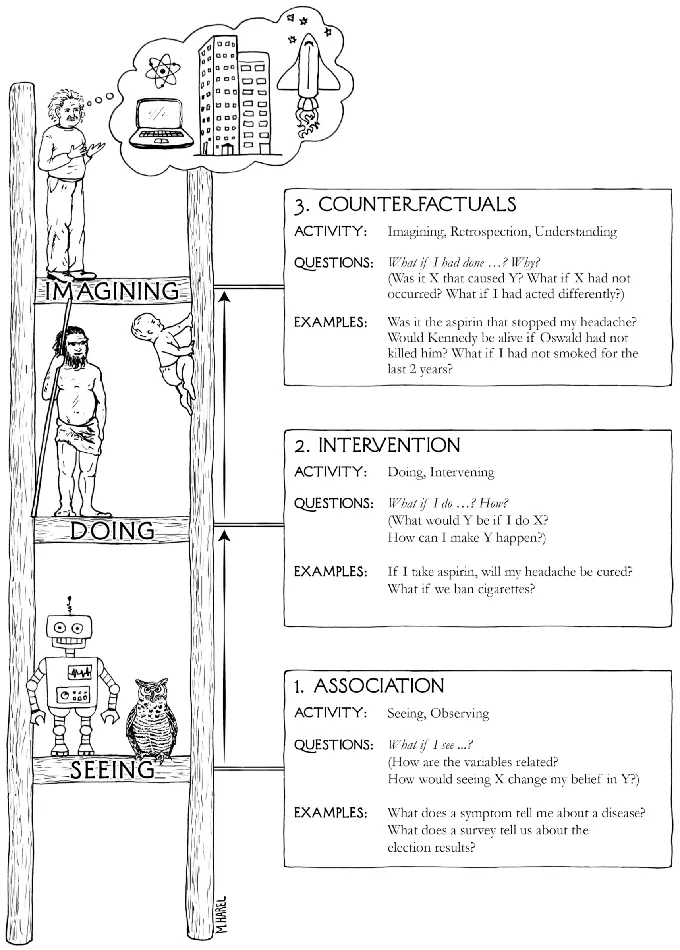
图灵奖得主Judea Pearl的科普读物The book of why中绘制了一副因果阶梯,最下层是“关联”,也就是今天大部分LLM/VLM模型主要在做的事;中间层是“干预”,强化学习中的探索就是典型的干预;最上层是反事实,通过想象回答
what if 问题。Judea为反事实推理绘制的示意图,就像科学家靠推理想象来找出世界运行的规律,即世界模型。

图片来源:网络
META AI负责人,AI界大神杨立昆对世界模型推崇备至,对LLM/VLM是不屑一顾。
世界模型不是新生事物,它比LLM还要古老,早在1994年基本定型了。
图片来源:网络
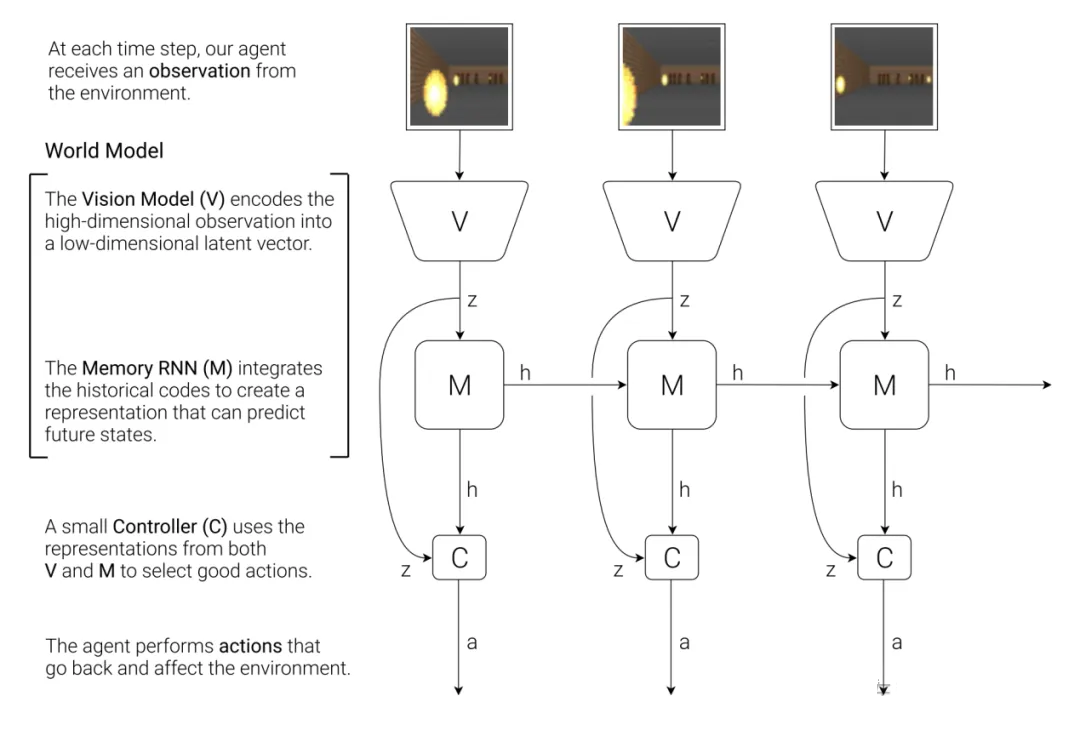
该框架图有三个主要的模块组成, 即 Vision Model(V),
Memory RNN(M)和 Controller (C)。首先是Vision Model (V),这个模块的主要作用是学习视觉观测的表示,这里用的方法是VAE,
即变分自编码器,其主要作用是将输入的视频(早期是图片) 抽取特征,Transformer兴起后则转换为Token,这个过程变成Tokenizer。在1994年,Christopher
M. Bishop就提出Mixture Density Networks,MDN 结合了常规的深度神经网络和高斯混合模型GMM。它在网络的输出部分不再使用线性层或softmax作为预测值,为了引入高斯分布模型的不确定性,每个输出都是一种高斯混合分布,而不是一个确定值或者单纯的高斯分布,高斯混合分布可以解决高斯分布不好解决的多值映射问题。以回归问题为例,输入和输出均是可能有多个维度的矢量。目标值的概率密度可以表示成多个核函数的线性组合。看到这里,熟悉强化学习的朋友就知道了,世界模型实际就是基于模型的强化学习即Model-based
RL,MBRL。
世界模型这种RNN架构,非常不适合GPU加速,所以前期发展缓慢。
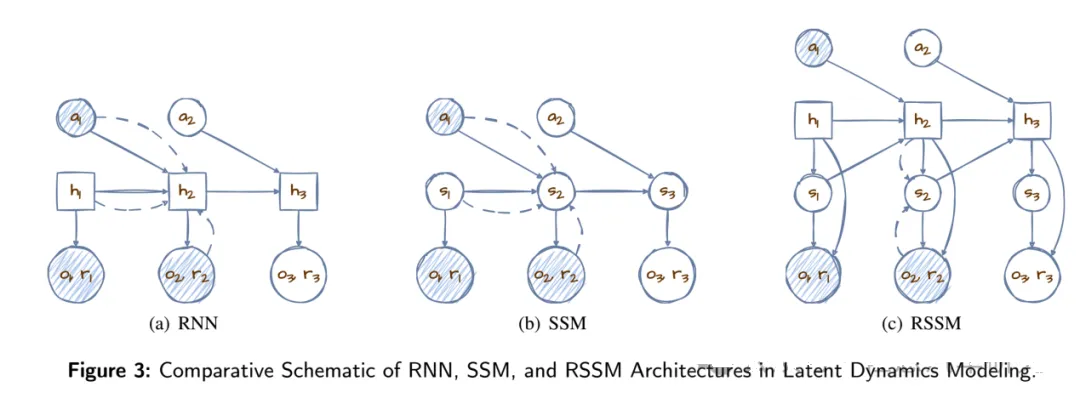
2019年进一步演化出了RSSM。
图片来源:网络
RSSM将确定和随机结合,既有确定部分防止模型随意发挥,又有随机部分提升容错性。
图片来源:网络
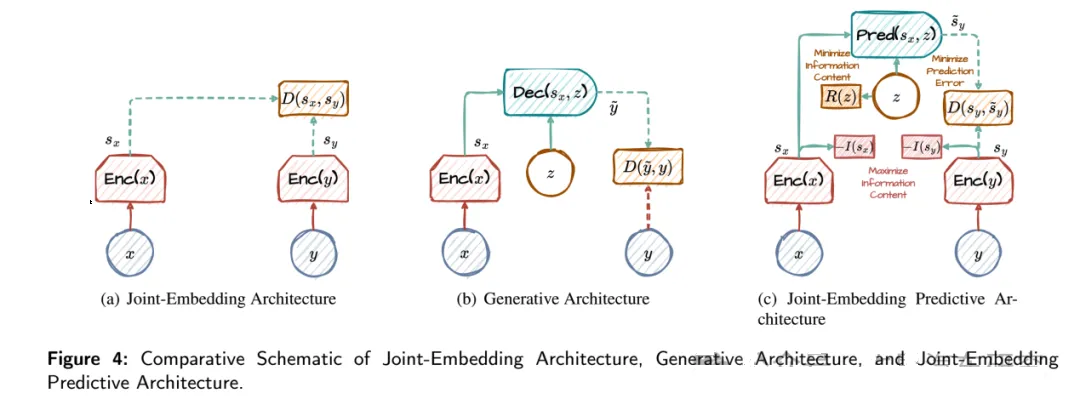
另外演化出了JEPA,RSSM和JEPA是目前的主流世界模型核心架构。JEPA是在2023年才提出的,目前最新的是2025年6月推出的V-JEPA2,JEPA的设计灵感源自人类认知方式。人类并不逐像素记忆世界,而是通过观察和互动,形成对物理世界的抽象理解,例如「推倒瓶子可能导致它翻滚」。这种理解基于高层次表征,而非精确的细节再现。与生成式模型(如LLM或扩散模型)试图重建数据(如文本或图像)的做法不同,JEPA专注于预测抽象表征,从而更高效地仿真世界动态。
具体而言,JEPA通过自我监督学习(self-supervised
learning),从输入数据(如影片、传感器数据)中提取高维表征,并预测未来状态的表征,而非生成像素级细节。例如,在分析一段影片时,JEPA不会试图预测下一帧的每个像素,而是预测场景的抽象状态(如「有人坐下」或「物体移动」)。这种方法大幅降低计算需求,并更接近人类的认知效率。
V-JEPA2
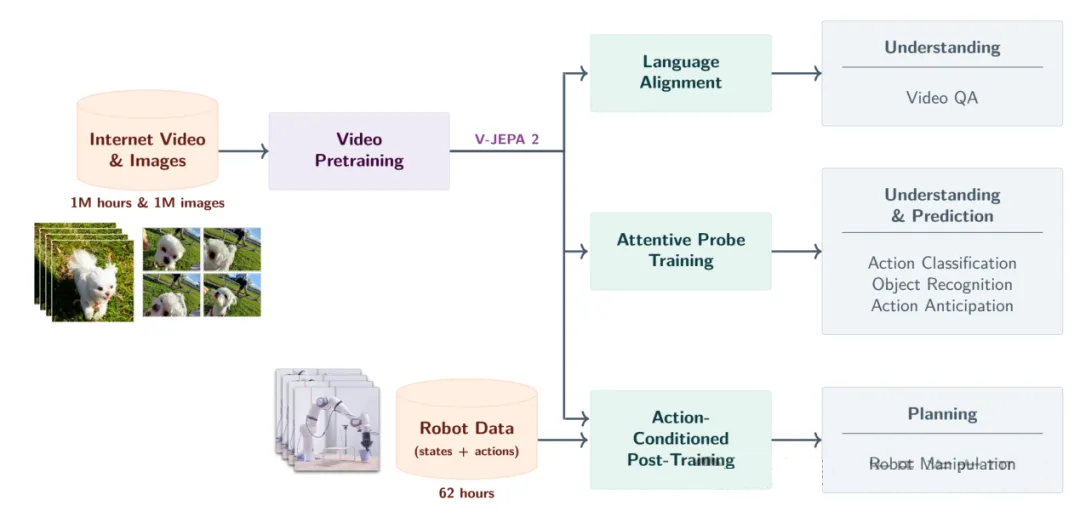
图片来源:META
模型先「看」超过一百万小时的无标注的网络影片,以及大量静态图片。透过一种名为「遮蔽潜在特征预测」的技术,V-JEPA
2学会在不完整的影像片段中,推测被遮蔽的动态与结果。例如,看见球滚动到桌边的片段时,它能在心中「补齐」球掉下去的情景。接着,V-JEPA
2只用了来自 Droid 开放数据集、不到62小时的机器人影片(就是针对特定任务的微调),就学会了如何在现实环境中操控机械手臂。它会根据任务目标生成路径,并在执行过程中不断预测下一步的可能结果,根据情况动态调整策略。这种训练方式打破了传统依赖大量专家示范数据的做法,让机器人在零样本(Zero-Shot)条件下,也能在新场景中完成任务。
世界模型两大优势,一是非逐点像素计算,所需运算资源低于VLA,而是训练数据无需任何标注,可以全部使用网络资源。然而为什么没有量产部署世界模型,只有在云端训练呢?
首先是在于数据的采集与多样性,世界模型要学会准确地理解物理世界,就需要大量涵盖各种道路、天气、交通密度等场景的高质量多样化数据。而有些如暴雨天的道路积水、急弯处突然出现的行人或者车辆失控等极端或风险场景在真实环境下往往难以收集到足够样本。如果模型只在“平时”的数据上学得很好,到真正出现罕见场景时可能就会力不从心。为应对这一点,就有技术提出将现实数据与仿真数据结合起来,先用虚拟仿真器生成极端工况的“补充样本”,再用现实数据做微调;同时,还会采用域适应(Domain
Adaptation)等技术,让模型在不同数据源之间迁移时损失更低,减少“模拟到真实”的性能差距。
其次是token化的视觉或点云难以表达物理世界的全部信息,理论上世界模型泛化能力很强,具备因果推理,但还是受限于传感器的信息,物理世界不只有视觉,视觉也不是像摄像头这样,有帧率,有FOV,人眼类似于事件相机,只在意有价值的信息,而目前摄像头和激光雷达做不到。
再次是表征崩溃,Representation Collapse。崩溃指系统忽略输入数据,生成无意义的表征,例如将所有输入映像到相同的向量。这种现象在早期联合嵌入模型中常见,限制了模型的有效性。为解决崩溃问题,需要多种正则化技术,通过限制参数值域空间,显式地控制了
模型复杂度,从而避免了过拟合。这意味着模型的学习边界被确定了,换句话说,有些因果关系无法学习得到。再有是长期预测的误差累积。因为世界模型在潜在空间里一次又一次地根据上一步的结果预测下一步,随着预测步数的增加,小小的误差就会不断叠加,最终导致与真实环境严重偏离。这在做短期预测(比如一两秒)时还可以接受,但如果要做更长时间范围的规划时,就需要特别关注。对此可采用在训练时用“半监督、自回归”和“教师强制”相结合的策略,即让模型既学会用自己预测的产出作为下一个输入,也偶尔用真实观测数据来校正;另外,在损失函数里加入对多步预测误差的惩罚,让模型对长距离时序的稳定性更敏感。这意味着世界模型又回到了典型的监督学习,失去泛化能力。
最后,VLM/VLA有CoT,模型是可以自我解释的,世界模型完全是黑盒子,没有任何可解释性,当车辆决策出现异常时很难追根溯源。此外,模型可能会被对抗攻击扰乱,使其对同一个路况输出完全不同的预测,这会对行车安全造成严重威胁。也就是说,世界模型无法迭代,只有相关性,没有确定性,彻底坠入炼丹的境界,增加训练数据可能会提高性能,也可能不会。
VLA最大的好处是它可以微调,可以用世界模型或者说基于模型的强化学习微调,它可以吸收世界模型的优点,而世界模型无法利用VLM/VLA的优点,当然VLM/VLA最大缺点是运算资源特别是存储带宽消耗比较多。
目前,几乎所有的VLA都有强化学习微调增强阶段。典型例子如博世上海研究院提出了IRL-VLA,一个全新的闭环强化学习方法,通过逆向强化学习奖励世界模型结合设计的VLA方法。具体可以看论文IRL-VLA:
Training an Vision-Language-Action Policy via Reward
World Model for End-to-End Autonomous Driving。
几种VLA对比
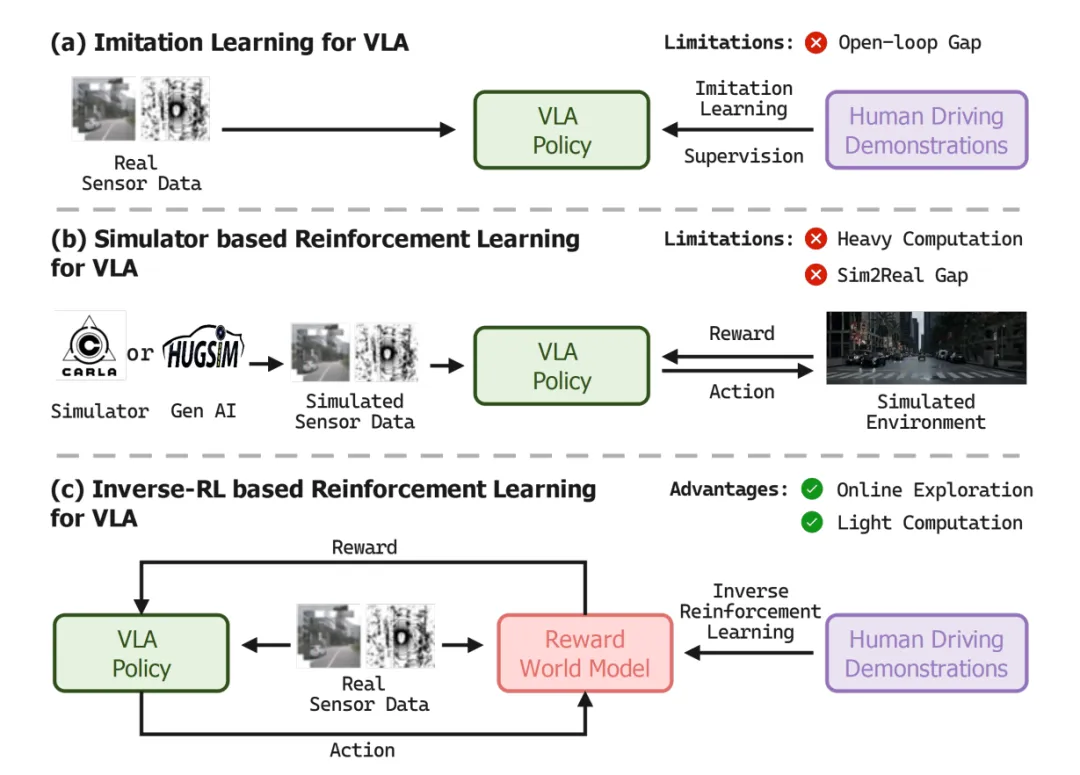
图片来源:博世
IRL-VLA框架
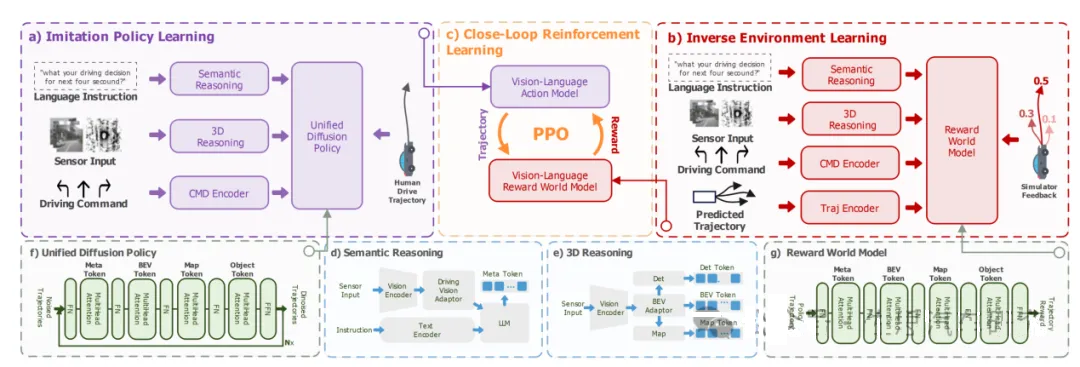
图片来源:博世
VLA和世界模型相互增强。这里需要指出Semantic reasoning使用了地平线的SENNA
VLA,其基础模型是META的小羊驼。
机器人领域亦是如此,例如阿里达摩院的WorldVLA。详细可见论文:WorldVLA:
Towards Autoregressive Action World Model。
WorldVLA框架
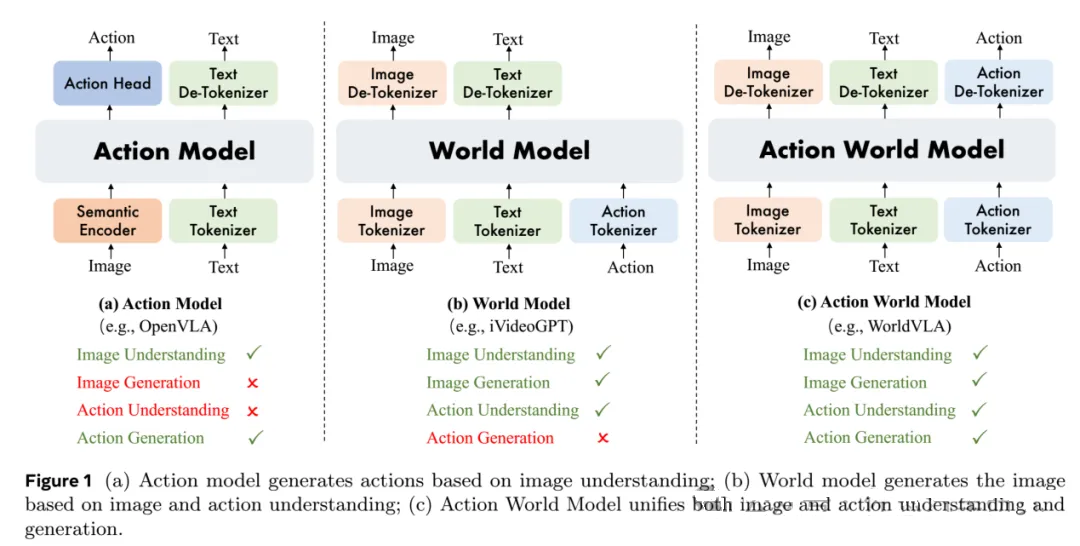
图片来源:阿里达摩院
世界模型和VLA,VLA大概率胜出,不过这个VLA不是纯粹VLA,是结合了世界模型增强的VLA。
| 






 订阅
订阅