| БрМЭЦМі: |
БОЮФЪєгкШыУХМЖБ№ЕФЮФеТЃЌжївЊНщЩмСЫЪЧЪВУДЃЌZeppelinдРэЃКInterpreterКЭSparkInterpreterЁЃ
БОЮФРДздВЉПЭдАЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
ZeppelinдРэМђНщ
ZeppelinЪЧвЛИіЛљгкWebЕФnotebookЃЌЬсЙЉНЛЛЅЪ§ОнЗжЮіКЭПЩЪгЛЏЁЃКѓЬЈжЇГжНгШыЖржжЪ§ОнДІРэв§ЧцЃЌШчsparkЃЌhiveЕШЁЃжЇГжЖржжгябдЃК
Scala(Apache Spark)ЁЂPython(Apache Spark)ЁЂSparkSQLЁЂ
HiveЁЂ MarkdownЁЂShellЕШЁЃБОЮФжївЊНщЩмZeppelinжаInterpreterКЭSparkInterpreterЕФЪЕЯждРэЁЃ
АВзАгыЪЙгУ
ВЮПМ
дРэМђНщ
Interpreter ZeppelinжазюКЫаФЕФИХФюЪЧInterpreterЃЌinterpreterЪЧвЛИіВхМўдЪаэгУЛЇЪЙгУвЛИіжИЖЈЕФгябдЛђЪ§ОнДІРэЦїЁЃУПвЛИіInterpreterЖМЪєгкЛЛвЛИіInterpreterGroupЃЌЭЌвЛИіInterpreterGroupЕФInterpretersПЩвдЯрЛЅв§гУЃЌР§ШчSparkSqlInterpreter
ПЩвдв§гУ SparkInterpreter вдЛёШЁ SparkContextЃЌвђЮЊЫћУЧЪєгкЭЌвЛИіInterpreterGroupЁЃЕБЧАвбОЪЕЯжЕФInterpreterгаsparkНтЪЭЦїЃЌpythonНтЪЭЦїЃЌSparkSQLНтЪЭЦї,JDBCЃЌMarkdownКЭshellЕШЁЃЯТЭМЪЧZeppelinЙйЭјжаНщЩмInterpreterЕФдРэЭМЁЃ
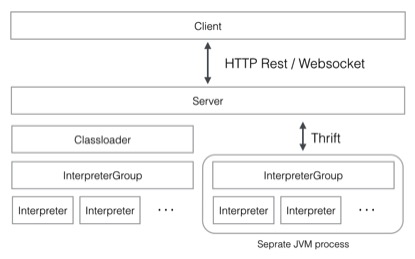
InterpreterНгПкжазюживЊЕФЗНЗЈЪЧopenЃЌcloseЃЌinterpertШ§ИіЗНЗЈЃЌСэЭтЛЙгаcancelЃЌgerProgressЃЌcompletionЕШЗНЗЈЁЃ
Open ЪЧГѕЪМЛЏВПЗжЃЌжЛЛсЕїгУвЛДЮЁЃ Close ЪЧЙиБеЪЭЗХзЪдДЕФНгПкЃЌжЛЛсЕїгУвЛДЮЁЃ Interpret ЛсдЫаавЛЖЮДњТыВЂЗЕЛиНсЙћЃЌЭЌВНжДааЗНЪНЁЃ CancelПЩбЁЕФНгПкЃЌгУгкНсЪјinterpretЗНЗЈ getPregress ЗНЗЈЛёШЁinterpretЕФАйЗжБШНјЖШ completion ЛљгкгЮБъЮЛжУЛёШЁНсЪјСаБэЃЌЪЕЯжетИіНгПкПЩвдЪЕЯжздЖЏНсЪј
SparkInterpreter
OpenЗНЗЈжаЃЌЛсГѕЪМЛЏSparkContextЃЌSQLContextЃЌZeppelinContextЃЛЕБЧАжЇГжЕФФЃЪНгаЃК
local[*] in local mode
spark://master:7077 in standalone
cluste
yarn-client in Yarn client mode
mesos://host:5050 in Mesos cluster
ЦфжаYarnМЏШКжЛжЇГжclientФЃЪНЁЃ
if (isYarnMode())
{
conf.set("master", "yarn");
conf.set("spark.submit.deployMode",
"client");
} |
InterpretЗНЗЈжаЛсжДаавЛааДњТыЃЈвд\nЗжИюЃЉЃЌЦфЪЕЛсЕїгУspark
ЕФSparkILoopвЛаавЛааЕФжДааЃЈРрЫЦгкspark shellЕФЪЕЯжЃЉЃЌетРяЕФвЛааЪЧТпМааЃЌШчЙћЯТвЛааДњТыжавдЁА.ЁБПЊЭЗЃЈЗЧЁА..ЁБ,ЁА./ЁБЃЉЃЌвВЛсКЭБОаавЛЦ№жДааЁЃЙиМќДњТыШчЯТЃК
scala.tools.nsc.interpreter.Results.Result
res = null;
try {
res = interpret(incomplete + s);
} catch (Exception e) {
sc.clearJobGroup();
out.setInterpreterOutput(null);
logger.info("Interpreter exception",
e);
return new InterpreterResult(Code.ERROR, InterpreterUtils.getMostRelevantMessage(e));
}
r = getResultCode(res); |
sparkInterpretЕФЙиМќЗНЗЈ
close ЗНЗЈЛсЭЃжЙSparkContext
cancel ЗНЗЈжБНгЕїгУSparkContextЕФcancelЗНЗЈЁЃsc.cancelJobGroup(getJobGroup(context) getProgress ЭЈЙ§SparkContextЛёШЁЫљгаstageЕФзмЕФtaskКЭвбОНсЪјЕФtaskЃЌНсЪјЕФtasksГ§вдзмЕФtaskЕУЕНЕФБШР§ОЭЪЧНјЖШЁЃ ЮЪЬт1ЃЌЪЧЗёПЩвдДцдкЖрИіSparkContextЃП
InterpreterжЇГж'shared', 'scoped', 'isolated'Ш§жжбЁЯюЃЌдкscopdeФЃЪНЯТЃЌspark
interpreterЮЊУПИіnotebookДДНЈБрвыЦїЕЋжЛгавЛИіSparkContextЃЛisolatedФЃЪНЯТЛсЮЊУПИіnotebookДДНЈвЛИіЕЅЖРЕФSparkContextЁЃ ЮЪЬт2ЃЌisolatedФЃЪНЯТЃЌЖрИіSparkContextЪЧЗёдкЭЌвЛИіНјГЬжаЃП вЛИіЗўЮёЖЫЦєЖЏЖрИіspark InterpreterКѓЃЌЛсЦєЖЏЖрИіSparkContextЁЃВЛЙ§ПЩвдгУСэЭтвЛИіjvmЦєЖЏspark
InterpreterЁЃ
ZeppelinгХШБЕуаЁНс
гХЕу 1.ЬсЙЉrestfulКЭwebSocketСНжжНгПкЁЃ 2.ЪЙгУsparkНтЪЭЦїЃЌгУЛЇАДееsparkЬсЙЉЕФНгПкБрГЬМДПЩЃЌгУЛЇПЩвдздМКВйзїSparkContextЃЌВЛЙ§гУЛЇ3.ВЛФмздМКШЅstop
SparkContextЃЛSparkContextПЩвдГЃзЄЁЃ 4.АќКЌИќЖрЕФНтЪЭЦїЃЌРЉеЙадвВКмКУЃЌПЩвдЗНБудіМгздМКЕФНтЪЭЦїЁЃ 5.ЬсЙЉСЫЖрИіЪ§ОнПЩЪгЛЏФЃПщЃЌЪ§ОнеЙЪОЗНБуЁЃ
ШБЕу 1.УЛгаЬсЙЉjarАќЕФЗНЪНдЫааsparkШЮЮёЁЃ 2.жЛгаЭЌВНЕФЗНЪНдЫааЃЌПЭЛЇЖЫПЩФмашвЊЕШД§НЯГЄЪБМфЁЃ |









