| 编辑推荐: |
本文主要介绍了Zeppelin可以实现什么,特性及Zeppelin的安装部署。
本文来自csdn,由火龙果软件Anna编辑、推荐。 |
|
Zeppelin介绍
Apache Zeppelin提供了web版的类似ipython的notebook,用于做数据分析和可视化。背后可以接入不同的数据处理引擎,包括spark,
hive, tajo等,原生支持scala, java, shell, markdown等。它的整体展现和使用形式和Databricks
Cloud是一样的,就是来自于当时的demo。
Zeppelin可实现你所需要的:
- 数据采集
- 数据发现
- 数据分析
- 数据可视化和协作
支持多种语言,默认是scala(背后是spark shell),SparkSQL,
Markdown 和 Shell。

甚至可以添加自己的语言支持。如何写一个zeppelin解释器
Zeppelin特性
Apache Spark 集成
Zeppelin 提供了内置的 Apache Spark 集成。你不需要单独构建一个模块、插件或者库。
Zeppelin的Spark集成提供了:
- 自动引入SparkContext 和 SQLContext
- 从本地文件系统或maven库载入运行时依赖的jar包。更多关于依赖载入器
- 可取消job 和 展示job进度
数据可视化
一些基本的图表已经包含在Zeppelin中。可视化并不只限于SparkSQL查询,后端的任何语言的输出都可以被识别并可视化。
Bank
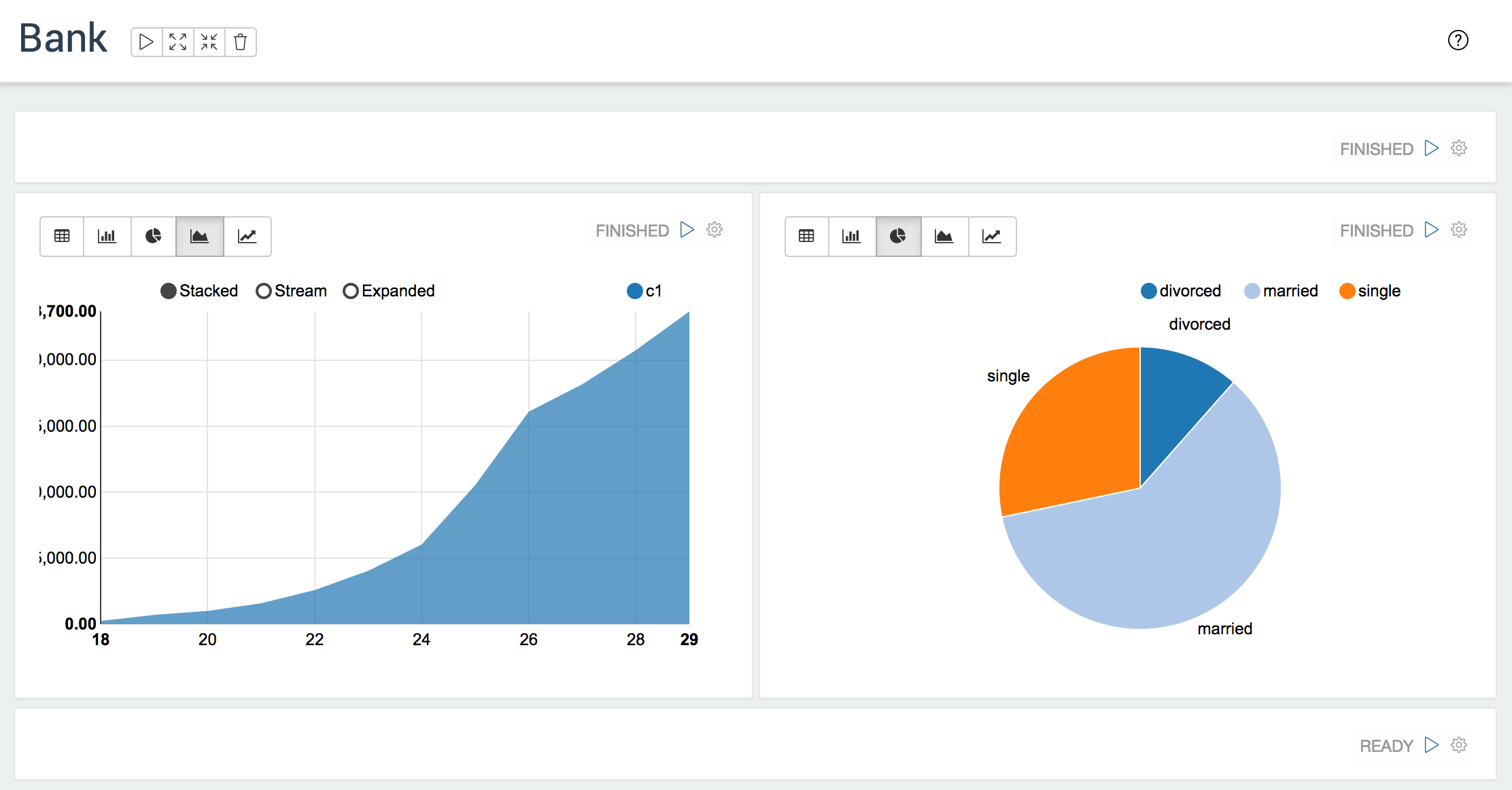
动态表格
Zeppelin 可以在你的笔记本中动态地创建一些输入格式。
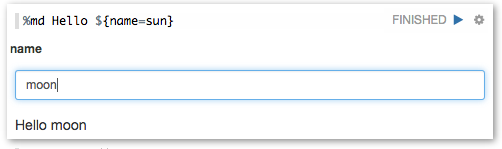
协作
Notebook 的 URL 可以在协作者间分享。 Zeppelin 然后可以实时广播任何变化,就像在
Google docs 中一样。
发布
Zeppelin提供了一个URL用来仅仅展示结果,那个页面不包括Zeppelin的菜单和按钮。这样,你可以轻易地将其作为一个iframe集成到你的网站。
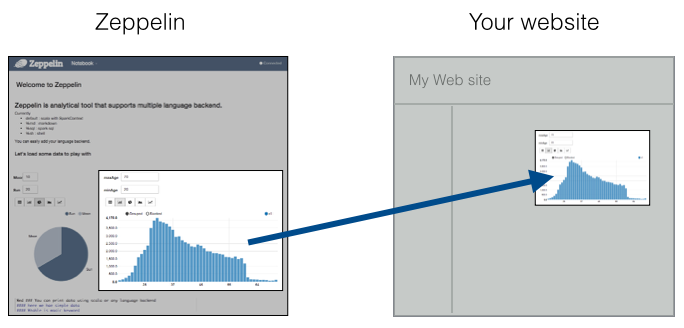
Zeppelin的安装部署
由于Zeppelin目前不提供binary安装包,所以这里Zeppelin的安装需要自己编译。
这里可以参考Zeppelin Github和Install Zeppelin
准备工作
需要
Java 1.7
Tested on Mac OSX, Ubuntu 14.X, CentOS 6.X
Maven (if you want to build from the source code)
Node.js Package Manager
在Ubuntu环境下可以这样安装:
sudo apt-get
update
sudo apt-get install openjdk-7-jdk
sudo apt-get install git
sudo apt-get install maven
sudo apt-get install npm |
注意:这里的maven工具如果不是最新的源的话,可能只是maven2,zeppelin的编译需要maven3,不然一些工具的下载会受到影响,可以从maven官网下载二进制压缩包,直接使用。
这里还需要node命令,apt-get安装npm时候会自动安装nodejs命令,这里只需要建立一个链接就可以:sudo
ln -s /usr/bin/nodejs /usr/bin/node
zeppelin-web项目的安装配置
我在之前对zeppelin整个项目进行maven部署的时候总是出现zeppelin-web项目的失败,不得其解,参照网上的方法,对zeppelin-web项目进行单独的安装配置。
这里每一步都很关键,我在这里的配置安装折腾了很多次,最终才能正常的完成安装,下面一一道来。
删除zeppelin-web项目的pom.xml下面给出的内容,换做手动安装:
<plugin>
<groupId>com.github.eirslett</groupId>
<artifactId>frontend-maven-plugin</artifactId>
<version>0.0.23</version>
<executions>
<execution>
<id>install node and npm</id>
<goals>
<goal>install-node-and-npm</goal>
</goals>
<configuration>
<nodeVersion>v0.10.18</nodeVersion>
<npmVersion>1.3.8</npmVersion>
</configuration>
</execution>
<execution>
<id>npm install</id>
<goals>
<goal>npm</goal>
</goals>
</execution>
<execution>
<id>bower install</id>
<goals>
<goal>bower</goal>
</goals>
<configuration>
<arguments>--allow-root install</arguments>
</configuration>
</execution>
<execution>
<id>grunt build</id>
<goals>
<goal>grunt</goal>
</goals>
<configuration>
<arguments>--no-color --force</arguments>
</configuration>
</execution>
</executions>
</plugin> |
手动安装步骤:
1. 安装好npm和node
2. 进入zeppelin-web目录下,执行npm install。它会根据package.json的描述安装一些grunt的组件,安装bower,然后再目录下生产一个node_modules目录。
3. 执行bower –-allow-root install,会根据bower.json安装前段库依赖,有点类似于java的mvn。
4. 执行grunt --no-color –-force,会根据Gruntfile.js整理web文件。
第3、4步要注意,本来给定的bower和grunt文件中使用的"node/node"命令,因为使用maven自动安装时,会在当前目录下生成node目录,其中包含node命令。我们之前已经安装了nodejs命令,并新链接了命令node,所以这里需要将其修改为"node"。
5. 执行mvn install -DskipTests,把web项目打包,在target目录下会生成war
pom.xml在生成war包的时候,要参照dist\WEB-INF\web.xml文件,所以在执行该步骤之前,要明确zeppelin-web目录下由dist目录,才能最终生成正确的war包。
其他zeppelin项目的编译
其他项目的编译依照正常程序进行就可以,安装文档.
根据自己的方式进行编译:
Local mode:
mvn install -DskipTests
Cluster mode:
mvn install -DskipTests -Dspark.version=1.1.0 -Dhadoop.version=2.2.0
配置
配置文件为环境变量文件(conf/zeppelin-env.sh)和Java属性文件(conf/zeppelin-site.xml)。根据自己的要求进行配置。
启动、关闭
启动、关闭Zeppelin进程命令为:
bin/zeppelin-daemon.sh start
bin/zeppelin-daemon.sh stop
|









