| БрМЭЦМі: |
| БОЮФЪЧЪ§ОнПЦбЇМвбЇЯАТЗОЖЕФЕФЭъНсЦЊ,жївЊНВНтСЫЪ§ОнЛёШЁЁЂЪ§ОнЧхЯДЁЂЙЄОпШ§ЬѕЯпТЗЕФФкШн.
БОЮФРДздЮЂаХЧиТЗЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
Ъ§ОнПЦбЇМвГЩГЄжИФЯ(ЩЯ)
Ъ§ОнПЦбЇМвГЩГЄжИФЯ(жа)
Data Ingestion Ъ§ОнЛёШЁ
етвЛПщЕФИХФюБШНЯЛьТвЃЌжївЊЪЧЩцМАЬЋЖрЕФУћДЪИХФюЃЌКмЛьЯ§ЃЌЮвДѓжТДжТдЕФЗвывЛЯТЁЃВЛБЃжЄвЛЖЈЖдЁЃ
Summary of Data Formats
Ъ§ОнИёЪНИХвЊ
дкНјааЪ§ОнЙЄГЬЛђепЪ§ОнЙЄзїЧАЃЌЪ§ОнПЦбЇМвгІИУеыЖдЪ§ОнИёЪНгавЛИіШЋУцЕФСЫНтЁЃ
Ъ§ОнИёЪНИїжжИїбљЃЌМШгаНсЙЙЛЏЪ§ОнЃЌвВгаЗЧНсЙЙЛЏЪ§ОнЁЃМШгаЮФБОЪ§ОнЃЌЪ§жЕЪ§ОнЃЌвВгаЪБМфШеЦкЪ§ОнЁЃФФХТЭЌвЛРрЃЌШчЪБМфШеЦкЃЌвВЛсвђЮЊЪБЧјЕФВЛЭЌЖјгаВювьЁЃ
ЖдЪ§ОнИёЪНЕФСЫНтгажњгкКѓајЙЄзїЕФПЊеЙЁЃ
Data Discovery
Ъ§ОнЗЂЯж
етЪЧвЛИіЭІДѓЕФЮЪЬтЃЌЮввВВЛЧхГўзїепЕФецЪЕКЌвхЃЌЙУЭ§бджЎЁЃ
ДгДѓФПБъПДЃЌЪЧСЫНтздМКгЕгаФФаЉЪ§ОнЃЌвђЮЊЖдЪ§ОнПЦбЇМвРДЫЕЃЌЮЪЬтВЛЪЧЪ§ОнЩйЃЌЖјЪЧЪ§ОнЬЋДѓСЫЃЌЕМжТЮоЗЈШЗЖЈЗжЮіжїЬтЖјЮоДгЯТЪжЁЃЮвгІИУгУФФаЉЪ§ОнЃПФФаЉЪ§ОнгаАяжњФФаЉЮогУЃПФФаЉЪ§ОнгазюДѓЕФРћгУМлжЕЃПФФаЉЪ§ОнгжецЪЕадДцвЩЃПЯжНзЖЮзюашвЊНтОіЕФЪ§ОнЮЪЬтЪЧФФИіЃПЮвЯыЖМЪЧАкдкЪ§ОнПЦбЇМвУцЧАЕФЮЪЬтЁЃDiscoveryМДЪЧЗЂЯжЃЌвВЪЧЬНЫїЁЃ
ДгаЁЯИНкПДЃЌЪЧеыЖдЪ§ОнНјааЬНЫїадбаОПЃЌЙлВьИїБфСПЕФЗжВМЁЂЗЖЮЇЁЃЙлВьЪ§ОнМЏЕФДѓаЁЁЃжївЊФПЕФЪЧСЫНтЪ§ОнЕФЯИНкЁЃ
етУЧАбетвЛЙ§ГЬРэНтЮЊЃЌдкЭкОђЕНЪ§ОнН№ПѓЧАЃЌЕУЯШжЊЕРФФвЛИіЕиЗНЛсТёВигаН№ПѓЁЃ
Data Sources & Acquisition
Ъ§ОнРДдДгыВЩМЏ
ЕБФужЊЕРетПщЕиЗНгаН№ПѓЪБЃЌФуЕУзМБИКУздМКЕФЙЄОпСЫЃКШЗЖЈздМКашвЊЕФЪ§ОндДЁЃБШШчвЊНјаагУЛЇааЮЊЗжЮіЃЌФЧУДОЭашвЊВЩМЏгУЛЇЕФааЮЊЪ§ОнЁЃВЩМЏЪВУДЪБМфЖЮЁЂВЩМЏФФРргУЛЇЁЂВЩМЏЖрЩйЪ§ОнСПЁЃШчЙћетаЉЪ§ОнВЛДцдкЃЌдђЛЙашвЊТёЕуНјааЪеМЏЁЃ
Data Integration
Ъ§ОнМЏГЩ
Ъ§ОнМЏГЩжИДњЕФЪЧНЋВЛЭЌРДдДЕФЪ§ОнМЏГЩдквЛЦ№ГЩЮЊвЛИіЭГвЛЕФЪгЭМЁЃМДПЩвдЪЧЪ§ОнеНТдВуУцЃЌБШШчСНМвЙЋЫОКЯВЂЃЈЕЮЕЮКЭUberЃЌУРЭХКЭЕуЦРЃЉЃЌЮЊСЫвЕЮёВуУцЕФЭГвЛКЭЙцЗЖЃЌОЭашвЊНЋгУЛЇЪ§ОнвЕЮёЪ§ОнЖМЛузмЕНвЛЦ№ЃЌетИіЙ§ГЬОЭНазіЪ§ОнМЏГЩЁЃ
вВПЩвдЪЧНЋФГвЛДЮЗжЮіЫљашвЊЕФЪ§ОндДЛузмЁЃБШШчЩЯЮФЕФгУЛЇааЮЊЗжЮіЃЌШчЙћРДдДгкВЛЭЌЪ§ОнЁЂдђашвЊШЗЖЈжїМќЃЌВЩМЏКѓЗХдквЛЦ№БугкЮвУЧЪЙгУЁЃ
Г§ДЫвдЭтЃЌЕкШ§ЗНЪ§ОнНгШыЃЌDMPгІвВДгЪєгкетИіИХФюЁЃ
Data Fusion
Ъ§ОнШкКЯ
Ъ§ОнШкКЯВЛЭЌгкЪ§ОнМЏГЩЃЌЪ§ОнМЏГЩЪєгкЕзВуЪ§ОнМЏЩЯЕФКЯВЂЁЃЖјЪ§ОнШкКЯНгНќФЃаЭВуУцЃЌЮвУЧПЩвдЯыГЩSQLЕФJoinЃЈВЛШЗЖЈЃЉЁЃ
Transformation & Enrichament
зЊЛЛКЭХЈЫѕ
етвЛПщЃЌдкЕиЭМЩЯКЭСэЭтвЛЬѕЗжжЇЁОЪ§ОнзЊЛЛData MungingЁПгаСЫНЛМЏЁЃСНЬѕжЇЯпКЯВЂКѓОЭЪЧЭъећЕФЪ§ОнЬиеїЙЄГЬЁЃетвЛВНжшЪЧНЋЮвУЧВЩМЏЕФЪ§ОнМЏНјааЭГМЦбЇвтвхЩЯЕФБфЛЛЃЌГЩЮЊЪ§ОнЪфШыЕФЬиеїЁЃ
Data Survey
Ъ§ОнЕїВщ
ЮввВВЛСЫНтвбОЭъГЩЪ§ОнЙЄГЬКѓЃЌЮЊЪВУДЛЙашвЊЪ§ОнЕїВщЁ
Google OpenRefine
GoogleЗЂВМЕФПЊдДЕФЪ§ОнДІРэШэМўЁЃ
How much Data
ЖрДѓЕФЪ§Он
вЛОфБШНЯЦЋИХФюЕФЛАЃЌЪ§ОнСПМЖОіЖЈСЫКѓајЗНЗНУцУцЃЌБШШчГщбљКЭжУаХЖШЃЌБШШчЪЪгУЕФЫуЗЈФЃаЭЃЌБШШчММЪѕбЁаЭЁЃ
Using ETL
ЪЙгУETLЃЌвбОНщЩмЙ§СЫ
ЁЊЁЊЁЊЁЊЁЊЁЊ
Data Munging Ъ§ОнЧхРэ/Ъ§ОнзЊЛЛ
Ъ§ОнЧхЯДЙ§ГЬЃЌЛњЦїбЇЯАжазюКФЗбЪБМфЕФЙ§ГЬЁЃ
Dimensionality & Numerosity Reduction
ЮЌЖШгыЪ§жЕЙщдМ
ЫфШЛЮвУЧгаКЃСПЪ§ОнЃЌЕЋЪЧЮвУЧВЛПЩФмдкКЃСПЪ§ОнЩЯНјааИДдгЕФЪ§ОнЗжЮіКЭЭкОђЁЃЫљвдвЊгІгУЪ§ОнЙцдМММЪѕЁЃЫќЕФФПЕФЪЧОЋМђЪ§ОнЃЌШУЫќОЁПЩФмЕФаЁЃЌгжФмБЃжЄЪ§ОнЕФЭъећадЃЌЪЙЕУЮвУЧдкКЃСПЪ§ОнМЏКЭаЁЪ§ОнМЏЩЯЛёЕУЯрНќЕФНсЙћЁЃ
жївЊЪЧЩОГ§ВЛживЊЛђВЛЯрЙиЕФЬиеїЃЌЛђепЭЈЙ§ЖдЬиеїНјаажизщРДМѕЩйЬиеїЕФИіЪ§ЁЃЦфддђЪЧдкБЃСєЁЂЩѕжСЬсИпдгаХаБ№ФмСІЕФЧАЬсЯТНјааЁЃ
Normalization
Ъ§ОнЙцЗЖЛЏ
дкЛњЦїбЇЯАЙ§ГЬжаЃЌЮвУЧВЂВЛФмжБНгЪЙгУдЪМЪ§ОнЃЌвђЮЊВЛЭЌЪ§жЕМфЕФСПИйВЛвЛбљЃЌЮоЗЈжБНгЧѓКЭКЭЖдБШЁЃЮвУЧЛсНЋЪ§ОнБъзМЛЏЃЌЪЙжЎТфдквЛИіЪ§жЕЗЖЮЇ[0,1]ФкЁЃЗНБуНјааМЦЫуЁЃ
ГЃМћЕФЪ§ОнБъзМЛЏгаmin-maxЃЌz-scoreЃЌdecimal scalingЕШЁЃ
зюаЁ-зюДѓЙцЗЖЛЏЃЈmin-maxЃЉЪЧЖддЪМЪ§ОнНјааЯпадБфЛЛЃЌаТЪ§Он = (дЪ§Он-зюаЁжЕ)ЃЏ(зюДѓжЕ-зюаЁжЕ)ЁЃ
z-score БъзМЛЏЪЧЛљгкОљжЕКЭБъзМВюНјааМЦЫуЃЌаТЪ§Он=ЃЈдЪ§Он-ОљжЕЃЉ/БъзМВюЁЃ
аЁЪ§ЖЈБъБъзМЛЏЃЈdecimal scalingЃЉЭЈЙ§вЦЖЏЪ§ОнЕФаЁЪ§ЕуЮЛжУРДНјааБъзМЛЏЃЌаЁЪ§ЕувЦЖЏЖрЩйШЁОігкзюДѓОјЖджЕЁЃБШШчзюДѓжЕЪЧ999ЃЌФЧУДЪ§ОнМЏжаЫљгажЕЖМГ§вд1000ЁЃ
ЮТмАЬсЪОЃЌБъзМЛЏЛсИФБфЪ§ОнЃЌЫљвдБъзМЛЏгІИУдкБИЗндЪМЪ§ОнКѓНјааВйзїЃЌБ№жБНгИВИЧроЁЃ
Data Scrubbing
Ъ§ОнЧхЯД
Ъ§ОнЭкОђжазюЭДПрЕФЙЄзїЃЌУЛгажЎвЛЁЃЪ§ОнвЛАуЖМЪЧЗЧЙцећЕФЃЌЮвУЧГЦжЎЮЊдрЪ§ОнЃЌЫќЪЧЮоЗЈжБНггУгкЪ§ОнФЃаЭЕФЃЌЭЈЙ§вЛЖЈЙцдђНЋдрЪ§ОнЙцЗЖЛюзХЯДЕєЃЌетИіЙ§ГЬНазіЪ§ОнЧхЯДЁЃ
ГЃМћЮЪЬтЮЊЃК
ШБЪЇЪ§ОнЃЌБэЯжЮЊNaNЃЌШБЪЇдвђИїгаВЛЭЌЃЌЛсгАЯьКѓајЕФЪ§ОнЭкОђЙ§ГЬЁЃ
ДэЮѓЪ§ОнЃЌШчЙћЪ§ОнЯЕЭГВЛНЁШЋЃЌЛсАщЫцКмЖрДэЮѓЪ§ОнЃЌР§ШчШеЦкИёЪНВЛЭГвЛЃЌДцдк1970ДэЮѓЃЌжаЮФТвТыЃЌБэЧщзжЗћЕШЕШЁЃЫМТЗзюКУЪЧДгДэЮѓИљдДЩЯНтОіЁЃ
ЗЧЙцЗЖЪ§ОнЃЌШчЙћДѓЦНЬЈУЛгаЭГвЛЕФЪ§ОнБъзМКЭЪ§ОнзжЕфЃЌЪ§ОнЛсгаВЛЙцЗЖЕФЧщПіЗЂЩњЁЃБШШчгааЉБэЃЌ1ДњБэФаШЫЃЌ0ДњБэХЎШЫЃЌЖјгааЉБэдђЗДЙ§РДЃЌвВПЩФмЪЧЩЯКЃКЭЩЯКЃЪаетРрЮЪЬтЁЃЭЈГЃЭЈЙ§mappingЛђепЭГвЛЕФзжЕфНтОіЁЃ
жиИДЪ§ОнЁЃНЋжиИДЪ§ОнАДжїМќЬоГ§ЕєОЭКУЃЌПЩФмЪЧJoinЪБЕФДэЮѓЃЌПЩФмЪЧГщбљДэЮѓЃЌЕШЕШЁЃ
Ъ§ОнЧхЯДЪЧвЛИіГЄЦкЕФЙ§ГЬЁЃКмЖрЧщПіЯТЖМЪЧППШЫШтНтОіЕФЁЃ
Handling Missing Values
ШБЪЇжЕДІРэ
Ъ§ОнЛёШЁЕФЙ§ГЬжаПЩФмЛсдьГЩШБЪЇЃЌШБЪЇгАЯьЫуЗЈЕФНсЙћЁЃ
ШБЪЇжЕЕФДІРэгаСНРрЫМТЗЃК
ЕквЛжжЪЧВЙШЋЃЌЪзЯШГЂЪдЦфЫћЪ§ОнВЙШЋЃЌР§ШчЩэЗнжЄКХТыФмЙЛЭЦЖЯГіадБ№ЁЂМЎЙсЁЂГіЩњШеЦкЕШЁЃЛђепЪЙгУЫуЗЈЗжРрКЭдЄВтЃЌБШШчЭЈЙ§аеУћВТВтгУЛЇЪЧФаЪЧХЎЁЃ
ШчЙћЪЧЪ§жЕаЭБфСПЃЌПЩвдЭЈЙ§ЫцЛњВхжЕЁЂОљжЕЁЂЧАКѓОљжЕЁЂжаЮЛЪ§ЁЂЦНЛЌЕШЗНЗЈВЙШЋЁЃ
ЕкЖўжжЪЧШБЪЇЙ§ЖрЃЌжЛФмЬоГ§етРрЪ§ОнКЭЬиеїЁЃЛђепНЋШБЪЇгыЗёзїЮЊаТЬиеїЃЌЯёН№ШкЗчЯеЙмПиЃЌЙиМќаХЯЂЕФШБЪЇШЗЪЕФмЕБаТЬиеїЁЃ
Unbiased Estimators
ЮоЦЋЙРМЦСП
ЮоЦЋЙРМЦжИЕФЪЧбљБООљжЕЕФЦкЭћЕШгкзмЬхОљжЕЁЃвђЮЊбљБООљжЕгРдЖгаЫцЛњвђЫиЕФИЩШХЃЌВЛПЩФмЭъШЋЕШгкзмЬхОљжЕЃЌЫљвдЫќжЛЪЧЙРМЦЃЌЕЋЫќЕФЦкЭћгжЪЧвЛИіецЪЕжЕЃЌЫљвдЮвУЧНазіЮоЦЋЙРМЦСПЁЃ
ЛњЦїбЇЯАжаГЃГЃгУНЛВцбщжЄЕФЗНЗЈЃЌеыЖдВтЪдМЏдкФЃаЭжаЕФБэЯжЃЌШУЙРМЦСПНЅНјЮоЦЋЁЃ
Binning Sparse Values
ЗжЯфЯЁЪшжЕЃЌСНИіКЯЦ№РДЮвВЛжЊЕРОпЬхвтЫМ
ЗжЯфЪЧвЛжжГЃМћЕФЪ§ОнЧхЯДЗНЗЈЃЌЪзЯШЪЧНЋЪ§ОнХХађВЂЧвЗжИєЕНвЛаЉЯрЕШЩюЖШЕФЭА(bucket)жаЃЌШЛКѓИљОнЭАЕФОљжЕЁЂжаМфжЕЁЂБпНчжЕЕШЦНЛЌЁЃГЃМћЕФЗжИєЗНЗЈгаЕШПэЛЎЗжКЭЕШЩюЛЎЗжЃЌЕШПэЗЖЮЇЪЧИљОнзюДѓжЕКЭзюаЁжЕОљдШЗжИєГіЪ§ИіЗЖЮЇЯрЭЌЕФЧјМфЃЌЕШЩюдђЪЧбљБОЪ§НќЫЦЕФЧјМфЁЃ
ЯЁЪшЪЧЭГМЦжаКмГЃМћЕФвЛИіДЪЃЌжИЕФЪЧдкОиеѓЛђепЬиеїжаЃЌОјДѓВПЗжжЕЖМЪЧ0ЁЃНазіЯЁЪшЬиеїЛђЯЁЪшОиеѓЁЃаЭЌЙ§ТЫОЭгУЕНСЫЯЁЪшОиеѓЁЃ
Feature Extraction
ЬиеїЬсШЁЃЏЬиеїЙЄГЬ
ЧАУцвбОгаЙ§етИіСЫЃЌетРяИХФюдйРЉДѓаЉЁЃЮвУЧжЊЕРЃКЪ§ОнКЭЬиеїОіЖЈСЫЛњЦїбЇЯАЕФЩЯЯоЃЌЖјФЃаЭКЭЫуЗЈжЛЪЧБЦНќетИіЩЯЯоЖјвбЁЃЫЕЕФдйЭЈЫзвЛЕуЃЌКУЫуЗЈ+РУЬиеїЪЧдЖБШВЛЩЯРУЫуЗЈ+КУЬиеїЕФЁЃ
ЬиеїЬсШЁЕФЙ§ГЬжївЊЗжЮЊЃК
Ъ§ОндЄДІРэЃКНЋвбОЧхЯДЙ§ЕФЪ§ОнНјаазЊЛЛЃЌАќРЈШЅСПИйЛЏЁЂЙщвЛЛЏЁЂЖўдЊЛЏЁЂРыЩЂЛЏЁЂбЦБфСПЛЏЁЂЖдЪ§БфЛЛжИЪ§БфЛЛЕШЁЃ
ЬиеїбЁдёЃКРћгУИїРрЭГМЦбЇбЁдёЬиеїЃЌжївЊгаFilterЙ§ТЫЗЈЁЂWrapperАќзАЗЈЁЂEmbeddedЧЖШыЗЈЁЃКЫаФФПЕФЪЧевГіЖдНсЙћгАЯьзюДѓЕФЬиеїЁЃЭЈГЃЪЧДгвЕЮёвтвхГіЗЂЃЌКУЕФвЕЮёзЈМвФмЙЛжБНгЬєбЁЙиМќЬиеїЁЃСэЭтгаЪБКђЛсгіЕНОпБИживЊвЕЮёвтвхЃЌЕЋЪЧЗЧЧПЬиеїЕФЧщПіЃЌетЪБКђашвЊвРОнЪЕМЪЧщПізіОёдёЁЃ
ЬиеїбЁдёЙ§ГЬжаашвЊПМТЧФЃаЭЕФЗКЛЏФмСІЃЌБмУтЙ§ФтКЯЁЃ
НЕЮЌЃКШчЙћЬиеїЮЌЖШЙ§ДѓЃЌЛсжБНггАЯьМЦЫуадФмЃЌашвЊНЕЮЌЁЃГЃгУЕФНЕЮЌЗНЗЈгажїГЩЗжЗжЮіЗЈЃЈPCAЃЉКЭЯпадХаБ№ЗжЮіЃЈLDAЃЉЁЃ
ЕБШЛБЉСІаЉвВФмжБНгбЁдёШЋВПБфСПЃЌШгНјRFЛђепXGBoostФЃаЭжаХмвЛИіЭэЩЯЃЌжБНгИљОнGiniжИЪ§ВщПДживЊадЁЃ
Denoising
ШЅды
дкЛњЦїбЇЯАКЭЪ§ОнЭкОђжаЃЌЪ§ОнЭљЭљгЩКмЖрдыЩљЃЌШЅГ§дыЩљЕФЗНЗЈгаЖржжЖрбљЃЌвЛАуЫЕРДЃЌЪ§ОнСПдНДѓЃЌдыЩљдьГЩЕФгАЯьОЭдНЩйЁЃ
дыЩљЪЧЗЧецЪЕЕФЪ§ОнЃЌШчЙћвЛИігУЛЇФГаЉаХЯЂУЛгаЬюаДЃЌЮЊШБЪЇжЕЃЌЫќВЛгІИУЪєгкдыЩљЃЌеце§ЕФдыЩљгІИУЪЧВтЪдШЫдБЁЂЛњЦїШЫЁЂХРГцЁЂЫЂЕЅЛЦХЃЁЂзїБзааЮЊЕШЁЃетРрЪ§ОнУЛгавЕЮёвтвхЃЌМгШыФЃаЭЛсгАЯьНсЙћЃЌдкдчЦкОЭИУХХГ§ЕєЁЃ
СэЭтвЛжждыЩљЪЧЮоЗЈНтЪЭЕФЪ§ОнВЈЖЏЃЌКЭЦфЫћЪ§ОнВЛЯрвЛжТЁЃвђЮЊЪ§ОнЛсЪмвЛаЉПЭЙлЬѕМўгАЯьдьГЩВЈЖЏЃЌШЅдыЪЧЪЙвьГЃВЈЖЏЯћГ§ЁЃ
ШЅдыдкЪ§ОнЧхЯДЙ§ГЬЁЃ
Sampling
Гщбљ
КмЖрЪБКђЭГМЦВЛПЩФмМЦЫуећЬхЃЌБШШчжаЙњЦНОљЙЄзЪОЭЪЧФУ14вкШЫПквЛИіИіМЦЫуЙ§РДЕФУДЃПЪ§ОнПЦбЇжаЃЌШчЙћФУШЋбљБОМЦЫуЃЌПЩФмЕЅЛњЕФФкДцГдВЛЯћЃЌЛђепУЛгаЗўЮёЦїзЪдДЁЃФЧУДжЛФмГщШЁВПЗжбљБОзїЮЊЪ§ОнЗжЮіЁЃ
ГщбљгаМђЕЅЫцЛњГщбљЁЂЯЕЭГГщбљЁЂЗжВуГщбљЁЂећШКГщбљЕШЁЃЮоТлдѕУДбљГщбљЃЌЖМвЊЧѓбљБОгазуЙЛЕФДњБэадЃЌМДТњзувЛЖЈЪ§СПЃЌгжТњзуЫцЛњадЁЃ
Stratified Sampling
ЗжВуГщбљ
ЪЧГщбљЕФвЛжжЁЃНЋГщбљЕЅЮЛвдФГжжЬиеїЛђепЙцТЩЛЎЗжГЩВЛЭЌЕФВуЃЌШЛКѓДгВЛЭЌЕФВужаГщбљЃЌзюКѓНсКЯЦ№РДзїЮЊзмбљБОЁЃ
ЮЊЪВУДашвЊЗжВуГщбљЃПШчЙћећШКЗћКЯЫцЛњадЕЙЛЙКУЃЌШчЙћВЛЪЧЛсдьГЩЭГМЦЩЯЕФЮѓВюЁЃЮввЊзіЩчЛсЕїбаЃЌИїРрШЫЖМашвЊЃЌФЧУДОЭБиаыгаФагаХЎЁЂгаРЯгаЩйЁЂгаГЧЪагаХЉДхЃЌЖјВЛЪЧДєдквЛИіЩЬГЁУХПкзіЕїбаЁЃЧАепОЭЪєгкЗжВуГщбљЁЃ
ЗжВуГщбљПЩвдНЕЕЭбљБОСПЃЌаЇТЪИпЁЃ
Principal Component Analysis
жїГЩЗжЗжЮі
МђГЦPCAЃЌЪЧвЛжжЭГМЦЗНЗЈЁЃдкЪЕМЪЙЄзїжаЃЌЮвУЧЛсгіЕНКмЖрБфСПЪ§ОнЃЈБШШчЭМЯёКЭаХКХЃЉЃЌЖјЮвУЧгжВЛПЩФмвЛвЛСаОйЫљгаЕФБфСПЃЌетЪБКђЮвУЧжЛФмФУГіМИИіЕфаЭЃЌНЋетаЉБфСПИпЖШИХРЈЃЌвдЩйЪ§ДњБэЖрЪ§ЕФЗНЪННјааУшЪіЁЃетжжЗНЪНОЭНазіжїГЩЗжЗжЮіЁЃ
ШчЙћБфСПЭъШЋЖРСЂЃЌФЧУДжїГЩЗжЗжЮіУЛгавтвхЁЃPCAЧАЬсЬѕМўЪЧДцдквЛЖЈЯрЙиадЁЃ
ЭЈЙ§ШЅОљжЕЛЏЕФmЮЌдЪМОиеѓГЫвдЦфаЗНВюОиеѓЕФЬиеїЯђСПЛёЕУkЮЌЭЖгАЃЌетРяЕФkЮЌОЭНазіжїГЩЗжЃЌгУРДДњБэmЮЌЁЃвђЮЊPCAЕФКЫаФЪЧЩйЪ§ДњБэЖрЪ§ЃЌЮвУЧДгkИіжїГЩЗжжабЁдёnИізїЮЊДњБэЃЌБъзМЪЧФмДњБэ80%ЕФдЪ§ОнМЏЁЃ
дкЛњЦїбЇЯАжаЃЌжївЊгУРДНЕЮЌЃЌМђЛЏФЃаЭЁЃГЃМћгкЭМЯёЫуЗЈЁЃ
ЁЊЁЊЁЊЁЊЁЊЁЊ
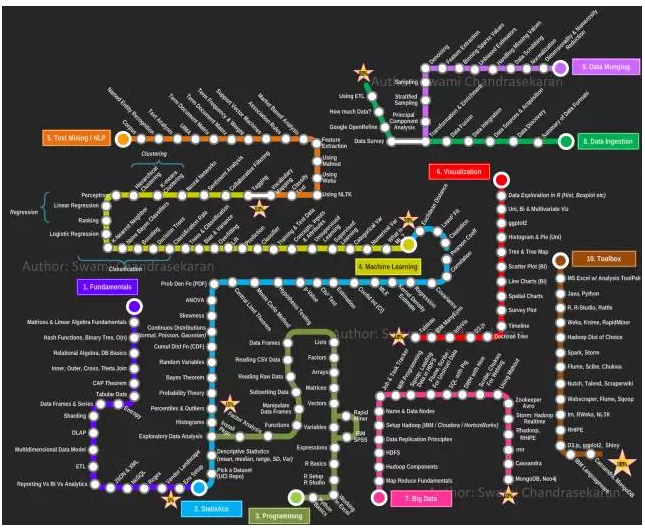
ToolBoxЙЄОпЯф
зюКѓФкШнСЫЃЌетвЛПщзїепгаЦДДеЕФЯгвЩЃЌЖМЪЧжЎЧАвбОГіЯжЕФФкШнЁЃЪ§ОнПЦбЇЕФЙЄОпИќаТЛЛДњЗЧГЃПьЃЌКУЙЄОпВуГіВЛЧюЃЌЫљвдИУЦЊеТЕФЙЄОпОЭШЪепМћШЪЃЌаДЕФМђТдвЛаЉЁЃ
MS Excel / Analysis ToolPak
ЮЂШэЕФExcelЃЌВЛЖрЫЕСЫЁЃ
КѓепЪЧExcelздДјЕФЗжЮіЙЄОпПтЃЌПЩвдЭъГЩВЛЩйЭГМЦВйзїЁЃ
Java, Python
СНжжГЃМћБрГЬгябдЃЌЧыдкетРяКЭЮвФюЃКШЫЩњПрЖЬЃЌПьгУPythonЁЃ
R, R-Studio, Rattle
RгябдВЛдйЖрНщЩмСЫЁЃ
RStudioЪЧRЕФIDEЃЌМЏГЩСЫЗсИЛЕФЙІФмЁЃ
RattleЪЧЛљгкRЕФЪ§ОнЭкОђЙЄОпЃЌЬсЙЉСЫGUIЁЃ
Weka, Knime, RapidMiner
WekaЪЧвЛПюУтЗбЕФЃЌЛљгкJAVAЛЗОГЯТПЊдДЕФЛњЦїбЇЯАвдМАЪ§ОнЭкОђШэМўЁЃ
KNIMEЪЧЛљгкEclipseЛЗОГЕФПЊдДЩЬвЕжЧФмЙЄОпЁЃ
RapidMinerЪЧвЛИіПЊдДЕФЪ§ОнЭкОђШэМў,ЬсЙЉвЛаЉПЩРЉеЙЕФЪ§ОнЗжЮіЭкОђЫуЗЈЕФЪЕЯжЁЃ
Hadoop Dist of Choice
бЁдёHadoopЕФФФИіЗЂааАц
HadoopЕФЗЂааАцГ§СЫЩчЧјЕФApache hadoopЭтЃЌКмЖрЩЬвЕЙЋЫОЖМЬсЙЉСЫздМКЕФЩЬвЕАцБОЁЃЩЬвЕАцжївЊЪЧЬсЙЉСЫзЈвЕЕФММЪѕжЇГжЃЌУПИіЗЂааАцЖМгаздМКЕФвЛаЉЬиЕуЁЃ
Spark, Storm
HadoopЯрЙиЕФЪЕЪБДІРэПђМм
зїепаДЕФЪБКђБШНЯдчЃЌЯждкКѓСНепвбОЗЧГЃЛ№СЫЁЃЪЧЖдHadoopЕФВЙГфКЭЭъЩЦЁЃЫќУЧздЩэвВЗЂеЙГіВЛЩйЕФЬзМўЃЌSparkMLЃЌSparkSQLЕШ
Flume, Scribe, Chukwa
FlumeЪЧКЃСПШежОВЩМЏЁЂОлКЯКЭДЋЪфЕФЯЕЭГЁЃ
ScribeЪЧFacebookПЊдДЕФШежОЪеМЏЯЕЭГЃЌдкFacebookФкВПвбОЕУЕНЕФгІгУЁЃ
chukwaЪЧвЛИіПЊдДЕФгУгкМрПиДѓаЭЗжВМЪНЯЕЭГЕФЪ§ОнЪеМЏЯЕЭГЁЃ
Nutch, Talend, Scraperwiki
NutchЪЧвЛИіПЊдДJavaЪЕЯжЕФЫбЫїв§ЧцЁЃЫќЬсЙЉСЫЮвУЧдЫааздМКЕФЫбЫїв§ЧцЫљашЕФШЋВПЙЄОпЁЃАќРЈШЋЮФЫбЫїКЭWebХРГцЁЃ
TalendЪЧвЛМвзЈвЕЕФПЊдДМЏГЩШэМўЙЋЫОЃЌЬсЙЉИїРрЪ§ОнЙЄОпЁЃ
ScraperWiKiЪЧвЛИіжТСІгкЪ§ОнПЦбЇСьгђЮЌЛљАйПЦЭјеОЃЌАяжњИіШЫКЭЦѓвЕЛёЕУзюзЈвЕЕФПЩЪгЛЏЪ§ОнЃЌВЂжЇГжЖдЪ§ОнНјааЗжЮіКЭЙмРэЁЃ
Webscraper, Flume, Sqoop
WebscraperЪЧЭјвГХРГцЁЃ
FlumeЪЧКЃСПШежОВЩМЏЁЂОлКЯКЭДЋЪфЕФЯЕЭГЁЃ
SqoopЪЧHaddopЬзМўЁЃ
tm, RWeka, NLTK
tmЪЧRгябдЕФЮФБОЭкОђАќЁЃ
RWekaЪЧRЕФШэМўАќЃЌМгдиКѓОЭФмЪЙгУwekaЕФвЛаЉЫуЗЈЁЃ
NLTKЪЧздШЛгябдЙЄОпАќЁЃ
RHIPE
RгыHadoopЯрЙиЕФПЊЗЂЛЗОГЁЃ
D3.js, ggplot2, Shiny
ЧАСНИіВЛЖрЫЕСЫЁЃ
ShinyЪЧRStudioЭХЖгПЊЗЂЕФвЛПюдкЯпЭјвГНЛЛЅПЩЪгЛЏЙЄОпЁЃПЩвдНЋRгябдзїЮЊАыИіBIгУЁЃ
IBM Languageware
IBMЕФздШЛгябдДІРэЁЃ
Cassandra, MongoDB
2жжNoSqlЪ§ОнПтЁЃ
ЖСЭъетРяЃЌШ§ЦЊЮФеТзмЙВЦпЪЎФъЕФЙІСІЮвЖМвбОДЋИјФуУЧСЫЁЃ |









