| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫЛљДЁдРэЁЂЭГМЦбЇЁЂБрГЬФмСІКЭЛњЦїбЇЯАЁЃ
БОЮФРДздЮЂаХЧиТЗЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
ЩйФъЃЌФуПЪЭћСІСПУДЃП
етВХЪЧеце§ЕФСІСПЃЌФъЧсШЫЃЁ
етЪЧSwami ChandrasekaranЫљЛцжЦЕФвЛеХЕиЭМЁЃУћзжНаMetroMap to Data
ScientistЃЈЪ§ОнПЦбЇМвжЎТЗЃЉЃЌБ№ГЦдѕУДЫРЖМВЛжЊЕРЕФЁЃ
Ъ§ОнПЦбЇМвЪЧНќФъЛ№БЌаЫЦ№ЕФжАЮЛЃЌЫќЪЧЪ§ОнЗжЮіЪІЕФКѓајНјНзЃЌШкКЯСЫЭГМЦЁЂвЕЮёЁЂБрГЬЁЂЛњЦїбЇЯАЁЂЪ§ОнЙЄГЬЕФИДКЯаЭжАЮЛЁЃ
ИУЕиЭМвЛЙВЪЎЬѕТЗЯпЃЌЗжБ№ЪЧЛљДЁдРэЁЂЭГМЦбЇЁЂБрГЬФмСІЁЂЛњЦїбЇЯАЁЂЮФБОЭкОђЃЏздШЛгябдДІРэЁЂЪ§ОнПЩЪгЛЏЁЂДѓЪ§ОнЁЂЪ§ОнЛёШЁЁЂЪ§ОнЧхРэЁЂГЃгУЙЄОпЁЃЬѕЬѕТЗЯпЖМВЛЪЧШЫзпЕФЁЃвђЮЊЭјЩЯжЛгагЂЮФАцЃЌЮвНЋЦфЗвыГЩжаЮФЃЌВЂЖдФкШнзївЛаЉНтЪЭКЭВЙГфЁЃ
ИУжИФЯжївЊЩцМАгВММФмЃЌЪ§ОнПЦбЇМвЕФСэЭтвЛИіКЫаФвЕЮёФмСІЃЌетРяУЛгаЩцМАЃЌЫќВЂВЛДњБэВЛживЊЁЃ
ЁЊЁЊЁЊЁЊЁЊЁЊ
FundamentalsдРэ
ЫуЪЧЖрбЇПЦЕФНЛВцЛљДЁЃЌЪєгкЪ§ОнПЦбЇМвЕФБиБИЫижЪЁЃ
Matrices & Linear Algebra
ОиеѓКЭЯпадДњЪ§
ОиеѓЃЈMatrixЃЉЪЧвЛИіАДееГЄЗНеѓСаХХСаЕФИДЪ§ЛђЪЕЪ§МЏКЯЁЃЩцМАЕНЕФЛњЦїбЇЯАгІгУгаSVDЁЂPCAЁЂзюаЁЖўГЫЗЈЁЂЙВщюЬнЖШЗЈЕШЁЃ
ЯпадДњЪ§ЪЧбаОПЯђСПЁЂЯђСППеМфЁЂЯпадБфЛЛЕШФкШнЕФЪ§бЇЗжжЇЁЃЯђСПЪЧЯпадДњЪ§зюЛљБОЕФФкШнЁЃжабЇЪБЃЌЪ§бЇЪщИцЫпЮвУЧЯђСПЪЧПеМфЃЈЭЈГЃЪЧЖўЮЌЕФзјБъЯЕЃЉжаЕФвЛИіМ§ЭЗЃЌЫќгаЗНЯђКЭЪ§жЕЁЃдкЪ§ОнПЦбЇМвблжаЃЌЯђСПЪЧгаађЕФЪ§зжСаБэЁЃЯпадДњЪ§ЪЧЮЇШЦЯђСПМгЗЈКЭГЫЗЈеЙПЊЕФЁЃ
ОиеѓКЭЯпадДњЪ§гаЪВУДЙиЯЕФиЃПЕБЯђСПНјааЯпадБфЛЛЪБЃЌетжжБфЛЛПЩвдЯыЯѓГЩМИКЮвтвхЩЯЕФЯпадМЗбЙКЭРГЖЃЌЖјОиеѓдђЪЧУшЪіетжжБфЛЛЕФаХЯЂЃЌгЩБфЛЛКѓЕФЛљЯђСПОіЖЈЁЃ
ОиеѓКЭЯпадДњЪ§ЪЧвЛЬхЕФЃЌОиеѓЪЧУшЪіЯпадДњЪ§ЕФВЮЪ§ЁЃЫќУЧЙЙГЩСЫЛњЦїбЇЯАЕФХгДѓЛљЪЏЁЃ
Hash Functions,Binary Tree,O(n)
ЙўЯЃКЏЪ§ЃЌЖўВцЪїЃЌЪБМфИДдгЖШ
ЙўЯЃКЏЪ§вВНаЩЂСаКЏЪ§ЃЌЫќФмНЋШЮвтЕФЪ§ОнзїЮЊЪфШыЃЌШЛКѓЪфГіЙЬЖЈГЄЖШЕФЪ§ОнЃЌетИіЪ§Он НаЙўЯЃжЕвВНаЩЂСажЕЃЌгУhБэЪОЃЌДЫЪБhОЭЪфШыЪ§ОнЕФжИЮЦЁЃ
ЙўЯЃКЏЪ§гавЛИіЛљБОЬиадЃЌШчЙћСНИіЙўЯЃжЕВЛЯрЭЌЃЌФЧУДЫќЕФЪфШывВПЯЖЈВЛЯрЭЌЁЃЗДЙ§РДЃЌШчЙћСНИіЙўЯЃжЕЪЧЯрЭЌЕФЃЌФЧУДЪфШыжЕПЩФмЯрЭЌЃЌвВПЩФмВЛЯрЭЌЃЌЙЪЮоЗЈЭЈЙ§ЙўЯЃжЕРДХаЖЯЪфШыЁЃ
ЙўЯЃКЏЪ§ГЃгУдкЪ§ОнНсЙЙЁЂУмТыбЇжаЁЃ
ЖўВцЪїЪЧМЦЫуЛњПЦбЇЕФвЛИіИХФюЃЌЫќЪЧвЛжжЪїаЮНсЙЙЁЃдкетИіНсЙЙжаЃЌУПИіНкЕузюЖргаСНИізгЪїЃЈзѓзгЪїКЭгвзгЪїЃЉЃЌзгЪїДЮађВЛФмЕпЕЙЁЃЖўВцЪїгжгаЖржжаЮЬЌЁЃ
ЖўВцЪїЪЧЪїетРрЪ§ОнНсЙЙЕФЕквЛжжЪїЃЌКѓајЛЙгаКьКкЪїЕШЃЌКмЖргябдЕФsetЃЌmapЖМЪЧгУЖўВцЪїаДЕФЁЃ
ЪБМфИДдгЖШЪЧБрГЬжаЕФвЛИіИХФюЃЌЫќУшЪіСЫжДааЫуЗЈашвЊЕФЪБМфЁЃВЛЭЌЫуЗЈгаВЛЭЌЕФЪБМфИДдгЖШЃЌР§ШчПьХХЁЂУАХнЕШЁЃ
МђБуЕФМЦЫуЗНЗЈЪЧПДгаМИИіforбЛЗЃЌвЛИіЪЧO(n)ЃЌСНИіЪЧO(n^2)ЃЌШ§ИіЪЧO(n^3)ЁЃЕБИДдгЖШЪЧn^3+n^2ЪБЃЌдђШЁзюДѓЕФСПМЖn^3МДПЩЁЃ
гыжЎЯрЖдгІЕФЛЙгаПеМфИДдгЖШЃЌЫќДњБэЕФЪЧЫуЗЈеМгУЕФФкДцПеМфЁЃЫуЗЈЭЈГЃвЊдкЪБМфКЭФкДцжаШЁЕУвЛИіЦНКтЃЌМШФкДцЛЛЪБМфЃЌЛђепЪБМфЛЛФкДцЁЃ
Relational Algebra
ЙиЯЕДњЪ§
ЫќЪЧвЛжжГщЯѓЕФВщбЏгябдЁЃЛљБОЕФДњЪ§дЫЫугабЁдёЁЂЭЖгАЁЂМЏКЯВЂЁЂМЏКЯВюЁЂЕбПЈЖћЛ§КЭИќУћЁЃ
ЙиЯЕаЭЪ§ОнПтОЭЪЧвдЙиЯЕДњЪ§ЮЊЛљДЁЁЃдкSQLгябджаЖМФмевЕНЙиЯЕДњЪ§ЯргІЕФМЦЫуЁЃ
InnerЁЂOuterЁЂCrossЁЂTheta Join
ФкСЌНгЁЂЭтСЌНгЁЂНЛВцСЌНгЁЂІШСЌНг
етЪЧЙиЯЕФЃаЭжаЕФИХФюЃЌвВЪЧЪ§ОнПтЕФВщбЏЛљДЁЁЃ
ФкСЌНгЃЌжЛСЌНгЦЅХфЕФааЃЌгжНаЕШжЕСЌНгЁЃ
ЭтСЌНгЃЌСЌНгзѓгвСНБэЫљгаааЃЌВЛТлЫќУЧЪЧЗёЦЅХфЁЃ
НЛВцСЌНгЪЧЖдСНИіЪ§ОнМЏЫљгаааНјааЕбПЈЖћЛ§дЫЫуЃЌБШШчвЛЗљЦЫПЫХЦЃЌЦфжагаAМЏЃЌЪЧ13ИіХЦЕФЕуЪ§МЏКЯЃЌМЏКЯBдђЪЧ4ИіЛЈЩЋЕФМЏКЯЃЌМЏКЯAКЭМЏКЯBЕФНЛВцСДНгОЭЪЧ4*13ЙВ52ИіЁЃ
ІШСЌНгЪЙгУwhereзгОфв§ШыСЌНгЬѕМўЃЌІШСЌНгПЩвдЪгзїНЛВцСЌНгЕФвЛИіЬиЪтЧщПіЁЃwhere ПЩвдЪЧЕШжЕЃЌвВПЩвдЪЧЗЧЕШжЕШчДѓгкаЁгкЁЃ
ВЛЭЌЪ§ОнПтЕФjoinЗНЪНЛсгаВювьЁЃ
CAP Theorem
CAPЖЈРэ
жИЕФЪЧдквЛИіЗжВМЪНЯЕЭГжаЃЌ ConsistencyЃЈвЛжТадЃЉЁЂ AvailabilityЃЈПЩгУадЃЉЁЂPartition
toleranceЃЈЗжЧјШнДэадЃЉЃЌШ§епВЛПЩЕУМцЁЃ
вЛжТадЃЈCЃЉЃКдкЗжВМЪНЯЕЭГжаЕФЫљгаЪ§ОнБИЗнЃЌдкЭЌвЛЪБПЬЪЧЗёЭЌбљЕФжЕЁЃЃЈЕШЭЌгкЫљгаНкЕуЗУЮЪЭЌвЛЗнзюаТЕФЪ§ОнИББОЃЉ
ПЩгУадЃЈAЃЉЃКдкМЏШКжавЛВПЗжНкЕуЙЪеЯКѓЃЌМЏШКећЬхЪЧЗёЛЙФмЯьгІПЭЛЇЖЫЕФЖСаДЧыЧѓЁЃЃЈЖдЪ§ОнИќаТОпБИИпПЩгУадЃЉ
ЗжЧјШнДэадЃЈPЃЉЃКвдЪЕМЪаЇЙћЖјбдЃЌЗжЧјЯрЕБгкЖдЭЈаХЕФЪБЯовЊЧѓЁЃЯЕЭГШчЙћВЛФмдкЪБЯоФкДяГЩЪ§ОнвЛжТадЃЌОЭвтЮЖзХЗЂЩњСЫЗжЧјЕФЧщПіЃЌБиаыОЭЕБЧАВйзїдкCКЭAжЎМфзіГібЁдёЁЃ
Ъ§ОнЯЕЭГЩшМЦБиаыдкШ§ИіадФмЗНБузіГіШЁЩсЃЌВЛЭЌЕФЪ§ОнПтЃЌCAPЧуЯђадВЛЭЌЁЃ
tabular data
СаБэЪ§Он
МДЖўЮЌЕФБэИёЪ§ОнЃЌЙиЯЕаЭЪ§ОнПтЕФЛљДЁЁЃ
DataFrames & Series
PandasЪ§ОнНсЙЙ
SeriesЪЧвЛИівЛЮЌЪ§ОнЖдЯѓЃЌгЩвЛзщNumPyЕФarrayКЭвЛзщгыжЎЯрЙиЕФЫїв§зщГЩЁЃPythonзжЕфКЭЪ§зщЖМФмзЊЛЛГЩЪ§зщЁЃSeriesвд0ЮЊПЊЪМЃЌВНГЄЮЊ1зїЮЊЫїв§ЁЃ
| x = Series([1,2,3,4,5])
x
0 1
1 2
2 3
3 4
4 5 |
DataFramesЪЧвЛИіБэИёаЭЕФЪ§ОнЃЌЪЧSeriesЕФЖрЮЌБэЯжЁЃDataFramesМДгаааЫїв§вВгаСаЫїв§ЃЌПЩвдПДзїSeriesзщГЩЕФзжЕфЁЃ
Sharding
ЗжЦЌ
ЗжЦЌВЛЪЧвЛжжЬиЖЈЕФЙІФмЛђепЙЄОпЃЌЖјЪЧММЪѕЯИНкЩЯЕФГщЯѓДІРэЃЌЪЧЫЎЦНЭиеЙЕФНтОіЗНЗЈЁЃвЛАуЪ§ОнПтгіЕНадФмЦПОБЃЌВЩгУЕФЪЧScale
UpЃЌМДЯђЩЯдіМгадФмЕФЗНЗЈЃЌЕЋЕЅИіЛњЦїзмгаЩЯЯоЃЌгкЪЧЫЎЦНЭиеЙгІдЫЖјЩњЁЃ
ЗжЦЌЪЧДгЗжЧј(Partition)ЕФЫМЯыЖјРДЃЌЗжЧјЭЈГЃеыЖдБэКЭЫїв§ЃЌЖјЗжЦЌПЩвдПчгђЪ§ОнПтКЭЮяРэМйЦкЁЃБШШчЮвУЧНЋжаЙњЛЎЗжФЯББЗНЃЌФЯЗНгУЛЇЗХдквЛИіЗўЮёЦїЩЯЃЌББЗНгУЛЇЗХдкСэвЛИіЗўЮёЦїЩЯЁЃ
ЪЕМЪаЮЪНЩЯЃЌУПвЛИіЗжЦЌЖМАќКЌЪ§ОнПтЕФвЛВПЗжЃЌПЩвдЪЧЖрИіБэЕФФкШнвВПЩвдЪЧЖрИіЪЕР§ЕФФкШнЁЃЕБашвЊВщбЏЪБЃЌдђШЅашвЊВщбЏФкШнЫљдкЕФЗжЦЌЗўЮёЦїЩЯВщбЏЁЃЫќЪЧМЏШКЃЌЕЋВЛЭЌгкHadoopЕФMRЁЃ
ШчЙћФмЙЛБЃжЄЪ§ОнСПКмФбГЌЙ§ЯжгаЪ§ОнПтЗўЮёЦїЕФЮяРэГадиСПЃЌФЧУДжЛашРћгУMySQL5.1ЬсЙЉЕФЗжЧј(Partition)ЙІФмРДИФЩЦЪ§ОнПтадФмМДПЩЃЛЗёдђЃЌЛЙЪЧПМТЧгІгУShardingРэФюЁЃСэЭтвЛИіСїДЋЩѕЙуЕФЙлЕуЪЧЃКЮвУЧЕФЪ§ОнвВаэУЛгаФЧУДДѓЃЌHadoopВЛЪЧБиашЕФЃЌгУshardingМДПЩЁЃ
OLAP
СЊЛњЗжЮіДІРэЃЈOnline Analytical ProcessingЃЉ
ЫќЪЧЪ§ОнВжПтЯЕЭГжївЊЕФгІгУЃЌжївЊгУгкИДдгЕФЗжЮіВйзїЁЃ
еыЖдЪ§ОнЗжЮіШЫдБЃЌЪ§ОнЪЧЖрЮЌЪ§ОнЁЃВщбЏОљЪЧЩцМАЕНЖрБэЕФИДдгЙиСЊВщбЏЃЌЮЊСЫжЇГжЪ§ОнвЕЮёЯЕЭГЕФДюНЈЃЌOLAPПЩвдЯыЯѓГЩвЛИіЖрЮЌЖШЕФСЂЗНЬхЃЌвдЮЌЖШЃЈDimensionЃЉКЭЖШСПЃЈMeasureЃЉЮЊЛљБОИХФюЁЃЮвУЧгУЕНЕФЖрЮЌЗжЮіОЭЪЧOLAPЕФОпЯѓЛЏгІгУЁЃ
OLAPИќЦЋЯђгкДЋЭГЦѓвЕЃЌЛЅСЊЭјЦѓвЕЛсСщЛюБфЖЏвЛаЉЁЃСэЭтЛЙгавЛИіOLTPЕФИХФюЁЃ
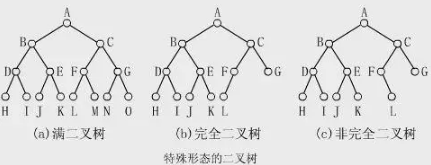
Multidimensional Data Model
ЖрЮЌЪ§ОнФЃаЭЁЃ
ЫќЪЧOLAPДІРэЩњГЩКѓЕФЪ§ОнСЂЗНЬхЁЃЫќЬсЙЉСЫзюжБЙлЙлВьЪ§ОнЕФЗНЗЈЁЃ
ЩцМАзъШЁЃЌЩЯОэЃЌЧаЦЌЃЌЧаПщЃЌа§зЊЕШВйзїЃЌОЭЪЧАбЩЯУцЕФСЂЗНЬхБфБфБфРВЁЃ
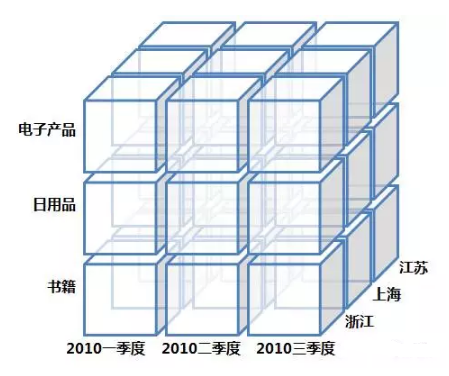
ETL
ETLЪЧГщШЁЃЈextractЃЉЁЂзЊЛЛЃЈtransformЃЉЁЂМгдиЃЈloadЃЉЕФЙ§ГЬЁЃГЃгУдкЪ§ОнВжПтЁЃ
ећИіСїГЬЪЧДгЪ§ОндДГщШЁЪ§ОнЃЌНсЙћЪ§ОнЧхЯДКЭзЊЛЛЃЌзюжеНЋЪ§ОнвдЬиЖЈФЃаЭМгдиЕНЪ§ОнВжПтжаШЅЁЃ
ETLЪЧвЛИіЙХРЯЕФИХФюЃЌдквдЧАSQLЪ§ОнВжПтЪБДњКЭOLAPАщЫцЖјЩњЃЌдкЯждкШеаТдТвьЕФММЪѕЩњЬЌШІЃЌЛсж№ВНбнНјЕНHadoopЯрЙиЕФММЪѕСЫЁЃ
Reporting vs BI vs Analytics
БЈБэгыЩЬвЕжЧФмгыЗжЮі
етЪЧBIЕФШ§ИізщГЩВПЗжЁЃReportingЪЧЪ§ОнБЈБэЁЃРћгУБэИёКЭЭМБэГЪЯжЪ§ОнЁЃБЈБэЭЈГЃЪЧЖЏЬЌЖрбљЕФЁЃЪ§ИіБЈБэЕФМЏКЯЭГГЦЮЊDashboardЁЃ
BIЪЧЩЬвЕжЧФмЃЌЪЧЖдЦѓвЕЕФЪ§ОнНјаагааЇећКЯЃЌЭЈЙ§Ъ§ОнБЈБэПьЫйзїГіОіВпЁЃ
AnalyticsЪЧЪ§ОнЗжЮіЃЌЛљгкЪ§ОнБЈБэзїГіЗжЮіЁЃАќРЈЧїЪЦЕФВЈЖЏЃЌЮЌЖШЕФЖдБШЕШЁЃ
JSON & XML
JSONЪЧвЛжжЧсСПМЖЕФЪ§ОнНЛЛЛИёЪНЃЌвзгкдФЖСКЭБраДЃЌвВвзгкЛњЦїНтЮіКЭЩњГЩЁЃ
JSONЕФгяЗЈЙцдђЪЧЃК
{ }БЃДцЖдЯѓЃЛ
[ ]БЃДцЪ§зщЃЛ
Ъ§ОнгЩЖККХЗжИєЃЛ
Ъ§ОндкМќжЕЖджаЃЛ
ЯТУцЗЖР§ОЭЪЧвЛзщJSONжЕ
{
"firstName":
"John",
"lastName": "Smith",
"age": 25,
"address":
{
"streetAddress": "21 2nd
Street",
"city": "New
York",
"state": "NY",
"postalCode": "10021"
}
}
|
XMLЪЧПЩЭиеЙБъМЧгябдЃЌБЛЩшМЦгУРДДЋЪфКЭДцДЂЪ§ОнЃЌгыжЎЖдгІЕФHTMLдђЪЧЯдЪОЪ§ОнЁЃXMLКЭHTMLЗўЮёгкВЛЭЌФПЕФЃЌXMLЪЧВЛзїЮЊЕФЁЃ
<note>
<to>George</to>
<from>John</from>
<heading>Reminder</heading>
<body>Don't forget the meeting!</body>
</note>
|
ЩЯУцЕФЗЖР§ЃЌДПДтОЭЪЧгУРДДЋЪфЕФвЛЖЮаХЯЂЃЌУЛгаШЮКЮвтвхЁЃ
NoSQL
ЗКжИЗЧЙиЯЕаЭЕФЪ§ОнПтЃЌвтЮЊNot Only SQLЁЃ
NoSQLЪЧЫцзХДѓЪ§ОнЪБДњЗЂеЙЦ№РДЕФЃЌДЋЭГЕФЙиЯЕЪ§ОнПтдкИпВЂЗЂДѓЙцФЃЖрЪ§ОнРраЭЕФЛЗОГЯТСІВЛДгаФЃЌЖјNoSQLОЭЪЧЮЊСЫНтОіетаЉЮЪЬтЖјВњЩњЕФЁЃ
NoSQLжївЊЗжЮЊЫФДѓРрЃК
МќжЕKeyValueЪ§ОнПт
етРрЪ§ОнПтЛсЪЙгУЙўЯЃБэЃЌЙўЯЃБэжагавЛИіЬиЖЈЕФМќжИЯђвЛИіЬиЖЈЕФжЕЃЌKeyValueЕФЬиЕуЪЧШЅжааФЛЏЃЌВЛЩцМАвЕЮёЙиЯЕЁЃДњБэRedisЁЃ
СаЪ§ОнПт
етРрЪ§ОнПтгУгкЗжВМЪНКЃСПДцДЂЃЌКЭKeyValueЕФЧјБ№дкгкетРяЕФKeyжИЯђЕФЪЧСаЁЃКсЯђЭиеЙадКУЃЌЪЪКЯДѓЪ§ОнСПИпIOЁЃДњБэHBaseЃЌCassandra
ЮФЕЕаЭЪ§ОнПт
ЪєгкKeyValueЪ§ОнПтЕФЩ§МЖАцЃЌдЪаэЧЖЬзМќжЕЁЃЮФЕЕЪЧДІРэаХЯЂЕФЛљБОЕЅЮЛЃЌвЛИіЮФЕЕЕШгквЛИіЙиЯЕЪ§ОнПтЕФвЛЬѕМЧТМЁЃ
вђЮЊЮФЕЕЕФздгЩадЃЌЮФЕЕаЭЪ§ОнПтЪЪКЯИДдгЁЂЫЩЩЂЁЂЮоНсЙЙЛђАыНсЙЙЛЏЕФЪ§ОнФЃаЭЃЌКЭJSONРрЫЦЃЌНазіBSONЃЈMongoDBЕФДцДЂИёЪНЃЉЁЃДњБэMongoDB
ЭМаЮЪ§ОнПт
ЛљгкЭМТлЫуЗЈЕФЪ§ОнПтЃЌНЋЪ§ОнМЏвдЭМаЮдЊЫиЃЈЕуЁЂЯпЁЂУцЃЉНЈСЂЦ№РДЁЃетжжЪ§ОнПтГЃгІгУдкЩчНЛЭјТчЙиЯЕСДЃЌNЖШЙиЯЕЕШЁЃДњБэNeo4j
Regex
е§дђБэДяЪНЃЈRegular ExpressionЃЉ
е§дђБэЭЈГЃБЛгУРДМьЫїЁЂЬцЛЛФЧаЉЗћКЯФГИіФЃЪН(Йцдђ)ЕФзжЗћДЎЁЃЭЈЙ§ЬиЖЈзжЗћЕФзщКЯЃЌЖдзжЗћДЎНјааТпМЙ§ТЫЁЃР§ШчзЂВсеЫКХЪБМьВщЖдЗНгЪМўИёЪНЖдВЛЖдАЁЃЌЪжЛњКХИёЪНЖдВЛЖдАЁЁЃ
бЇЦ№РДППМЧЃЌМЧСЫвВЛсЭќЃЌУПДЮгУЕУВщЃЌВщСЫЛЙЕУМьбщЁЃЭјЩЯМЧвфПкОївЛЖбЭМБэЃЌЯрЙиЭјеОвВВЛЩйЃЌШЪепМћШЪСЫЁЃ
Vendor Landscape
ВЛЖЎЃЌЙЉгІЩЬЗчОАЃП
Env Setup
ЛЗОГАВзА
ЯыСЫАыЬьЃЌEnvгІИУЪЧЛЗОГАВзАЕФвтЫМЃЌIDEАЁЃЌGUIАЁЕШЕШШЋВПАВзАЩЯШЅЃЌдйЕїИїжжТЗОЖЩЖЕФЁЃеыЖдЪ§ОнПЦбЇМвЃЌAnaconda
+ RstudioгУЕФБШНЯЖрЁЃ
ЁЊЁЊЁЊЁЊЁЊЁЊ
Statistics ЭГМЦ
ЭГМЦЪЧЪ§ОнПЦбЇМвЕФКЫаФФмСІжЎвЛЃЌЛњЦїбЇЯАОЭЪЧЛљгкЭГМЦбЇдРэЕФЃЌЮвВЛЫуОЋЭЈетвЛПщЃЌаэЖрФкШнЖМЪЧЭјТчНЬПЦЪщЪНЕФгябдЁЃЖМеЦЮеКѓдйжиаДвЛБщЁЃ
Pick a Dataset(UCI Repo)
евЪ§ОнЃЈUCIЪ§ОнМЏЃЉ
UCIЪ§ОнПтЪЧМгжнДѓбЇХЗЮФЗжаЃ(University of CaliforniaIrvine)ЬсГіЕФгУгкЛњЦїбЇЯАЕФЪ§ОнПтЃЌетИіЪ§ОнПтФПЧАЙВга335ИіЪ§ОнМЏЃЌЦфЪ§ФПЛЙдкВЛЖЯдіМгЃЌПЩвдФУРДЭцЛњЦїбЇЯАЁЃЭјЩЯЫбЕФЕНЁЃСэЭтЕФЪ§ОнРДдДЪЧKaggleОКШќЕШЁЃ
зюОЕфЕФЪ§ОнФЊЙ§гкIrisСЫЁЃ
Descriptive StatisticsЃЈmean, median, range, SD, VarЃЉ
УшЪіадЭГМЦЃЈОљжЕЃЌжаЮЛЪ§ЃЌМЋВюЃЌБъзМВюЃЌЗНВюЃЉ
ОљжЕвВНаЦНОљЪ§ЃЌЪЧЭГМЦбЇжаЕФИХФюЁЃаЁбЇбЇЯАЕФЫуЪ§ЦНОљЪ§ЪЧЦфжаЕФвЛжжОљжЕЃЌГ§ДЫвдЭтЛЙгажкЪ§КЭжаЮЛЪ§ЁЃ
жаЮЛЪ§ПЩвдБмУтМЋЖЫжЕЃЌдкЪ§ОнГЪЯжЦЋЬЌЕФЧщПіЯТЛсЪЙгУЁЃ
МЋВюОЭЪЧзюДѓжЕМѕзюаЁжЕЁЃ
БъзМВюЃЌвВНазіОљЗНВюЁЃЯжЪЕвтвхЪЧБэЪіИїЪ§ОнЦЋРыецЪЕжЕЕФЧщПіЃЌЗДгГЕФЪЧвЛзщЪ§ОнЕФРыЩЂГЬЖШЁЃЦНОљЪ§ЯрЭЌЕФСНзщЪ§ОнЃЌШч[1,9]КЭ[4,6]ЃЌЦНОљЪ§ЯрЭЌЃЌБъзМВюВЛвЛбљЃЌЧАепЕФРыЩЂГЬЖШИќДѓЁЃ
ЗНВюЃЌЪЧБъзМВюЕФЦНЗНЁЃЗНВюКЭБъзМВюЕФСПИйЪЧвЛжТЕФЁЃдкЪЕМЪЪЙгУЙ§ГЬжаЃЌБъзМВюашвЊБШЗНВюЖрвЛВНПЊЦНЗНЕФдЫЫуЃЌЕЋЫќдкУшЪіЯжЪЕвтвхЩЯИќЬљЧаЃЌИїгагХСгЁЃ
Exploratory Data Analysis
ЬНЫїадЪ§ОнЗжЮі
ЛёЕУвЛзщЪ§ОнМЏЪБЃЌЭЈГЃЗжЮіЪІашвЊеЦЮеЪ§ОнЕФДѓЬхЧщПіЃЌДЫЪБОЭвЊгУЕНЬНЫїадЪ§ОнЗжЮіЁЃ
жївЊЪЧСНРрЃК
ЭМаЮЗЈЃЌЭЈЙ§жБЗНЭМЁЂЯфЯпЭМЁЂОЅвЖЭМЁЂЩЂЕуЭМПьЫйЛузмУшЪіЪ§ОнЁЃ
Ъ§жЕЗЈЃКЙлВьЪ§ОнЕФЗжВМаЮЬЌЃЌАќРЈжаЮЛЪ§ЁЂМЋжЕЁЂОљжЕЕШЃЌЙлВьЖрБфСПжЎМфЕФЙиЯЕЁЃ
ЬНЫїадЪ§ОнЗжЮіВЛЛсЩцМАЕНИДдгдЫЫуЃЌЖјЪЧЭЈЙ§МђЕЅЕФЗНЪНЖдЪ§ОнгавЛИіДѓИХЕФСЫНтЃЌШЛКѓВХШЅЩюШыЭкОђЪ§ОнМлжЕЃЌдкPythonКЭRжаЃЌЖМгаЯрЙиЕФsummaryКЏЪ§ЁЃ
Histograms
жБЗНЭМ
ЫќгжГЦжЪСПЗжВМЭМЃЌЪЧвЛжжБэЪОЪ§ОнЗжВМЕФЭГМЦБЈИцЭМЁЃ
НќЫЦЭМБэжаЕФЬѕаЮЭМЃЌВЛЙ§жБЗНЭМЕФЬѕаЮЪЧСЌајХХСаЃЌУЛгаМфИєЁЂвђЮЊЗжзщЪ§ОнОпгаСЌајадЃЌВЛФмЗХПЊЁЃ
е§ГЃЕФжБЗНЭМЪЧжаМфИпЁЂСНБпЕЭЁЂзѓгвНќЫЦЖдГЦЁЃЖјвьГЃаЭЕФжБЗНЭМжжРрЙ§ЖрЃЌВЛЭЌЕФвьГЃДњБэВЛЭЌЕФПЩФмЧщПіЁЃ
Percentiles & Outliers
АйЗжЮЛЪ§КЭМЋжЕ
ЫќУЧЪЧУшЪіадЭГМЦЕФдЊЫиЁЃ
АйЗжЮЛЪ§жИНЋвЛзщЪ§ОнДгаЁЕНДѓХХађЃЌВЂМЦЫуЯргіЕФРлЛ§АйЗжжЕЃЌФГвЛАйЗжЮЛЫљЖдгІЪ§ОнЕФжЕОЭГЦЮЊетвЛАйЗжЮЛЕФАйЗжЮЛЪ§ЁЃБШШч1ЁЋ100ЕФЪ§зщжаЃЌ25ДњБэ25ЗжЮЛЃЌ60ДњБэ60ЗжЮЛЁЃ
ЮвУЧГЃНЋАйЗжЮЛЪ§ОљдШЫФЕШЗжЃКЕк25АйЗжЮЛЪ§ЃЌНазіЕквЛЫФЗжЮЛЪ§ЃЛЕк50АйЗжЮЛЪ§ЃЌГЦЕкЖўЫФЗжЮЛЪ§ЃЌвВНажаЮЛЪ§ЃЛЕк75АйЗжЮЛЪ§ЃЌНазіЕкШ§ЫФЗжЮЛЪ§ЁЃЭЈЙ§ЫФЗжЮЛЪ§ФмЙЛМђЕЅПьЫйЕФКтСПвЛзщЪ§ОнЕФЗжВМЁЃЫќУЧЙЙГЩСЫЯфЯпЭМЕФжИБъЁЃ
МЋжЕЪЧзюДѓжЕКЭзюаЁжЕЃЌвВЪЧЕквЛАйЗжЮЛЪ§КЭЕквЛАйАйЗжЮЛЪ§ЁЃ
АйЗжЮЛЪ§КЭМЋжЕПЩвдгУРДУшЛцЯфЯпЭМЁЃ
Probability Theory
ИХТЪТлЃЌЭГМЦбЇЕФКЫаФжЎвЛЃЌжївЊбаОПЫцЛњЯжЯѓЗЂЩњЕФПЩФмадЁЃ
Bayes Theorem
БДвЖЫЙЖЈРэ
ЫќЙигкЫцЛњЪТМўAКЭBЕФЬѕМўИХТЪЕФЖЈРэЁЃ
ЯжЪЕЪРНчгаКмЖрЭЈЙ§ФГаЉаХЯЂЭЦЖЯГіЦфЫћаХЯЂЕФЭЦРэКЭОіВпЃЌБШШчПДЕНЬьАЕСЫЁЂђпђбЕЭЗЩСЫЃЌФЧУДОЭБэЪОгаПЩФмЯТгъЁЃетзщЙиЯЕБЛГЦЮЊЬѕМўИХТЪЃКгУP(A|B)БэЪОдкBЗЂЩњЕФЧщПіЯТAЗЂЩњЕФПЩФмадЁЃ
БДвЖЫЙЙЋЪНЃКP(B|A) = P(A|B)*P(B) / P(A)
ЯжЪЕЩњЛюжазюОЕфЕФР§згОЭЪЧМВВЁМьВтЃЌШчЙћФГжжМВВЁЕФЗЂВЁТЪЮЊЧЇЗжжЎвЛЁЃЯждкгавЛжжЪджНЃЌЫќдкЛМепЕУВЁЕФЧщПіЯТЃЌга99%ЕФзМШЗХаЖЯЛМепЕУВЁЃЌдкЛМепУЛгаЕУВЁЕФЧщПіЯТЃЌга5%ЕФПЩФмЮѓХаЛМепЕУВЁЁЃЯждкЪджНЫЕвЛИіЛМепЕУСЫВЁЃЌФЧУДЛМепецЕФЕУВЁЕФИХТЪЪЧЖрЩйЃП
ДгЮвУЧЕФжБОѕПДЃЌЪЧВЛЪЧЛМепЕУВЁЕФИХТЪКмДѓЃЌга80%ЃП90%ЃПЪЕМЪЩЯЃЌЛМепЕУВЁЕФИХТЪжЛга1.9%ЁЃЙиМќдкФФРяЃПвЛИіЪЧМВВЁЕФЗЂВЁТЪЙ§ЕЭЃЌвЛИіЪЧ5%ЕФЮѓХаТЪЬЋИпЃЌЕМжТДѓЖрЪ§УЛгаЕУВЁЕФШЫБЛЮѓХаЁЃетОЭЪЧБДвЖЫЙЖЈРэЕФзїгУЃЌгУЪ§бЇЃЌЖјВЛЪЧжБОѕзіХаЖЯЁЃ
зюОЕфЕФгІгУФЊЙ§гкРЌЛјгЪМўЕФЙ§ТЫЁЃ
Random Variables
ЫцЛњБфСП
БэЪОЫцЛњЪдбщИїжжНсЙћЕФЪЕМЪжЕЁЃБШШчЬьЦјЯТгъЕФНЕЫЎСПЃЌБШШчФГвЛЪБМфЖЮЩЬГЧЕФПЭСїСПЁЃ
ЫцЛњБфСПЪЧЙцТЩЕФЗДгІЃЌШгвЛУЖгВБвЃЌМШгаПЩФме§УцЁЂвВгаПЩФмЗДУцЃЌСНепЕФИХТЪЖМЪЧ50%ЁЃШгїЛзгЃЌНсЙћЪЧ1ЁЋ6жЎМфЕФШЮКЮвЛИіЃЌИХТЪвВЪЧСљЗжжЎвЛЁЃЫфШЛзівЛДЮЪдбщЃЌНсЙћПЯЖЈЪЧВЛШЗЖЈадЕФЃЌЕЋЪЧИХТЪЪЧвЛЖЈЕФЁЃЫцЛњБфСПЪЧИХТЪЕФЛљЪЏЁЃ
Cumul Dist Fn(CDF)
РлМЦЗжВМКЏЪ§ЃЈCumulative Distribution FunctionЃЉ
ЫќЪЧИХТЪУмЖШКЏЪ§ЕФЛ§ЗжЃЌФмЙЛЭъећУшЪівЛИіЪЕЪ§ЫцЛњБфСПXЕФИХТЪЗжВМЁЃжБЙлПДЃЌРлЛ§ЗжВМКЏЪ§ЪЧИХТЪУмЖШКЏЪ§ЧњЯпЯТЕФУцЛ§ЁЃ
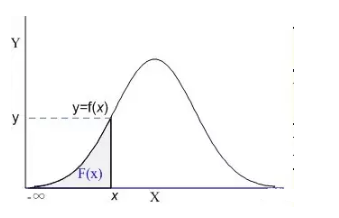
ЩЯЭМвѕгАВПЗжОЭЪЧвЛИіБъзМЕФРлЛ§ЗжВМКЏЪ§F(x)ЃЌИјЖЈШЮвтжЕxЃЌМЦЫуаЁгкxЕФИХТЪЮЊЖрДѓЁЃЪЕМЪЙЄзїжаВЛЛсЩцМАCDFЕФМЦЫуЃЌЖМЪЧМЦЫуЛњИКд№ЕФЁЃМЧЕУдкЮвДѓбЇПМЪдЃЌвВЪЧзЈУХВщБэЕФЁЃ
ЯжЪЕЩњЛюжаЃЌЮвУЧУшЪіЕФКмЖрИХТЪЖМЪЧРлЛ§ЗжВМКЏЪ§ЃЌЮвУЧЫЕПМЪд90ЗжвдЩЯЕФИХТЪга95%ЃЌЪЕМЪЪЧ90ЗжЁЋ100ЗжЫљгаЕФИХТЪЧѓКЭЮЊ95%ЁЃ
Continuos Distributions(Normal, Poisson, Gaussian)
СЌајЗжВМЃЈе§ЬЌЁЂВДЫЩЁЂИпЫЙЃЉ
ЗжВМгаСНжжЃЌРыЩЂЗжВМКЭСЌајЗжВМЁЃСЌајЗжВМЪЧЫцЛњБфСПдкЧјМфФкФмЙЛШЁШЮвтЪ§жЕЁЃ
е§ЬЌЗжВМЪЧЭГМЦбЇжазюживЊЕФЗжВМжЎвЛЃЌЫќЕФаЮзДГЪжгаЭЃЌСНЭЗЕЭЃЌжаМфИпЃЌзѓгвЖдГЦЁЃ
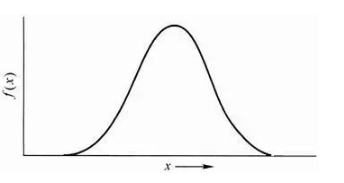
е§ЬЌЗжВМгаСНИіВЮЪ§ЃЌЦкЭћІЬКЭБъзМВюІвЃКІЬЗДгІСЫе§ЬЌЗжВМЕФМЏжаЧїЪЦЮЛжУЃЌІвЗДгІСЫРыЩЂГЬЖШЃЌІвдНДѓЃЌЧњЯпдНБтЦНЃЌІвдНаЁЃЌЧњЯпдНеИпЁЃ
здШЛНьжаДѓСПЕФЯжЯѓЖМАДе§ЬЌаЮЪНЗжВМЃЌБъзМе§ЬЌЗжВМдђЪЧе§ЬЌЗжВМЕФвЛжжЃЌЦНОљЪ§ЮЊ0ЃЌБъзМВюЮЊ1ЁЃгІгУжаЃЌЖМЛсНЋе§ЬЌЗжВМЯШзЊЛЛГЩБъзМе§ЬЌЗжВМНјааМЦЫуЁЃКмЖрЭГМЦбЇЗНЗЈЃЌЖМЛсвЊЧѓЪ§ОнЗћКЯе§ЬЌЗжВМВХФмМЦЫуЁЃ
ВДЫЩЗжВМЪЧРыЩЂИХТЪЗжВМЁЃЪЪКЯУшЪіФГИіЫцЛњЪТМўдкЕЅЮЛЪБМфЃЏОрРыЃЏУцЛ§ЕШГіЯжЕФДЮЪ§ЁЃЕБnГіЯжЕФДЮЪ§зуЙЛЖрЪБЃЌВДЫЩЗжВМПЩвдПДзїе§ЬЌЗжВМЁЃ
ИпЫЙЗжВМОЭЪЧе§ЬЌЗжВМЁЃ
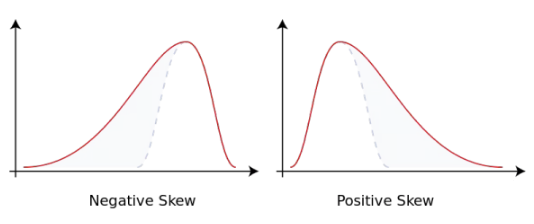
Skewness
ЦЋЖШ
ЫќЪЧЪ§ОнЗжВМЧуаБЗНЯђКЭГЬЖШЕФЖШСПЃЌЕБЪ§ОнЗЧЖдГЦЪБЃЌашвЊгУЕНЦЋЖШЁЃ
е§ЬЌЗжВМЕФЦЋЖШЮЊ0ЃЌЕБЦЋЖШЮЊИКЪБЃЌЪ§ОнЗжВМЭљзѓЦЋРыЃЌНазіИКЦЋРыЃЌвВГЦзѓЦЋЬЌЁЃЗДжЎНагвЦЋЬЌЁЃ
ANOVA
ЗНВюЗжЮі
гУгкЖрИіБфСПЕФЯджјадМьбщЁЃЛљБОЫМЯыЪЧЃКЭЈЙ§ЗжЮібаОПВЛЭЌРДдДЕФБфвьЖдзмБфвьЕФЙБЯзДѓаЁЃЌДгЖјШЗЖЈПЩПивђЫиЖдбаОПНсЙћгАЯьСІЕФДѓаЁЁЃ
ЗНВюЗжЮіЪєгкЛиЙщЗжЮіЕФЬиР§ЁЃЗНВюЗжЮігУгкМьбщЫљгаБфСПЕФЯджјадЃЌЖјЛиЙщЗжЮіЭЈГЃеыЖдЕЅИіБфСПЕФЁЃ
Prob Den Fn(PDF)
ИХТЪУмЖШКЏЪ§
PDFЪЧгУРДУшЪіСЌајаЭЫцЛњБфСПЕФЪфГіжЕЁЃИХТЪУмЖШКЏЪ§гІИУКЭЗжВМКЏЪ§вЛЦ№ПД:
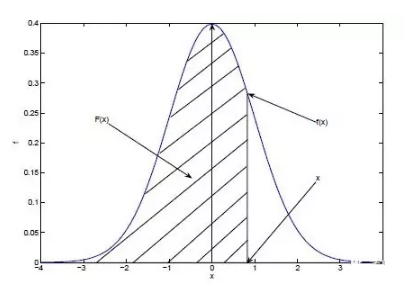
РЖЩЋЧњЯпЪЧИХТЪУмЖШКЏЪ§ЃЌвѕгАВПЗжЪЧРлЛ§ЗжВМКЏЪ§ЁЃЮвУЧгУИХТЪУмЖШКЏЪ§дкФГвЛЧјМфЩЯЕФЛ§ЗжРДПЬЛЫцЛњБфСПТфдкетИіЧјМфжаЕФИХТЪЁЃИХТЪЕШгкЧјМфГЫИХТЪУмЖШЃЌРлЛ§ЗжВМЕШгкЫљгаИХТЪЕФРлМгЁЃ
ИХТЪУмЖШКЏЪ§ЃКf(x) = P(X=x)
РлЛ§ЗжВМКЏЪ§ЃКF(x) = P(X<=x)
ИХТЪУмЖШКЏЪ§ЪЧРлЛ§ЗжВМКЏЪ§ЕФЕМЪ§ЃЌЯжгаЗжВМКЏЪ§ЃЌВХгаУмЖШКЏЪ§ЁЃРлЛ§ЗжВМКЏЪ§МДПЩвдРыЩЂвВПЩвдСЌајЃЌЖјУмЖШКЏЪ§ЪЧгУдкСЌајЗжВМжаЕФЁЃ
Central Limit THeorem
жааФМЋЯоЖЈРэ
ЫќЪЧИХТЪТлжазюживЊЕФвЛРрЖЈРэЁЃ
здШЛНьжаКмЖрЫцЛњБфСПЖМЗўДге§ЬЌЗжВМЃЌжааФМЋЯоЖЈРэОЭЪЧРэНтКЭНтЪЭетаЉЫцЛњБфСПЕФЁЃЮвУЧгавЛИізмЬхбљБОЃЌДгжаШЁбљБОСПЮЊnЕФбљБОЃЌетИібљБОгавЛИіОљжЕЃЌЕБЮвУЧжиИДШЁСЫmДЮЪБЃЌЖдгІгаmИіОљжЕЃЌШчЙћЮвУЧАбЪ§ОнЗжВМЛГіРДЃЌЕУЕНЕФНсЙћНќЫЦе§ЬЌЗжВМЁЃ
етОЭЪЧжааФМЋЯоЖЈРэЃЌЫќЩёЦцЕФЕиЗНОЭдкгкВЛЙмзмЬхЪЧЪВУДЗжВМЁЃЮвУЧКмЖрЭЦЕМЖМЪЧЛљгкжааФМЋЯоЖЈРэЕФЁЃ
Monte Carlo Method
УЩЬиПЈТоЗНЗЈ
ЫќЪЧЪЙгУЫцЛњЪ§РДНтОіМЦЫуЮЪЬтЕФЗНЗЈЁЃ
УЩЬиПЈТоЪЧвЛИіДѓЖФГЁЃЌвдЫќУќУћЃЌКЌвхНќЫЦгкЫцЛњЁЃЮвУЧгаЪБКђЛсвђЮЊИїжжЯожЦЖјЮоЗЈЪЙгУШЗЖЈадЕФЗНЗЈЃЌДЫЪБЮвУЧжЛФмЫцЛњФЃФтЃЌгУЭЈЙ§ИХТЪЪЕбщЫљЧѓЕФИХТЪРДЙРМЦЮвУЧИааЫШЄЕФвЛИіСПЁЃзюжЊУћЕФР§зггаВМЗсЭЖеыЪдбщЁЃ
18ЪРМЭЃЌВМЗсЬсГівдЯТЮЪЬтЃКЩшЮвУЧгавЛИівдЦНааЧвЕШОрФОЮЦЦЬГЩЕФЕиАхЃЌФОЮЦМфОрЮЊaЃЌЯждкЫцвтХзвЛжЇГЄЖШlБШФОЮЦжЎМфОрРыaаЁЕФеыЃЌЧѓеыКЭЦфжавЛЬѕФОЮЦЯрНЛЕФИХТЪЁЃВМЗсМЦЫуГіРДСЫИХТЪЮЊp
= 2l/ІаaЁЃ
ЮЊСЫМЦЫудВжмТЪЃЌШЫУЧЗзЗзЭЖеыЃЌвдЪЕМЪЕФЪдбщНсЙћРДМЦЫуЁЃ
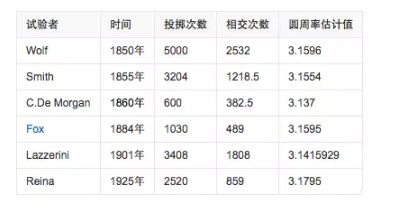
ЯТЭМдђЪЧМЦЫуЛњФЃФтЕФНсЙћ
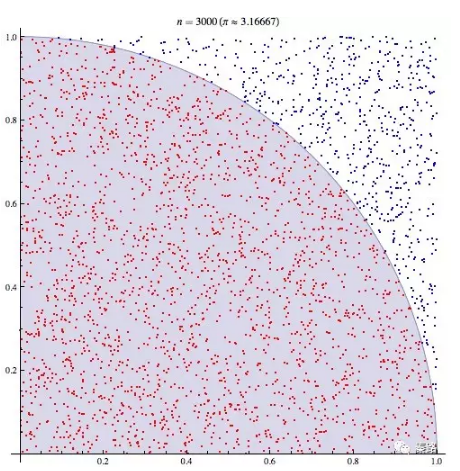
етОЭЪЧУЩЬиПЈТоЗНЗЈЕФЪЕМЪгІгУЁЃЫќЕФРэТлвРОнЪЧДѓЪ§ЖЈРэКЭжааФМЋЯоЖЈРэЁЃ
Hypothesis Testing
МйЩшМьбщ
ЫќЪЧИљОнвЛЖЈЕФМйЩшЬѕМўгЩбљБОЭЦЖЯзмЬхЕФЗНЗЈЁЃ
ЪзЯШИљОнЪЕМЪЮЪЬтзїГівЛИіМйЩшЃЌМЧзїH0ЃЌЯрЗДЕФМйЩшГЦЮЊБИдёМйЩшЁЃЫќЕФКЫаФЫМЯыЪЧаЁИХТЪЗДжЄЗЈЃЌШчЙћетИіМйЩшЗЂЩњЕФИХТЪЬЋаЁвджСгкВЛПЩФмЗЂЩњЃЌНсЙћЫќЗЂЩњСЫЃЌФЧУДЮвУЧШЯЮЊМйЩшЪЧВЛГЩСЂЕФЁЃ
МйЩшМьбщЪЧашвЊШнШЬЕФЃЌвђЮЊбљБОЛсДцдкВЈЖЏЃЌетИіВЈЖЏЗЖЮЇВЛЛсЬЋбЯИёЃЌдкетИіЗЖЮЇФкГіЯжЕФЪТМўЮвУЧЖМФмНгЪмЁЃЕЋЪЧЮвУЧЖМетУДШнШЬСЫЃЌЛЙЪЧГіЯжСЫЮЅБГдМйЩшЕФаЁИХТЪЪТМўЃЌФЧУДЫЕУїдМйЩшгаЮЪЬтЁЃВЛФмШнШЬЕФЗЖЮЇМДОмОјгђЃЌдкОмОјгђЗЂЩњЕФИХТЪЮвУЧЖМШЯЮЊЫќЪЧаЁИХТЪЪТМўЁЃ
МйЩшМьбщШнвзЗИСНРрДэЮѓЃЌЕквЛРрДэЮѓЪЧецЪЕЧщПіЮЊh0ГЩСЂЃЌЕЋХаЖЯh0ВЛГЩСЂЃЌЗИСЫЁАвдецЮЊМйЁБЕФДэЮѓЁЃЕкЖўРрДэЮѓЪЧh0ЪЕМЪВЛГЩСЂЃЌЕЋХаЖЯЫќГЩСЂЃЌЗИСЫЁАвдМйЮЊецЁБЕФДэЮѓЁЃ
МйЩшМьбщгаUМьбщЁЂTМьбщЁЂFМьбщЕШЗНЗЈЁЃ
p-Value
PжЕ
ЫќЪЧНјааМйЩшМьбщХаЖЈЕФвЛИіВЮЪ§ЁЃЕБдМйЩшЮЊецЪБбљБОЙлВьНсЙћЃЈЛђИќМЋЖЫНсЙћЃЉГіЯжЕФИХТЪЁЃPжЕКмаЁЃЌЫЕУїдМйЩшЗЂЩњЕФИХТЪКмаЁЃЌЕЋЫќШЗЪЕЗЂЩњСЫЃЌФЧУДЮвУЧОЭгаРэгЩОмОјдМйЩшЁЃ
жСгкPжЕЕФбЁдёИљОнОпЬхЧщПіЃЌвЛАуЪЧ1%ЃЌ5%МИИіЕЕДЮЁЃ
ШЛЖјЃЌPжЕдкЭГМЦбЇЩЯељвщКмДѓЃЌPжЕЪЧЗёЪЧНгЪмдМйЩшЕФБъзМЃЌЖМЪЧЭГМЦбЇИїжжСїХЩЛьКЯКѓЕФЙлЕуЁЃPжЕДгРДУЛгаБЛжЄУїПЩвдгУРДНгЪеФГИіМйЩшЃЈЫљвдЮвЩЯЮФЕФЫЕУїВЂВЛбЯНїЃЉЃЌЫќжЛЪЧНіЙЉВЮПМЁЃЯждкЭГМЦбЇМвУЧвВПЊЪМГЋЕМЃКгІИУИјГіжУаХЧјМфКЭЭГМЦЙІаЇЃЌЪЕМЪЕФааЖЏХаЖСЛЙЪЧСєИјШЫАЩЁЃ
Chi2 Test
ПЈЗНМьбщ
ChiЖСзїПЈЁЃЭЈГЃгУзїЖРСЂадМьбщКЭФтКЯгХЖШМьбщЁЃ
ПЈЗНМьбщЛљгкПЈЗНЗжВМЁЃМьбщЕФМйЩшЪЧЙлВьЦЕЪ§гыЦкЭћЦЕЪ§УЛгаВюБ№ЁЃ
ЖРСЂадМьбщЃКПЈЗНЗжВМЕФвЛИіживЊгІгУЪЧЛљгкбљБОЪ§ОнХаЖЯСНИіБфСПЕФЖРСЂадЁЃЖРСЂадМьбщЪЙгУСаСЊБэИёЪНЃЌвђДЫвВБЛГЦЮЊСаСЊБэМьбщЁЃдМйЩшжаЃЌСаБфСПгыааБфСПЖРСЂЃЌЭЈЙ§УПИіЕЅдЊИёЕФЦкЭћЦЕЪ§МьбщЭГМЦСПЁЃ
ФтКЯгХЖШМьбщЃКЫќвРОнзмЬхЗжВМзДПіЃЌМЦЫуГіЗжРрБфСПжаИїРрБ№ЕФЦкЭћЦЕЪ§ЃЌгыЗжВМЕФЙлВьЦЕЪ§НјааЖдБШЃЌХаЖЯЦкЭћЦЕЪ§гыЙлВьЦЕЪ§ЪЧЗёгаЯджјВювьЁЃФПЕФЪЧХаЖЯМйЩшЕФИХТЪЗжВМФЃаЭЪЧЗёФмгУзїбаОПзмЬхЕФФЃаЭЁЃ
ЖРСЂадМьбщЪЧФтКЯгХЖШМьбщЕФЭЦЙуЁЃ
Estimation
ЙРМЦ
ЭГМЦбЇРяУцЙРМЦЗжЮЊВЮЪ§ЙРМЦКЭЗЧВЮЪ§ЙРМЦЁЃ
ВЮЪ§ЙРМЦЪЧгУбљБОжИБъЙРМЦзмЬхжИБъЃЌетИіжИБъПЩвдЪЧЦкЭћЁЂЗНВюЁЂЯрЙиЯЕЪ§ЕШЃЌжИБъЕФе§ЪНУћГЦОЭЪЧВЮЪ§ЁЃЕБЙРМЦЕФЪЧетаЉВЮЪ§ЕФжЕЪБЃЌНазіЕуЙРМЦЁЃЕБЙРМЦЕФЪЧвЛИіЧјМфЃЌМДзмЬхжИБъдкФГЗЖЮЇФкЕФПЩФмЪБЃЌНазіЧјМфЙРМЦЃЌМђЕЅШЯЮЊЪЧШЫУЧГЃЫЕЕФгаЖрЩйАбЮеБЃжЄФГжЕдкФГИіЗЖЮЇФкЁЃ
ВЮЪ§ЙРМЦашвЊЯШУїШЗЖдбљБОЕФЗжВМаЮЬЌгыФЃаЭЕФОпЬхаЮЪНзіМйЩшЁЃГЃМћЕФЙРМЦЗНЗЈгаМЋДѓЫЦШЛЙРМЦЗЈЁЂзюаЁЖўГЫЗЈЁЂБДвЖЫЙЙРМЦЗЈЕШЁЃ
ЗЧВЮЪ§ЙРМЦдђЪЧВЛзіМйЩшЃЌжБНгРћгУбљБОЪ§ОнШЅзіБЦНќЃЌевГіЯргІЕФФЃаЭЁЃ
Confid Int(CI)
жУаХЧјМф
ЫќЪЧВЮЪ§МьбщжаЖдФГИібљБОЕФзмЬхВЮЪ§ЕФЧјМфЙРМЦЁЃЫќУшЪіЕФЪЧетИіВЮЪ§гавЛЖЈИХТЪТфдкВтСПНсЙћЕФЗЖЮЇГЬЖШЁЃетИіИХТЪНазіжУаХЫЎЦНЁЃ
вдЭјЩЯР§згРДЫЕЃЌШчЙћдквЛДЮДѓбЁжаФГШЫЕФжЇГжТЪЮЊ55%ЃЌЖјжУаХЫЎЦН0.95вдЩЯЕФжУаХЧјМфЪЧЃЈ50%,60%ЃЉЃЌФЧУДЫћЕФецЪЕжЇГжТЪга95%ЕФИХТЪТфдкКЭ50ЁЋ60ЕФжЇГжТЪжЎМфЁЃЮвУЧвВПЩвдКмШнвзЕФЭЦЕУЃЌЕБжУаХЧјМфдНДѓЃЌжУаХЫЎЦНвВвЛЖЈдНДѓЃЌТфдк40ЁЋ70%жЇГжТЪЕФПЩФмадОЭга99.99%СЫЁЃЕБШЛЃЌдНДѓЕФжУаХЧјМфЃЌЫќдкЯжЪЕЕФОіВпМлжЕвВдНЕЭЁЃ
жУаХЧјМфОГЃМћгкГщбљЕїбаЃЌABВтЪдЕШЁЃ
MLE
МЋДѓЫЦШЛЙРМЦ
ЫќЪЧНЈСЂдкМЋДѓЫЦШЛдРэЕФЛљДЁЩЯЁЃ
ШчЙћЪдбщШчгаШєИЩИіПЩФмЕФНсЙћAЃЌBЃЌCЁЁЃШєдкНіНізївЛДЮЪдбщжаЃЌНсЙћAГіЯжЃЌдђвЛАуШЯЮЊЪдбщЬѕМўЖдAГіЯжгаРћЃЌвВМДAГіЯжЕФИХТЪКмДѓЁЃ
ДЫЪБЮвУЧашвЊевГіФГИіВЮЪ§ЃЌВЮЪ§ФмЪЙетИібљБОГіЯжЕФИХТЪзюДѓЃЌЮвУЧЕБШЛВЛЛсдйШЅбЁдёЦфЫћаЁИХТЪЕФбљБОЃЌЫљвдИЩДрОЭАбетИіВЮЪ§зїЮЊЙРМЦЕФецЪЕжЕЁЃ
Kernel Density Estimate
КЫУмЖШЙРМЦ
ЫќЪЧИХТЪТлжаЙРМЦЮДжЊЕФУмЖШКЏЪ§ЃЌЪєгкЗЧВЮЪ§МьбщЁЃ
вЛАуЕФИХТЪЮЪЬтЃЌЮвУЧЖМЛсМйЖЈЪ§ОнЗжВМТњзузДЬЌЃЌЪЧЛљгкМйЖЈЕФХаБ№ЁЃетжжНаВЮЪ§МьбщЁЃШчЙћШчЙћЪ§ОнгыМйЖЈДцдкКмДѓЕФВювьЃЌФЧУДетаЉЗНЗЈОЭВЛКУгУЃЌгкЪЧБугаСЫЗЧВЮЪ§МьбщЁЃКЫУмЖШЙРМЦОЭЪЧЗЧВЮЪ§МьбщЃЌЫќВЛашвЊМйЖЈЪ§ОнТњзуФЧжжЗжВМЁЃ
Regression
ЛиЙщ
ЛиЙщЃЌжИбаОПвЛзщЫцЛњБфСП(Y1 ЃЌY2 ЃЌЁЃЌYi)КЭСэвЛзщ(X1ЃЌX2ЃЌЁЃЌXk)БфСПжЎМфЙиЯЕЕФЭГМЦЗжЮіЗНЗЈЃЌгжГЦЖржиЛиЙщЗжЮіЁЃЭЈГЃY1ЃЌY2ЃЌЁЃЌYiЪЧвђБфСПЃЌX1ЁЂX2ЃЌЁЃЌXkЪЧздБфСПЁЃ
ЛиЙщЗжЮіГЃгУРДЬНЬжБфСПжЎМфЕФЙиЯЕЃЌдкгаЯоЧщПіЯТЃЌвВФмЭЦЖЯЯрЙиадКЭвђЙћадЁЃЖјдкЛњЦїбЇЯАСьгђжаЃЌЫќБЛгУРДдЄВтЃЌвВФмгУРДЩИбЁЬиеїЁЃ
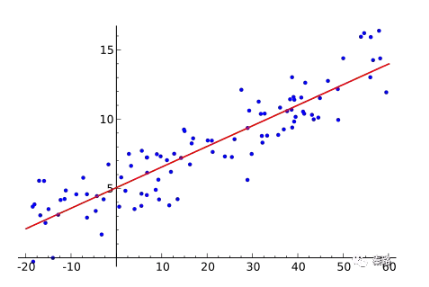
ЛиЙщАќРЈЯпадЛиЙщЁЂЗЧЯпадЛиЙщЁЂТпМЛиЙщЕШЁЃЩЯЭМОЭЪЧЯпадЛиЙщЁЃ
Convariance
аЗНВю
гУгкКтСПСНИіБфСПЕФзмЬхЮѓВюЃЌЗНВюЪЧаЗНВюЕФвЛжжЬиЪтЧщПіЃЌМДСНИіБфСПЯрЭЌЁЃ
аЗНВюгУЪ§ОнЦкЭћжЕEМЦЫуЃКcov(x,y) = E[XY]-E[X][Y]ЁЃ
ШчЙћXYЛЅЯрЖРСЂЃЌдђcov(x,y)=0.ДЫЪБE[XY] = E[X][Y]ЁЃ
Correlation
ЯрЙиад
МДБфСПжЎМфЕФЙиСЊадЃЌЯрЙиаджЛЩцМАЪ§бЇВуУцЃЌМДвЛИіБфСПБфЛЏЃЌСэЭтвЛИіБфСПЛсВЛЛсБфЛЏЃЌЕЋЪЧСНИіБфСПЕФвђЙћадВЛзібаОПЁЃ
ЯрЙиЙиЯЕЪЧвЛжжЗЧШЗЖЈадЕФЙиЯЕЃЌМДЮоЗЈЭЈЙ§вЛИіБфСПОЋШЗЕиШЗЖЈСэЭтвЛИіБфСПЃЌБШШчЮвУЧЖМШЯЮЊЃЌвЛИіШЫЩэИпдНИпЬхжидНжиЃЌЕЋЪЧВЛФмецЕФЭЈЙ§ЩэИпШЅШЗЖЈШЫЕФЬхжиЁЃ
Pearson Coeff
ЦЄЖћбЗЯрЙиЯЕЪ§
ЫќЪЧЖШСПСНИіБфСПЯпадЯрЙиЕФЯЕЪ§ЃЌгУrБэЪОЃЌЦфжЕНщгк-1гы1жЎМфЁЃ1БэЪОЭъШЋе§ЯрЙиЃЌ0БэЪОЭъШЋЮоЙиЃЌ-1БэЪОЭъШЋИКЯрЙиЁЃ
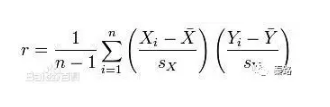
Causation
вђЙћад
КЭЯрЙиадЪЧвЛЖбКУЛљгбЁЃЯрЙиадДњБэЪ§бЇЩЯЕФЙиЯЕЃЌЕЋВЂВЛДњБэОпгавђЙћадЁЃ
ЯФЬьЃЌГдРфвћЕФШЫЪ§КЭбЭЫРЕФШЫЪ§ЖМГЪЯже§ЯрЙиЁЃФбЕРЪЧГдРфвћЕМжТСЫбЭЫРЃПВЛЪЧЕФЃЌЪЧвђЮЊЬьШШЃЌЬьШШГдРфвћЕФШЫЖрСЫЃЌгЮгОЕФШЫвВЖрСЫЁЃ
ЁЖДѓЪ§ОнЪБДњЁЗдјОЧПЕїЃЌЮвУЧгІИУжиЪгЯрЙиадЖјВЛЪЧвђЙћадЃЌетЪЧДцвЩЕФЃЌвђЮЊЖдЪ§ОнПЦбЇМвРДЫЕЃЌЖдвЕЮёвђЙћадЕФСЫНтЭљЭљЪЄгкЯрЙиадЃЌБШШчФудЄВтвЛИіШЫЪЧЗёЛсЕУАЉжЂЃЌФуВЛФмФУЪЧЗёзіЙ§ЗХСЦзїЮЊЬиеїЃЌвђЮЊЗХСЦвбОЪЧАЉжЂЕФЙћЃЌБиШЛЪЧЗЧГЃЧПЯрЙиЃЌЕЋЪЧЖддЄВтУЛгаШЮКЮАяжњЃЌжЛЪЧВтЪдЪ§ОнЩЯКУПДЖјвбЁЃ
Least2 fit
зюаЁЖўГЫЗЈ
ЫќЪЧЯпадЛиЙщЕФвЛжжгУгкЛњЦїбЇЯАжаЕФгХЛЏММЪѕЁЃ
зюаЁЖўГЫЕФЛљБОЫМЯыЪЧЃКзюгХФтКЯжБЯпгІИУЪЧЪЙИїЕуЕНЛиЙщжБЯпЕФОрРыКЭзюаЁЕФжБЯпЃЌМДЦНЗНКЭзюаЁЁЃЫќЪЧЛљгкХЗЪНОрРыЕФЁЃ
Eculidean Distance
ХЗЪЯОрРы
жИдкmЮЌПеМфжаСНИіЕужЎМфЕФецЪЕОрРыЁЃаЁбЇЪБЧѓЕФзјБъжсжсЩЯСНИіЕуЕФжБЯпОрРыОЭЪЧЖўЮЌПеМфЕФХЗЪНОрРыЁЃКмЖрЫуЗЈЖМЪЧЛљгкХЗЪНОрРыЧѓНтЕФЁЃ
ЖўЮЌЃК
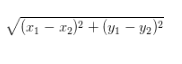
ЁЊЁЊЁЊЁЊЁЊЁЊ
Programming БрГЬ
Ъ§ОнПЦбЇМвЪЧашвЊвЛЖЈЕФБрГЬФмСІЃЌЫфШЛВЛашвЊГЬађдБФЧУДОЋЭЈЃЌзЂжиЕФЪЧНтОіЕФФмСІЃЌЖјВЛЪЧЙЄГЬЛЏЕФФмСІЁЃзїепДгФкШнПДИќЭЦГчRЃЌЮвИіШЫЪЧЭЦГчPythonЕФЁЃ
Python Basics
PythonЛљДЁжЊЪЖЁЃ
ШЫЩњПрЖЬЃЌЮвгУPythonЁЃ
PythonЕФЛљДЁФкШнБШRЗсИЛЕФЖрЃЌНќМИФъЃЌPythonгазїЮЊЕквЛЪ§ОнПЦбЇгябдЕФЧїЪЦЁЃЛљДЁФкШнОЭВЛЖрИДЪіСЫЁЃ
Working in Excel
ExcelИЩЛю
еЦЮеГЃгУКЏЪ§ЃЌЖЎЕУЪ§ОнЗжЮіПтЃЌЛсPowerЯЕСаМгЗжЁЃVBAетжжОЭВЛгУбЇСЫЁЃ
R Setup, RStudio R
АВзАRКЭRStudio
RЪЧвЛУХЭГМЦбЇгябдЁЃЯТСаЕФФкШнЃЌЖМЪЧRгябдЯрЙиЁЃ
R Basics
RЕФЛљДЁЃЌВЛЖрзїГТЪіСЫЁЃ
Varibles
БфСП
БфСПЪЧМЦЫуЛњгябджаЕФГщЯѓИХФюЃЌПЩвдРэНтГЩЮвУЧМЦЫуЕФНсЙћЛђепжЕЃЌВЛЭЌМЦЫугябдЕФБфСПаджЪВЛвЛбљЁЃжївЊРэНтRКЭPythonЕФБфСПОЭааЁЃДѓЪ§ОнФЧПщПЩФмЛЙЛсЩцМАЕНJavaКЭScalaЁЃ
R гУ <- ИјБфСПИГжЕЃЌ=вВФмгУЃЌЕЋВЛНЈвщЁЃ
Vectors
ЯђСП
ЯђСПЪЧвЛЮЌЪ§зщЃЌПЩвдДцДЂЪ§жЕаЭЁЂзжЗћаЭЛђТпМаЭЪ§ОнЕФвЛЮЌЪ§зщЁЃRРяУцЪЙгУКЏЪ§c( )ДДНЈЯђСПЁЃ
ЯђСПжаЕФЪ§ОнБиаыгЕгаЯрЭЌЕФЪ§ОнРраЭЃЌЮоЗЈЛьдгЁЃ
Matrices
Оиеѓ
ОиеѓЪЧвЛИіЖўЮЌЪ§зщЃЌКЭЯђСПвЛбљЃЌУПИідЊЫиБиаыгЕгаЯрЭЌЕФЪ§ОнРраЭЁЃЕБЮЌЖШГЌЙ§2ЪБЃЌЮвУЧИќНЈвщЪЙгУЪ§зщ
| m <- matrix(1:20,nrow=5,ncol=4) |
Arrays
Ъ§зщ
Ъ§зщгыОиеѓРрЫЦЃЌЕЋЪЧЮЌЖШПЩвдДѓгк2ЃЌЪ§ОнРраЭБиаывЛбљЁЃ
Factors
вђзг
вђзгЪЧRжаЕФгаађБфСПКЭРрБ№БфСПЁЃ
РрБ№БфСПвВНазіУћвхБфСПЃЌЫќУЛгаЫГађжЎЗжЃЌБШШчФаХЎЃЌЫфШЛБрТыжаПЩФмФаЮЊ1ЃЌХЎЮЊ2ЃЌЕЋВЛОпБИЪ§жЕМЦЫуКЌвхЁЃгаађБфСПдђБэЪОвЛжжЫГађЙиЯЕЃЌЩйФъЁЂЧрФъЁЂРЯФъдђЪЧвЛжжгаађБфСПЁЃ
| f <- factor(c("type1","type2","type1)) |
дкfactorКЏЪ§жаМгШыВЮЪ§ordered = TrueЃЌОЭБэЪОЮЊгаађаЭБфСПСЫЁЃ
Lists
СаБэ
ЫќЪЧRзюИДдгЕФЪ§ОнРраЭЃЌЫќПЩвдЪЧЩЯЪіЪ§ОнНсЙЙЕФзщКЯЁЃ
| l <- list(names
= v,m,a,f ) |
ЩЯЪіР§згОЭАќКЌСЫЯђСПЁЂОиеѓЁЂЪ§зщЁЂвђзгЁЃЮвУЧПЩвдЪЙгУЫЋжиЗНРЈКХ[[ ]]бЁШЁСаБэжаЕФдЊЫиЁЃRжаЕФЯТБъВЛДг0ПЊЪМЃЌЫљвдlist[[1]]
бЁШЁЕФЪЧvЁЃ
Data Frames
Ъ§ОнПђ
дкRКЭPythonжаЮЊГЃгУЕФЪ§ОнНсЙЙЁЃ
RгябджаЮЊdata.frameЃЌPythonжаЮЊPandasЕФDataFrameЁЃетРявдRгябдОйР§ЁЃ
Ъ§ОнПђПЩвдАќКЌВЛЭЌЪ§ОнРраЭЕФСаЃЌЫќЪЧБШОиеѓИќЙуЗКЕФИХФюЃЌвВЪЧRжазюГЃгУЕФЪ§ОнНсЙЙЁЃУПвЛСаЕФЪ§ОнРраЭБиаыЮЈвЛЁЃ
| x <- data.frame(col1,col2,col3) |
Reading CSV Data
ЖСШЁCSV
етвЛПщБШНЯПгЕФЕиЗНЪЧжаЮФЃЌRгябдЖджаЮФБрТыЕФжЇГжБШНЯТщЗГЁЃ
Reading Raw Data
ЖСШЁдЪМЪ§Он
ВЛЧхГўетКЭCSVЕФЧјБ№ЁЃ
Subsetting Data
ЙЙНЈЪ§ОнМЏ
RЬсЙЉСЫГЃгУКЏЪ§ЗНБуЮвУЧЙЙНЈЪ§ОнМЏЃЈЗДе§РДШЅЖМФЧМИИігЂЮФЃЉЁЃ
Ъ§ОнМЏКЯВЂЪЙгУmergeКЏЪ§ЁЃ
ЬэМгЪ§ОнааЪЙгУrbindКЏЪ§ЁЃ
dataframeбЁШЁзгМЏгУ[ row,column]ЁЃ
ЩОГ§БфСППЩвдЭЈЙ§ <- NullЁЃ
ИДдгВщбЏдђЪЙгУsubsetКЏЪ§ЁЃ
ШчЙћвбОЯАЙпSQLКЏЪ§ЃЌПЩвддиШыlibrary(sqldf)КѓгУsqldfКЏЪ§ЁЃ
Manipulate Data Frames
ВйзїЪ§ОнПђ
Г§СЫЩЯУцЕФЙЙНЈЪ§ОнМЏЕФММЧЩЃЌШчЙћЮвУЧашвЊИќИДдгЕФВйзїЃЌМгЙЄФГаЉЪ§ОнЃЌШчЧѓБфСПКЭЁЂМЦЫуЗНВюЕШЃЌдђвЊгУЕНRгябдЕФЦфЫћКЏЪ§ЁЃ
RБОЩэЬсЙЉСЫabs(x),sort(x),mean(x),cos(x)ЕШГЃгУЕФЭГМЦЗНЗЈЃЌШчКЮгІгУдкЪ§ОнПђФиЃПЮвУЧЪЙгУapplyКЏЪ§ЃЌПЩНЋШЮвтвЛИіКЏЪ§гІгУдкОиеѓЁЂЪ§зщЁЂЪ§ОнПђжаЁЃ
| apply(dataframe,margin,fun) |
Functions
КЏЪ§
RгябдздДјСЫЗсИЛЕФЭГМЦКЏЪ§ЃЌПЩвдЭЈЙ§ЙйЗН/ЕкШ§ЗНЮФЕЕВщбЏЃЌRвВПЩвдздНЈКЏЪ§ЁЃ
myfunction <-
function(arg1,arg2,ЁЁ){
statements
return(object)
} |
КЏЪ§жаЕФЖдЯѓжЛдкКЏЪ§ФкВПЪЙгУЁЃШчЙћвЊЕїЪдКЏЪ§ЃЌПЩвдЪЙгУwarning( ),messagr( ),stop(
)ЕШОРДэЁЃ
Factor Analysis
вђзгЗжЮі
ЮвВЛжЊЕРетПщЕФБрГЬЛљДЁФкШнЮЊЪВУДвЊМгШывђзгЗжЮіЁЃRгябдЕФвђзгЗжЮіКЏЪ§ЪЧfactanal()
Install Pkgs
ЕїАќЯР
RЕФАќЗЧГЃЗсИЛЃЈPythonИќЪЧЃЉЃЌПЩвдЭЈЙ§cranЯТдиЃЌАќРЈХРГцЁЂНтЮіЁЂИїзЈвЕСьгђЕШЁЃКЏЪ§libraryПЩвдЯдЪОгаФФаЉАќЃЌПЩФмжБНгМгШыАќЁЃRStudioдђЬсЙЉСЫгыАќЯрЙиЕФЗсИЛВщбЏНчУцЁЃ
ЁЊЁЊЁЊЁЊЁЊЁЊ
Machine LearningЛњЦїбЇЯА
Ъ§ОнПЦбЇЕФжеМЋгІгУЃЌЯждквбОЪЧЩюЖШбЇЯАСЫЁЃетЬѕТЗвВНаДгЕїАќЕНПЦбЇЕїВЮЁЃетРяЕФЫуЗЈЪєгкОЕфЫуЗЈЃЌЕЋЪЧЯђGBDTЁЂXGBoostЁЂRFЕШНќМИФъОКШќжаДѓЗЂвьВЪЕФЫуЗЈУЛгаЩцМАЃЌгІИУЪЧаДЕУБШНЯдчЕФдвђЁЃ
What is ML?
ЛњЦїбЇЯАЪЧЩЖзггД
ЛњЦїбЇЯАЃЌЧјБ№гкЪ§ОнЭкОђЃЌЛњЦїбЇЯАЕФЫуЗЈЛљгкЭГМЦбЇКЭИХТЪТлЃЌИљОнвбгаЪ§ОнВЛЖЯздЖЏбЇЯАевЕНзюгХНтЁЃЪ§ОнЭкОђФмАќКЌЛњЦїбЇЯАЕФЫуЗЈЃЌЕЋЪЧаЭЌЙ§ТЫЃЌЙиСЊЙцдђВЛЪЧЛњЦїбЇЯАЃЌдкЛњЦїбЇЯАЕФНЬГЬЩЯПДВЛЕНЃЌЕЋЪЧдкЪ§ОнЭкОђЪщБОФмПДЕНЁЃ
Numerical Var
Ъ§жЕБфСП
ЛњЦїбЇЯАжажївЊЪЧСНРрБфСПЃЌЪ§жЕБфСПКЭЗжСПБфСПЁЃ
Ъ§жЕБфСПОпгаМЦЫувтвхЃЌПЩгУМгМѕГЫГ§ЁЃЪ§ОнРраЭгаintЁЂfloatЕШЁЃ
дкКмЖрФЃаЭжаЃЌСЌајадЕФЪ§жЕБфСПВЛЛсжБНгЪЙгУЃЌЮЊСЫФЃаЭЕФЗКЛЏФмСІЛсНЋЦфзЊЛЛЮЊЗжРрБфСПЁЃ
Categorical Var
ЗжРрБфСП
ЗжРрБфСППЩвдгУЗЧЪ§жЕБэЪОЃЌЫќЪЧРыЩЂБфСПЁЃ
гаЪБКђЮЊСЫЗНБуКЭНкЪЁДцДЂПеМфЃЌвВЛсгУЪ§жЕБэЪОЃЌБШШч1ДњБэФаЃЌ0ДњБэХЎЁЃЕЋЫќУЧУЛгаМЦЫувтвхЁЃдкЪфШыФЃаЭЕФЙ§ГЬжаЃЌЛсНЋЦфзЊБфЮЊбЦБфСПЁЃ
Supervised Learning
МрЖНбЇЯА
ЛњЦїбЇЯАжївЊЗжЮЊМрЖНбЇЯАКЭЗЧМрЖНбЇЯАЁЃ
МрЖНбЇЯАЪЧДгИјЖЈЕФбЕСЗМЏжабЇЯАГівЛИіГЌМЖКЏЪ§Y=F(X)ЃЌЮвУЧвВГЦжЎЮЊФЃаЭЁЃЕБаТЪ§ОнЗХШыЕНФЃаЭЕФЪБКђЃЌЫќФмЪфГіЮвУЧашвЊЕФНсЙћДяЕНЗжРрЛђепдЄВтЕФФПЕФЁЃНсЙћYНазіФПБъЃЌXНазіЬиеїЁЃЕБгааТЪ§ОнНјШыЃЌФмЙЛВњЩњаТЕФзМШЗЕФНсЙћЁЃ
МШШЛДгбЕСЗМЏжаЩњГЩФЃаЭЃЌФЧУДбЕСЗМЏЕФНсЙћYгІИУЪЧвбжЊЕФЃЌжЊЕРЪфШыXКЭЪфГіYЃЌФЃаЭВХЛсНЈСЂЃЌетИіЙ§ГЬНазіМрЖНбЇЯАЁЃШчЙћЪфГіжЕЪЧРыЩЂЕФЃЌЪЧЗжРрЃЌШчЙћЪфГіжЕЪЧСЌајЕФЃЌЪЧдЄВтЁЃ
МрЖНбЇЯАГЃМћгкKNNЁЂЯпадЛиЙщЁЂЦгЫиБДвЖЫЙЁЂЫцЛњЩСжЕШЁЃ
Unsupervied Learning
ЗЧМрЖНбЇЯА
ЮоМрЖНбЇЯАКЭМрЖНбЇЯАЃЌМрЖНбЇЯАЪЧжЊЕРНсЙћYЃЌЮоМрЖНбЇЯАЪЧВЛжЊЕРYЃЌНіЭЈЙ§вбгаЕФXЃЌРДевГівўВиЕФНсЙЙЁЃ
ЮоМрЖНбЇЯАГЃМћгкОлРрЁЂвўТэЖћПЩЗђФЃаЭЕШЁЃ
Concepts, Inputs & Attributes
ИХФюЁЂЪфШыКЭЬиеї
ЛњЦїбЇЯААќРЈЪфШыПеМфЁЂЪфГіПеМфЁЂКЭЬиеїПеМфШ§РрЁЃЬиеїбЁдёЕФФПЕФЪЧЩИбЁГіНсЙћгагАЯьЕФЪ§ОнЁЃ
Traning & Test Data
бЕСЗМЏКЭВтЪдМЏ
ЛњЦїбЇЯАЕФФЃаЭЪЧЙЙНЈдкЪ§ОнМЏЩЯЕФЃЌЮвУЧЛсВЩгУЫцЛњГщбљЛђепЗжВуГщбљЕФНЋЪ§ОнЗжГЩДѓаЁСНИіВПЗжЃЌФУГіДѓВПЗжбљБОНјааНЈФЃаЭЃЌСєаЁВПЗжбљБОгУИеНЈСЂЕФФЃаЭНјаадЄБЈЃЌЭЈЙ§аЁбљБОЕФдЄВтНсЙћКЭецЪЕНсЙћзіЖдБШЃЌРДХаЖЯФЃаЭгХСгЁЃетИіНазіНЛВцбщжЄЁЃ
НЛВцбщжЄФмЙЛЬсИпФЃаЭЕФЮШЖЈадЃЌЕЋВЛЪЧЭъШЋБЃЯеЕФЃЌвРОЩгаЙ§ФтКЯЕФЗчЯеЁЃ
ЭЈГЃгУ80%ЕФЪ§ОнЙЙНЈбЕСЗМЏЃЌ20%ЕФЪ§ОнЙЙНЈВтЪдМЏ
Classifier
ЗжРр
МрЖНбЇЯАжаЃЌШчЙћЪфГіЪЧРыЩЂБфСПЃЌЫуЗЈГЦЮЊЗжРрЁЃ
ЪфГіЕФРыЩЂБфСПШчЙћЪЧЖўдЊЕФЃЌдђЪЧЖўдЊЗжРрЃЌБШШчХаЖЯЪЧВЛЪЧРЌЛјгЪМў{ЪЧЃЌЗё}ЃЌКмЖрЗжРрЮЪЬтЖМЪЧЖўдЊЗжРрЁЃгыжЎЯрЖдЕФЪЧЖрдЊЗжРрЁЃ
Prediction
дЄВт
МрЖНбЇЯАжаЃЌШчЙћЪфГіЪЧСЌајБфСПЃЌЫуЗЈГЦЮЊдЄВтЁЃ
дЄВтМДПЩвдЪЧЪ§жЕаЭЃЌБШШчЮДРДЕФЯњСПЃЌвВПЩвдЪЧНщгк[0,1]МфЕФИХТЪЮЪЬтЁЃ
гааЉЫуЗЈЪЪКЯЗжРрЁЂгааЉдђЪЧдЄВтЃЌвВгаЫуЗЈПЩвдСНепЖМФмзіЕНЁЃ
Lift
LiftЧњЯп
ЫќЪЧКтСПФЃаЭадФмЕФвЛжжзюГЃгУЕФЖШСПЃЌЫќПМТЧЕФЪЧФЃаЭЕФзМШЗадЁЃЫќКЫаФЕФЫМЯыЪЧвдНсЙћзїЕМЯђЃЌгУСЫФЃаЭЕУЕНЕФе§РрЪ§СПБШВЛгУФЃаЭЕФаЇЙћЬсЩ§СЫЖрЩйЃП
БШШчФГвЛДЮЛюЖЏгЊЯњЃЌ1000ИігУЛЇЛсга200ИіЯьгІЃЌЯьгІТЪЪЧ20%ЁЃгУСЫФЃаЭКѓЃЌЮвЭЈЙ§ЫуЗЈЃЌНВгУЛЇЗжШКЃЌЬєГіСЫзюгаПЩФмЯьгІЕФгУЛЇ200ИіЃЌВтЪдКѓЕФНсЙћЪЧга100ИіЃЌДЫЪБЕФЯьгІТЪБфГЩСЫ50%ЁЃДЫЪБЕФLiftжЕЮЊ5ЁЃ
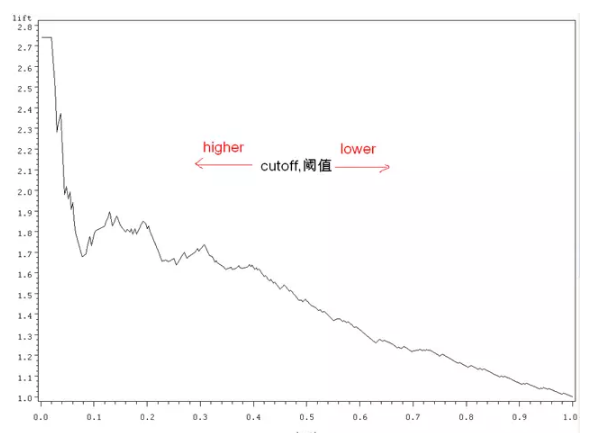
ЩЯЭМОЭЪЧАДLiftжЕЛГіЧњЯпЕФЗЖР§ЁЃзнзјБъЪЧliftжЕЃЌКсзјБъЪЧЬєбЁЕФЕФЗЇжЕЁЃЗЇжЕдНЕЭЃЌЫЕУїЬєбЁЕФдНбЯИёЃЌАДЩЯЮФЕФР§згРэНтЃЌЬєбЁЕФОЭЪЧзюгаПЩФмЯьгІЕФгУЛЇЁЃЕБУЛгаЗЇжЕЪБЃЌliftОЭЮЊ0СЫЁЃЗЇжЕЭЈГЃЪЧИљОндЄВтЗжЪ§ХХађЕФЁЃ
ЛЙгавЛжжГЃгУЕФНаROCЧњЯпЁЃ
Overfitting
Й§ФтКЯ
Й§ФтКЯЪЧЛњЦїбЇЯАжаГЃХіЕНЕФвЛРрЮЪЬтЁЃжївЊЬхЯждкФЃаЭдкбЕСЗЪ§ОнМЏЩЯБфЯжгХауЃЌЖјдкецЪЕЪ§ОнМЏЩЯБэЯжЧЗМбЁЃдьГЩЕФдвђЪЧЮЊСЫдкбЕСЗМЏЩЯЛёЕУГіЩЋЕФБэЯжЃЌЪЙЕУФЃаЭЕФЙЙдьШчДЫОЋЯИИДдгЃЌЙцдђШчДЫбЯИёЃЌвджСгкШЮКЮгыбљБОЪ§ОнЩдгаВЛЭЌЕФЮФЕЕЫќШЋЖМШЯЮЊВЛЪєгкетИіРрБ№ЁЃ
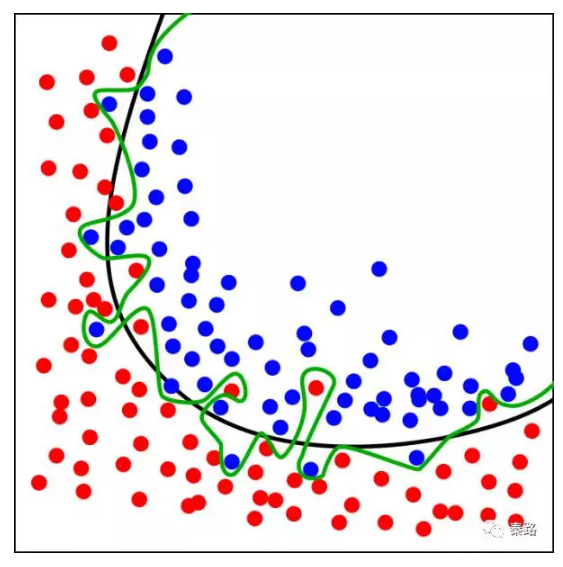
ЩЯЭМЃЌКкЩЋЕФЯпЬѕЪЧе§ГЃФЃаЭЃЌТЬЩЋЕФЯпЬѕЪЧЙ§ФтКЯФЃаЭЁЃ
ВЛЭЌЕФЛњЦїбЇЯАЫуЗЈЃЌЪЧЗёШнвзФтКЯЕФГЬЖШвВВЛНіЯрЭЌЁЃЭЈГЃВЩгУМгДѓбљБОЪ§ОнСПЁЂМѕЩйЙВЯпадЁЂдіМгЬиеїЗКЛЏФмСІЕФЗНЗЈНтОіЙ§ФтКЯЁЃ
гыжЎЯрЗДЕФЪЧЧЗФтКЯЁЃ
Bias & Variance
ЦЋВюКЭЗНВю
ЦЋВюКЭЗНВюГ§СЫЭГМЦбЇИХФюЭтЃЌЫќУЧвВЪЧНтЪЭЫуЗЈЗКЛЏФмСІЕФвЛжжживЊЙЄОпЁЃ
ЫуЗЈдкВЛЭЌбЕСЗМЏЩЯЕУЕНЕФНсЙћВЛЭЌЃЌЮвУЧгУЦЋВюЖШСПЫуЗЈЕФЦкЭћдЄВтКЭецЪЕНсЙћЕФЦЋРыГЬЖШЃЌетДњБэЫуЗЈБОЩэЕФФтКЯФмСІЃЌЗНВюдђЖШСПСЫЫуЗЈЪмЪ§ОнВЈЖЏдьГЩЕФгАЯьЁЃ
ЦЋВюдНаЁЁЂдНФмЙЛФтКЯЪ§ОнЃЌЗНВюдНаЁЁЂдНФмЙЛПИЪ§ОнВЈЖЏЁЃ
Trees & Classification
ЪїЗжРр
ЪїЗжРрЪЧашвЊЭЈЙ§ЖрМЖХаБ№ВХФмШЗЖЈФЃЪНЫљЪєРрБ№ЕФвЛжжЗжРрЗНЗЈЁЃЖрМЖХаБ№Й§ГЬПЩвдгУЪїзДНсЙЙБэЪОЃЌЫљвдГЦЮЊЪїЗжРрЦїЁЃзюОЕфЕФБуЪЧОіВпЪїЫуЗЈЁЃ
Classification Rate
ЗжРре§ШЗТЪ
ЮЊСЫбщжЄФЃаЭЕФКУЛЕЃЌМДзюжеХаЖЯНсЙћЕФЖдДэЃЌЮвУЧв§ШыСЫЗжРре§ШЗТЪЁЃ
ЗжРре§ШЗТЪМДПЩвдХаЖЯЖўЗжРрШЮЮёЃЌвВЪЪгУгкЖрЗжРрШЮЮёЁЃЮвУЧЖЈвхЗжРрДэЮѓЕФбљБОЪ§еМзмбљБОЕФБШТЪЮЊДэЮѓТЪЃЌОЋШЗЖШдђЪЧе§ШЗЕФбљБОЪ§БШТЪЁЃСНепЯрМгЮЊ1ЁЃ
ЮЊСЫИќКУЕФХаЖЯФЃаЭЃЌжївЊЪЧвЕЮёашвЊЃЌЮвУЧЛЙМгШыСЫВщзМТЪ(precision),ВщШЋТЪ(recall)ЃЌВщзМТЪЪЧдЄВтЮЊецЕФЪ§ОнжагаЖрЩйЪЧецЕФЁЃВщШЋТЪЪЧецЕФЪ§ОнжагаЖрЩйЪ§ОнБЛдЄВтЖдСЫЁЃ
етИігаЕуШЦЃЌжївЊЪЧЮЊСЫвЕЮёХаЖЯЃЌМйШчЮвУЧЕФдЄВтЪЧВЁШЫЪЧЗёЛМСЫФГИіжТЫРМВВЁЃЌМйЩшЕУВЁЮЊецЃЌЮвУЧЯдШЛЯЃЭћАбШЋВПЖМЕУВЁЕФЛМепевГіРДЃЌФЧУДДЫЪБВщШЋТЪЃЈЕУВЁЕФЛМепгаЖрЩйБЛзМШЗдЄВтГіРДЃЉБШВщзМТЪЃЈдЄВтЕУВЁЕФЛМепгаЖрЩйецЕФЕУВЁСЫЃЉИќживЊЃЌвђЮЊетИіЛсЫРШЫЃЌФЧУДПЯЖЈЪЧбЁдёгаЩБДэЮоЗХЙ§ЁЃДЫЪБИќзЗЧѓВщШЋТЪЁЃ
ЫуЗЈОКШќОЭЪЧЛљгкЩЯЪіжИБъЦРЗжЕФЁЃ
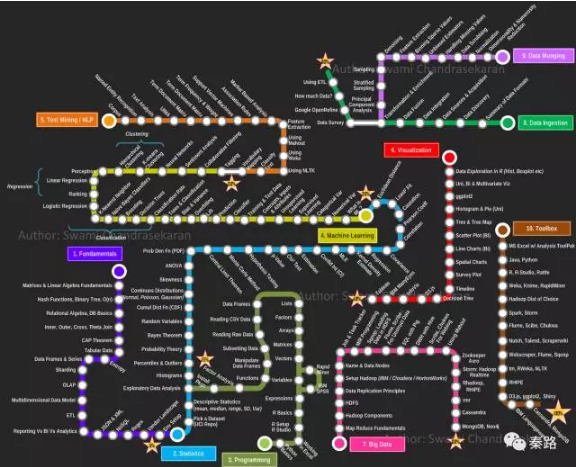
Decision Tress
ОіВпЪї
ЫќЪЧЛљБОЕФЗжРрКЭЛиЙщЗНЗЈЁЃПЩвдРэНтГЩIf-ThenЕФЙцдђМЏЃЌУПвЛЬѕТЗОЖЖМЛЅГтЧвЭъБИЁЃОіВпЪїЗжЮЊФкВПНкЕуКЭвЖНкЕуЃЌФкВПНкЕуОЭЪЧIf-ThenЕФЙцдђЃЌвЖНкЕуОЭЪЧЗжРрНсЙћЁЃ
ОіВпЪїжїСїгаID3ЁЂC4.5ЃЈC5.0вВгаСЫЃЉЁЂCARTЫуЗЈЁЃ
вђЮЊОіВпЪїаЮГЩЕФНсЙЙЪЧИљОнЪїаЮЕнЙщВњЩњЃЌЫќЖдбЕСЗЪ§ОнБэЯжСМКУЃЌЕЋЪЧЛсВњЩњЙ§ФтКЯЯжЯѓЁЃЮЊСЫБмУтетвЛЯжЯѓЃЌЛсНјааМѕжІЁЃМєжНЭЈЙ§Ы№ЪЇКЏЪ§ЛђДњМлКЏЪ§ЪЕЯжЁЃ
ОіВпЪїЕФгХЕуЪЧЃКИпаЃМђЕЅЁЂПЩНтЪЭадЧПЁЂдкДѓаЭЪ§ОнПтгаСМКУБэЯжЁЂЪЪКЯИпЮЌЪ§ОнЁЃ
ШБЕуЪЧЃКШнвзЙ§ФтКЯЁЂВЂЧвЗжРрНсЙћЛсЧуЯђгЕгаИќЖрЪ§жЕЕФЬиеїЃЈЛљгкаХЯЂдівцЃЉЁЃ
ЫцЛњЩСжЫуЗЈЪЧЛљгкОіВпЪїЕФЁЃ
Boosting
ЬсЩ§ЗНЗЈ
ЪєгкМЏГЩбЇЯАЕФвЛжжЁЃЬсЩ§ЗНЗЈBoostingвЛАуЪЧЭЈЙ§ЖрИіШѕЗжРрЦїзщГЩвЛИіЧПЗжРрЦїЃЌЬсИпЗжРрадФмЁЃМђЖјбджЎЪЧШ§ИіГєЦЄНГЖЅвЛИіжюИ№ССЁЃ
ЭЈЙ§ЖдбЕСЗМЏбЕСЗГівЛИіЛљбЇЯАЦїЃЌШЛКѓИљОнЛљбЇЯАЦїЕФЗжРрБэЯжЬјзЊКЭгХЛЏЃЌЗжРрДэЮѓЕФбљБОНЋЛсЛёЕУИќЖрЙизЂЃЌвдДЫжиИДЕќДњЃЌзюжеВњЩњЕФЖрИіЛљЗжРрЦїНјааМгЧПНсКЯЕУГівЛИіЧПЗжРрЦїЁЃ
жїСїЗНЗЈЪЧAdaBoostЃЌвдЛљЗжРрЦїзіЯпадзщКЯЃЌУПвЛТжЬсИпЧАМИТжБЛДэЮѓЗжРрЕФШЈжЕЁЃ
Naive Bayes Classifiers
ЦгЫиБДвЖЫЙЗжРр
ЫќЛљгкБДвЖЫЙЖЈРэЕФЗжРрЗНЗЈЁЃЦгЫиБДвЖЫЙЗЈЕФЪЙгУЬѕМўЪЧИїЬѕМўЛЅЯрЖРСЂЁЃетРяв§ШыОЕфЕФБДвЖЫЙЖЈРэЃК
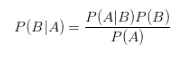
дкЫуЗЈжаЃЌЮвУЧЕФBОЭЪЧЗжРрНсЙћTargetЃЌAОЭЪЧЬиеїЁЃвтЫМЪЧдкЬиеївбОЗЂЩњЕФЧщПіЯТЃЌЗЂЩњBЕФИХТЪЪЧЖрЩйЃП
ИХТЪЙРМЦЗНЗЈгаМЋДѓЫЦШЛЙРМЦКЭБДвЖЫЙЙРМЦЃЌМЋДѓЫЦШЛЙРМЦШнвзВњЩњИХТЪжЕЮЊ0ЕФЧщПіЁЃ
гХЕуЪЧЖдШБЪЇЪ§ОнВЛЬЋУєИаЃЌЫуЗЈвВБШНЯМђЕЅЁЃШБЕуЪЧЬѕМўЛЅЯрЖРСЂдкЪЕМЪЙЄзїжаВЛЬЋГЩСЂЁЃ
K-Nearest Neighbour
KНќСкЗжРрЁЃ
KНќСкЗжРрЕФЬиЕуЪЧЭЈЙ§бЕСЗЪ§ОнЖдЬиеїЯђСППеМфНјааЛЎЗжЁЃЕБгааТЕФЪ§ОнЪфШыЪБЃЌбАевОрРыЫќзюНќЕФKИіЪЕР§ЃЌШчЙћKИіЪЕР§ЖрЪ§ЪєгкФГРрЃЌФЧУДОЭАбаТЪ§ОнвВЫузїФГРрЁЃ
ЬиеїПеМфжаЃЌУПИібЕСЗЪ§ОнЖМЪЧвЛИіЕуЃЌОрРыИУЕуБШЦфЫћЕуИќНќЕФЫљгаЕуНЋзщГЩвЛИізгПеМфЃЌНазіЕЅдЊCellЃЌетЪБКђЃЌУПИіЕуЖМЪєгквЛИіЕЅдЊЃЌЕЅдЊНЋЪЧЕуЕФЗжРрЁЃ
kжЕЕФбЁдёНЋЛсгАЯьЗжРрНсЙћЃЌkжЕдНаЁЃЌФЃаЭдНИДдгЃЌШнвзЙ§ФтКЯЃЌВЛПЙИЩШХЁЃKжЕдНДѓЃЌФЃаЭНЋдНМђЕЅЃЌЗжРрЕФзМШЗЖШЛсЯТНЕЁЃЩЯЭМЪЧK=1ЪБЕФзгПеМфЛЎЗжЃЌЯТЭМЪЧK=5ЪБЕФзгПеМфЛЎЗжЃЌДгбеЩЋКмжБЙлЕФПДЕНгАЯьЁЃ
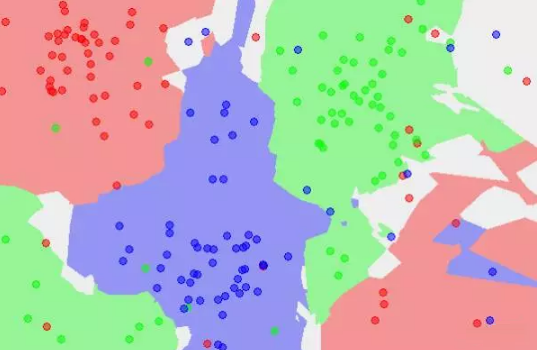
KНќСкЕФетРрЛљгкОрРыЕФЫуЗЈЃЌбЕСЗЕФЪБМфИДдгЖШЕЭЃЌЮЊO(n)ЃЌЪЪгУЗЖЮЇЗЖЮЇЙуЁЃЕЋЪЧЪБМфИДдгЖШЕЭЪЧЭЈЙ§ПеМфИДдгЖШЛЛРДЕФЃЌЫљвдашвЊДѓСПЕФМЦЫузЪдДКЭФкДцЁЃСэЭтбљБОВЛЦНКтЮЪЬтНтОіВЛСЫЁЃ
Logistic Regression
ТпМЫЙкаЛиЙщЃЌМђГЦТпМЛиЙщЁЃ
ТпМЛиЙщЪєгкЖдЪ§ЯпадФЃаЭЃЌЫфШЛНаЛиЙщЃЌБОжЪШДЪЧЗжРрФЃаЭЁЃШчЙћЮвУЧвЊгУЯпадФЃаЭзіЗжРрШЮЮёЃЌдђевЕНsigmoidКЏЪ§НЋЗжРрФПБъYКЭЛиЙщЕФдЄВтжЕСЊЯЕЦ№РДЃЌЕБдЄВтжЕДѓгк0,ХаЖЯе§Р§ЃЌаЁгк0ЮЊЗДР§ЃЌЕШгк0ШЮвтХаБ№ЃЌетИіЗНЗЈНаТпМЛиЙщФЃаЭЁЃ
ФЃаЭВЮЪ§ЭЈЙ§МЋДѓЫЦШЛЗЈЧѓЕУЁЃТпМЛиЙщЕФгХЕуЪЧПьЫйКЭМђЕЅЃЌШБЕуЪЧИпЮЌЪ§ОнжЇГжВЛКУЃЌШнвзЧЎФтКЯЁЃ
Ranking
ХХађЃЌPageRank
етРягІИУЗКжИGoogleЕФPageRankЫуЗЈЁЃ
PageRankЕФКЫаФЫМЯыга2ЕуЃК
ШчЙћвЛИіЭјвГБЛКмЖрЦфЫћЭјвГСДНгЕНЕФЛАЫЕУїетИіЭјвГБШНЯживЊЃЌвВОЭЪЧpagerankжЕЛсЯрЖдНЯИпЃЛ
ШчЙћвЛИіpagerankжЕКмИпЕФЭјвГСДНгЕНвЛИіЦфЫћЕФЭјвГЃЌФЧУДБЛСДНгЕНЕФЭјвГЕФpagerankжЕЛсЯргІЕивђДЫЖјЬсИпЁЃ
PageRankВЂВЛЪЧЮЈвЛЕФХХУћЫуЗЈЃЌЖјЪЧзюЮЊЙуЗКЪЙгУЕФвЛжжЁЃЦфЫћЫуЗЈЛЙгаЃКHilltop ЫуЗЈЁЂExpertRankЁЂHITSЁЂTrustRankЁЃ
Linear Regression
ЯпадЛиЙщ
ЯпадЛиЙщЪЧЛњЦїбЇЯАЕФШыУХМЖБ№ЫуЗЈЃЌЫќЭЈЙ§бЇЯАЕУЕНвЛИіЯпадзщКЯРДНјаадЄВтЁЃ
вЛАуаДГЩF(x) = wx +bЃЌЮвУЧЭЈЙ§ОљЗНЮѓВюЛёЕУwКЭbЃЌОљЗНЮѓВюЪЧЛљгкХЗЪНОрРыЕФЧѓНтЃЌОЭЪЧзюаЁЖўГЫЗЈРВЁЃевЕНвЛЬѕЯпЃЌЫљгаЪ§ОнЕНетЬѕЯпЕФХЗЪНОрРыжЎКЭзюаЁЁЃ
ЯпадЛиЙщШнвзгХЛЏЃЌФЃаЭМђЕЅЃЌШБЕуЪЧВЛжЇГжЗЧЯпадЁЃ
Perceptron
ИажЊЛњ
ЫќЪЧЖўРрЗжРрЕФЯпадЗжРрФЃаЭЁЃ
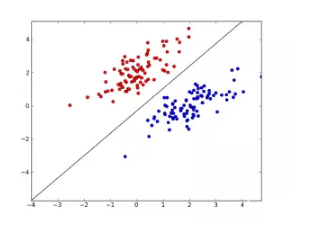
ЫќЭЈЙ§вЛИіwx+bЕФГЌЦНУцSЛЎЗжЬиеїПеМфЁЃЮЊСЫевГіетИіГЌЦНУцЃЌЮвУЧРћгУЫ№ЪЇКЏЪ§МЋаЁЛЏЧѓГіЁЃГЌЦНУцЕФНтВЛЪЧЮЈвЛЕФЃЌВЩШЁВЛЭЌГѕжЕЛђЮѓЗжРрЕуНЋЛсдьГЩВЛЭЌНсЙћЁЃ
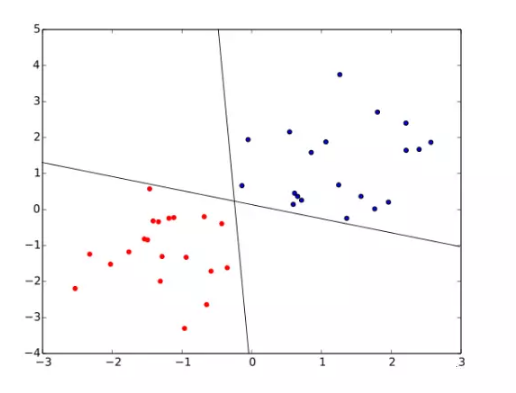
Hierarchical Clustering
ВуДЮОлРр
ВуДЮОлРржИдкВЛЭЌВуДЮЖдЪ§ОнМЏНјааЛЎЗжЃЌДгЖјаЮГЩЪїаЮЕФОлРрНсЙЙЁЃ
ЫќНЋбљБОПДзївЛИіГѕЪМОлРрДиЃЌУПДЮдЫЫуевГізюНќЕФДиНјааКЯВЂЃЌИУЙ§ГЬВЛЖЯКЯВЂЃЌжБЕНТњзудЄЩшЕФДиЕФИіЪ§ЁЃ

ЩЯЭМОЭЪЧЫљгабљБОжиИДжДаазюжеK=1ЪБЕФНсЙћЁЃКсжсЪЧОлРрДижЎМфЕФОрРыЃЌЕБОрРы=5ЪБЃЌЮвУЧгаСНИіОлРрДиЃЌЕБОрРы=3ЪБЃЌЮвУЧгаЫФИіОлРрДиЁЃ
K-means Clusterning
KОлРр
ШЋГЦKОљжЕОлРрЃЌЮоМрЖНбЇЯАЕФОЕфЫуЗЈЁЃЮявдРрОлШЫвдШКЗжЕФЕфаЭДњБэЁЃ
KОлРрашвЊНЋдЪМЪ§ОнЮоСПИйЛЏЃЌШЛКѓЩшжУОлРрЕуЕќДњЧѓНтЁЃKОлРрЕФКЫаФЪЧеыЖдЛЎЗжГіЕФШКДиЪЙЦфзюаЁЛЏЦНЗНЮѓВюЁЃжБЙлЫЕЃЌОЭЪЧШУбљБОНєУмЮЇШЦШКДиОљжЕЁЃ
ЩшжУЖрЩйИіОлРрЕуЖрЩйгаЕужїЙлЕФвтЫМЃЌетвВЪЧKОлРрЮЈвЛЕФВЮЪ§ЃЌПМВьЕФЪЧЭтВПжИБъЃЌМДФуОлРрБОЩэЪЧЯыЗжГіМИРрЃЌЭЈЙ§ЖдНсЙћЕФЙлВьвдМАEжЕХаЖЯЁЃ
KОлРрВЛЪЪКЯЖрЮЌЬиеїЃЌвЛАу3ЁЋ4ЮЌМДПЩЃЌЮЌЖШЬЋЖрЛсШБЗІНтЪЭадЃЌRFMФЃаЭЪЧЦфОЕфгІгУЁЃвђЮЊЮявдРрОлЃЌЫљвдЖдЦЋРыОљжЕЕуЕФвьГЃжЕЗЧГЃУєИаЁЃ
Neural Networks
ЩёОЭјТч
ЩёОЭјТчЪЧвЛжжФЃЗТЩњЮяЩёОЯЕЭГЕФЫуЗЈЃЌЩёОЭјТчЫуЗЈвдЩёОдЊзїЮЊзюЛљДЁЕФЕЅЮЛЃЌЩёОдЊЭЈЙ§НЋЪфШыЪ§ОнзЊЛЛЮЊ0Лђ1ЕФЗЇжЕЃЌДяЕНМЄЛюгыЗёЕФФПЕФЃЌЕЋЪЧ0КЭ1ВЛСЌајВЛЙтЛЌЃЌЖдгкСЌајадЪ§ОнЃЌЭљЭљгУsigmoidКЏЪ§зЊЛЛГЩ[0,1]
МфЕФЗЖЮЇЁЃ
НЋетаЉЩёОЕЅдЊвдВуДЮНсЙЙСЌНгЦ№РДЃЌОЭГЩСЫЩёОЭјТчЁЃвђЮЊетИіЬиадЃЌЩёОЭјТчгааэЖрЕФВЮЪ§ЃЌПЩВЛОпБИПЩНтЪЭадЁЃЖрВуЩёОЭјТчЃЌЫќЕФЪфШыВуКЭЪфГіВужЎМфЕФВуМЖНазівўВуЃЌОЭЪЧЬьЯўЕУЫќДњБэЪВУДКЌвхЁЃ
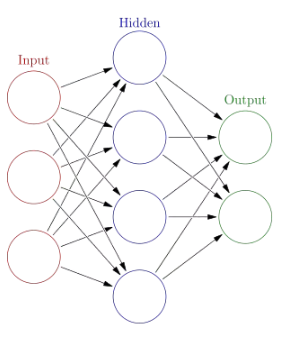
ЩёОЭјТчЕФВуЪ§вЛАуЪЧЙЬЖЈЕФЃЌЕЋЮвУЧвВФмНЋЭјТчВуЪ§зїЮЊбЇЯАЕФФПБъжЎвЛЃЌевЕНзюЪЪКЯЕФВуЪ§ЁЃ
СэЭтЃЌВуЪ§дНЖрЃЌВЮЪ§дНЖрЕФЩёОЭјТчИДдгЖШдНИпЃЌЩюЖШбЇЯАОЭЪЧЕфаЭЕФВуЪ§КмЖрЕФЩёОЭјТчЁЃГЃМћЕФгаCNNЁЂDNNЁЂRNNЕШЫуЗЈЁЃ
Sentiment Analysis
ЧщИаЗжЮі
БШНЯЧАбиЕФвЛИіСьгђЁЃАќРЈЧщИаДЪЕФе§УцИКУцЗжРрЃЌБъзЂгяСЯЃЌЧщИаДЪЕФЬсШЁЕШЁЃ
ЧщИаЗжЮіПЩвдЭЈЙ§ЧщИаЙиМќДЪПтМЦЫуЃЌБШШчЛузмПЊаФЁЂБЏЩЫЁЂФбЙ§ЕФДЪЛуЃЌМЦЫуЧщИажЕЃЌдйМгШыБэЪОЧщИаЧПСвГЬЖШЕФЮЌЖШЃЌШч1ЁЋ5ЕФЪ§жЕНјааДђЗжЁЃгУЛЇЖдЩЬЦЗЦРТлЕФЗжЮіОЭЪЧвЛИіГЃМћЕФЧщИаЗжЮіЃКетЪжЛњЬЋTMЦЦСЫЃЌОЭЪЧ5ЗжЗпХЁЃ
ШЛЖјЧщИаДЪЕфашвЊЮЌЛЄЃЌЙЙНЈГЩБОНЯИпЃЌЮвУЧвВПЩвдгУЛњЦїбЇЯАЕФЗНЗЈНЋЦфПДД§ЮЊЗжРрЮЪЬтЁЃНВЙиМќДЪЬиеїЯђСПЛЏЃЌГЃгУДЪДќФЃаЭЃЈbag-of-words
ЃЉвдМАСЌајЗжВМДЪЯђСПФЃаЭЃЈword EmbeddingЃЉЃЌЬиеїЛЏКѓЃЌЭљЭљгУCNNЁЂRNNЛђепSVMЫуЗЈЁЃ
Collaborative Fitering
аЭЌЙ§ТЫ
МђГЦCFЫуЗЈЁЃаЭЌЙ§ТЫВЛЪєгкЛњЦїбЇЯАСьгђЃЌЫљвдФудкЛњЦїбЇЯАЕФЪщЩЯПДВЛЕНЃЌЫќЪєгкЪ§ОнЭкОђЁЃ
аЭЌЙ§ТЫЕФКЫаФЪЧвЛжжЩчЛсЙЄГЬЕФЫМЯыЃКШЫУЧИќЧуЯђгкЯђПкЮЖБШНЯРрЫЦЕФХѓгбФЧРяЛёЕУЭЦМіЁЃаЭЌЙ§ТЫжївЊЗжЮЊСНРрЃЌЛљгкгУЛЇЕФuser-based
CFвдМАЛљгкЮяЬхЕФitem-based CFЁЃЫфШЛаЭЌЙ§ТЫВЛЪЧЛњЦїбЇЯАЃЌЕЋЫќвВЛсгУЕНSVDОиеѓЗжНтМЦЫуЯрЫЦадЁЃ
гХЕуЪЧМђЕЅЃЌФуВЂВЛашвЊЛљгкФкШнзіФкШнЗжЮіКЭДђБъЧЉЃЌЭЦМігааТгБадЃЌПЩвдЗЂОђгУЛЇЕФЧБдкаЫШЄЕуЁЃ
аЭЌЙ§ТЫЕФШБЕуЪЧЮоЗЈНтОіРфЦєЖЏЮЪЬтЃЌаТгУЛЇУЛааЮЊЪ§ОнЃЌвВУЛгаКУгбЙиЯЕЃЌФуЪЧзюВЛЕНЭЦМіЕФЃЛЭЦМіЛсЪеЕНЯЁЪшадЕФдМЪјЃЌФуЕФааЮЊдНЖрЃЌВХЛсдНзМЃЛЫцзХЪ§ОнСПЕФдіДѓЃЌЫуЗЈЛсЪеЕНадФмЕФдМЪјЃЌВЂЧвФбвдЭиеЙЁЃ
аЭЌЙ§ТЫПЩвдКЭЦфЫћЫуЗЈЛьКЯЃЌРДЬсИпаЇЙћЁЃетвВЪЧЭЦМіЯЕЭГЕФжїСїзіЗЈЁЃ
Tagging
БъЧЉ/БъзЂ
етРяЩдЮЂгаЦчвхЁЂШчЙћЪЧБъЧЉЃЌМфНгРэНтЮЊгУЛЇЛЯёЃЌЩцМАЕНБъЧЉЯЕЭГЁЃгУЛЇЕФФаХЎЁЂадБ№ЁЂГіЩњЕиНдЪЧБъЧЉЃЌдНЗсИЛЕФБъЧЉЃЌдНФмдкЬиеїЙЄГЬжаЮЊЮвУЧЫљгУЁЃ
ШчЙћЪЧЗжРрБъЧЉ/БъзЂЃЌдђЪЧЪ§ОнБъзЂЁЃгаМрЖНбЇЯАашвЊбЕСЗМЏгаУїШЗЕФНсЙћYЃЌКмЖрЪ§ОнМЏашвЊШЫЙЄЬэМгЩЯНсЙћЁЃБШШчЭМЯёЪЖБ№ЃЌФуашвЊБъзЂЭМЯёЪєгкЪВУДЗжРрЃЌЪЧУЈЪЧЙЗЁЂЪЧФаЪЧХЎЕШЁЃдкгявєЪЖБ№ЃЌдђашвЊБъзЂЫќЖдгІЕФжаЮФКЌвхЃЌШчЙћЩцМАЕНЗНбдЃЌдђЛЙашвЊНЋЗНбдБъзЂЮЊЦеЭЈЛАЁЃ
Ъ§ОнБъзЂЪЧИіПрСІЛюЁЃ |









