| БрМЭЦМі: |
БОЮФжївЊНВНтСЫЪ§ОнПЦбЇМвЕкЮхЁЂСљЁЂЦпЬѕЯпТЗЃКздШЛгябдДІРэЁЂЪ§ОнПЩЪгЛЏЁЂДѓЪ§ОнЁЃ
БОЮФРДздЮЂаХЧиТЗЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
дкЁЖ Ъ§ОнПЦбЇМвГЩГЄжИФЯ(ЩЯ)
ЁЗжавбОНщЩмСЫЛљДЁдРэЁЂЭГМЦбЇЁЂБрГЬФмСІКЭЛњЦїбЇЯАЕФвЊЕуДѓИйЃЌНёЬьИќаТКѓајЕФЕкЮхЁЂСљЁЂЦпЬѕЯпТЗЃКздШЛгябдДІРэЁЂЪ§ОнПЩЪгЛЏЁЂДѓЪ§ОнЁЃ
зМБИКУдкаТЕФвЛФъЃЌбЇЯАГЩЮЊЮДРДЮхФъзюадИаЕФжАЮЛУДЁЃ
ЁЊЁЊЁЊЁЊЁЊЁЊ
Text Mining / NLP
ЮФБОЭкОђЃЌздШЛгябдДІРэЁЃетЪЧвЛИіКсПчШЫРрбЇЁЂгябдбЇЕФНЛВцСьгђЁЃжаЮФЕФздШЛгябдДІРэИќгаФбЖШЃЌетЪЧККгягяЗЈЬиадОіЖЈЕФЃЌгЂЮФЪЧвЛДЪЕЅДЪЮЊзюаЁдЊЫиЃЌгаПеИёЧјЗжЃЌжаЮФдђЪЧзжЃЌЧвЪЧСЌајЕФЁЃетОЭашвЊжаЮФдкЗжДЪЕФЛљДЁЩЯдйНјааздШЛгябдДІРэЁЃжаЮФЗжДЪжЪСПОіЖЈСЫКѓајКУЛЕЁЃ
Corpus
гяСЯПт
ЫќжИДѓЙцФЃЕФЕчзгЮФБОПтЃЌЫќЪЧздШЛгябдЕФЛљДЁЁЃгяСЯПтУЛгаЙЬЖЈЕФРраЭЃЌЮФЯзЁЂаЁЫЕЁЂаТЮХЖМПЩвдЪЧгяСЯЃЌжївЊШЁОігкФПЕФЁЃгяСЯПтгІИУПМТЧЖрИіЮФЬхМфЕФЦНКтЃЌМДаТЮХгІИУАќКЌИїЬтВФаТЮХЁЃ
гяСЯПтЪЧашвЊМгЙЄЕФЃЌВЛЪЧЫцБуЭјЩЯЯТдиИіtxtОЭЪЧгяСЯПтЃЌЫќБиаыДІРэЃЌАќКЌгябдбЇБъзЂЃЌДЪадБъзЂЁЂУќУћЪЕЬхЁЂОфЗЈНсЙЙЕШЁЃгЂЮФгяСЯПтБШНЯГЩЪьЃЌжаЮФгяСЯЛЙдкЗЂеЙжаЁЃ
NLTK-Data
здШЛгябдЙЄОпАќ
NLTKДДСЂгк2001ФъЃЌЭЈЙ§ВЛЖЯЗЂеЙЃЌвбОГЩЮЊзюКУЕФгЂгягябдЙЄОпАќжЎвЛЁЃФкКЌЖрИіживЊФЃПщКЭЗсИЛЕФгяСЯПтЃЌБШШчnltk.corpus
КЭ nltk.utilitiesЁЃPythonЕФNLTKКЭRЕФTMЪЧжїСїЕФгЂЮФЙЄОпАќЃЌЫќУЧвВФмгУгкжаЮФЃЌБиаыЯШЗжДЪЁЃжаЮФвВгаВЛЩйДІРэАќЃКTextRankЁЂJiebaЁЂHanLPЁЂFudanNLPЁЂNLPIRЕШЁЃ
Named Entity Recognition
УќУћЪЕЬхЪЖБ№
ЫќЪЧШЗЧаЕФУћДЪЖЬгяЃЌШчзщжЏЁЂШЫЁЂЪБМфЃЌЕиЧјЕШЕШЁЃУќУћЪЕЬхЪЖБ№дђЪЧЪЖБ№ЫљгаЮФзжжаЕФУќУћЪЕЬхЃЌЪЧздШЛгябдДІРэСьгђЕФживЊЛљДЁЙЄОпЁЃ
УќУћЪЕЬхгаСНИіашвЊЭъГЩЕФВНжшЃЌвЛЪЧШЗЖЈУќУћЪЕЬхЕФБпНчЃЌЖўЪЧШЗЖЈРраЭЁЃККзжЕФЪЕЬхЪЖБ№БШНЯРЇФбЃЌБШШчФЯОЉЪаГЄНДѓЧХЃЌЛсВњЩњФЯОЉ
| ЪаГЄ | НДѓЧХ ЁЂФЯОЉЪа | ГЄНДѓЧХ СНжжНсЙћЃЌетОЭЪЧЗжДЪЕФШЮЮёЁЃШЗЖЈРраЭдђЪЧУїШЗетИіЪЕЬхЪЧЕиЧјЁЂЪБМфЁЂЛђепЦфЫћЁЃПЩвдРэНтГЩЮФзжАцЕФЪ§ОнРраЭЁЃ
УќУћЪЕЬхжївЊгаСНРрЗНЗЈЃЌЛљгкЙцдђКЭДЪЕфЕФЗНЗЈЃЌвдМАЛљгкЛњЦїбЇЯАЕФЗНЗЈЁЃЙцдђжївЊвдДЪЕфе§ШЗЧаЗжГіЪЕЬхЃЌЛњЦїбЇЯАжївЊвдвўТэЖћПЩЗђФЃаЭЁЂзюДѓьиФЃаЭКЭЬѕМўЫцЛњгђЮЊжїЁЃ
Text Analysis
ЮФБОЗжЮі
етЪЧвЛИіБШНЯДѓЕФНЛВцСьгђЁЃвдгябдбЇбаОПЕФНЧЖШПДЃЌЮФБОЗжЮіАќРЈгяЗЈЗжЮіКЭгявхЗжЮіЃЌКѓепЯжНзЖЮНјеЙБШНЯЛКТ§ЁЃгяЗЈЗжЮівде§ШЗЙЙНЈГіЖЏДЪЁЂУћДЪЁЂНщДЪЕШзщГЩЕФгяЗЈЪїЮЊжївЊФПЕФЁЃ
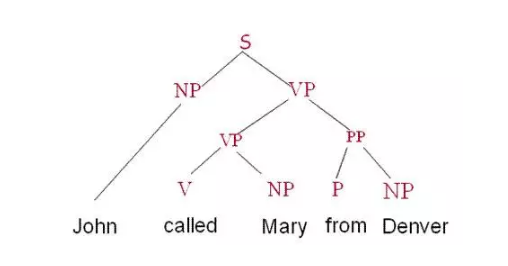
ШчЙћВЛЩюШыбаОПСьгђЁЂдђгаЮФБОЯрЫЦЖШЁЂдЄВтЕЅДЪЁЂРЇЛѓжЕЕШЗжЮіЃЌетЪЧБШНЯГЩЪьЕФгІгУЁЃ
UIMA
UIMA ЪЧвЛИігУгкЗжЮіЗЧНсЙЙЛЏФкШнЃЈБШШчЮФБОЁЂЪгЦЕКЭвєЦЕЃЉЕФзщМўМмЙЙКЭШэМўПђМмЪЕЯжЁЃетИіПђМмЕФФПЕФЪЧЮЊЗЧНсЙЙЛЏЗжЮіЬсЙЉвЛИіЭЈгУЕФЦНЬЈЃЌДгЖјЬсЙЉФмЙЛМѕЩйжиИДПЊЗЂЕФПЩжигУЗжЮізщМўЁЃ
Term Document Matrix
ДЪ-ЮФЕЕОиеѓ
ЫќЪЧвЛИіЖўЮЌОиеѓЃЌааЪЧДЪЃЌСаЪЧЮФЕЕЃЌЫќМЧТМЕФЪЧЫљвдЕЅДЪдкЫљгаЮФЕЕжаГіЯжЦЕТЪЁЃЫљвдЫќЪЧвЛИіИпЮЌЧвЯЁЪшЕФОиеѓЁЃ
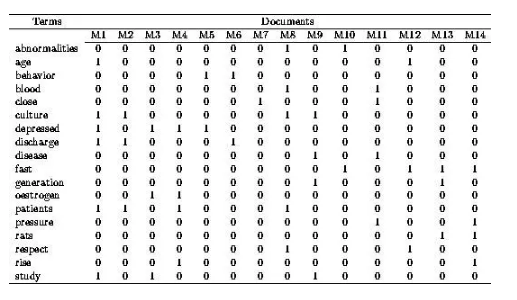
етИіОиеѓЪЧTF-IDFЃЈterm frequencyЈCinverse
document frequencyЃЉЫуЗЈЕФЛљДЁЁЃTFжИДњЕФДЪдкЮФЕЕжаГіЯжЕФЦЕТЪЃЌУшЪіЕФЪЧДЪгядкИУЮФЕЕЕФживЊЪ§ЃЌIDFЪЧФцЯђЮФМўЦЕТЪЃЌУшЪіЕФЪЧЕЅДЪдкЫљгаЮФЕЕжаЕФживЊЪ§ЁЃЮвУЧШЯЮЊЃЌдкЫљгаЮФЕЕжаЖМГіЯжЕФДЪПЯЖЈЪЧЕФЁЂФуКУЁЂЪЧВЛЪЧетРрГЃгУДЪЃЌживЊадВЛИпЃЌЖјдНЯЁЩйЕФДЪдНживЊЁЃЙЪгЩзмЮФЕЕЪ§Г§вдАќКЌИУДЪЕФЮФЕЕЪ§ЃЌШЛКѓШЁЖдЪ§ЛёЕУЁЃ
ДЪ-ЮФЕЕОиеѓПЩвдгУОиеѓЕФЗНЗЈПьЫйМЦЫуTF-IDFЁЃ
ЫќЕФБфжжаЮЪНЪЧDocument Term MatrixЃЌааСаЕпЕЙЁЃ
Term Frequency & Weight
ДЪЦЕКЭШЈжи
ДЪЦЕМДДЪгядкЮФЕЕжаГіЯжЕФДЮЪ§ЃЌетРяЕФЮФЕЕПЩвдШЯЮЊЪЧвЛЦЊаТЮХЁЂвЛЗнЮФБОЃЌЩѕжСЪЧвЛЖЮЖдЛАЁЃДЪЦЕБэЪОСЫДЪгяЕФживЊГЬЖШЃЌвЛАуетИіДЪГіЯжЕФдНЖрЃЌЮвУЧПЩвдШЯЮЊЫќдНживЊЃЌЕЋвВгаПЩФмгіЕНКмЖрЮогУДЪЃЌБШШчЕФЁЂЕиЁЂЕУЕШЁЃетаЉЪЧЭЃгУДЪЃЌгІИУЩОГ§ЁЃСэЭтвЛВПЗжЪЧШеГЃгУгяЃЌФуКУЃЌаЛаЛЃЌЖдЮФБОЗжЮіУЛгаАяжњЃЌЮЊСЫЧјЗжГіЫќУЧЃЌЮвУЧдйМгШыШЈжиЁЃ
ШЈжиДњБэСЫДЪгяЕФживЊГЬЖШЃЌЯёФуКУЁЂаЛаЛетжжЃЌЮвУЧШЯЮЊЫќЕФШЈжиЪЧКмЕЭЃЌМИКѕУЛгаШЮКЮМлжЕЁЃШЈжиМШФмШЫЙЄДђЗжЃЌвВФмЭЈЙ§МЦЫуЛёЕУЁЃЭЈГЃЃЌзЈвЕРрДЪЛуЮвУЧЛсИјгшИќИпЕФШЈжиЃЌГЃгУДЪдђЕЭШЈжиЁЃ
ЭЈЙ§ДЪЦЕКЭШЈжиЃЌЮвУЧФмЬсШЁГіДњБэетЗнЮФБОЕФЬиеїДЪЃЌОЕфЫуЗЈЮЊTF-IDFЁЃ
Support Vector Machines
жЇГжЯђСПЛњ
ЫќЪЧвЛжжЖўРрЗжРрФЃаЭЃЌгаБ№гкИажЊЛњЃЌЫќЪЧЧѓМфИєзюДѓЕФЯпадЗжРрЁЃЕБЪЙгУКЫКЏЪ§ЪБЃЌЫќвВПЩвдзїЮЊЗЧЯпадЗжРрЦїЁЃ
ЫќПЩвдЯИЗжЮЊЯпадПЩЗжжЇГжЯђСПЛњЁЂЯпаджЇГжЯђСПЛњЃЌЗЧЯпаджЇГжЯђСПЛњЁЃ
ЗЧЯпадЮЪЬтВЛЬЋКУЧѓНтЃЌЭМзѓОЭЪЧНЋЗЧЯпадЕФЬиеїПеМфгГЩфЕНаТПеМфЃЌНЋЦфзЊЛЛГЩЯпадЗжРрЁЃЫЕЕФЭЈЫзЕуЃЌОЭЪЧРћгУКЫКЏЪ§НЋзѓЭМЬиеїПеМфЃЈХЗЪНЛђРыЩЂМЏКЯЃЉЕФГЌЧњУцзЊЛЛГЩгвЭМЬиеїПеМфЃЈЯЃЖћВЎЬиПеМфЃЉжаЕФЕФГЌЦНУцЁЃ
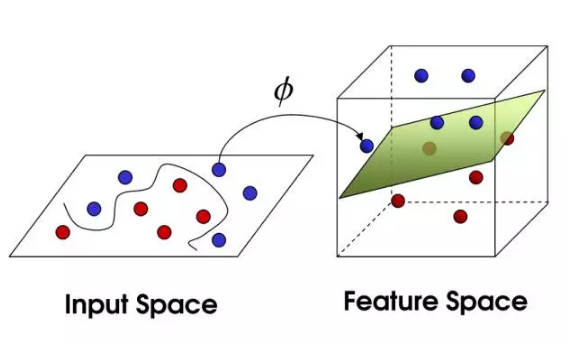
ГЃгУКЫКЏЪ§гаЖрЯюЪНКЫКЏЪ§ЃЌИпЫЙКЫКЏЪ§ЃЌзжЗћДЎКЫКЏЪ§ЁЃ
зжЗћДЎКЫКЏЪ§гУгкЮФБОЗжРрЁЂаХЯЂМьЫїЕШЃЌSVMдкИпЮЌЕФЮФБОЗжРржаБэЯжНЯКУЃЌетвВЪЧГіЯждкздШЛгябдДІРэТЗОЖЩЯЕФдвђЁЃ
Association Rules
ЙиСЊЙцдђ
ЫќгУРДЭкОђЪ§ОнБГКѓДцдкЕФаХЯЂЃЌзюжЊУћЕФР§згОЭЪЧЦЁОЦгыФђВМСЫЃЌЫфШЛЫќЪЧащЙЙЕФЁЃЕЋЮвУЧПЩвдРэНтЫќдЬКЌЕФвтЫМЃКТђСЫФђВМЕФШЫИќгаПЩФмЙКТђЦЁОЦЁЃ
ЫќЪЧаЮШчXЁњYЕФдЬКЪНЃЌЪЧвЛжжЕЅЯђЕФЙцдђЃЌМДТђСЫФђВМЕФШЫИќгаПЩФмЙКТђЦЁОЦЃЌЕЋЪЧТђСЫЦЁОЦЕФШЫЮДБиЛсТђФђВМЁЃЮвУЧдкЙцдђжав§ШыСЫжЇГжЖШКЭжУаХЖШРДНтЪЭетжжЕЅЯђЁЃжЇГжЖШБэУїетЬѕЙцдђЕФдкећЬхжаЗЂЩњЕФПЩФмадДѓаЁЃЌШчЙћТђФђВМЦЁОЦЕФШЫЩйЃЌФЧУДжЇГжЖШОЭаЁЁЃжУаХЖШБэЪОДгXЭЦЕМYЕФПЩаХЖШДѓаЁЃЌМДЪЧЗёецЕФТђСЫФђВМЕФШЫЛсТђЦЁОЦЁЃ
ЙиСЊЙцдђЕФКЫаФОЭЪЧевГіЦЕЗБЯюФПМЏЃЌAprioriЫуЗЈОЭЪЧЦфжаЕФЕфаЭЁЃЦЕЗБЯюФПМЏЪЧЭЈЙ§БщРњЕќДњЧѓНтЕФЃЌЪБМфИДдгЖШКмИпЃЌДѓаЭЪ§ОнМЏЕФБэЯжВЛКУЁЃ
ЙиСЊЙцдђКЭаЭЌЙ§ТЫвЛбљЃЌЖМЪЧЯрЫЦадЕФЧѓНтЃЌЧјЗжЪЧаЭЌЙ§ТЫевЕФЪЧЯрЫЦЕФШЫЃЌНЋШЫЛЎЗжШКЬхзіИіадЛЏЭЦМіЃЌЖјЙиСЊЙцдђУЛгаЙ§ТЫЕФИХФюЃЌЪЧеыЖдећЬхЕФЃЌгыИіШЫЦЋКУЮоЙиЃЌМЦЫуГіЕФНсЙћЪЧеыЖдЫљгаШЫЁЃ
Market Based Analysis
ЙКЮяРКЗжЮіЃЌЪЕМЪЪЧMarket Basket AnalysisЃЌзїепБЪЮѓЁЃ
ДЋЭГСуЪлвЕжаЃЌЙКЮяРКжИЕФЪЧЯћЗбепвЛДЮадЙКТђЕФЩЬЦЗЃЌЪегЊЬѕЩЯЕФЕЅзгЪ§ОнЖМЛсБЛМЧТМЯТРДвдЙЉЗжЮіЁЃИќгХауЕФЙКЮяРКЗжЮіЃЌЛЙЛсгУКьЭтЩфЦЕМЧТМЩЬЦЗЕФАкЗХЃЌЙЫПЭдкГЌЪаЕФвЦЖЏЃЌШЫСїСПЕШЪ§ОнЁЃ
ЙиСЊЙцдђЪЧЙКЮяРКЗжЮіЕФжївЊгІгУЃЌЕЋЛЙАќРЈДйЯњДђелЖдЯњЪлСПЕФгАЯьЁЂЛсдБжЦЖШЛ§ЗжжЦЖШЕФЗжЮіЁЂЛиЭЗПЭКЭаТПЭЕФЗжЮіЁЃ
Feature Extraction
ЬиеїЬсШЁ
ЫќЪЧЬиеїЙЄГЬЕФживЊИХФюЁЃЪ§ОнКЭЬиеїОіЖЈСЫЛњЦїбЇЯАЕФЩЯЯоЃЌЖјФЃаЭКЭЫуЗЈжЛЪЧБЦНќетИіЩЯЯоЖјвбЁЃЖјКмЖрФЃаЭЖМЛсгіЕНЮЌЪ§джФбЃЌМДЮЌЖШЬЋЖрЃЌетЖдадФмЦПОБдьГЩСЫПМбщЁЃГЃМћЮФБОЁЂЭМЯёЁЂЩљвєетаЉСьгђЁЃ
ЮЊСЫНтОіетвЛЮЪЬтЃЌЮвУЧашвЊНјааЬиеїЬсШЁЃЌНЋдЪМЬиеїзЊЛЛГЩзюгаживЊадЕФЬиеїЁЃЯёжИЮЦЪЖБ№ЁЂБЪМЃЪЖБ№ЃЌетаЉЖМЪЧгаЪЕЬхгаМЃПЩбЕФЃЌЖјБэЧщЪЖБ№ЕШдђЪЧБШНЯГщЯѓЕФИХФюЁЃетвВЪЧЬиеїЬсШЁЕФЬєеНЁЃ
ВЛЭЌФЃЪНЯТЕФЬиеїЬсШЁЗНЗЈВЛвЛбљЃЌЮФБОЕФЬиеїЬсШЁгаTF-IDFЁЂаХЯЂдівцЕШЃЌЯпадЬиеїЬсШЁАќРЈPCAЁЂLDAЃЌЗЧЯпадЬиеїЬсШЁАќРЈКЫKernelЁЃ
Using Mahout
ЪЙгУMahout
MahoutЪЧHadoopжаЕФЛњЦїбЇЯАЗжВМЪНПђМмЃЌжаЮФУћЧ§ЯѓШЫЁЃ
MahoutАќКЌСЫШ§ИіжїЬтЃКЭЦМіЯЕЭГЁЂОлРрКЭЗжРрЁЃЗжБ№ЖдгІВЛЭЌЕФГЁОАЁЃ
MahoutдкHadoopЦНЬЈЩЯЃЌНшжњMRМЦЫуПђМмЃЌПЩвдМђБуЛЏЕФДІРэВЛЩйЪ§ОнЭкОђШЮЮёЁЃЪЕМЪMahoutвбОВЛдйЮЌЛЄаТЕФMRЃЌЛЙЪЧЭЖЯђСЫSparkЃЌгыMlibЛЅЮЊВЙГфЁЃ
Using Weka
WekaЪЧвЛПюУтЗбЕФЃЌЛљгкJAVAЛЗОГЯТПЊдДЕФЛњЦїбЇЯАвдМАЪ§ОнЭкОђШэМўЁЃ
Using NLTK
ЪЙгУздШЛгябдЙЄОпАќ
Classify Text
ЮФБОЗжРр
НЋЮФБОМЏНјааЗжРрЃЌгыЦфЫћЗжРрЫуЗЈУЛгаБОжЪЧјБ№ЁЃМйШчЯждквЊНЋЩЬЦЗЕФЦРТлНјаае§ИКЧщИаЗжРрЃЌЪзЯШЗжДЪКѓвЊНЋЮФБОЬиеїЛЏЃЌвђЮЊЮФБОБиШЛЪЧИпЮЌЃЌЮвУЧВЛПЩФмбЁдёЫљгаЕФДЪгязїЮЊЬиеїЃЌЖјЪЧгІИУвдзюФмДњБэИУЮФБОЕФДЪзїЮЊЬиеїЃЌР§ШчжЛдке§ЧщИажаГіЯжЕФДЪЃКЬиБ№АєЃЌКмКУЃЌЭъУРЁЃМЦЫуГіПЈЗНМьбщжЕЛђаХЯЂдівцжЕЃЌгУХХУћППЧАЕФЕЅДЪзїЮЊЬиеїЁЃ
ЫљвдЦРТлЕФЮФБОЬиеїОЭЪЧ[word11,word12,ЁЁ]ЃЌ[word21,word22,ЁЁ]ЃЌзЊЛЛГЩИпЮЌЕФЯЁЪшОиеѓЃЌжЎКѓдђЪЧбЁШЁзюЪЪКЯЕФЫуЗЈСЫЁЃ
РЌЛјгЪМўЁЂЗДЛЦМјБ№ЁЂЮФеТЗжРрЕШЖМЪєгкетИігІгУЁЃ
Vocabulary Mapping
ДЪЛугГЩф
NLPгавЛИіживЊЕФИХФюЃЌБОЬхКЭЪЕЬхЃЌБОЬхЪЧвЛИіРрЃЌЪЕЬхЪЧвЛИіЪЕР§ЁЃБШШчЪжЛњОЭЪЧБОЬхЁЂiPhoneКЭаЁУзЪЧЪЕЬхЃЌЫќУЧЙВЭЌЙЙГЩСЫжЊЪЖПтЁЃКмЖрЮФзжЪЧвЛДЪЖрвтЛђепЖрДЪвЛвтЃЌБШШчЦЛЙћМШПЩвдЪЧЪжЛњвВПЩвдЪЧЫЎЙћЃЌiPhoneдђЭЌЪБгаЫЎЙћЛњЁЂЦЛЙћЛњЁЂiPhone34567ЕФжюЖрНаЗЈЁЃМЦЫуЛњЪЧЮоЗЈРэНтетУДИДдгЕФКЌвхЁЃДЪЛугГЩфОЭЪЧНЋМИИіИХФюЯрНќЕФДЪЛуЭГвЛГЩвЛИіЃЌШУМЦЫуЛњКЭШЫЕФШЯжЊУЛгаЧјБ№ЁЃ
ЁЊЁЊЁЊЁЊЁЊЁЊ
VisualizationЪ§ОнПЩЪгЛЏ
етЪЧФбЖШНЯЕЭЕФЛЗНкЃЌЭГМЦбЇЛђепДѓЪ§ОнЃЌЖМЪЧВЛЖЯЗЂеЙбнБфЃЌЪЧЪєгкжеЩэбЇЯАЕФжЊЪЖЃЌЖјПЩЪгЛЏжЛвЊСЫНтеЦЮеЃЌПЩвдЪмгУКмЖрФъЁЃетРяВЂВЛАќРЈПЩЪгЛЏЕФБрГЬЛЗНкЁЃ
Uni, Bi & Multivariate Viz
ЕЅ/ЫЋ/Жр БфСП
дкЪ§ОнПЩЪгЛЏжаЃЌЮвУЧЭЈЙ§ВЛЭЌЕФБфСПЃЏЮЌЖШзщКЯЃЌПЩвдзїГіВЛЭЌЕФПЩЪгЛЏГЩЙћЁЃЕЅБфСПЁЂЫЋБфСПКЭЖрБфСПгаВЛЭЌзїЭМЗНЪНЁЃ
ggplot2
RгябдЕФвЛИіОЕфПЩЪгЛЏАќ
ggoplot2ЕФКЫаФТпМЪЧАДЭМВузїЭМЃЌУПвЛИігяОфЖМДњБэСЫвЛИіЭМВуЁЃвдДЫНЋИїЛцЭМдЊЫиЗжРыЁЃ
ggplot(...) +
geom(...) +
stat(...) +
annotate(...) +
scale(...)
ЩЯЭМОЭЪЧЕфаЭЕФggplot2КЏЪ§ЗчИёЁЃplotЪЧећЬхЭМБэЃЌgeomЪЧЛцЭМКЏЪ§ЃЌstatЪЧЭГМЦКЏЪ§ЃЌannotateЪЧзЂЪЭКЏЪ§ЃЌscaleЪЧБъГпКЏЪ§ЁЃggplotЕФЛцЭМЗчИёЪЧЛвЕзАзИёЁЃ
ggplot2ЕФШБЕуЪЧЛцЭМБШНЯЛКТ§ЃЌБЯОЙЪЧвдЭМВуЕФЗНЪНЃЌЕЋЪЧшІВЛбкшЄЃЌЫќвРОЩЪЧКмЖрШЫЪЙгУRЕФРэгЩЁЃ
Histogram & Pie(Uni)
жБЗНЭМКЭБ§ЭМЃЈЕЅБфСПЃЉ
жБЗНЭМвбОНщЩмЙ§СЫЃЌетРяОЭЗХеХЭМЁЃ
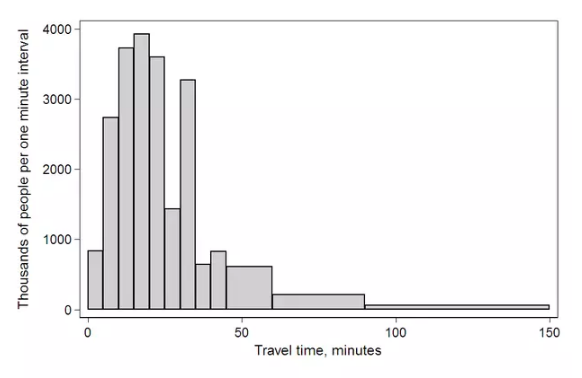
Б§ЭМВЛЪЧГЃгУЕФЭМаЮЃЌШєБфСПжЎМфЕФВюБ№ВЛДѓЃЌШч35%КЭ40%ЃЌдкБ§ЭМЕФУцЛ§БШР§ППШтблЪЧЗжБцВЛГіРДЁЃ
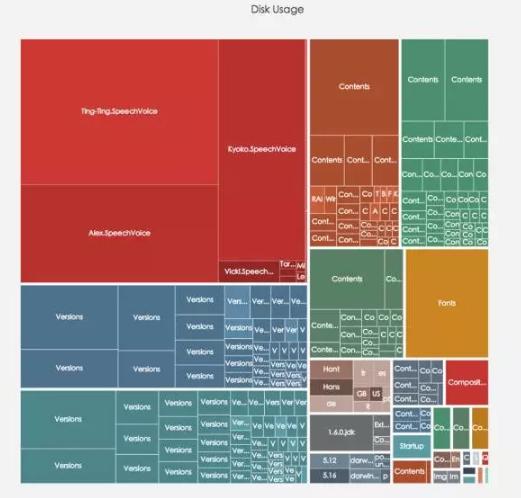
Tree & Tree Map
ЪїЭМКЭОиаЮЪїЭМ
ЪїЭМДњБэЕФЪЧвЛжжНсЙЙЁЃВуДЮОлРрЕФЪЕР§ЭМОЭЪєгкЪїЭМЁЃ
ЕБЮЌЖШЕФБфСПЖрДѓЃЌгжашвЊЖдБШЪБЃЌПЩвдЪЙгУОиаЮЪїЭМЁЃЭЈЙ§УцЛ§БэЪОБфСПЕФДѓаЁЃЌбеЩЋБэЪОРрФПЁЃ
Scatter Plot (Bi)
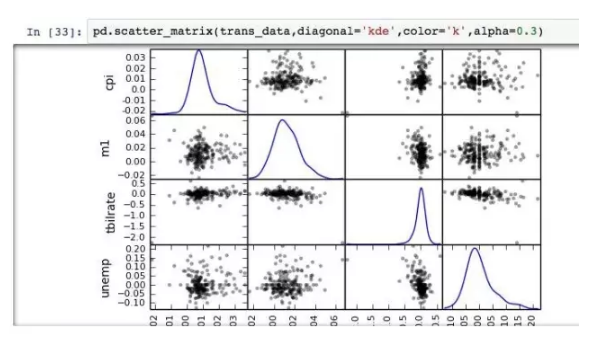
ЩЂЕуЭМЃЈЫЋБфСПЃЉ
ЩЂЕуЭМдкЪ§ОнЬНЫїжаОГЃгУЕНЃЌгУвдЗжЮіСНИіБфСПжЎМфЕФЙиЯЕЃЌвВПЩвдгУгкЛиЙщЁЂЗжРрЕФЬНЫїЁЃ
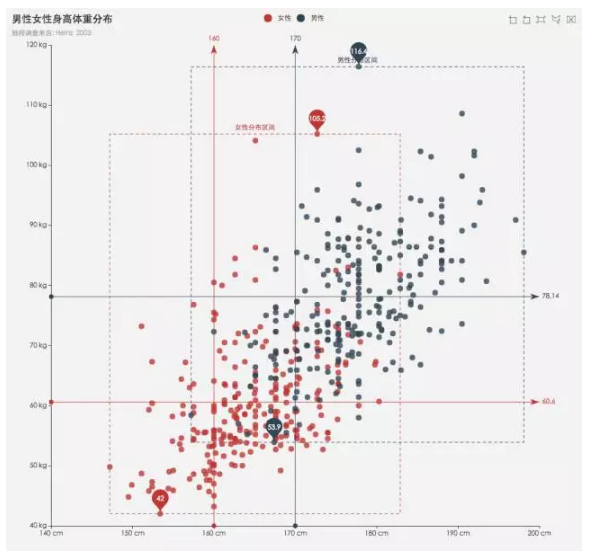
РћгУЩЂЕуЭМОиеѓЃЌдђФмНЋЫЋБфСПЭиеЙЮЊЖрБфСПЁЃ
Line Charts (Bi)
елЯпЭМЃЈЫЋБфСПЃЉ
ЫќГЃгУгкУшЛцЧїЪЦКЭБфЛЏЃЌКЭЪБМфЮЌЖШЪЧКУЛљгбЃЌШчгАЫцаЮЁЃ
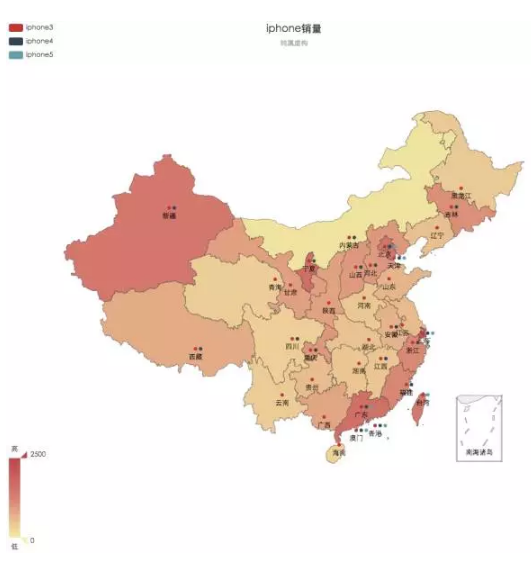
Spatial Charts
ПеМфЭМЃЌгІИУОЭЪЧЕиЭМЕФвтЫМ
вЛЧаЩцМАЕНПеМфЪєадЕФЪ§ОнЖМФмЪЙгУЕиРэЭМЁЃЕиРэЭМашвЊБэЪОзјБъЕФЪ§ОнЃЌПЩвдЪЧОЮГЖШЁЂвВПЩвдЪЧЕиРэЪЕЬхЃЌБШШчЩЯКЃЪаББОЉЪаЁЃОЮГЖШЕФЪ§ОнЃЌГЃГЃКЭPOIЙвЙГЁЃ
Survey Plot
ВЛжЊЕРОпЬхЕФКЌвхЃЌДжТдЗвыЭМаЮЬНЫї
plotЪЧRжазюГЃгУЕФКЏЪ§ЃЌЭЈЙ§plotЃЈxЃЌyЃЉЃЌЮвУЧПЩвдЩшЖЈВЛЭЌЕФВЮЪ§ЃЌОіЖЈЪЙгУФЧжжЭМаЮЁЃ
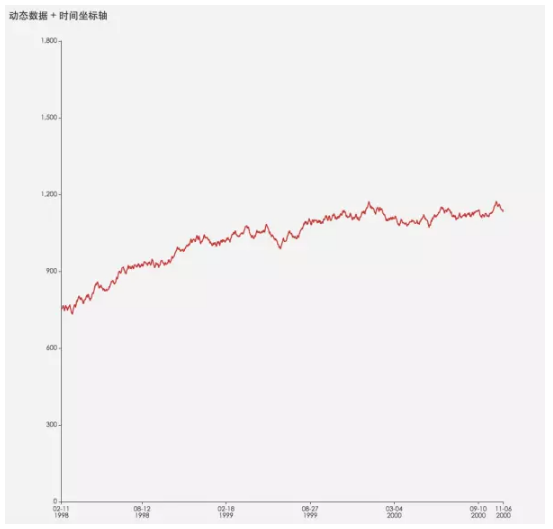
Timeline
ЪБМфжс
ЕБЪ§ОнЩцМАЕНЪБМфЃЌЛђепДцдкЯШКѓЫГађЃЌЮвУЧПЩвдЪЙгУЪБМфжсЁЃВЛЩйПЩЪгЛЏПђМмЃЌвВжЇГжвдЪБМфВЅЗХЕФаЮЪНУшЪіЪ§ОнЕФБфЛЏЁЃ

Decision Tree
ОіВпЪї
етРяЕФОіВпЪїВЛЪЧЫуЗЈЃЌЖјЪЧЛљгкНтЪЭадКУЕФвЛИігІгУЁЃ
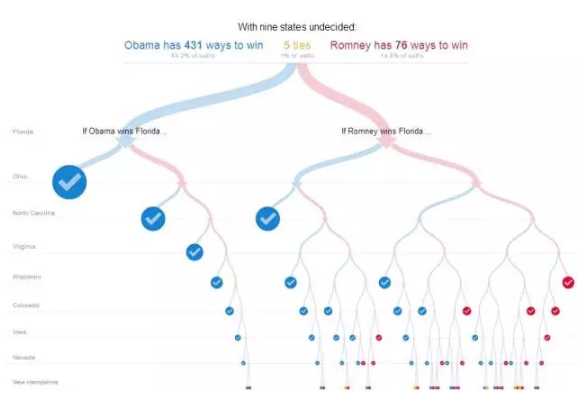
ЕБЪ§ОнгіЕНЪЧЗёЃЌЛђепбЁдёЕФТпМХаЖЯЪБЃЌОіВпЪїВЛЪЇЮЊвЛжжПЩЪгЛЏЫМТЗЁЃ
D3.js
жЊУћЕФЪ§ОнПЩЪгЛЏЧАЖЫПђМм
d3ПЩвджЦзїИДдгЕФЭМаЮЃЌЯёжБЗНЭМЩЂЕуЭМетРрЃЌгУЦфЫћПђМмЭъГЩБШНЯКУЃЌбЇЯАГЩБОБШЧАепЕЭЁЃ
d3ЪЧЛљгкsvgЕФЃЌЕБЪ§ОнСПБфДѓдЫЫуИДдгКѓЃЌd3адФмЛсБфВюЁЃЖјcanvasЕФадФмЛсКУВЛЩйЃЌЙњФкЕФechartsЛљгкКѓепЁЃгажаЮФЮФЕЕЃЌЪєгкБШНЯгбКУЕФПђМмЁЃ
RгябджагавЛИіНаd3NetWorkЕФАќЃЌPythonдђгаd3pyЕФАќЃЌЕБШЛжБНгДюНЈЛЗОГвВааЁЃ
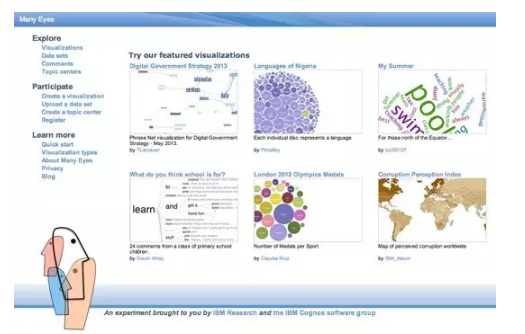
IBM ManyEyes
Many EyesЪЧIBMЙЋЫОЕФвЛПюдкЯпПЩЪгЛЏДІРэЙЄОпЁЃИУЙЄОпПЩвдЖдЪ§зжЃЌЮФБОЕШНјааПЩЪгЛЏДІРэЁЃгІИУЪЧУтЗбЕФЁЃЭМЭјЩЯЫцБуевЕФЁЃ
Tableau
ЙњЭтжЊУћЕФЩЬгУBIЃЌЗжЮЊDesktopКЭServerЃЌЧАепЪЧЪ§ОнЗжЮіЕЅЛњАцЃЌКѓепжЇГжЫНгаЛЏВПЪ№ЁЃМгЦ№РДЕУМИЧЇУРН№ЃЌЭІЙѓЕФЁЃЭМЭјЩЯЫцБуевЕФЁЃ
ЁЊЁЊЁЊЁЊЁЊЁЊ
Big Data ДѓЪ§Он
дНРДдНЛ№БЌЕФММЪѕИХФюЃЌHadoopЛЙУЛгааЫЦ№МИФъЃЌЕкЖўДњSparkвбОКѓРДОгЩЯЁЃ
вђЮЊзїепаДЕФБШНЯдчЃЌЯждкЕФаТММЪѕУЛгаЙ§ЖрЩцМАЁЃВПЗжЙЄОпЮвВЛЪьЯЄЃЌОЭТдЙ§СЫЁЃ
Map Reduce Fundamentals
MapReduceПђМм
ЫќЪЧHadoopКЫаФИХФюЁЃЫќЭЈЙ§НЋМЦЫуШЮЮёЗжИюГЩЖрИіДІРэЕЅдЊЗжЩЂЕНИїИіЗўЮёЦїНјааЁЃ
MapReduceгавЛИіКмАєЕФНтЪЭЃЌШчЙћФувЊМЦЫувЛИБХЦЕФЪ§СПЃЌДЋЭГЕФДІРэЗНЗЈЪЧеввЛИіШЫЪ§ЁЃЖјMapReduceдђЪЧевРДвЛШКШЫЃЌУПИіШЫЪ§ЦфжаЕФвЛВПЗжЃЌзюжеНЋНсЙћЛузмЁЃЗжХфИјУПИіШЫЪ§ЕФЙ§ГЬЪЧMapЃЌДІРэЛузмНсЙћЕФЙ§ГЬЪЧReduceЁЃ
Hadoop Components
HadoopзщМў
HadooКХГЦЩњЬЌЃЌЫќОЭЪЧгЩЮоЪ§зщНЈЦДНгЦ№РДЕФЁЃ
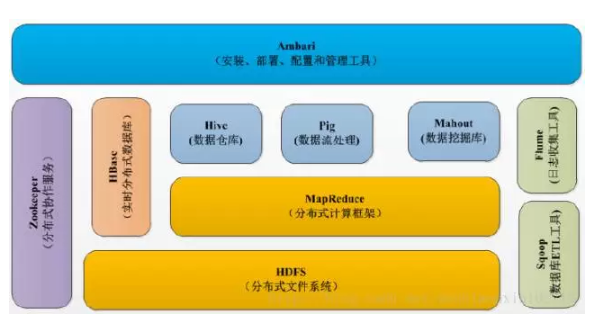
ИїРрзщМўАќРЈHDFSЁЂMapReduceЁЂHiveЁЂHBaseЁЂZookeeperЁЂSqoopЁЂPigЁЂMahoutЁЂFlumeЕШЁЃзюКЫаФЕФОЭЪЧHDFSКЭMapReduceСЫЁЃ
HDFS
HadoopЕФЗжВМЪНЮФМўЯЕЭГ
HDFSЕФЩшМЦЫМТЗЪЧвЛДЮЖСШЁЃЌЖрДЮЗУЮЪЃЌЪєгкСїЪНЪ§ОнЗУЮЪЁЃHDFSЕФЪ§ОнПщФЌШЯ64MBЃЈHadoop
2.X БфГЩСЫ128MBЃЉЃЌВЂЧввд64MBЮЊЕЅЮЛЗжИюЃЌПщЕФДѓаЁзёбФІЖћЖЈРэЁЃЫќКЭMRЯЂЯЂЯрЙиЃЌЭЈГЃРДЫЕЃЌMap
TaskЕФЪ§СПОЭЪЧПщЕФЪ§СПЁЃ64MBЕФЮФМўЮЊ1ИіMapЃЌ65MBЃЈ64MB+1MBЃЉЮЊ2ИіMapЁЃ
Data Replication Principles
Ъ§ОнИДжЦдРэ
Ъ§ОнИДжЦЪєгкЗжВМЪНМЦЫуЕФЗЖГыЃЌЫќВЂВЛНіНіОжЯогкЪ§ОнПтЁЃ
HadoopКЭЕЅИіЪ§ОнПтЯЕЭГЕФВюБ№дкгкдзгадКЭвЛжТадЁЃдкдзгадЗНУцЃЌвЊЧѓЗжВМЪНЯЕЭГЕФЫљгаВйзїдкЫљгаЯрЙиИББОЩЯвЊУДЬсНЛЃЌ
вЊУДЛиЙіЃЌ МДГ§СЫБЃжЄдгаЕФОжВПЪТЮёЕФдзгадЃЌЛЙашвЊПижЦШЋОжЪТЮёЕФдзгадЃЛ дквЛжТадЗНУцЃЌЖрИББОжЎМфашвЊБЃжЄЕЅвЛИББОвЛжТадЁЃ
HadoopЪ§ОнПщНЋЛсБЛИДжЦЕНЖрЬЌЗўЮёЦїЩЯвдШЗБЃЪ§ОнВЛЛсЖЊЪЇЁЃ
Setup Hadoop (IBM/Cloudera/HortonWorks)
АВзАHadoop
АќРЈЩчЧјАцЁЂЩЬвЕЗЂааАцЁЂвдМАИїжждЦЁЃ
Name & Data Nodes
УћГЦКЭЪ§ОнНкЕу
HDFSЭЈаХЗжЮЊСНВПЗжЃЌClientКЭNameNode &
DataNodeЁЃ
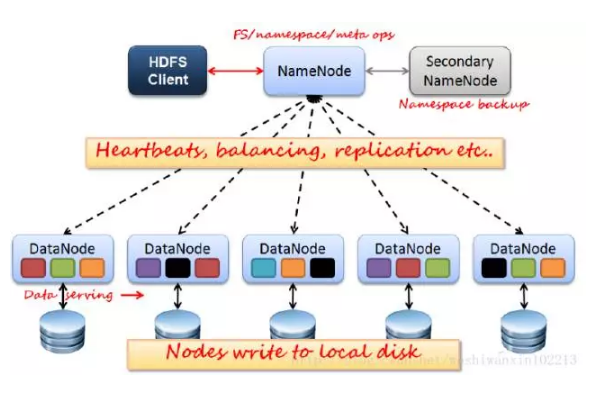
NameNodeЃКЙмРэHDFSЕФУћГЦПеМфКЭЪ§ОнПщгГЩфаХЯЂЃЌДІРэclientЁЃNameNodeгавЛИіжњЪжНаSecondary
NameNodeЃЌИКд№ОЕЯёБИЗнКЭШежОКЯВЂЃЌИКЕЃЙЄзїИКдиЁЂЬсИпШнДэадЃЌЮѓЩОЪ§ОнЕФЛАетРявВФмЛжИДЃЌЕБШЛИќНЈвщМгtrashЁЃ
DataNodeЃКеце§ЕФЪ§ОнНкЕуЃЌДцДЂЪЕМЪЕФЪ§ОнЁЃЛсКЭNameNodeжЎМфЮЌГжаФЬјЁЃ
Job & Task Tracker
ШЮЮёИњзй
JobTrackerИКд№ЙмРэЫљгазївЕЃЌНВзївЕЗжИєГЩвЛЯЕСаШЮЮёЃЌШЛЖјНВШЮЮёжИХЩИјTaskTrackerЁЃФуПЩвдАбЫќЯыЯѓГЩОРэЁЃ
TaskTrackerИКд№дЫааMapШЮЮёКЭReduceШЮЮёЃЌЕБНгЪеЕНJobTrackerШЮЮёКѓИЩЛюЁЂжДааЁЂжЎКѓЛуБЈШЮЮёзДЬЌЁЃФуПЩвдАбЫќЯыЯѓГЩдБЙЄЁЃвЛЬЈЗўЮёЦїОЭЪЧвЛИідБЙЄЁЃ
M/R Programming
Map/ReduceБрГЬ
MRЕФБрГЬвРРЕJobTrackerКЭTaskTrackerЁЃTaskTrackerЙмРэзХMapКЭReduceСНИіРрЁЃЮвУЧПЩвдАбЫќЯыЯѓГЩСНИіКЏЪ§ЁЃ
MapTaskв§ЧцЛсНЋЪ§ОнЪфШыИјГЬађдББраДКУЕФMap( )КЏЪ§ЃЌжЎКѓЪфГіЪ§ОнаДШыФкДцЃЏДХХЬЃЌReduceTaskв§ЧцНЋMap(
)КЏЪ§ЕФЪфГіЪ§ОнКЯВЂХХађКѓзїЮЊздМКЕФЪфШыЪ§ОнЃЌДЋЕнИјreduce( )ЃЌзЊЛЛГЩаТЕФЪфГіЁЃШЛКѓЛёЕУНсЙћЁЃ
ЭјТчЩЯКмЖрАИР§ЖМЭЈЙ§ЭГМЦДЪЦЕНтЪЭMRБрГЬЃК
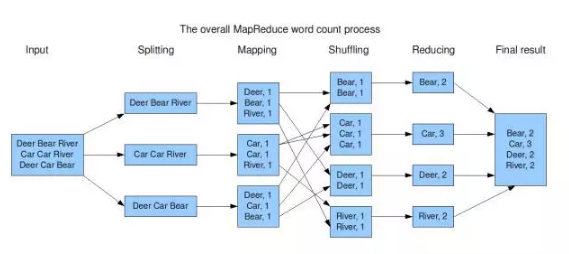
дЪМЪ§ОнМЏЗжИюКѓЃЌMapКЏЪ§ЖдЪ§ОнМЏЕФдЊЫиНјааВйзїЃЌЩњГЩМќ-жЕЖдаЮЪНжаМфНсЙћЃЌетРяОЭЪЧ{ЁАwordЁБ,counts}ЃЌReduceКЏЪ§ЖдМќ-жЕЖдаЮЪННјааМЦЫуЃЌЕУЕНзюжеЕФНсЙћЁЃ
HadoopЕФКЫаФЫМЯыЪЧMapReduceЃЌMapReduceЕФКЫаФЫМЯыЪЧshuffleЁЃshuffleдкжаМфЦ№СЫЪВУДзїгУФиЃПshuffleЕФвтЫМЪЧЯДХЦЃЌдкMRПђМмжаЃЌЫќДњБэЕФЪЧАбвЛзщЮоЙцдђЕФЪ§ОнОЁСПзЊЛЛГЩвЛзщОпгавЛЖЈЙцдђЕФЪ§ОнЁЃ
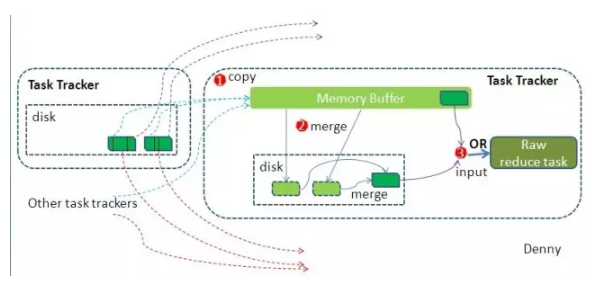
ЧАУцЫЕЙ§ЃЌmapКЏЪ§ЛсНЋНсЙћаДШыЕНФкДцЃЌШчЙћМЏШКЕФШЮЮёгаКмЖрЃЌЫ№КФЛсЗЧГЃРїКІЃЌshuffleОЭЪЧМѕЩйетжжЫ№КФЕФЁЃЭМР§жаЮвУЧПДЕНЃЌmapЪфГіСЫНсЙћЃЌДЫЪБЗХдкЛКДцжаЃЌШчЙћЛКДцВЛЙЛЃЌЛсаДШыЕНДХХЬГЩЮЊвчаДЮФМўЃЌЮЊСЫадФмПМТЧЃЌЯЕЭГЛсАбЖрИіkeyКЯВЂдквЛЦ№ЃЌРрЫЦmerge/groupЃЌЭМР§ЕФКЯВЂОЭЪЧ{"Bear",[1,1]},{"Car",[1,1,1]}ЃЌШЛКѓЧѓКЭЃЌЕШMapШЮЮёжДааЭъГЩЃЌReduceШЮЮёОЭжБНгЖСШЁЮФМўСЫЁЃ
СэЭтЃЌЫќвВЪЧдьГЩЪ§ОнЧуаБЕФдвђЃЌОЭЪЧФГвЛИіkeyЕФЪ§СПЬиБ№ЖрЃЌЕМжТШЮЮёМЦЫуКФЪБЙ§ГЄЁЃ
Sqoop: Loading Data in HDFS
SqoopЪЧвЛИіЙЄОпЃЌгУРДНЋДЋЭГЪ§ОнПтжаЕФЪ§ОнЕМШыЕНHadoopжаЁЃЫфШЛHadoopжЇГжИїжжИїбљЕФЪ§ОнЃЌЕЋЫќвРОЩашвЊКЭЭтВПЪ§ОнНјааНЛЛЅЁЃ
SqoopжЇГжЙиЯЕаЭЪ§ОнПтЃЌMySQLКЭPostgreSQLОЙ§СЫгХЛЏЁЃШчЙћвЊСЌЦфЫћЪ§ОнПтР§ШчNoSQLЃЌашвЊСэЭтЯТдиСЌНгЦїЁЃЕМШыЪБашвЊзЂвтЪ§ОнвЛжТадЁЃ
SqoopвВжЇГжЕМГіЃЌЕЋЪЧSQLгаЖржжЪ§ОнРраЭЃЌР§ШчStringЖдгІЕФCHARЃЈ64ЃЉКЭVARCHARЃЈ200ЃЉЕШЃЌБиаыШЗЖЈетИіРраЭПЩВЛПЩвдЪЙгУЁЃ
Flue, Scribe: For Unstruct Data
2жжШежОЯрЙиЕФЯЕЭГЃЌЮЊСЫДІРэЗЧНсЙЙЛЏЪ§ОнЁЃ
SQL with Pig
РћгУPigгябдРДНјааSQLВйзїЁЃ
PigЪЧвЛжжЬНЫїДѓЙцФЃЪ§ОнМЏЕФНХБОгябдЃЌPigЪЧНгНќНХБОЗНЪНШЅУшЪіMapReduceЁЃЫќКЭHiveЕФЧјБ№ЪЧЃЌPigгУНХБОгябдНтЪЭMRЃЌHiveгУSQLНтЪЭMRЁЃ
ЫќжЇГжЮвУЧЖдМгдиГіРДЕФЪ§ОнНјааХХађЁЂЙ§ТЫЁЂЧѓКЭЁЂЗжзщ(group by)ЁЂЙиСЊ(Joining)ЁЃВЂЧвжЇГжздЖЈвхКЏЪ§ЃЈUDFЃЉЃЌЫќБШHiveзюДѓЕФгХЪЦдкгкСщЛюКЭЫйЖШЁЃЕБВщбЏТпМЗЧГЃИДдгЕФЪБКђЃЌHiveЕФЫйЖШЛсКмТ§ЃЌЩѕжСЮоЗЈаДГіРДЃЌФЧУДPigОЭгагУЮфжЎЕиСЫЁЃ
DWH with Hive
РћгУHiveРДЪЕЯжЪ§ОнВжПт
HiveЬсЙЉСЫвЛжжВщбЏгябдЃЌвђЮЊДЋЭГЪ§ОнПтЕФSQLгУЛЇЧЈвЦЕНHadoopЃЌШУЫћУЧбЇЯАЕзВуЕФMR
APIЪЧВЛПЩФмЕФЃЌЫљвдHiveГіЯжСЫЃЌАяжњSQLгУЛЇУЧЭъГЩВщбЏШЮЮёЁЃ
HiveКмЪЪКЯзіЪ§ОнВжПтЃЌЫќЕФЬиадЪЪгУгкОВЬЌЃЌSQLжаЕФInsertЁЂUpdateЁЂDelЕШМЧТМВйзїВЛЪЪгУгкHiveЁЃ
ЫќЛЙгавЛИіШБЕуЃЌHiveВщбЏгабгЪБЃЌвђЮЊЫќЕУЦєЖЏMRЃЌетИіЪБМфЯћКФВЛЩйЁЃДЋЭГSQLЪ§ОнПтМђЕЅВщбЏМИУыФкОЭФмЭъГЩЃЌHiveПЩФмЛсЛЈЗбвЛЗжжгЁЃжЛгаЪ§ОнМЏзуЙЛДѓЃЌФЧУДЦєЖЏКФЗбЕФЪБМфОЭКіТдВЛМЦЁЃ
ЙЪHiveЪЪгУЕФГЁОАЪЧУПЬьСшГПХмЕБЬьЪ§ОнЕШЕШЁЃЫќЪЧРрSQLгябдЃЌЪ§ОнЗжЮіЪІФмжБНггУЃЌВњЦЗОРэФмжБНггУЃЌСрГівЛИіДѓбЇЩњХрбЕМИЬьвВФмгУЁЃаЇТЪПьЁЃ
ПЩвдНЋHiveзїЭЈгУВщбЏЃЌЖјгУPigЖЈжЦUDFЃЌзіИїжжИДдгЗжЮіЁЃHiveКЭMySQLгяЗЈзюНгНќЁЃ
Scribe, Chukwa For Weblog
ScribeЪЧFacebookПЊдДЕФШежОЪеМЏЯЕЭГЃЌдкFacebookФкВПвбОЕУЕНЕФгІгУЁЃ
ChukwaЪЧвЛИіПЊдДЕФгУгкМрПиДѓаЭЗжВМЪНЯЕЭГЕФЪ§ОнЪеМЏЯЕЭГЁЃ
Using Mahout
вбОНщЩмЙ§СЫ
Zookeeper Avro
ZookeeperЃЌЪЧHadoopЕФвЛИіживЊзщМўЃЌЫќБЛЩшМЦгУРДзіаЕїЗўЮёЕФЁЃжївЊЪЧгУРДНтОіЗжВМЪНгІгУжаОГЃгіЕНЕФвЛаЉЪ§ОнЙмРэЮЪЬтЃЌШчЃКЭГвЛУќУћЗўЮёЁЂзДЬЌЭЌВНЗўЮёЁЂМЏШКЙмРэЁЂЗжВМЪНгІгУХфжУЯюЕФЙмРэЕШЁЃ
AvroЪЧHadoopжаЕФвЛИізгЯюФПЃЌЫќЪЧвЛИіЛљгкЖўНјжЦЪ§ОнДЋЪфИпадФмЕФжаМфМўЁЃГ§ЭтЛЙгаKryoЁЂprotobufЕШЁЃ
Storm: Hadoop Realtime
StormЪЧзюаТЕФвЛИіПЊдДПђМм
ФПЕФЪЧДѓЪ§ОнСїЕФЪЕЪБДІРэЁЃЫќЕФЬиЕуЪЧСїЃЌHadoopЕФЪ§ОнВщбЏЃЌгХЛЏЕФдйКУЃЌвВвЊЛљгкHDFSНјааMRВщбЏЃЌгаУЛгаИќПьЕФЗНЗЈФиЃПЪЧгаЕФЁЃОЭЪЧдкЪ§ОнВњЩњЪБОЭШЅМрПиШежОЃЌШЛКѓТэЩЯНјааМЦЫуЁЃБШШчвГУцЗУЮЪЃЌгаШЫЕуЛївЛЯТЃЌЮвМЦЫуОЭ+1ЃЌдйгаШЫЕуЃЌ+1ЁЃФЧУДетИівГУцЕФUVЮввВОЭФмЪЕЪБжЊЕРСЫЁЃ
HadoopЩУГЄХњДІРэЃЌЖјStormдђЪЧСїЪНДІРэЃЌЭЬЭТПЯЖЈЪЧHadoopгХЃЌЖјЪБбгПЯЖЈЪЧStormКУЁЃ
Rhadoop, RHipe
НЋRКЭhadoopНсКЯЦ№РД2жжМмЙЙЁЃ
RHadoopАќКЌШ§ИіАќЃЈrmrЃЌrhdfsЃЌrhbaseЃЉЃЌЗжБ№ЖдгІMapReduceЃЌHDFSЃЌHBaseШ§ИіВПЗжЁЃ
SparkЛЙгаИіНаSparkRЕФЁЃ
rmr
RHadoopЕФвЛИіАќЃЌКЭhadoopЕФMapReduceЯрЙиЁЃ
СэЭтHadoopЕФЩОГ§УќСювВНаrmrЃЌВЛжЊЕРзїепЪЧВЛЪЧжИДњЕФетИіЁЁ
Classandra
вЛжжСїааЕФNoSqlЪ§ОнПт
ЮвУЧГЃГЃЫЕCassandraЪЧвЛИіУцЯђСаЃЈColumn-OrientedЃЉЕФЪ§ОнПтЃЌЦфЪЕетВЛЭъШЋЖдЁЊЁЊЪ§ОнЪЧвдЫЩЩЂНсЙЙЕФЖрЮЌЙўЯЃБэДцДЂдкЪ§ОнПтжаЃЛЫљЮНЫЩЩЂНсЙЙЃЌЪЧжИУПааЪ§ОнПЩвдгаВЛЭЌЕФСаНсЙЙЃЌЖјдкЙиЯЕаЭЪ§ОнжаЃЌЭЌвЛеХБэЕФЫљгаааБиаыгаЯрЭЌЕФСаЁЃдкCassandraжаПЩвдЪЙгУвЛИіЮЈвЛЪЖБ№КХЗУЮЪааЃЌЫљвдЮвУЧПЩвдИќКУРэНтЮЊЃЌCassandraЪЧвЛИіДјЫїв§ЕФЃЌУцЯђааЕФДцДЂЁЃ
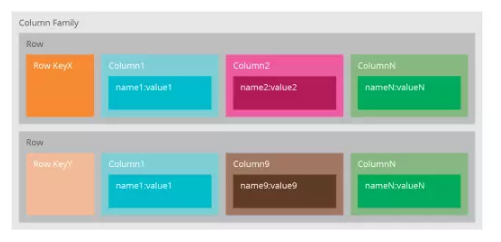
CassandraжЛашвЊФуЖЈвхвЛИіТпМЩЯЕФШнЦїЃЈKeyspacesЃЉзАдиСазхЃЈColumn
FamiliesЃЉЁЃ
CassandraЪЪКЯПьЫйПЊЗЂЁЂСщЛюВПЪ№МАЭиеЙЁЂжЇГжИпIOЁЃЫќКЭHBaseЛЅЮЊОКељЖдЪжЃЌCassandra+Spark
vs HBase+HadoopЃЌCassandraЧПЕїAP ЃЌHbaseЧПЕїCPЁЃ
MongoDB, Neo4j
MongoDBЪЧЮФЕЕаЭNoSQLЪ§ОнПтЁЃ
MongoDBШчЙћВЛЩцМАJoinЃЌЛсЗЧГЃСщЛюКЭгХЪЦЁЃОйвЛИіЮвУЧзюГЃМћЕФЕчзгЩЬЮёЭјеОзїР§згЃЌВЛЭЌЕФВњЦЗРрФПЃЌВњЦЗЙцЗЖЁЂЫЕУїКЭНщЩмЖМВЛвЛбљЃЌЕчзгВњЦЗФђВМСуЪГЪжЛњПЈЕШЕШЃЌдкЙиЯЕаЭЪ§ОнПтжаЩшМЦБэНсЙЙЪЧджФбЃЌЕЋЪЧдкMongoDBжаОЭФмздЖЈвхЭиеЙЁЃ
дйЗХвЛеХКЭЙиЯЕаЭЪ§ОнПтЖдБШЕФембЇЭМАЩЃК
Neo4jЪЧзюСїааЕФЭМаЮЪ§ОнПтЁЃ
ЭМаЮЪ§ОнПтШчЦфУћзжЃЌдЪаэЪ§ОнвдНкЕуЕФаЮЪНЃЌгІгУЭМаЮРэТлДцДЂЪЕЬхжЎМфЕФЙиЯЕаХЯЂЁЃ
зюГЃМћЕФГЁОАЪЧЩчНЛЙиЯЕСДЁЂЗВЪЧвЕЮёТпМКЭЙиЯЕДјЕуБпЕФЖМФмгУЭМаЮЪ§ОнПтЁЃ
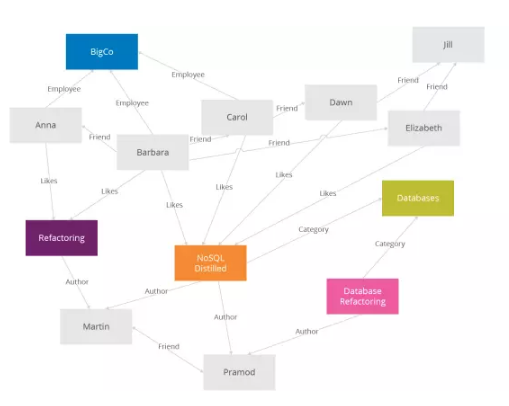
ИњЙиЯЕЪ§ОнПтЯрБШЃЌЭМаЮЪ§ОнПтзюжївЊЕФгХЕуЪЧНтОіСЫЭММЦЫу(вЕЮёТпМ)дкЙиЯЕЪ§ОнПтЩЯДѓСПЕФjoinВйзїЃЌБШШчШУФуВщбЏЃКФуТшТшЕФНуНуЕФОЫОЫЕФХЎЖљЕФУУУУЪЧЫЃПетЕУаДМИИіJoinАЁЁЃЕЋЗВЙиЯЕЃЌjoinВйзїЕФДњМлЪЧОоДѓЕФЃЌЖјGraphDBФмКмПьЕиИјГіНсЙћЁЃ |









