| 编辑推荐: |
本文主要介绍了CLAUDE.md
的拆解:Agent 进仓库前的上下文入口相关内容 。希望对你的学习有帮助。
本文来自于微信公众号架构师,由火龙果软件Alice编辑,推荐。 |
|
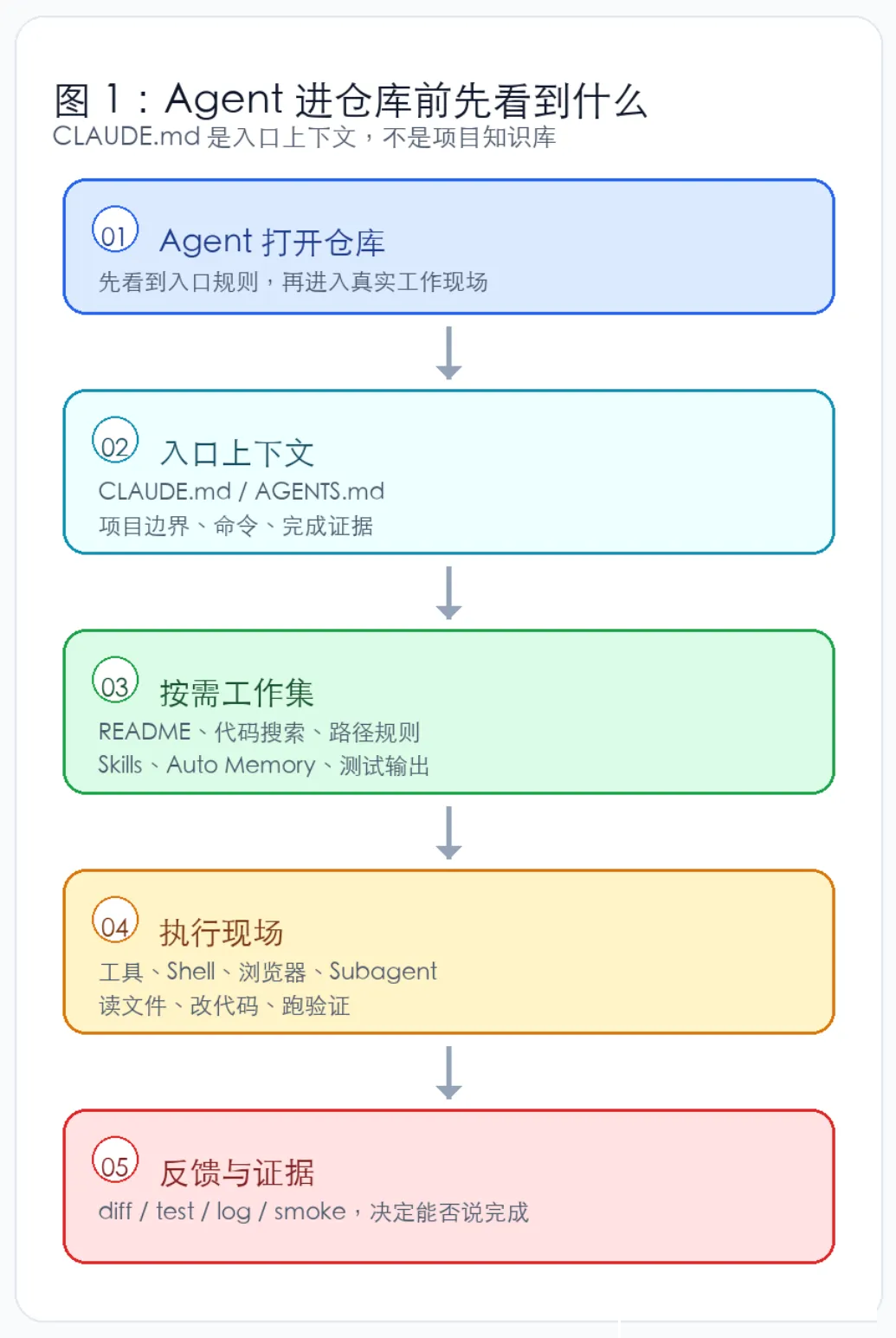
一个新会话打开仓库时,Agent 第一眼看到什么,后面很多偏差已经埋下了。
它可能先扫 README,也可能先搜文件、跑命令、读测试。放到 Claude
Code 里,还有一类信息会更早进入它的视野:CLAUDE.md、记忆、局部规则,以及随后按需加载的
Skills、Hooks、工具反馈。
这个细节看起来很小。放到真实项目里,很多偏差都从这里开始:Agent
猜技术栈,猜测试命令,猜目录边界,猜什么叫完成。它通常会带着一套“看起来合理”的默认经验往前跑。
我更愿意把 CLAUDE.md 放回这条链路里看。
它不像一份更长的项目说明,也不像给模型贴一张“听话纸条”。它更接近
Agent 进仓库前的第一眼上下文:先告诉它这个项目里哪些东西最容易被猜错,哪些边界一旦越过去会有成本,哪些结果需要证据才能算数。
一个好的 CLAUDE.md,可以省很多事情::《Claude
Code 错误率从 41% 到 3%:CLAUDE.md 到底改对了什么?》
先说结论
• CLAUDE.md 的价值在于启动时注入 少量关键上下文,不在于把项目写成百科。
• 好的入口规则通常来自真实失败:错误假设、过度复杂、无关改动、缺少验证。
• AGENTS.md 更适合做跨工具公共规则,CLAUDE.md
可以导入它,再补 Claude Code 专属约定。
• .claude/rules/、Auto Memory、Skills、Hooks
解决的是不同问题,混在一个文件里会增加维护成本。
• CLAUDE.md 是软约束。涉及权限、密钥、发布、测试
gate 这类风险时,还需要 Hook、权限配置、CI 或脚本 兜住。
• 我的理解是:入口文件最有用的地方,是减少
Agent 启动时的错误假设。
问题变了
这波关于 CLAUDE.md、AGENTS.md 的讨论,表面上像是大家又发现了一个新模板。往深一点看,它对应的是
Coding Agent 进入真实仓库后的几类老问题。
Karpathy 之前在网上聊 LLM 写代码时,提到过几个很有共鸣的现象:模型会替人做假设,然后沿着假设一路写下去;会把本来很小的改动做复杂;也会碰一些和当前任务无关的代码。社区里后来有人把这类观察整理成
CLAUDE.md 风格的规则,比如先思考再编码、保持简单、只做外科手术式改动、围绕目标验证。
这类规则吸引人的地方,不在“像不像 Karpathy 写的”。关键是它命中了
Agent 的高频失败模式。
Addy Osmani 最近写 Harness Engineering
时,把 CLAUDE.md、AGENTS.md、Skills、Subagent 指令、Hooks、日志和成本观测都放进同一个运行底座里看。这个视角对我有帮助:模型能力当然重要,但模型外面的上下文、工具、权限、反馈和可观测性,同样决定
Agent 最终表现。
Simon Willison 则提醒了另一个容易被忽略的点:让代码库更适合
Agent,并不一定靠更多文档。好的测试、lint、类型检查、清晰错误信息、可启动的本地服务,对 Agent
也很关键。
早些时候整理 Claude Code 工作流时,我更多把 CLAUDE.md
看成“把纠错写成规则”的地方:Claude 犯过的错、review 里反复出现的边界、PR 后留下的
notes,都可以沉到入口规则里,或者被入口文件引用起来。
那条线讲的是规则怎么沉淀。这里再往前挪一步:规则沉淀之后,下一次新会话最先看到什么。
这也接上今年一直在《架构师》里梳理的那条线:上下文按工作集来管理;Skills
更接近过程资产;Harness 是模型外面的工作现场;Loop 关心反馈、状态和停止条件。
CLAUDE.md 放在这条线里,位置很靠前。
它管的是 Agent 进仓库的第一眼:先看到什么边界,先记住哪些命令,先知道哪些事不能靠猜。
把这几条线放在一起,CLAUDE.md 的位置就清楚一些了。
它只是规则层的入口。
图 1:Agent 进仓库前先看到什么
入口先看
讨论 CLAUDE.md,加载机制要先摆清楚。
在 Claude Code 里,CLAUDE.md 是会话启动时读取的持久指令。它可以放在用户级、项目级、本地私有级,也可以出现在子目录里。靠近当前工作目录的规则会排在后面,语义上也更贴近当前任务。
几个细节会直接影响写法:
• 根目录和当前路径上的 CLAUDE.md 会在启动时进入上下文;
• 子目录里的 CLAUDE.md,通常在 Claude 读取对应目录文件时再进入上下文;
• @path 导入文件很方便,但导入内容同样会在启动时展开并占用上下文;
• 官方建议单个 CLAUDE.md 控制在 200 行以内,原因很朴素:文件越长,越占窗口,关键规则也越容易被稀释;
• .claude/rules/ 可以按路径触发,适合把局部约定从入口文件里拆出去;
• Auto Memory 的 MEMORY.md 启动时只加载前
200 行或 25KB,两者取较小值,细节文件按需读取。
这是我重新理解 CLAUDE.md 时最在意的地方:它会消耗上下文预算。
写得太长,就像把所有项目知识都堵在门口;写得准一点,才像一张入场卡。
再放到跨工具环境里看,AGENTS.md 也在承担类似角色。Codex
会在开始工作前读取 AGENTS.md,并按全局、项目、子目录层级合并;AGENTS.md 官方站也把它定位成给
coding agents 使用的开放指令格式。
两者的关系可以先简单理解成:
• AGENTS.md 更适合做项目级公共规则;
• CLAUDE.md 更适合承接 Claude Code 的加载机制和专属习惯;
• 两边共享的部分尽量保持一份来源,避免同一个项目在不同 Agent
眼里变成两套边界。
两条路线不一样,但有一个共同问题:
Agent 进仓库前,到底先知道哪些事?
CLAUDE.md 回答的就是这个问题。它把少量高频、稳定、容易误判的信息提前放到入口处:
• 这个仓库做什么,也不做什么;
• 常用构建、测试、lint 命令是什么;
• 代码分层和目录边界在哪里;
• 哪些文件或配置需要格外谨慎;
• 什么证据可以支撑“完成”这个说法。
这些信息如果不提前出现,模型会自己补。
模型补出来的内容,有时也能用。工程里更麻烦的经常是“差一点对”:差一点对的技术栈、差一点对的测试命令、差一点对的完成口径,后面都会变成返工。
执行看 CLAUDE
很多文章会把 CLAUDE.md 解释成“给 Claude 看的
README”。这个说法方便入门,也容易把文件写宽。
README 关心的是人怎么理解项目。它可以讲愿景、背景、模块、部署、贡献流程。
CLAUDE.md 更贴近执行过程。它关心的是 Agent 进入项目后,哪些可预见的偏差可以提前收住。
我会用一个很朴素的筛选标准:
删掉这一行,Agent 下次会不会更容易犯同类错误?
比如下面这些内容,就值得进入入口文件:
- Backend uses Spring Boot 4 and Java 21.
- API handlers only validate input and shape responses.
- Services own business orchestration and transactions.
- External HTTP and LLM calls must stay outside DB transactions.
- Separate code changes, local checks, and production evidence in summaries.
|
这些信息足够具体。版本会影响生成写法,分层边界会影响改动范围,事务内调用外部服务会带来真实故障,生产证据和本地测试混在一起会误导团队。
反过来,这类句子就比较弱:
- Write clean code.
- Follow best practices.
- Keep the project organized.
- Be careful with security.
|
这些话没错,只是不够具体。Agent 看完以后,仍然不知道下一步该多查哪个文件、少碰哪个目录、在哪个检查失败后停下来。
三层规则
更容易失控的,是把所有东西都往 CLAUDE.md 里放。
一开始 30 行。Agent 犯一次错,加一条。Code review
发现一次问题,加一条。几周以后变成 300 行,再加上 IMPORTANT、加粗、大写,大家心里才稍微踏实一点。
我自己的经验是,问题通常出在分层没拆开。
更稳的做法,是把规则分成三类。
| 层次 |
放什么 |
解决什么问题 |
| 入口规则 |
AGENTS.md
、CLAUDE.md |
Agent 第一眼需要知道的项目边界 |
| 按需规则 |
.claude/rules/
、docs、Skills、Auto Memory |
只在特定目录、任务或流程里需要的细节 |
| 硬门禁 |
Hooks、permissions、CI、linter、脚本 |
不能只靠模型自觉的风险 |
图 2:三层规则怎么分工
AGENTS.md 和 CLAUDE.md 的关系,放在这里会更好理解。
OpenAI Codex 会在工作前读取 AGENTS.md。AGENTS.md
官方站也把它定义成面向 coding agents 的开放指令格式。Claude Code 官方文档说得更具体:Claude
Code 读的是 CLAUDE.md;如果仓库已经有 AGENTS.md,可以在 CLAUDE.md
里用 @AGENTS.md 导入,保持一份公共规则。
一个比较干净的写法是:
@AGENTS.md
## Claude Code
- Use plan mode for changes under `src/billing/`.
- Run `/memory` when
project instructions appear missing after compaction.
|
公共规则只有一份,Claude 专属规则单独补。这样不容易出现两个
Agent 看到两套项目边界的情况。
.claude/rules/、Auto Memory、Skills
则更适合处理局部知识。
API 目录的约定,只在相关任务里读;复杂验证流程,按需加载更省窗口;某次协作里学到的本机调试经验,更适合进
Auto Memory,没必要写成团队共享规则。
硬风险硬挡
CLAUDE.md 还有一个常见用法,是把它写成权限系统:
- Never modify `.env`.
- Never touch production config.
- Always run tests before commit.
|
这些话可以提醒模型,但它们承受不了事故成本。
Claude Code 官方文档里有个关键边界:CLAUDE.md
是上下文,强制能力有限。Claude 会读,也会尽量遵守,但它承担不了系统级拦截。官方也把阻断动作放到了
PreToolUse Hook、权限配置、管理设置这类更硬的机制里。
所以我会这样分工:
• 密钥文件和生产配置,用权限 deny、Hook 或仓库保护拦住;
• 保存后格式化,用 PostToolUse Hook、编辑器配置或
CI 接住;
• 迁移文件、API 契约、生成代码,用 review gate
或检查脚本标出来;
• 发布前 smoke、测试结果、线上证据,用 release
script 或 checklist 留痕。
自然语言适合讲意图、背景和边界。机器门禁更适合承担“漏一次就出事故”的事情。
这也是 Harness 工程里很重要的一点:模型外面的系统,要把反馈和拦截做成确定性机制。
第一版要短
如果今天给一个真实项目补第一版 CLAUDE.md,我不会从模板仓库里复制一大段。
我会先写成一张 60 行以内的入口卡。
# Project Agent Entry
## What this repo is
One short paragraph. Say what the system does and what it does not do.
## Commands
- Build: `...`
- Test: `...`
- Lint: `...`
## Architecture boundaries
- API handlers validate input and shape responses.
- Services own orchestration and transactions.
- Repositories only access data.
## Before changing scope
- Ask before expanding the change outside the requested module.
- Ask before changing public API contracts.
- Stop if the same check fails twice with the same error.
## Verification
- Do not call work complete without command output, test result, diff evidence, or live smoke.
- Separate code changed, local checks, and production evidence in summaries.
|
第一版只解决入口问题。
架构长文放 docs/,目录规则放 .claude/rules/,重复验证流程做成
Skill,强制拦截动作放 Hook。入口文件越短,关键规则越容易被模型和人同时看到。
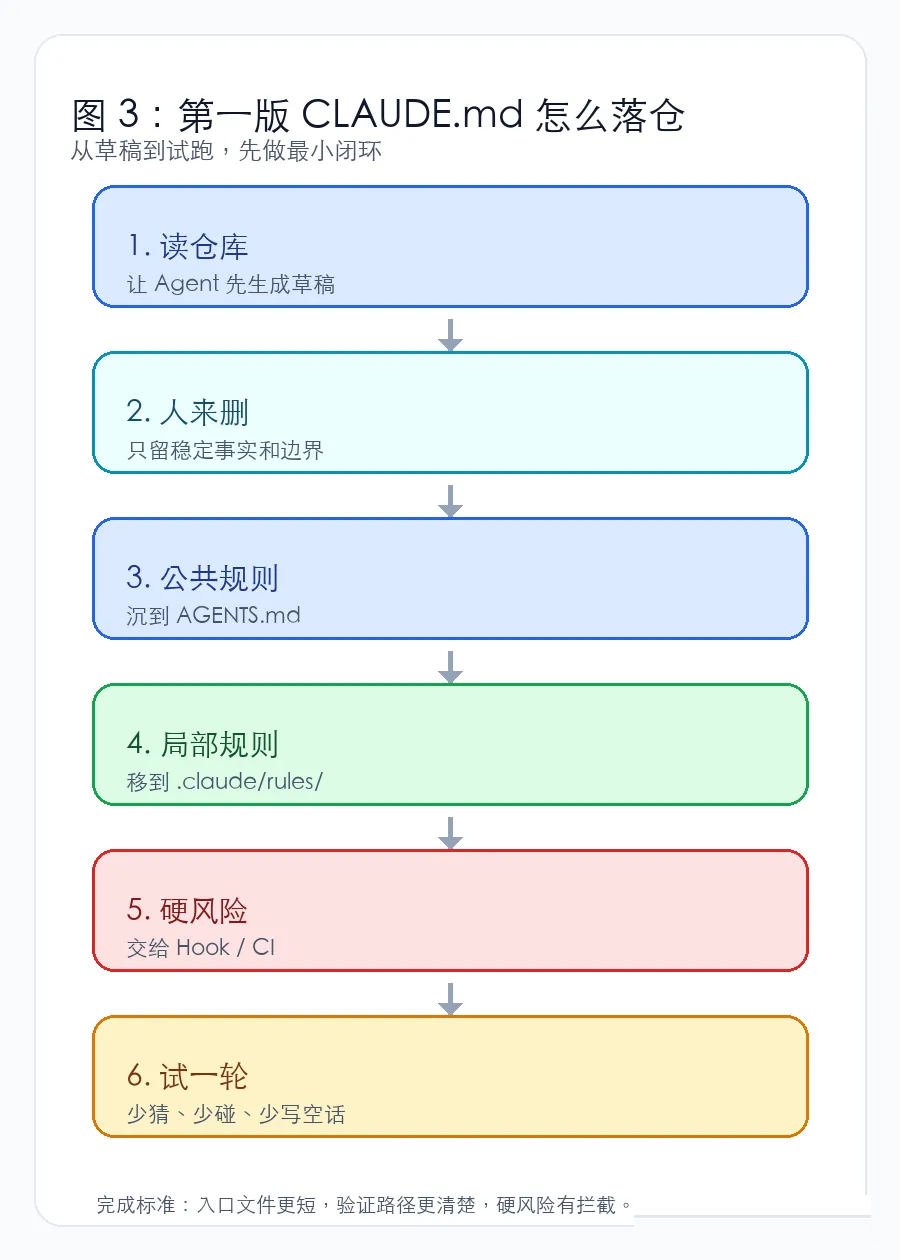
落到仓库里,可以按一个很小的顺序推进:
1. 先让 Agent 读仓库,生成一版草稿;
2. 人来删,只留下版本、命令、边界、验证这几类稳定信息;
3. 把公共规则沉到 AGENTS.md,Claude 专属内容留在
CLAUDE.md;
4. 把目录级规则移到 .claude/rules/;
5. 把高风险动作交给 Hook、权限或 CI;
6. 用一次真实任务试跑,看它是否少猜了一步、少碰了一个无关文件、少写了一句没有证据的完成总结。
图 3:第一版 CLAUDE.md 怎么落仓
如果这六步跑完,文件还是很长,大概率是它混进了太多“知识库内容”。入口文件只负责开场,后面的上下文可以让
Agent 自己读。
我会特别留意三类内容:
• 蓝色这一层:启动就该知道的项目事实,比如命令、版本、边界;
• 绿色这一层:能被验证的完成证据,比如测试、diff、日志、smoke;
• 红色这一层:漏一次就会出事故的动作,比如密钥、生产配置、发布权限。
蓝色可以进 CLAUDE.md。绿色最好有脚本或 checklist。红色尽量交给
Hook、权限和 CI。
维护靠错误
CLAUDE.md 创建起来不难,三个月后还干净才难。
我会用一个很简单的节奏维护。
第一,从真实错误里加规则。
Agent 第二次犯同类错,或者 code review 发现它本该知道某个项目边界,再写进去。还没有发生过的担心,先放在观察里。
如果背后有复盘、PR 记录或排障日志,我更倾向于让 CLAUDE.md
指向 notes 或 docs。入口文件留下规则,证据和上下文放到它能找到的地方。
第二,每条规则尽量写成可检查的行为。
“注意边界”不如“改动超出 src/auth/ 前先说明原因”。
“测试充分”不如“修 bug 先补一个能复现失败的测试,再让它通过”。
第三,定期删。
一条规则已经被 linter、CI、Hook 接管,就从入口文件里移走,或者只留一行指向。
只适用于某个目录,就挪到路径规则。只属于本机调试经验,就交给 Auto
Memory。只在某个复杂流程里有用,就做成 Skill。
维护入口文件,有点像维护一个轻量控制面。它不追求全,追求每次启动都能把
Agent 带到正确的工作轨道上。
最后
我现在对 CLAUDE.md 的看法,比前阵子更克制。
它承担不了万能文件的角色。写得再长,也不能替代测试、权限、Hook、CI、review、运行日志和线上证据。
但它确实很关键。
因为 Agent 每次进仓库,都需要一个起点。这个起点如果只有 README,它看到的是人类理解项目的入口;如果再加上一份干净的
CLAUDE.md 或 AGENTS.md,它看到的就是执行过程里的项目边界。
这也能接上我们长期讨论的 Harness、Loop、Skills 和上下文工作集。
Agent 能不能把活做稳,不只看模型有多强,也看项目把多少经验沉进了
可读取、可验证、可回滚 的工程结构里。
CLAUDE.md 只是其中很小的一层。
但在新会话打开仓库的那一刻,这一层会先被看见。 | 






 订阅
订阅