| 编辑推荐: |
本文主要介绍了AIGC核心技术与原理
、AIGC典型应用场景 及AIGC落地产品形态等相关知识。希望对你的学习有帮助。
本文来自于知乎,由火龙果软件Linda编辑,推荐。 |
|
一、简介
近期,短视频平台上火爆的“AI绘画”,在各大科技平台上刷屏的智能聊天软件ChatGPT,引起了人们广泛关注。人工智能潜力再次被证明,而这两个概念均来自同一个领域:AIGC。AIGC到底是什么?为什么如此引人关注?AIGC能产生什么样的应用价值?
本文将重点关注三个方面:
1、AIGC核心技术与原理 2、AIGC典型应用场景 3、AIGC落地产品形态
二、AIGC是什么?
AIGC全称为AI-Generated Content,直译:人工智能内容生成。即采用人工智能技术来自动生产内容。那么,AIGC采用了什么人工智能技术?可生成什么内容?
对以上两个问题进行回答,首先,从技术层面AIGC可分为三个层次,分别为:
1、智能数字内容孪生:
简单的说,将数字内容从一个维度映射到另一个维度。与生成有什么关系呢?因为另一个维度内容不存在所以需要生成。内容孪生主要分为内容的增强与转译。增强即对数字内容修复、去噪、细节增强等。转译即对数字内容转换如翻译等。
该技术旨在将现实世界中的内容进行智能增强与智能转译,更好的完成现实世界到数字世界映射。例如,我们拍摄了一张低分辨率的图片,通过智能增强中的图像超分可对低分辨率进行放大,同时增强图像的细节信息,生成高清图。再比如,对于老照片中的像素缺失部分,可通过智能增强技术进行内容复原。而智能转译则更关注不同模态之间的相互转换。比如,我们录制了一段音频,可通过智能转译技术自动生成字幕;再比如,我们输入了一段文字,可以自动生成语音,两个例子均为模态间智能转译应用。
【应用】:图像超分、语音转字幕、文字转语音等。
2、智能数字内容编辑:
智能数字内容编辑通过对内容的理解以及属性控制,进而实现对内容的修改。如在计算机视觉领域,通过对视频内容的理解实现不同场景视频片段的剪辑。通过人体部位检测以及目标衣服的变形控制与截断处理,将目标衣服覆盖至人体部位,实现虚拟试衣。在语音信号处理领域,通过对音频信号分析,实现人声与背景声分离。以上三个例子均在理解数字内容的基础上对内容的编辑与控制。
【应用】:视频场景剪辑、虚拟试衣、人声分离等。
3、智能数字内容生成:
智能数字内容生成通过从海量数据中学习抽象概念,并通过概念的组合生成全新的内容。如AI绘画,从海量绘画中学习作品不同笔法、内容、艺术风格,并基于学习内容重新生成特定风格的绘画。采用此方式,人工智能在文本创作、音乐创作和诗词创作中取得了不错表现。再比如,在跨模态领域,通过输入文本输出特定风格与属性的图像,不仅能够描述图像中主体的数量、形状、颜色等属性信息,而且能够描述主体的行为、动作以及主体之间的关系。
【应用】:图像生成(AI绘画)、文本生成(AI写作、ChatBot)、视频生成、多模态生成等。
从生成内容层面AIGC可分为五个方面:
1、文本生成
基于NLP的文本内容生成根据使用场景可分为非交互式与交互式文本生成。非交互式文本生成包括摘要/标题生成、文本风格迁移、文章生成、图像生成文本等。交互式文本生成主要包括聊天机器人、文本交互游戏等。
【代表性产品或模型】:JasperAI、copy.AI、ChatGPT、Bard、AI dungeon等。
2、图像生成
图像生成根据使用场可分为图像编辑修改与图像自主生成。图像编辑修改可应用于图像超分、图像修复、人脸替换、图像去水印、图像背景去除等。图像自主生成包括端到端的生成,如真实图像生成卡通图像、参照图像生成绘画图像、真实图像生成素描图像、文本生成图像等。
【代表性产品或模型】:EditGAN,Deepfake,DALL-E、MidJourney、Stable
Diffusion,文心一格等。
3、音频生成
音频生成技术较为成熟,在C端产品中也较为常见,如语音克隆,将人声1替换为人声2。还可应用于文本生成特定场景语音,如数字人播报、语音客服等。此外,可基于文本描述、图片内容理解生成场景化音频、乐曲等。
【代表性产品或模型】:DeepMusic、WaveNet、Deep Voice、MusicAutoBot等。
4、视频生成
视频生成与图像生成在原理上相似,主要分为视频编辑与视频自主生成。视频编辑可应用于视频超分(视频画质增强)、视频修复(老电影上色、画质修复)、视频画面剪辑(识别画面内容,自动场景剪辑)。视频自主生成可应用于图像生成视频(给定参照图像,生成一段运动视频)、文本生成视频(给定一段描述性文字,生成内容相符视频)。
【代表性产品或模型】:Deepfake,videoGPT,Gliacloud、Make-A-Video、Imagen
video等。
5、多模态生成
以上四种模态可以进行组合搭配,进行模态间转换生成。如文本生成图像(AI绘画、根据prompt提示语生成特定风格图像)、文本生成音频(AI作曲、根据prompt提示语生成特定场景音频)、文本生成视频(AI视频制作、根据一段描述性文本生成语义内容相符视频片段)、图像生成文本(根据图像生成标题、根据图像生成故事)、图像生成视频。
【代表性产品或模型】:DALL-E、MidJourney、Stable Diffusion等。
三、AIGC的核心技术有哪些?
1、基础模型
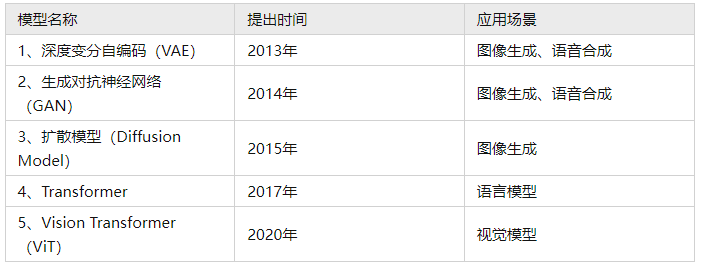
(1)变分自编码(Variational Autoencoder,VAE)
变分自编码器是深度生成模型中的一种,由Kingma等人在2014年提出,与传统的自编码器通过数值方式描述潜空间不同,它以概率方式对潜在空间进行观察,在数据生成方面应用价值较高。
VAE分为两部分,编码器与解码器。编码器将原始高维输入数据转换为潜在空间的概率分布描述;解码器从采样的数据进行重建生成新数据。
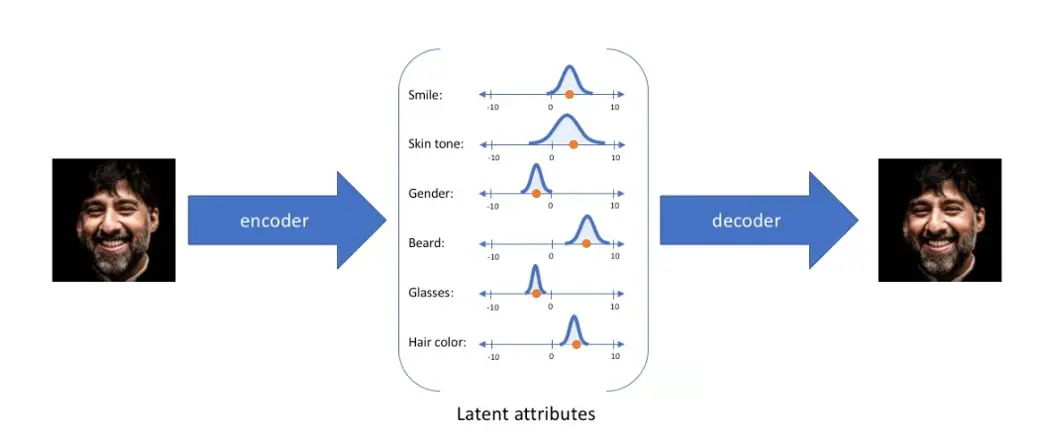
VAE模型
如上图所示,假设有一张人脸图片,通过解码器生成了多种特征,这些特征可以有“微笑”,“肤色”,“性别”,“胡须”,“眼镜”,“头发颜色”。传统的自编码器对输入图像编码后生成的潜在特征为具体的数值,比如,微笑=0.5,肤色=0.8等,得到这些数值后通过解码器解码得到与输入接近的图像。也就是说该张人脸的信息已经被存储至网络中,我们输入此人脸,就会输出一张固定的与该人脸相似的图像。
我们的目标是生成更多新的与输入近似的图像。因此,我们将每个特征都由概率分布来表示,假设“微笑”的取值范围为0-5,“肤色”的取值范围为0-10,我们在此范围内进行数值采样可得到生成图像的潜在特征表示,同时,通过解码器生成的潜在特征解码得到生成图像。
(2)生成对抗网络(Generative Adversarial Networks,GAN)
2014年 Ian GoodFellow提出了生成对抗网络,成为早期最著名的生成模型。GAN使用零和博弈策略学习,在图像生成中应用广泛。以GAN为基础产生了多种变体,如DCGAN,StytleGAN,CycleGAN等。
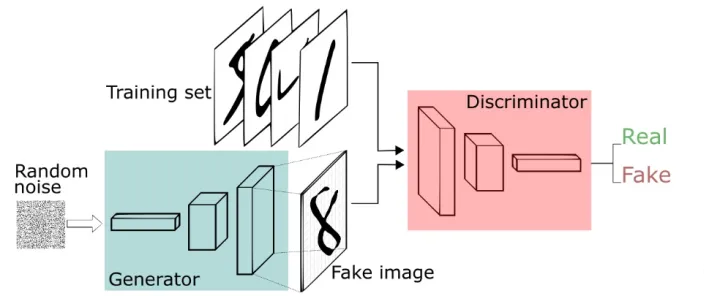
GAN模型
GAN包含两个部分:
生成器:学习生成合理的数据。对于图像生成来说是给定一个向量,生成一张图片。其生成的数据作为判别器的负样本。
判别器:判别输入是生成数据还是真实数据。网络输出越接近于0,生成数据可能性越大;反之,真实数据可能性越大。
如上图,我们希望通过GAN生成一些手写体来以假乱真。我们定义生成器与判别器:
生成器:图中蓝色部分网络结构,其输入为一组向量,可以表征数字编号、字体、粗细、潦草程度等。在这里使用特定分布随机生成。
判别器:在训练阶段,利用真实数据与生成数据训练二分类模型,输出为0-1之间概率,越接近1,输入为真实数据可能性越大。
生成器与判别器相互对立。在不断迭代训练中,双方能力不断加强,最终的理想结果是生成器生成的数据,判别器无法判别是真是假。
以生成对抗网络为基础产生的应用:图像超分、人脸替换、卡通头像生成等。
(3)扩散模型(Diffusion Model,里程碑式模型)
扩散是受到非平衡热力学的启发,定义一个扩散步骤的马尔科夫链,并逐渐向数据中添加噪声,然后学习逆扩散过程,从噪声中构建出所需的样本。扩散模型的最初设计是用于去除图像中的噪声。随着降噪系统的训练时间越来越长且越来越好,可以从纯噪声作为唯一输入,生成逼真的图片。
一个标准的扩散模型分为两个过程:前向过程与反向过程。在前向扩散阶段,图像被逐渐引入的噪声污染,直到图像成为完全随机噪声。在反向过程中,利用一系列马尔可夫链在每个时间步逐步去除预测噪声,从而从高斯噪声中恢复数据。
前向扩散过程,向原图中逐步加入噪声,直到图像成为完全随机噪声。

前向扩散
反向降噪过程,在每个时间步逐步去除噪声,从而从高斯噪声中恢复源数据。
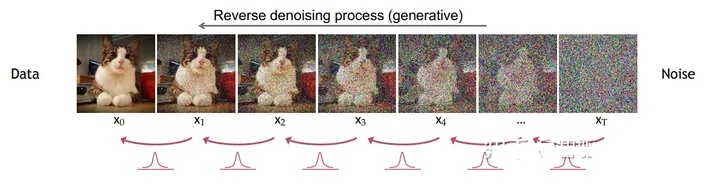
反向扩散
扩散模型的工作原理是通过添加噪声来破坏训练数据,然后通过逆转这个噪声过程来学习恢复数据。换句话说,扩散模型可以从噪声中生成连贯的图像。
扩散模型通过向图像添加噪声进行训练,然后模型学习如何去除噪声。然后,该模型将此去噪过程应用于随机种子以生成逼真的图像。
下图为向原始图像中添加噪声,使原始图像成为随机噪声。

添加噪声
下图为从噪声中恢复的原始图像的变种图像。
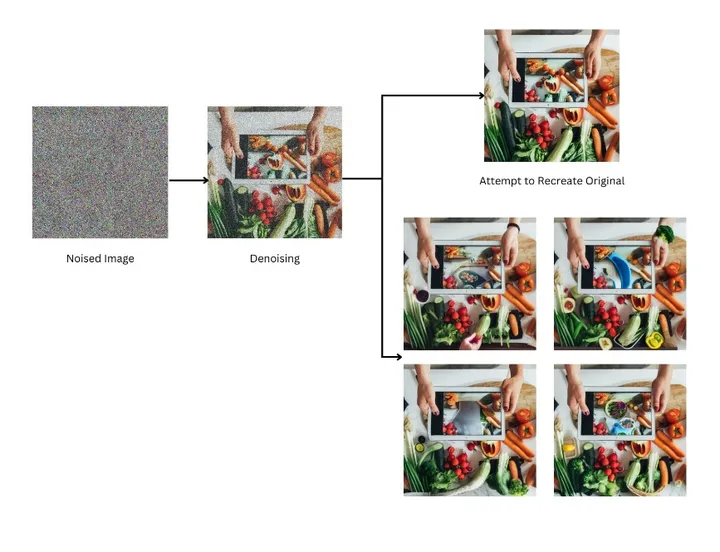
生成图像
应用:在扩散模型(diffusion model)的基础上产生了多种令人印象深刻的应用,比如:
图像超分、图像上色、文本生成图片、全景图像生成等。
如下图,中间图像作为输入,基于扩散模型,生成左右视角两张图,输入图像与生成图像共同拼接程一张全景图像。

生成全景图像
产品与模型:在扩散模型的基础上,各公司与研究机构开发出的代表产品如下:
DALL-E 2(OpenAI 文本生成图像,图像生成图像)
DALL-E 2由美国OpenAI公司在2022年4月发布,并在2022年9月28日,在OpenAI网站向公众开放,提供数量有限的免费图像和额外的购买图像服务。
如下图,左图像为原始图像,右图像为DALL-E 2所生成的油画风格的变种图像。

DALL-E 2生成的变种图像
Imagen(Google Research 文本生成图像)
Imagen是2022年5月谷歌发布的文本到图像的扩散模型,该模型目前不对外开放。用户可通过输入描述性文本,生成图文匹配的图像。如下图,通过prompt提示语“一只可爱的手工编织考拉,穿着写着“CVPR”的毛衣”模型生成了考拉图像,考拉采用手工编织,毛衣上写着CVPR,可以看出模型理解了提示语,并通过扩散模型生成了提示语描述图像。

“一只可爱的手工编织考拉,穿着写着“CVPR”的毛衣”
Stable Diffusion(Stability AI 文本生成图像,代码与模型开源)
2022年8月,Stability AI发布了Stable Diffusion ,这是一种类似于DALL-E
2与Imagen的开源Diffusion模型,代码与模型权重均向公众开放。
通过prompt提示语“郊区街区一栋房子的照片,灯光明亮的超现实主义艺术,高度细致8K”,生成图像如下,整体风格与内容锲合度高,AI作画质量较高。

“郊区街区一栋房子的照片,灯光明亮的超现实主义艺术,高度细致8K”
(4)Transformer
2017年由谷歌提出,采用注意力机制(attention)对输入数据重要性的不同而分配不同权重,其并行化处理的优势能够使其在更大的数据集训练,加速了GPT等预训练大模型的发展。最初用来完成不同语言之间的翻译。主体包括Encoder与Decoder分别对源语言进行编码,并将编码信息转换为目标语言文本。
采用Transformer作为基础模型,发展出了BERT,LaMDA、PaLM以及GPT系列。人工智能开始进入大模型参数的预训练模型时代。
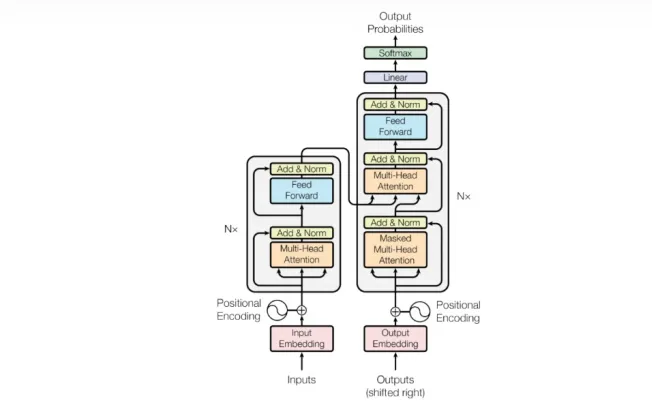
Transformer模型
(5)Vision Transformer (ViT)
2020年由谷歌团队提出,将Transformer应用至图像分类任务,此后Transformer开始在CV领域大放异彩。ViT将图片分为14*14的patch,并对每个patch进行线性变换得到固定长度的向量送入Transformer,后续与标准的Transformer处理方式相同。
以ViT为基础衍生出了多重优秀模型,如SwinTransformer,ViTAE Transformer等。ViT通过将人类先验经验知识引入网络结构设计,获得了更快的收敛速度、更低的计算代价、更多的特征尺度、更强的泛化能力,能够更好地学习和编码数据中蕴含的知识,正在成为视觉领域的基础网络架构。以ViT为代表的视觉大模型赋予了AI感知、理解视觉数据的能力,助力AIGC发展。
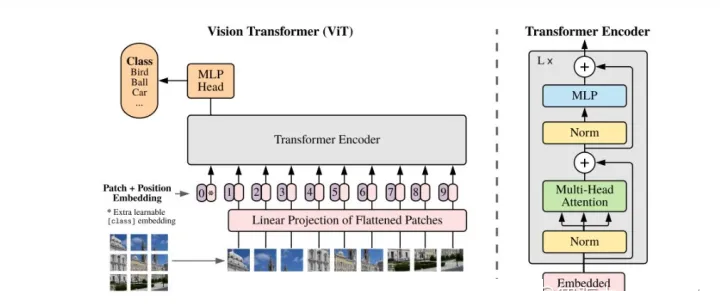
Vision Transformer(ViT)
2、预训练大模型
虽然过去各种模型层出不穷,但是生成的内容偏简单且质量不高,远不能够满足现实场景中灵活多变以高质量内容生成的要求。预训练大模型的出现使AIGC发生质变,诸多问题得以解决。大模型在CV/NLP/多模态领域成果颇丰,并如下表的经典模型。诸如我们熟知的聊天对话模型ChatGPT,基于GPT-3.5大模型发展而来。
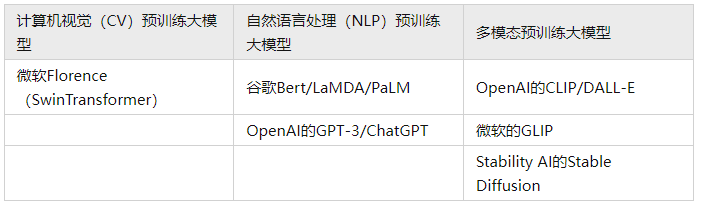
(1)计算机视觉(CV)预训练大模型
Florence
Florence是微软在2021年11月提出的视觉基础模型。Florence采用双塔Transformer结构。文本采用12层Transformer,视觉采用SwinTransformer。通过来自互联网的9亿图文对,采用Unified
Contrasive Learning机制将图文映射到相同空间中。其可处理的下游任务包括:图文检索、图像分类、目标检测、视觉问答以及动作识别。
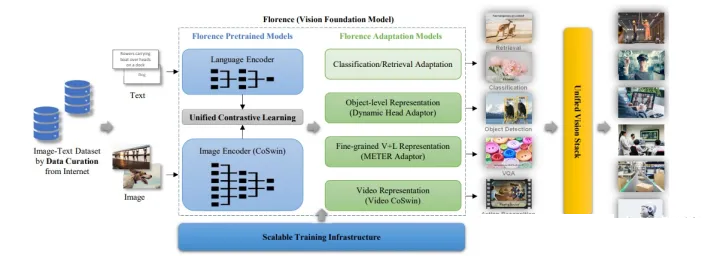
Florence overview
(2)自然语言处理(NLP)预训练大模型
LaMDA
LaMDA是谷歌在2021年发布的大规模自然语言对话模型。LaMDA的训练过程分为预训练与微调两步。在预训练阶段,谷歌从公共数据数据中收集了1.56T数据集,feed给LaMDA,让其对自然语言有初步认识。
到这一步通过输入prompt能够预测上下文,但是这种回答往往不够准确,需要二次调优。谷歌的做法是让模型根据提问输出多个回答,将这些回答输入到分类器中,输出回答结果的安全性Safety,敏感性Sensible,专业性Specific以及有趣性Interesting。根据这些指标进行综合评价,将评价从高分到低分进行排列,从中挑选出得分最高的回答作为本次提问的答案。

LaMDA对话系统原理图
ChatGPT
ChatGPT是美国OpenAI公司在2022年11月发布的智能对话模型。截止目前ChatGPT未公开论文等技术资料。大多数的技术原理分析是基于InstructGPT分析。ChatGPT与GPT-3等对话模型不同的是,ChatGPT引入了人类反馈强化学习(HFRL:Human
Feedback Reinforcement Learning)。
ChatGPT与强化学习:强化学习策略在AlphaGo中已经展现出其强大学习能力。简单的说,ChatGPT通过HFRL来学习什么是好的回答,而不是通过有监督的问题-答案式的训练直接给出结果。通过HFRL,ChatGPT能够模仿人类的思维方式,回答的问题更符合人类对话。
ChatGPT原理:举个简单的例子进行说明,公司员工收到领导安排任务,需完成一项工作汇报的PPT。当员工完成工作PPT制作时,去找领导汇报,领导在看后认为不合格,但是没有清楚的指出问题在哪。员工在收到反馈后,不断思考,从领导的思维方式出发,重新修改PPT,提交领导查看。通过以上多轮反馈-修改后,员工在PPT制作上会更符合领导思维方式。而如果领导在第一次查看时,直接告诉员工哪里有问题,该怎样修改。那么,下一次员工所做的PPT很大概率还是不符合要求,因为,没有反馈思考,没有HFRL,自然不会做出符合要求的工作。ChatGPT亦是如此。
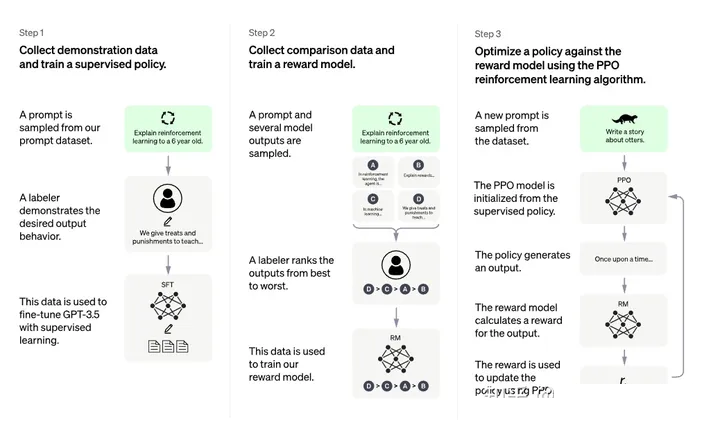
ChatGPT训练过程图
ChatGPT能够回答出好的问题与它的“领导”所秉持的价值观有很大关系。因此,你的“点踩”可能会影响ChatGPT的回答。
ChatGPT的显著特点如下:
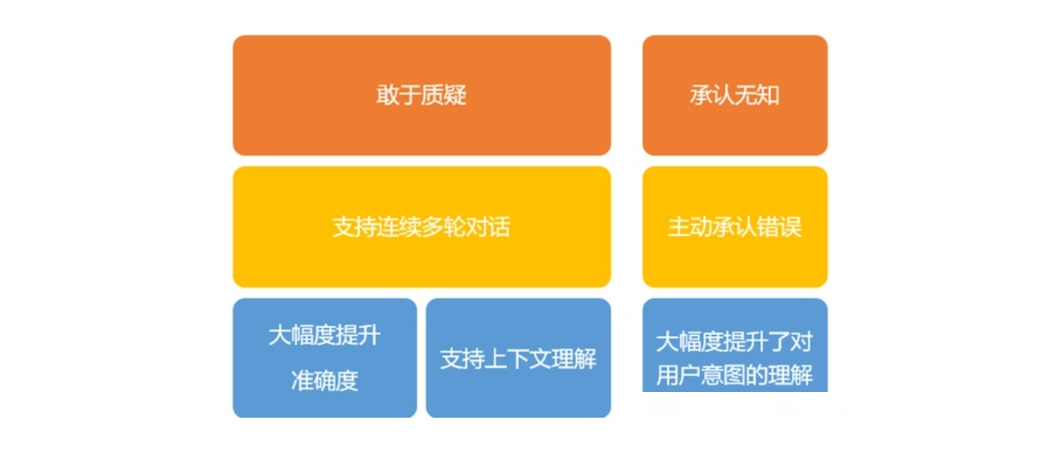
ChatGPT特点
1)主动承认错误:若用户指出其错误,模型会听取,并优化答案。
2)敢于质疑:对用户提出的问题,如存在常识性错误,ChatGPT会指出提问中的错误。如提出“哥伦布2015年来到美国时的情景”,ChatGPT会指出,哥伦布不属于这一时代,并调整输出,给出准确答案。
3)承认无知:对于非常专业的问题或超出安全性范围,如果ChatGPT不清楚答案,会主动承认无知,而不会一本正经的“胡说八道”。
4)支持连续多轮对话:ChatGPT能够记住先前对话内容,并展开多轮自然流畅对话。
(3)多模态预训练大模型
CLIP(OpenAI)
2021年美国OpenAI公司发布了跨模态预训练大模型CLIP,该模型采用从互联网收集的4亿对图文对。采用双塔模型与比对学习训练方式进行训练。CLIP的英文全称是Contrastive
Language-Image Pre-training,即一种基于对比文本-图像对的预训练方法或者模型。
简单说,CLIP将图片与图片描述一起训练,达到的目的:给定一句文本,匹配到与文本内容相符的图片;给定一张图片,匹配到与图片相符的文本。
怎样进行训练?
首先,采用Text-Encoder与Image-Encoder对文本与图像进行特征提取。Text-Encoder采用Text
Transformer模型,Image-Encoder采用CNN或Vision Transformer(ViT)。
其次,这里对提取的文本特征和图像特征进行对比学习。对于一个包含
个文本-图像对的训练batch,将
个文本特征和
个图像特征两两组合,CLIP模型会预测出
个可能的文本-图像对的相似度,这里的相似度直接计算文本特征和图像特征的余弦相似性(cosine similarity),即下图所示的矩阵。这里共有
个正样本,即真正属于一对的文本和图像(矩阵中的对角线元素),而剩余的
个文本-图像对为负样本,那么CLIP的训练目标就是最大
个正样本的相似度,同时最小化
个负样本的相似度。
最后,训练模型,优化目标函数。完成训练,输入文本经模型预测输出匹配图片;输入图片经模型预测输出匹配文本。
有什么应用?
1)跨模态检索:如搜索中文本搜索图片、文本搜索视频,图片搜索文本等。
2)跨模态内容生成:文本生成图片(DALL-E 2,Stable Diffusion等)、图片生成标题、图片生成描述等。
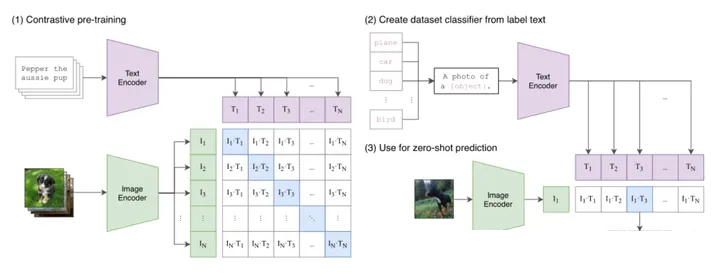
CLIP模型结构
Stable Diffusion(Stablility AI)
Stable Diffusion是英国伦敦 Stability AI公司开源的图像生成扩散模型。Stable
Diffusion的发布是AI图像生成发展过程中的一个里程碑,相当于给大众提供了一个可用的高性能模型,不仅生成的图像质量非常高,运行速度快,并且有资源和内存的要求也较低。
Stable Diffusion从功能上来说主要包括两个方面:
1)利用文本输入来生成图像(Text-to-Image)
2)对图像根据文字描述进行修改(输入为文本+图像)
具体原理是怎样实现?下面以文本生成图片进行分析。
如下图:Stable diffusion=Text Encoder+Image Generator
1) Text Encoder(文本特征提取)
我们知道,文本与图片为两个不同模态。要建立文本与图片之间的匹配需要多模态模型,因此,需利用多模态预训练模型中的Text
Encoder提取文本特征(与CLIP中的Text Encoder功能一致。)
之后,文本特征向量与随机噪声一并输入Image Generator。
输入:文本;
输出:77*768向量(77个token,每个token 768维)。

Stable diffusion原理图
2)Image Generator(图像生成)
Image Generator=Image Information Creator+Image Decoder
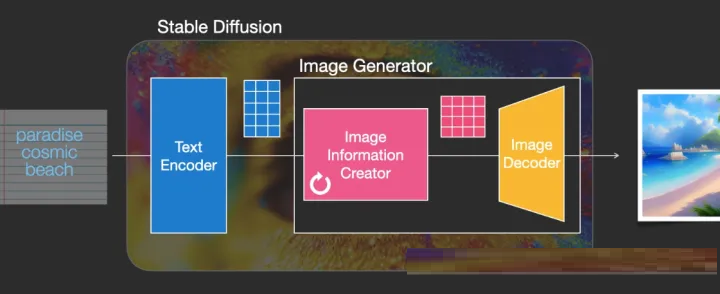
Stable diffusion原理图
A:Image Information Creator(独家秘方,领先的关键)
Image Information Creator=UNet+Scheduler
相比之前的模型,它的很多性能增益都是在这里实现的。该组件运行多个steps来生成图像信息,通常默认为50或100。
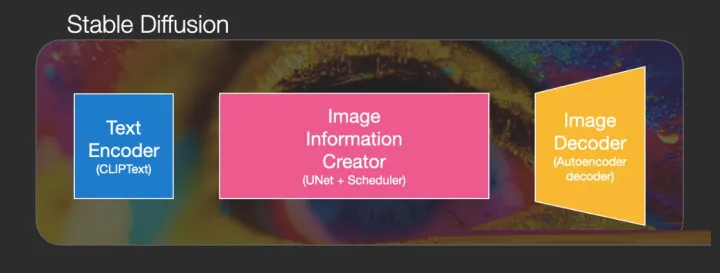
Stable diffusion原理图
整个运行过程是step by step的,每一步都会增加更多的相关信息。
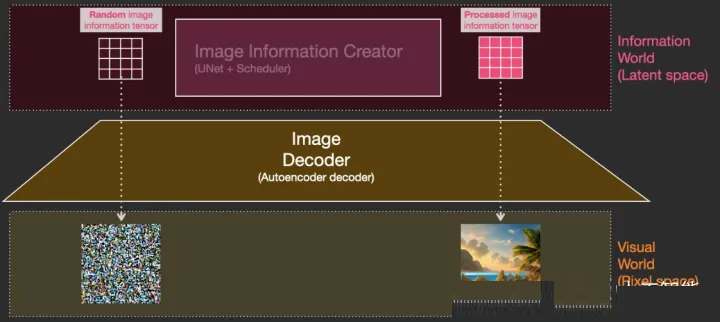
Stable diffusion原理图
整个diffusion过程包含多个steps,其中每个step都是基于输入的latents矩阵进行操作,并生成另一个latents矩阵以更好地贴合「输入的文本」和从模型图像集中获取的「视觉信息」。将这些latents可视化可以看到这些信息是如何在每个step中相加的。
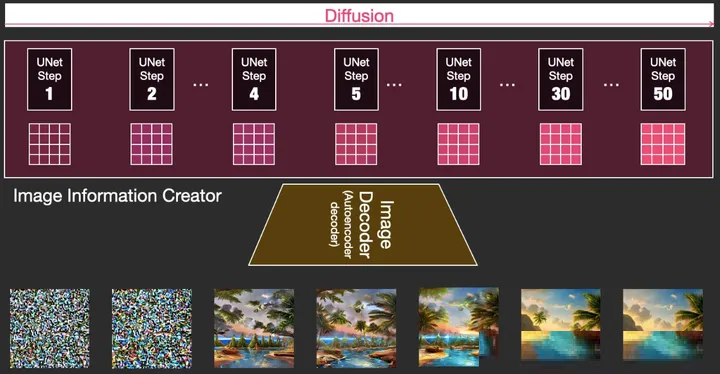
Stable diffusion原理图
由上图可以看到,图像从噪声中生成的全过程,从无到有,到每一步的变化,生成细微差异的图像。
B:Image Decoder
Image Decoder对处理过的信息矩阵进行解码,输出生成图像。
输入:处理过的信息矩阵,维度为(4, 64, 64)
输出:结果图像,各维度为(3,512,512)
Stable Diffusion是一款功能强大、免费且开源的文本到图像生成器。不仅完全开放了图片版权,甚至开放了源代码,并允许用户免费使用该工具,允许后继的创业者们使用开源框架构建起更加开放而强大的内容生成大生态。
“Stable Diffusion最初采用4000台A100的显卡训练,这些显卡价值不菲(每台价格一至两万美元),很难想象他们有着怎样的财力,抱着怎样的理念,或者说为人们做贡献的精神去把这个东西放出来的。它的价值之高,对业界的影响之大,说是AI革命都不过分。”
四、AIGC的应用场景有哪些?
1、AIGC在传媒行业应用
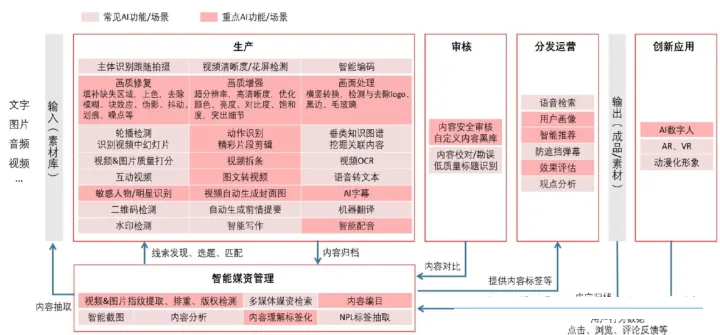 AI在媒体行业架构
如上图为AI在媒体行业应用架构,包括生成、审核、分发运营、创新应用以及媒资管理。以上架构总体上分为两部分:AI内容生成(AIGC)与AI内容分析。AIGC在媒体行业能做什么?
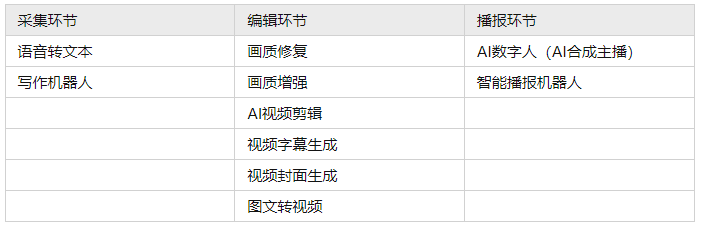
(1)采集环节
借助语音识别技术将语音实时转换为文本,压缩稿件生产过程中的重复性工作,提高内容生产效率。采用智能写作机器人,提升新闻资讯写作的时效性。
(2)编辑环节
采用AIGC技术对视频画质修复与增强,提升视频质量。此外,可利用AIGC技术对视频场景识别,实现智能视频剪辑。如人民日报社利用“智能云剪辑师”并能够实现自动匹配字幕、人物实时追踪与画面抖动修复等功能。2022冬奥会期间,央视视频通过AI智能内容剪辑系统,高效生产与发布冰雪项目视频集锦内容。
(3)播报环节
AI合成主播开创了新闻领域实时语音及人物动画合成的先河,只需要输入所需要播发的文本内容,计算机就会生成相应的AI合成主播播报的新闻视频,并确保视频中人物音频和表情、唇动保持自然一致,展现与真人主播无异的信息传达效果。

AI合成主播
2、AIGC在影视行业应用
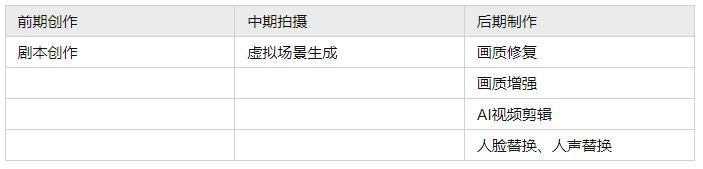
在前期创作阶段,AIGC可通过对海量剧本进行学习,并按照预定风格生成剧本,创作者可进行二次筛选与加工,激发创作灵感,缩短创作周期。
在中期拍摄阶段,可通过人工智能合成虚拟场景,将无法实拍或成本过高的场景生成出来,提升视听体验。比如,在拍摄前,进行大量场景素材收集与建模制作虚拟场景,演员在绿棚中进行拍摄,根据实时人员识别与抠图技术,将人物嵌入至虚拟场景中进行融合,生成最终视频。
在后期制作阶段,可结合AIGC技术对视频画质进行增强,若视频中出现“劣迹艺人”等敏感人员可通过“人脸替换”、“人声替换”对视频进行编辑。此外,制作者可利用AI技术自动对视频片段进行剪辑,缩短视频预告片、片段集锦的制作时间。
3、AIGC在电商行业应用
在商品展示环节:AIGC生成3D模型用于商品展示和虚拟适用,提升线上购物体验;
在主播打造环节:打造虚拟主播,赋能直播带货;
在交易场景环节:虚拟商城构建,智能聊天机器人,赋能线上和线下秀场加速演变,为消费者提供全新的购物场景。
4、AIGC在娱乐行业应用
全民娱乐:在图像内容生成应用(人脸美妆、融合;黑白图像上色、图像风格转换、人像属性变换)
社交互动:虚拟主播、虚拟网红、聊天机器人、聊天互动游戏。
5、AIGC在其他行业应用
在教育行业:AIGC为教育工作者提供了丰富的教学工作与内容素材。比如,在通过数字人生成技术,可对历史人物进行生成并与之对话,提升课堂互动。再比如,通过ChatGPT生成创意性教学方案,提供更加广泛的授课思路。
在工业行业:将AIGC技术融合工业设计软件CAD,Solidworks中,通过文本输入提示语生成,特定样式的机构模型供设计者参考。比如“设计一款卫星太阳能电池板可伸缩折翼机构”通过AIGC模型生成3D设计机构。
AIGC在内容生成行业的突破,将提升内容创作者,设计师,工程师,教育工作者等各行业人员工作效率与质量。同时,将加速企业数字化与智能化进程。
五、AIGC的产品形态有哪些?
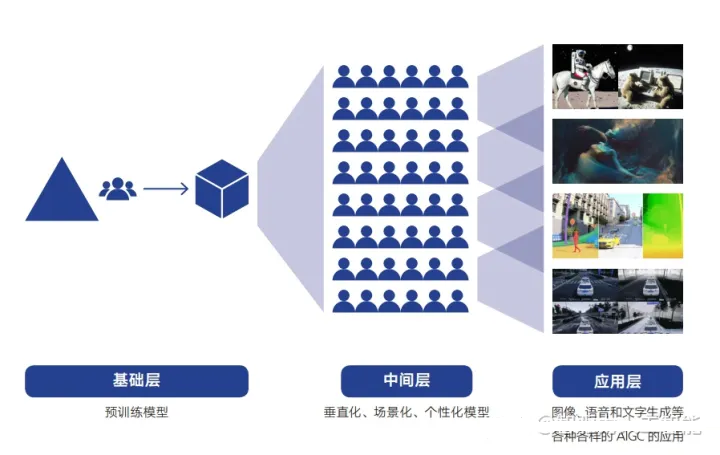 AIGC产业生态体系
1、基础层(模型服务)
基础层为采用预训练大模型搭建的基础设施。由于开发预训练大模型技术门槛高、投入成本高,因此,该层主要由少数头部企业或研发机构主导。如谷歌、微软、Meta、OpenAI、DeepMind、Stability.ai等。基础层的产品形态主要包括两种:一种为通过受控的api接口收取调用费;另一种为基于基础设施开发专业的软件平台收取费用。
2、中间层(2B)
该层与基础层的最主要区别在于,中间层不具备开发大模型的能力,但是可基于开源大模型等开源技术进行改进、抽取或模型二次开发。该层为在大模型的基础上开发的场景化、垂直化、定制化的应用模型或工具。在AIGC的应用场景中基于大模型抽取出个性化、定制化的应用模型或工具满足行业需求。如基于开源的Stable
Diffusion大模型所开发的二次元风格图像生成器,满足特定行业场景需求。中间层的产品形态、商业模式与基础层保持一致,分别为接口调用费与平台软件费。
3、应用层(2C)
应用层主要基于基础层与中间层开发,面向C端的场景化工具或软件产品。应用层更加关注用户的需求,将AIGC技术切实融入用户需求,实现不同形态、不同功能的产品落地。可以通过网页、小程序、群聊、app等不同的载体呈现。
总结:基础模型与预训练大模型的发展,促使AIGC迎来质变期与大规模应用期,未来随着核心技术演进、产品形态丰富、场景应用多元化、生态建设的日益完善,AIGC将充分释放应用价值与商业潜力。
|







 订阅
订阅