| 编辑推荐: |
本文主要介绍了VLA(视觉-语言-动作)模型如何通过将“看、懂、做”统一到一个端到端的神经网络中,使机器人从依赖预设规则的自动化设备进化为具备理解、推理和泛化能力的通用具身智能体,希望对你的学习有帮助。
本文来自于具身智能技术,由火龙果软件Alice编辑推荐。 |
|
引 言
现在的机器人,早就不是过去那种靠死规则驱动的“编程傀儡”了。曾经的机器人更像是一台被精确操控的自动化机器,程序员提前写好所有规则:
- 如果检测到A,就执行B;
- 如果环境变化超出预期,机器人直接“懵圈”。
它们不会理解语言,不知道自己“看见”了什么,更谈不上在复杂真实世界中自主决策。但这一切,正在被 VLA(Vision–Language–Action,视觉-语言-动作)模型 彻底改写。

1、先搞懂 : VLA到底是什么?机器人的「超级大脑」
如果只用一句话概括—— VLA(Vision–Language–Action)模型,就是让机器人第一次拥有“完整认知闭环”的大脑。
过去的机器人系统,其实是“碎片化智能”:
它们之间靠人工规则、接口协议强行拼接,一旦环境或任务变化,系统就很容易崩溃。而 VLA的革命性之处在于:它把“看、懂、做”这三件事,压缩进同一个模型空间里统一学习。
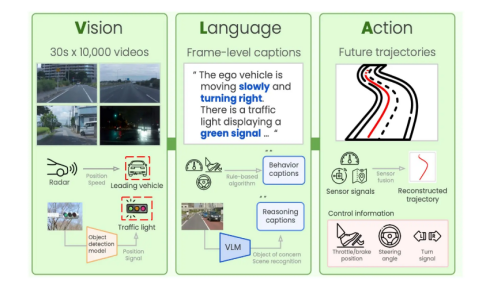
1.1 VLA的三大核心能力:看、懂、做,一步到位
1.1.1 视觉(Vision):不只是识别物体,而是理解“可行动的世界”
在VLA模型中,视觉输入通常来自:
- RGB 摄像头
- 深度相机(RGB-D)
- 有时还包括触觉、力反馈等传感器
但重点不在“看得清不清”,而在于—— 看懂什么是“和任务相关的”。 VLA的视觉能力通常学会三类关键信息:
- 物体语义: 这是苹果、盘子、桌子
- 空间关系: 苹果在盘子左边 / 被遮挡 / 可抓取
- 动作可行性( Affordance):
- 能不能抓
- 从哪个角度抓
- 抓了会不会失败

也就是说,视觉输出的不是“像素”,而是 为动作服务的世界理解。
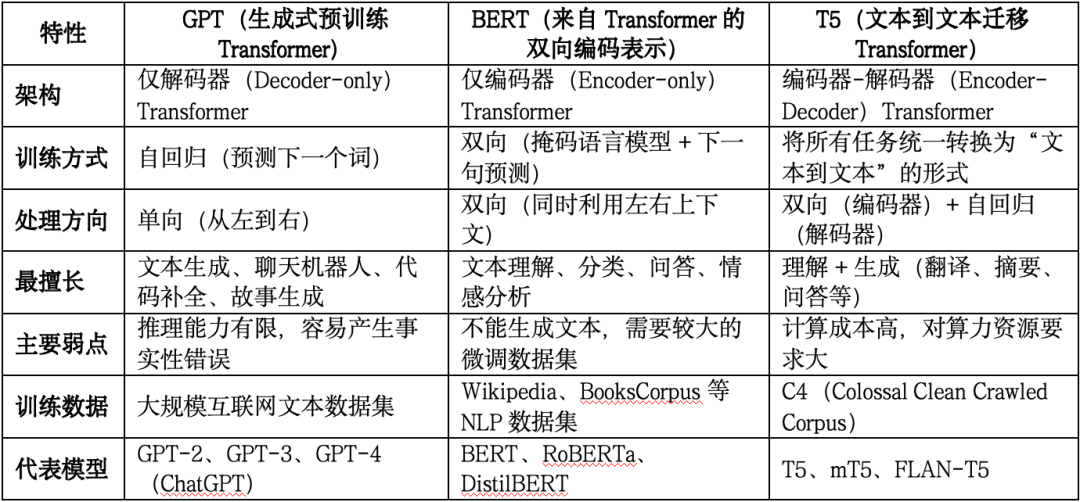
1.1.2 语言(Language):把人话翻译成“机器能推理的目标”
VLA里的语言模块,本质是一个 高阶意图解释器。 当人类说出一句自然语言,比如:“把苹果放到红色盘子里”。语言编码器要做的,不是简单语义解析,而是:
- 理解“苹果”和“红色盘子”是 视觉实体
- 判断这是一个 目标导向任务
- 提取约束条件(颜色、位置、动作结果)
通常会使用:
- BERT / T5(偏理解)
- LLaMA / GPT 类模型(偏推理)
最终输出的是一个 语义向量表示 ,作为后续动作规划的“任务锚点”。这一步,直接决定了机器人是不是“听懂了你想要什么”。
1.1.3 动作(Action):不是执行指令,而是生成行为
动作模块是 VLA 最容易被低估、但也最硬核的部分。在传统系统中,动作通常是:
而在 VLA 体系下: 动作是模型根据当前状态“生成”的结果, 动作输出可能是:
- 机械臂各关节的连续角度
- 夹爪的开合力度
- 移动机器人的速度与方向
- 多步动作序列(抓 → 抬 → 移 → 放)
更关键的是: 动作生成是条件性的、动态的、可随时修正的。 机器人不是“想好了再做”,而是 边看边做、边做边调整。
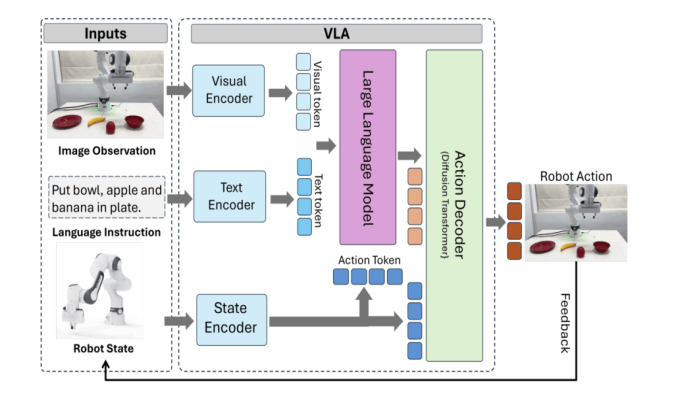
1.2 VLA的核心架构:一套端到端的多模态流水线
你这个“搭积木”的比喻非常准,我们可以把整个 VLA 拆成四大模块:
1.2.1 视觉编码器:把世界压缩成“可理解特征”
常见技术包括:
- ResNet / ConvNet:擅长局部特征
- ViT(Vision Transformer): 擅长全局关系
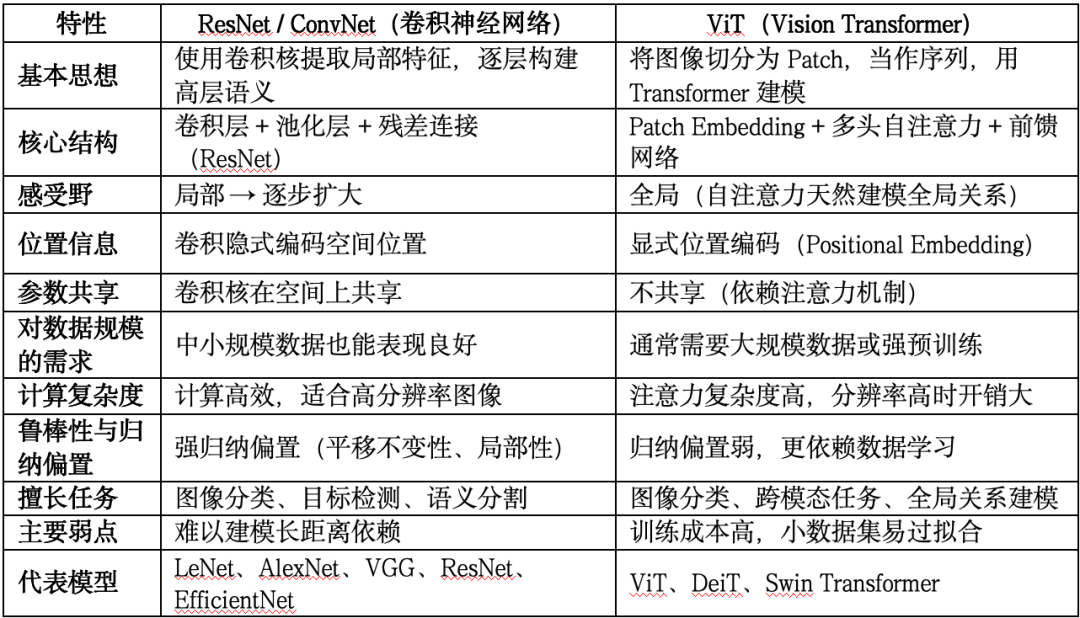
视觉编码器的目标不是分类,而是输出 高维语义特征向量 ,例如:
这些特征会被送进后续的多模态模块,与语言信息对齐。
1.2.2 语言编码器:把“人话”变成“任务表征”
语言模型在这里扮演的是 意图抽象器 :
很多前沿工作已经开始用 冻结的大语言模型 ,只训练后续模块,这大幅提升了理解能力,也减少了训练成本。
1.2.3 多模态融合模块:VLA的“灵魂所在”
这是整个系统最关键的一步。融合模块通常基于:
- Cross-Attention
- 多模态 Transformer
- 联合嵌入空间(Joint Embedding Space)
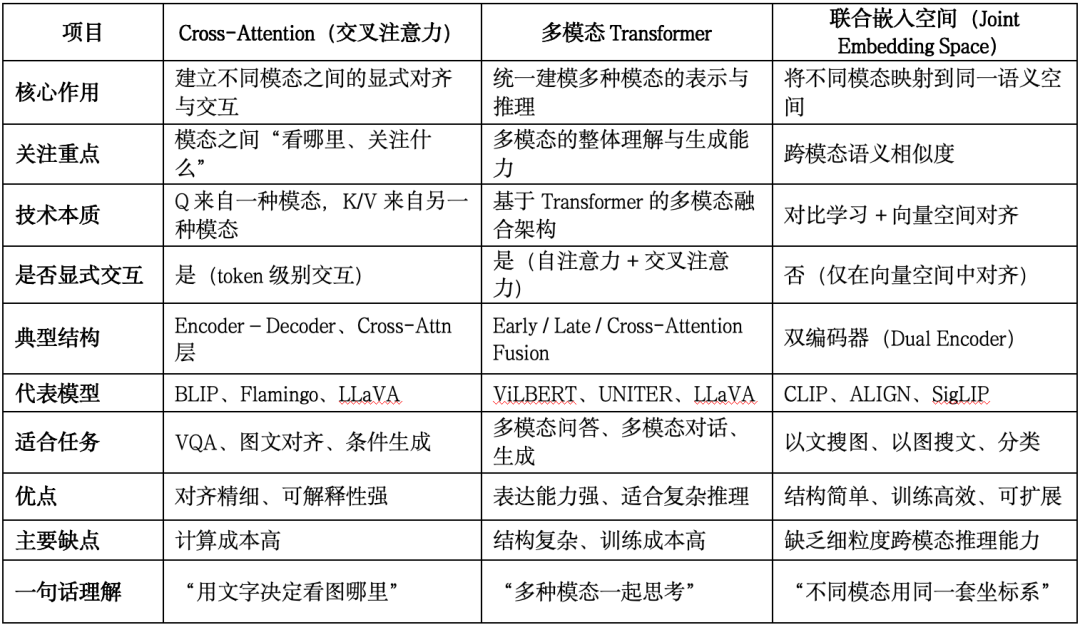
它要解决一个本质问题: 语言里提到的“苹果”,到底对应画面中的哪一个?
通过对齐,模型能建立起:
- 词语 ↔ 视觉实体
- 语义目标 ↔ 空间位置
- 动作意图 ↔ 环境约束
这一步,决定了机器人会不会“看错、理解错、抓错”。
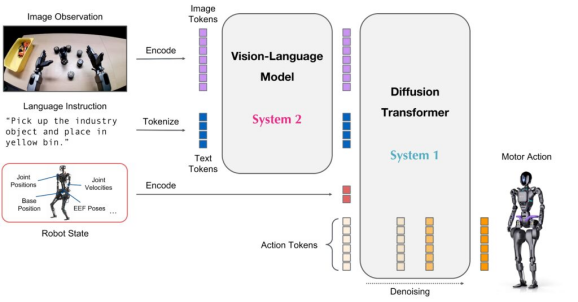
1.2.4 动作解码器:从“理解”到“物理执行”
动作解码器负责把融合后的表示,转换为:
常见形式包括:
- 连续动作回归
- 离散动作 token 化
- 行为序列生成(类似语言生成)
很多最新工作,甚至把“动作”当成一种 语言 来建模,这也是 VLA 泛化能力强的关键原因之一。
1.3 为什么说 VLA 是通用机器人的关键?
VLA不是为“一个任务”设计的,而是为“学会做任务”设计的。
它的核心优势在于:
- 端到端学习: 减少人为规则
- 强泛化能力: 新任务、新环境也能迁移
- 组合能力: 学过的技能可以自由拼装
这意味着:
- 不用为每个新场景重新写代码
- 不用为每个物体单独训练策略
- 机器人开始具备“举一反三”的能力
这,才是从“专用机器人”迈向 通用机器人 的真正门槛。
2、技术突破史: 从 0 到 1 的狂飙进化
如果回头看 VLA 的发展速度,会发现一个非常反直觉的事实: 它不是慢慢成熟的,而是连续“跳跃式进化”的。
短短三年时间,VLA 完成了从
「实验室概念」→「通用机器人中枢」
的跨越,每一个关键节点,都在 重构机器人智能的基本范式。
2.1 奠基期(2022–2023 初):RT-1 与 PaLM-E,第一次“跑通闭环”
这一阶段的核心问题只有一个: 多模态模型,真的能控制真实机器人吗?
RT-1:第一次证明“端到端是可行的”
Google 推出的 RT-1(Robotics Transformer 1) ,是VLA历史上的 第一个真正意义上的落地模型。

它的突破点不在参数规模,而在 数据和建模方式:
- 使用 13 万条真实机器人操作轨迹
- 覆盖数百种日常操作任务
- 输入:摄像头画面 + 自然语言
- 输出:连续机械臂动作
最震撼的数据是:
1. 训练任务成功率高达 97%
2. 对未见过的新任务,依然具备可观泛化能力
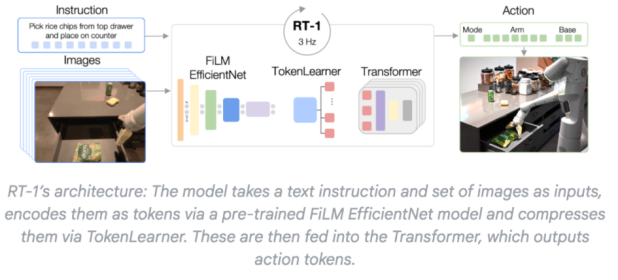
这直接击碎了一个长期存在的质疑:“机器人必须为每个任务单独设计控制策略”
RT-1 证明: 一个统一模型,就能覆盖大量不同技能。
PaLM-E:把“世界”塞进语言模型
如果说 RT-1 解决的是“能不能动”,那 PaLM-E 解决的则是—— 能不能真正理解世界? PaLM-E 的做法极其激进:
- 基于 5620 亿参数 的 PaLM 语言模型
- 把图像、机器人状态、传感器信息 全部当作“语言 token”嵌入模型
结果出现了一个关键现象: 正迁移(Positive Transfer)
也就是说:
- 加入机器人任务后
- 模型在 视觉问答、推理任务上的表现反而更好了
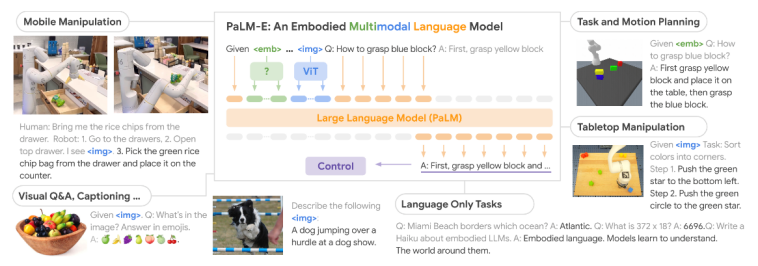
这第一次证明: 具身经验,不是拖累语言模型,而是增强认知能力。 这一发现,直接影响了后续所有 VLA 架构设计。
2.2 范式确立(2023.7):RT-2 封神,动作=语言
如果说前面是“能跑”,那么 RT-2 的出现,直接定义了“怎么玩”。
核心革命:把动作离散化成 Token
RT-2 做了一件极其大胆的事: 把连续的机器人动作,离散成“文字序列”
例如一个 7 维动作向量,被编码为:1 128 91 241 5 101 127这意味着什么?
1. 机器人控制,被彻底转化为“语言生成问题”
2. 可以直接复用大语言模型的推理、泛化、组合能力
这是 VLA 真正的“范式切换”。 涌现能力:不是教会的,是“长出来的”
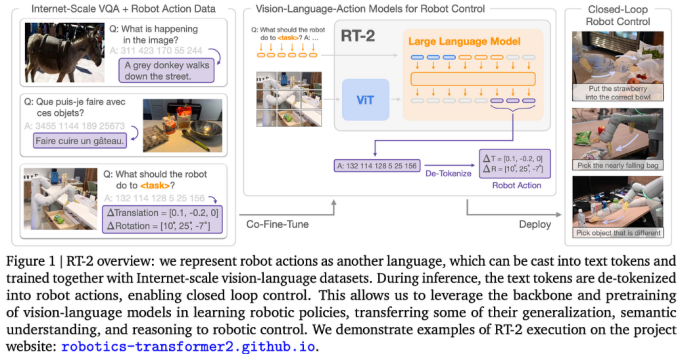
RT-2 最震撼的,并不是执行精度,而是 从未显式训练却自然出现的能力:
- 抽象指令理解 “把东西放在数字 3 上”(模型从未学过“数字 3 的位置概念”)
- 常识推理 “敲碎香蕉” → 选择石头而不是苹果
- 链式思考(Chain of Thought)
需要敲碎 →需要硬物 →石头更硬 →抓石头
这已经不再是“控制算法”,而是 具身推理能力的雏形。
2.3 开源浪潮(2024):VLA 从“神坛”走向“普惠”
2024年,是 VLA 真正爆发的一年。关键词只有一个: 去中心化。
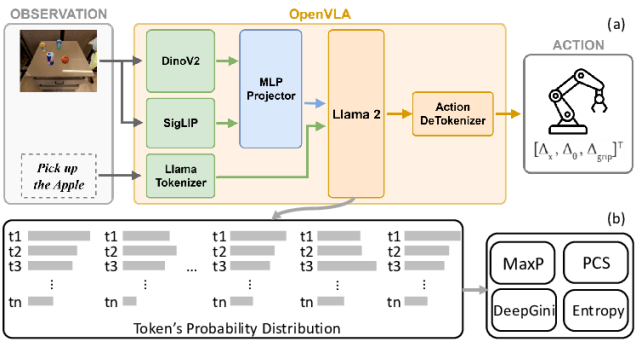
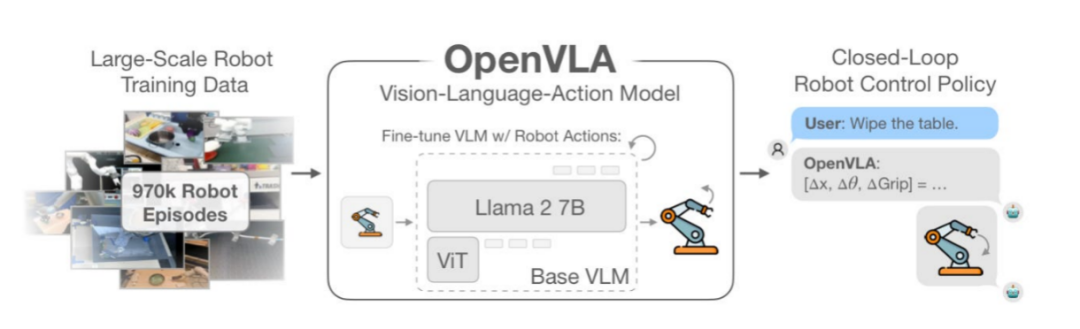
OpenVLA:把门槛打下来
OpenVLA 是首个 工程级可用的开源 VLA 框架:
- 支持多种机器人平台
- 使用 LoRA 微调
- 只需调整 ≈1.4% 参数 就能适配新硬件
这意味着:中小实验室,创业团队,甚至个人研究者都可以 玩得起 VLA 。
Octo:轻量化路线的胜利
Octo 证明了另一件事: VLA 不一定非要“巨无霸”
- 27M / 93M 参数
- 使用 扩散策略(Diffusion Policy)
- 输出连续动作
- 一套模型适配多种机器人形态
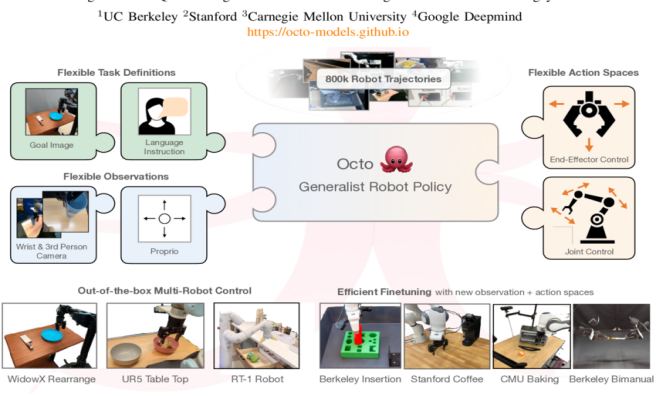
它更像是: “机器人界的 MobileNet + Transformer”
π0:高频连续控制的技术突破
π0 引入了 流匹配(Flow Matching) 技术:
- 可生成 50Hz 高频连续动作
- 极其平滑、稳定
- 擅长精细操作
例如:
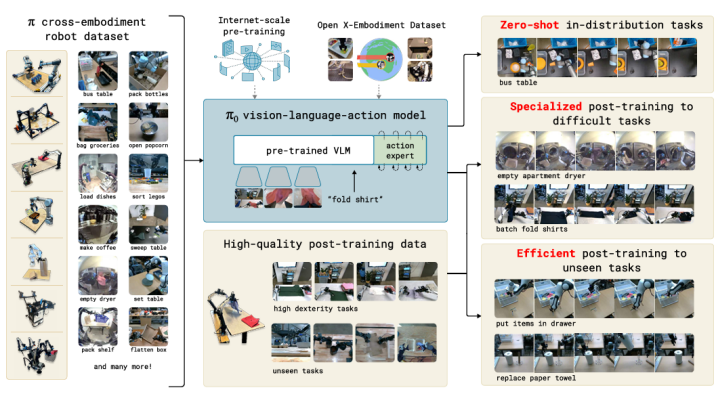
这一步,补上了 VLA 在 精细操作上的最后一块短板。
2.4 群雄逐鹿(2025):VLA 正式拥抱人形机器人
到了 2025 年,VLA 的主战场发生了根本转移: 从机械臂 → 人形机器人
人形机器人带来的挑战是指数级的:
于是,一个新共识形成了: 单一时间尺度的模型不够用了,双系统架构成为主流。
Figure AI · Helix
- 快系统(200Hz): 负责实时动作控制
- 慢系统(7–9Hz): 负责高层规划与理解
- 能控制人形机器人 全上半身
- 甚至支持 双机器人协同作业
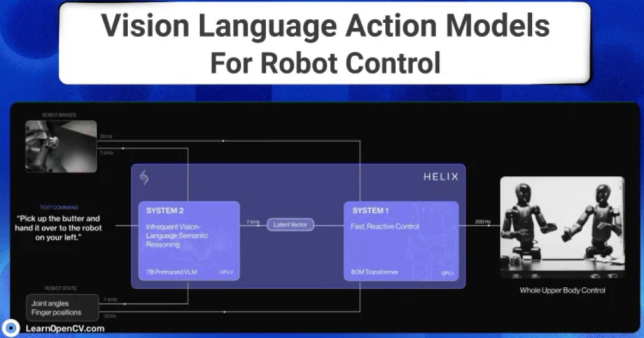
这已经非常接近人类的“反射 + 意识”分工。
NVIDIA · GROOT N1
- 完全开源
- 混合:
- 真实机器人数据
- 仿真数据
- 人类操作视频

GROOT 更像是 VLA 的“工业标准底座” 。
Google · Gemini Robotics
- 双模型设计:
- 一个管 逻辑推理
- 一个管 动作执行
- 能完成:
- 折纸
- 做沙拉
- 多步骤家庭任务
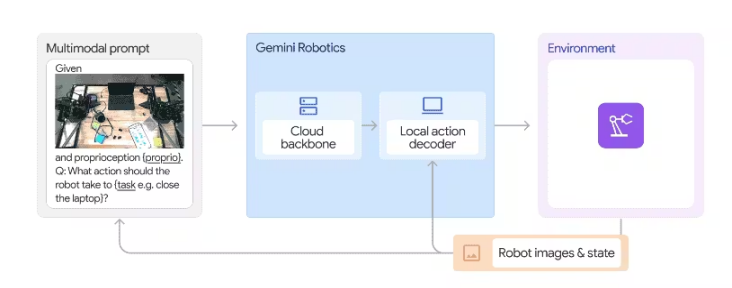
这标志着: “通用具身智能”已经不再只是实验展示。
回看这三年,你会发现 VLA 的进化逻辑非常清晰: 先跑通 → 再统一范式 → 再规模化 → 再复杂化
而现在,它已经站在了 通用人形机器人智能中枢 的门口。
3、核心技术揭秘:这些黑科技撑起 VLA
如果把 VLA 看成一台“超级大脑”,那下面这四项技术,就是它的 血液、神经、运动系统和大脑结构 。缺任何一个,VLA 都跑不起来。
3.1 数据是燃料:Open X-Embodiment,跨形态智能的根基
在 VLA 之前,机器人学习最大的问题只有一个: 数据太少、太碎、太专用。 Open X-Embodiment 的出现,本质上解决的是“机器人版 ImageNet”的问题。

数据集到底有多狠?
Open X-Embodiment 汇集了:
- 22 种不同机器人形态
- 不同机械臂
- 不同自由度
- 不同控制接口
- 100 万 + 条真实操作轨迹 ,涵盖:
- 抓取
- 放置
- 推拉
- 组合操作
- 长时序任务
最关键的一点是: 这些数据被统一成同一种“抽象动作空间”
跨形态训练:为什么能“举一反三”?

传统思路是:一种机器人,一套模型,Open X-Embodiment 则反过来:
让模型学“任务本身”,而不是“某个机器人怎么动”
例如:
- 抓杯子
- 不管是两指夹爪、三指手、还是五指灵巧手
- 本质任务是一样的
VLA 学到的是“抓取的语义和几何结构”,而不是具体关节角度。这也是为什么一个在 A 机器人上训练的 VLA,可以 零样本或少样本迁移 到 B 机器人上。
3.2 模仿学习:从“人类示范”中偷师
强化学习在机器人领域一直很难落地,原因很现实:
- 真实机器人试错成本极高
- 一次失败,可能就是硬件损伤
于是,模仿学习(Imitation Learning)成为 VLA 的主力训练方式。
3.3 人类遥操作:最昂贵,但最有效的数据
常见方式包括:
人类直接告诉机器人:“这件事,应该这样做。”这相当于 给模型一条“正确解的捷径” 。
3.4 动作分块(Action Chunking):让动作更“像人”
如果让模型一步一步生成动作,会出现两个问题:
解决方案就是: 动作分块。 模型不输出“下一毫秒干什么”,而是输出: 接下来一小段时间的动作序列, 好处非常直观:
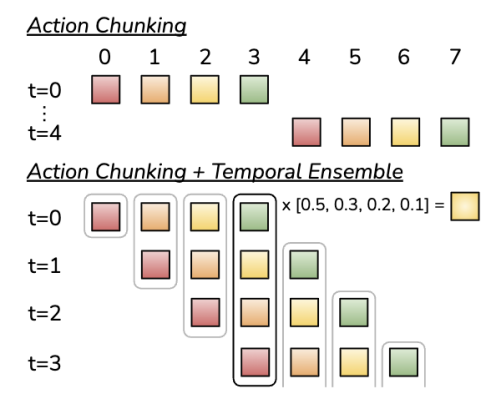
这和人类运动控制中的“运动单元”高度一致。
3.5 扩散模型 & 流匹配:复杂动作生成的终极武器
随着任务复杂度上升,传统动作生成方式开始失效:
- 多模态动作空间
- 同一目标有多种可行解
- 连续控制极其不稳定

这正是 扩散模型(Diffusion) 和 流匹配(Flow Matching) 登场的舞台。
3.6 扩散策略:从“噪声”中长出动作
扩散模型的核心思想是: 不是直接预测动作,而是逐步“去噪”生成
这在机器人领域带来了三个巨大优势:
Octo 等模型,正是靠扩散策略,在小模型下仍然实现了强泛化。
3.7 流匹配:为高频控制而生
流匹配可以理解为: 学习一条从“随机动作”到“最优动作”的连续轨迹
它的优势在于:
- 可以生成 高频(如 50Hz)连续动作
- 动作变化极其平滑
- 非常适合精细操作
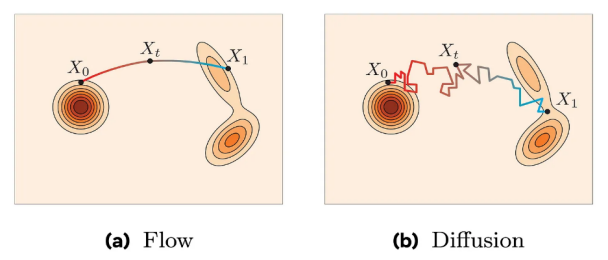
π0 之所以能折衣服、装杂货,靠的正是这一套连续控制能力。
3.8 双系统架构:像人一样“想”和“动”
随着机器人任务变得越来越复杂,一个单一模型开始力不从心。于是,VLA 领域逐渐形成一个共识: 必须拆分时间尺度。
3.9 慢系统:负责“理解与规划”
慢系统通常:
- 更新频率低(几 Hz)
- 接收:
- 视觉
- 语言
- 世界状态
- 负责:
- 任务分解
- 逻辑推理
- 高层动作规划
它更像是: 前额叶皮层。
3.10 快系统:负责“即时执行”
快系统则:
- 高频运行(几十到几百 Hz)
- 只关注:
- 当前状态
- 局部目标
- 输出:
- 实时控制信号
它更接近: 人类的运动皮层 + 小脑。
3.11 两者协作,才是真正的通用智能
慢系统告诉快系统:“接下来,把苹果放进盘子。”快系统负责解决:“现在这一刻,手该怎么动?”这种架构,几乎是 唯一可扩展到人形机器人的路线。
VLA 之所以能成立,不是靠某一个“神模型”,而是靠 一整套协同进化的技术栈:大规模数据 + 人类示范 + 先进生成模型 + 仿生架构 它们一起,把机器人从“自动化设备”,推向了真正的 具身智能体 。
4、未来已来?挑战与机遇并存
必须承认一句话: 今天的 VLA,已经远超“惊艳演示”,但距离“可靠通用智能”仍有鸿沟。 这条鸿沟,不是算力问题,也不是模型规模问题,而是 物理世界的残酷现实 。
4.1 仍未攻克的关键挑战:VLA卡在哪?
高质量机器人数据,依然是“稀缺资源” 和互联网数据不同,机器人数据有三个天然劣势:
- 贵: 一条真实机器人轨迹 = 时间 + 人力 + 硬件损耗
- 慢: 一天能采集的数据量,远不如网络爬虫
- 不通用: 不同机器人、不同传感器、不同控制接口,难以直接复用
即便有 Open X-Embodiment 这样的突破,但和语言模型的“万亿 token”相比, 具身数据仍然处在“前寒武纪”阶段 。这直接限制了 VLA 的上限。
4.2 物理世界的安全与可靠性:错一次,代价极高
在数字世界里,模型犯错只是“答错题”;但在物理世界:
- 抓错 → 物体损坏
- 判断失误 → 设备受损
- 行为异常 → 可能危及人类安全
当前 VLA 的一个核心问题是: 它“看起来很聪明”,但并不总是“可控”。 如何做到:
是 VLA 迈向大规模商用的 硬门槛 。
4.3 长时程任务:从“会做动作”到“会完成目标”
现在的 VLA 非常擅长:
但现实世界的任务往往是:“去厨房 → 找杯子 → 如果没洗先洗 → 倒水 → 端过来”,这涉及:
也就是说: VLA 的“肌肉”已经很强,但“耐力和战略意识”还在成长中。
4.4 那为什么大家依然如此乐观?
答案很简单: VLA 的技术曲线,已经跑在“指数段”上。 我们正在同时看到四条趋势叠加:
- 数据规模持续扩大(真实 + 仿真 + 人类视频)
- 架构不断仿生化(双系统、多时间尺度)
- 生成模型持续进化(扩散、流匹配)
- 硬件与算力同步成熟
这些趋势一旦叠加,就会出现 非线性跃迁 ——就像语言模型在 2020–2023 年经历的那样。
4.5 VLA模型发展时间线总结(3年=一代技术范式)
这张时间线,本质上不是“模型列表”,而是 机器人智能范式的演化轨迹。
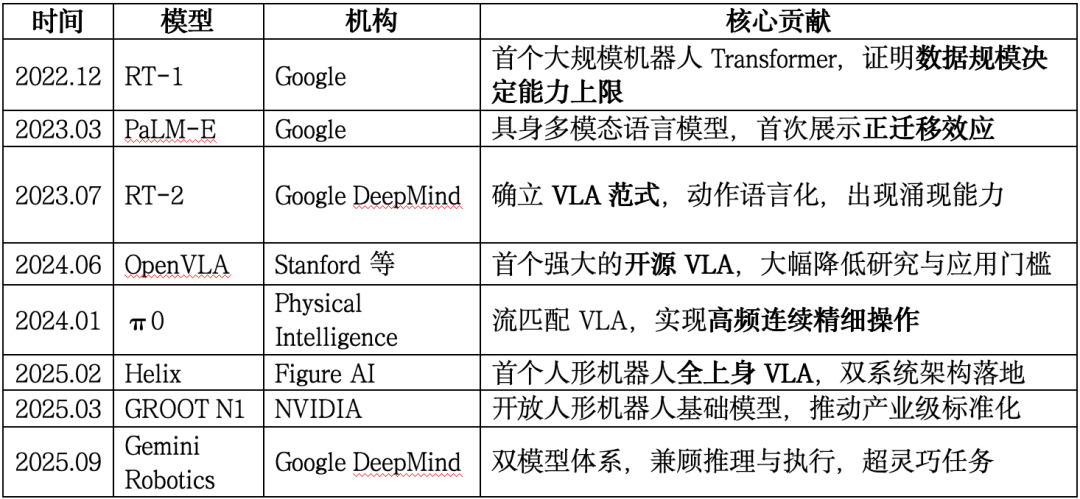
如果你把这些节点连起来,会发现一条清晰主线: 从“能不能动” → “懂不懂世界” → “能不能泛化” → “能不能成为通用形态”
VLA,正在重塑人与物理世界的关系 从 RT-1 到 Gemini Robotics, VLA 只用了 3 年时间 ,就让机器人完成了一次质变:从「专用工具」到「通用助手」再到「具身智能体」,未来受影响的,绝不只是机器人行业本身:
- 制造业:柔性生产、无人工厂
- 物流:全天候、泛场景操作
- 家庭服务:真正“能帮忙”的机器人
- 人机交互:从“点按钮”到“自然协作”
人类正在第一次,拥有能真正理解并作用于物理世界的“非人智能伙伴”。
科技迷们,这场具身智能革命,才刚刚开始。下一个惊喜,很可能比我们想象得更早到来。
| 






 订阅
订阅