| 编辑推荐: |
本文主要介绍了
Palantir 的 Ontology——FDE 真正值钱的东西不是写代码,是给数据穿上业务的衣服。希望对你的学习有帮助。
本文来自于微信公众号互联互说,由火龙果软件Alice编辑,推荐。 |
|
拆解 Palantir 的 Ontology——FDE 真正值钱的东西不是写代码,是给数据穿上业务的衣服
你的
ERP 系统里有几百张表。你每月花几十万养着数据团队。但你做决策的时候,还是要靠微信群里的
Excel 文件。
这不是你的问题。这是整个行业的问题——数据库存的是"表(Tables)",而人做决策时,脑子里想的是"实体(Objects)"。
有一个被严重低估的角色,专门在填补这个鸿沟。这篇文章不说概念,只拆机制。
|
一、一个尴尬的现实
先做一个思想实验。
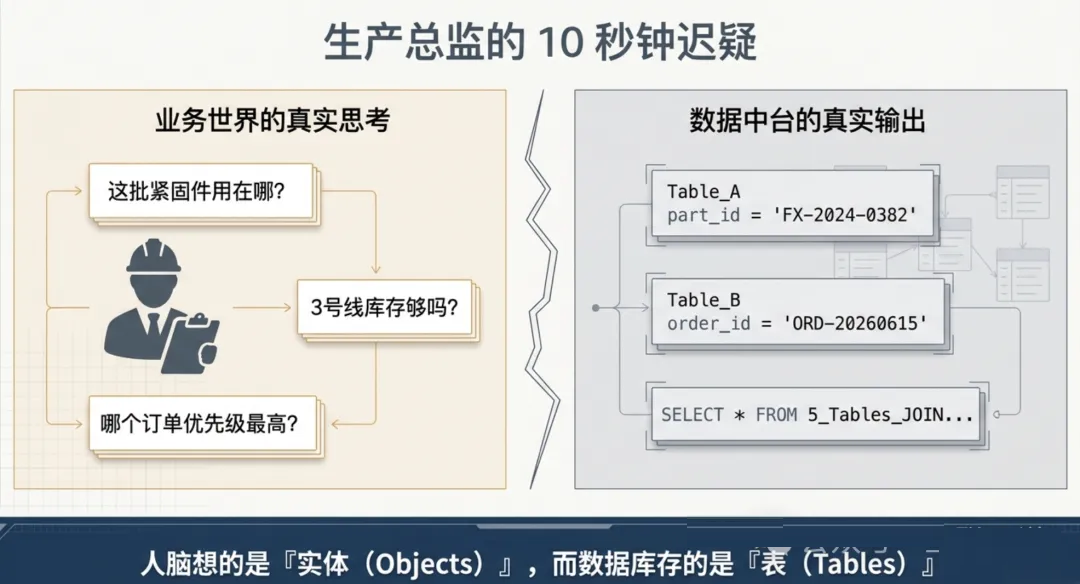
你是工厂的生产总监。今天一早,装配线来报:一批紧固件在海关被扣了,预计晚两天到货。
你的第一反应不是"查 SQL 数据库",而是快速在脑子里过了一遍:
•
"这批紧固件用在哪儿?"
•
"3号线和5号线的工位上还有多少库存?"
•
"如果从7号线的备件里临时拆借,来得及补吗?"
•
"哪个订单的优先级最高?"
|
看到了吗?你在脑子里思考的,全是业务实体:零件、工位、产线、订单、优先级。
但现在转头去看你花了几千万建的数据中台。它在告诉你什么?
它告诉你:Table_A part_id = 'FX-2024-0382'、Table_B order_id
= 'ORD-20260615'、join 条件:5 张表关联。
你把"FX-2024-0382"这个字符串看了十秒钟,脑子里才反应过来:哦,这就是那批被海关卡住的紧固件。
问题出在哪?
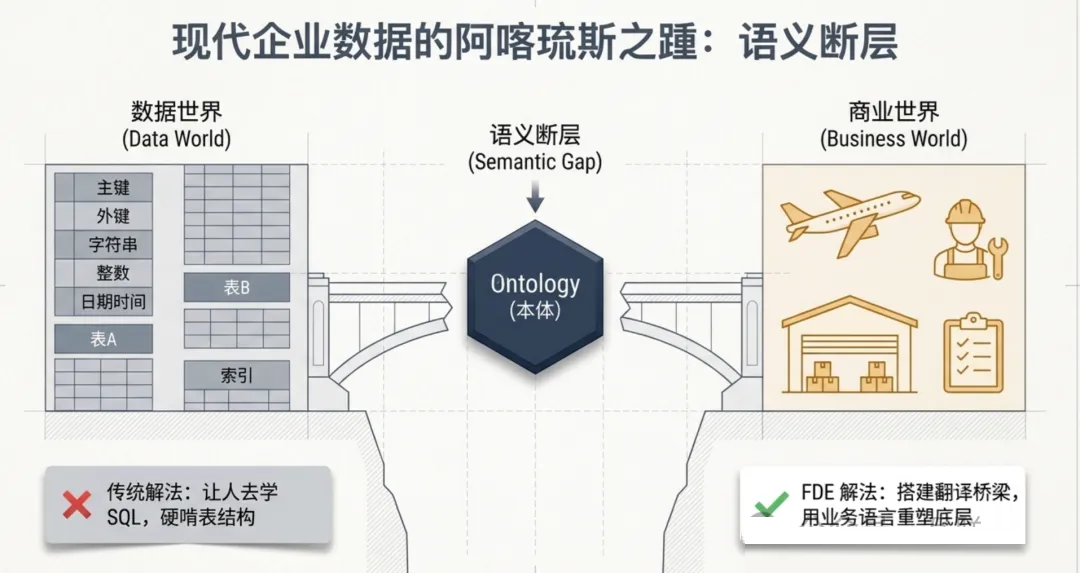
出在数据中台存的是"表",而人做决策时想的是"实体"。这两个世界之间存在一个语义断层。很多企业花了大价钱建数据中台,最终发现还是没法辅助决策,原因就在这里——你没有把表翻译成业务能听懂的语言。
这个断层的存在,是整个现代企业数据建设的阿喀琉斯之踵。
而 Palantir 的 FDE 团队,花了二十年时间,专门在做一件事:填上这个断层。
他们的武器,叫 Ontology(本体)。
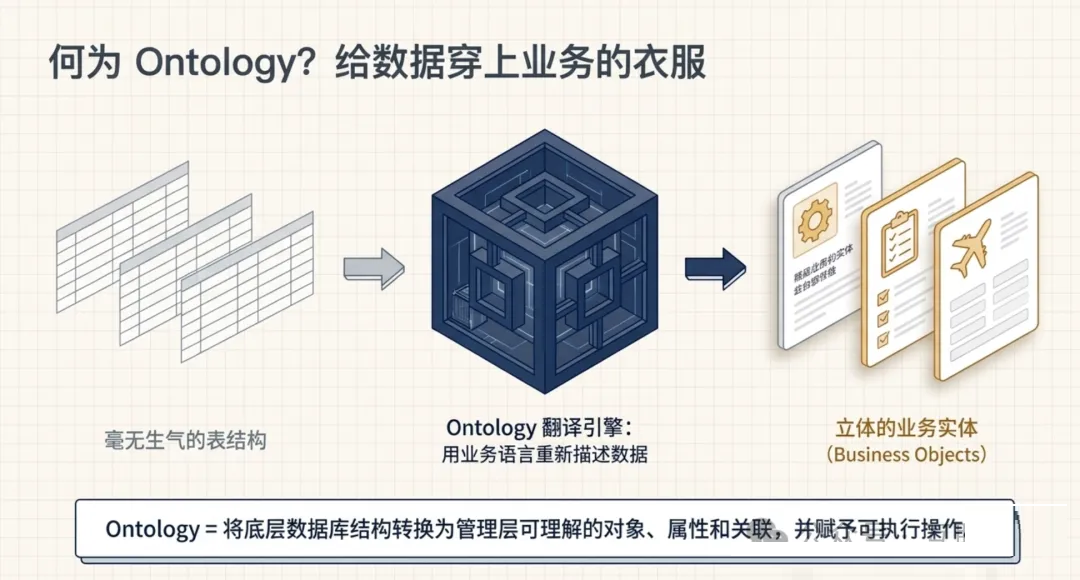
二、Ontology 不是什么高深概念,它就是"给数据穿上业务的衣服"
先给一个最朴素的定义:
Ontology
= 用业务能听懂的话,把数据库里的表重新说一遍。 |
传统数据库里存的是:
| part_id |
sku_code |
category_id |
supplier_id |
| FX-001 |
6mm-304 |
03 |
SUPP-47 |
经过 Ontology 翻译之后,在业务界面上显示的是:
品名: 6mm 304不锈钢紧固件
状态: 已到港
用于: A350-900 机翼装配
目前所在: 上海洋山港 3号保税仓
关联工单: WO-20260614-003(今日到期)
|
后者才是人决策时需要的"信息"。前者只是"数据"。
Ontology 做的工作,就是把表结构转换成管理层可以理解的对象、属性和关联,并在此基础上赋予可执行的操作。
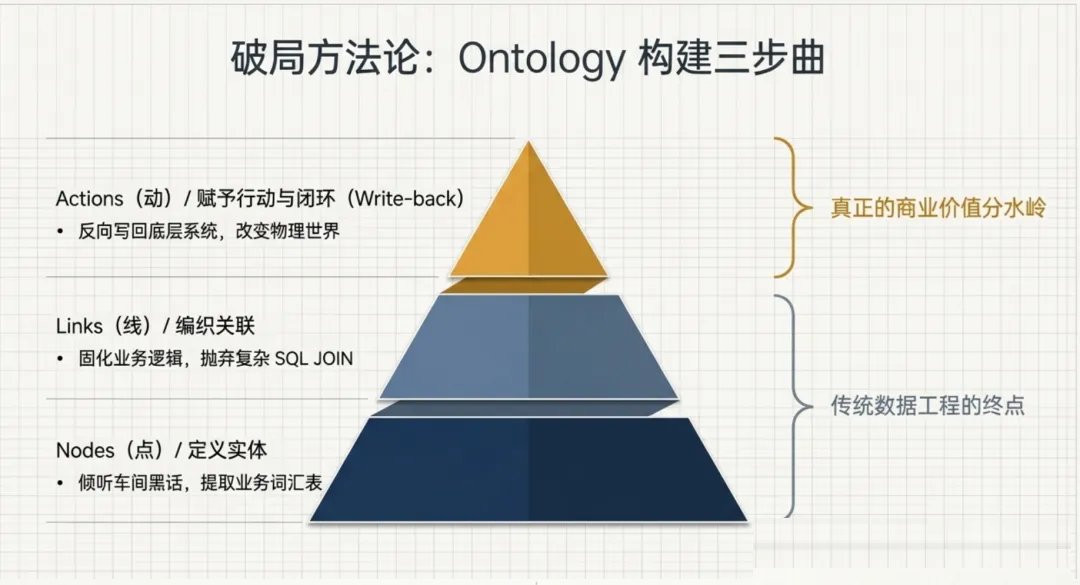
三、Ontology 构建三步法
下面以 大型客机总装线 为例,拆解 FDE 如何从零构建一个 Ontology。
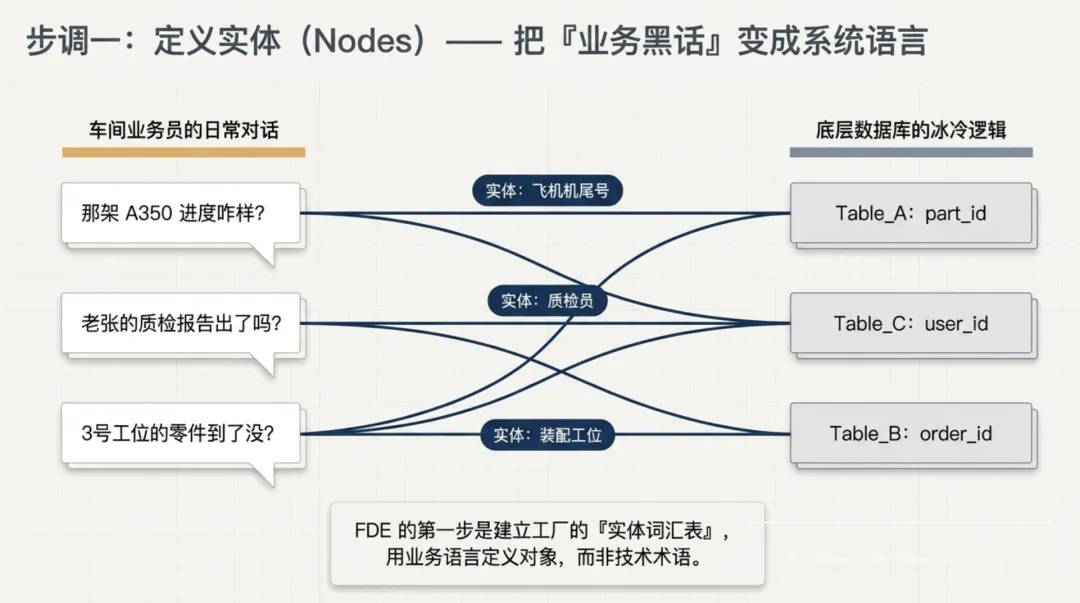
第一步:定义实体(Objects)
FDE 进场第一天,不会去打开数据库看表结构。他干的第一件事是:坐在车间里,听业务员怎么说。
他会听到这样的话:
•
"A350 的机翼装配今天进度怎么样?"
•
"3号工位那批紧固件到了没有?"
•
"老张,你那个批次的质检报告出了吗?"
|
这个 FDE 脑子在做的,就是提取出这个工厂的"实体词汇表":飞机机尾号、紧固件、装配工位、质检员、工单、批次。
然后他会问一个关键问题:"你们说的'那架飞机',
在系统里对应哪个表、哪个字段?"
这个问题,就是 Ontology 构建的起点。
原则:用业务能听懂的语言定义实体,不是用技术术语。
| 技术人员的语言 |
业务人员的语言 |
| Table_A: part_id, sku_code |
这批紧固件 |
| Table_B: order_id, status_code |
3号工位的订单 |
| Table_C: user_id, role_id |
老张(那个干了20年的质检员) |
有意思的是,FDE 在第一天花的大部分时间不是写代码,而是和业务员聊天——搞清楚他们嘴里的"那个零件""老张""3号线"在系统里到底对应什么表和字段。
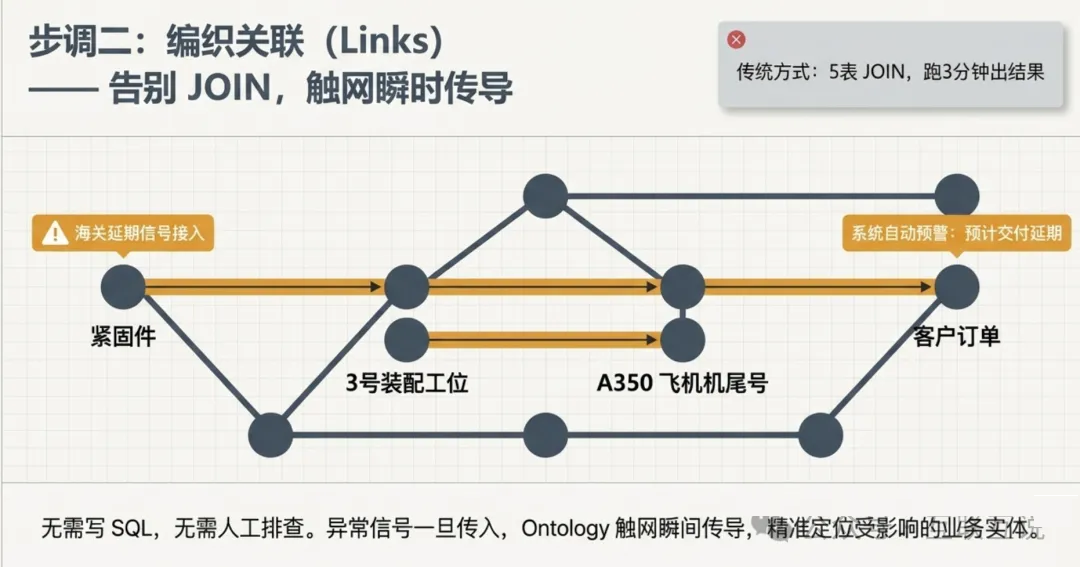
第二步:编织关联(Links)
定义好实体之后,FDE 要做的是把这些孤立的实体编织成一张网。
传统方式: 想知道"一批螺丝钉延期会影响哪架飞机"——需要写极度复杂的 SQL
语句,做 5 张表的 JOIN,跑几分钟才能出结果。
FDE 方式: 提前把这些关系"固化"到 Ontology 里:
•
紧固件 → 链接到 → 装配工位
•
装配工位 → 链接到 → 飞机机尾号
•
飞机机尾号 → 链接到 → 客户订单
•
客户订单 → 链接到 → 交付日期
|
效果是什么?当某批次零件在海关被卡住的信号一传入系统,Ontology 就像一张触网,瞬间传导震动——直接在屏幕上把受影响的飞机标红,同时计算出每个订单的预计延期时间。
不需要写 SQL。不需要等人来查。系统会自动告诉你,谁会被影响。
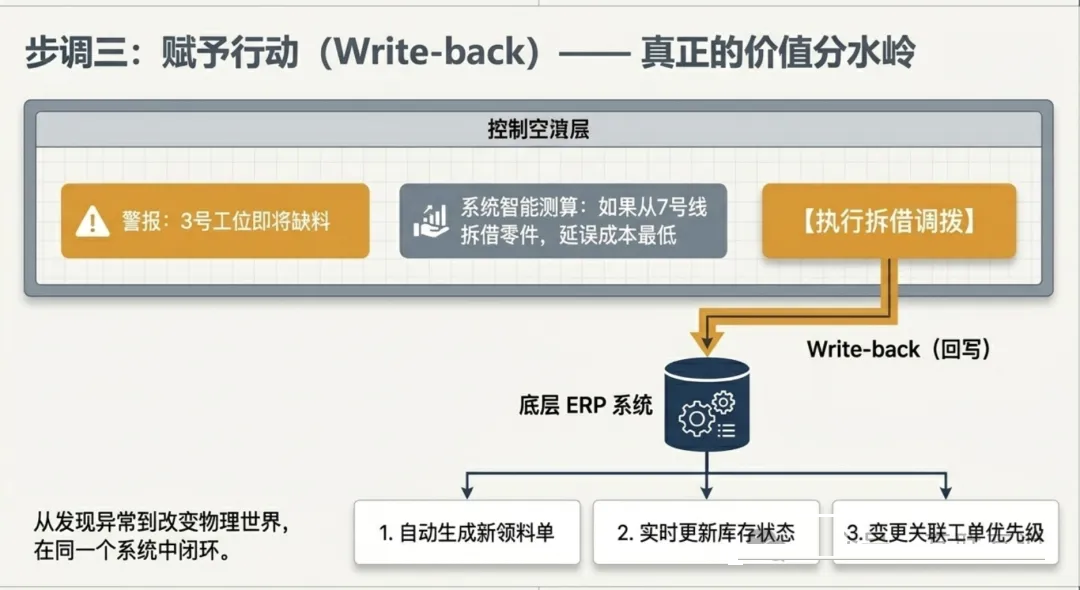
第三步:赋予行动与闭环(Actions & Write-back)
绝大多数数据项目到这里就结束了——做了一套报表,建了一个大屏,能"看到"问题了。
但 FDE 不会停在这里。
如果只做到第二步,系统依然只是个"高级监控"——能告诉你问题在哪,但你得自己去想办法解决。
FDE 的第三步,也是整个 Ontology 最关键的一步,是把系统从"被动展示"变成"主动行动"。
具体来说,FDE 会在 Ontology 中定义 Actions(操作):
•
发现缺料 → 系统不仅发出警报
•
还基于 Ontology 中的关联数据自动测算:如果从另一架优先级较低的飞机上拆借零件,延误成本是多少?
•
然后,在界面上生成一个【执行拆借调拨】的按钮
|
当供应链总监按下这个按钮——关键来了——系统会直接把这个调拨指令反向写回工厂底层的 ERP 系统,自动生成新的领料单,更新库存状态,变更工单优先级。
这个机制,叫 Write-back(回写)。
从发现异常,到评估影响,再到下达指令改变物理世界——全部在一个系统内闭环。
这是 FDE 和传统数据工程师最本质的区别。传统数据工程师做到"出报表"就结束了。FDE
要做到"按钮按下去,仓库里的零件真正被调走了"。
四、Ontology 的商业逻辑:越做越便宜
理解完技术机制之后,再来看商业逻辑。
如果每一个项目都要靠 FDE 从头搭 Ontology,那为什么 Palantir 的利润率能做到
80%?
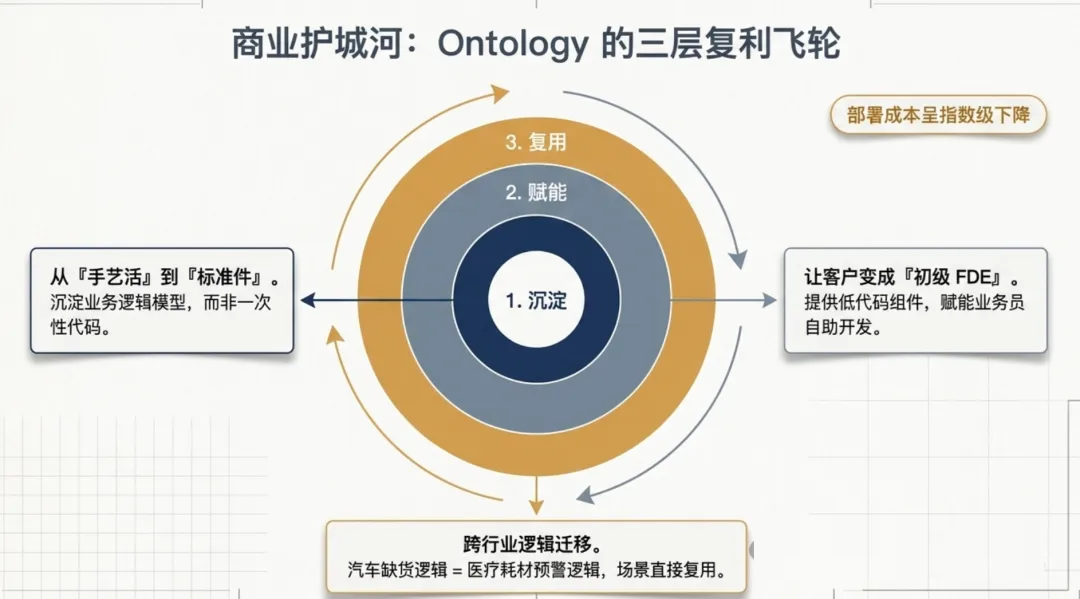
答案在于 Ontology 的资产化能力——通过三个层次的复利效应。
第一层:沉淀——从"手艺活"到"标准件"
第一个 FDE 在某银行解决了反洗钱建模问题。他离开时,留下的不是一套代码,而是一系列被封装好的"数据模板"和"逻辑套件",叫做反洗钱本体模型。
第二个银行项目开始时,新的 FDE 不再需要从零开始写 ETL。他直接调用这套已经被验证过的反洗钱本体模型——改几个参数就能适配新客户。
沉淀的结果是:每一次部署都在降低下一次部署的成本。
第二层:赋能——让客户的 IT 变成"初级 FDE"
一个更聪明的手段是:在项目后期,FDE 会刻意让自己"失业"。
怎么操作?通过 Foundry 平台提供的低代码工具(Workshop),FDE 把复杂的底层逻辑包装成简单的拖拽组件。
结果是什么?企业内部那些只会写简单 SQL 或只会用 Excel 的普通业务员,经过几周培训后,就能在
FDE 搭建好的框架上,自己开发新的分析应用。
不是 Palantir 帮他做,是 Palantir
帮他学会自己做。
第三层:复用——跨行业的逻辑迁移
最有意思的在这里。
汽车制造业的"零部件缺货预警"逻辑,和医疗器械的"耗材库存预警"逻辑——在
Ontology 层面,几乎是一回事。
FDE 只需要把"飞机机尾号"换成"医院科室",把"装配工位"换成"手术室"——逻辑完全复用。
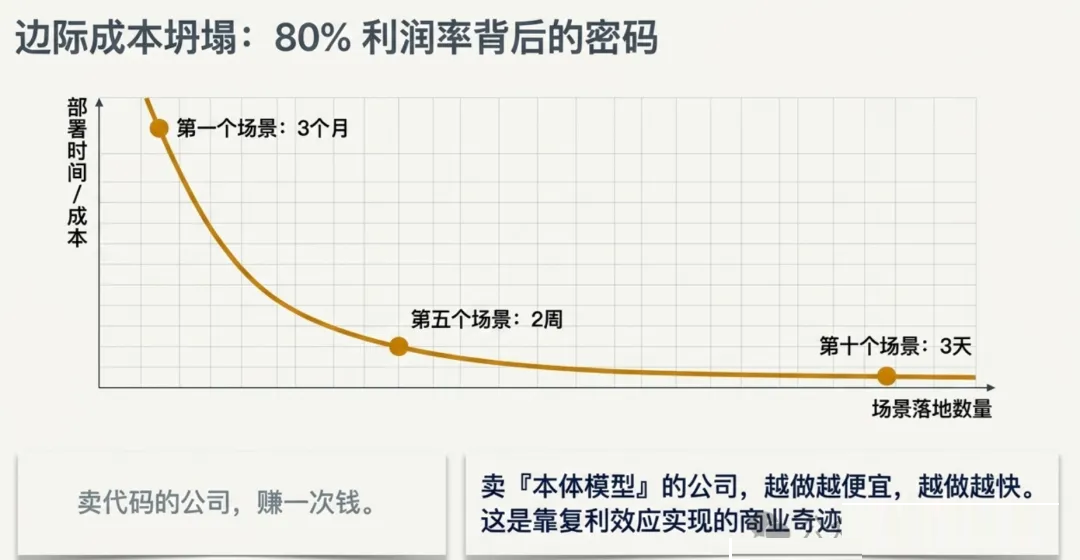
滚雪球效应一旦形成:
•
第一个场景落地可能要 3 个月
•
到了第五个场景,可能只需要 2 周
•
到了第十个场景,可能只需要 3 天
|
这就是 Palantir 能做到 80% 利润率的秘密——不是靠技术壁垒,而是靠"本体模型"的复利效应。卖代码的公司赚一次钱。卖"本体模型"的公司,越做越便宜、越做越快。
五、AI 时代的 Ontology:FDE 从"搬砖"到"定义"
最后,说说 AI 怎么改变了这件事。
以前 FDE 的时间去哪了?
70% 消耗在极其枯燥的"体力活"上:
•
对着几千个乱码一样的字段名猜业务含义
•
写 SQL 脚本清洗脏数据
•
调优 PySpark 代码
|
AI 成为"副驾驶"之后
在 AIP(Artificial Intelligence Platform)的加持下,AI 自动处理底层复杂性:
| 步骤 |
AI负责 |
FDE负责 |
| 需求捕捉 |
— |
用自然语言描述需求 |
| 自动建模 |
自动检索数据表、推断字段含义、建议挂载方式 |
确认逻辑无误 |
| 策略模拟 |
自动模拟多种方案,计算成本和成功率 |
选择最优方案 |
| 安全围栏 |
自动生成前端看板和操作按钮 |
最终审查确认 |
结论: AI 负责搞定所有的底层复杂度,FDE
只需要负责"定义实体"和"最终确认"。
但恰恰是"定义实体"这件事——定义这个工厂里什么东西是重要的、这些东西之间有什么关系、什么情况下应该做什么动作——是
AI 永远无法替代的。
因为"什么东西重要"这个判断,依赖于对业务的深层理解。而这种理解,只能来自坐在车间里听业务员说了三天"老张""那架飞机""3号线"之后,才能建立起来。
六、结尾
写到这里,回到开头的那个问题:
为什么花了几千万建了数据中台,还是没法做决策?
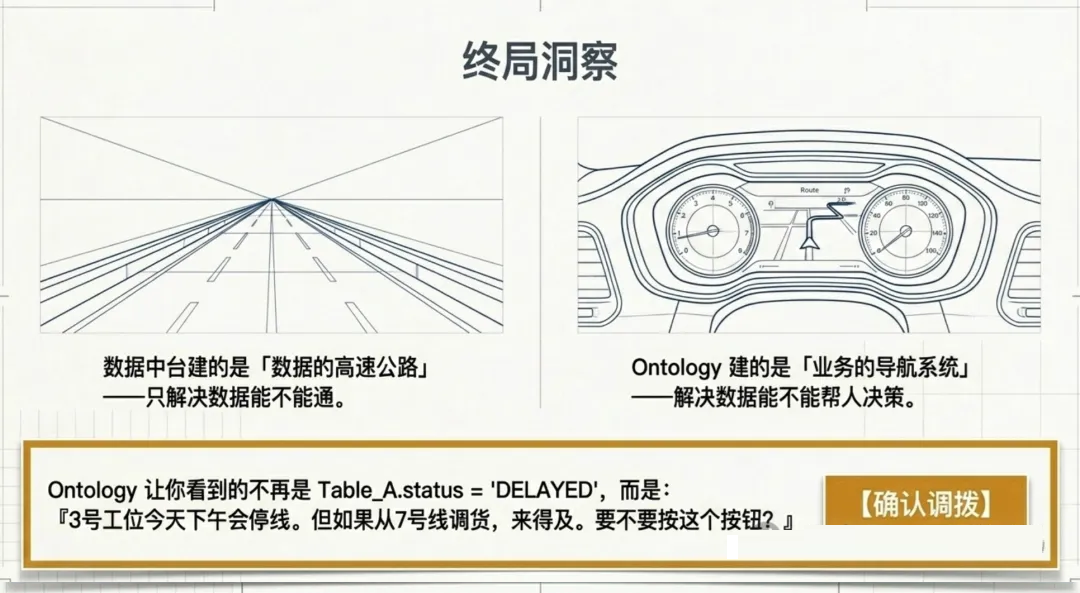
因为你在建的是"数据的高速公路",而不是"业务的导航系统"。
数据中台解决的是"数据能不能通"的问题。Ontology 解决的是"数据能不能帮人做决策"的问题。
Ontology 的本质,不是在加工数据,而是在翻译业务。
数据库把一切压扁成表和字段。Ontology 把它们还原回立体的商业世界。
FDE 在做的,就是那个翻译。
他让一个工厂的总监看到的不再是「Table_A.status_code = 'DELAYED'」,而是——
"3号工位今天下午会停线。但如果从7号线调这批货过来,来得及。要不要按这个按钮?"
|
这才是人做决策时,真正需要的东西。 | 






 订阅
订阅