| 编辑推荐: |
本文主要介绍了如何通过构建“验证类Skill”,将团队的系统经验和验收标准固化为Agent的工作流程,以解决AI生成代码后“审不完、验不透、记不住”的工程可靠性问题,希望对你的学习有帮助。
本文来自于架构师,由火龙果软件Alice编辑推荐。 |
|
这几个月我们一直在梳理一条线:Agent 进入真实研发以后,问题不再只是“会不会写代码”。
更麻烦的是后面几步。
写得出,审不完。
跑得快,验不透。
这次修好了,下次换个会话又忘了。
读 Anthropic 这篇 Claude Code Skills 实践时,我没有停在九类 Skill 或 SKILL.md 写法上。让我停下来的,是它把一个工程现场问题摆到了台面上:
当 Agent 的生成能力越来越强,团队更该写进系统里的,往往是验证经验。
Anthropic 原文里有一句话很醒目: Verification skills have had the most measurable impact on Claude's output quality internally.
放到工程现场里看,很多时候,改善 Claude 输出质量的一条路,是把“怎么证明自己写对了”这件事讲清楚,而不只是继续补代码写法。
这和我们前面聊 Skills、 Hooks 、Dynamic Workflows、数据级 Harness ,其实是同一条线。
只不过这次更具体。
它没有停在“AI 工程化”这个大词上,而是给了一个团队可以先动手做的小东西: 验证类 Skill 。
先说结论
可以先收成几句话:
- Skill 可以看成一个目录。 SKILL.md 是入口,脚本、模板、配置、参考资料、失败记录都可以放在旁边。
- 验证类 Skill 的价值很高。Agent 往往不缺生成能力,缺的是知道“在你们系统里,什么才算做完”。
- gotchas 可以当成团队踩坑后的回归记忆。它告诉 Agent:这些旧错不要再犯。
- Skill 的 description 直接影响模型路由。它决定什么时候该加载这个 Skill。
- hooks、marketplace、usage metrics 说明 Skill 正在从个人提示词,进入团队级过程资产。
- 落地可以先不碰平台。挑一个高频、高风险、能验证的流程,写一个小的 verification Skill。
- 第一版不用覆盖所有场景。能稳定触发、能跑一条验证路径、能留下证据、能记录失败,就已经有价值。
瓶颈后移
以前我们评估 AI Coding,经常看它能不能把代码写出来。
现在这个问题当然还重要,但已经不是全部。
在很多团队里,更常见的卡点变成了:
| 环节 | Agent 很擅长 | 团队更担心 |
| 生成 |
快速写出 diff |
有没有改错边界 |
| 解释 |
给出一套听起来顺的理由 |
理由和真实系统是否一致 |
| 修复 |
根据报错继续改 |
会不会越改越远 |
| 总结 |
写一段完成说明 |
有没有证据证明完成 |
| 复用 |
下次重新生成 |
上次踩过的坑是否留下来 |
这也是为什么单纯追求“更会写代码”的 Skill,收益会很快变薄。
Claude 已经会读代码、会写测试、会改 bug、会调用工具。更容易缺的,是团队自己的工作现场:
- 哪张表才是真实状态;
- 哪个字段不能动;
- 哪个接口返回 200 也不代表成功;
- 哪个服务改了以后还要查下游;
- 哪类变更需要先过安全或兼容性门禁。
这些东西,模型训练语料里没有。
类似的工程张力,在国内很多大仓、多服务、多仓协作里也很常见。
AI 一旦进入生产链路,就要面对流程、拓扑、契约、知识和演进这些业务约束。
换到 Claude Code Skills 这里,验证类 Skill 正是在补这层东西。
它把“做完的标准”写给 Agent。
三个乘号
这件事可以先压成一个很粗的公式:
Agent 可靠产出 = 模型能力 × 上下文质量 × 验证闭环
|
模型能力越来越强,这是大趋势。
上下文质量,决定 Agent 知不知道自己在什么系统里干活。
验证闭环,决定它做完以后有没有办法证明结果站得住。
这里值得看的,是乘号。
上下文接近零,模型再强,也会在错误路径上跑得很快。
验证闭环接近零,代码生成得越快,团队后面越累。
很多“AI 写得不可靠”的问题,表面看是模型问题,落到真实仓库里,常常是两件事没写清:
第一,任务现场缺什么上下文。
第二,完成以后用什么证据收口。
Skill 适合处理第一类。
Verification Skill 则把第二类也一并拉进来。
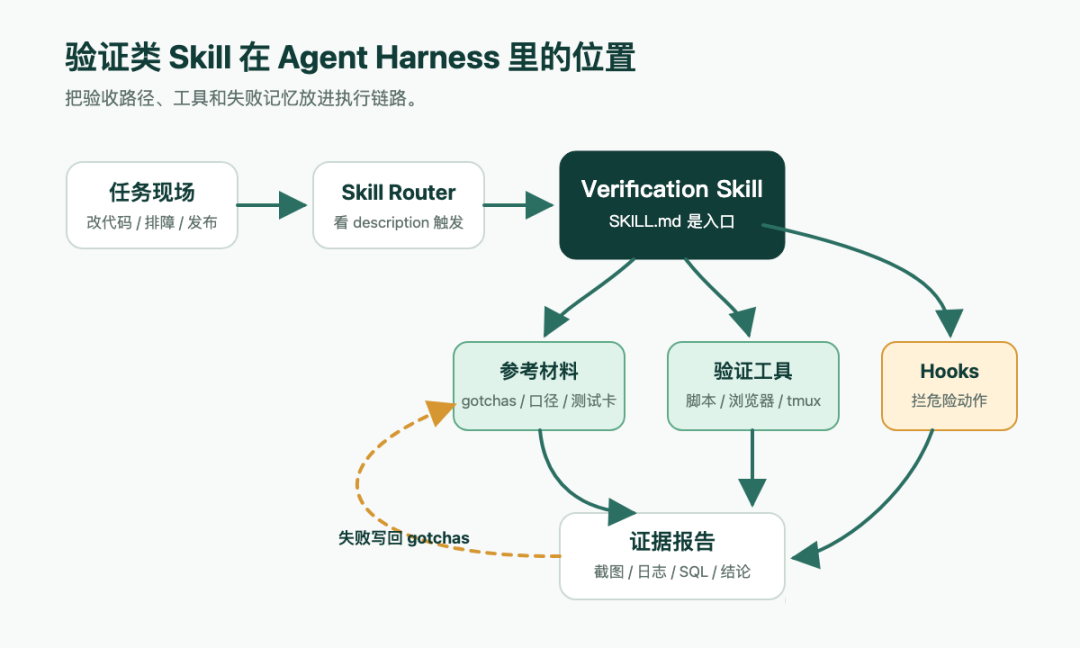
图1:验证类 Skill 在 Agent Harness 里的位置
这张图里我会多看后半段:参考材料、验证工具、Hooks 和证据报告要连起来。连起来以后,失败才有机会写回 gotchas,下一次任务也少一点重复试错。
Skill 是目录
Anthropic 这次给出的定义很具体:Skill 是一个文件夹,里面通常不止一个 Markdown。
一个验证类 Skill,可以长这样:
.claude/skills/checkout-verifier/
SKILL.md
references/gotchas.md
references/test-cards.md
scripts/run_checkout_flow.js
assets/report-template.md
logs/failures.log
|
这比“写一个很长的提示词”更接近工程制品。
SKILL.md 负责入口:
- 什么时候用;
- 什么时候不能用;
- 这个 Skill 能帮 Agent 找到哪些文件;
- 最后要留下什么证据。
详细 API、业务口径、测试卡、验收报告模板、失败记录,都不需要塞进同一个文件。
Agent 需要的时候再读。
这就是 progressive disclosure,渐进式披露。
前面几篇写 Skills 时,我们一直把它叫做过程资产。今天再看,可以再补一句: 好的 Skill 少堆知识,多把任务现场拆成 Agent 能按需加载的工程材料。
Addy Osmani 在 Agent Skills 那篇文章里也有个说法,放在这里很贴切: Process over prose 。
换成工程话说,Skill 不是把经验写成一篇更长的说明文。
它更像把“下一步怎么做、做到哪一步能退出、中间哪些坑要避开”写进 Agent 的工作路径。
知识堆得太多,会变成上下文噪声。
材料分层放好,才有机会变成可复用的流程。
先写验收
Anthropic 把内部 Skills 归成九类:库和 API 参考、产品验证、数据分析、业务自动化、脚手架、代码质量、CI/CD、runbook、基础设施操作。
分类本身有价值,但我更关心第二类:产品验证。
因为它和可靠性贴得最近。
几类 Skill 放在一起看,差别会更清楚:
| 类型 | 它帮 Agent 做什么 | 常见短板 |
| API 参考 Skill |
知道库、CLI、SDK 怎么用 |
只能保证调用看起来像样 |
| 脚手架 Skill |
快速生成模板和样板代码 |
模板错了会复制很多次 |
| 流程自动化 Skill |
把重复动作压成一次调用 |
自动化也会自动放大错误 |
| 验证 Skill |
知道怎样证明结果有效 |
成本更高,但能留下证据 |
图2:普通提示词、生成类 Skill、验证类 Skill 的差别
图 2 的差别就在这里:验证类 Skill 多了一件事。它让 Agent 完成动作以后,还要交代证据从哪里来。
比如一个支付流程验证 Skill,如果只写一句“记得测试支付”,效果通常有限。
那和写在 PR 模板里的提醒差不多,Agent 可能看过就算。
更扎实的写法,是把验收路径拆出来:
- 用哪些测试卡;
- 前端页面要走哪些步骤;
- 每一步怎么断言页面状态;
- 后端订单、发票、支付事件分别查哪里;
- webhook 失败或延迟时怎么重试;
- 最终报告里要放哪些证据。
Anthropic 原文里给了几个贴近工程现场的例子。
signup-flow-driver 走注册、邮箱验证、onboarding,并在每一步断言状态。
checkout-verifier 用 Stripe 测试卡驱动结账 UI,再确认发票确实进入正确状态。
tmux-cli-driver 则服务于交互式 CLI 测试,因为有些东西没有 TTY 就验不准。
这几个例子其实都在做同一件事:把任务完成前的检查动作显性化,让 Claude 交付之前走完一条可观察的验证路径。
有些场景还可以让 Claude 录屏,或者在每一步写程序化断言。
这比“我看起来测过了”更接近工程验收。
这类信息具体,而且很难通用化。
模型知道怎么写测试,但不知道某个系统里哪张表是准的。
模型知道怎么查日志,但不知道 @request_id 和 trace_id 在两个服务里其实指同一个东西。
模型知道 HTTP 200 是成功,但不知道某些 staging 环境里 200 可能只是网关成功,支付事件并没有实际落库。
这些不是编程技巧。
这是系统经验。
验证分层
落到团队里,verification Skill 不必只理解成“跑测试命令”。
常见形态可以先拆几类:
| 验证 Skill | 适合场景 | 证据形态 |
| UI 流程验证 |
注册、结账、onboarding、后台表单 |
截图、录屏、页面状态、后端记录 |
| CLI / TTY 验证 |
交互式命令行、脚手架、迁移工具 |
tmux 会话、命令输出、退出码 |
| 数据状态验证 |
指标口径、支付状态、订单流转、报表 |
SQL 结果、事件记录、口径说明 |
| 发布验证 |
灰度、回滚、配置变更、依赖升级 |
CI、烟测、错误率、日志对比 |
| Review 验证 |
大 PR、跨服务改动、安全敏感改动 |
diff 摘要、风险清单、review 结论 |
这张表不是官方分类,只是一个方便落地的拆法。
它的用途,是把问题收窄:先不问“要不要做 Skills 平台”,先看“哪条链路最需要被证明”。
比如:
- 支付团队,先做 checkout verifier;
- 数据团队,先做 metric verifier;
- 平台团队,先做 deploy verifier;
- 工具团队,先做 tmux-cli verifier;
- 大仓团队,先做 PR review verifier。
一条链路跑通后,再扩展第二条。
旧坑入库
Anthropic 这篇里,gotchas 这一段很有现场感。
在普通文档里,它可能只是“注意事项”。
放到 Agent 语境里,gotchas 更像一组轻量回归测试:
- 这类字段别按名字猜;
- 这个状态要看数据库,不要只看页面;
- 这个接口要等异步事件;
- 这张表是 append-only,别拿 created_at 排序就下结论;
- 这个模块过去因为分页无上限出过问题,新增查询时先看限制。
它不一定可执行,但它会改变 Agent 的默认路径。
这能接上我们前面写“自我修复”的那篇。
一次错误如果只停在聊天记录里,下次大概率还会重来。
一次错误如果能进入 gotchas.md 、验证脚本、hook 或门禁,它就开始变成团队资产。
更重的团队治理做法,也会把团队经验写进项目上下文,再通过复盘让错误沉淀到下一次任务里。
Claude Code Skills 的 gotchas 没有那么重,但方向是一样的。
旧坑只靠老人记、靠新人问,很容易丢。把它写进 Agent 的工作路径,成本不高,收益也更稳定。
描述管触发
还有一个常被忽略的小细节:Skill 的 description 。
很多人会把它写成人类简介:
description: A useful skill for checkout testing.
|
这句话有用,但不够。它没有说清楚什么时候触发。
对模型更友好的写法,大概会像这样:
description: Use when code touches checkout, payments, invoices, billing state,
Stripe webhook handling, or any task that requires end-to-end billing verification.
|
这不是文采问题,更多是路由问题。
Claude Code 启动时会看到可用 Skills 的名称和描述。它靠这些描述判断当前任务要不要加载某个 Skill。
描述写得像宣传语,就容易漏触发。
描述写得太宽,又容易误触发。
所以一个 Skill 的入口,可以说清三件事:
这里还有一个小边界。
Claude Code 官方文档里提到,如果 Skills 很多,描述会占用上下文预算,太长的描述可能被截断。换句话说, description 不是越详细越好。
我的经验是,第一句先放触发词和任务边界,后面再补少量约束。
比如:
description: Use for checkout, payments, invoices, billing state,
and Stripe webhook verification. Do not use for unrelated UI copy or pricing page edits.
|
这比写一大段“这个 Skill 很有用、可以帮助验证支付流程”更可控。
如果某个 Skill 总是没触发,可以先检查描述里有没有用户会自然说出来的词。
如果它触发太频繁,就把边界收窄,或者让它只支持手动调用。
这和我们 0517 那篇讲 Skill Router 时的判断一致:到了更复杂的系统,只找“语义最相似的 Skill”还不够,还要判断它在当前工作现场里能不能执行、能不能验证、风险能不能接受。
Hooks 刹车
Anthropic 文里提到两个按需 hooks: /careful 和 /freeze 。
这个设计挺务实。
/careful 面向危险命令。比如删目录、删表、强推、删除 Kubernetes 资源这类动作,在高风险场景里先拦一下。
/freeze 面向范围控制。比如排查问题时只允许在某个目录加日志,避免 Agent 顺手改了无关模块。
这里有个现实经验:刹车不一定要常开。
常开的高强度 hook 会打断节奏,也可能让开发体验变差。
但在生产排障、数据库迁移、权限改动、发布前修复这类场景里,临时打开它,就能派上用场。
Skill 负责告诉 Agent 怎么做。
Hook 负责在关键动作前问一句:这一步能不能做,范围对不对,证据够不够。
一个是流程,一个是约束。
两者合起来,才不像一段软提示。
团队治理
Anthropic 还讲了 Skill 分发。
小团队可以把 Skills 放在 repo 的 .claude/skills 下面。成本低,贴近项目,也容易 code review。
规模大了,可以走 plugin marketplace,让团队按需安装。
只要进入分发,Skill 就不再是个人提示词。
还有一个容易被低估的边界:Skill 既然可以带脚本、工具和参考资料,就要像代码资产一样 review。
尤其是从 marketplace 或外部仓库安装 Skill 时,可以先看几件事:
- 触发描述会不会过宽;
- 脚本会读写哪些路径;
- 是否调用外部网络;
- 是否可能把 token、日志、客户数据带出去;
- 失败时有没有降级方式。
它要面对几个团队问题:
- 谁维护;
- 谁 review;
- 什么时候触发;
- 触发错了怎么办;
- 用了以后有没有改善结果;
- 过期以后怎么降级或下线。
更重的团队做法,会把这层拆成流程、门禁、知识体系、Skill / Agent / Command 三件套,甚至适配多种运行时。
普通团队不必照搬那套规模,但它提供了一个参照: 当 AI 协作进入团队级研发,流程、知识、门禁和经验都要变成可版本化的工程制品。
Claude Code Skills 是其中更轻的一层。
轻,并不等于弱。
它可以先从一个目录、一个脚本、几条 gotchas 开始。
一条链路
团队刚开始试 Skills,不妨先避开“大而全”。
先找一个高频、高风险、边界清楚的流程。
比如:
- 注册到 onboarding;
- 支付到开票;
- 一个数据指标从口径到 SQL 到报表;
- 一次 灰度发布 ;
- 一个 PR 从修改到 review 到合并;
- 一次线上告警排查。
然后只做一个 verification Skill。
选第一条链路时,可以用四个条件筛:
| 条件 | 为什么 |
| 高频 |
低频流程不值得先工程化 |
| 出错有代价 |
没风险的流程,用普通提示词就够 |
| 验证路径清楚 |
说不清怎么验,先写成普通流程文档 |
| 证据能保存 |
没证据,下一次还是靠感觉 |
四条都满足,再写 Skill 会省力很多。
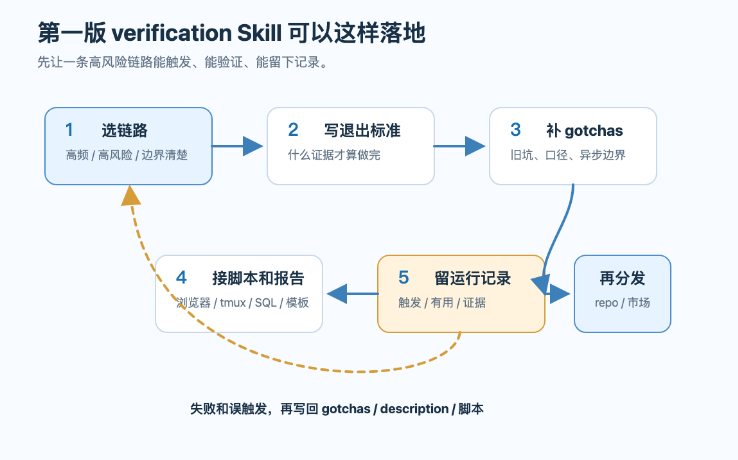
图3:第一版 verification Skill 的落地流程
第一版不用做厚。能把触发条件、退出标准、旧坑和证据记录串起来,就已经从“提醒 Agent”往“约束流程”走了一步。
第一版可以很小:
---
name: checkout-verifier
description: Use when code touches checkout, payments, invoices, billing state, or Stripe webhook handling.
---
# Checkout Verifier
## When to use
Use this skill before claiming that a checkout or billing change is complete.
## Exit criteria
- Checkout completes with an approved test card.
- Invoice reaches the expected state in the billing system.
- Payment event is persisted and linked to the request id.
- Evidence is written into the final report.
## Gotchas
- A successful HTTP response is not enough; check persisted payment events.
- Use the canonical customer id from the billing table, not the UI label.
- If webhook processing is delayed, wait and re-check before marking the task complete.
## Tools
- Run `scripts/run_checkout_flow.js` for the browser path.
- Use `references/test-cards.md` for allowed payment cases.
- Write failures to `logs/failures.log`.
|
这个版本已经比“请认真测试一下”更可靠。
因为它写清楚了四件事:
- 什么时候用;
- 怎么退出;
- 哪些坑别踩;
- 证据放在哪里。
再补一点,可以给每个 verification Skill 留一份小的“运行记录”。
不用复杂,Markdown 表就够:
| date | task | triggered | result | new_gotcha | evidence |
|---|---|---|---|---|---|
| 2026-06-07 | checkout webhook fix | auto | failed | staging 200 can hide webhook failure | reports/checkout-20260607.md |
|
这张表的价值不在汇报,而在复盘:
- 该触发时有没有触发;
- 触发后有没有帮上忙;
- 失败是不是新增了 gotcha;
- 这个 Skill 是否越来越准;
- 有没有开始误伤不相关任务。
Anthropic 原文里提到,他们用 PreToolUse hook 记录 Skill 使用情况,找出哪些热门、哪些本该触发却没触发。小团队不一定一开始就上这套日志,先用一张轻量表,也能把问题看出来。
后面可以按这个顺序加东西:
- 先补 gotchas;
- 再补能跑的脚本;
- 再补报告模板;
- 再补按需 hook;
- 再看触发日志;
- 最后再考虑分发和 marketplace。
一开始把顺序反过来,风险也很明显。
很多团队一开始就想做 AI 工程平台,但第一批可信 Skill 还没写出来。
那就容易变成另一个内部知识库:入口很高级,内容不太敢用。
今天这篇再往里收一层:
Skills 里面最值得先做的,可能要从增加动作,转向补上“证明自己做对了”的路径。
生成能力当然还重要。
没有生成,后面这些都谈不上。
但当生成越来越便宜,模型外面的东西会越来越重要:上下文怎么给,流程怎么拆,验证怎么跑,失败怎么写回,危险动作怎么拦。
这些合在一起,才像一个能长期工作的 Agent Harness。
最后
我以前看 Skills,会先看它能帮 Agent 多做什么。
这次读 Anthropic 的实践,我更想问另一个问题:
它能不能把团队那些“不写下来就会反复出事”的经验,变成 Agent 每次都能用上的流程?
如果能做到这一点,它就不只是一个提示词技巧。
它是团队过程的一小块运行时。
这一小块不一定复杂。
可能只是一个 gotchas.md ,一段 checkout 验证脚本,一个报告模板,一个拦危险命令的 hook。
但这些东西能落地。
它们会把 Agent 从一句“我已经改好了”,拉回几个更具体的问题:
我怎么知道它改好了?
证据在哪里?
旧坑有没有再踩?
下一次遇到同类任务,能不能少靠一点运气?
所以,我更关注的是:验证经验能不能进入 Agent 的工作路径。 让 Agent 少记几句漂亮话,多带一点现场经验去干活。
| 






 订阅
订阅