| 编辑推荐: |
本文主要介绍了AI产品经理必须掌握的10个Agent核心概念(如感知、记忆、规划、推理、目标、工具使用、动作空间、观测、反思、多智能体协作),希望对你的学习有帮助。
本文来自于产品经理老王霸,由火龙果软件Alice编辑推荐。 |
|
多数 AI 产品经理在推动 Agent 落地时,卡点不是技术选型,而是连 Agent 到底在干什么都还没搞清楚。PRD 写了一堆,研发团队跑起来系统之后发现不稳定、不可控,第 6 周开始出现不可逆的返工。
问题不出在框架选型,也不出在模型能力,而是 10 个底层概念没有对齐 。凡是让研发先动手的,最后都绕回来重新讲概念。
老王复盘过多个 Agent 落地项目,得出的结论一致: 概念对齐先于一切 。这 10 个概念,先搞懂再动手。
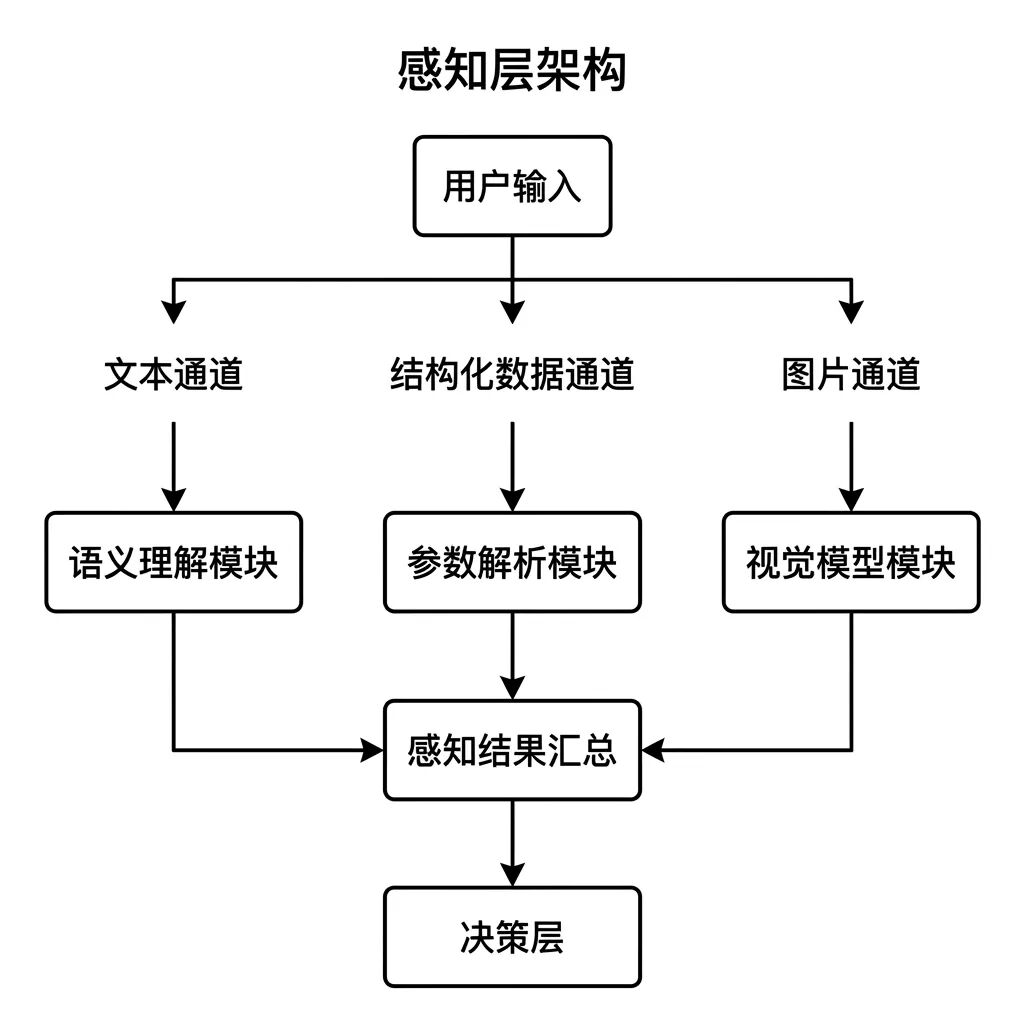
01 ️ 感知,Agent 能接收什么
你可以把 感知 理解成 Agent 的眼睛和耳朵,它能接收到什么信息,就只能在那个范围里做决策。超出感知范围的信息,对 Agent 来说根本不存在。
产品经理设计 Agent 时,最常犯的错是默认用户只会输入文字。但真实场景远不止于此。用户会上传表单数据、图片截图、结构化 JSON,工具执行后也会返回结果,这些都是 Agent 要处理的输入。
哪个通道没设计好,那个通道的信息就会被丢掉。信息一旦丢掉,后面的决策质量就已经上限了,再好的模型也补不回来。
老王在评估 Agent 感知层时,第一件事是列清楚所有 输入来源 和 数据类型 ,确认每种类型有没有对应的处理机制:
每个通道单独确认,不能笼统假设全部支持。
❗ 老王核心思考
感知层的完整性决定了信息边界,信息边界决定了整个 Agent 系统决策质量的上限。
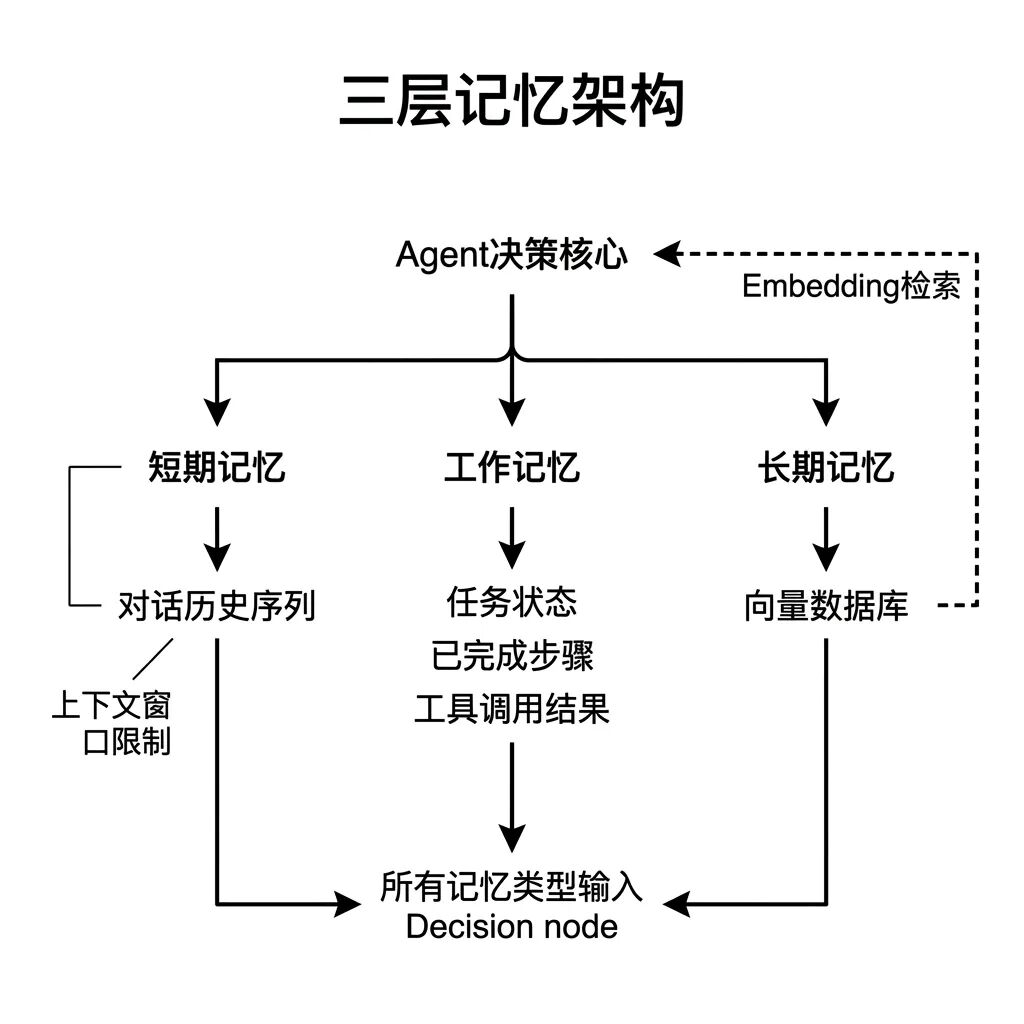
2. Memory,Agent 怎么记住事情
Agent 没有天生的记忆能力,它的记忆是通过 三套独立机制 拼出来的,分别对应不同时间维度。
短期记忆 存在对话历史里,也就是当前会话从头到现在的所有消息。这个空间是有上限的,一旦对话内容超过这个长度,最早的内容就会被截断。Agent 截断前说过的事,就真的不再知道了。多轮对话场景里,用户反映 Agent 忘记了之前说的需求,大多数原因都在这里。
长期记忆 存在 向量数据库 里。把历史信息转成向量,需要时根据当前问题去检索最相关的内容拿出来用。检索准不准,直接决定 Agent 拿到的背景知识质量够不够。老王的前面文章也讲过类似的思路。
工作记忆 是当前这个任务的中间状态,比如任务编号是什么、已经完成了哪几步、下一步要做什么、上一个工具返回了什么结果。这些临时信息要有专门的容器去存,否则 Agent 在多步任务里就会出现重复操作或者跳过关键步骤。
💡 梳理建议
三套机制各自独立,混在一起设计必然乱。产品经理在做 Agent 需求时,要先明确每类信息该走哪套记忆机制,测试时也要分别验证。
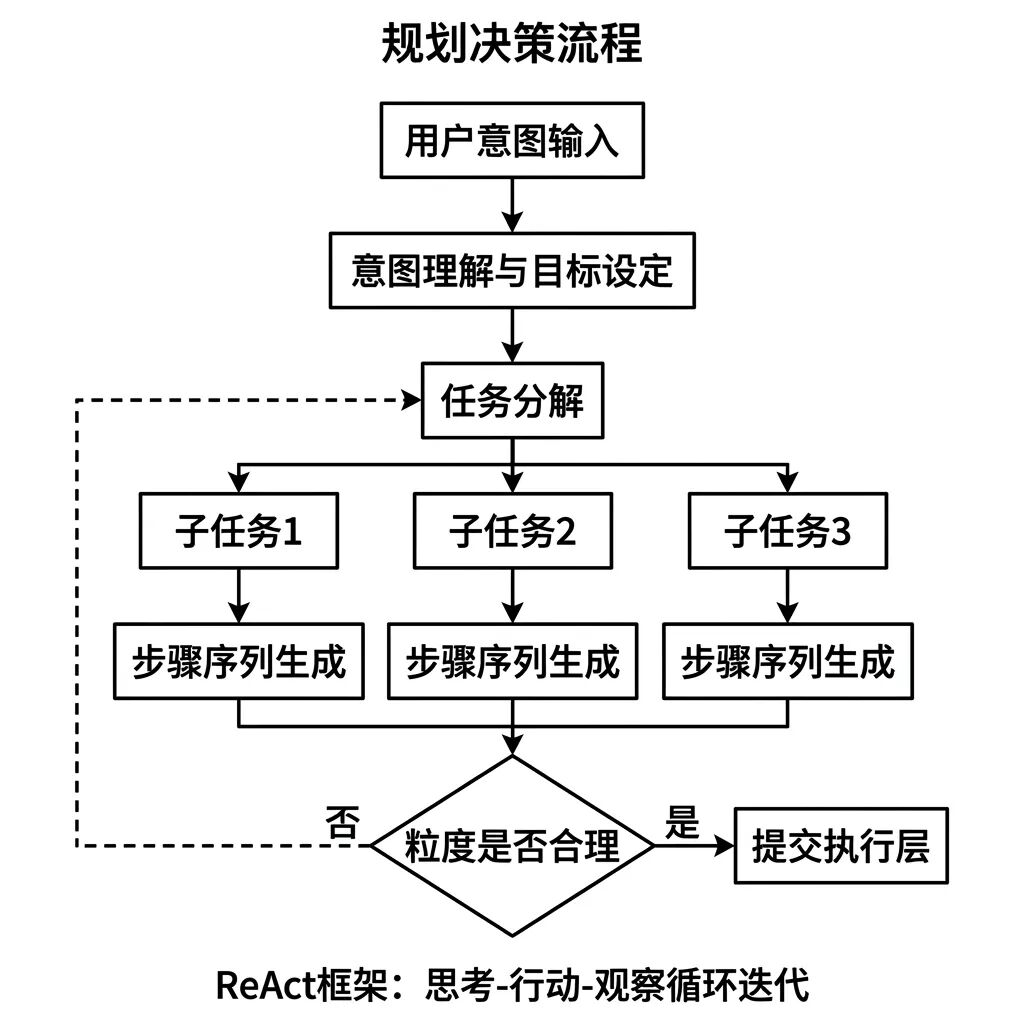
03. Planning,把模糊意图变成可执行步骤
用户说的是意图,但 Agent 要执行的是具体动作。中间那段从模糊到具体的转化,就是 Planning 在做的事。
很多人以为模型足够聪明,Planning 就自然搞定了。这个判断存在一个关键漏洞, Planning 的质量高度取决于 Prompt 设计,而不是模型本身的聪明程度 。同一个模型,换一套任务分解策略,执行质量可以相差 40% 以上。
目前主流的 Planning 框架叫 ReAct ,逻辑是 思考-行动-观察 的循环。Agent 先做推理,决定下一步要做什么动作,执行之后观察结果,再进入下一轮推理。每个中间步骤都可以看到,便于排查问题。
⚠️ 踩坑了
Planning 设计时最容易出问题的地方是 子任务的拆分粒度 。拆太粗,每步任务超出工具能力,执行失败;拆太细,步骤太多,累积误差上升。一个可操作的判断标准:每个子任务的输出结果必须是 明确可验证的 ,不能用"处理完成"这种没法判断的结论收尾。
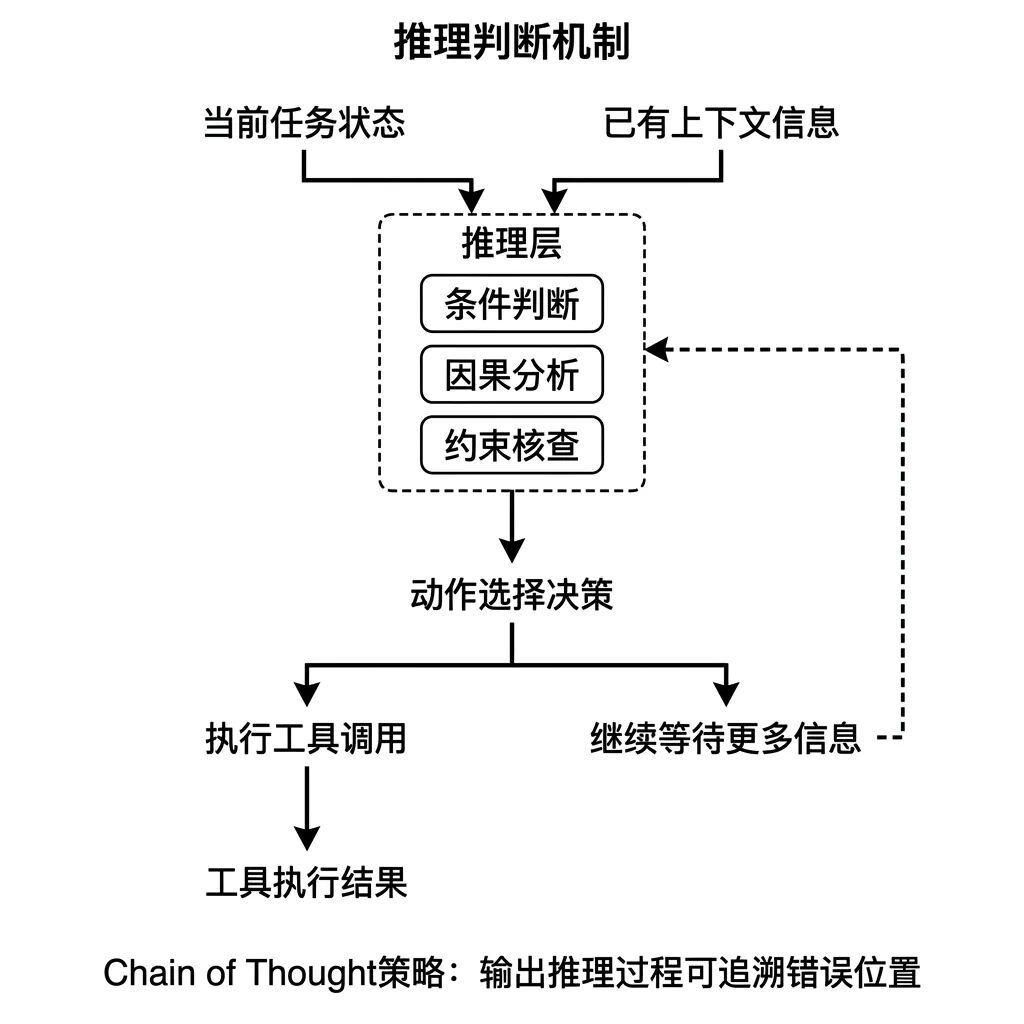
04 Reasoning,每一步动作前的判断过程
Planning 决定做什么任务, Reasoning 决定在具体这一步该怎么做。
两者的区别在于粒度:
- Reasoning → 步骤级别的判断,包括条件判断、因果分析、约束核查
在 ReAct 框架里,每一轮推理步骤就是 Reasoning 的体现。Agent 在执行下一个动作之前,先基于当前状态和已有信息,判断应不应该执行、执行什么、用什么参数。这个判断出错,Agent 就会调用不该调用的工具,或者参数填错,导致工具执行失败。
Reasoning 质量差,通常不是模型能力问题,而是输入信息不完整。 Agent 拿不到足够的上下文,只能基于残缺信息做推断,结论自然偏差。这意味着产品经理在评估 Agent 行为异常时,要先检查那一步 Agent 拿到的上下文是否完整,而不是先怀疑模型。
Chain of Thought 是提升 Reasoning 可靠性的一种常见策略,核心机制是要求模型输出推理过程,而不只是结论。有了推理过程,就能定位出错在哪一步,问题才能定向修复。
05
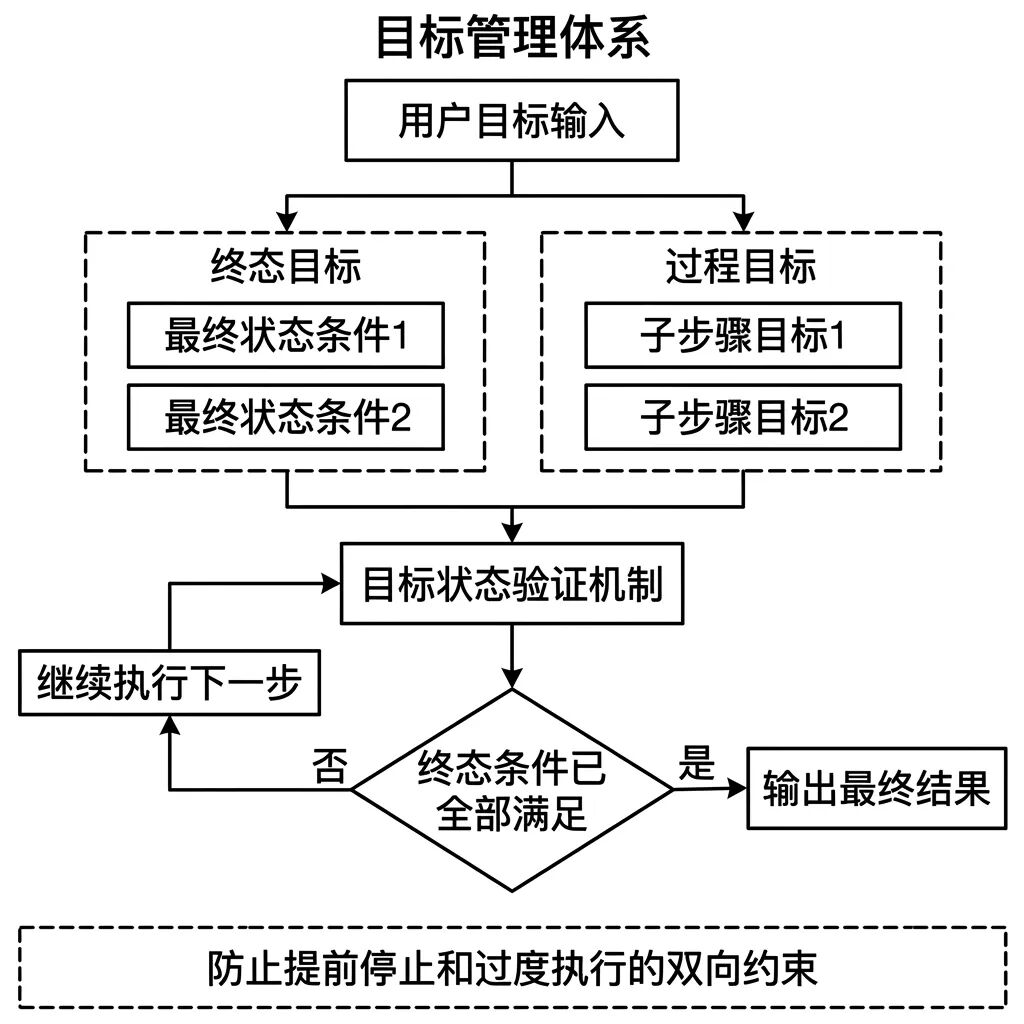
Goal,Agent 凭什么知道什么时候该停
没有明确的目标,Agent 就不知道往哪个方向走,也不知道什么时候算完成了。这是最直接的 失控来源 。
目标在工程上分两个层次:
- 终态目标 —— 描述最终要达成的状态,比如用户的问题已经得到准确回答,或者文件已经成功写入指定位置
- 过程目标 —— 描述每个子步骤的局部完成状态,比如当前轮次的信息已检索完毕、工具调用结果已记录
目标设计不清晰会导致两类问题:
- 提前停止 —— Agent 误判任务已完成,但实际上用户的需求没有被满足
- 过度执行 —— Agent 没有明确的终止条件,持续调用工具直到 Token 耗尽或触发系统限制,每次调用都在产生费用
❗ 产品设计思路
产品经理设计需求时,要在 System Prompt 里明确描述终态条件,同时设计一个显式的 任务完成验证机制 ,Agent 在输出最终结果之前先过一遍终态条件清单。这个机制不需要复杂,但必须存在。
目标体系设计是 Agent 可控性最核心的杠杆,比框架选型、比模型选择都重要得多。
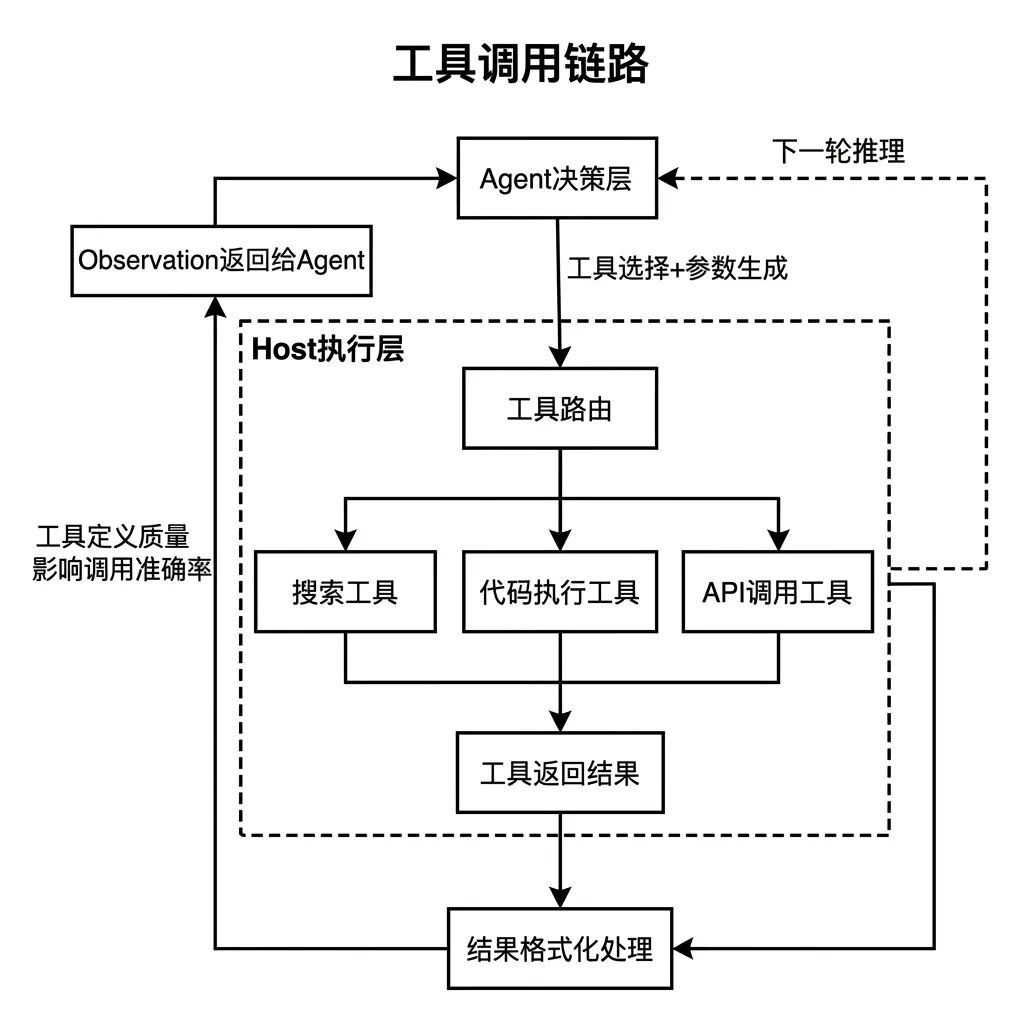
06 Tool Use,Agent 能做的事为什么不止聊天
LLM 本身只能生成文字。真正让 Agent 变得有用的原因,是它能调用 外部工具 。搜索网页、执行代码、查询数据库、发送请求、操作文件,这些能力全部来自工具调用,而不是模型自身。
工具调用分四步:
- 模型根据当前状态判断需要调用哪个工具、传什么参数
- Host 系统实际执行调用,等待工具返回结果
- 工具返回结果作为 观测值 传给 Agent
- Agent 基于这个结果继续推理,决定下一步动作
⚠️ 都是细节
工具的 定义质量 对调用效果影响很大。每个工具的名称、描述、参数说明,模型都会读取并依此决定如何调用。描述不清楚,模型选错参数,工具执行失败,整个链路就断了。和研发确认工具定义的清晰度,是产品经理在 Agent 需求阶段最容易忽视的事。
你需要在 System Prompt 里面把调用的工具以及它的参数约束好,以及返回的 JSON 格式。
工具数量也有上限。实测中,当 Agent 同时可以调用的工具超过 20 个 时,选择准确率开始明显下降,因为模型在工具选择阶段的判断负担加重。工具集应该按任务场景严格筛选,不能无差别地全部暴露给 Agent。
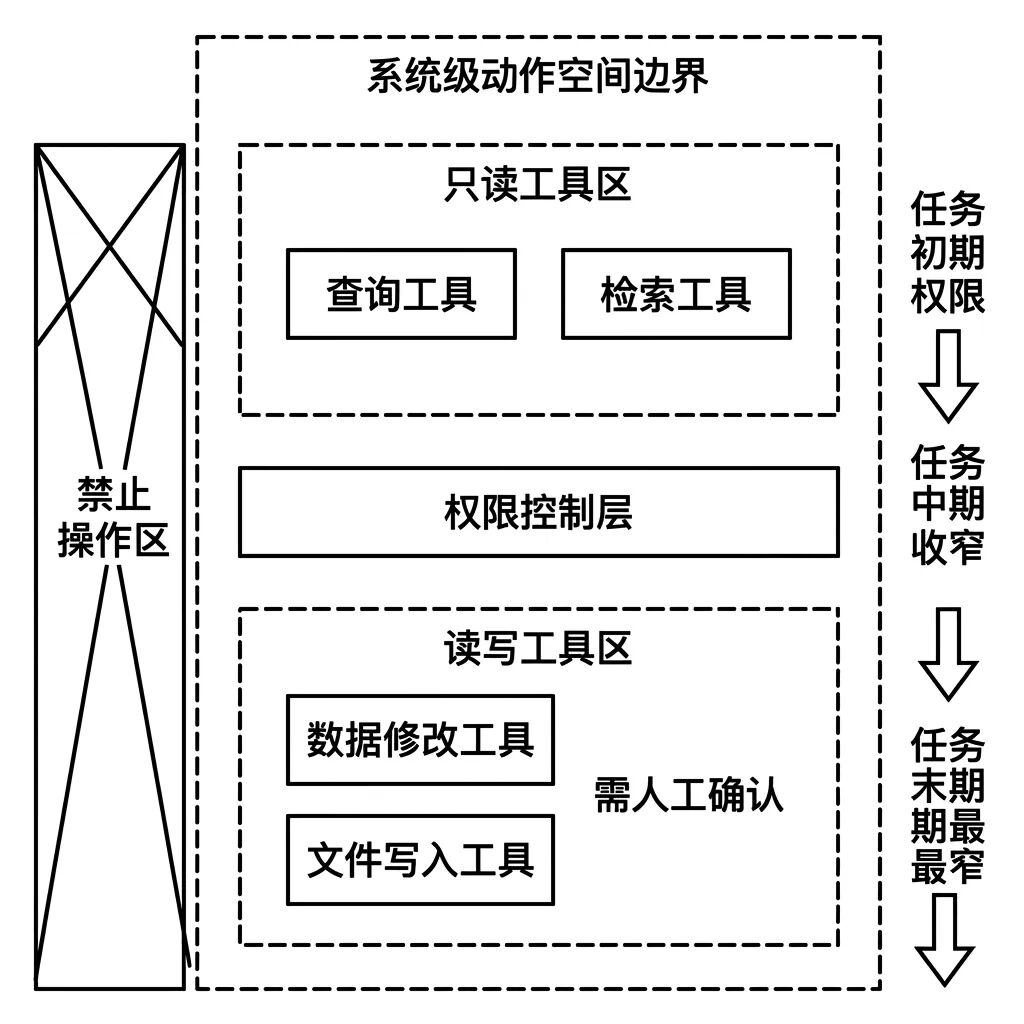
07 Action Space ,给 Agent 划定行动边界
Agent 被允许做的所有动作的集合,就是 动作空间 。这个边界不是靠 Agent 自己判断的,而是在系统层面硬性限定的。
这个概念对产品经理来说非常重要。Agent 能不能修改数据库,能不能写文件,能不能发外部请求,这些不是 Prompt 能控制的,是 系统设计层面必须明确划定的权限边界 。
🔴 安全红线
🔴 安全红线
动作空间设计过宽是 Agent 安全问题最常见的来源。内容生成类的 Agent 如果被给予了文件系统写入权限,在 Prompt 设计不当的情况下,可能覆写不该动的配置文件甚至核心数据。这类损失不是因为模型判断错了,而是因为系统从一开始就没有划定边界。
区分 只读工具 和 读写工具 是动作空间设计的基础:
- 只读工具 —— 风险极低,可以让 Agent 自主使用
- 读写工具 —— 涉及状态修改,必须配合人工确认或审核机制,不能让 Agent 单独决策
高风险业务场景里,动作空间还应该随任务阶段 动态收窄 ,任务启动阶段和执行中期可以用的工具集不一样,按阶段逐步放开权限,而不是一次性全部开放。
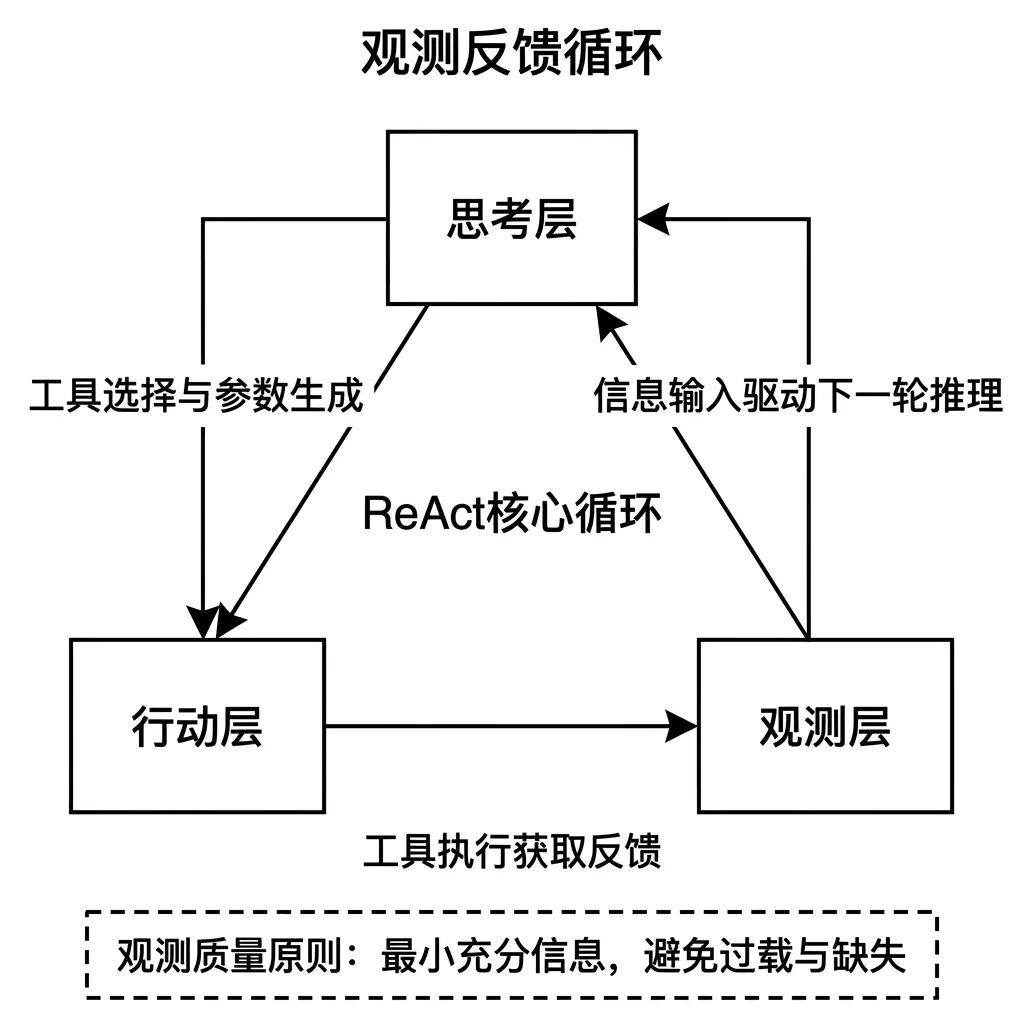
08 Observation,执行之后 Agent 怎么知道发生了什么
Agent 执行完一个动作之后,环境会给它一个反馈,这个反馈就叫 Observation 。它是 Agent 进入下一轮推理的唯一信息来源。
Think-Act-Observe 是 Agent 运作的基础循环,三个环节缺一不可。Observation 的质量直接决定下一轮推理能不能正常推进。
Observation 有两类常见的工程问题:
- 信息过载 —— 工具返回了大量原始数据,内容太多,Agent 反而抓不到真正有用的信号,做出的判断反而不如拿到更少但更精准数据时的效果
- 信息缺失 —— 工具出错时只返回了空值或通用错误码,Agent 从中无法推导出任何有意义的后续动作,整个链路就此卡住
💡 设计思路
设计 Observation 的基本原则是 最小充分 :返回的信息足够支撑下一步决策,但不引入无关噪声。如果工具返回的原始结果很长,应该在工具层先做一次提炼,而不是把原始内容直接扔给 Agent 处理。
多步任务里,历史 Observation 也会占用上下文窗口。随着步骤增多,早期 Observation 会被截断。工作记忆管理的一个核心要求,就是只保留对当前决策仍然有效的 Observation,不再有效的及时清理。
09 Reflection,Agent 能不能发现自己做错了
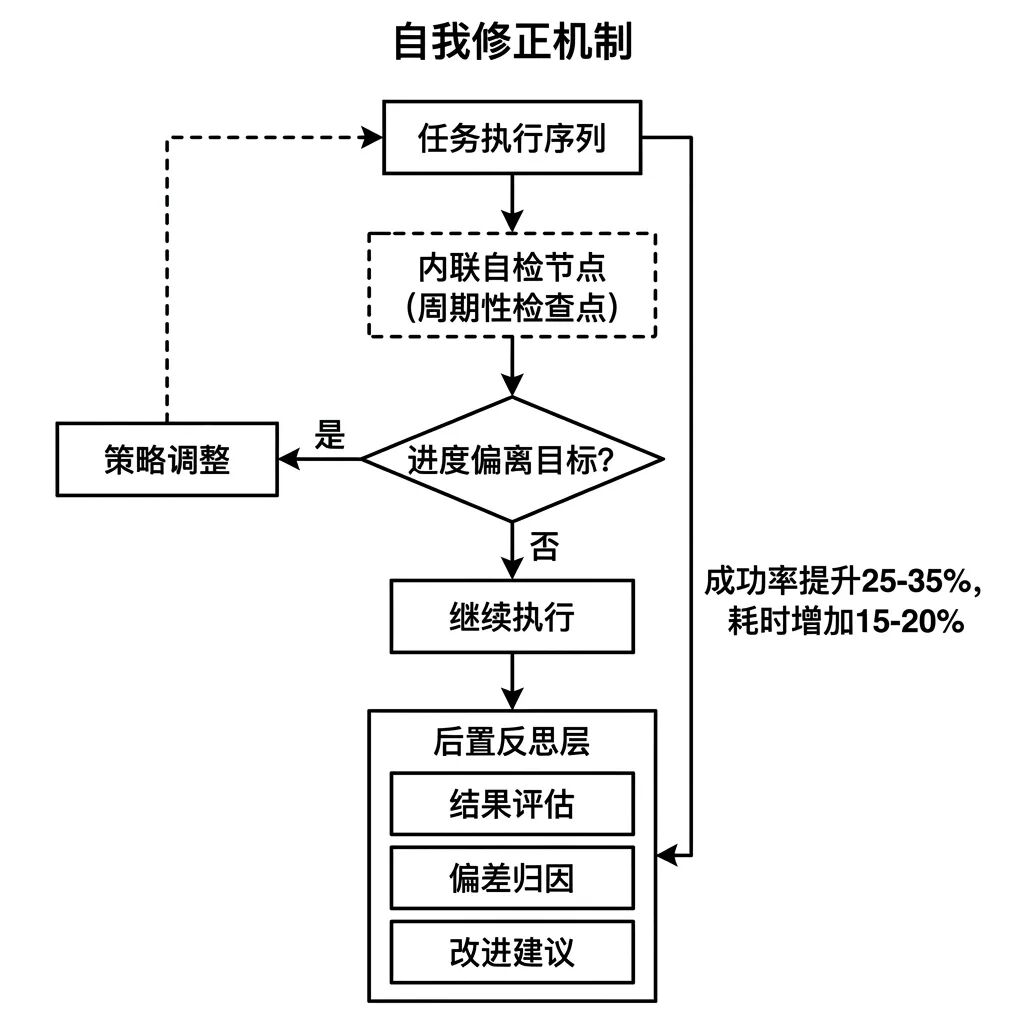
Reflection 是 Agent 对自身执行结果进行评估和修正的能力。Agent 执行完一段任务序列,主动判断结果是否符合预期,识别偏差并调整后续策略。
没有 Reflection 的 Agent,遇到偏差只会继续错下去,因为它没有机制发现自己在偏航。有了 Reflection,Agent 才能在中间环节检测到偏差并主动纠偏。
Reflection 的实现分两类:
- 内联 Reflection —— 在任务执行过程中嵌入周期性自检节点,每隔若干步骤暂停一次,评估当前进度是否偏离目标。响应快,但每次自检都消耗额外 Token
- 后置 Reflection —— 任务完成后整体复盘,评估结果、归因偏差、产出改进建议,适合长期运行的 Agent 系统用来积累经验
⚠️ 概念辨析
Reflection 和重试是两件事,不能混用。 重试是失败后重复执行相同动作,Reflection 是在评估失败原因之后调整策略再执行。区别在于有没有对失败原因进行分析。重试不分析原因,只是机械重复,第二次大概率还会失败。
加入 Reflection 机制的 Agent 系统,在复杂多步任务上的成功率平均提升 25-35% ,但任务总耗时也会相应增加 15-20% 。产品经理决策是否引入 Reflection 时,需要评估这个成本收益比是否适合当前场景。
10 Multi-Agent,什么时候需要多个 Agent 协作
多个 Agent 实例协同工作来完成一个任务,这种架构叫 Multi-Agent 。它解决的是单 Agent 在上下文长度、并发能力、能力边界上的天花板问题。
单 Agent 的核心限制是 上下文窗口 。当一个任务需要的信息量超过单个上下文窗口能装下的范围时,Agent 必然要丢失部分信息,决策质量因此下降。Multi-Agent 的出发点是把任务拆开,让不同 Agent 各自持有局部但完整的上下文,再通过协调机制汇总结果。
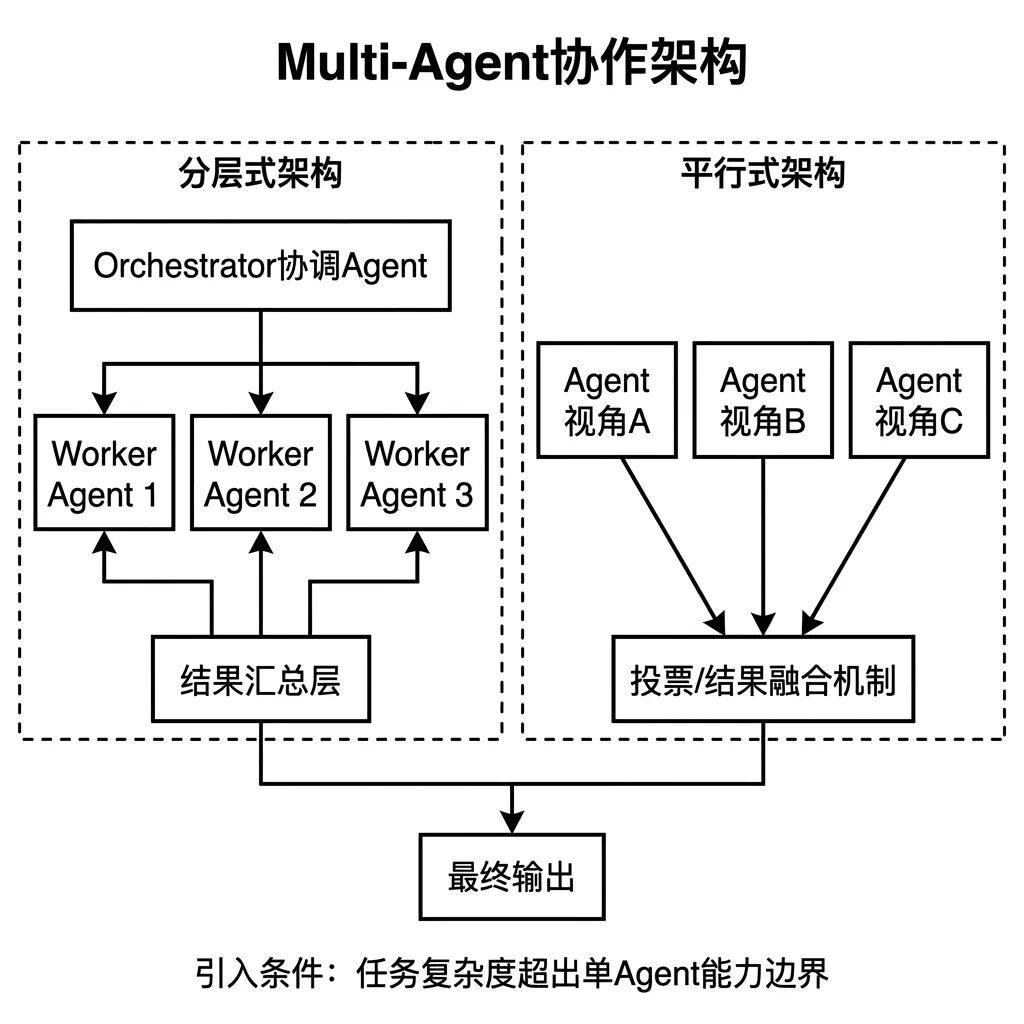
Multi-Agent 有两种主流架构:
- 分层式架构 —— 一个协调 Agent 负责任务分解和结果汇总,若干执行 Agent 各自负责具体子任务。协调 Agent 不直接操作工具,只处理协调逻辑。边界清晰,适合大多数业务场景
- 平行式架构 —— 多个对等 Agent 各自独立处理同一个任务,最后通过投票或结果融合确定最终输出,适合需要多视角验证的高精度场景,比如代码评审、风险评估
🔴 引入决策标准
Multi-Agent 带来的新问题是 协调成本 。多个 Agent 并发运行时,如何避免重复操作、如何处理冲突结果、如何追踪整体状态,这些问题的复杂度不低于单 Agent 本身的设计。
只有一个判断标准:任务的复杂度或规模明确超出单 Agent 能力边界时才引入。 单 Agent 能完成的,不用 Multi-Agent。引入多智能体架构意味着系统复杂度显著上升,调试难度成倍增加,不是越多越好。
11.最后
10 个概念相互依赖,哪一条没对齐,最终都会用不同的症状显现出来——产品功能异常、成本超预期、系统不稳定——根因几乎全部指向同一个问题: 概念没有在产品团队和研发团队之间真正对齐过。
Agent 系统的可控性不是调出来的,是设计进去的。 概念对齐是设计的前提,这一步跳过了,后面的每一步都在还债。
| 






 订阅
订阅