| 编辑推荐: |
本文主要介绍了都是
AI Coding,为什么 Java 体验差了一个量级?五条方法论帮你构建自己的
Harness 环境相关内容。希望对你的学习有帮助。
本文来自于微信公众号阿里云开发者,由火龙果软件Alice编辑,推荐。 |
|
1. 体验差距到底在哪
在依赖比较轻的项目里(比如前端、CLI 工具、纯本地的 Python 脚本),AI Coding
的体验是这样的:
编辑代码 → 本地运行 → 测试验证 → AI 读取结果 → 自动修复 → 再次验证 → ...
|
整个循环在本地完成,不需要人盯着。你甚至可以用上 autoresearch 的思想,和 AI 说:「帮我持续优化迭代这个功能,排查并修复bug,至少10轮」,AI
Agent 就可以自己迭代几十轮,直到功能跑通。
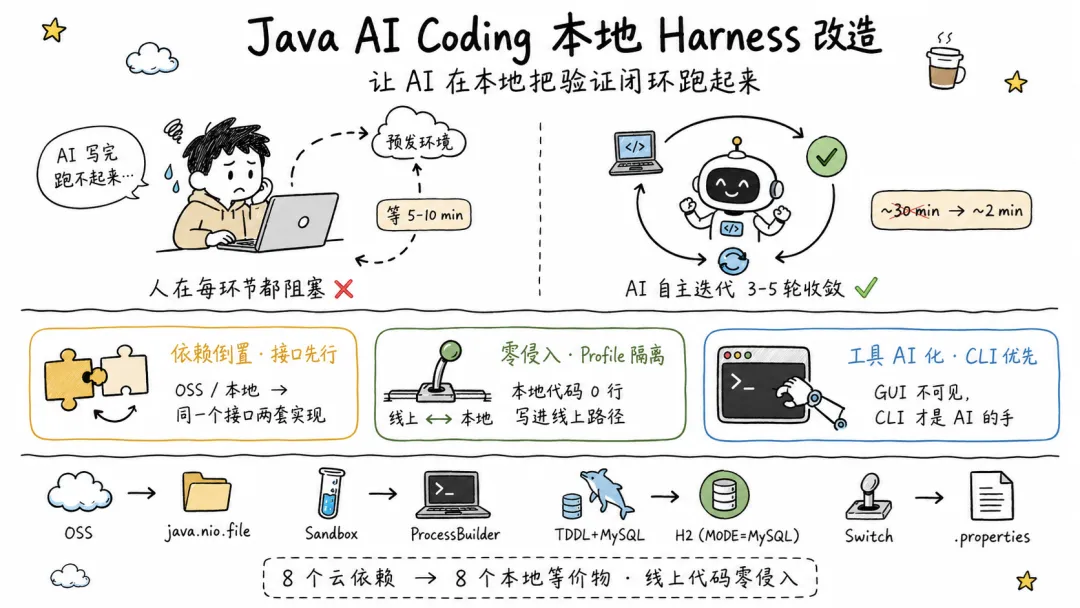
但 Java 微服务项目里,这个闭环基本是断的。
这周让 AI 给一个 Agent 应用加一个新的 Tool 实现,逻辑不复杂,大概 150 行代码。AI
写完之后很自信地说"已完成",但它没有任何办法验证自己写的东西能不能跑。因为这个项目依赖
OSS、远程沙箱、HSF 一整套云端基础设施,本地 mvn spring-boot:run 直接启动失败。
于是进入了经典循环:我把代码推到预发,等 5 分钟部署完成,手动触发一次调用,发现 NPE,截图贴回给
AI,AI 改了两行,我再推预发,再等 5 分钟……三轮下来半小时过去了,改的只是一个参数注入顺序的问题。
如果是一个本地能跑的项目,AI 自己跑一下测试就能发现这个错误,整个修复可能 30 秒就结束了。同样的模型、同样的
Prompt,差距不在 AI 能力,在如何构建 AI 友好的工程环境,即 Harness Engineering。
2. 问题的本质
这个体验差距不是偶然的,根源在微服务时代的技术架构。
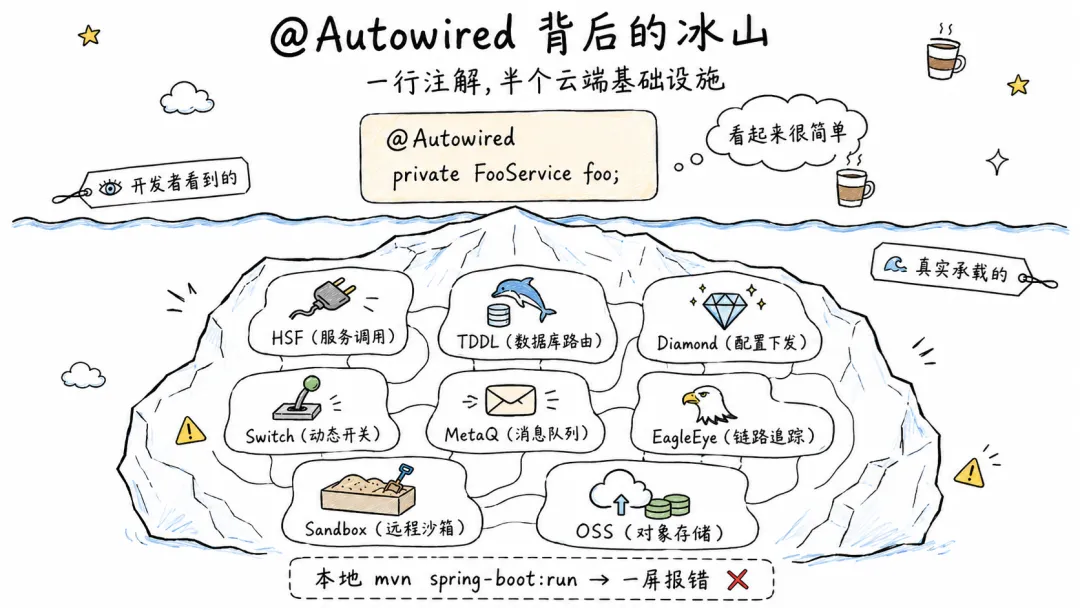
通常 Java 项目都重度依赖云端微服务基础设施:HSF 做服务调用、TDDL 做数据库路由、Diamond/Switch
做配置下发、MetaQ 做消息队列。一个看起来很简单的 @Autowired,背后可能牵着一整套分布式基础设施。这些东西在云端跑得很好,但在本地全部不可用。
说白了,微服务架构天然不 AI 友好。AI Coding Agent 需要一个能在本地跑起来的环境来验证自己的输出,但微服务架构把运行时依赖全部推到了云端。项目在本地跑不起来,AI
就没办法自主验证,只能靠人去推预发、看结果、再反馈。
于是就出现了一个很常见的工作流:
本地 Vibe Coding 开发
→ 推预发部署
→ 人工在预发环境验证结果
→ 人工把验证结果反馈给 AI
→ AI 继续改
→ 再次推预发 → 再次人工验证 → ...
|
人在每个环节都是阻塞点。跟那些本地能直接跑的项目里 AI 能自己迭代几十轮比起来,Java 微服务项目里
AI 每做一步都得等人。
最近社区关于 Harness Engineering 的讨论很多,大家聊的焦点通常在 CLAUDE.md
怎么写、lint 规则怎么配、验证脚本怎么跑。但对于 Java 微服务项目,还有一个更基础的问题:项目在本地能跑起来吗?
CLAUDE.md 写得再好,AI 连代码能不能编译通过都验证不了,后面的一切都是空谈。
这篇文章聊的就是这个问题:怎么让 Java 微服务项目的本地环境变得 AI 友好,让 AI 拥有自主验证的能力。做法来自一个
Agent 应用的实际改造,算是抛砖引玉。
3. 三条改造原则
我在这次改造中总结出三条原则,后面逐个展开。
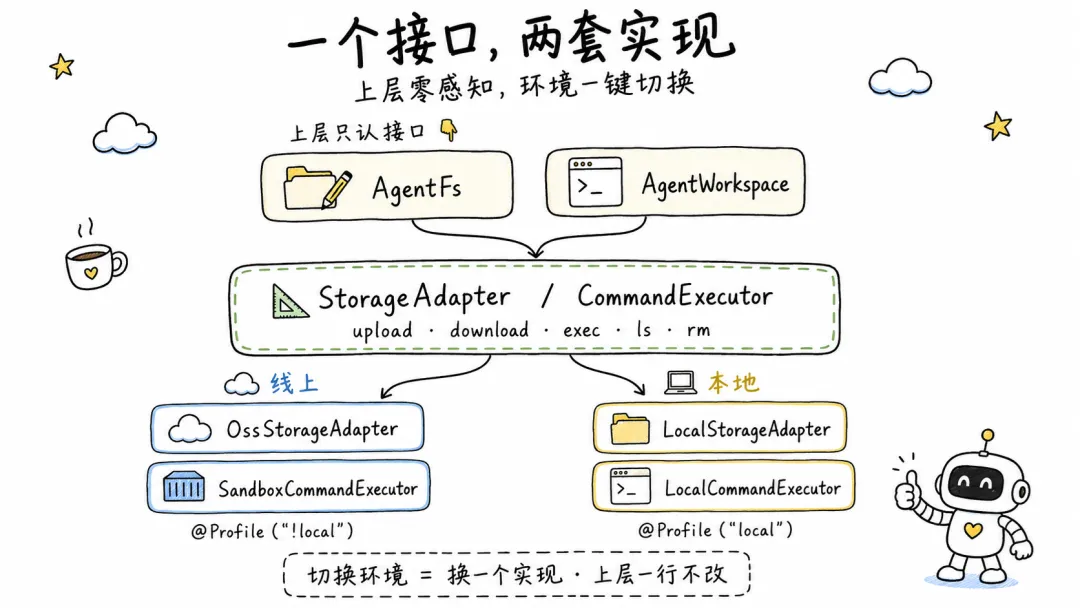
3.1 依赖倒置,接口先行
上层逻辑依赖抽象接口,不依赖具体实现。云端和本地只是接口的不同实现。
这是经典的依赖倒置(DIP),但在本地 Harness 的场景下有了实际的意义:它决定了你的系统能不能在本地跑起来。
拿我的实际改造举例。线上环境中,Agent 的文件系统(AgentFs)基于 OSS 对象存储,命令执行走远程沙箱(Sandbox),两者通过
OSS Mount 共享文件系统。这套架构在云端跑得好好的,但本地完全不可用,没有 OSS 服务,也没有远程沙箱。
改造前的依赖关系:
FilesystemService → OssStorageAdapter
(具体类,直接调 OSS SDK)
AgentWorkspace → SandboxCommandExecutor
(具体类,调远程沙箱 API)
|
上层直接依赖了具体的云端实现,想在本地跑就得把整个 OSS 和 Sandbox
搬过来。不现实。
改造后,我抽了一个 StorageAdapter 接口,把上传、下载、判断存在、删除、列举这些操作统一定义好。线上的
OSS 实现加一行 implements StorageAdapter,本地新写一个 LocalStorageAdapter,用
java.nio.file 把逻辑 key 映射到本地路径。工厂类在创建文件系统时,检测到有本地参数就走本地实现,否则走
OSS 实现。
StorageAdapter (接口)
├── OssStorageAdapter (线上,走
OSS SDK)
└── LocalStorageAdapter (本地,走
java.nio.file)
CommandExecutor (接口)
├── SandboxCommandExecutor
(线上,调远程沙箱 API)
└── LocalCommandExecutor
(本地,ProcessBuilder + bash -c)
|
上层所有用到文件操作和命令执行的代码完全不用改。它们只依赖接口,不关心底层是 OSS 还是本地文件系统。切换运行环境就是换一个接口实现,不用重写上层逻辑。
3.2 零侵入,Profile 隔离
本地改造不能让线上代码路径多走一行额外的代码。
这条容易被忽视。很多团队做本地化适配时,会在主流程里加 if (isLocal) 分支,线上代码路径变复杂了,出问题的风险也跟着上去。
我的做法是严格的零侵入:
Spring Profile 隔离:本地专属的 Bean 通过 @Profile("local")
装配,线上专属的通过 @Profile("!local") 守卫。两套配置编译期就彼此不可见。
@Configuration
@Profile("local")
public class LocalRepositoryConfig
{
@Bean
CommandExecutor localCommandExecutor()
{ ... }
@Bean("localFsBasePath")
String localFsBasePath()
{ ... }
// 用 AtomicLong 替代 TDDL GroupSequence
@Bean("sessionSequence")
Sequence sessionSequence()
{ return new LocalSequence(); }
}
|
同时在本地启动入口通过 @ComponentScan 的正则过滤,把线上专属的包(远程沙箱、OpenTelemetry
观测等)整个排除掉,不用在每个类上加条件注解。
@Nullable 参数注入:可选依赖标 @Nullable,不存在时 Spring 注入 null,不用写
@ConditionalOnBean。
public AgentRunner(@Nullable
@Qualifier("localFsBasePath") String
localFsBasePath, ...) {
// 线上环境:localFsBasePath =
null,走 OSS 路径
// 本地环境:localFsBasePath =
"/tmp/agentfs",走本地路径
}
|
条件守卫:运行时通过 null 检查决定走哪条路径。localFsBasePath 不为空就走本地,ossClient
不为空就走线上,逻辑非常简单。
最终效果按侵入性分级:
| 侵入级别 |
改动类型 |
示例 |
| 零侵入 |
新建文件 |
新接口、新的本地实现类 |
| 极低 |
加一行声明 |
线上实现类加 implements 接口 |
| 低 |
类型上提 |
字段类型从实现类改为接口 |
| 中等 |
新增可选参数 |
构造器加可选的本地路径参数(原有构造器不动) |
线上代码路径中,这些新增代码全部被跳过:null 检查不通过、Profile 不匹配、接口多态自然走原有实现。一个检验标准:删掉所有本地相关代码后,线上行为完全不变。
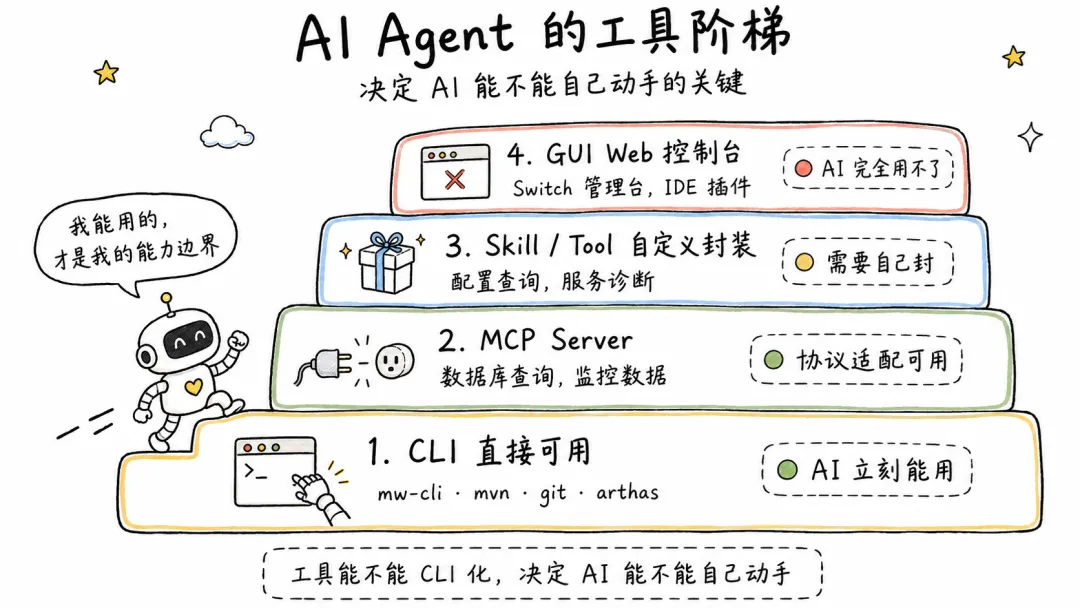
3.3 工具 AI 化:CLI 优先
AI Agent 的能力边界 = 它能调用的工具的边界。GUI 对 AI 不可见,CLI 才是 AI
能用的东西。
Java 生态有大量运维和管理工具,但大多是 Web 控制台:Switch 管理台、Diamond
配置中心、HSF 服务治理台。人用着方便,但 AI Coding Agent 完全用不了。
我的做法是用 CLI 桥接企业内部系统:
# 通过 mw-cli 查询 Diamond 运行时配置值
mw diamond get --unit online
--data-id application.properties --group DEFAULT_GROUP
# 通过 mw-cli 查询 HSF 服务地址
mw hsf address --unit daily
--app my-application
|
这些命令的输出是结构化文本,AI 直接就能解析。改造过程中,我写了一个 scripts/fetch-switch-config.sh,用
mw-cli 从预发 Diamond 拉 Switch 配置,解析成 properties 格式写到本地:
# fetch-switch-config.sh 核心逻辑
mw diamond get idealab-agent-runtime
asp-switch --env staging --unit pre -o json
# → 解析 JSON,写入 switch-config-local.properties
# → switch.modelApiKey=xxx
# → switch.defaultTimeoutMs=60000
# → switch.maxReactIterations=10
|
AI 也能直接跑这个脚本来同步最新的线上配置,不用人工登录管理台复制粘贴。
我还通过 Skill 把这些 CLI 能力注册到 AI Agent 的工具箱里,让 AI 需要的时候自己调用。
工具 AI 化的优先级:
| 优先级 |
工具形态 |
AI可用性 |
示例 |
| 1 |
CLI |
直接可用 |
mw-cli, mvn, git, arthas |
| 2 |
MCP Server |
协议适配 |
数据库查询、监控数据 |
| 3 |
Skill / Tool |
自定义封装 |
配置查询、服务诊断 |
| 4 |
GUI |
不可用 |
Web 管理台、IDE 插件 |
4. 实践案例:从"推预发验证"到"本地闭环"
4.1 改造前
这个 Agent 应用是一个 AI Agent 运行时平台,核心能力之一是让 AI Agent 可以操作文件(ReadFile/WriteFile)和执行命令(Bash)。
线上架构:
- 文件操作:AgentFs → OSS 对象存储
- 命令执行:远程 Sandbox(容器沙箱)
- 文件共享:Sandbox 通过 OSS Mount 挂载 Agent 的 OSS 存储桶
本地开发时:没有 OSS、没有 Sandbox、没有 OSS Mount。Agent 的 ReadFile
写到 OSS 里的文件,Bash 在本地根本看不到。文件系统是割裂的,没法用。
4.2 改造方案
核心思路:一个接口,两套实现,Profile 条件装配。工厂类根据参数自动选择实现,上层完全无感。
改造后,本地 @Profile("local") 激活时:
- 文件系统工厂检测到本地参数,自动创建 LocalStorageAdapter,文件存到 /tmp/agentfs/{sessionId}/...
- Bash 走 LocalCommandExecutor,用 ProcessBuilder 在本机执行
bash -c 命令,工作目录指向同一个本地路径
- ReadFile/WriteFile 和 Bash 看到的是同一套文件,闭环打通了
除了文件系统和命令执行,还有一整套配套改造(详见附录):H2 替代 TDDL 数据源,AtomicLong
替代分布式 Sequence,本地 Switch 配置文件替代 Switch Center,ComponentScan
排除线上专属的 sandbox 和 observation 包。最终效果是一个完全自包含的本地运行环境,不依赖任何远程基础设施。
4.3 改造效果
| 对比项 |
改造前 |
改造后 |
| 文件操作验证 |
推预发,通过 OSS 控制台查看 |
本地直接 ls 查看 |
| Bash 执行验证 |
推预发,登录沙箱查看 |
本地 Terminal 直接看 |
| AI 自主验证 |
做不到 |
ReadFile → 验证 WriteFile 结果 |
| 单次迭代耗时 |
5-10 分钟(含部署等待) |
秒级 |
| AI 自主修复轮数 |
0(每轮都要人工介入) |
平均 3-5 轮后自行收敛 |
改造前后的核心差异:一个完整的 bug fix 流程,改造前需要 3-4 轮人工推预发验证、总耗时
30 分钟以上;改造后 AI 在本地自主迭代,通常 2 分钟内收敛,人只需要最后 review 一下结果。
5. 配合 Harness Engineering 落地
本地 Harness 跑起来之后,还需要配合 Context Engineering 才能让 AI
真正高效地工作。具体来说,有几件事需要做:
5.1 CLAUDE.md:给 AI 一张地图
项目根目录放一份 CLAUDE.md,告诉 AI 这个项目是什么、怎么构建、怎么测试、本地环境怎么启动。不需要写得很长,100
行以内,重点是让 AI 在拿到任务后能快速定位该看哪些代码、该跑什么命令。
# 项目简介
AI Agent 运行时平台,支持 ReadFile/WriteFile/Bash
等 Tool。
# 本地开发
- 启动:`mvn spring-boot:run
-Dspring.profiles.active=local`
- 测试:`mvn test`
- 本地文件系统根目录:`/tmp/agentfs/`
# 架构约束
- 上层模块只依赖接口,不依赖具体实现类
- 本地专属代码通过 @Profile("local")
隔离
- 新增本地适配不得修改线上代码路径
|
5.2 验证脚本:让 AI 自己检查
Checklist 是给人看的,AI 需要的是可执行的验证命令。我在项目里加了一个
scripts/verify-local.sh:
#!/bin/bash
# 本地 Harness 验证脚本:AI 可以直接跑这个来确认本地环境是否正常
set -e
echo "=== 1. 编译检查 ==="
mvn compile -q -Dspring.profiles.active=local
echo "=== 2. 单元测试 ==="
mvn test -q 2>&1 | tail -5
echo "=== 3. 本地启动检查 ==="
timeout 30 mvn spring-boot:run -Dspring.profiles.active=local
&
PID=$!
sleep 15
if curl -s http://localhost:8080/actuator/health
| grep -q "UP"; then
echo "✓ 本地启动成功,health check 通过"
else
echo "✗ 本地启动失败"
exit 1
fi
kill $PID 2>/dev/null
echo "=== 4. 文件系统闭环检查 ==="
# 验证 ReadFile/WriteFile 和 Bash 看到的是同一套文件
TEST_FILE="/tmp/agentfs/test-$(date +%s)/verify.txt"
mkdir -p $(dirname $TEST_FILE)
echo "hello" > $TEST_FILE
if [ -f "$TEST_FILE" ] &&
[ "$(cat $TEST_FILE)" = "hello"
]; then
echo "✓ 文件系统闭环正常"
else
echo "✗ 文件系统闭环异常"
exit 1
fi
rm -rf $(dirname $TEST_FILE)
echo "=== 全部通过 ==="
|
AI 改完代码后跑一次 bash scripts/verify-local.sh,不需要人工介入就能知道本地环境是不是还能正常工作。这比
Checklist 有用得多。
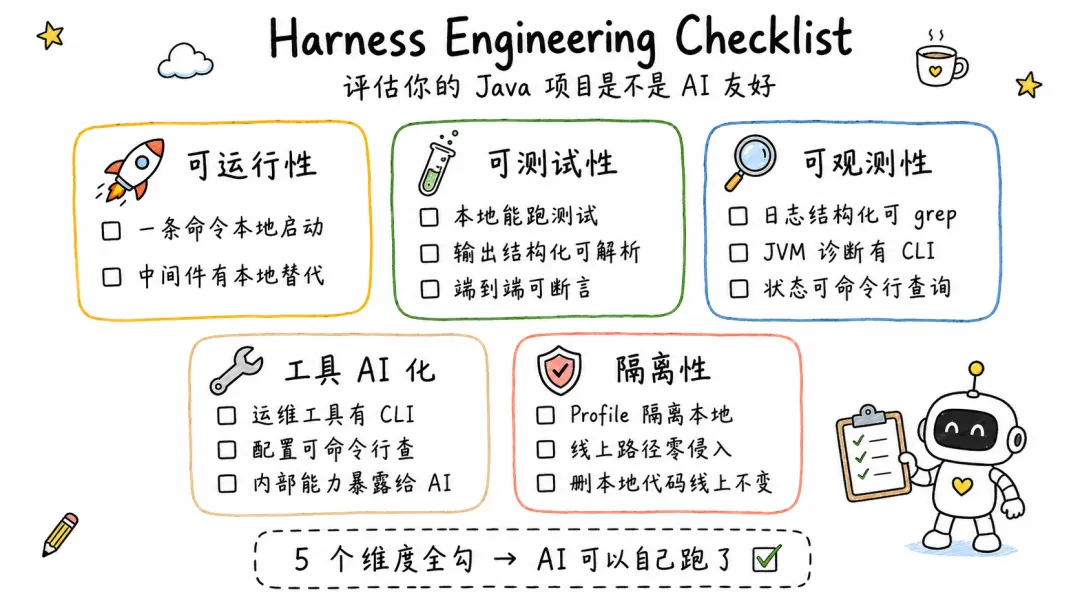
6. Harness Engineering Checklist
这份清单可以用来评估任意 Java 项目的本地 AI Coding 友好度,也可以当改造的行动指引。
- 项目能否在本地通过一条命令启动?(mvn spring-boot:run 或等价命令)
- 启动是否依赖外部中间件?如果是,有没有本地替代?(H2 替代 MySQL、内存队列替代 MetaQ
等)
- 外部依赖是否通过接口抽象?能否通过 Profile 切换实现?
可测试性 -
AI 能否在本地运行测试并读取结果?(mvn test 输出是否结构化)
- 核心逻辑是否有单元测试?AI 改完代码后能否立即验证?
- 端到端验证是否需要人工?能否通过 API 调用 + 断言自动完成?
可观测性 -
日志是否结构化(JSON 格式)、可 grep?
- 是否集成了 CLI 化的 JVM 诊断工具?(Arthas、jstack 脚本等)
- AI 是否能通过命令行获取运行时状态?(health check endpoint、metrics
输出等)
工具 AI 化 -
团队使用的运维工具是否有 CLI 入口?
- 配置管理(Switch/Diamond)是否可通过命令行查询?
- 是否有 MCP Server 或 Skill 将内部系统能力暴露给 AI Agent?
隔离性 -
本地改造是否通过 @Profile 隔离?
- 本地代码是否对线上代码路径零侵入?
- 删除所有本地相关代码后,线上行为是否完全不变?
7. 方法论总结
回过头来看这次改造,有几个可以复用的方法论。
第一,找到最小可运行子集。 不需要把所有线上能力都搬到本地,只需要找到核心链路跑通所需的最小依赖集合。这个项目的核心链路是"接收请求
→ 调 LLM → 执行 Tool → 返回结果",围绕这条链路需要的就是数据库、文件系统、命令执行三个基础设施。其他的比如监控、链路追踪、服务发现,本地不需要,排除就好。
第二,替代而非模拟。 H2 不是在"模拟" MySQL,它就是一个真实的关系型数据库,跑的是真实的
SQL。LocalCommandExecutor 不是在"模拟"沙箱,它就是在执行真实的
bash 命令。替代方案要能真实运行,不能只是返回 mock 数据。这样 AI 在本地发现的问题,线上大概率也会有。
第三,脚本化一切人工操作。 但凡需要人登录某个管理台、复制某个配置、点击某个按钮才能完成的操作,都应该有一个对应的脚本。fetch-switch-config.sh
替代了"登录 Switch 管理台 → 找到应用 → 复制配置"的人工流程。start-local.sh
替代了"先编译、再配置环境变量、再选对 main 类启动"的多步操作。脚本就是
AI 的手,没有脚本 AI 就是残废的。
第四,分层隔离,逐层验证。 不要想着一步到位把所有东西都改完再测。先让项目能编译,再让它能启动,再让核心接口能调通,再跑端到端测试。每一层都有对应的验证手段:mvn
compile、/checkpreload.htm、API 冒烟测试、Playwright E2E。AI
也可以按这个顺序逐层排查问题。
第五,让 AI 成为改造的参与者。 这次改造本身就是和 AI 一起完成的。我先手动搞定了 H2 替换和核心接口抽象,确保项目能在本地启动。之后
StorageAdapter 的实现、LocalCommandExecutor 的异常处理、冒烟测试脚本,都是
AI 在本地闭环里自己迭代出来的。一旦 AI 能跑测试、能看到报错,它的效率就上来了。这形成了一个正向循环:每完成一步改造,AI
能做的事情就多一点,下一步改造就更快。
8. 后续方向
本地环境还可以再往前走一步,把 JVM 诊断能力也工具化。比如应用响应超时时自动跑 jstack
把结果输出到 AI 能读的地方,或者通过 Skill 封装 Arthas 的 watch、trace、tt
命令,让 AI 实时观测方法调用。异常信息如果能以 JSON 格式输出,AI 直接就能解析定位到具体代码行。
理想的状态是 AI 不光能跑测试,还能理解测试为什么失败:
AI 修改代码 → mvn test → 解析 Surefire
报告 → 定位失败用例
→ 读取相关源码 → 分析原因 → 修复 → 再次测试
→ ...
|
这要求测试输出是结构化的、错误信息是可解析的、日志是可追溯的。目标就是让 AI 在本地能完全自主地跑完"发现问题→定位原因→修复代码→验证修复"这整个循环,跟人类开发者拥有一样的本地开发能力。
9. 附录:本项目本地化改造清单
下面列举这个 Agent 应用为了本地化部署做的所有改动,可以作为其他 Java 项目本地化改造的参考。
9.0 这个应用依赖了什么
改造之前先盘一下,这个应用到底挂在哪些东西上面:
- 数据库:TDDL 连 MySQL 集群,本地没有 TDDL 数据源,Spring 启动直接报 Bean
创建失败
- 分布式 ID:TDDL GroupSequence 靠数据库表做号段分配,TDDL 起不来它也起不来
- 对象存储:文件系统基于 OSS,本地没有 OSS 服务,Agent 的 ReadFile/WriteFile
全废
- 命令执行:走远程沙箱,本地没有沙箱服务,Bash Tool 直接报错
- 配置中心:API Key、超时时间、功能开关这些运行时配置走 Switch Center 动态下发,本地读不到
- 中间件:EagleEye、HSF、Sunfire、Pandora 这些的 AutoConfiguration
启动时会尝试初始化,本地没有这些基础设施,启动直接挂
- 监控:OpenTelemetry 埋点、metrics 导出,本地不需要但不排除也会报错
叠在一起的效果就是 mvn spring-boot:run 一跑一屏报错。下面逐个说怎么解决。
9.1 数据源:H2 替代 TDDL
线上用 TDDL 连 MySQL 集群,本地用 H2 文件数据库,零外部依赖。
# application-local.properties
spring.datasource.url=jdbc:h2:file:./data/local-db;AUTO_SERVER=TRUE;MODE=MySQL
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.username=sa
spring.datasource.password=
|
配合 schema-h2.sql 自动建表。表结构和线上 MySQL 保持一致,字段名、索引、约束都对齐。Repository
层用的是同一套 JDBC 实现,不需要为本地单独写一套。
spring.sql.init.mode=always 让每次启动自动执行建表脚本,H2 的 MODE=MySQL
兼容 MySQL 语法,基本不用改 SQL。
9.2 分布式 ID:AtomicLong 替代 GroupSequence
线上用 TDDL GroupSequence 生成全局唯一 ID,本地用 AtomicLong 包一层就够了:
public class LocalSequence
implements Sequence {
private final AtomicLong
counter = new AtomicLong(
System.currentTimeMillis()
% 1_000_000
);
@Override
public long nextValue() {
return counter.incrementAndGet(); }
}
|
本地配置类里注册了 session、message、checkpoint 等多个 Sequence
Bean,覆盖线上所有需要分布式 ID 的地方。用时间戳取模做种子,本地够用了,不会冲突。
9.3 Switch/Diamond 配置:脚本拉取到本地
线上通过 Switch Center 动态下发配置,本地通过 switch-config-local.properties
文件模拟。
scripts/fetch-switch-config.sh 做的事情:
1.调 mw diamond get 从预发环境拉 Switch 配置(JSON 格式)
2.用 Python 脚本解析 JSON,提取 SwitchConfig.* 前缀的字段
3.写入 switch-config-local.properties,格式类似 switch.modelApiKey=xxx
4.缺失的字段补上默认值(defaultTimeoutMs=60000、maxReactIterations=10
等)
本地配置类的 @PostConstruct 方法会读这个文件,把值设到 Switch 配置的静态字段上。API
Key 的优先级是:properties 文件 > 环境变量 > application
配置 > 空值。
这样做的好处是 AI 随时可以跑 bash scripts/fetch-switch-config.sh
来同步最新配置,不需要人工登管理台。
9.4 包排除:ComponentScan 正则过滤
本地启动入口用 @ComponentScan 的 excludeFilters 把线上专属的包整个排掉:远程沙箱包、OpenTelemetry
观测包,本地不需要的整包排除。
再加上 application-local.properties 里的 spring.autoconfigure.exclude,把
EagleEye、HSF、TDDL、Sunfire 等中间件的自动配置全部跳过。
排除的原则很简单:如果一个包的所有类都是线上专属的,用 ComponentScan 排除;如果是某个自动配置类,用
exclude 排除。不需要在每个类上加 @Profile 或 @ConditionalOnProperty。
9.5 一键启动:start-local.sh
# 一条命令启动本地环境
bash scripts/start-local.sh
|
这个脚本做了三件事:
1.检查 switch-config-local.properties 是否存在,不存在就自动跑 fetch-switch-config.sh
2.mvn compile -q 编译项目
3.拼接 classpath,直接 java -cp 启动 LocalApplication,监听 7001
端口
启动后 http://localhost:7001/checkpreload.htm 返回 "success"
就说明环境正常。AI 在 CLAUDE.md 里看到这条命令,改完代码直接跑就行。
9.6 端到端冒烟测试
tests/smoke/local-chat-smoke.mjs 是一个 Node.js 写的冒烟测试,覆盖三个层面:
1.Health Check:GET /checkpreload.htm 返回 "success",H2
控制台 API 能正常查表
2.API 验证:创建 Session → SSE 流式调用 → 验证 message 和 MODEL_STOP
事件 → 查询消息历史 → 确认数据落库
3.UI E2E:Playwright 打开页面,创建会话,发送消息,等待 AI 回复,截图保存到 /tmp
AI 改完代码跑一次 node tests/smoke/local-chat-smoke.mjs,几秒钟就能知道核心链路有没有挂。比人工在预发点点点快得多。
9.7 改造全景图
把上面这些改动汇总一下:
| 线上依赖 |
本地替代 |
改动方式 |
| OSS 对象存储 |
本地文件系统 (java.nio.file) |
新增接口 + 本地实现 |
| 远程沙箱 |
本机 bash 执行 (ProcessBuilder) |
新增本地实现 |
| TDDL + MySQL |
H2 文件数据库 (MODE=MySQL) |
application-local.properties |
| TDDL GroupSequence |
AtomicLong 本地序号 |
新增本地实现 |
| Switch Center |
switch-config-local.properties |
脚本从预发拉取 |
| Diamond 配置中心 |
application-local.properties |
Spring Profile |
| EagleEye / HSF / Sunfire |
排除自动配置 |
spring.autoconfigure.exclude |
| Pandora 启动器 |
标准 java -cp 启动 |
start-local.sh |
| OpenTelemetry |
排除观测包 |
ComponentScan excludeFilters |
| 






 订阅
订阅