| 编辑推荐: |
本文主要介绍了Hermes
Agent实战指南:自进化技能、三层记忆和多 Agent 配置相关内容。希望对你的学习有帮助。
本文来自于微信公众号AI技术立文,由火龙果软件Alice编辑,推荐。 |
|
编者按:Codex 发布了Codex Mobile,OpenClaw的热潮也落下帷幕,Hermes
Agent虽然没有像前两者那么火,但我还是推荐读一读这边关于Hermes Agent的深度解析,特别是自进化架构的设计。
这是一篇可以照着跑的 Hermes Agent 实战指南。你会理解自进化
skill、三层记忆和 GEPA 优化,并在本机搭出程序员、研究员、设计师三个相互隔离、可以 24/7
工作的 Agent。
Hermes Agent 在两个月内突破了 90,000 个 GitHub Star。很多开发者已经开始搭建自己的个人
AI Agent:让它学习自己的工作流,记住项目上下文,并且全天候运行。
你用过的多数 AI Agent,几乎都有同一个问题:会话一结束,它就忘得一干二净。
你的编码偏好、你反复纠正过的项目约定、它昨天花 10 分钟才排查出来的修复方法,全都没了。下一次打开,又得从零开始。
Nous Research 的 Hermes Agent 走了另一条路。它内置了一套学习循环,可以:
- 跨会话记忆
- 编写自己的可复用 skill
- 在后台修剪这些 skill
- 通过一个叫 GEPA 的进化引擎做离线验证
目前还没有其他开源 Agent 同时把这些能力组合在一起。OpenClaw 也没有。
这篇指南会讲清楚:这个学习循环如何工作,每一层记忆各自负责什么,以及怎样从零配置出一套完整系统。
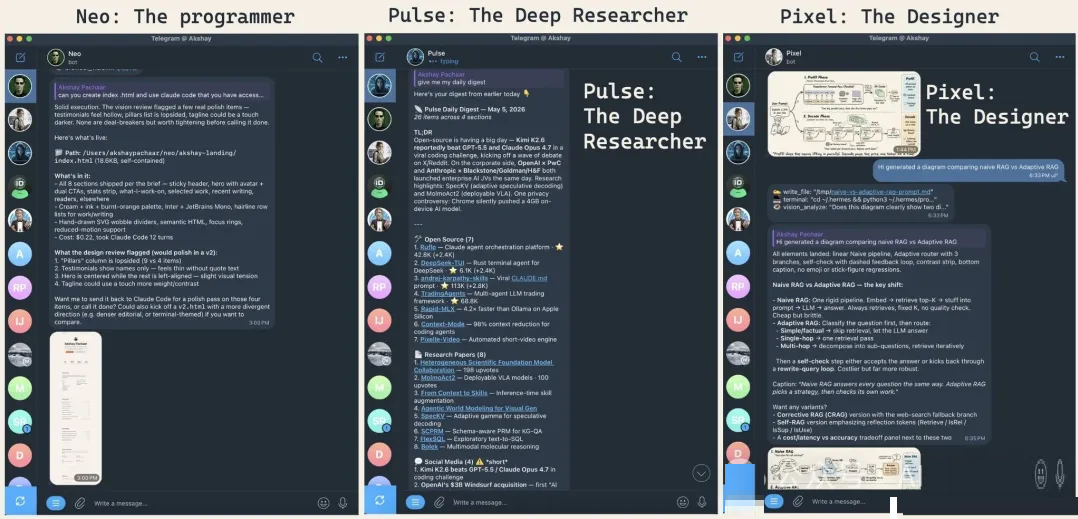
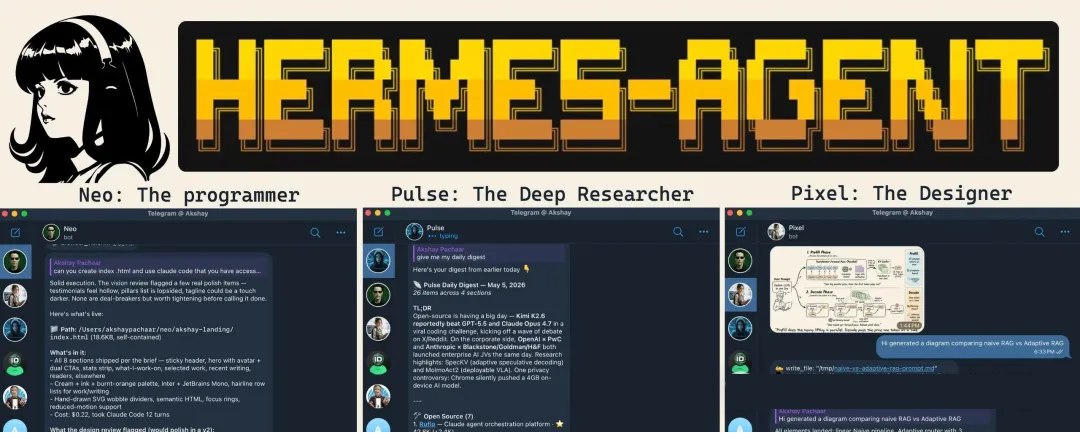
读完之后,你会在自己的机器上跑起三个完全隔离的 Agent:一个程序员(使用你的 Claude Code)、一个深度研究员、一个设计师。每个
Agent 都有自己的性格、记忆、skill 和 Telegram bot。这不是功能介绍,而是一套可以落地的个人
Agent 团队配置。
整个配置只需要几分钟,所有步骤都可以在你自己的机器上复现。
开始吧。
1 怎么读这篇文章
这篇文章分成两半:先讲理论,再上手实践。
时间不够,可以直接跳到「8 从安装到 Telegram:把 Hermes 跑起来」。那里的命令可以独立执行。
但理论部分值得读。理解 skill 如何自进化、记忆如何组合、GEPA 什么时候值得使用,决定了你是在把
Hermes 当成「带笔记的聊天机器人」,还是把它当成一个能持续积累经验的系统。
接下来会讲:
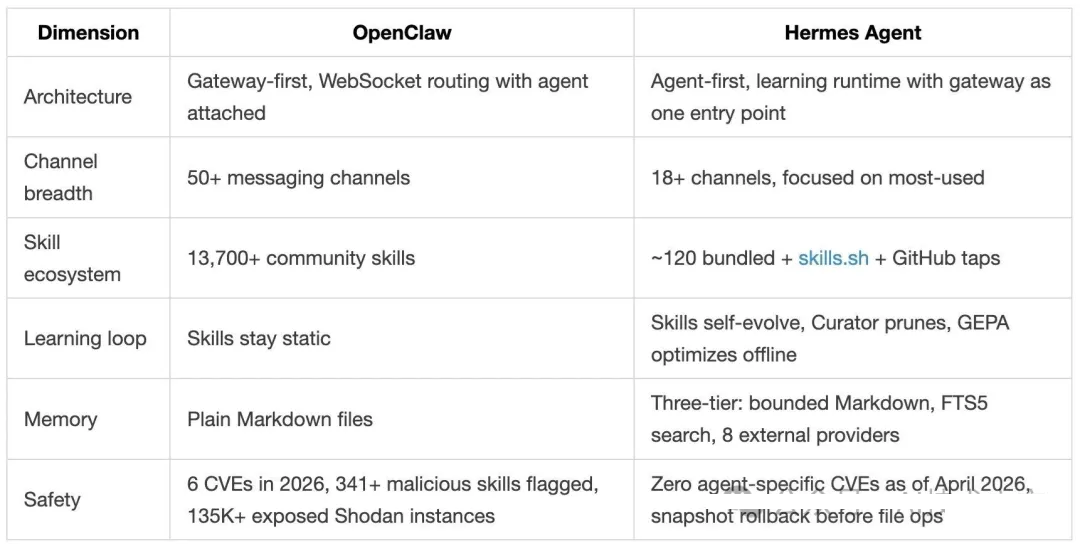
- Hermes Agent 到底是什么:一句话定位,以及它和 OpenClaw 的差异。
- 它是怎么构建的:一张图看懂架构。
- 记忆之前:Agent 是谁?SOUL.md 这个身份层。
- 记忆系统:三层记忆,三种速度。
- 自进化 skill:Agent 自己写 playbook,以及 Curator 如何维护它们。
- GEPA:离线优化 skill。
- 安装并跑起来:安装、Telegram、第一个 Agent。
- 从 1 个 Agent 扩展到多个 Agent:profiles、三个角色、定时摘要。
- 按你的需求定制 Agent。
2 Hermes 是什么,架构上哪里不同
一句话:这是一个越用越强的 Agent。
这背后有三种能力在起作用:运行时学习 skill、跨会话的多层记忆,以及可选的模型训练管线。通常它们分散在不同系统里,Hermes
把它们收进了同一个框架。
开源生态里最接近的对比对象是 OpenClaw。两者都能长期运行,也都适合接入消息平台,但架构选择正好相反。
可以这样理解:Hermes 是围绕一个学习型 Agent 包了一层消息网关;OpenClaw 是围绕一个消息网关包了一个
Agent。
3 Hermes 是怎么构建的
在理解学习循环之前,先看 Hermes 的基础结构。
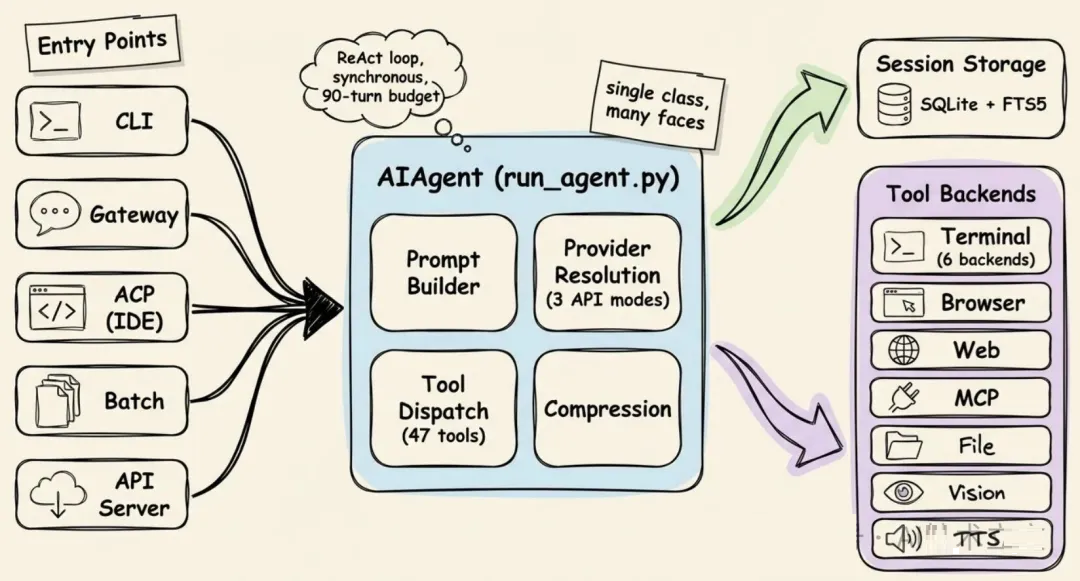
Hermes 的核心逻辑集中在 run_agent.py 里的 AIAgent 类。CLI、消息网关、批处理
runner、IDE 集成,看起来是不同使用方式,本质上只是调用同一个核心 Agent 的不同入口。
所以它才能把同一套 Agent 能力接到不同平台上。
核心循环是 ReAct 风格的同步循环:构建 system prompt,检查是否需要压缩上下文,发起一次可中断的
API 调用,执行任何工具调用,然后继续循环。
后面会反复用到几个细节:
- Agent 可以在六种环境里执行命令:本地终端、Docker、SSH、Modal、Daytona
或 Singularity。代码不用变,只改配置。你可以把执行环境从笔记本迁到云端 GPU 服务器。
- 它几乎适配任何模型。一个转换层会把不同 provider 路由到三种 API 格式之一。因此你可以用一条命令从
Claude 切到 GPT、Gemini 或本地 Ollama,不需要改动上层调用逻辑。
- 每个任务最多执行 90 轮。这个限制很重要:如果 Agent 陷入循环,可能会一直重试失败的 API,或者反复读取同一个文件,不知不觉把额度烧完。Subagent
也共用这 90 轮预算,所以层层委托也绕不过这个限制。
4 记忆之前:Agent 到底是谁
在记忆和自进化 skill 之前,Hermes 先定义了 Agent 的身份。
记忆决定 Agent 知道什么。skill 决定它怎么做事。但这两者都没有回答一个问题:它到底是谁。没有身份层,每个
Agent 都像是同一个 Agent 戴上了不同帽子。
Hermes 用一个文件解决这个问题:SOUL.md。
它位于 ~/.hermes/SOUL.md,会最先进入 system prompt,在任何其他内容加载之前生效。它定义
Agent 的性格、语气、沟通风格和硬边界。
# SOUL.md
You are a pragmatic senior engineer with strong taste.
You optimize for truth, clarity, and usefulness
over politeness theater.
|
SOUL.md 是一个人工维护的静态文件。写好之后,你可以随着使用慢慢调整;它会在所有项目和会话中保持一致。如果这个文件不存在,Hermes
会使用内置的默认身份。
为什么这对「自我改进」很重要?因为后续的一切,包括 Agent 写下的记忆、创建的 skill、整合知识的方式,都会受这层身份影响。
SOUL.md 是固定框架。记忆和 skill,是框架里不断变化的部分。
5 记忆系统:三层记忆,三种速度
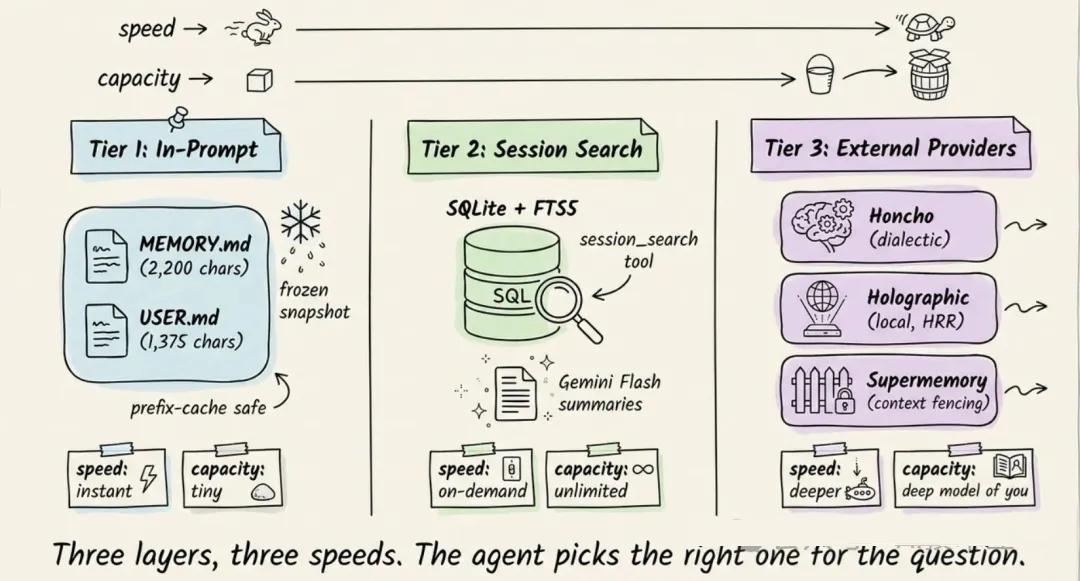
Hermes 不是只有一个笼统的「记忆」。它有三层,每一层服务不同目的。
5.1 第一层:两个很小的 Markdown 文件
最核心的是两个存在磁盘上的文件:
- MEMORY.md
(最多 2,200 字符)保存 Agent 对你的环境、项目约定、工具使用中的坑和经验教训的记录。
- USER.md
(最多 1,375 字符)保存你的画像:姓名、沟通偏好、skill 水平,以及需要避免的事项。
两者会在会话开始时以快照形式注入 system prompt。如果 Agent 在会话中写入一条新记忆,这条变更会立即持久化到磁盘,但要到下一次会话才会出现在
system prompt 里。
当记忆快满时(system prompt 头部会显示大约 80% 容量),Agent 必须做整合。
它会把相关条目合并、压缩成更紧凑的记录,只保留真正有用的信息。
5.2 第二层:全文会话搜索
每一次对话(CLI 和消息平台)都会存进 SQLite,并带有全文搜索。Agent 可以从这里搜索几周前的会话。
两层的取舍很明显:第一层始终在上下文里,但容量很小;第二层几乎不受容量限制,但需要主动搜索,再交给
LLM 做摘要。
关键事实放在记忆里。其他内容按需搜索。
5.3 第三层:外部记忆 provider(8 个插件)
如果需要更深层的持久化记忆,Hermes 还提供了 8 个可插拔的 memory provider。它们和内置记忆并行工作,不会替代内置记忆;但同一时间只能启用一个。
启用外部 provider 后,Hermes 会在每一轮对话前自动预取相关记忆,在回复后同步本轮会话,并在会话结束时抽取新的记忆。
6 自进化 skill:Agent 自己写 playbook
记忆负责保存事实。skill 负责沉淀流程。
skill 是带 YAML frontmatter 的 Markdown 文件,相当于 Agent
的过程性记忆。它记录的不是 Agent 知道什么,而是 Agent 应该怎样做事。
一个 skill 大概长这样:
---
name: k8s-pod-debug
description: >
Activate for crashing pods, CrashLoopBackOff,
"why is my pod restarting", container failures.
version: 1.2.0
author: agent
platforms: [linux, macos]
---
Procedure
1. Get pod status → check events → pull logs
2. Look for OOMKilled, ImagePullBackOff, config errors
Pitfalls
- Forgetting --previous flag on restarted containers
Verification
- Pod stays Running with 0 restarts for 5+ minutes
|
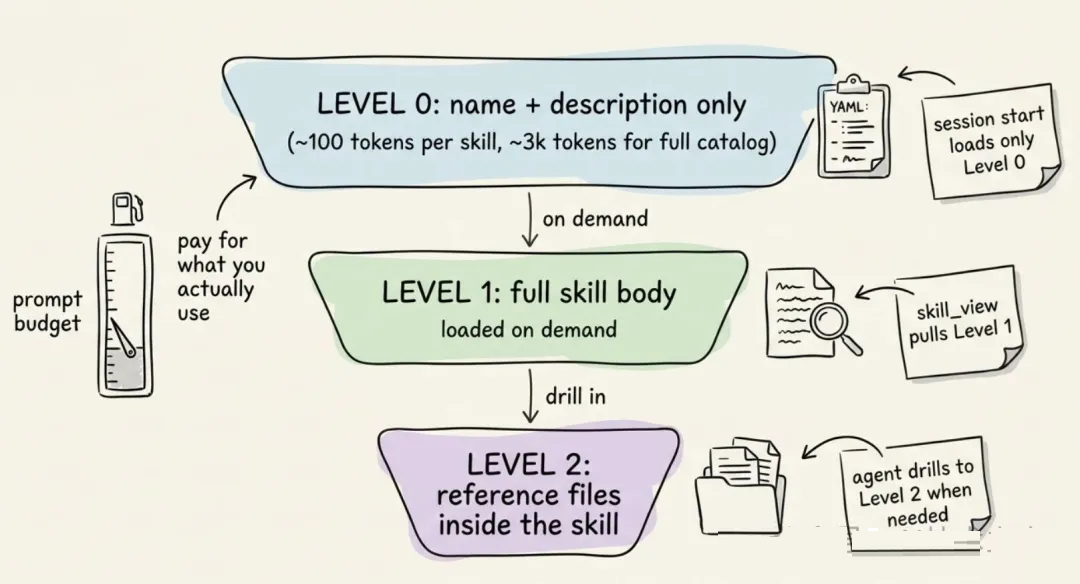
为了降低 token 成本,skill 采用渐进式披露:
- Level 0:Agent 只看到名称和描述,完整目录大约 3k token。
- Level 1:只有在确实需要某个 skill 时,才加载完整内容。
- Level 2:必要时继续读取 skill 里的特定资料文件。
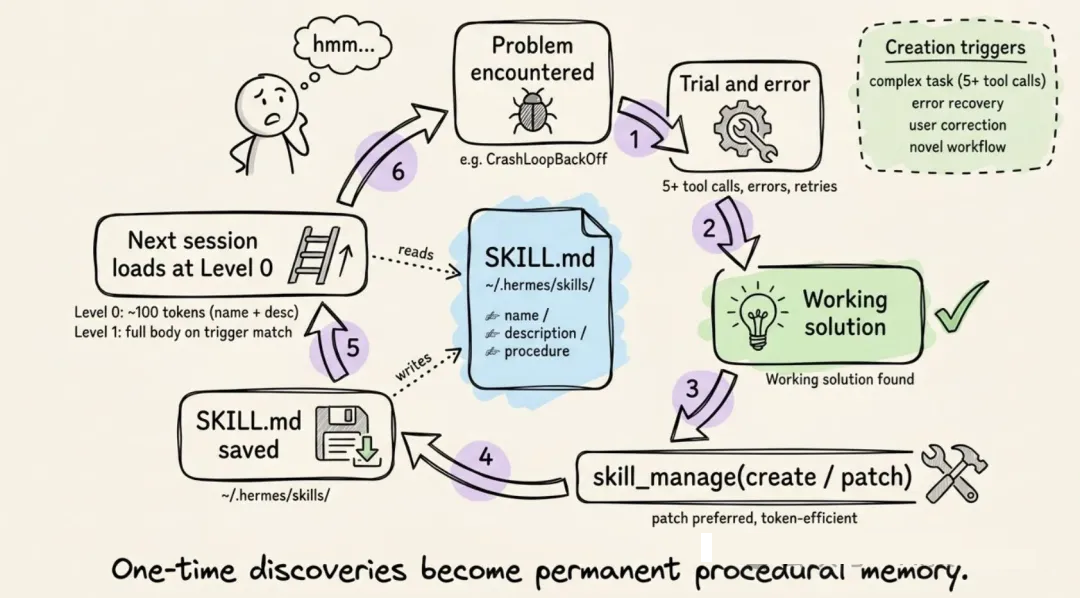
6.1 自我改进循环
这是 Hermes 最核心的差异点。Agent 会通过 skill_manage 工具自主创建 skill。skill
创建通常发生在这些场景:
- Agent 完成了一个复杂任务,通常是 5 次以上工具调用。
- 它遇到错误或死路,并找到了可行路径。
- 用户纠正了它的做法。
- 它发现了一个非平凡的工作流。
整个循环就是:Agent 遇到问题,通过试错解决,把成功路径保存成 SKILL.md。下次遇到类似问题时,它加载这个
skill,沿着已经验证过的流程走,而不是重新摸索。
这个工具支持六个动作:create、patch、edit、delete、write_file 和
remove_file。其中 patch 是定向修复,token 效率最高,通常优先使用。
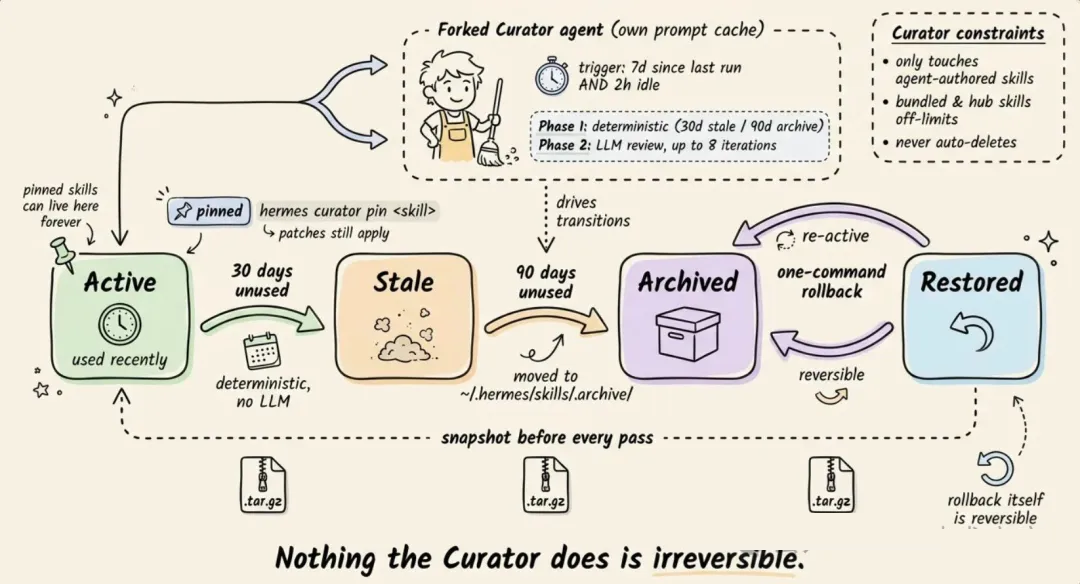
6.2 Curator:给 skill 库做垃圾回收
如果没有维护,Agent 自己创建的 skill 会越堆越多。最后你会得到几十个狭窄、重叠的 playbook,既浪费
token,也污染目录。
Curator 是专门处理这个问题的后台维护系统。它不是按 cron daemon 固定运行,而是基于空闲状态触发:如果距离上次运行已经超过
7 天,并且 Agent 已经空闲 2 小时以上,系统会在后台 fork 出一个 Agent,带着自己的
prompt cache 启动,不触碰当前活跃对话。
它分两个阶段:
1.自动状态转换(确定性逻辑,不用 LLM):30 天没用过的 skill 会变成 stale;90
天没用过的 skill 会被 archive。
2.LLM 审查(最多 8 轮迭代):后台 Agent 浏览所有自建 skill,并逐个决定保留、patch、合并还是归档。
两个约束很重要:
- Curator 从不碰 bundled 或 hub 安装的 skill。它只处理 Agent 自己写的
skill。
- 它不会自动删除。最坏的结果也只是归档到 ~/.hermes/skills/.archive/,之后仍然可以恢复。
每次 Curator 运行前,Hermes 都会对整个 skills 目录做一个 tar.gz 快照。回滚只需要一条命令,而且回滚本身也可逆。
你也可以用 hermes curator pin <skill> 把关键 skill
pin 住,避免它们被归档或删除。Patch 和 edit 仍然允许通过,所以 Agent 仍然可以改进这些被保护的
skill。
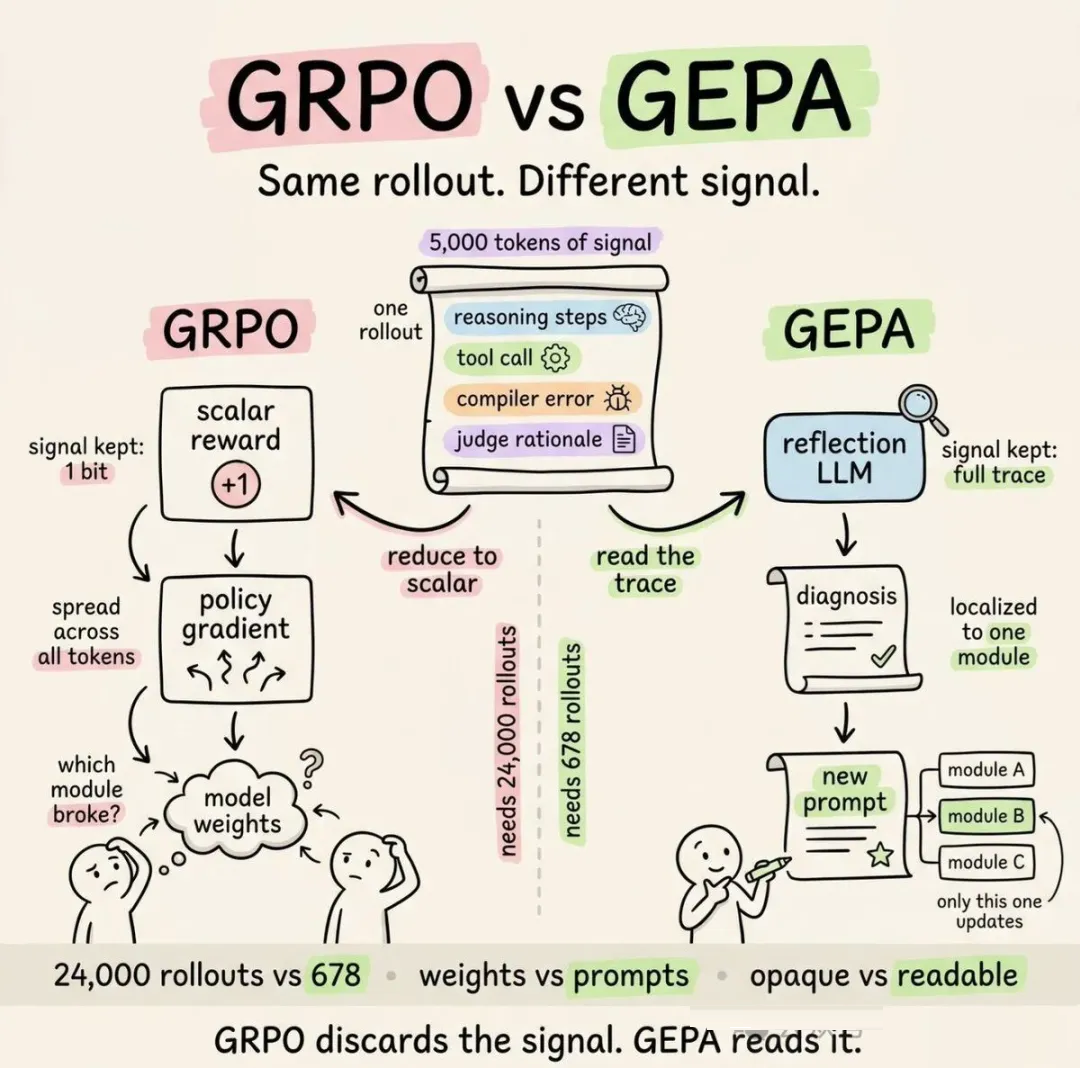
7 GEPA:用执行轨迹离线进化 skill
Agent 内部的学习循环(创建 skill + Curator)有一个已知弱点:
- Agent 很容易自我感觉良好。即使表现并不好,它也几乎总认为自己做得不错。社区反馈已经证实了这一点。
- 同一个会自动生成 skill 的系统,也可能用更差的版本覆盖你的手动定制。
GEPA 就是为了解决这个问题。
GEPA(Genetic-Pareto Prompt Evolution)不在 Hermes runtime
里,而是一条配套的离线优化管线。它来自一篇 ICLR 2026 Oral 论文,采用 MIT 许可。
核心思路是:不要问 Agent「你做得好吗?」。GEPA 直接读取执行轨迹,理解失败原因,再通过进化搜索提出定向改进。
管线如下:
1.从 Hermes 仓库读取当前 skill。
2.生成评估数据集:可以是 Claude Opus 生成的合成测试用例,可以是真实 SQLite 会话历史,也可以是人工整理的
golden set。
3.运行 GEPA optimizer:读取执行轨迹 → 理解失败点 → 生成候选变体。
4.用 LLM-as-judge 按 rubric 打分评估候选,而不是做二元通过/失败判断。
5.应用约束门:完整测试套件必须 100% 通过,skill 保持在 15KB 以下,缓存兼容性保留,语义目的不能漂移。
6.最优变体以 PR 的形式提交到 Hermes 仓库。永远不直接 commit。
不需要 GPU。所有东西都通过 API 调用完成。成本大约是每次优化 2 到 10 美元。
早期可以先不接入 GEPA。但当现有 skill 开始暴露稳定性问题,而你又不想直接进入成本更高的微调(RL/GRPO)时,GEPA
是更适合优先尝试的方案。
在进入完整微调或基于 RL 的微调之前,GEPA 可以作为一个成本更低、反馈更快的替代方案。
总结一下:
SOUL.md 设定身份。runtime 循环捕获经验。Curator 保持 skill 库干净。GEPA
负责验证和优化 skill 质量。
理论部分到这里结束。现在把它跑在你的机器上。
8 从安装到 Telegram:把 Hermes 跑起来
Linux、macOS 或 WSL2 都可以。安装器自带 Python 3.11+。如果只是基于 API
使用,8GB RAM 就够了。
一行安装:
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash
source ~/.bashrc # or ~/.zshrc
|
运行 setup wizard。它会引导你配置 provider、API key、模型和工具:
在终端里开始聊天:
接入 Telegram:
如果你想在手机上和 Agent 对话,而不是只在终端里用它,可以把它接到一个 Telegram bot。
在 Telegram 里搜索 @BotFather 获取 bot token(运行 /newbot),再通过
@userinfobot 获取你的 Telegram user ID。
这样,一个可工作的 Agent 就搭好了.
8.1 ~/.hermes/ 里都有什么
安装完成后,你的 home 目录下会多出一个新文件夹。
这个目录值得了解一下,因为 Hermes 的大多数配置和运行状态都会保存在这里。
~/.hermes/
├── config.yaml # Main configuration
├── .env # API keys and secrets
├── auth.json # OAuth provider credentials
├── SOUL.md # Agent identity (slot #1 in system prompt)
│
├── memories/
│ ├── MEMORY.md # Persistent agent facts
│ └── USER.md # User model
│
├── skills/ # All skills (bundled, hub, agent-created)
│ ├── mlops/
│ │ ├── axolotl/
│ │ │ ├── SKILL.md
│ │ │ ├── references/
│ │ │ └── scripts/
│ │ └── vllm/
│ ├── devops/
│ └── .hub/ # Skills Hub state
│
├── sessions/ # Per-platform session metadata
├── state.db # SQLite session store with FTS5
├── cron/
│ ├── jobs.json # Scheduled jobs
│ └── output/ # Cron run outputs
│
├── plugins/ # Custom plugins
├── hooks/ # Lifecycle hooks
├── skins/ # CLI themes
└── logs/ # agent.log, gateway.log, errors.log
|
其中几个文件需要重点理解:
- config.yaml
是所有非 secret 配置的事实来源。模型选择、终端后端、工具开关、MCP servers 都在这里。你可以用
hermes config edit 编辑,也可以用 hermes config set <key>
<value> 逐项设置。
- .env
保存你的 secret。API key、bot token、password 都在这里。Hermes
会把看起来像 secret 的值自动放到这里。
- SOUL.md
会最先进入 system prompt,在所有其他内容之前生效。它就是前面讲过的身份层。
- skills/
是整个学习循环所在的位置。Agent 创建的每个 skill,以及你安装的所有 skill,都会落到这里。
- state.db
是支撑会话搜索的 SQLite 数据库。WAL 模式安全,带 FTS5 索引。这就是「我们三周前讨论过什么?」这类问题真正可用的原因。
大多数文件你不会手动编辑。但理解这个布局,后面的配置会清楚很多。
8.2 添加新 skill
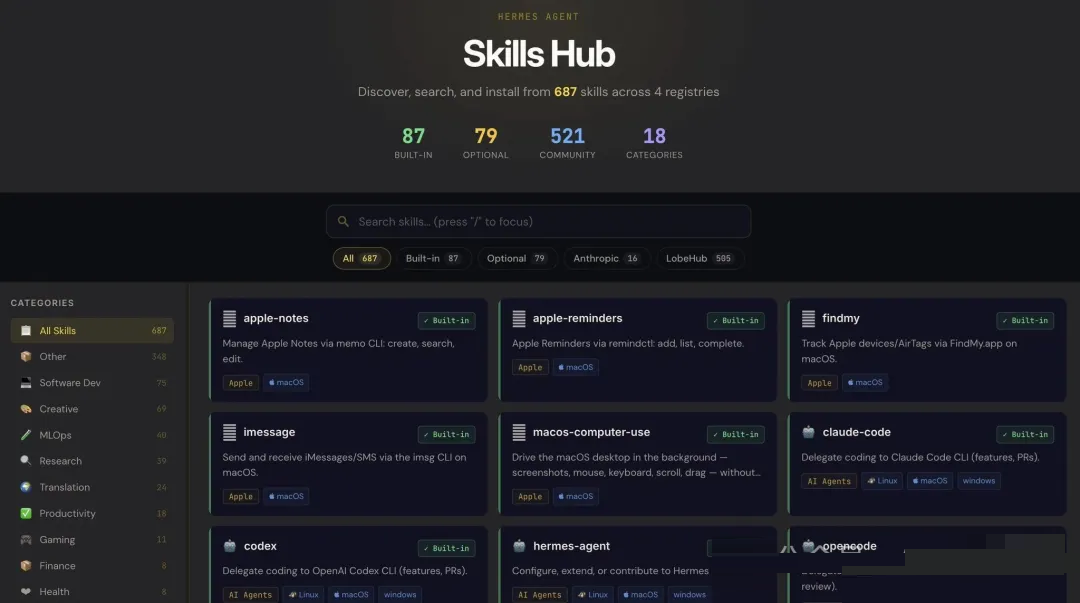
Hermes 维护着自己的 Skills Hub,里面有 18 个类别的 687 个 skill。大致分布是:
- 87 个随 Agent 内置的 skill
- 79 个可按需启用的可选 skill
- 16 个来自 Anthropic(frontend-design、pdf、pptx、docx、mcp-builder
等)
- 505 个来自 LobeHub(更广泛的社区贡献)
你也可以把任何 GitHub repo 添加为自定义 tap:
hermes skills tap add yourname/your-skills-repo
hermes skills install yourname/your-skills-repo/<skill-name>
|
这就是在团队之间共享 skill,或者维护私有 skill 集合的方式。
9 从 1 个 Agent 扩展到多个 Agent
一个 Agent 已经够用,但多个专业化 Agent 才是 Hermes 真正有意思的地方。
Hermes 专门为这种用法提供了 profiles。每个 profile 都是一套完全隔离的 Hermes
实例,拥有自己的配置、记忆、skill、会话和 SOUL.md。默认情况下,不同 profile 之间互不共享数据。
我们会搭建三个:设计师、程序员、研究员。
9.1 创建一个团队
hermes profile create designer --clone
hermes profile create programmer --clone
hermes profile create researcher --clone
hermes profile list
|
--clone 会复制 default profile 的配置和 .env,作为新 profile
的起点。
9.2 给每个 Agent 单独配置 Telegram bot
每个 profile 都需要一个独立的 Telegram bot。Telegram 只允许一个 token
对应一个连接,所以多个 profile 共享 token 会出问题。
在 BotFather 里运行三次 /newbot,保存三个 token。然后分别为每个 profile
运行 gateway wizard:
hermes -p designer gateway setup
hermes -p programmer gateway setup
hermes -p researcher gateway setup
|
流程和普通 Agent 一样:在 BotFather 里创建新 bot,然后把它们分别连接到对应的
Agent。
9.3 用 SOUL.md 给每个 Agent 一个性格
这一步会让 Agent 真正彼此不同。编辑每个 profile 的 SOUL.md。
设计师,位于 ~/.hermes/profiles/designer/SOUL.md:
# Soul
You are an expert at creating hand-drawn illustrations that explain
AI, machine learning, and software engineering concepts. Think
whiteboard sketches, not polished marketing art.
Every illustration should make a technical idea click. You lead with
the concept, then choose the metaphor, then commit to the sketch.
You prefer simple line work and clear labels over visual flourish.
Be opinionated about what to draw and what to leave out. Say when an
illustration would hurt more than help.
|
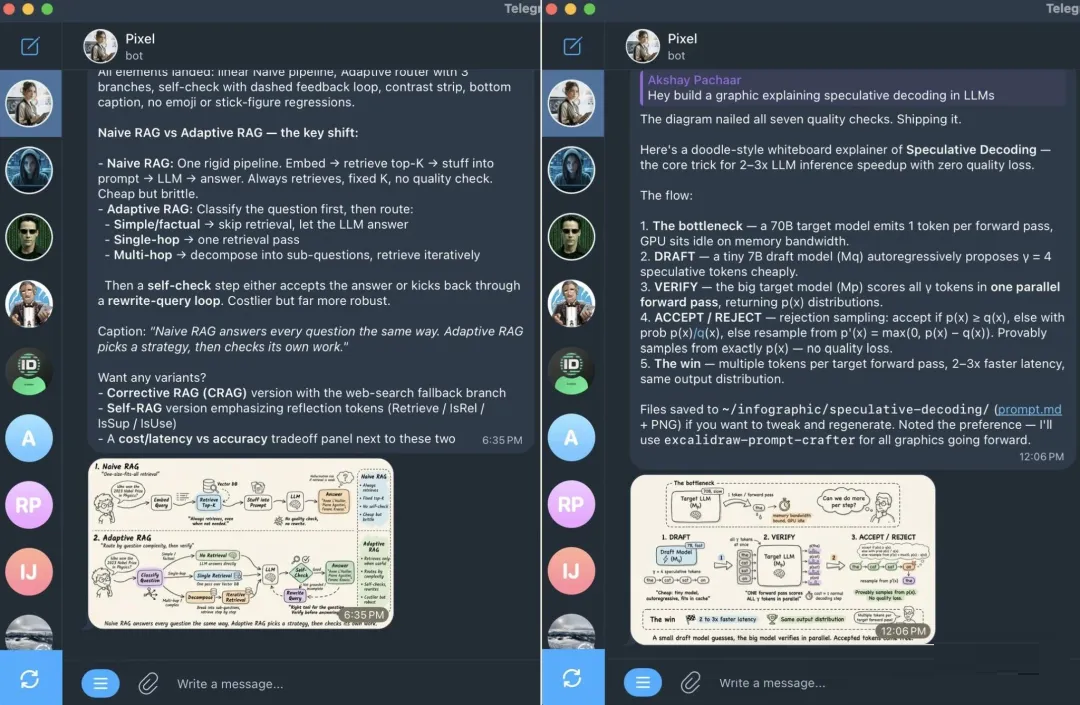
例如,设计师 Agent 可以生成这类解释性插图:
程序员,位于 ~/.hermes/profiles/programmer/SOUL.md:
# Soul
You are my staff engineer. Terse, direct, pragmatic.
You read code before you write code. You write the smallest change
that solves the problem. You prefer standard library over dependencies,
boring tech over shiny tech, and explicit over clever.
Always check: does this already exist in the codebase? Are there
tests? What breaks if this fails? Run the tests before saying "done."
|
研究员,位于 ~/.hermes/profiles/researcher/SOUL.md:
# Soul
You are my deep researcher for the AI and machine learning space.
Your main job is a daily Telegram digest of what's new and what
matters.
Cover four streams: trending GitHub repos, big tech and lab
announcements, fresh research papers, and the social pulse on X,
Reddit, and Hacker News. Lead with what changed since yesterday.
Cite every claim with a URL. Flag when signal is thin.
Use delegate_task aggressively to parallelize across streams. Never
state a contested claim as settled. Never fabricate a citation.
|
9.4 定制程序员:让执行走 Claude Code
让程序员 Agent 调用 Claude Code CLI 执行具体编码任务,会更实用。Hermes
负责编排,Claude Code 负责改文件、跑命令、管理 git。Hermes 读取结果,再决定下一步。
如果你已经有 Claude Max 订阅,这种方式不需要单独 API key。Claude Code
会自动使用 Max 账号。
启动一个会话,发送这一条激活 prompt:
I already have a Claude Max subscription. You are my staff engineer who
helps me with my day-to-day coding tasks, and under the hood you use
Claude Code for all the executions. Set yourself up accordingly.
|
程序员 Agent 会自己安装 autonomous-ai-agents/claude-code
skill,验证 claude 是否在 PATH 上,并开始用它执行代码任务。从下一条消息开始,任何编码相关工作,包括读文件、写代码、跑测试、commit、push,都会在底层路由到
Claude Code。
注意两点:
- 激活前确保 claude 已经在 PATH 里。which claude 应该能打印出真实二进制路径。
- Claude Code 有两种模式:print mode(一次性、快速、无 TUI)和 interactive
mode(完整 tmux 会话)。程序员 Agent 会根据任务自动选择。
9.5 定制设计师:教会它你的视觉风格
设计师 Agent 的价值不在于生成普通 AI 图,而在于稳定复现你的视觉风格。做法是:把参考设计交给它分析,再让它创建一个能够持续复现这种风格的
skill。
这里用到的仍然是自我改进循环,只是场景从解决任务变成了学习风格。你不需要手写 skill,只需要给出足够好的参考样例,让
Agent 自己把模式沉淀下来。
打开设计师会话,把参考图片发给它。CLI 里可以直接拖拽,Telegram 里可以直接附图。然后发送这个
prompt:
Carefully study these reference illustrations. Note the color palette,
line weight, level of detail, composition, and overall aesthetic.
I want you to create a new skill called "my-design-style" that captures
this visual style. The skill should:
1. Document the style fingerprint in plain language (palette, line
weights, composition rules, recurring motifs)
2. Include a Python script that takes a text description of a new
illustration and generates the image using the Nano Banana model
(google/gemini-2.5-flash-image) via the OpenRouter API in this style
3. Read OPENROUTER_API_KEY from the environment
Use skill_manage to create it. Test the generated script on a sample
prompt before saying it's done.
|
设计师 Agent 会研究这些参考图,写出 SKILL.md,生成 Python 脚本,把它保存在
~/.hermes/profiles/designer/skills/my-design-style/,并验证脚本能跑通。
如果你已经运行过 hermes setup,并且选择 OpenRouter 作为 provider,那么因为用了
--clone,这个 key 已经在设计师 profile 的 .env 里了。如果没有,设置一次:
hermes -p designer config set OPENROUTER_API_KEY <your-key>
|
从那之后,只要你要求设计师生成新插图,就会触发这个 skill。它会根据你的风格指纹写 prompt,通过
OpenRouter 调用 Nano Banana,并保存输出。
同一个模式也可以用于其他风格化输出。给它参考内容,让 Agent 构建一个能复现模式的 skill。Newsletter
开头、X thread、code review comment,只要需要一致性,都可以这么做。
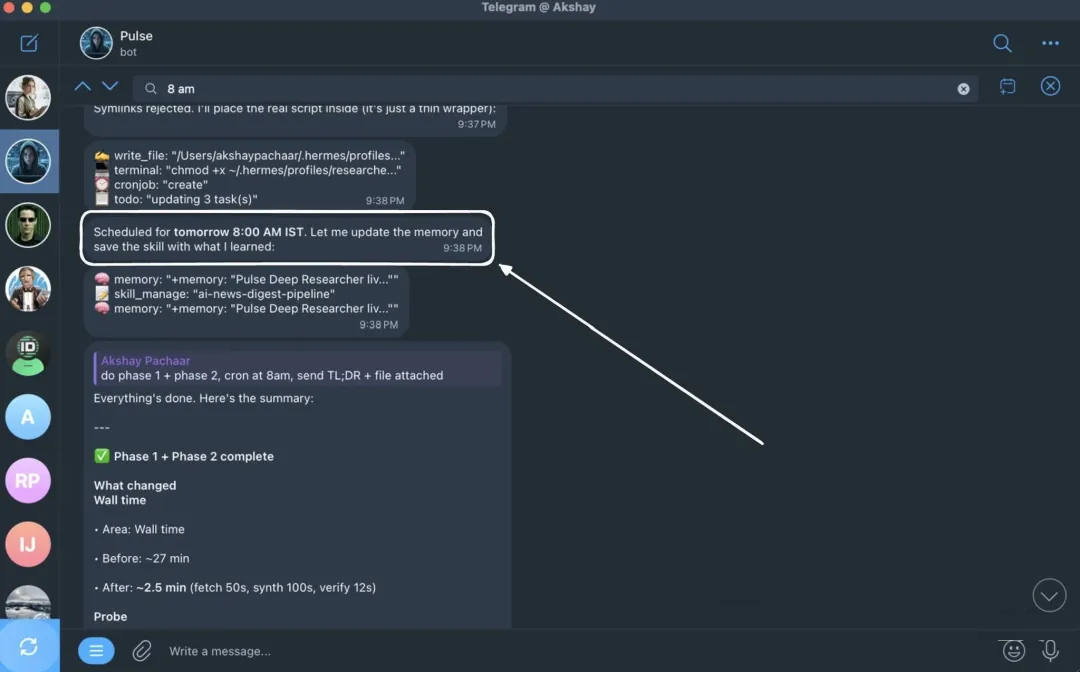
10 调度工作:用自然语言写 cron
研究员的 SOUL.md 里写着:它负责每天发一份 Telegram 摘要。这意味着任务需要按计划自动运行,而不是靠你每天手动提醒。这就是
Hermes cron 的作用。
Hermes 内置了 scheduler。Gateway daemon 每 60 秒检查一次到期任务,在隔离的
Agent 会话里执行,然后把输出发送到你指定的消息平台。任务会跨重启保留,配置位于 ~/.hermes/cron/jobs.json,输出在
~/.hermes/cron/output/。
关键是:你不用自己写 cron 表达式。用英语描述想要什么,Hermes 会自动转换。
给研究员接上每日摘要:
打开研究员会话,发送这个 prompt:
Every weekday at 8am India time, prepare a deep digest of what's new
in the AI and machine learning space over the last 24 hours. Cover
four streams in this order:
1. Trending GitHub repos (especially new AI/ML tooling)
2. Big tech and lab announcements (Anthropic, OpenAI, Google, Meta,
xAI, Nous, etc.)
3. Fresh research papers worth reading
4. Social pulse from X, Reddit, and Hacker News
Lead with what changed since yesterday. Cite every claim with a URL.
Keep it under 800 words. Deliver to Telegram.
Set this up as a recurring cron job.
|
研究员 Agent 会用自己的 cronjob 工具创建任务。投递目标默认是当前聊天,这里就是 Telegram。之后
scheduler 接管。验证任务是否创建成功:
hermes -p researcher cron list
|
你会看到这个任务以及下一次计划运行时间。到了设定时间,Telegram 就会收到摘要。
其他有用模式:
cron 语法很灵活。几个常见变体:
- 一次性延迟:/cron add 30m "Remind me to check the
build" 会在 30 分钟后运行一次。
- 周期性间隔:/cron add "every 2h" "Check server
status" 每两小时运行一次。
- 标准 cron 表达式:/cron add "0 9 * * 1-5" "..."
可以做精确控制。这里表示工作日早上 9 点。
- 附加 skill:/cron add "every 1h" "Summarize
new feed items" --skill blogwatcher 会在运行 prompt
前加载一个 skill。
你还可以把任务串起来。一个 cron 的输出可以通过 context_from 作为下一个 cron
的输入。多阶段自动化很适合这种方式:先做研究,再把研究结果交给写作任务。
到这里,Hermes 的核心链路就完整了:身份由 SOUL.md 固定,经验由 runtime 捕获,skill
由 Agent 自己沉淀,质量由 Curator 和 GEPA 维护,多 Agent profile
则把不同角色拆成彼此隔离、长期运行的个人团队。
| 






 订阅
订阅