| 编辑推荐: |
本文系统介绍了大模型从底层原理(Token、注意力机制、MoE)到上层应用(预训练、Prompt、Function Call/MCP、RAG、Agent)的六级技术叠加体系,揭示了大模型并非魔法盒子,而是一套通过逐层补短板、工程化构建智能的完整开发路径,希望对你的学习有帮助。
本文来自于雪上加码,由火龙果软件Alice编辑,推荐。 |
|
大模型为什么叫"大"?参数动辄上千亿,训练数据动辄几十 T。但光有大还不够——要理解为什么它能听懂人话、为什么有时候又答得离谱,得先扒开底层看三个零件: Token 、注意力、MoE。
一、预训练:大模型与生俱来的三板斧
Token:语言与数字世界的翻译官
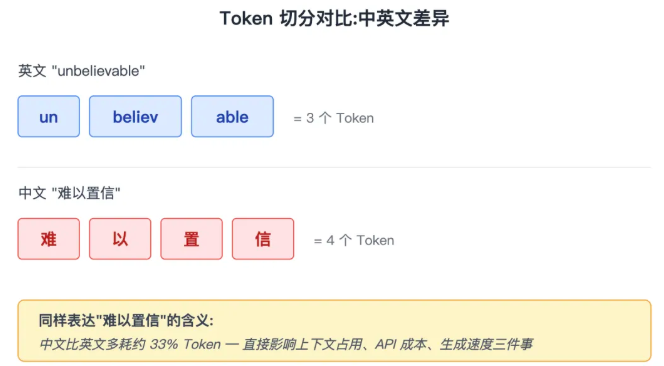
大模型不认字,它只认数字。任何一句话进入大模型前,都要先被切成一个个 Token(词元),每个 Token 对应一个数字 ID。
举个例子,"苹果"可能是 1 个 Token,但英文 "unbelievable" 可能被切成 "un / believ / able" 3 个 Token。
中文比英文更吞 Token——同样表达一个意思,中文往往要多耗 30%-50% 的 Token。
这直接关系到三件钱袋子的事:
- 上下文窗口够不够用 :目前主流大模型上下文在几万到几十万 Token 之间
- 调用成本 :绝大部分 API 按 Token 计费,中文项目的账单天然更贵
- 生成速度 :Token 越多越慢,用户就越等不住
注意力:动态聚焦的眼神
大模型看一段文字时,不是平均用力,而是像人读书一样——重点划线、次要略过。这就是注意力机制。
想象你问大模型"Python 怎么读取 CSV 文件",它上下文里同时塞了 Java 文件 IO、Python 读 JSON、Python 读 CSV、Python 读 Excel 四段技术文档。注意力机制会把权重几乎全压在"Python 读 CSV"那一段,其它部分一带而过。
注意力机制的演进直接决定三件事:
- 质量 :聚焦越准,答案越对
- 速度 :过滤越多,输出越快
- 成本 :省下的算力就是省下的钱
DeepSeek 的 MLA( 多头潜在注意力 )、DSA(稀疏注意力),本质都是在这三件事上做权衡。
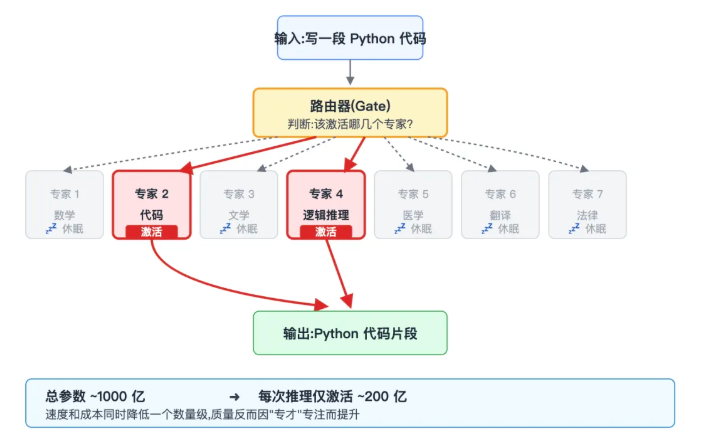
MoE :分而治之的专家团
早期大模型是一个"全才"——问什么都用同一套参数硬算,资源吞噬量可怕。MoE(混合专家)架构改成了一群"偏科学霸":数学题甩给数学专家,代码题甩给代码专家,每次推理只激活相关的几个专家,其余沉睡。
MoE 架构:偏科学霸的专家团
好处立竿见影:总参数可以做到千亿级别,但每次推理只激活几百亿参数,速度和成本都被拉下来一个数量级。
一个现实问题:预训练的大模型是半成品
预训练只是让大模型"见过世面",但它既不知道今天的天气,也不会帮你下订单,更不懂你们公司的内部规范。要让它真正干活,后续五级台阶才是主战场。
二、Prompt:第一次对话的艺术
拿到一个预训练好的大模型,最直接的用法就是——跟它说话。但"说话"这件事本身就有讲究。
温度和采样:控制输出风格的两个旋钮
同一个问题,大模型可以答得一本正经,也可以答得天马行空,差别就在两个参数:
- 温度(temperature) :低温(0.2)让高概率词更高、低概率词更低,输出保守稳定,适合客服、代码生成;高温(1.0)把概率拉平,输出多样有创意,适合写故事、搞创作
- Top-p 采样 :只在累计概率 0.8 的候选词里随机挑——既有多样性,又规避了 Top-k 容易抓到烂词的弊端
实战口诀: 写代码用 0.2,写故事用 0.9 。
Prompt 写作规范
一条 Prompt 写得好不好,直接决定大模型表现好不好。两条铁律:
- 结构清晰、不混淆 :背景、任务、输出格式分开写,后续加需求时知道加到哪
- 用语无歧义、有条理 :如果一个 Prompt 人读起来都费劲,大模型大概率也看不懂
一个常见误区是"堆料式" Prompt——把能想到的都塞进去,结果大模型抓不住重点。好 Prompt 的评判标准是: 删掉任何一句都会让效果变差 。
Prompt 的天花板
光靠 Prompt 能解决 80% 的单轮任务,但两个硬性限制绕不过去:
- 知识冻结在训练截止日 :问它"昨天上线的新框架文档",它只能瞎猜
- 不能执行操作 :让它真的帮你发邮件、创建工单、改线上配置?门儿都没有
要突破这两条天花板,就得给大模型"装手"——Function Call 上场。
三、Function Call:给大模型装上手
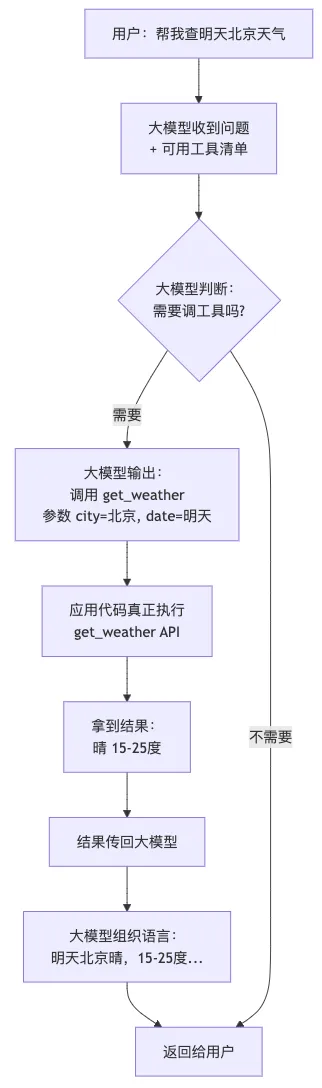
Function Call 的核心思想只有一句话: 大模型自己不调工具,但它学会了说"我要调这个工具" ,剩下的事应用代码来干。
工作流程
想象一个餐厅服务员(大模型)和后厨(各种工具)的分工:
整个过程中, 工具调用是应用代码执行的,大模型只负责"决策调哪个、传什么参数" 。
开发者要做的事
调用大模型 API 时,把可用工具列表(名称、描述、参数 schema)一起塞进去。大模型根据问题决定调不调、调哪个。返回结果后,再次调用大模型让它基于结果组织回答。
Function Call 的痛点
这套机制好用,但有个老大难问题—— 工具每次变更,所有调用方都要跟着改代码 :
- 工具名字改了,调用代码要改
- 参数格式改了,调用代码要改
- 工具多了,Prompt 里塞不下
- 想用第三方工具,要现学现写适配层
痛点攒够了, MCP 就出场了。
四、MCP:给工具调用立个行业规矩
MCP(Model Context Protocol)是 Anthropic 推出的协议,可以理解为 Function Call 的标准化封装 。
类比 USB-C
没有 USB-C 之前,苹果用 Lightning、安卓用 Micro-USB、电脑用 Type-A,每种设备都要专属充电线。USB-C 统一接口后,一根线通吃所有设备。
MCP 对工具调用做的就是这件事:
- 工具方 按 MCP 协议暴露接口
- 大模型应用方 按 MCP 协议读取
- 中间解耦 :工具方升级接口,应用方不用改一行代码
MCP 不是替代 Function Call
这点特别容易搞混—— MCP 只是在 Function Call 外面套了一层规范,底层依然是 Function Call 。对大模型来说,它看到的还是"工具清单 + 调用指令"那一套。MCP 解决的是工程侧的解耦问题,不是能力侧的升级。
带来的变化
现在开发一个 Agent,第三方 MCP Server(GitHub、Slack、数据库、浏览器……)可以即插即用,省下大量造轮子的时间。打开 Claude Code 的 MCP 市场,几百个现成工具一键接入——这是实打实的生态红利。
五、RAG:给大模型装上"专属记忆库"
Function Call 和 MCP 解决了"动起来"的问题,但还有个硬伤——大模型不知道公司内部的东西。它不懂你们产品的使用规则,不懂内部的业务术语,不懂团队沉淀的最佳实践。
硬塞进 Prompt?上下文窗口塞不下,而且每次调用都要带一遍,成本爆炸。
RAG 的基本思路
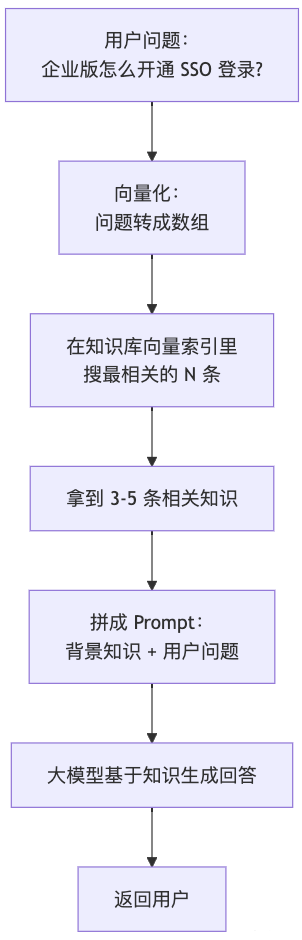
检索增强生成(Retrieval-Augmented Generation):
核心就一件事—— 问题来了先查资料,带着资料再答题 ,就像开卷考试。
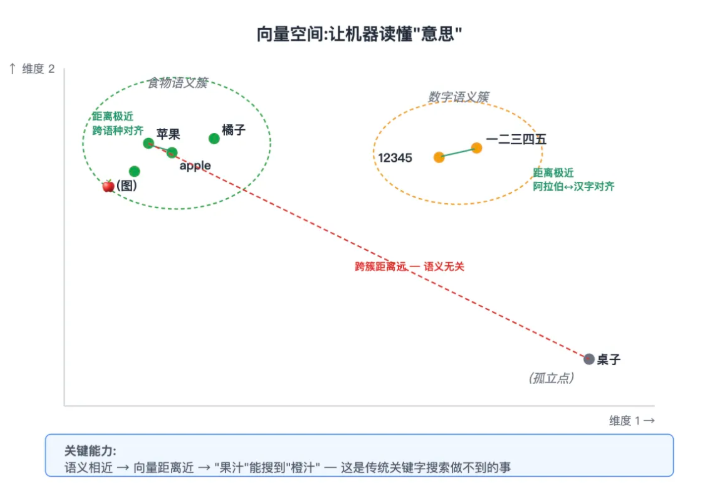
向量:让机器读懂"意思"
为什么能做到"语义搜索"?靠的是向量(Embedding)。
向量是把一段文字压缩成一个几百维的数组。语义接近的内容,数组距离也接近:
- "苹果"和 "apple"——几乎一样的数组(跨语种对齐)
- "苹果"和 🍎图片——几乎一样的数组(跨模态对齐)
- "苹果"和"桌子"——数组距离很远
- "12345"和"一二三四五"——几乎一样的数组
传统关键字搜索,"果汁"搜不到"橙汁";向量搜索靠语义,"果汁"能找到"橙汁、苹果汁、饮料"。这种"懂意思"的能力,是 RAG 的根基。
知识库维护:RAG 成败的命门
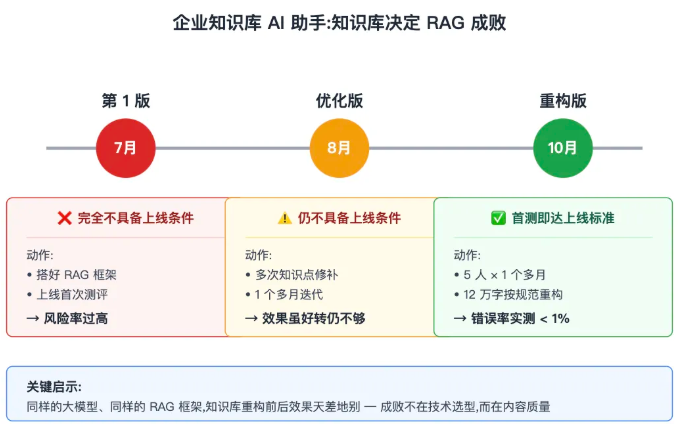
RAG 框架谁都能搭,真正拉开差距的是 知识库的质量 。来看一个真实案例:
某大型企业的内部知识库 AI 助手项目,一条真实的"血泪线":
- 7 月第 1 版 :框架搭好,测评效果完全不具备上线条件
- 8 月 :经过 1 个多月多次知识优化和测评,依然不具备上线条件
- 10 月 :5 个人花 1 个多月,按规范重构 12 万字知识库—— 重构后第一次测评直接达到上线标准 ,错误率实测低于 1%
同样的大模型、同样的 RAG 框架,知识库重构前后效果天差地别。
知识维护四条硬规矩
- 体系清晰 :相关知识放一起,按逻辑顺序排布,方便维护也方便大模型推理
- 避免混淆 :相近但不同的知识必须表述清晰区分,否则大模型会张冠李戴
- 避免重复冗余 :同一个知识点多处出现且表述不一,大模型会被带乱
- 用语清晰无歧义 :人读起来都费劲的内容,大模型更费劲
背景知识:上下文工程的雏形
光有知识条目不够,复杂场景下还要配"背景知识"。
举个例子,某 SaaS 产品的权限模型有三层嵌套(组织 / 团队 / 项目 × 所有者/管理员/成员/访客 × 读/写/管理/删除),单独查任何一条权限规则都容易答错——必须把完整的权限体系背景一起喂给大模型,它才能正确推理"A 账号能不能删除 B 项目的某文档"这类复合问题。
这其实就是后来火起来的"上下文工程": 不是告诉大模型答案,而是告诉大模型思考答案所需的前提 。
把原始知识给大模型,而不是只给结论
这条规矩反直觉但极其重要。举个运费计算的例子:
- 只给结论 :"北京到上海 1 公斤包裹运费 15 元"——大模型不知道怎么算的,用户换个城市、换个重量它就傻
- 给原始规则 :"运费 = 基础运费 + (实重 - 首重) × 续重单价,跨省加收 20%,节假日再加 10%"——大模型能基于规则自行推理任意场景
用户问题无穷无尽,结论穷举不完;规则可以推理所有问题。这是读书笔记和参考手册的区别。
六、Agent:把所有能力编排起来的大脑
到这里,大模型已经有了"嘴(Prompt)、手(Function Call/MCP)、专属记忆(RAG)"。但要让它像一个真正的员工干活,还缺最后一步—— 决策与编排 。这就是 Agent。
两个核心抉择
做 Agent 开发,逃不开两个选择:
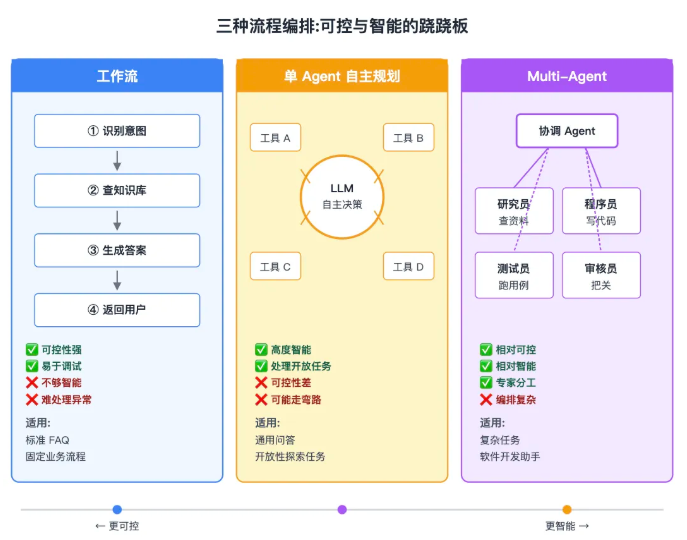
- 流程编排方法 :工作流 / 单 Agent(自主规划)/ Multi-Agent——决定"谁来调度"
- 思考决策方法 :CoT / ReAct / ToT / 规划-执行-反思——决定"怎么思考"
两个维度可以自由组合,排列出几十种玩法。
流程编排:可控与智能的跷跷板
| 编排方式 |
特点 |
适用场景 |
| 工作流 |
每步写死,可控但显得不智能 |
标准客服 FAQ、固定业务流程 |
| 单 Agent 自主规划 |
大模型自己决定下一步,智能但不可控 |
开放性任务、通用问答 |
| Multi-Agent |
多个专家分工协作,相对可控且相对智能 |
复杂任务、软件开发助手 |
没有最好的,只有最合适的。简单任务硬上 Multi-Agent 是浪费,复杂任务死守工作流是找死。
思考方法:从直觉到深思熟虑
用"制定徒步计划"这个任务类比几种思考方法:
- 直觉反应(Baseline) :上来就写计划,可能漏天气漏装备
- CoT(思维链) :按步骤来——先确认日期城市,再查天气,再查路线,最后出计划
- ReAct(边想边查) :一边想缺什么信息,一边调工具查,再基于结果继续想
- ToT(思维树) :同时提出挑战型、中等型、休闲型三个候选方案,各自查资料推演,淘汰不合适的
- Plan-Execute-Reflect(规划-执行-反思) :做完之后回头检查——这计划合理吗?不合理就重做
任务越复杂,越需要后几种方法。Claude Code、Cursor 这类工具本质都是 ReAct + Plan-Execute-Reflect 的组合拳。
数据评测与飞轮:Agent 持续进化的引擎
Agent 不是上线就完事。两件事必须做:
- 数据评测 :每个环节都要能测——RAG 召回率、工具调用准确率、最终答案质量,哪个差优化哪个
- 数据飞轮 :系统能自发现问题、自评估、自优化、自保护——用户的每次交互都变成下一次迭代的燃料
没有评测的 Agent 就是黑盒,没有飞轮的 Agent 就是死水。
七、一张全景图与一条成长路径
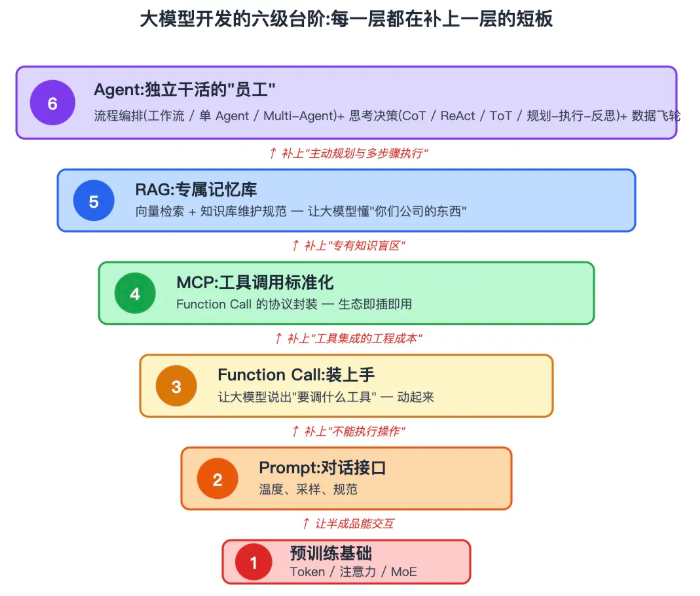
从预训练到 Agent,大模型开发是逐级叠加的过程——每一层都在补上一层的短板:
大模型开发的六级台阶
每一层都是前一层的必要补丁:
- 预训练 解决"基础智能",但是半成品
- Prompt 让半成品能对话,但知识有限、不能操作
- Function Call / MCP 让它能操作,但不懂专有知识
- RAG 让它懂专有知识,但缺乏主动规划能力
- Agent 让它能主动规划和多步骤执行,成为真正的"员工"
学习路径建议
- 基础理解 :看一本系统讲解大模型训练部署的书,啃下 Token、注意力、MoE 等底层概念
- 上手 Agent 开发 :扣子、百炼、Dify 任选其一搭 Demo,快速跑通 Prompt → Function Call → RAG → Agent 完整链路
- Agent 深度使用 :用 Claude Code、Cursor 在日常工作中自定义 skill,把大模型变成效率放大器
- 持续跟进最新动态 :这个领域半年一个范式、季度一个技术,不读就掉队
后记
大模型不是一个"魔法盒子",而是一套层层递进的工程体系。预训练给了它底层智能,Prompt 让它能对话,Function Call / MCP 让它能动手,RAG 让它懂业务,Agent 让它能独立干活。
真正决定项目成败的,往往不是选了哪个大模型,而是—— 每一层有没有做扎实 。前面那个企业知识库 AI 助手的案例最能说明问题:同样的大模型、同样的 RAG 框架,知识库质量差一档,效果就差一个世界。
工程的魅力从来如此:大方向千篇一律,细节百转千回。
| 






 订阅
订阅