| 编辑推荐: |
本文主要介绍了Claude
Code 的整体架构是什么样的及11 个值得参考的企业级 Agent 工程实践
。希望对你的学习有帮助。
本文来自于微信公众号韦东东,由火龙果软件Alice编辑,推荐。 |
|
摘要:Claude Code 的整体架构是什么样的、一个单线程 Agent
循环如何通过模式切换扩展为 Coordinator-Worker 编排、一套三层记忆系统如何让 Agent
支撑长时间运行的复杂任务(社区有 72 小时连续工作的说法,但源码中未发现该具体数字的直接引用)、从
Prompt Cache 优化到定时任务 Jitter 设计这些体现顶级工程品味的细节,以及最重要的对于正在做企业级大模型应用落地的人来说,这些模式意味着什么。
1
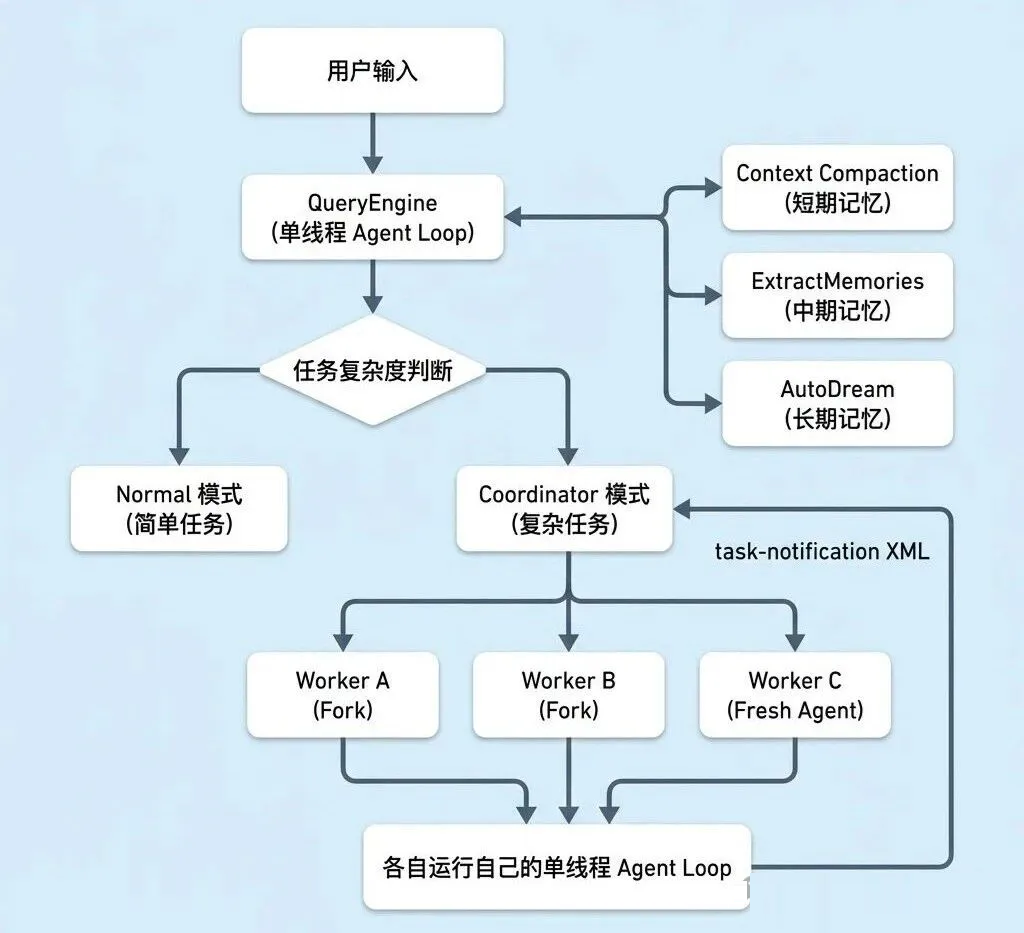
全局架构:分层调度,不是多 Agent 对等协作
在深入各个模块之前,先通过一张全局架构图,快速盘点 Claude Code 的整体设计逻辑。
Claude Code 的源码里有 Coordinator、Worker、Fork 这些概念,乍一看像是一套多
Agent Swarm 系统。但实际读完代码之后会发现,它的架构是分层调度的,换句话说,就是有一个主循环在顶层,需要的时候往下派生子
Agent,子 Agent 干完活把结果交回来。整体是上下级关系,而不是多个 Agent 对等协作。
从架构图里可以看出几个关键点:
1、所有模式共用同一个引擎
不管是普通的单Agent 模式,还是 Coordinator 编排模式,还是被派生出来的 Worker,底层跑的都是同一个
QueryEngine 的 Think → Act → Observe → Repeat 循环。换句话说,Claude
Code 没有为多 Agent 单独写一套运行时,Coordinator 和普通 Agent 的区别,仅仅是换了一套
System Prompt。
2、Coordinator 本质上就是“换了个 Prompt 的普通 Agent”
同一个QueryEngine 实例,给它注入 Coordinator 的 System Prompt,它就开始指挥别人干活;注入普通
Prompt,它就自己干活。模式切换的成本非常低。
3、Worker 是子进程,不是对等节点
每个 Worker 也是一个 QueryEngine 实例,跑自己的单线程循环。Coordinator
派任务下去,Worker干完之后通过 <task-notification> XML 把结果交回来。这是一个上下级的父子关系,不是多个
Agent 互相发消息的 Swarm。
4、记忆系统独立于主循环运行
Context Compaction(短期)、ExtractMemories(中期)、AutoDream(长期)三套记忆机制在主循环旁边各自运行,后面会逐个展开。
下面我按模块再逐个拆解下。
2
Agentic Loop:单线程循环跑完绝大多数任务
Claude Code 的基础是一个单线程递归循环,绝大多数任务在这个循环内就能完成,不需要启动多
Agent。Coordinator-Worker 是在这个基础上通过模式切换实现的可选扩展,而非默认架构。
2.1
QueryEngine:核心运行引擎
QueryEngine.ts 是 Claude Code 的核心文件,管理着整个 Agent 的生命周期:会话状态、工具调用、权限检查、Token
追踪,全在这一个文件里。
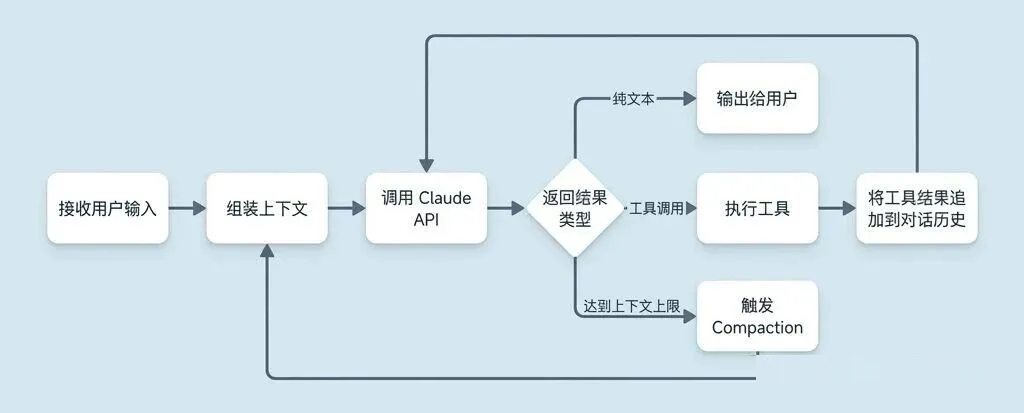
循环的基本结构如下图所示:
这个循环的工程实现有几个值得注意的地方。
首先,整套工具调度系统完全是手搓的,没有用 LangChain、LangGraph 或者任何第三方
Agent 框架。大约 40 个 Tool 的注册、描述、参数校验、调用分发,全在 QueryEngine
里自己管。这带来的好处是完全可控,坏处是工作量不小,但对于 Anthropic 这种体量的团队来说,可控性显然比开发效率更重要。
其次,工具调用是同步递归的。Claude API 返回一个工具调用请求,QueryEngine 就去执行这个工具,把工具输出追加到对话历史里,然后再调一次
Claude API。整个过程是串行的,没有用异步消息队列。这种设计的优势也是简单、可控、容易调试,出了问题直接看调用栈就行。
第三,每一轮循环都有显式的 Token 消耗追踪。QueryEngine 会实时记录已经用了多少
Token,判断上下文窗口还剩多少空间。一旦接近上限,就会触发 Context Compaction(后面第三章会详细讲)。这个机制保证了长时间运行的任务不会因为上下文溢出而崩掉。
下面是从 query.ts(1730 行)中精简出来的核心循环骨架:
//
query.ts — queryLoop 核心结构(精简版,省略错误处理和 fallback)
async function* queryLoop(params: QueryParams)
{
let state = { messages: params.messages, turnCount:
1, /* ... */ }
while (true) {
let messagesForQuery = getMessagesAfterCompactBoundary(state.messages)
// 1. 上下文压缩(接近 Token 上限时自动触发)
const { compactionResult } = await autocompact(messagesForQuery,
/* ... */)
if (compactionResult) messagesForQuery = buildPostCompactMessages(compactionResult)
// 2. 调用 Claude API,流式接收响应
for await (const msg of callModel({ messages:
messagesForQuery, tools, systemPrompt }))
{
if (msg.type === 'assistant') assistantMessages.push(msg)
}
// 3. 没有工具调用 → 结束循环,返回结果
if (toolUseBlocks.length === 0) return { reason:
'end_turn' }
// 4. 执行工具 → 收集结果 → 追加到对话历史 → 下一轮
const toolResults = await runTools(toolUseBlocks,
canUseTool, toolUseContext)
state = { messages: [...messagesForQuery,
...assistantMessages, ...toolResults], turnCount:
state.turnCount + 1 }
} // while (true)
}
|
结构很直白:压缩上下文 → 调 API → 有工具调用就执行、没有就结束 → 把结果塞回对话历史 →
下一轮。整个1730行的 query.ts,本质上就是在这个骨架外面包了一层错误恢复、fallback
模型切换、流式输出、Token 预算管理等生产级的防护逻辑。
2.2
动态 Prompt 组装:六层拼装
Claude Code 的系统提示词不是一个写死的长字符串。context.ts 这个文件负责实时组装
Prompt,每次调用 Claude API 之前,都会从六个不同的来源拼出完整的上下文:
| 层次 |
来源 |
内容 |
更新频率 |
| System |
硬编码 |
基础角色定义、安全规则 |
每版本更新 |
| Mode |
coordinatorMode / workerMode |
Coordinator/Worker/Normal 行为规范 |
每次模式切换 |
| Tools |
40+ 工具注册 + MCP 动态加载 |
工具描述和使用规范 |
MCP 连接时 |
| Project |
CLAUDE.md |
项目级持久记忆 |
用户/Agent 主动更新 |
| Git |
context.ts 实时读取 |
仓库状态快照(分支、改动文件) |
每轮对话 |
| History |
对话历史 + Compaction 摘要 |
会话上下文 |
每轮对话 |
这种分层组装的好处是每一层可以独立更新,互不干扰。比如用户通过 MCP
接入了一个新的工具,只需要更新 Tools 层,不影响 System 和 Project 层的内容。再比如
Agent 从普通模式切换到 Coordinator 模式,只需要替换 Mode 层的 Prompt,其他五层保持不变。
这也解释了前面说的“Coordinator 本质上是换了个 Prompt 的普通 Agent”,模式切换只动了六层里的一层。
2.3
单 Agent 还是多 Agent
国内外很多技术社区过去一年多都在推崇多 Agent 架构,各种 multi-agent framework
也层出不穷。但从 Claude Code 的源码层面上看,它回归到了一个很朴素的选择,默认就是单 Agent
+ 丰富工具集,只有在任务确实复杂到需要并行处理时,才通过模式切换启用 Coordinator-Worker。
这和我之前拆解 Manus 时看到的逻辑是一致的:“Less structure, more intelligence”。对于大多数实际任务,单
Agent 加丰富工具集的方案,比多个 Agent 互相通信要稳定得多。
原因其实想想也很简单,多 Agent 通信本身就会引入额外的失败点,比如消息丢失、状态不一致、死循环。而单
Agent 的上下文是连续的,不需要在多个 Agent 之间来回同步信息。至于扩展性,Claude
Code 通过 MCP 协议支持动态加载外部工具,一个 Agent 能用的工具数量本身就没有硬性限制。
所以 Claude Code 做的事情不是不能做多 Agent,而是大多数时候没必要。下一章来聊聊,它在确实需要多
Agent 的时候是怎么做的。
3
Coordinator-Worker:需要时才启用的多 Agent 编排
Claude Code 的 Coordinator-Worker 不是独立于 Agent Loop
的另一套系统,而是在同一个 QueryEngine 上换了一套 Prompt 就能启用的编排模式,也就是需要的时候打开,不需要的时候关掉。Coordinator
最核心的工作不是把任务分下去让别人干,而是把别人干完的结果读懂想明白、再决定下一步怎么做。
3.1
Coordinator 的 370 行系统提示词
coordinatorMode.ts 里的 getCoordinatorSystemPrompt()
函数返回了一份超过370行的 System Prompt。这份 Prompt 本身就是一份多 Agent
编排的工程规范文档,下面摘出几个最关键的设计。
四阶段工作流。 Coordinator 的 Prompt 里定义了一张明确的分工表(coordinatorMode.ts
第 204-209 行):
| 阶段 |
执行者 |
职责 |
| Research(调研) |
Worker(可并行) |
调查代码库、定位文件、理解问题 |
| Synthesis(综合) |
Coordinator 自己 |
阅读调研结果,理解问题,撰写实施方案 |
| Implementation(实施) |
Worker |
按方案做针对性修改,提交代码 |
| Verification(验证) |
Worker |
验证改动是否正确 |
这里最关键的是 Synthesis 阶段——Prompt 里用了非常强硬的语气明确要求这一步必须由
Coordinator 自己做(第 255-259 行):
Always
synthesize — your most important job. When workers
report research findings, you must understand
them before directing follow-up work. Read the
findings. Identify the approach. Then write
a prompt that proves you understood by including
specific file paths, line numbers, and exactly
what to change. |
永远要做综合——这是你最重要的工作。 当 Worker 汇报调研结果后,你必须先理解这些结果,然后才能指导后续工作。读结果、分析思路、然后写一个能证明你理解了的
Prompt——里面要包含具体的文件路径、行号和修改内容。
紧接着,Prompt 里还给出了一个反面教材(第 262-268 行):
// 反面教材——偷懒式委派(Anti-pattern
— lazy delegation)
AgentTool({ prompt: "Based
on your findings, fix the auth bug",
... })
// 正面示例——综合后的精确指令
AgentTool({ prompt: "Fix
the null pointer in src/auth/validate.ts:42.
The user field on Session
is undefined when sessions expire but the
token remains cached. Add
a null check before user.id access —
if null, return 401 with
'Session expired'. Commit and report the hash.",
... })
|
这段反面教材指出了一个在实际项目中非常常见的问题,“based on
your findings, fix the bug”(根据你的调研结果,修复这个 bug)。这种写法把理解工作推给了
Worker,而 Coordinator 自己没有做任何综合判断。正确的做法是 Coordinator
读完调研结果后,自己消化、理解,然后给 Worker 一个包含具体文件路径、行号和修改方案的精确指令。
并行是核心优势。 Prompt 的 Concurrency 部分(第 213 行)直接写道:
Parallelism
is your superpower. Workers are async. Launch
independent workers concurrently whenever possible
— don't serialize work that can run simultaneously.
|
并行是你的超能力。 Worker 是异步的。只要任务之间互相独立,就应该同时启动,不要把能并行的工作串行化。
同时也划了红线,就是只读任务(调研)可以随意并行,写操作(修改代码)同一组文件同一时间只能有一个 Worker
在改。
3.2
AgentTool:Fork 和 Fresh Agent 的选择
AgentTool/prompt.ts 定义了子 Agent 的两种模式。Fork 模式继承父 Agent
的完整上下文,和父 Agent 共享 Prompt Cache,所以调用成本很低。Fresh Agent
模式从零开始,适合需要"独立视角"的场景,比如代码审查——不希望审查者带着实现者的预设来看代码。
源码里提供了一张选择决策表(AgentTool/prompt.ts 第 284-291 行),列出了几种典型场景的推荐做法:
| 场景 |
推荐方式 |
原因 |
| 调研结果正好覆盖了要修改的文件 |
Continue(继续同一 Worker) |
Worker 已有相关文件的上下文 |
| 调研范围很广但实施范围很窄 |
Spawn fresh(新建 Worker) |
避免把调研噪声带入实施上下文 |
| 纠正失败或扩展最近的工作 |
Continue |
Worker 有错误上下文,知道刚才试过什么 |
| 验证另一个 Worker 刚写的代码 |
Spawn fresh |
验证者需要完全独立的视角,避免先入为主 |
Prompt 里还定义了两条很有意思的规范:
1、Don't peek(不要偷看)
Fork 返回结果后,Coordinator 不要去读 Fork 的中间过程文件。源码原文(第
91 行):“Reading the transcript mid-flight pulls the
fork's tool noise into your context, which defeats
the point of forking.”——偷看 Fork 的工作过程会把工具调用的噪声引入 Coordinator
的上下文,这和 Fork 的初衷矛盾。
2、Don't race(不要抢跑)
Fork 还在运行时,Coordinator 不能预测或编造结果。源码原文(第 93 行):“Never
fabricate or predict fork results in any format —
not as prose, summary, or structured output.”——不要以任何形式编造
Fork 的结果。如果用户在 Fork 完成之前追问进展,Coordinator 应该说还在跑,给状态,不给猜测。
3.3
Ultraplan:远程 Agent 编排
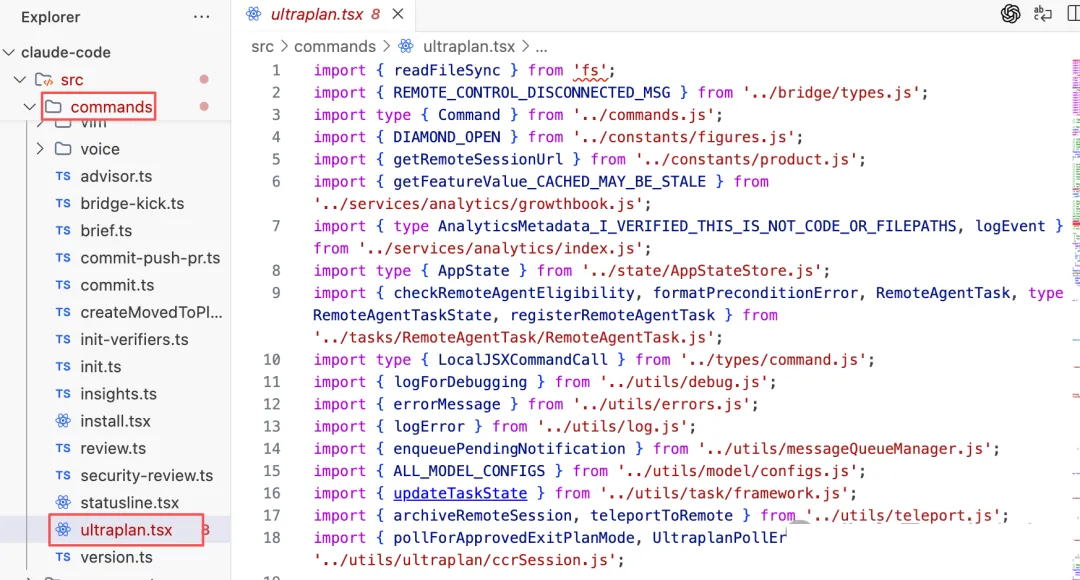
commands/ultraplan.tsx 还暴露了一个标记为 ant-only(Anthropic
内部使用)的功能。虽然普通用户用不到,但它背后的架构模式值得了解。
Ultraplan 的流程是一个 Plan → Approve → Execute 的三阶段模型。第一步,把本地对话上下文通过"teleport"机制序列化后传送到远程
CCR(Claude Code Remote)环境,用更强的模型(Opus 级,30 分钟超时)生成规划方案。第二步,方案生成后等待人类审批,支持轮询机制。第三步,审批通过后在本地按计划执行。
这部分我觉得有两个设计值得注意,一是 Teleport 机制解决了本地资源不够做复杂规划,但不想把整套代码上传到云端的矛盾。就是只传送对话上下文,不传代码。二是计划和执行的模型分离,规划用强模型(高成本、低频),执行用快模型(低成本、高频)。
这和我在之前介绍过的售前报价 Agent 项目中设计的“草稿生成 → 老板审核 → 下载报价单”三阶段其实是同一个模式。
4
三层记忆系统:短期压缩、中期萃取、长期整合
Claude Code 有三套独立的记忆管理机制,分别解决短期、中期、长期记忆的问题。这部分在泄露之前是外界讨论比较多的一个话题,也是我认为这次源码泄露中技术含金量最高的部分。
4.1
Context Compaction:9 段式结构化摘要
services/compact/prompt.ts(375 行)定义了上下文压缩的完整逻辑。当对话上下文接近
Token 上限时,Claude Code 不是简单地截断历史消息,而是用一个专门的 LLM 调用把对话历史压缩成一份结构化的摘要。
这份摘要有严格的 9 段格式要求:
1、Primary Request and Intent(主要需求和意图)
2、Key Technical Concepts(关键技术概念)
3、Files and Code Sections(涉及的文件和代码片段,包含实际代码)4、Errors
and fixes(遇到的错误和修复方案)
5、Problem Solving(问题解决过程)
6、All user messages(所有用户消息,逐条保留,不能遗漏)
7、Pending Tasks(待办任务)
8、Current Work(当前工作状态)
9、Optional Next Step(可选的下一步,包含原始对话的直接引用,防止任务漂移)
|
这里有两个工程细节值得展开:
第一个是 <analysis> scratchpad 机制
摘要生成时,模型先在 <analysis> 标签里写一段分析草稿,用来梳理思路、提高摘要质量。生成完成后,formatCompactSummary()
函数会自动把这段草稿剥离掉,不让它进入正式的上下文。也就是说,用额外的 Token 消耗换取了更高质量的摘要输出,但这些额外的
Token 不会长期占用上下文窗口。
第二个是 Partial Compaction
Claude Code 不是把整个对话历史全部压缩成摘要,而是只压缩靠前的旧内容,保留最近几轮的原始对话(通过
recentMessagesPreserved 参数控制)。这样最近的上下文保持原貌,不会因为压缩而丢失细节,远期的上下文则变成高密度的结构化摘要。
4.2
ExtractMemories:后台自动记忆萃取
services/extractMemories/prompts.ts 定义了一个后台运行的子 Agent,它作为主对话的分叉(Fork)独立运行,自动从对话中提取值得长期保存的信息。
这个机制有一个前置判断:如果主 Agent 在对话过程中已经主动写过记忆文件(通过 hasMemoryWritesSince
检测),extractMemories 就会跳过,不重复提取。只有主 Agent 没有写记忆的情况下,它才会自动介入。
在执行层面有一个严格的约束,就是 turn budget。extractMemories 要求先并行
Read 所有可能需要更新的记忆文件,再并行 Write,不允许交替读写。这个约束保证了记忆更新的原子性,避免出现读到半更新状态的问题。记忆本身也区分了
private memory(个人记忆)和 team memory(团队记忆),写入不同的文件路径。
这和我在工控知识库项目那期文章里提到的“强制反馈 → 数据积累 → 持续优化”闭环是同一个思路,区别在于
Claude Code 把这个闭环做到了完全自动化,用户不需要主动做任何反馈操作,系统自己就能从对话中提取有价值的信息。
从 1600+ 份 Word 文档到生产级 RAG
4.3
AutoDream:记忆整合
services/autoDream/consolidationPrompt.ts 定义了一个叫
Dream 的功能。简单说就是 Claude Code 在 Agent 空闲的时候,会自动对已有的记忆文件做一次整理和合并。
这个过程分四个阶段执行。Phase 1 是 Orient(定位),ls 记忆目录,读取 MEMORY.md
索引文件,搞清楚当前有哪些记忆。Phase 2 是 Gather recent signal(收集新信号),从最近的
session transcript 中 grep 出新产生的信息。Phase 3 是 Consolidate(整合),把新信号和旧记忆合并,删除互相矛盾的旧记忆,还会把“昨天”“上周”这种相对日期转换成绝对日期,避免时间久了之后语义失真。Phase
4 是 Prune and index(修剪和索引),确保 MEMORY.md 索引文件不超过 200
行或 25KB。
这个设计似乎是借鉴了认知科学中关于睡眠和记忆整合的研究,就是人在睡眠期间大脑会对白天的短期记忆做整理,把有用的转化为长期记忆,把无用的淘汰掉。Claude
Code 用了一个类似的异步过程,在 Agent 不忙的时候做同样的事情,不得不说是个很好的巧思。
4.4
三层协同
为了方便理解,我把三层记忆系统的协同关系大致整理如下:
| 记忆层 |
机制 |
生命周期 |
触发条件 |
数据载体 |
| 短期 |
Context Compaction |
单次会话 |
接近 Token 上限时自动触发 |
对话内摘要 |
| 中期 |
ExtractMemories |
跨会话 |
每轮对话结束后后台运行 |
CLAUDE.md 文件 |
| 长期 |
AutoDream |
跨项目 |
Agent 空闲时异步运行 |
MEMORY.md + 索引 |
对比目前市面上的 Agent 框架,比如 LangGraph 的 Checkpointer、CrewAI
的 Memory,Claude Code 的方案在自动化程度和结构化程度上都高出不少。大多数框架的记忆功能还停留在把对话历史存起来的阶段,而
Claude Code 是做到了自动提取、自动整合、自动修剪的完整闭环。
5
工程细节:几个不起眼但很实用的设计
除了架构层面的东西,源码里还有不少细节设计,单独拿出来和各位说道说道。每一个都不算大,但放在一起就能看出
claude code 团队在生产环境中踩过多少坑,下面挑几个我觉得最有参考价值的。
5.1
Agent 列表从内联改为 Attachment:省了 10.2% 的 Cache Token
AgentTool/prompt.ts 里有一个函数叫 shouldInjectAgentListInMessages(),专门处理
Agent 列表的注入方式。
原来的做法是把当前可用的 Agent 列表写在 AgentTool 的工具描述(tool description)里。但问题是,MCP
客户端连接、插件加载、权限变更的时候,Agent 列表会跟着变。列表一变,工具描述就变了,工具描述一变,整个
tools-block 的 Prompt Cache 就失效了。
源码注释里记录了具体的量化数据(AgentTool/prompt.ts 第 53 行 + attachments.ts
第 1482 行):
"The
dynamic agent list was ~10.2% of fleet cache_creation
tokens: MCP async connect, plugin load, permission
changes all mutate the list..." |
10.2% 的全局 cache_creation tokens,这个数字不小。解决方案是把 Agent
列表从工具描述里拿出来,改为通过 agent_listing_delta 这种 attachment
消息注入到对话中。这样工具描述变成了静态内容,Cache 不会再因为 Agent 列表的变化而失效。
这个优化思路其实是通用的,凡是用到 Prompt Cache 的场景,都应该把频繁变化的内容从 Cache
边界内移到边界外。
5.2
Cron 调度的 Jitter 设计:避开整点
ScheduleCronTool/prompt.ts 里有一个很小但很聪明的设计。当用户说“每天早上
9 点提醒我”的时候,Claude Code 不会把 cron 表达式设成 0 9 * * *,而是会偏移几分钟,比如设成
57 8 * * * 或者 3 9 * * *。
原因很直接,全球所有用户说“9 点”都会映射到 :00,如果不做偏移,API 请求就会在整点集中爆发,给服务端造成压力峰值。Prompt
里原文是这么写的:
"Pick a minute that is NOT 0 or 30... the user
will not notice, and the fleet will."
用户不会注意到提醒是 8:57 还是 9:03 发出的,但服务端的负载曲线会平滑很多。这种用户无感但系统受益的设计,在高并发的企业级应用中非常实用。
5.3
NO_TOOLS_PREAMBLE:防止模型在不该调工具的时候调工具
services/compact/prompt.ts 第 12-26 行有一个很有代表性的工程细节。
Context Compaction 是通过 Fork 主对话来执行的。Fork 会继承父对话的完整工具集,这是为了命中
Prompt Cache。但摘要任务本身不需要调用任何工具,只需要模型输出一段文本。
问题在于 Sonnet 4.6+ 这一代模型有时候会自作主张去调用工具,即使 Prompt 末尾已经写了不要调用工具。一旦工具调用被拒绝(因为
maxTurns: 1 限制了只有一轮机会),这一整轮压缩就失败了,只能降级到流式 Fallback
重新来。
源码注释里记录了精确的故障率(compact/prompt.ts 第 16 行):
"2.79% on 4.6 vs 0.01% on 4.5"
也就是说在 Sonnet 4.6 上,差不多每 36 次就有 1 次压缩会因为模型擅自调用工具而失败。解决方案是在
Prompt 的最前面(不是末尾)加一段强硬的 NO_TOOLS_PREAMBLE:
CRITICAL: Respond with TEXT
ONLY. Do NOT call any tools.
- Do NOT use Read, Bash,
Grep, Glob, Edit, Write, or ANY other tool.
- Tool calls will be REJECTED
and will waste your only turn — you will fail
the task.
|
把约束放在 Prompt 开头而不是末尾,是因为模型对 Prompt 开头部分的注意力最集中。这个经验我在实际做项目的时候也经常验证到,关键的约束条件写在前面,比写在后面有效得多。
5.4
Feature Flags 的编译时消除
Claude Code 通过 bun:bundle 提供的 feature() 函数来控制功能开关,比如
feature('VOICE_MODE')、feature('KAIROS')、feature('COORDINATOR_MODE')
等。
这套机制和一般的运行时 feature flag 不同。它是编译时的 Dead Code Elimination,也就是说如果某个
feature flag 是关闭状态,相关的代码在编译阶段就被完全移除了,构建产物里根本不会出现这部分代码。不会占内存,没有运行时判断分支的开销,开发团队可以在同一个代码仓库里并行开发多个未发布的功能,互不干扰。
从泄露的 feature flags 也能看出一些 Anthropic 尚未发布的功能方向:PROACTIVE(主动模式)、KAIROS(定时任务系统)、DAEMON(守护进程模式)、VOICE_MODE(语音交互)、MONITOR_TOOL(监控工具)等。这些功能的代码已经写好了,只是通过
feature flag 控制着不对外暴露。
6
工程视角:从 Prompt Engineering 到 Harness Engineering
整体看完 Claude Code 的源码,我最大的感受其实不是某个具体技巧有多巧,而是这套源码很好地体现了行业正在发生的一个趋势变化。
6.1
三个阶段的演进
个人感觉,过去三年大模型应用开发的重心经历了以下三个阶段的迁移:
23 到 24 年,市面上谈得最多的是 Prompt Engineering,也就是怎么写一条好的结构化的提示词,让模型输出更准确的结果。这个阶段的核心假设是只要
Prompt 写得够好,模型就能给出好的输出。
到了 25 年,市面上讨论 Context Engineering/上下文工程开始多了起来,核心关注的是怎么管理、压缩、保留和传递上下文信息,让模型在长时间运行中不会忘事。Claude
Code 的三层记忆系统整体看下来(Compaction / ExtractMemories / AutoDream)也是这个阶段的典型产物。
到了 26 年,一个更大的概念开始被讨论,也就是最近海内外还是烂大街的 Harness Engineering。这个概念的核心观点是模型本身在快速进化,但模型能力的差异在缩小,真正决定一个
Agent 系统能不能在生产环境中稳定运行的,不是模型本身,而是围绕模型构建的那一整套控制系统。这套系统包括工具编排、记忆管理、错误恢复、降级兜底、权限控制、可观测性等等,行业里把它叫做
Harness(直译是缰绳,意思是控制和约束模型行为的基础设施)。
一句话总结就是:“Agents aren't hard; the harness is hard.”(做
Agent 不难,难的是做 Harness。)
6.2
Claude Code 对三个阶段的覆盖
回头来看 Claude Code 的源码,它对这三个阶段的覆盖是很完整的。
Prompt Engineering 层面,它有精心设计的多层 Prompt 组装(System
/ Mode / Tools / Project / Git / History 六层动态拼装),有
Coordinator 的 370 行系统提示词,有 AgentTool 里详尽的 Fork 规范。
Context Engineering 层面,它有完整的三层记忆系统(Compaction 做短期压缩、ExtractMemories
做中期萃取、AutoDream 做长期整合),有 Partial Compaction 的部分保留机制,有
<analysis> scratchpad 的质量优化。
Harness Engineering 层面,它有NO_TOOLS_PREAMBLE 这种“Prompt
约束 → 代码校验 → 降级兜底”的三层防护,有 Cron 调度的 Jitter 设计,有 feature
flag 的编译时消除,有 maxTurns 的硬性轮次限制,有 Prompt Cache 的精细化管理。
这三个层面不是递进替代的关系,而是同时存在、各自负责不同层面的问题。Prompt 管的是怎么跟模型说话,Context
管的是模型能记住什么,Harness 管的是模型出错了怎么办。
6.3
可迁移到企业场景的三个模式
最后,我想可以从这套源码中能提炼出三个通用模式,对做企业级大模型应用都有直接的参考价值。
第一个是三层防护:Prompt 约束 → 代码校验 → 降级兜底。 Claude Code 在每一个可能出错的环节都能看到这个模式。比如
NO_TOOLS_PREAMBLE 用 Prompt 约束模型不要调用工具,maxTurns: 1
用代码限制只有一轮机会,万一还是失败就降级到流式 Fallback 重新来。这和我在之前介绍过的售前报价
Agent 项目中设计的 SKU 校验三道防线(Prompt 强约束 → 代码事后校验 → 自动替换兜底)是同一个工程范式。不能指望
Prompt 能 100% 约束模型行为,任何关键逻辑都必须有代码层面的兜底。
第二个是推理和执行的分离。 Claude Code 的架构贯穿一个原则:LLM 只负责推理和决策,格式处理、计算、文件操作这些确定性的工作交给代码。Compaction
的 formatCompactSummary() 负责格式清理,Coordinator 做综合判断而
Worker 做具体执行,Cron 调度中 LLM 理解"每天 9 点"而代码负责
Jitter 偏移。这和我在报价 Agent 中坚持的"模板 + JSON 填充"原则完全一致,在严肃的生产类场景里,LLM
负责内容生成,模板负责格式约束,代码负责逻辑校验。
第三个是无感数据飞轮。 我在之前的很多项目里,反馈到优化的闭环需要用户主动参与,比如报价 Agent
的强制反馈才能下载,工控知识库的点赞/点踩。Claude Code 的 ExtractMemories
把这个闭环完全自动化了,不需要用户做任何额外操作,系统自己从对话中提取有价值的记忆并持久化。最好的数据收集方式,就是让用户在完成本职工作的过程中自然地贡献数据。
7
写在最后
为什么要花这么大篇幅来拆解 Claude Code?
因为 AI Coding 是目前大家公认在 Agent 领域里最成熟、最能发挥大模型能力的应用方向。而
Claude Code 又是这个方向里,全球范围内公认产品化程度最高的工具之一。说实话,我日常工作中
Claude Code 和 Codex 是交叉使用的,GPT 5.4 pro 的底层模型能力并不见得比
Claude 4.6 Opus 弱,某些场景下甚至更强。但从工程架构和产品设计的角度来看,Claude
Code 在很多地方确实走得更远,比如它的三层记忆系统、Coordinator-Worker 的 Prompt
工程规范、以及 Prompt Cache 优化这些细节,都不是靠模型能力堆出来的,而是靠工程团队在生产环境中反复迭代打磨出来的。
现在市面上模型层出不穷,各种 Agent 框架也越来越多。我觉得在精力有限的情况下,与其什么都看,不如把最好的东西研究透。尤其是在企业级大模型应用落地的场景里,不要闭门造车,要看全球范围内最好的实践是怎么做的。Claude
Code 这次泄露的源码里那些工程设计,说白了就是房间里的大象,值得做 Agent 的盆友结合自己的业务场景针对性借鉴。
这篇文章受限于篇幅和写作时间,很多内容就点到为止。我另外整理了四份深度拆解文档,连同源码包一起提供给知识星球和视频课程的盆友们:
1、Context Compaction完整Prompt 逐句精读(对应源码src/services/compact/prompt.ts,375
行)。NO_TOOLS_PREAMBLE 为什么放在 Prompt 最前面、<analysis>
scratchpad 怎么做到“用 Token 换质量但不浪费持久空间”、Partial Compaction
的三种模式分别适用什么场景。每一段都给了英文原文 + 中文翻译 + 设计意图,最后附了面向企业多轮对话场景的改造建议。
2、Coordinator + AgentTool 完整 Prompt 精读(对应源码 src/coordinator/coordinatorMode.ts
370 行 + src/tools/AgentTool/prompt.ts 288 行)。四阶段工作流表格、Synthesis
规范的正反面教材、Fork vs Fresh Agent 的决策矩阵、Don't peek / Don't
race 的完整原文。最后附了一张 Claude Code vs LangGraph vs CrewAI
的横向功能对比表。
3、三层记忆系统架构设计文档(对应源码 src/services/compact/、src/services/extractMemories/、src/services/autoDream/
三个目录)。重点是架构全局图和数据流时序图,讲清楚三层之间怎么协同、各自的触发条件和降级策略。最后根据不同的企业场景(单次对话、跨会话、长周期项目)给了简化实现建议。
4、Feature Flags 全量清单 + 未发布功能预测(通过扫描源码中所有 feature()
调用整理)。86 个 Flag 逐个标注了引用次数、所在文件和功能描述。KAIROS 定时任务系统共
86 次引用、TRANSCRIPT_CLASSIFIER 独占 69 次、TEAMMEM 团队记忆
44 次,从这些数据能看出 Anthropic 下一步的产品方向。
| 






 订阅
订阅