| 编辑推荐: |
本文主要介绍了如何从0构建AI
Agent相关内容!希望对你的学习有帮助。
本文来自于微信公众号腾讯云开发者,由火龙果软件Alice编辑,推荐。 |
|
01
概念全景图
02
基础概念
2.1 LLM(大语言模型)
ChatGPT、Claude、Gemini、DeepSeek 等都是 LLM。本质是超大号的"文字接龙"机器——给一段文字,按概率逐词预测下一个词。当参数量达到千亿级别,它就涌现出了写代码、写文章、做数学题的能力。
2.2 LLM API(大模型接口)
LLM 跑在云端 GPU 集群上,厂商通过 HTTP API 提供调用能力:
你的代码
→ HTTP POST(带上问题) → LLM 服务 → HTTP 响应(返回回答) |
2.3 Context(上下文)
LLM 本身是无状态的——每次调用都是一次全新的请求,它不会记得上一句你说了什么。所谓"上下文",就是你随请求一起发过去的所有信息,包括:
- 对话历史:之前的每一轮问答
- 系统提示词:告诉 AI "你是谁、该怎么做"的指令
- 工具结果:上一步工具调用返回的数据
第
1 次请求:[消息1] → AI 回复1
第 2 次请求:[消息1, 回复1, 消息2] → AI 回复2
第 3 次请求:[消息1, 回复1, 消息2, 回复2, 消息3] → AI 回复3 |
每次都把完整历史发过去,AI 才能"记住"之前聊了什么。"记忆"不在
AI 脑子里,而在你发送的数组里。
每个模型有上下文窗口(Context Window)限制,比如 128K tokens。超出这个长度,最早的内容就会被截掉。
2.4 Tool / Function Calling(工具调用)
这是从"聊天机器人"进化到"Agent"的关键一步。普通
LLM 只能生成文字,但如果告诉它有个 get_weather 工具,它就能返回结构化的调用请求:
{
"functionCall": { "name":
"get_weather", "args": {
"city": "深圳" } } } |
LLM 并没有真的查天气,它只是说"我想调这个工具"。真正执行的是你的代码。LLM
负责"动脑"决策,代码负责"动手"执行。
2.5 AI Agent(智能体)
Agent 是一种架构模式,把上面三者串在一起:
Agent = LLM(大脑) + Tools(手脚) + Loop(驱动循环) |
1.LLM 负责理解任务、做出决策
2.Tools 负责执行具体操作
3.Loop 让 AI 反复"思考→行动→观察",直到任务完成
2.6 MCP(模型上下文协议)
有了 Tool Calling,Agent 可以调用工具。但每接一个新工具,你都要写一套定义、解析、执行的代码。工具一多,维护成本爆炸。
MCP(Model Context Protocol) 定义了一套统一的协议,让 Agent 能以即插即用的方式对接外部工具和数据源——相当于
AI 世界的 USB 接口标准。
2.7 Sub-Agent(子智能体)
一个 Agent 什么都干,容易出错,上下文也会被塞满无关信息。Sub-Agent 模式是让主 Agent
把子任务委派给专门的小 Agent。每个子 Agent 有自己独立的上下文和专属工具,做完后只把结果交还给主
Agent。
2.8 Agent Skill(技能)
Tool 是单个动作(比如"读文件"),但很多任务是一套固定流程(比如"生成
Git commit"需要:查状态 → 看 diff → 写 commit message
→ 执行提交)。
Agent Skill 就是预定义好的 prompt + 工具组合——把多个工具和 prompt
打包成一键触发的流程。
2.9 Context Management(上下文管理)
LLM 的上下文窗口是有限的。对话越长,历史消息越多,总会塞满。而且 token 越多,响应越慢、费用越高。
上下文管理就是在"记住足够多"和"别超标"之间找平衡,常见策略包括滑动窗口、摘要压缩、RAG
检索增强。
03
从零构建 Agent — 四个阶段
整个构建过程分为四个递进阶段,每个阶段解锁一项新能力。
3.1 阶段一:单次对话(API 调用)
最简单的起点——调用 LLM API,让 AI 回答一个问题。
const body = {
messages: [
{ role: "system", content: "你是一个有帮助的助手。"
},
{ role: "user", content: "你好"
},
],
};
const res = await fetch(apiEndpoint, {
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": `Bearer ${apiKey}`,
},
body: JSON.stringify(body),
});
const data = await res.json();
console.log(data.choices[0].message.content);
|
关键参数:
系统提示词(system prompt):告诉 AI "你是谁、该怎么做"的隐藏指令,用户看不到,但
AI 会始终遵守。
对话内容(messages):用户实际发送的消息,每条消息带 role(谁说的)和 content(说了什么)。
能力: 单轮问答,关掉程序就全忘。
3.2 阶段二:多轮对话(上下文维护)
LLM 本身不记得上一句你说了什么——每次 API 调用都是一次全新的、独立的请求。解决方案是在客户端维护一个
history 数组,每次请求时带上完整历史:
class
Chat {
private history: Message[] = [];
async send(text: string): Promise<string>
{
this.history.push({ role: "user",
content: text });
const reply = await this.client.sendMessage(this.history,
this.systemPrompt);
this.history.push({ role: "assistant",
content: reply });
return reply;
}
}
|
每次调 API 都把完整对话历史发过去,LLM 本身是无状态的,"记忆"完全靠客户端的数组模拟。
能力: 多轮对话,但只会"说"不会"做"。
3.3 阶段三:工具调用(Function Calling)
AI 能记住对话了,但它只能"说",不能"做"。给 AI
一双"手"——Tool Calling。
工具注册表——用标准格式描述每个工具:
{
name: "run_shell_command",
description: "Run a shell command on the
user's machine...",
parameters: {
command: { type: "string", description:
"The shell command to execute" },
},
required: ["command"],
} |
工具实现:
execute(params: Record<string,
unknown>): Promise<unknown> {
const command = params.command
as string;
return new Promise((resolve)
=> {
exec(command, { timeout:
timeoutMs }, (error, stdout, stderr) =>
{
resolve({ exitCode: error?.code
?? 0, stdout, stderr });
});
});
}
|
把工具列表随请求发给 API 后,AI 的回复可能从纯文本变成函数调用请求:
//
纯文本回复
{ "text": "你好!有什么可以帮你的?"
}
// 工具调用请求
{ "functionCall": { "name":
"run_shell_command", "args":
{ "command": "ls -la"
} } }
|
AI 没有真的执行命令,它只是下达指令,代码负责跑腿。
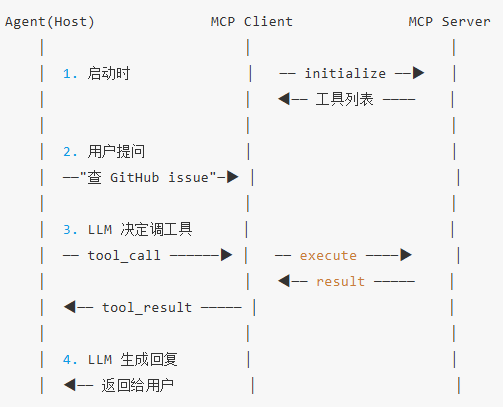
3.4 阶段四:Agent Loop(ReAct 循环)
有了工具调用能力,但 AI 只能完成"单步动作"。现实任务通常需要多步协作。引入
Agent Loop,即自动化的驱动循环——调完工具看结果,把结果喂回给 AI,让它继续判断下一步。
这个过程通常被称为 ReAct (Reason + Act):
1.Reasoning(推理):AI 思考当前状况,决定下一步
2.Acting(行动):AI 发出工具调用请求,代码执行工具
3.Observation(观察):代码将工具执行结果反馈给 AI
核心循环代码:
async
send(text: string): Promise<string> {
this.history.push({ role: "user",
content: text });
for (let i = 0; i < MAX_ROUNDS; i++)
{
const result = await this.client.sendMessage(this.history,
options);
this.history.push({ role: "assistant",
content: result });
if (!result.functionCall) {
return result.text ?? "";
}
const { name, args } = result.functionCall;
const toolResult = await this.toolRegistry.execute(name,
args);
this.history.push({
role: "tool",
content: JSON.stringify({ name, result: toolResult
}),
});
}
throw new Error("Max tool call rounds
exceeded");
}
|
实际运行示例:
用户:"帮我看看当前目录有什么文件,然后统计代码行数"
第 1 圈:AI → 执行 ls -la → 代码返回结果
第 2 圈:AI → 执行 wc -l src/*.ts → 代码返回结果
第 3 圈:AI → 返回文本总结 → 循环结束 ✅
|
MAX_ROUNDS 是安全阀,防止 AI 死循环。
3.5 工程化原则
拥有 Agent Loop 后,Agent 已经能自主运行,但要真正可用,还需要关注以下工程化原则。
1. 工具设计:从 "万能胶" 到 "手术刀"
不要只提供一个 run_shell_command 万能工具,而应该设计专门的工具:
- read_file:支持分页读取,避免大文件直接撑爆上下文
- edit_file:通过 old_string → new_string 的方式修改代码,比让 AI
生成 shell 命令更安全且可靠
- list_directory:返回结构化的 JSON 列表,包含文件大小和类型
工具越"原子化"、越"结构化",Agent 运行的成功率就越高。
2. 上下文注入:给 Agent 戴上 "扩增实境眼镜"
在每轮对话启动前,自动采集环境信息并注入到 Prompt 中:
- 当前工作目录 (CWD)
- 文件列表 (File List)
- 当前时间 (Timestamp)
这样 Agent 一开始就知道自己"在哪里"、"手头有什么",不需要先花一轮工具调用去探索环境。
3. 显示优化:让 "黑盒" 变透明
Agent 在执行工具时,应该给用户清晰的反馈:
interface
ToolExecuteResult {
data: unknown; // LLM 需要的结构化原始数据
displayText?: string; // 用户在终端看到的友好提示
} |
比如执行 shell 命令时显示 $ ls -la,读取文件时显示 Read src/index.ts
(lines 1-20),而不是把原始 JSON 甩给用户。
4. 指令优化:从 "聊天" 到 "工作"
系统提示词对 Agent 的行为影响巨大,为开发者工具场景应注意:
- 强制要求:禁止废话,直接输出结果
- 角色定位:明确自己是一个交互式 CLI Agent
- 思考链:鼓励在调用工具前进行简短的推理
04
进阶架构
4.1 上下文管理
上下文窗口是 Agent 的"工作记忆",但它有硬性限制。对话越长、工具调用越多,token
消耗越快。
为什么需要上下文管理
| 问题 |
说明 |
| Token 限制
|
每个模型有上下文窗口上限(如 128K tokens),超出就截断 |
| 成本 |
Token 数量直接决定 API 费用,历史越长越贵 |
| 速度 |
输入 token 越多,模型响应延迟越高 |
常见策略
策略 1:滑动窗口
只保留最近 N 轮对话,丢弃更早的消息。
function
slidingWindow(history: Message[], maxTurns:
number): Message[] {
if (history.length <= maxTurns * 2) {
return history;
}
const systemPrompt = history[0];
const recentMessages = history.slice(-(maxTurns
* 2));
return [systemPrompt, ...recentMessages];
} |
优点:实现简单,效果直接。 缺点:早期信息完全丢失。
策略 2:摘要压缩
让 LLM 把旧的对话历史压缩成一段摘要。
原始历史(5000
tokens):
用户问了天气 → AI 查了天气 → 用户问了新闻 → AI 查了新闻 → ...
压缩后(200 tokens):
"用户先查了深圳天气(25°C 晴),然后查了今日科技新闻(共 3 条),
接着要求将新闻翻译成英文。"
|
优点:保留关键信息,压缩比高。 缺点:压缩本身消耗 token,且可能丢失细节。
策略 3:RAG 检索增强
不把所有信息都塞进上下文,而是存到外部知识库,需要时按需检索。
用户提问:"上次讨论的数据库方案是什么?"
1. 把问题转成向量 → 去向量数据库检索
2. 找到相关的历史片段 → 注入当前上下文
3. LLM 基于检索结果回答
|
优点:上下文永远保持精简,可以"记住"无限量的历史。 缺点:需要额外的向量数据库基础设施。
策略组合
实际项目中通常组合使用:
上下文管理没有银弹,需要按场景组合不同策略。
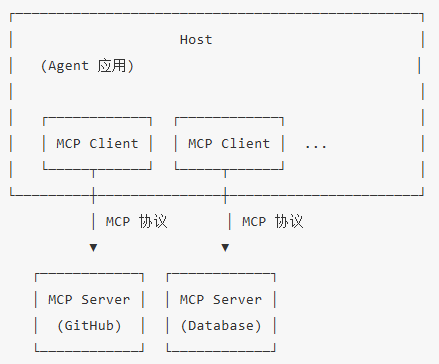
4.2 MCP 协议
每个工具都要写一套"定义→解析→执行"的胶水代码。工具一多,维护成本爆炸。MCP
就是为解决这个问题而生的标准化协议。
MCP 解决的问题
没有 MCP 时:
Agent
A 对接 GitHub → 写一套 GitHub 工具定义 + 执行逻辑
Agent A 对接 Slack → 写一套 Slack 工具定义 + 执行逻辑
Agent B 对接 GitHub → 再写一套(跟 A 的还不一样)
... |
M 个 Agent × N 个工具 = M × N 套集成代码。
有了 MCP:
Agent
A ─┐ ┌─ GitHub MCP Server
Agent B ─┤── MCP 协议 ──────┤─ Slack MCP Server
Agent C ─┘ (标准接口) └─ 数据库 MCP Server |
M + N 套代码就够了。
MCP 的核心能力
MCP 定义了三种核心原语:
1.Tools (工具):Agent 可以调用的可执行函数,让模型执行操作
2.Resources (资源):Server 暴露给 Agent 的只读数据,让模型读取上下文
3.Prompts (提示词):Server 提供的预定义 Prompt 模板,复用高质量的指令
MCP 架构
MCP 通信过程
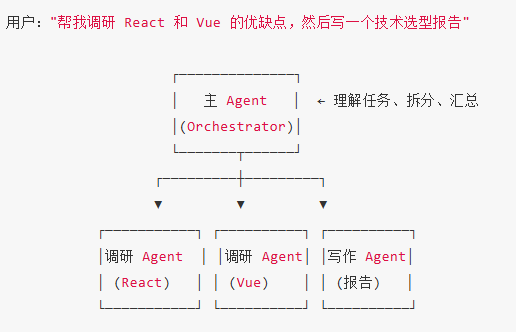
4.3 Sub-Agent 模式
单 Agent 面临两个核心瓶颈:上下文污染(搜索代码的中间结果、测试日志等占满上下文)和任务过杂(需要在不同类型的工作间反复切换)。Sub-Agent
模式通过分工协作来解决这些问题。
Sub-Agent 架构
每个子 Agent:
- 有自己独立的上下文——互不干扰
- 有自己专属的工具集——搜索 Agent 有搜索工具,写作 Agent 有文件工具
- 做完后只返回结果——不带过程中的废料
Sub-Agent 定义
每个 Sub-Agent 通常由以下元素组成:
name:
code-reviewer # 唯一标识
description: "Reviews code..." # 描述信息,用于主
Agent 决策时选择
tools: [read_file, list_dir] # 工具白名单
model: "model-name" # 可覆盖默认模型
maxTurns: 15 # 限制最大工具调用轮数
prompt: | # 专属系统提示词
You are a code reviewer specialized in identifying:
- Security vulnerabilities
- Performance issues
... |
关键设计要点:
- 工具白名单:限制子 Agent 只能用必要的工具,降低风险
- 独立模型:可以为不同子任务选择最合适的模型
- 轮数限制:每个子 Agent 有自己的 maxTurns,防止某个子任务失控
执行流程
主
Agent 决定委派任务
│
▼
1. 根据任务描述选择合适的 Sub-Agent
│
▼
2. 构建受限的工具集(只给白名单中的工具)
│
▼
3. 创建新的 Chat 实例(独立上下文)
│
▼
4. Sub-Agent 执行任务(在自己的 Agent Loop 中)
│
▼
5. 返回结果给主 Agent(只有最终结果,没有中间过程) |
4.4 Agent Skill
Tool 是单个动作,但很多实际任务是一套固定流程,需要多个 Tool 配合加上特定的 prompt
指引。Skill 就是把这套流程打包成一个可复用的快捷操作。
Skill 的本质
一个 Skill = prompt 模板 + 元数据。
Skill 与 Tool、Sub-Agent 的区别
| |
Tool |
Skill |
Sub-Agent |
| 粒度 |
单个动作 |
一套完整流程 |
独立的子任务 |
| 触发 |
LLM 自动选择 |
用户命令 / LLM 调用 |
LLM 调用 |
| 执行方式 |
直接执行函数 |
prompt 注入主对话上下文 |
派生独立 Chat 实例 |
| 上下文 |
共享主 Agent 上下文 |
共享主 Agent 上下文 |
独立上下文 |
Skill 定义示例
name:
commit
description: "Generate a conventional commit
message for staged changes"
trigger: /commit
prompt: |
Analyze the staged changes and generate a commit
message
following the Conventional Commits specification.
The commit message should:
1. Start with a type: feat, fix, docs, style,
refactor, test, or chore
2. Include a scope in parentheses if applicable
3. Have a concise subject line (max 50 chars)
4. Include a body if the change is complex |
两种触发方式
方式一:用户命令触发
用户直接输入触发命令(如 /commit),系统匹配到对应 Skill,将 prompt 注入对话:
const
skillMatch = skillRegistry.match(userInput);
if (skillMatch) {
const injectedPrompt = skillLoader.load(skillMatch.skill,
skillMatch.args);
const reply = await chat.send(injectedPrompt);
} |
方式二:LLM 自主调用
将 Skill 包装成一个 Tool,LLM 在 Agent Loop 中可以自主决定调用:
{
"tool": "skill",
"parameters": {
"skill_name": "commit",
"task":
"为当前暂存的更改生成提交信息"
}
} |
Skill 的价值
| 场景 |
不用Skill |
用Skill |
| 重复性流程 |
用户每次手动描述每一步 |
一条命令一键搞定 |
| 领域知识 |
用户需要知道具体步骤和参数 |
Skill 封装了专家经验,自动执行 |
| 团队协作 |
每个人的操作方式不一致 |
统一的 Skill 定义保证流程一致性 |
4.5 如何选择:Tool vs Skill vs Sub-Agent
|
需求来了
│
├─ 是单个原子操作?(读文件、发请求、执行命令)
│ └─ → 用 Tool
│
├─ 是固定流程?(每次步骤一样,只是输入不同)
│ └─ → 用 Skill
│
├─ 需要独立上下文?(中间过程会污染主对话)
│ └─ → 用 Sub-Agent
│
└─ 需要不同模型?(子任务适合用专门的模型)
└─ → 用 Sub-Agent
|
具体场景对照
| 场景 |
推荐方案 |
理由 |
| 读取一个文件 |
Tool |
单个原子操作 |
| 生成 Git commit message |
Skill |
固定流程(查 diff → 写 message → 提交) |
| 调研某个技术方案 |
Sub-Agent |
需要大量搜索,中间结果会污染主上下文 |
| 执行代码审查 |
Sub-Agent |
需要独立上下文,可能需要不同模型 |
| 格式化代码 |
Tool |
单个操作,调用 formatter 即可 |
| 生成单元测试 |
Skill |
固定流程(读源码 → 分析 → 生成测试) |
| 同时调研 3 个竞品 |
Sub-Agent × 3 |
并行执行,各自独立上下文 |
组合使用
实际项目中这三者经常组合使用:
用户输入
/review(触发 Skill)
│
▼
Skill prompt 指导主 Agent 拆分任务
│
├─ Sub-Agent 1:代码审查(使用 read_file Tool)
├─ Sub-Agent 2:安全检查(使用 grep、read_file Tool)
└─ Sub-Agent 3:性能分析(使用 run_command Tool)
│
▼
主 Agent 汇总三个 Sub-Agent 的结果,生成报告 |
05
总结
本文覆盖了从 LLM 到 Agent 的完整知识体系:
基础概念:
- LLM 是无状态的文字接龙机器,通过 API 调用
- Context 是你发送的全部信息(历史 + 提示词 + 工具结果),"记忆"在数组里而不是
AI 脑子里
- Tool Calling 让 LLM 从"只能说"进化到"能动手",但
LLM 只负责决策,代码负责执行
构建过程(四个阶段):
1.单次对话 → 调 API,一问一答
2.多轮对话 → 客户端维护 history 数组
3.工具调用 → 注册工具,LLM 决定何时调用
4.Agent Loop → ReAct 循环,自动多步执行
进阶架构:
- 上下文管理:滑动窗口 摘要压缩 RAG,按场景组合
- MCP 协议:标准化工具对接,M × N → M + N
- Sub-Agent:独立上下文的分工协作
- Skill:可复用的流程模板
- 选择原则:原子操作用 Tool,固定流程用 Skill,需要独立上下文用 Sub-Agent
| 






 订阅
订阅