| 编辑推荐: |
本文主要介绍了Claude
Agent Skills 的底层原理相关内容。希望对你的学习有帮助。
本文来自于微信公众号AI架构师汤师爷,由火龙果软件Alice编辑,推荐。 |
|
OpenClaw 爆火,但大部分人连 Skill 都还没入门,而 Skill
正是 OpenClaw 的基础。
你以为 Claude 的Skill 系统背后是一堆精密的代码?
这是最大的误区,没有复杂的算法,没有高深的架构。
它的整个Skill 机制,靠的就是阅读理解。
我把 Claude Agent Skills 的源码翻了个底朝天。
所谓的技能,本质上就是一个 Markdown 文件。
没有 Python,没有 JavaScript,没有服务器。
一个文件夹、一段提示词,就是全部。
接下来,我会带你深入拆解 Skill 系统的每个核心部分。
从技能的发现机制,到 SKILL.md 文件的编写规范,再到技能如何被调用、执行,以及如何设计高质量的技能。
每一步都会结合源码和实际案例,让你不仅知道怎么用,更重要的是理解为什么这样设计。
Claude Agent Skills 总览
先给你一个全景图,搞清楚 Skills 到底是什么、不是什么,以及它的基本工作原理。
Claude 用技能(Skills)来提升自己处理特定任务的能力。
每个技能本质上就是一个文件夹,里面装着指令、脚本和资源文件。
当 Claude 需要的时候,就会把这些东西加载进来。
Claude 是怎么发现和调用技能的呢?
靠的是一套基于提示词的系统(Declarative, Prompt-based System)。
简单说,就是把所有技能的名字和描述列成一张清单,放在 Claude 能看到的地方。
Claude 读完清单后,自己判断该不该用、用哪个。
在代码层面,没有任何算法在帮 Claude 选技能。
没有智能匹配、没有意图识别。
所有的决策都发生在 Claude 自己的推理过程中。
技能不是什么
先划几条线,搞清楚技能不是什么
• 技能不是可执行代码。它不会跑 Python、不会跑 JavaScript,背后也没有 HTTP
服务器或函数调用。
• 技能不是写死在系统提示词里的。它们存放在技能自己的目录下面。
技能是什么
技能是专用的提示词模板(Prompt Templates),会把特定领域的指令注入到对话上下文中。
当一个技能被激活时,它会同时做两件事
• 修改对话上下文,往对话里注入一大段详细的指令提示词
• 修改执行上下文,改变工具权限,甚至切换模型
技能本身不直接干活。
它展开成详细的提示词,让 Claude 做好准备去解决某类问题。
就像你给一个聪明的助理递了一份详细的操作手册,助理照着手册去执行。
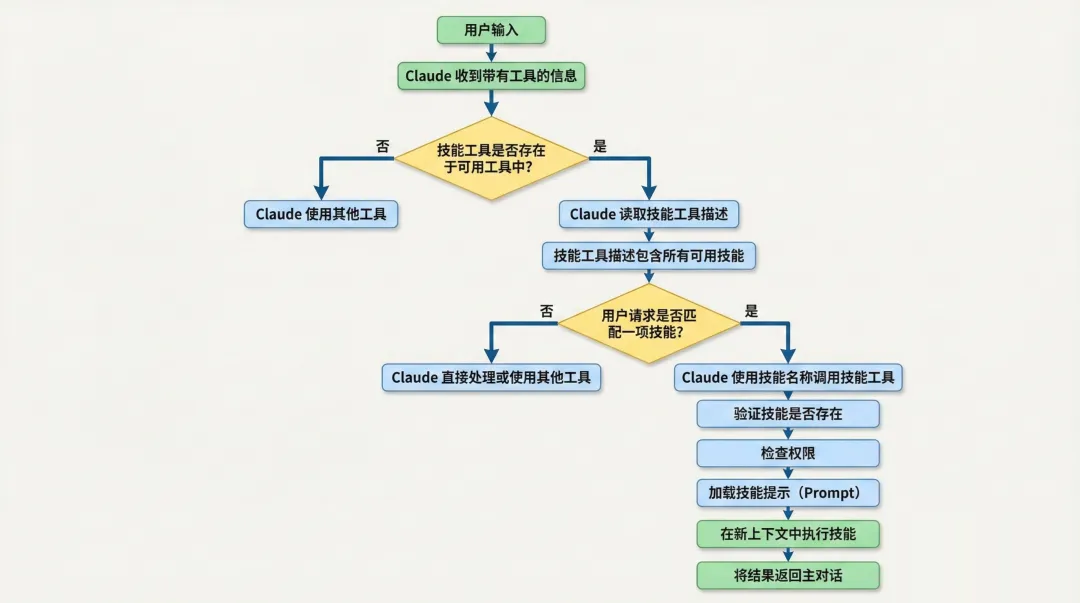
用户请求的处理流程
当用户发送一条请求时,Claude 会同时收到三样东西
• 步骤1 用户消息(比如帮我提取这个 PDF 的文字)
• 步骤2 可用工具列表(Read、Write、Bash 等常规工具)
• 步骤3 Skill 工具(里面包含所有技能的名字和描述)
Claude 读完技能清单后,用自己的语言理解能力,把你的意图和技能描述做匹配。
如果你说帮我创建一个技能。
Claude 看到 skill-creator 的描述是当用户想创建新技能时使用,就会判断匹配成功,然后调用
Skill 工具。
技能选择的机制
技能选择机制没有任何算法路由或意图分类。
Claude Code 不用词向量嵌入(Embeddings)、不用分类器(Classifiers)、不用正则匹配。
系统只是把所有技能的描述格式化成一段文字,嵌在 Skill 工具的提示词里,然后让 Claude
的语言模型自己做决定。
这是纯粹的大语言模型推理。
技能被调用后发生了什么
当 Claude 调用一个技能时,系统会按顺序做以下事情
• 步骤1 加载一个 markdown 文件(SKILL.md)
• 步骤2 把文件内容展开成详细的指令
• 步骤3 把这些指令作为新的用户消息注入到对话上下文中
• 步骤4 修改执行上下文(调整允许使用的工具、切换模型等)
• 步骤5 带着这个加强版的环境继续对话
这和传统工具完全不同。
传统工具是执行动作然后返回结果,而技能是让 Claude 做好准备去解决问题,而不是直接替你解决。
工具 vs. 技能对比
| 对比维度 |
传统工具(Tools) |
技能(Skills) |
| 执行方式 |
同步、直接执行 |
提示词展开(Prompt Expansion) |
| 用途 |
执行具体操作 |
引导复杂工作流 |
| 返回值 |
立即返回结果 |
修改对话上下文 + 执行上下文 |
| 举例 |
Read、Write、Bash |
internal-comms、skill-creator |
| 并发安全 |
通常安全 |
不支持并发 |
| 类型 |
多种类型 |
始终是 prompt 类型 |
如何构建 Agent Skills
我们以 Anthropic 官方的 skill-creator 技能为案例,手把手拆解如何构建一个技能。
技能的本质可以用一个公式概括
技能 = 提示词模板 + 对话上下文注入 + 执行上下文修改 + 可选的数据文件和脚本
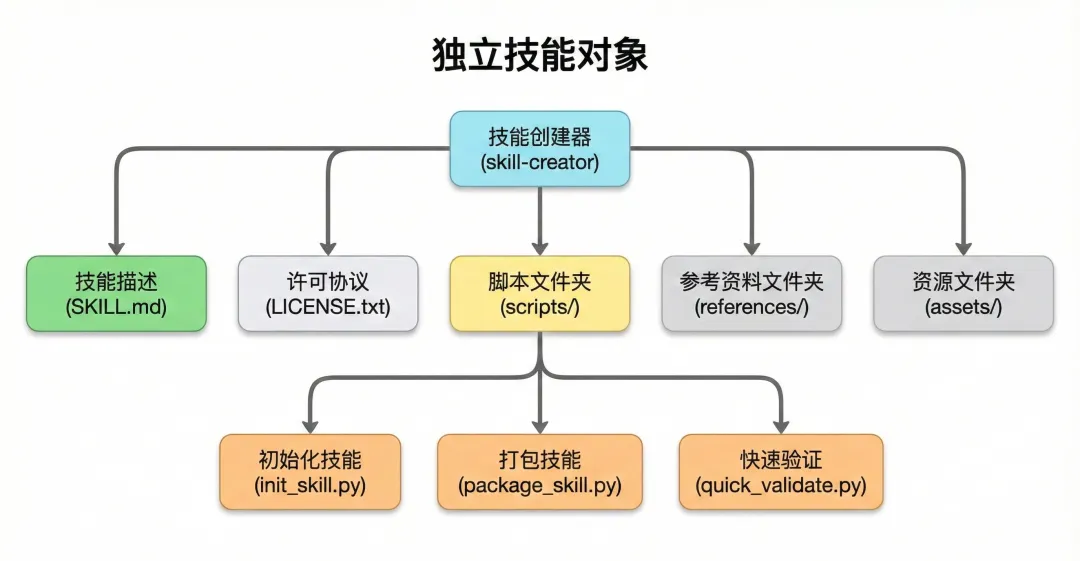
技能的文件结构
每个技能都定义在一个叫 SKILL.md 的 markdown 文件中(文件名不区分大小写),旁边可以选择性地放一些辅助文件。
以 skill-creator 技能为例,它的文件包结构如下
• SKILL.md 核心指令文件
• LICENSE.txt 许可证
• scripts/ 文件夹 里面放了几个 Python 脚本
技能从哪里被发现和加载
Claude Code 会从多个来源扫描技能
• 用户级配置 ~/.config/claude/skills/
• 项目级配置 .claude/skills/
• 插件提供的技能
• 内置技能
对于 Claude Desktop 桌面版,用户可以直接上传自定义技能。
渐进式披露 :构建技能最重要的设计思想
渐进式披露(Progressive Disclosure)是构建技能最核心的概念。
意思是先只展示刚好够做决策的信息,需要更多细节时再逐层展开。
在技能系统中,渐进式披露分三步
• 步骤1 先只展示元数据头(Frontmatter),包括技能名称、简介、许可证等最少信息
• 步骤2 如果 Claude 选中了某个技能,才加载完整的 SKILL.md 文件
• 步骤3 在技能执行过程中,再按需加载辅助的脚本、参考文档和资源文件
SKILL.md 的两部分结构
SKILL.md 文件由两部分组成
第一部分 元数据头(Frontmatter)
用 YAML 格式写在文件最上方,配置技能怎么运行,包括权限、模型、元信息等。
第二部分 Markdown 正文内容
告诉 Claude 该做什么,包含具体的指令、工作流程、示例等。
你可以把它想象成一封信。信封上写着收件人、邮编(元数据头),信里面才是正文内容。
1. YAML 元数据头(配置信息)
---
name: skill-name
description: 简要说明
allowed-tools: Bash, Read
version: 1.0.0
---
2. Markdown 正文(给 Claude 的指令)
用途说明
详细指令
示例和指南
分步操作流程
|
元数据头(Frontmatter)详解
本节逐个拆解 SKILL.md 文件头部的每个字段,搞清楚每个字段的作用。
以 skill-creator 的元数据头为例
---
name: skill-creator
description: Guide for creating effective skills. This skill should be used
when users want to create a new skill (or update an existing skill) that
extends Claude's capabilities with specialized knowledge, workflows, or
tool integrations.
license: Complete terms in LICENSE.txt
---
|
name 字段(必填)
技能的名字。这个名字会被用作 Skill 工具的 command 参数。
比如技能叫 skill-creator,那调用时就是 command: skill-creator。
description 字段(必填)
技能的简要说明,一两句话描述这个技能干什么。
这是 Claude 判断要不要用这个技能的最主要依据。
所以描述必须清晰、面向行动。
比如上面的例子写了当用户想创建新技能时使用,这种表述就很好,Claude 一看就知道什么时候该调用它。
系统还会自动在描述后面附加来源信息(比如 (plugin:skills)),方便区分不同来源的技能。
when_to_use 字段(未公开文档,可能已弃用)
这个字段在代码库中大量出现,但官方文档里完全没有提到。
它可能是正在被淘汰的老功能,也可能是还没正式发布的实验功能。
如果这个字段存在,系统会把它拼接到 description 后面,中间用一个短横线分隔。
建议不要用这个字段。直接把使用指引写进 description 里更安全。
license 字段(可选)
许可证信息,不多解释。
allowed-tools 字段(可选)
这个字段定义了技能可以免用户确认直接使用的工具列表。
它是一个用逗号分隔的字符串,会被解析成工具名数组。
你可以用通配符来限定权限范围。
比如 Bash(git:) 只允许 git 相关的命令,Bash(npm:) 允许所有 npm 操作。
好的做法是只列出技能真正需要的工具
# 好的做法 只列需要的工具
allowed-tools: Read,Write,Edit,Glob,Grep
# 好的做法 只允许特定的 git 命令
allowed-tools: Bash(git status:*),Bash(git diff:*),Read,Grep
# 不好的做法 权限范围过大,有安全风险
allowed-tools: Bash,Read,Write,Edit,Glob,Grep,WebSearch,Task,Agent
|
model 字段(可选)
指定技能使用哪个模型。
默认继承当前会话的模型。
对于复杂任务(比如代码审查),可以指定更强的模型,比如 Claude Opus。
model: claude-opus-4-20250514 # 使用指定模型
model: inherit # 使用当前会话模型(默认)
|
version、disable-model-invocation 和 mode 字段(可选)
这三个字段分别用于
• version 版本号,主要用于技能的文档管理和版本追踪
• disable-model-invocation 如果设为 true,Claude 就不能自动调用这个技能,只能由用户手动通过
/技能名 来触发。适合那些有风险的操作或需要用户明确控制的流程
• mode 如果设为 true,这个技能会被归类为模式命令(Mode Command),出现在技能列表顶部一个专门的区域,和普通技能分开展示。适合
debug-mode、expert-mode 这类切换工作模式的技能
SKILL.md 正文内容
元数据头下面就是 markdown 正文,也就是 Claude 被激活技能后真正收到的指令。
这部分决定了技能的行为。
写好技能提示词的关键是保持聚焦,配合渐进式披露。
核心指令放在 SKILL.md 里,详细内容引用外部文件。
推荐的正文结构
---
# 元数据头
---
# 简要用途说明(1-2 句话)
## 概述
这个技能做什么、什么时候用、提供什么能力
## 前置条件
需要什么工具、文件或上下文
## 操作步骤
### 步骤 1 第一个动作
具体指令和示例
### 步骤 2 下一个动作
具体指令
### 步骤 3 最后一个动作
具体指令
## 输出格式
结果应该怎么组织
## 错误处理
出问题了怎么办
## 示例
具体的使用例子
## 资源
引用 scripts/、references/、assets/ 中的文件
|
以 skill-creator 技能为例,它的正文包含以下工作流步骤
• 步骤1 理解技能并收集具体案例
• 步骤2 规划可复用的技能内容
• 步骤3 初始化技能
• 步骤4 编辑技能
• 步骤5 打包技能
当 Claude 调用这个技能时,会收到完整的正文指令,并且系统会自动在前面加上技能的安装目录路径。
其中 {baseDir} 变量会自动解析为技能的实际安装路径,这样 Claude 就可以用 Read
工具去读取技能包里的参考文件,比如 Read({baseDir}/scripts/init_skill.py)。
正文写作的最佳实践
• 控制在 5000 字以内(大约 800 行),避免撑爆上下文窗口
• 用祈使句式(分析代码中的...),而不是第二人称(你应该分析...)
• 详细内容引用外部文件,不要全塞进 SKILL.md
• 路径一律用 {baseDir},绝不写死绝对路径
技能包的资源目录结构
除了 SKILL.md 主文件,技能还可以打包辅助资源文件。标准结构有三个目录,各有分工。
my-skill/
├── SKILL.md # 核心指令文件
├── scripts/ # 可执行的 Python/Bash 脚本
├── references/ # 会被加载到上下文的参考文档
└── assets/ # 模板和二进制文件(不加载到上下文)
|
为什么要打包资源?
因为 SKILL.md 要保持精简(5000 字以内),才不会撑爆 Claude 的上下文窗口。
把详细文档、自动化脚本和模板放在外部,Claude 需要时再按需加载。
scripts/ 目录 -- 可执行脚本
scripts/ 目录存放 Claude 通过 Bash 工具运行的可执行代码,比如自动化脚本、数据处理器、校验器或代码生成器。
以 skill-creator 为例,它的 SKILL.md 里这样引用脚本
创建新技能时,先运行 init_skill.py 脚本。这个脚本会自动生成一个模板目录,包含技能所需的全部文件结构。
|
当 Claude 看到这条指令,就会执行 python {baseDir}/scripts/init_skill.py,其中
{baseDir} 会自动替换成实际路径。
什么时候用 scripts/ ?
需要精确逻辑的复杂操作、数据转换、API 交互,或者用代码比用自然语言表达更靠谱的任务。
references/ 目录 -- 参考文档
references/ 目录存放 Claude 需要读入上下文的文档内容。
可以是 markdown 文件、JSON 模式定义、配置模板等。
当 Claude 遇到引用指令时,会用 Read 工具加载文件内容到自己的上下文中,比如 Read({baseDir}/references/mcp_best_practices.md)。
什么时候用 references/ ?
详细文档、大型模式库、检查清单、API 模式定义,或者内容太多不适合放在 SKILL.md 里但又必不可少的文本。
assets/ 目录 -- 静态资源
assets/ 目录存放模板和二进制文件,Claude 只知道路径,但不会把内容读入上下文。
你可以把它理解为技能的静态资源仓库,比如 HTML 模板、CSS 文件、图片、配置模板等。
Claude 可能会复制模板到新位置、填充占位符,或在输出中引用路径,但不会把文件内容加载进来。
references/ 和 assets/ 的核心区别
• references/ 文本内容,会通过 Read 工具加载到 Claude 的上下文,占用上下文
Token
• assets/ 只按路径引用,不占用上下文 Token
这个区别对上下文管理很重要。
一个 10KB 的 markdown 文件放在 references/ 里,加载后会消耗上下文窗口的容量。
同样大小的 HTML 模板放在 assets/ 里,不会消耗任何上下文容量。
最佳实践:路径一律使用 {baseDir},永远不要写死绝对路径。这样技能才能在不同用户环境、项目目录和安装位置之间通用。
常见技能设计模式
本节总结了几种最常用的技能设计模式,帮你快速选择适合自己场景的架构方案。
模式一:脚本自动化
**适用场景:**需要多步命令或精确逻辑的复杂操作。
这个模式把计算任务交给 scripts/ 目录里的 Python 或 Bash 脚本。
技能的提示词告诉 Claude 去执行脚本并处理输出。
流程是,技能指令 -> Claude 执行脚本 -> 解析脚本输出 -> 整理结果呈现给用户。
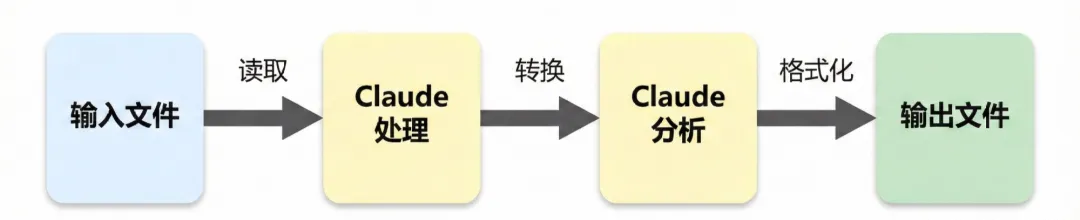
模式二:读取-处理-写入
**适用场景:**文件转换和数据处理。
最简单的模式。
读入输入文件,按指令转换内容,写出输出文件。
适合格式转换、数据清洗或报告生成。
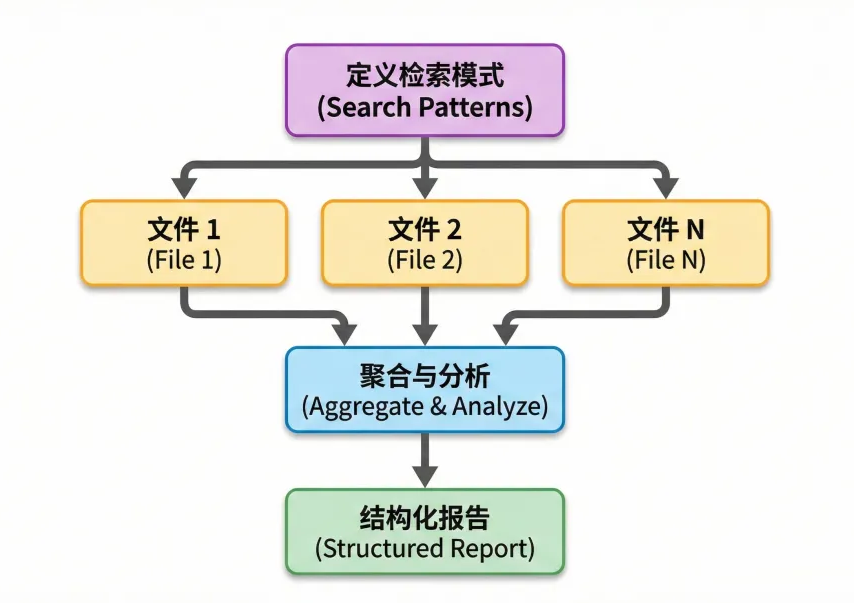
模式三:搜索-分析-报告
**适用场景:**代码库分析和模式检测。
用 Grep 工具在代码库中搜索模式,读取匹配的文件获取上下文,分析发现的问题,生成结构化报告。
也可以用于企业数据分析。
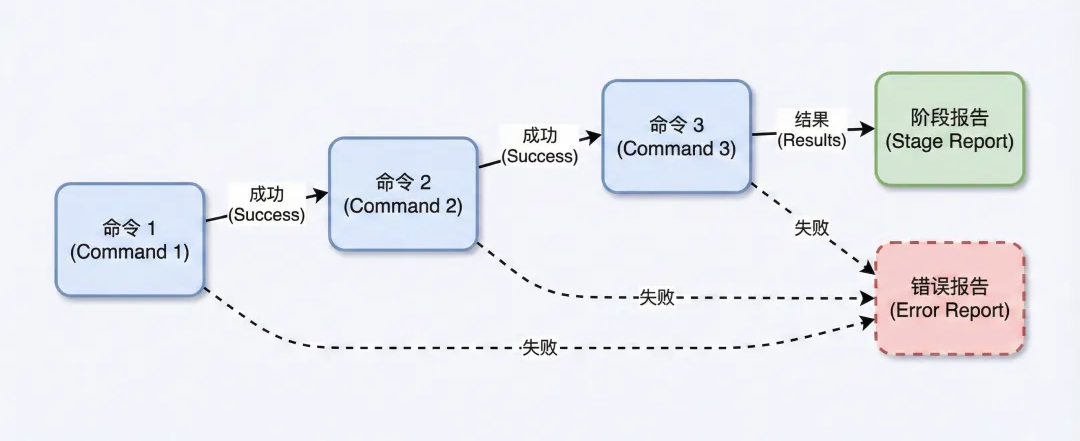
模式四:命令链执行
**适用场景:**有依赖关系的多步操作。
按顺序执行一系列命令,每一步都依赖上一步的成功。
常见于类似 CI/CD 的工作流。
进阶技能模式
介绍几种更复杂的技能设计模式,适合需要用户交互、多轮迭代或多源信息整合的场景。
向导式多步工作流
**适用场景:**需要在每一步征求用户输入的复杂流程。
把复杂任务拆分成离散的步骤,每个阶段之间需要用户确认才能继续。
适合配置向导、安装引导等场景。
模板生成
**适用场景:**从 assets/ 中的模板创建结构化输出。
加载模板 -> 解析用户需求 -> 填充占位符 -> 写出结果文件。
迭代优化
**适用场景:**需要多轮扫描、逐步深入的流程。
• 第一轮 广域扫描,发现高层面问题
• 第二轮 对每个问题深入分析根因和严重程度
• 第三轮 研究最佳实践,给出具体修复建议
适合代码审查、安全审计或质量分析。
多源信息汇总
**适用场景:**从多个来源收集信息,综合成完整的全景认知。
从不同文件和工具中收集数据,整合为一份连贯的总结。
适合项目概况、依赖分析或影响评估。
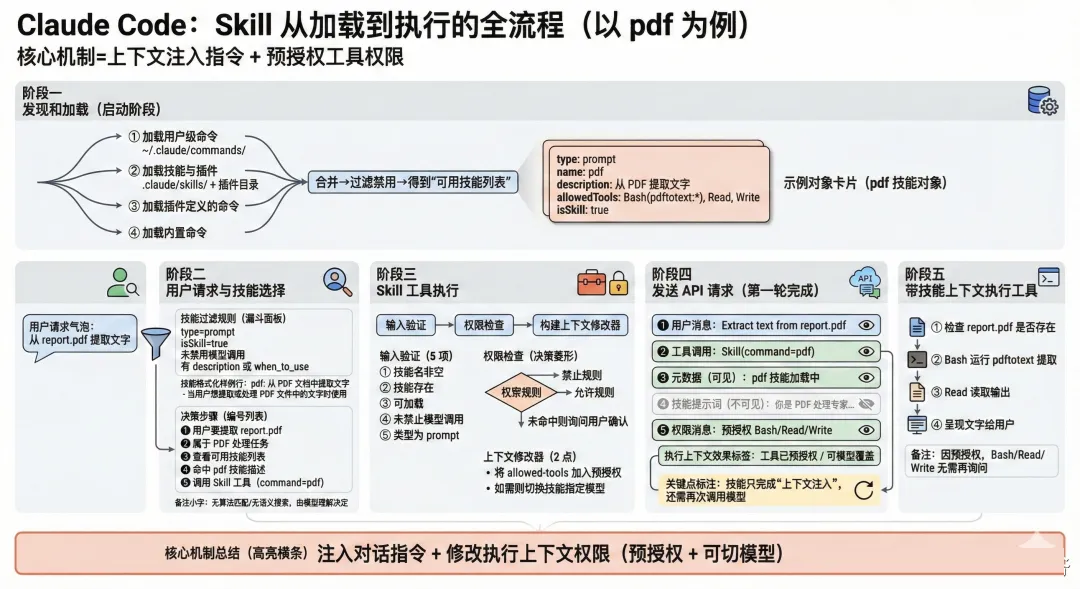
案例分析:完整执行生命周期
用一个pdf 技能为例,完整走一遍用户说提取 PDF 文字后系统内部发生的所有事情。
阶段一 发现和加载(启动阶段)
Claude Code 启动时,会从多个来源并行扫描和加载技能
• 步骤1 加载用户级命令(来自 ~/.claude/commands/)
• 步骤2 加载技能和插件(来自 .claude/skills/ 和插件目录)
• 步骤3 加载插件定义的命令
• 步骤4 加载内置命令
所有来源的结果合并后,过滤掉已禁用的,形成最终的可用技能列表。
对于 pdf 技能,加载后会得到这样一个数据对象
• type: prompt(类型是提示词)
• name: pdf(名字)
• description: 从 PDF 文档中提取文字(描述)
• allowedTools: [Bash(pdftotext:*), Read, Write](允许使用的工具)
• isSkill: true(标记为技能)
阶段二 用户请求和技能选择
用户发送请求:从PDF中提取文字 report.pdf。
在 Claude 做决定之前,系统需要先把可用技能列表呈现出来。
技能过滤规则
不是所有加载的技能都会出现在 Skill 工具的提示词里。
一个技能必须满足以下条件才会被展示
• 类型是 prompt
• 标记为 isSkill: true
• 没有禁用模型调用
• 有用户指定的描述或者有 when_to_use 字段
技能格式化
每个通过过滤的技能会被格式化成一行文字,比如
pdf: 从 PDF 文档中提取文字 - 当用户想提取或处理 PDF 文件中的文字时使用
Claude 的决策过程
Claude 收到用户请求和 Skill 工具后,内部推理过程大致如下
1. 用户想从 report.pdf 提取文字
2. 这是一个 PDF 处理任务
3. 看看可用技能列表...
4. 找到了 pdf 技能,描述完全匹配
5. 决定 调用 Skill 工具,command 设为 pdf
再强调一次,这里没有算法匹配,没有词法匹配,没有语义搜索。
完全靠 Claude 自己读理解后做判断。
阶段三 Skill 工具执行
Claude 决定调用 pdf 技能后,Skill 工具开始执行,依次走过三步
步骤1 输入验证
系统依次检查 5 种错误情况
1. 技能名是否为空
2. 技能是否存在
3. 技能是否能加载
4. 是否禁止了模型调用
5. 是否是提示词类型
pdf 技能全部通过验证。
步骤2 权限检查
系统检查权限规则
1. 先查禁止规则,看有没有被阻止
2. 再查允许规则,看是否已预授权
3. 都没匹配到,默认询问用户 是否执行 pdf 技能?
用户确认后继续。
步骤3 加载技能文件并生成执行上下文修改器
验证和权限都通过后,Skill 工具会
1. 加载 SKILL.md 的完整内容
2. 生成元数据标签(用户可见的加载状态)
3. 创建消息数组(元数据消息 + 隐藏的技能提示词 + 可选的附件和权限消息)
4. 提取配置信息(允许的工具列表、模型覆盖设置)
5. 生成一个执行上下文修改器函数(contextModifier)
这个修改器函数会做两件事
• 把技能声明的 allowed-tools 加入预授权列表,这样后续使用这些工具时不需要再问用户
• 如果技能指定了不同的模型,切换到那个模型
阶段四 发送 API 请求(第一轮完成)
系统把所有对话消息和新注入的技能消息组装成完整的请求,发送给 Anthropic API。
请求的消息数组按顺序包含
1. 用户原始消息 Extract text from report.pdf
2. Claude 的工具调用 调用 Skill 工具,command 为 pdf
3. 元数据消息(用户可见) pdf 技能正在加载
4. 技能提示词(用户不可见) 你是一个 PDF 处理专家...(完整指令)
5. 权限消息 预授权 Bash(pdftotext:*)、Read 和 Write
执行上下文修改器同时生效,预授权了后续需要的工具。
到这里,如果是普通工具,就已经结束了。
但技能不一样,技能只完成了上下文注入。
系统还需要带着这些注入的上下文再次调用 Claude 来完成用户的实际请求。
阶段五 带着技能上下文执行工具
Claude 收到包含注入上下文的 API 响应后,它的行为已经被技能提示词改造了。现在它拥有
• PDF 处理的专业指令(来自对话上下文)
• 预授权的工具权限(来自执行上下文)
• 一套清晰的工作流程(来自对话上下文)
Claude 按照 pdf 技能的工作流程执行
• 步骤1 验证 report.pdf 文件存在
• 步骤2 运行 pdftotext 命令提取文字(使用 Bash 工具,已预授权无需用户确认)
• 步骤3 用 Read 工具读取输出文件
• 步骤4 把提取的文字呈现给用户
技能成功引导 Claude 完成了 PDF 文字提取的专业工作流。
核心机制就是往对话上下文注入指令 + 修改执行上下文的工具权限。
总结
看到这里,你可能会有一个疑问。
为什么 Anthropic 要把技能系统设计得如此简单?
答案很简单:因为 Claude 本身就足够强大。
当模型的阅读理解能力足够好时,复杂的匹配算法、精密的调度系统都是多余的。
一个 Markdown 文件,就能让 Claude 理解你的意图,执行你的工作流。
这才是真正的第一性原理:不是用代码控制 AI,而是用自然语言引导 AI。
现在回头看,整个技能系统的本质就是三件事:
• 发现:扫描文件夹,加载技能列表
• 注入:把技能提示词插入对话上下文
• 执行:预授权工具,让 Claude 按照指令工作
没有魔法,没有黑科技。
只有清晰的设计和对 LLM 能力的深刻理解。
如果你真正理解了这套机制,你就掌握了构建 AI Agent 的核心能力。
不是调用 API,不是写复杂的代码,而是用自然语言设计工作流。 | 






 订阅
订阅