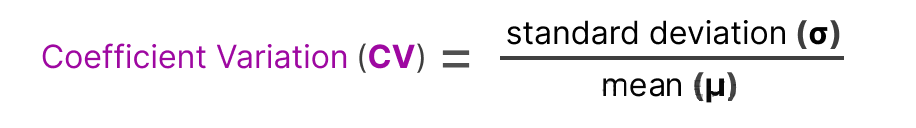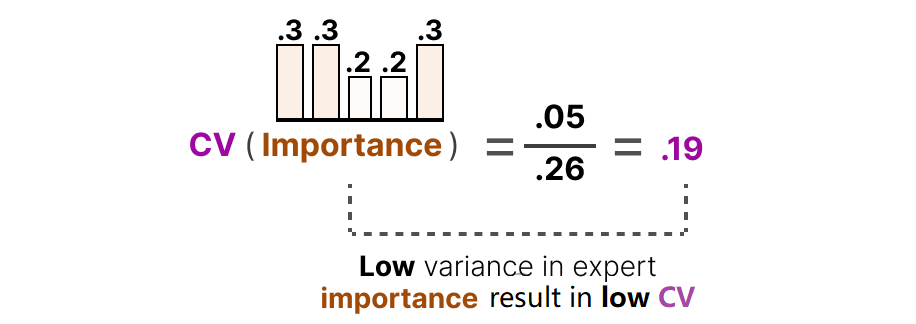| 编辑推荐: |
本文介绍了混合专家模型(MoE)的核心思想、关键技术(尤其是负载均衡)及其在视觉领域的应用,希望对你的学习有帮助。
本文来自于智驾和机器人前瞻局,由火龙果软件Alice编辑,推荐。 |
|
MoE 模型深度指南:架构、路由、负载均衡与视觉扩展,一篇全讲透!(上)
四、负载均衡:让每个专家都 “物尽其用”
负载均衡是 MoE 训练的核心技术难点,也是决定模型性能的关键。本节将详细介绍三种主流的负载均衡策略: KeepTopK 策略、辅助损失函数、专家容量限制。
4.1 KeepTopK 策略:引入随机性的 “公平分配”
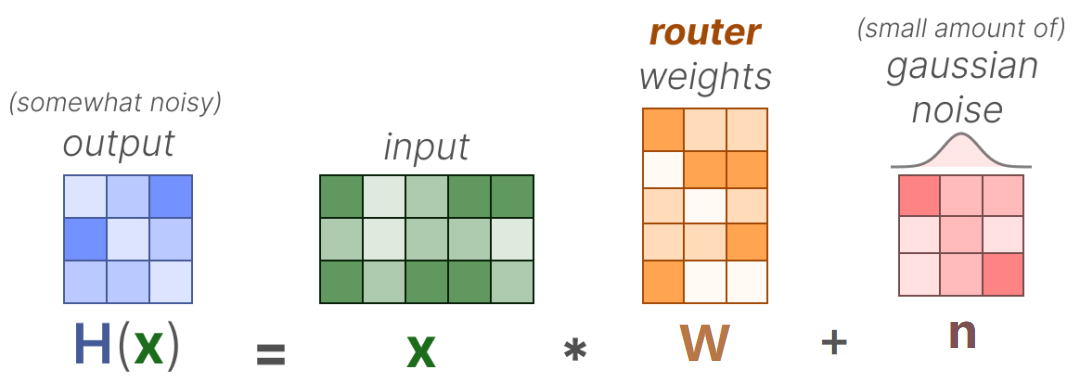
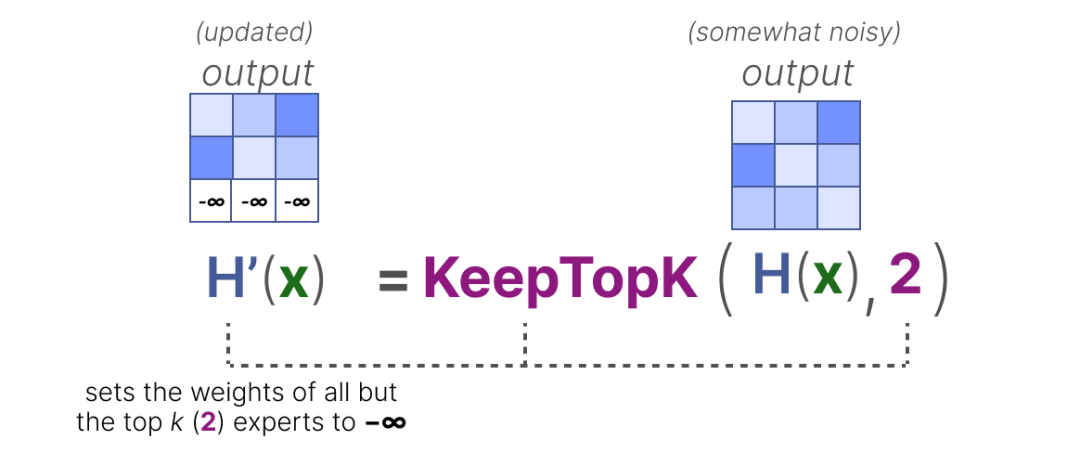
KeepTopK 是 最基础也最常用的负载均衡策略 ,核心思想是 “ 引入噪声 + 强制选优 ”,避免路由器过度依赖热门专家。
(1)核心步骤
1.引入高斯噪声:在计算适配分数 时,加入少量可训练的高斯噪声 ( ),打破热门专家的分数垄断:
2.强制选择 Top-k 专家:将非 Top-k 专家的分数设为 ,使得这些专家在 SoftMax 计算中概率为 0,无法被选中:
3.概率归一化:对 Top-k 专家的分数重新计算 SoftMax,确保概率和为 1:
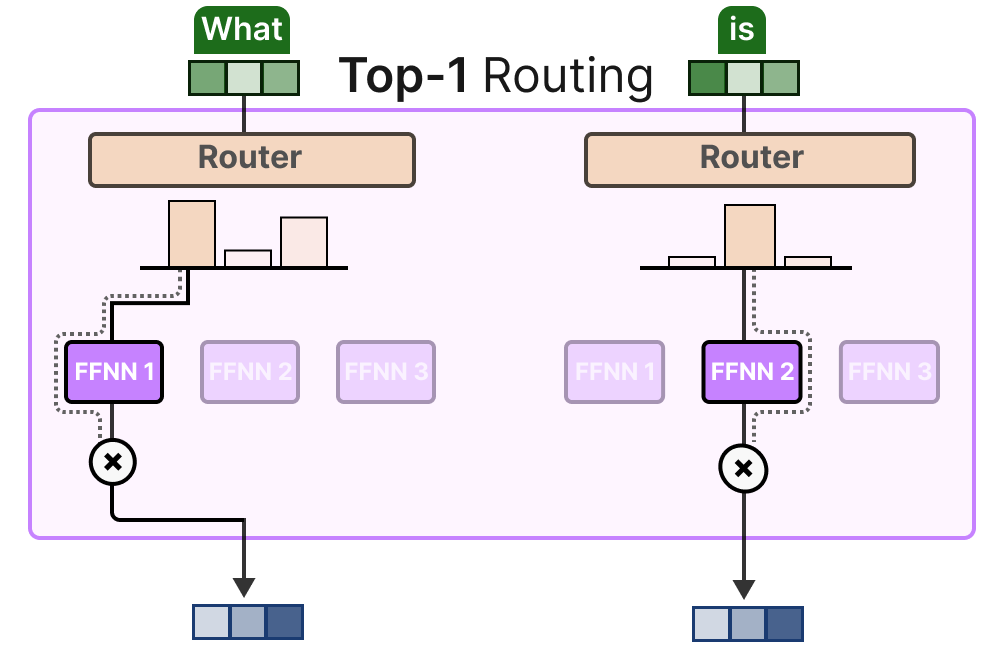
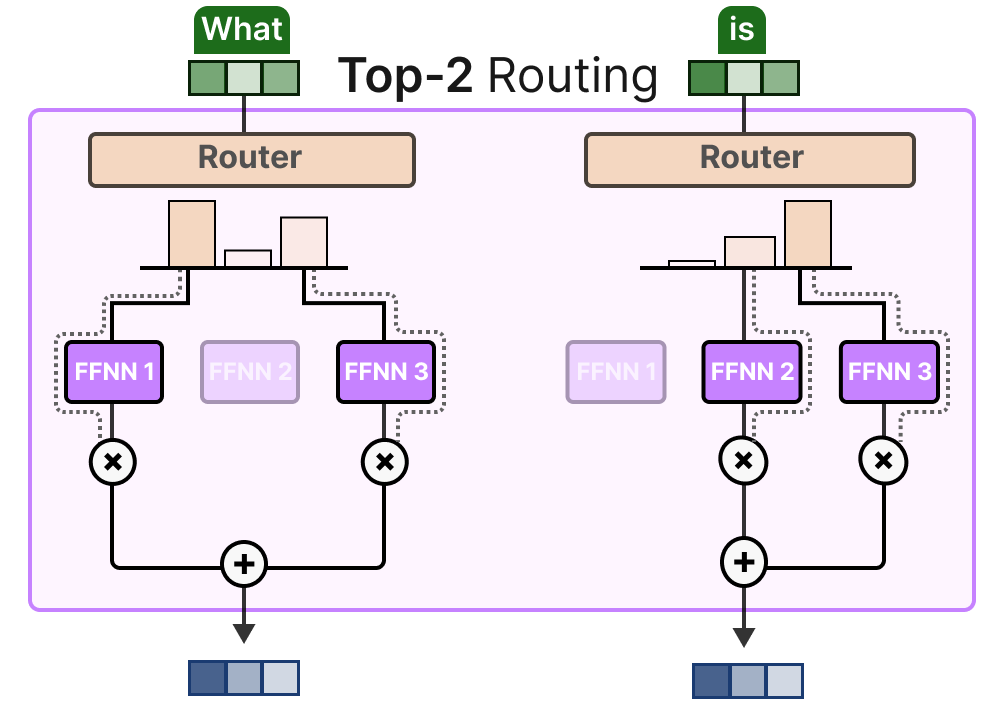
(2)Token Choice:Top-1 vs Top-k 路由
Top-1 路由:每个 token 仅分配给 1 个专家(如 Switch Transformer),计算成本最低,但可能丢失多专家协同的优势;
Top-k 路由(k≥2):每个 token 分配给 k 个专家,加权合并输出,灵活性更高,可融合多专家知识,但计算成本略有增加。
图12:Top-1与Top-2路由模式对比
4.2 辅助损失函数:用数学约束实现均衡
仅靠策略调整难以完全解决负载均衡问题,因此研究者在主损失(如交叉熵损失)之外,引入 “ 辅助损失(Auxiliary Loss) ”,将 “ 专家使用均匀性 ” (各个专家模块被激活的频率是否均衡。它衡量的是: 模型是否公平地利用了所有专家,而不是偏向某几个专家。 )纳入模型优化目标
(1)核心逻辑
通过计算所有专家的 “使用重要性差异”( 不同专家对模型最终输出的贡献程度的高低 ),迫使模型降低差异,实现公平分配。具体步骤如下:
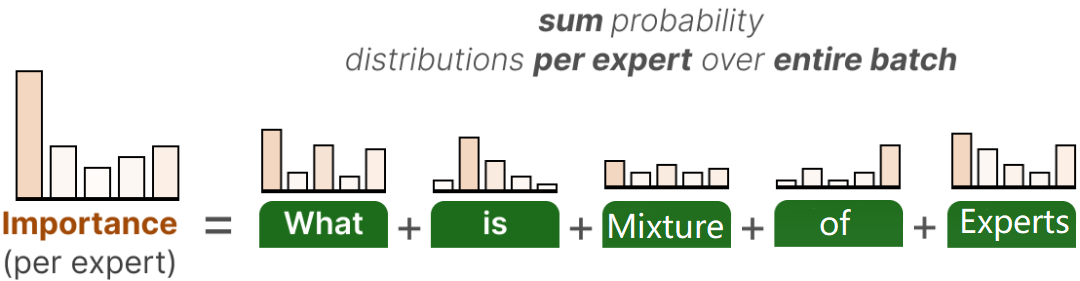
步骤 1:计算专家的重要性分数
对一个训练批次(batch)中的所有 token,统计每个专家被选中的概率总和,作为该专家的 “重要性分数” :
其中 为批次中 token 的数量, 为第 个 token 选择第 个专家的概率。
步骤 2:计算变异系数(CV)
变异系数用于衡量所有专家重要性分数的离散程度,计算公式为:
其中 为重要性分数的标准差, 为重要性分数的均值。
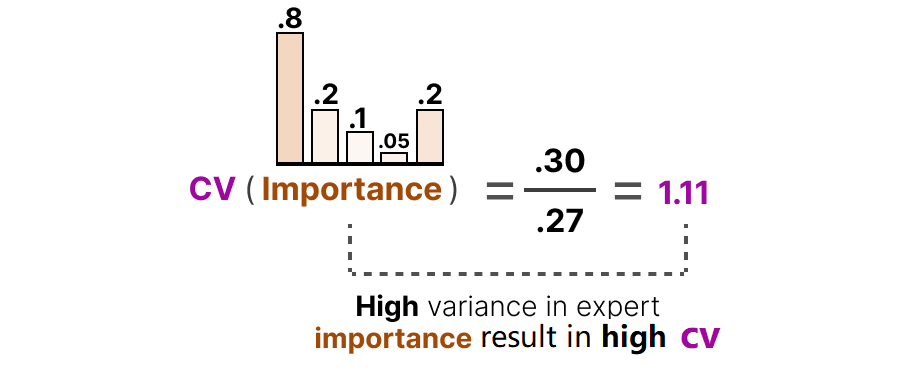
CV 值越高,说明专家使用越不均衡。
CV 值越低,说明使用越均匀。
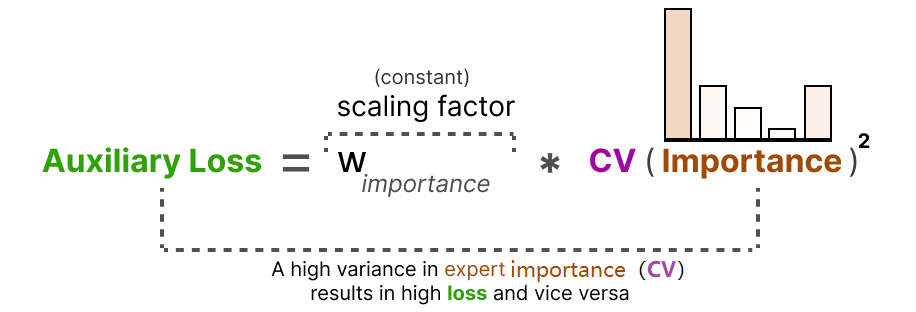
步骤 3:构建辅助损失
辅助损失与 CV 的平方成正比,目的是最小化 CV 值:
其中 为权重系数(超参数,通常设为 0.1~0.5),用于平衡主损失与辅助损失的重要性。
步骤 4:整体优化目标
模型的最终损失为核心损失与辅助损失之和:
通过这一机制,模型在优化主任务性能的同时,会主动降低专家使用的不均衡性,确保每个专家都能获得足够的训练数据。
图13:变异系数与专家均衡性的关系
4.3 专家容量:限制 “工作量” 的硬性约束
负载不均衡不仅体现在 “选择哪些专家”,还体现在 “ 每个专家处理多少 token ”。即使专家被选中的次数相近,若大量 token 集中路由到某几个专家,仍会导致训练不充分。
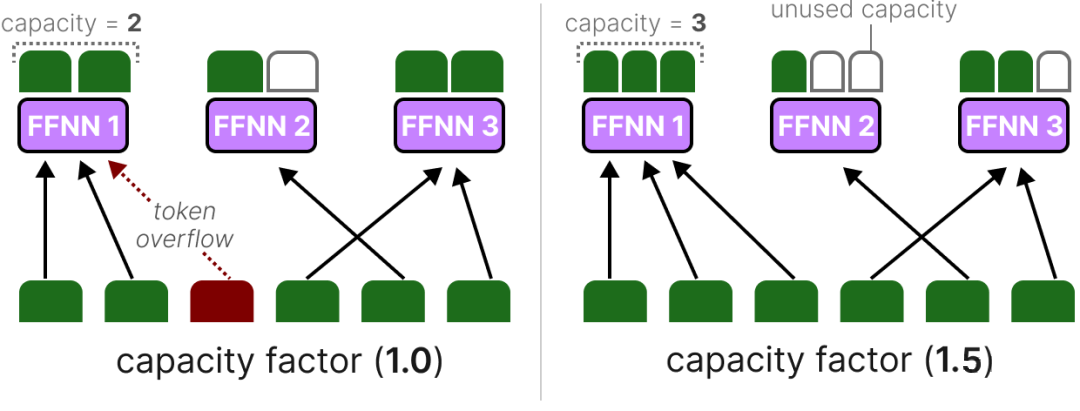
(1)专家容量的定义
专家容量(Expert Capacity) 是指单个专家在一个批次中最多能处理的 token 数量,设为 。当某专家处理的 token 数量达到 时,后续分配给该专家的 token 会被路由到次优专家。
(2)容量计算与调整
专家容量通常由 “容量因子(Capacity Factor)” 控制,计算公式为:
其中:
- 为批次中 token 的总数;
- 为每个 token 选择的专家数(Top-k);
- 为专家数量;
- 为容量因子(超参数,通常设为 1.0~1.2)。
(3)Token 溢出处理
若所有候选专家均达到容量上限,剩余 token 将跳过当前 MoE 层,直接进入下一层(称为 Token Overflow)。为减少溢出对性能的影响,通常需合理设置容量因子: 过大会浪费算力, 过小会导致大量溢出。
图14展示了当专家模块的溢出情况,FFNN1(左)承担了大部分的tokens任务,从而降低了整体的性能。
图14:专家容量限制与Token溢出示意图
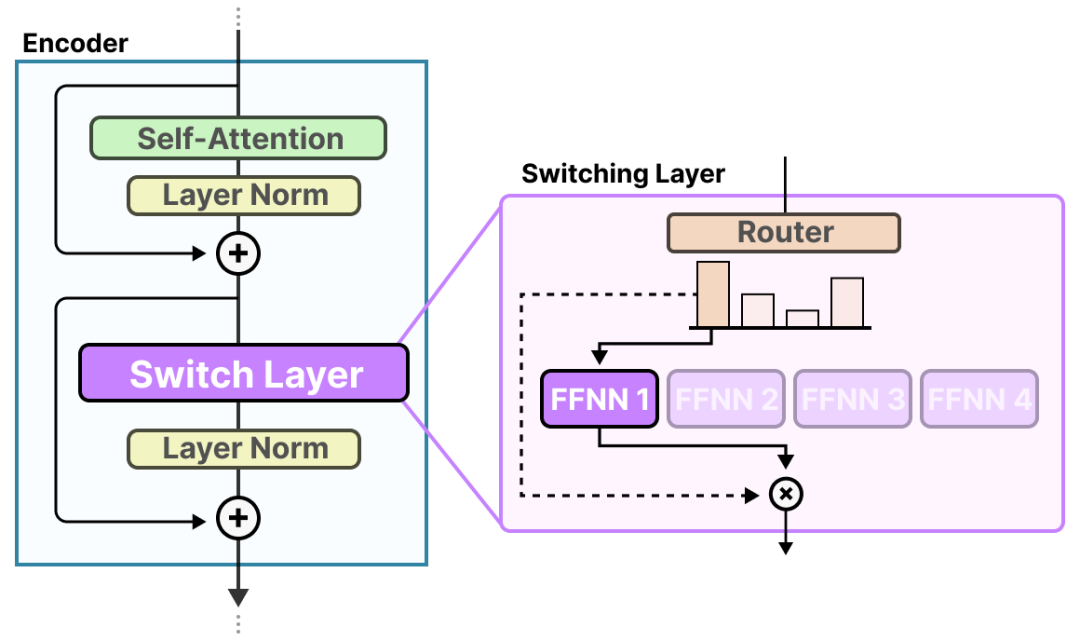
4.4 Switch Transformer:简化 MoE 的负载均衡方案
Switch Transformer 是最早解决 MoE 训练不稳定性的经典架构,其核心贡献是通过 “ 简化路由 + 优化容量控制 ”,降低 MoE 的实现难度,同时提升训练稳定性。
(1)核心改进:Top-1 路由简化
Switch Transformer 采用 Top-1 路由策略,每个 token 仅分配给 1 个专家,基于假设:“每个 token 的处理需求可由单个专家满足”。这一简化大幅降低了路由计算成本,同时减少了负载均衡的复杂度, 专家容量的组成部分很简单:
(2)容量因子的自适应调整
Switch Transformer 将容量因子作为核心超参数,允许用户根据硬件资源和任务需求灵活调整:
- 当硬件资源充足时,增大 ,提升专家容量,减少 Token 溢出;
- 当硬件资源有限时,减小 ,牺牲少量溢出,降低显存占用。
(3)简化的辅助损失
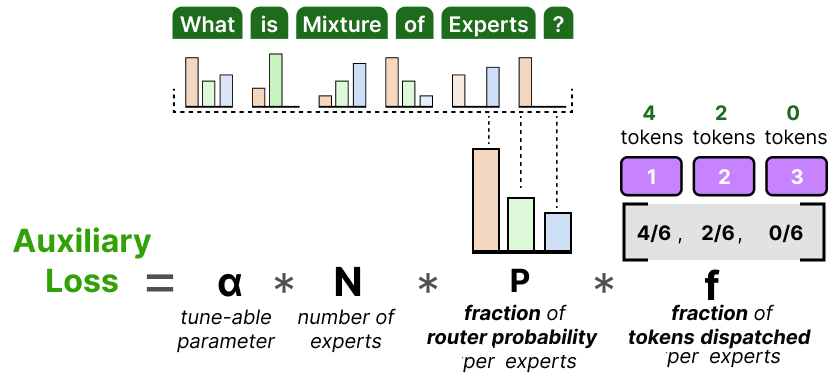
Switch Transformer 不再使用复杂的数学方法(比如变异系数)衡量专家使用是否均衡,而是采用一种更直接的方法: 看路由器的分配意图和专家实际处理情况之间的差距,即:
- 路由器原本“打算”分配给每个专家多少 token(这是概率)
- 实际上每个专家“真的”处理了多少 token(这是结果)
其中:
- 为路由器为第 个专家分配的概率均值;
- 为第 个专家实际处理的 token 比例;
- 为权重系数。
目标是让 和 均接近 ,实现 token 的均匀分配。
图15:Switch Transformer的切换层结构
五、视觉模型中的 MoE:从文本到图像的跨领域扩展
MoE 并非语言模型的 “专属技术”。视觉模型(如 ViT)基于 Transformer 架构,同样面临 “ 规模扩大→算力飙升 ” 的困境,因此 MoE 的稀疏机制可自然迁移至视觉领域,实现性能与效率的平衡。
5.1 ViT 与 MoE 的适配性基础
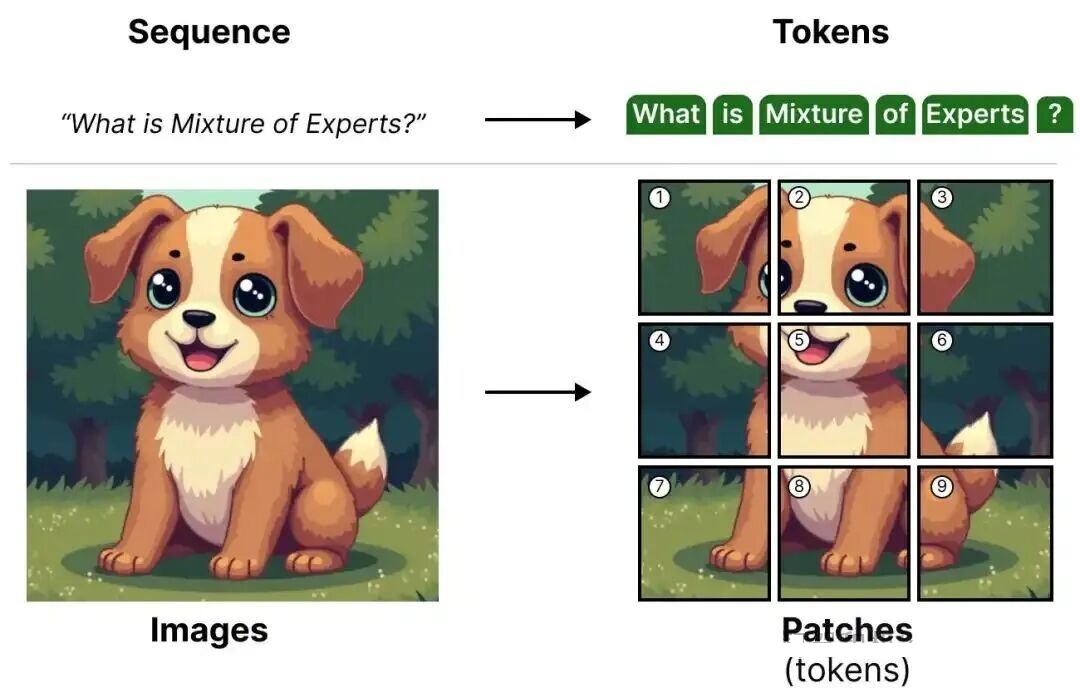
ViT(Vision Transformer)的核心思想是 “ 将图像切分为 patch(图像块),并将 patch 视为‘视觉 token',采用与文本 Transformer 相同的方式处理”。 这一特性使得 ViT 与 MoE 的融合极为自然:
- 文本 MoE:路由机制分配 “文本 token” 给专家;
- 视觉 MoE:路由机制分配 “图像 patch” 给专家。
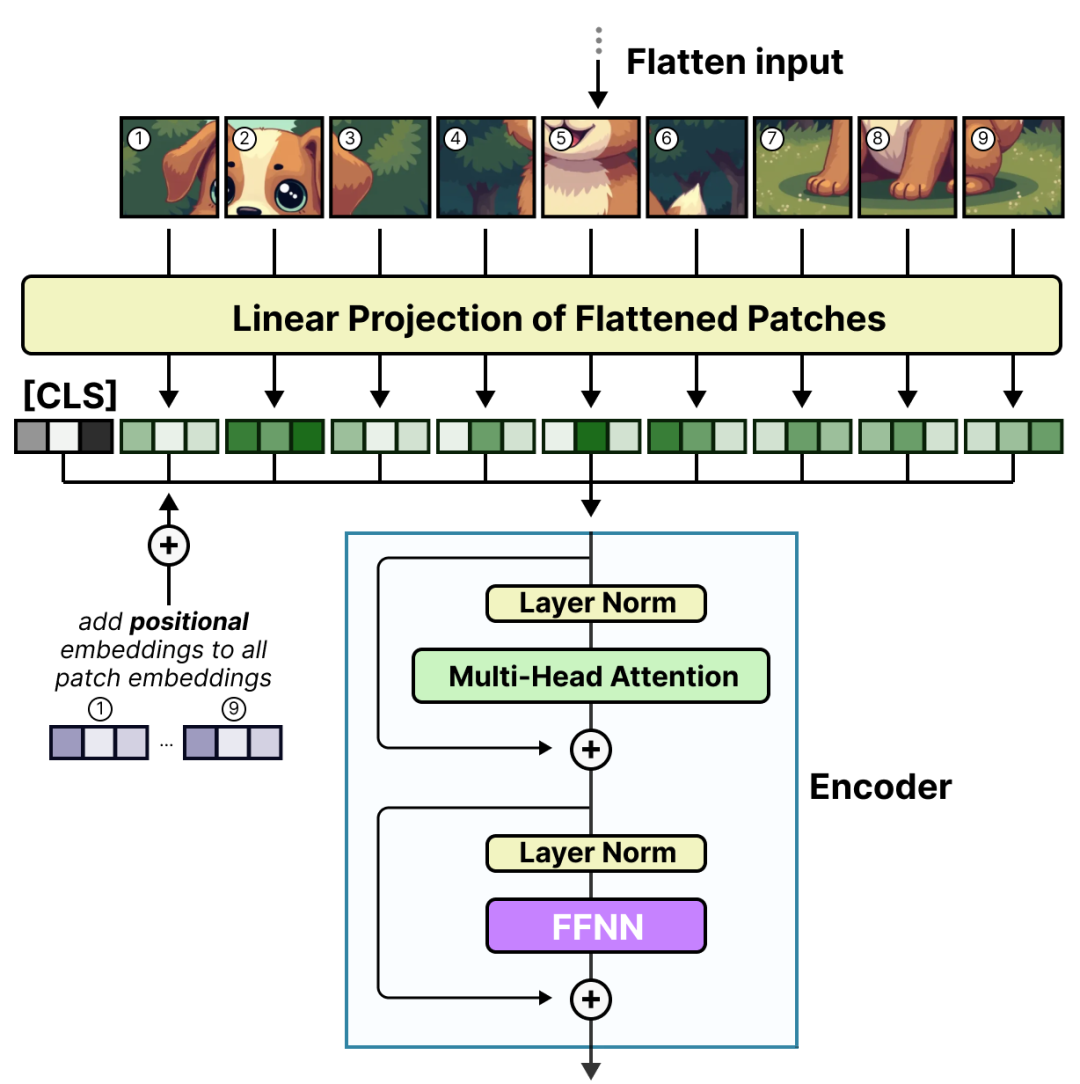
图16:文本token与图像patch的对应关系 这些 patch(或 token)会被映射为 embedding(并加上额外的位置 embedding),然后送编码器中,ViT 的基础架构如下,其中 FFNN 层可直接替换为 MoE 层:
图17:ViT的基础架构示意图
5.2 Vision-MoE(V-MoE):图像领域的首个 MoE 方案
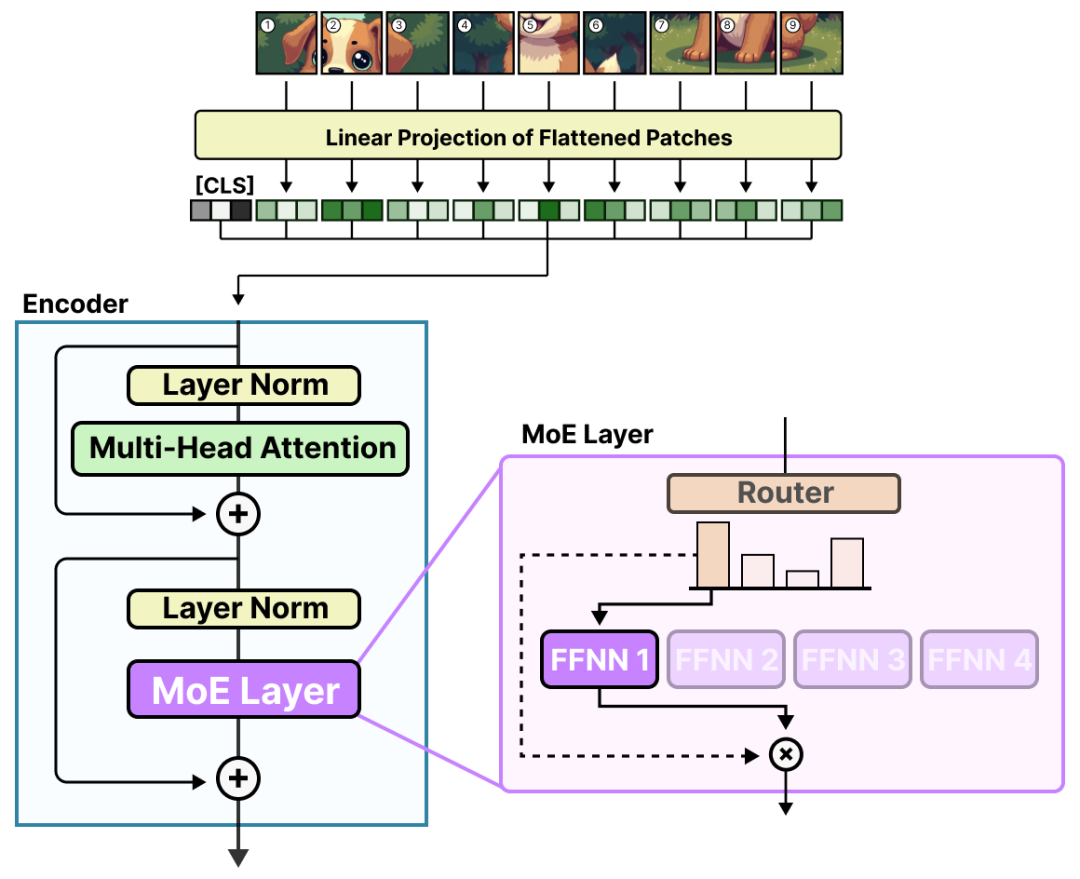
Vision-MoE 是最早在图像模型中实现 MoE 的经典方案,其核心是 “ 用稀疏 MoE 层替代 ViT 中的稠密 FFNN 层 ”,同时针对图像处理场景优化负载均衡策略。
(1)核心架构改进
V-MoE 的架构与 ViT 一致,仅将编码器中的 FFNN 层替换为 “路由器 + 多个专家” 的 MoE 层:
图18:V-MoE的架构示意图
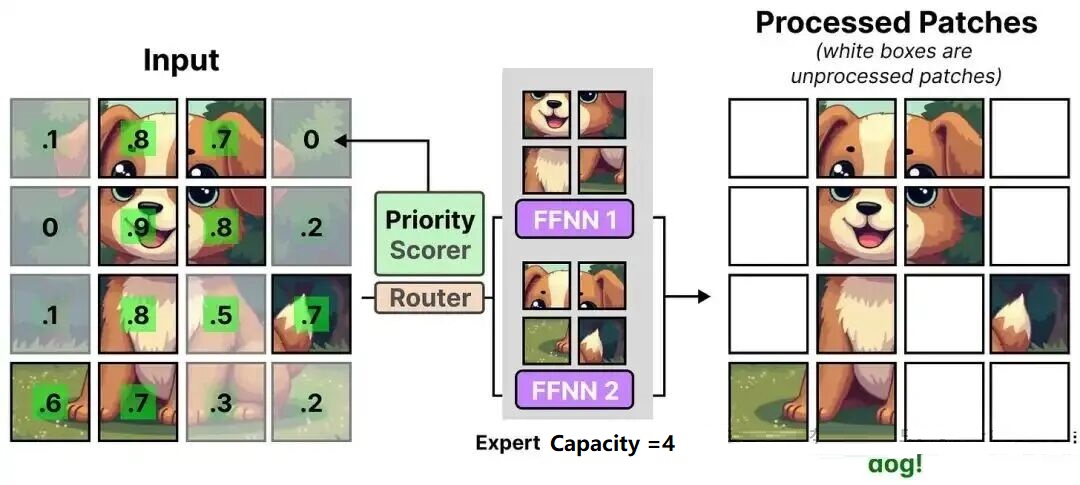
(2)针对图像的负载均衡优化:优先路由(Priority Routing)
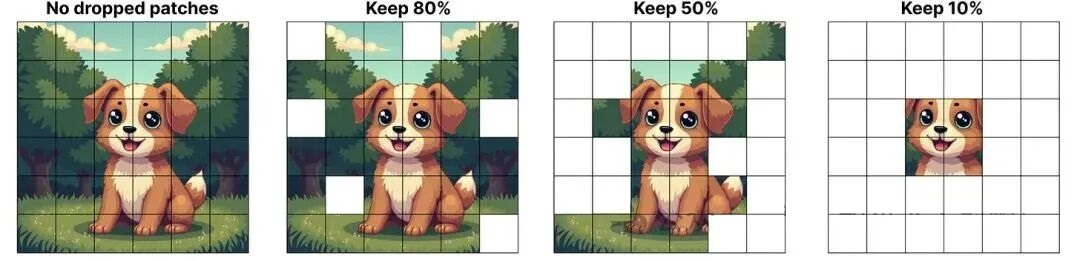
图像处理的特殊挑战是:图像 patch 数量多(一张 224×224 图像切分为 16×16 patch 后,共 196 个 patch),若每个专家容量过小,会导致大量重要 patch 被丢弃。
V-MoE 的解决方案是 “优先路由”:
- 为每个 patch 计算 “ 重要性分数 ”(图19左,基于 patch 的信息熵或显著性);
- 优先将重要性高的 patch 分配给专家处理;(图19中)
- 仅当重要 patch 处理完毕后,再分配次要 patch,确保关键信息不丢失。(图19右)
图19:V-MoE的优先路由示意图
实验验证:即使仅处理 50% 的 patch,V-MoE 通过优先路由仍能保持 90% 以上的性能,大幅降低了计算成本。
图20:优先路由的性能保持效果
5.3 Soft-MoE:解决 patch 丢失的 “软分配” 方案
V-MoE 的优先路由虽能减少重要 patch 丢失,但仍存在 “未处理 patch 信息浪费” 的问题。Soft-MoE 提出 “ 软分配 ” 机制, 将离散的 patch 分配改为 “加权混合分配”,让所有 patch 的信息都能参与计算。
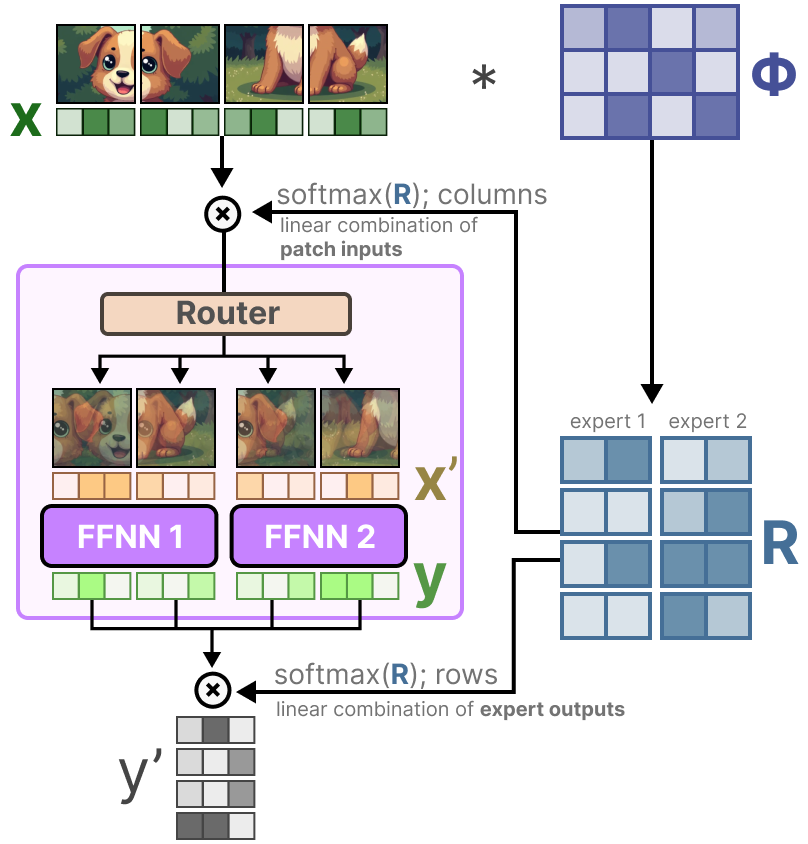
(1)核心创新:软路由机制
Soft-MoE 的路由过程分为两步,核心是 “ patch 混合→专家处理→输出融合 ”:
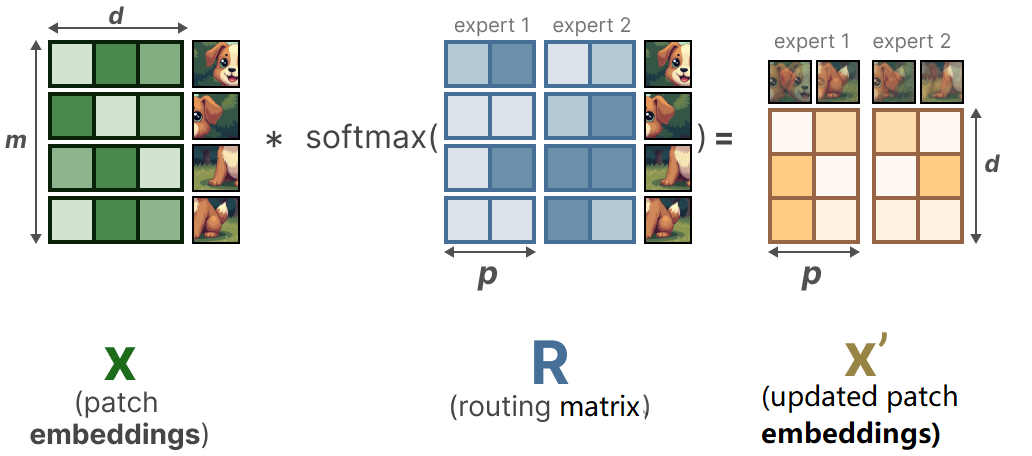
- patch 混合:将输入 patch 的 embedding 矩阵 (维度为 , 为 patch 数量)与可学习矩阵 (维度为 )相乘,得到路由矩阵 (维度为 , 为专家数量),表示每个 patch 与专家的关联程度;
- 软分配:对 按列做 SoftMax,得到权重矩阵 ,每个 patch 的 embedding 更新为所有 patch 的加权平均:
- 专家处理与融合:更新后的 分配给所有专家处理,输出再与 按行做 SoftMax 后的权重矩阵融合,得到最终结果。
(2)优势:无信息丢失的稀疏计算
Soft-MoE 通过 “软分配” 避免了 patch 丢弃,同时保留了 MoE 的稀疏特性(专家仅处理混合后的关键信息),在图像分类、目标检测等任务中,性能优于传统 ViT 和 V-MoE。
图21:Soft-MoE的软路由流程
六、活动参数 vs 稀疏参数:MoE 的算力优势本质
MoE 之所以能实现 “ 大模型能力 + 小模型效率 ”,核心是其独特的 “ 参数激活机制”—— 模型包含大量 “稀疏参数”(加载时需全部加载),但推理时仅激活少量 “活动参数”(参与计算的参数)。 本节以
Mixtral 8x7B 为例,深入解析这一机制。
6.1 核心概念辨析
- 稀疏参数(Sparse Parameters):MoE 模型的总参数,包括所有专家的参数、路由器参数及共享参数(如 embedding 层、注意力层),加载模型时需全部存入显存( VRAM );
- 活动参数(Active Parameters):推理时实际被激活的参数,仅包括被选中的少数专家参数、路由器参数及共享参数,参与计算的参数量远小于稀疏参数。
6.2 Mixtral 8x7B 的参数对比实例
Mixtral 8x7B 是当前最流行的 MoE 模型之一,其参数构成如下:
- 专家数量:8 个,每个专家参数规模为 5.6B(而非 7B);
- 共享参数:embedding 层(131M)、注意力层(1.34B)、路由器(32K)、LM Head(131M);
- 稀疏参数总量: ;
- 活动参数总量:推理时采用 Top-2 路由,激活 2 个专家,故活动参数为 。
图22:Mixtral 8x7B的参数构成对比
6.3 算力优势的核心逻辑
Mixtral 8x7B 的实例清晰展示了 MoE 的算力优势:
- 显存需求:加载时需容纳 46.7B 稀疏参数,显存需求略高于稠密模型;
- 计算需求:推理时仅需计算 11.3B 活动参数,计算成本与 11B 规模的稠密模型相当;
- 性能表现:由于稀疏参数达 46.7B,模型的表征能力接近 50B 规模的稠密模型,实现 “11B 算力→50B 性能” 的跨越。
这一机制的本质是: 用 “显存换算力”,通过加载更多参数(稀疏参数)提升模型能力,同时通过稀疏激活控制计算成本 ,完美解决了大模型 “规模与效率” 的矛盾。
七、总结与展望
混合专家模型(MoE)通过 “ 专家分工 + 智能路由 ” 的核心思想,为大模型的性能提升与效率优化提供了革命性解决方案。 从本质上看,MoE 并非全新的模型架构,而是对传统 Transformer 的 “稀疏化改造”—— 通过拆分 FFNN 为多个专家,引入路由机制实现精准任务分配,再通过负载均衡技术确保所有专家高效协同,最终实现 “规模扩大、成本可控、性能提升” 的目标。
核心贡献回顾
- 突破算力瓶颈:通过稀疏激活机制,让模型在有限计算资源下支持更大规模,解决了稠密模型 “规模与效率” 的矛盾;
- 提升泛化能力:多个专家分工协作,可捕捉更细粒度的任务特征,适配多样化的输入场景;
- 跨领域迁移性:从语言模型(LLMs)到视觉模型(ViT),MoE 的核心机制可灵活迁移,适配不同模态的任务需求;
- 工程化落地成熟:以 Mixtral 8x7B、Switch Transformer、V-MoE 为代表的模型,验证了 MoE 在实际场景中的可行性与优越性。
未来研究方向
- 路由机制优化:当前路由仍依赖简单的概率分配,未来可引入强化学习、注意力机制等,提升路由的精准性;
- 动态专家配置:根据输入场景自适应调整专家数量和容量,进一步提升计算效率;
- 多模态 MoE:探索 MoE 在语音、视频等多模态任务中的应用,实现跨模态的稀疏协同;
- 轻量化部署:针对边缘设备,优化 MoE 的显存占用和推理速度,推动 MoE 的工业化落地。
如今,MoE 已从最初的尝试性技术,成为大模型领域的 “标配组件”。无论是 LLaMA-MoE、GPT-4(疑似采用 MoE 架构)等语言模型,还是 V-MoE、Soft-MoE 等视觉模型,都印证了 MoE 的巨大潜力。对于领域从业者而言,深入理解 MoE 的核心机制,不仅能为模型优化提供新思路,更能把握大模型发展的核心趋势 —— “稀疏化” 将是未来大模型突破算力限制的关键方向 。
| 






 订阅
订阅