| 编辑推荐: |
本文主要深入剖析Palantir本体论的内在机制,看看这个被称为"企业AI的语义操作系统"的架构,到底是如何工作的,希望对你的学习有帮助。
本文来自于人月聊IT,由火龙果软件Alice编辑,推荐。 |
|
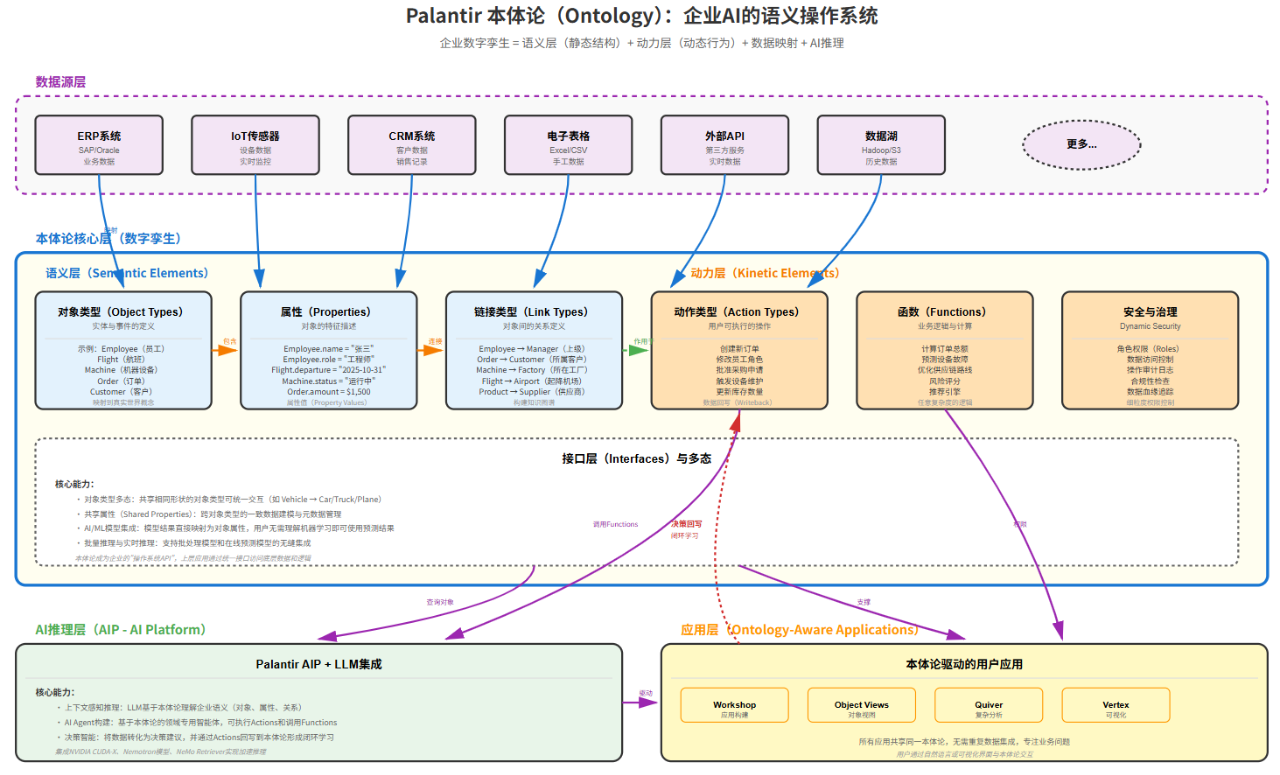
今天继续基于我前面给出的SBR工程学系统建模的可视化来对 Palantir 的本体论进行分析。SBR建模提示语我在前面已经给出过不再叙述,基于该提示语我们提供具体的建模需求描述如下: 美国科技公司沉Palantir 凭借其提出的本体论,对企业进行数字孪生建模,实现了很好的和AI大模型的结合。也有人说本体论构建了企业AI的语义操作系统。我希望你详细分析和理解Palantir本体论后,参考前面的SBR建模提示语,对这个概念进行完整建模,输出SVG模型图。我希望能够表达清楚模型的核心构成组件和组件间的关系。 最终AI输出如下建模图:
我们基于该模型对Palantir本体论核心逻辑进行解释:
引言:一个价值千亿美元的核心概念 2024年,Palantir成为全球最炙手可热的科技公司之一,股价一年内涨幅超过300%。很多人将其归因于AI浪潮的推动,但真正的秘密藏在一个看似学术化的概念背后—— 本体论(Ontology) 。 这不是哲学课上讨论的"存在的本质",而是Palantir用十多年时间打磨出的企业数字化核心引擎。它解决了困扰企业数字化转型的根本问题:如何让散落在各个系统中的数据真正"说同一种语言"?如何让AI不仅能处理数据,还能理解数据的含义?如何让人类的决策经验变成系统可以学习的知识? 今天,我们将深入剖析Palantir本体论的内在机制,看看这个被称为"企业AI的语义操作系统"的架构,到底是如何工作的。
第一层:数据源层——从碎片到整体的起点
企业数据的现实困境 走进任何一家大型企业,你会发现一个令人头疼的现实:数据无处不在,但又相互隔离。财务部门用SAP记录收入支出,生产车间的传感器实时监控设备状态,销售团队在Salesforce中管理客户信息,采购部门还在用Excel表格追踪供应商。 这些数据存在于不同的系统中,使用不同的格式,遵循不同的命名规则。当CEO想要了解"哪个产品线的利润率最高"时,IT部门需要花费数周甚至数月时间,从各个系统中提取数据、清洗整合,最后才能给出答案。而等答案出来时,市场可能已经变了。
本体论的第一步:统一映射 Palantir本体论的底层是一个强大的数据映射引擎。模型图的底部展示了六类典型的数据源:ERP系统、IoT传感器、CRM系统、电子表格、外部API、数据湖,以及无数其他可能的数据来源。 关键在于,本体论不是简单地"搬运"这些数据到一个新的仓库,而是在源头就建立起 语义映射 。比如,SAP中的"Employee ID"、Salesforce中的"Rep Code"、考勤系统中的"工号",虽然字段名不同、格式各异,但它们在本体论中都被映射为同一个概念:Employee对象的唯一标识符。 这种映射是双向且实时的。当源系统的数据更新时,本体论中对应的对象也会自动更新。更重要的是,当用户通过本体论对数据进行修改(比如批准一个采购申请)时,这个变更会回写到源系统,保证数据的一致性。 用蓝色箭头标注的"映射"关系,正是这个统一语义层的建立过程。它将碎片化的数据世界,转化为一个连贯的数字孪生体。
第二层:本体论核心——数字孪生的双重结构
本体论的核心层是整个架构的灵魂,它由两个相互依存的部分构成:语义层和动力层。
语义层:定义"是什么" 语义层回答的是最基础的问题:这个企业由哪些"事物"构成?它们有什么特征?它们之间有什么关系? **对象类型(Object Types)**是语义层的基础单元。在一个制造企业的本体论中,可能定义了这些对象类型:员工(Employee)、机器设备(Machine)、订单(Order)、原材料(RawMaterial)、产品(Product)、供应商(Supplier)。每个对象类型代表了真实世界中的一类实体。 这里的关键是"类型"的概念。就像编程语言中的类(Class),对象类型定义了一类事物的共同特征,而具体的对象(Object Instance)则是这个类型的实例。比如,"张三"是Employee类型的一个实例,"生产线A的冲压机"是Machine类型的一个实例。 **属性(Properties)**描述了对象的特征。Employee对象有name(姓名)、role(角色)、department(部门)等属性;Machine对象有status(运行状态)、temperature(温度)、last_maintenance(上次维护时间)等属性。每个属性都有明确的数据类型,比如字符串、数字、日期、 布尔值 等。 **链接类型(Link Types)**定义了对象之间的关系。这是本体论最强大的部分,也是它区别于传统数据库的关键。Employee对象可以有一个"reports_to"链接,指向他的Manager(也是一个Employee对象);Order对象可以有一个"placed_by"链接,指向下单的Customer对象;Machine对象可以有一个"located_in"链接,指向它所在的Factory对象。
通过这些链接,本体论构建起一张复杂的 知识图谱 。当你查看一个订单时,可以沿着链接追溯到下单客户、负责的销售员、生产该订单的工厂、使用的原材料、涉及的供应商,形成一张完整的关系网络。
动力层:定义"能做什么" 如果说语义层定义了企业的静态结构,那么动力层就定义了动态行为。这是Palantir本体论的一大创新,也是它被称为"操作系统"而非"数据库"的原因。 **动作类型(Action Types)**定义了用户可以对对象执行的操作。这不是简单的CRUD(创建、读取、更新、删除),而是业务语义明确的动作。比如:
- "批准采购申请":这个动作会修改Order对象的status属性,同时触发财务系统的付款流程
- "触发设备维护":这个动作会创建一个Maintenance任务对象,分配给相关工程师,并更新Machine对象的维护计划
- "修改员工角色":这个动作不仅更新Employee对象,还会触发权限系统的重新计算,更新该员工可以访问的数据范围
关键在于,这些动作不是在本体论内部闭环,而是会 回写到源系统 。当你在本体论驱动的界面上批准一个订单,这个决策会实时同步到ERP系统、通知相关人员、触发后续流程。这就是模型图中红色虚线标注的"决策反馈"——形成了一个完整的闭环。 **函数(Functions)**则定义了任意复杂度的业务逻辑和计算。这可以是简单的计算(如订单总额 = 单价 × 数量),也可以是复杂的机器学习模型(如设备故障预测、供应链优化路径)。 函数的输入是本体论中的对象和属性,输出可以是新的计算属性、推荐决策、风险评分等。比如,一个"计算客户信用评分"的函数,会读取Customer对象的历史订单、付款记录、行业信息等属性,通过算法计算出一个信用分数,存储为Customer对象的derived_credit_score属性。
接口层:多态与AI集成 语义层和动力层之间是一个关键的 接口层 。它实现了两个重要能力: 一是 对象类型多态 。就像面向对象编程中的继承和多态,如果定义了一个Vehicle(交通工具)类型,那么Car(汽车)、Truck(卡车)、Plane(飞机)都可以是Vehicle的子类型。它们共享Vehicle的通用属性(如位置、速度),但也有各自特有的属性。这样,一个"追踪所有交通工具"的应用,可以统一处理所有Vehicle类型的对象,而不需要为每种具体车型写单独的代码。 二是 AI模型的无缝集成 。这是Palantir本体论AI化的关键。机器学习模型的输出,可以直接映射为对象的属性。比如,一个设备故障预测模型,它的输入是Machine对象的历史运行数据(温度、振动、运行时长等),输出是一个故障概率值。这个概率值不是孤立的数字,而是直接成为Machine对象的predicted_failure_probability属性,可以像其他属性一样被查询、被应用、被用于决策。 用户不需要理解机器学习的原理,只需要知道"这台机器的故障风险是85%,建议立即维护"。AI的能力被优雅地封装在本体论的接口背后。
第三层:AI推理层——让机器理解企业语言
从数据到决策的智能跨越 传统的企业系统,AI只能做"数据分析"——给你一堆图表,告诉你过去发生了什么。但Palantir通过本体论,让AI进化为"决策智能"——不仅分析过去,还能预测未来、推荐行动、甚至自主执行。 这就是AIP(Artificial Intelligence Platform)的作用。它是Palantir本体论之上的AI推理引擎,核心能力包括: 上下文感知推理 :当你向AI提问"哪些订单有交付延期风险"时,AI不是盲目地搜索所有数据,而是理解Order对象、Delivery对象、Supplier对象之间的关系,知道要检查什么属性(如estimated_delivery_date、supplier_reliability_score),应用什么业务规则(如"距交付期不足3天且供应商可靠性低于70%")。 AI能做到这一点,是因为它"看到"了本体论的语义结构。大语言模型( LLM )天然就擅长理解结构化的语义信息——对象、属性、关系正是它能够理解的"语法"。本体论为AI提供了一个"企业知识的语法书"。 AI Agent 构建 :基于本体论,可以快速构建领域专用的智能体。比如,一个"采购优化Agent",它理解Supplier、RawMaterial、Order、Inventory等对象及其关系,能够:
- 监控库存水平,预测何时需要补货
- 比较不同供应商的价格、交付时间、可靠性
- 生成采购建议,甚至自动创建采购订单(当然,受权限控制)
- 从历史采购决策中学习,优化未来推荐
这个Agent不需要从头训练一个AI模型,而是将通用LLM的能力,通过本体论"接地"到具体的企业领域知识上。 决策智能与闭环学习 :最关键的是,AI的推荐不是终点,而是闭环的起点。当AI推荐"应该向供应商A采购原材料X"时,人类决策者可以接受、修改或拒绝这个建议。无论做出什么决策,这个决策及其结果(如实际交付时间、质量评分)都会回写到本体论。 下一次面对类似场景时,AI会参考这些历史决策:"上次选择供应商A时虽然价格便宜,但交付延误了5天,导致生产线停工。这次虽然供应商B贵10%,但更可靠。"这就是橙色虚线标注的"决策反馈"——AI从人类决策中持续学习,不断优化。
与NVIDIA的深度整合 值得一提的是,Palantir与NVIDIA的合作,让AI推理层的性能达到了新高度。通过NVIDIA的CUDA-X加速库、Nemotron大模型、NeMo Retriever检索增强技术,AI可以在秒级时间内处理海量对象、执行复杂推理。 这种性能对于企业应用至关重要。想象一个供应链优化场景,涉及数千个订单、数百个供应商、数万个零部件,AI需要在几秒内给出优化方案。传统系统可能需要几小时甚至几天的计算时间,而Palantir+NVIDIA的组合可以实现实时决策。
第四层:应用层——将能力交付给最终用户
统一本体论,多样化应用 有了下面三层的支撑,最顶层的应用开发变得极其高效。所有应用共享同一个本体论,意味着它们自动获得了:
- 统一的数据视图(无需重复集成)
- 一致的业务语义(无需重新定义概念)
- 内置的AI能力(无需单独训练模型)
- 细粒度的权限控制(继承本体论的安全策略)
模型图展示了四类典型应用: Workshop 是应用构建平台,类似于企业的"App Store"。业务人员(不仅是IT人员)可以通过拖拽方式,快速组装出满足特定需求的应用。因为底层本体论已经定义好了对象、关系、动作,构建应用变成了"组装乐高积木"而非"从零编程"。 Object Views 提供了以对象为中心的视图。当你查看一个客户对象时,可以看到他的所有订单、历史互动、信用评分、推荐的营销策略,以及可以执行的动作(如发送促销邮件、升级VIP等级)。所有相关信息聚合在一个界面,避免了在多个系统间切换。 Quiver 是复杂分析工具,支持跨对象类型的深度查询。比如"找出所有在过去3个月内有超过5次投诉,但购买金额超过10万的客户"。这种查询在传统系统中需要复杂的SQL联表,而在本体论中是自然语言式的对象关系导航。 Vertex 是可视化工具,将知识图谱以直观的方式呈现。你可以看到对象之间的链接关系,发现隐藏的模式和异常。比如在供应链分析中,可以可视化地看到"某个关键零部件只依赖一个供应商"的风险点。
自然语言交互 更进一步,用户甚至不需要学习任何界面操作,直接用自然语言与本体论对话:"给我列出所有故障风险超过80%的设备"、"为什么订单 #12345会延期 "、"如果我们将生产计划提前一周,会影响哪些订单"。 AI理解这些问题,转化为对本体论的查询,返回结果,甚至提供行动建议。这种交互方式,让本体论真正成为"每个员工都能使用的智能助手"。
核心价值:为什么说是"语义操作系统"
操作系统的类比 为什么Palantir本体论被称为"企业AI的语义操作系统"?我们可以类比计算机的操作系统来理解。 Windows或MacOS是计算机的操作系统,它做了什么?它将底层的硬件(CPU、内存、硬盘)抽象为统一的接口(文件系统、进程管理、网络协议),让上层应用(Word、Chrome、Photoshop)可以专注于自己的功能,而不需要关心硬件细节。应用不需要知道数据存在机械硬盘还是固态硬盘,不需要知道CPU是Intel还是 AMD ,操作系统屏蔽了这些复杂性。 Palantir本体论在企业中扮演的正是这个角色:
- 底层的"硬件" :各种异构数据源(ERP、IoT、CRM...)
- 本体论的"抽象层" :统一的语义模型(对象、属性、链接、动作)
- 上层的"应用" :Workshop、AI Agent、分析工具
应用不需要知道数据来自SAP还是Salesforce,不需要关心字段名是"Employee ID"还是"工号",本体论提供了统一的"API"——对象类型和属性。就像你在Windows上写文件时,调用的是File.write()接口,而不需要关心底层硬盘的物理结构。
四大核心价值 统一语义层(Single Source of Truth) :消除了企业最大的痛点——数据孤岛。不是物理地将数据搬到一个地方,而是通过语义映射,让所有数据"说同一种语言"。当财务、生产、销售都在讨论"客户"时,他们说的是同一个Customer对象,而不是三个不同系统里的三个不同概念。 企业数字孪生(Digital Twin) :本体论不是静态的数据快照,而是实时镜像企业运营的动态模型。就像游戏《模拟城市》让你在虚拟世界中管理一座城市,本体论让你在数字世界中"看到"整个企业的运行状态,可以模拟、预测、优化决策。 AI可理解的语义(AI-Ready Semantics) :这是最革命性的部分。传统系统的数据对AI来说是"原始材料",需要大量的特征工程、数据清洗、模型训练才能使用。而本体论的数据天然就是"结构化知识",AI可以直接理解对象、关系、业务规则,无需额外训练就能进行上下文推理。 决策闭环(Decision Capture & Learning) :这是从"数据智能"到"决策智能"的关键跃迁。系统不仅帮助你做决策,还会记录你的决策、执行结果、经验教训,下次遇到类似情况时给出更好的建议。企业的集体智慧被沉淀为系统可学习的知识,而不是散落在员工脑海中的碎片化经验。
与传统方案的本质差异 很多人会问:这和数据仓库、数据湖有什么区别? 传统数据仓库/湖 关注的是"存储"——把数据从业务系统抽取出来,清洗后存到一个集中的地方,方便分析。但它们缺乏语义理解。数据仓库知道"表A的字段X关联到表B的字段Y",但不知道这代表什么业务含义。每个新应用都要重新理解这些表、重新写SQL、重新集成数据。 Palantir本体论 关注的是"语义"——定义对象、关系、行为的业务含义,然后将分散的数据映射到这个语义模型上。数据依然留在源系统(也可以缓存在本体论的存储层),但通过语义层,所有应用看到的是统一的、业务友好的对象视图。 更重要的是,本体论不是单向的"数据消费",而是双向的"决策闭环"。传统系统是"读数据→分析→人工决策→在各个系统中手动执行"。本体论是"读对象→AI推理→执行Action→自动回写源系统→记录决策→学习优化"。 这种差异,决定了Palantir本体论不仅是"更好的数据仓库",而是一个全新的范式—— 企业的智能中枢 。
典型应用场景
本体论的威力在实际场景中才能真正体现: 供应链优化 :在疫情期间,某跨国企业使用Palantir本体论整合了全球数百个工厂、数千个供应商、数万种零部件的数据。当某个地区封锁导致供应商无法交付时,系统立即识别受影响的订单、寻找替代供应商、重新规划生产计划,将原本需要数周的应急响应缩短到几小时。 工业设备预测性维护 :某能源公司将数千台设备的传感器数据映射为Machine对象,AI持续监控设备状态、预测故障风险。当某台涡轮机的振动模式异常时,系统不仅发出告警,还自动调度维护团队、准备备件、调整生产计划以最小化停机影响。 金融风险管理 :某投资机构通过本体论整合交易数据、市场数据、新闻舆情、社交媒体,构建起实时的风险图谱。AI可以追踪"某公司的债券→持有该债券的基金→该基金的投资者→投资者的关联方"的复杂关系链,提前识别潜在的系统性风险。
结语:从数据时代到语义时代 Palantir本体论的意义,远超一家公司的产品创新。它代表了企业数字化的一次范式转移:从"数据驱动"到"语义驱动",从"IT工具"到"业务语言",从"辅助决策"到"智能决策"。 在数据时代,企业的核心资产是"拥有多少数据"。在语义时代,核心资产变成了"如何理解数据、如何将知识形式化、如何让AI与人协同决策"。本体论正是实现这一转变的关键技术。 当AI成为企业运营的核心生产力时,那些率先构建起自己"语义操作系统"的企业,将在智能时代占据不可替代的优势。这也是为什么Palantir在AI浪潮中爆发的深层原因——它十多年的技术积累,在大模型时代找到了最完美的应用场景。 未来已来,语义操作系统的时代正在开启。
| 






 订阅
订阅