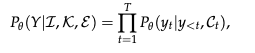| 编辑推荐: |
本文主要介绍“Vibe Coding”的新兴AI驱动开发范式,阐述了其理论基础、技术生态、五种实践模型以及未来挑战,论证了它将如何重塑人机协作的软件开发流程,希望对你的学习有帮助。
本文来自于AI修猫Prompt,由火龙果软件Alice编辑,推荐。 |
|
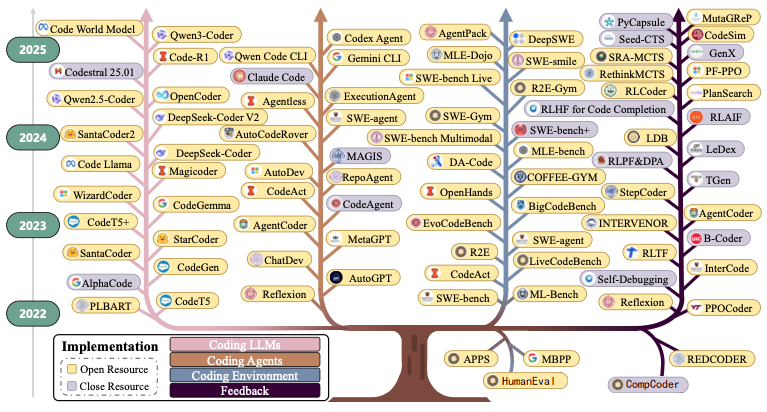
编码智能体(Coding Agents), 这些智能体能够处理复杂的编程任务,与开发环境交互,执行测试,甚至进行自我调试。这一飞跃催生了一种范式转变,带来了一种引人思考的新开发方法论, 尽管“Vibe Coding”的概念已经广为流传,但 一直缺乏对其进行全面系统的梳理、建立严谨理论基础和实用框架的尝试。在此背景下, 来自中国科学院计算技术研究所、杜克大学等机构的研究者们近期发布的这份里程碑式的调研报告,通过系统分析超过1000篇研究论文,构成了对这一实践的 首次全面且系统的综述 。
这篇综述的核心结论是:“跟着感觉走”的编程实践正面临比预期更复杂的现实考验。它远非开发的“万能钥匙”,那些宣称“程序员即将消亡”的论调,在严谨的研究面前显得为时过早。
本文将分为 四大篇章 ,为您 系统性地导航 Vibe Coding 的世界:
- 定义 Vibe Coding
- Vibe Coding 生态解析
- Vibe Coding 的五种开发模式
- 未来影响与开放挑战
通过这四个步骤,您将对 Vibe Coding 获得一览无余的清晰认知。
定义“Vibe”:究竟是什么?
该报告并非随意地定义 Vibe Coding,而是将其正式确立为一种基于 LLM 的 工程方法论(engineering methodology) 其核心在于一个动态的 三元关系(triadic relationship) ,涉及三个关键实体:
- 人类开发者 (Human, H): 从直接的代码编写者转变为 意图阐述者 (intent articulator) 、上下文管理者 (context curator) 和质量仲裁者 (quality arbiter)。我 们定义“做什么”(what)和“为什么”(why)。
- 软件项目 (Project, P): 不再仅仅是静态的代码库,而是扩展为一个多层面的 信息空间 (information space) ,包含代码、数据库、领域知识和执行环境。它定义了“在哪里”(where)——即边界和上下文。
- 编码智能体 (Coding Agent): 一个由 LLM 驱动的智能执行者,在人类意图和项目约束的双重指导下,执行代码生成、修改和调试。它负责管理“如何做”(how)。
Vibe Coding 概述 - 展示三元关系和交互循环
为了巩固这一概念,研究者们首次使用 约束马尔可夫决策过程(Constrained Markov Decision Process, Constrained MDP) 对其进行了形式化。论文中展示了一个具体的数学模型来捕捉这个动态过程:其中项目状态定义了状态空间,人类指令触发智能体动作,智能体的动作在项目约束下进行状态转移,而人类的评估则提供了奖励信号。
上下文:AI 创作的“灵感源泉”与“紧箍咒”
形式化模型揭示了一个关键点: 上下文工程(context engineering) 是这场演出的灵魂。智能体并非凭空创作,它的每一次“挥毫”(代码生成)都深度依赖于当前接收到的信息——即动态上下文。
这个上下文就像是 AI 的“灵感包”,混合了三方的信息:
- 人类的指令 (instr): 明确的需求和提示。
- 项目的底蕴 (code, data, know): 现有的代码库、API、数据结构、文档、最佳实践等。
- 智能体的“记忆”与“工具箱” (tool, mem, tasks): 可用的编译器、测试框架,过往的交互记录,以及当前待办事项。
Vibe coding的核心哲学在于:
人 掌控 “什么” (定义正确的问题,并允许问题动态演变) 和 “为什么” (判断解决方案是否恰当);
项目 定义 “在哪里” (约束解决方案的空间边界);
智能体 管理 “如何做” (探索具体的技术实现路径)。
这三者的协同,构成了一个能够自我调整、需求能够不断演化的 闭环软件开发系统 。它不再是线性的瀑布,也不是简单的循环,而更像是一个共同学习、共同进化的有机体。关于上下文工程,之前还有一篇文章,也是综述,感兴趣您可以看下
中科院清北重磅发布:「上下文工程」的系统脉络图来了!
支撑 Vibe Coding 的生态系统:深度解析
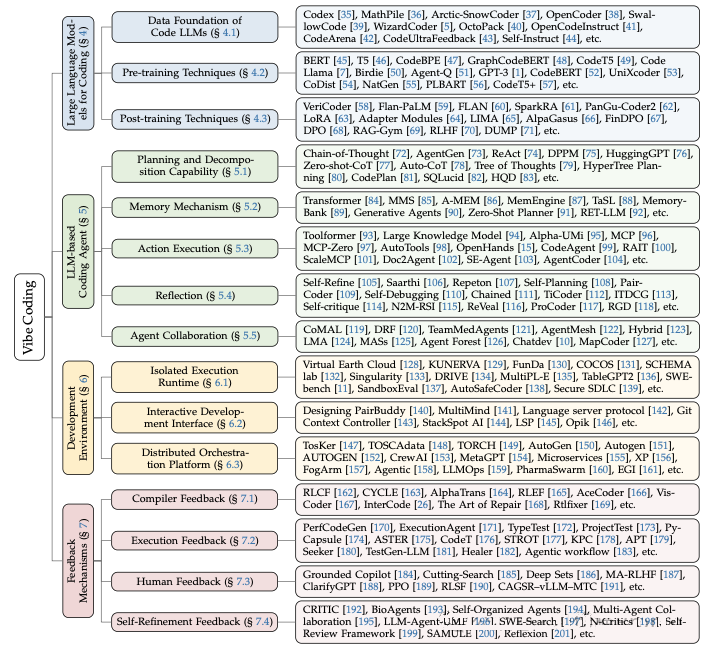
该报告细致地描绘了支撑 Vibe Coding 的整个技术生态系统,并将其组织成四个关键层面。理解这些层面是认识当前系统能力和局限性的关键。
Vibe Coding 的技术分类 - 展示四个主要组成部分及其子领域
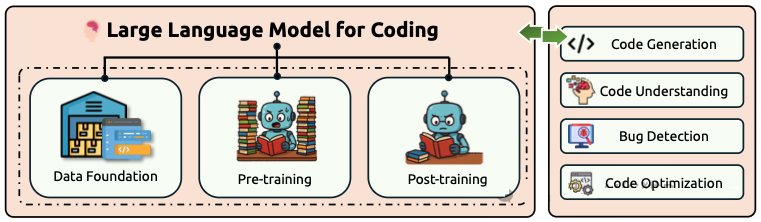
第一层:用于编码的大型语言模型 (LLMs for Coding)
这是基石,依赖于为代码相关任务专门优化的大模型。
- 数据是王道: 训练这些模型需要海量的代码语料库(如 The Stack, CodeParrot)以及精心策划的指令/偏好数据集(如 CommitPack, OpenCodeInstruct, CodeUltraFeedback)。数据质量和复杂的处理流程(例如,过滤、去重、通过 Self-Instruct 或 Evol-Instruct 进行合成数据生成)至关重要。
- 训练技术:
- 预训练: 目标包括用于理解的掩码语言建模 (MLM) (如 CodeBERT)、用于生成的自回归建模 (如 Code Llama)、去噪目标 (如 PLBART),以及利用代码语法/语义的结构感知目标 (如 GraphCodeBERT)。持续预训练 (CPT) 将通用模型适配到代码领域 (如 DeepSeek-Coder-V2),但需注意数据混合和灾难性遗忘。
- 后训练: 监督微调 ( SFT ) / 指令调优 使模型遵循指令,常因模型规模巨大而使用参数高效微调 (PEFT) 如 LoRA。强化学习 (RL),特别是来自人类反馈的强化学习 ( RLHF ) 或其更简单的替代方案直接偏好优化 (DPO),用于使模型与人类偏好或正确性标准(例如,使用编译器/测试反馈)对齐。
第二层:基于 LLM 的编码智能体
这些智能体将“被动”的 LLM 转变为“主动”的问题解决者。
- 核心能力:
- 规划与分解 (Planning & Decomposition): 将复杂任务分解为步骤(例如,使用思维链 CoT、思维树 ToT)并制定行动计划。像 ReAct 这样的框架将推理和行动交织在一起。
- 记忆 (Memory): 智能体需要超越上下文窗口的记忆。这包括短期工作记忆和长期记忆,后者常使用外部向量数据库 或受认知科学启发的专门架构如 MemoryBank 和 MemGPT。
- 动作执行 (Action Execution): 通过调用工具(编译器、调试器、API、文件操作、shell 命令)与环境交互。使用可执行代码作为统一的动作空间(如 CodeAct)比僵化的 JSON 格式更具灵活性。
- 反思 (Reflection): 迭代、验证和调试的能力。这涉及自我批判、自我调试,以及利用反馈(编译器错误、测试失败)来改进输出。像 Self-Refine 这样的框架对此进行了形式化。
- 协作 (Collaboration): 多个智能体协同工作,通常扮演专门角色(程序员、测试员、评审员),通过通信协议进行协调。像 MetaGPT 和 ChatDev 这样的框架是这种多智能体方法的范例。
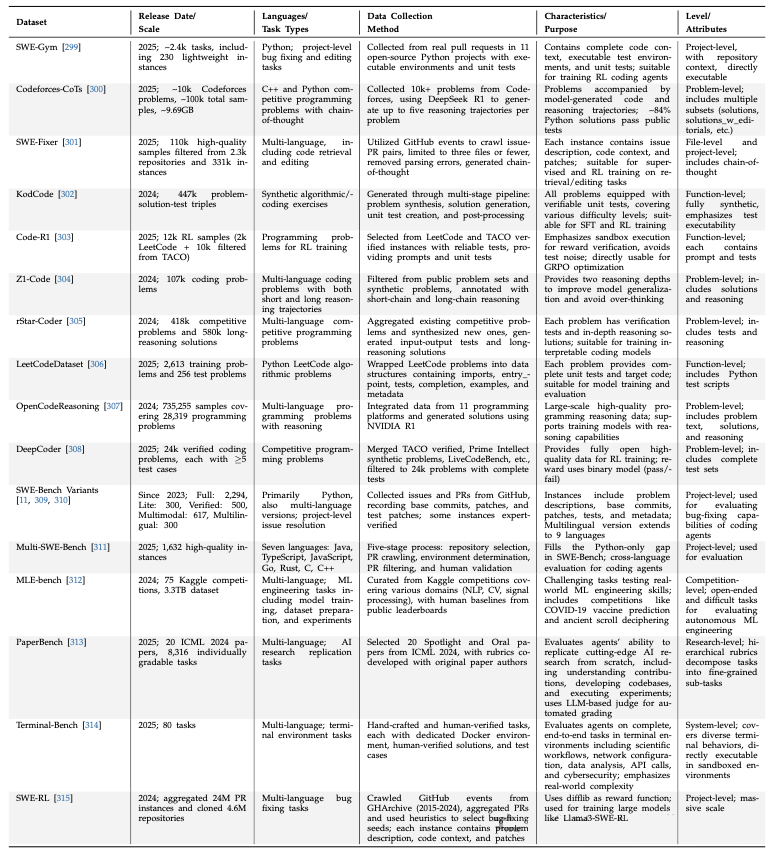
目前不同产品的具体能力。
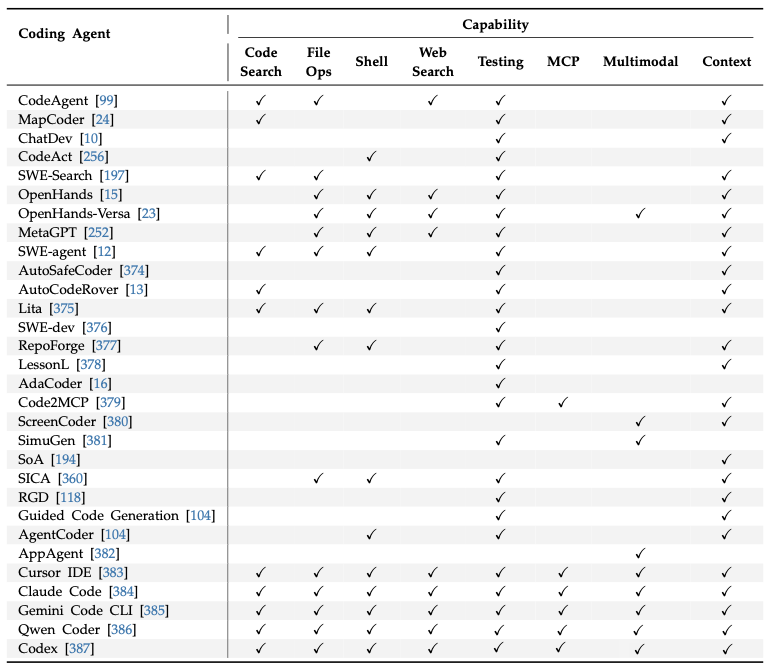
第三层:开发环境
Vibe Coding 需要稳健且安全的环境供智能体运行。
三个关键环境组件:隔离、交互、分布式
- 隔离的执行运行时 (Isolated Execution Runtime): 对于安全运行可能不受信任的 AI 生成代码至关重要。通过以下方式实现:
- 容器化 (Docker, Kubernetes) 以确保一致性和资源管理。
- 安全沙箱 (gVisor, 多层框架, 硬件隔离) 以防止损害。
- 云平台 提供跨多种语言的可扩展、可复现的执行环境。
- 交互式开发接口 (Interactive Development Interface): 开发者与智能体交互的方式。
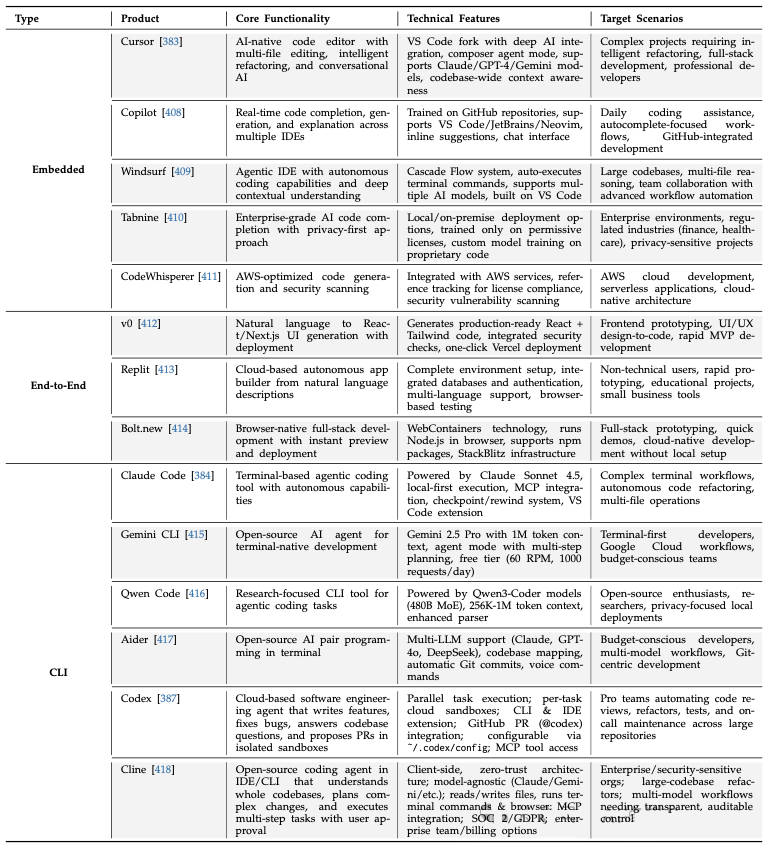
- AI 原生 IDE (如 Cursor) 嵌入对话式 AI 和上下文感知能力。
- 远程开发环境 (GitHub Codespaces) 提供标准化、隔离的云端工作区。
- 标准化协议 (MCP, LSP, DAP) 实现智能体与现有工具的互操作性。
- 分布式编排平台 (Distributed Orchestration Platform): 管理复杂工作流和多智能体系统。
- CI/CD 流水线集成 确保 AI 生成的代码经过严格验证。
- 云计算编排 (使用 TOSCA 等标准) 实现动态资源调配。
- 多智能体协作框架 (AutoGen, CrewAI, MetaGPT) 为协调专业智能体提供基础设施。
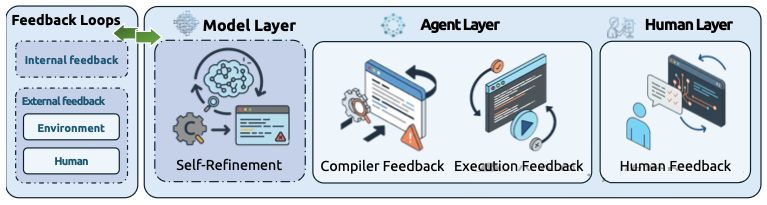
第四层:反馈机制
反馈是驱动 Vibe Coding 迭代和改进的引擎。
可视化内部(自我改进)和外部(环境、人类)反馈循环
- 编译器反馈 (Compiler Feedback): 语法错误、类型错误、静态分析警告(来自 linter 等工具)提供了底层的正确性信号。
- 执行反馈 (Execution Feedback): 运行代码提供了关键洞见:
- 单元测试结果(通过/失败,具体失败信息)。
- 集成测试反馈 关注系统级行为。
- 运行时错误和异常,在执行期间捕获。
- 人类反馈 (Human Feedback): 开发者的输入仍然至关重要:
- 交互式需求澄清 以解决模糊性。像 ClarifyGPT 这样的系统旨在自动化此过程。
- 代码审查反馈,通常通过 RLHF/DPO 中使用的偏好数据隐式捕获。
- 自我改进反馈 (Self-Refinement Feedback): 智能体自我提升:
- 自我评估与批判 (Self-Evaluation and Critique) (如 Self-Refine, CRITIC),智能体评估自己的输出。
- 多智能体协作反馈,智能体相互批判。
- 反思与基于记忆的反馈 (Reflection and Memory-Based Feedback) (如 Reflexion),利用存储在记忆中的过去经验(失败)来指导未来行动。
选择你的“Vibe”:五种开发模型
基于人类控制、结构化约束和上下文管理这三个维度的相互作用,该报告提出了五种不同的 Vibe Coding 开发模型。这个分类法为实践者提供了一个框架,可以根据项目需求和风险承受能力选择合适的方法。
在约束与速度等轴上比较五种 Vibe Coding 模型与传统软件工程模型
- 1.无约束自动化模型 (UAM - Unconstrained Automation Model):
- 概念: 对 AI 输出最大程度的信任,最少的人工审查,通过输出测试进行验证。最接近“纯粹 Vibe”的概念。
- 优点: 开发速度最快,入门门槛最低。
- 缺点: Bug、安全漏洞、技术债、可维护性差的风险极高。
- 软件工程对应: 快速应用开发 (RAD)。
- 适用场景: 一次性原型、概念验证、个人工具。 不推荐用于生产环境 。
- 2.迭代式对话协作模型 (ICCM - Iterative Conversational Collaboration Model):
- 概念: AI 作为编程伙伴,持续对话,人类在接受前审查并理解 所有 AI 输出。
- 优点: 平衡速度与质量,确保代码符合标准,更好的可维护性。
- 缺点: 需要经验丰富的开发者,增加了审查的认知负荷和时间成本。
- 软件工程对应: 结对编程 (Pair Programming)。
- 适用场景: 专业开发环境、需要长期维护的项目、团队协作。
- 3.计划驱动模型 (PDM - Planning-Driven Model):
- 概念: 人类预先定义详细的计划、架构和规范(“蓝图”),然后指导 AI 执行。架构优先的理念。有些类似于Spec,感兴趣您可以看下
- 上下文工程难吗?试下Claude Code写入Kiro的Spec,自动搞定上下文
- 优点: 保证方向正确性,产出结构化、一致性高的代码,适合复杂系统。降低长期维护成本。
- 缺点: 需要大量的预先规划投入。初期灵活性低于 ICCM 或 UAM。
- 软件工程对应: 瀑布模型 (Waterfall Model) (但由于 AI 的迭代能力而更灵活)。
- 适用场景: 复杂的全栈应用,需要清晰模块化和架构完整性的项目。
- 4.测试驱动模型 (TDM - Test-Driven Model):
- 概念: 人类首先编写测试/验收标准,AI 生成代码以通过测试。测试作为对 AI 的精确、可执行的规范。
- 优点: 通过机器验证提供客观的质量保证,减少人工审计负担,失败的测试能精确定位问题。提高重构信心。
- 缺点: 需要预先投入大量精力编写全面的测试。测试质量至关重要。
- 软件工程对应: 测试驱动开发 (TDD)。
- 适用场景: 核心算法实现、生产级应用、关键业务逻辑、需要长期维护的代码库。
- 5.上下文增强模型 (CEM - Context-Enhanced Model):
- 概念: 不是独立的工作流模型,而是一种可以应用于任何其他模型的横向增强能力 。使用检索增强生成 (RAG)、代码库索引、文档加载 等技术,为 AI 提供项目特定的上下文。
- 优点: 生成的代码能更好地与现有代码库、风格和约定保持一致。提高准确性和一致性,尤其适用于大型项目或重构场景。
- 缺点: 需要建立索引/检索机制;效果依赖于上下文源的质量和检索机制的有效性。
- 组合应用: UAM+CEM (受控原型),ICCM+CEM (大型代码库维护),PDM+CEM (确保规范符合性),TDM+CEM (高质量和一致性)
前路漫漫:未来的影响与开放性挑战
Vibe Coding 不仅仅是一项新技术;它有望(也可能威胁到)重塑整个软件开发流程,并带来严峻的挑战。
- 重塑开发流程:
- 流程转变: 从瀑布/敏捷的阶段性生命周期 转向持续的 "prompt-generate-validate" 微迭代,模糊了传统界限。
- 角色演变: 开发者变为架构师、提示工程师、上下文管理者和系统级调试者。技能重心转向意图表达和验证。
- 管理挑战: 工作量估算变得困难。代码审查需要重新思考,以涵盖提示和行为,而不仅仅是代码本身。协作可能涉及“群体提示”(mob prompting)。
- 代码可靠性与安全性: 这可能是 Vibe Coding 进入生产系统的 最大障碍 。
- 人工审查的不足: 如果人类必须手动检查每一行代码,那么 AI 生成带来的速度优势将被抵消。开发者也可能缺乏发现 AI 引入的缺陷所需的专业知识。
- 需要集成的反馈回路: 安全性和可靠性检查必须嵌入 Vibe Coding 周期 内部 ,而不仅仅是在 CI/CD 阶段。这包括实时静态应用安全测试 (SAST) 分析部分代码 ,在验证阶段进行沙箱化的动态应用安全测试 (DAST) 和模糊测试 (Fuzzing),以及 AI 驱动的威胁建模。人类仍然是最终的仲裁者,负责解释自动化工具的输出。
- 自主智能体的可扩展监督: 随着智能体自主性增强(例如,跨代码库生成和部署代码),监督范围必须从代码级验证扩展到系统级治理。
- 新出现的风险: 自主工作流可能导致 级联错误 (Cascading Errors) 在流水线中传播, 依赖扩散 (Dependency Proliferation) 增加攻击面,以及 对齐失败 (Alignment Failures) 即智能体行为偏离预期意图。
- 需要可扩展的架构: 传统的人工监督无法扩展。研究重点是 弱到强泛化 (weak-to-strong generalization) ,即利用有限的人类/弱 AI 监督来指导强大的智能体。技术包括: 分层监督 (Hierarchical Supervision) 、 多智能体辩论与批判 (Multi-Agent Debate and Critique) (如 DEBATECODER)、以及 持续监控与自动化保障 (Continuous Monitoring and Automated Safeguards) (如看门狗智能体)。
- 人的因素: Vibe Coding 从根本上改变了人类编程的体验。
- 心智模型转变: 从操控代码逻辑转向 上下文工程 (Context Engineering) ——管理提示、约束和背景信息。
- 技能演变: 提示设计、任务分解、质量监督(测试、验证)、智能体治理和安全 变得至关重要。
- 团队协作: AI 智能体成为准团队成员。挑战包括信任校准(避免过度依赖或过度怀疑)、AI 错误的责任归属,以及调整审查流程。其影响还延伸到教育和组织结构。
结论:工程化“Vibe”
研究者们通过为 Vibe Coding 奠定理论基础、描绘复杂技术生态并勾勒实用框架,清晰地指出:
成功的关键在于将AI的自动化能力与人类的深刻理解、批判性思维和工程纪律相结合 。仅仅依赖AI输出而放弃深入代码理解,已被证明是通往不可靠、难以维护系统的捷径。因此,扎实的编程基础、良好的代码理解习惯以及强大的逻辑思维能力,非但没有过时,反而成为驾驭AI、使其真正服务于高质量软件开发目标的 核心竞争力 。
在这个新范式中,具备这些能力的开发者将能更有效地指导AI、评估其产出、整合其贡献,从而在新的人机协作模式中“如鱼得水”。如果你正身处软件开发领域,理解这一点并相应调整,就不仅仅是跟上潮流,而是关乎未来能否在行业中保持领先。
| 






 订阅
订阅