| 编辑推荐: |
本文介绍了如何训练大模型(LLM)相关内容。希望对你的学习有帮助。
本文来自于微信公众号智作工坊 ,由火龙果软件Alice编辑,推荐。 |
|
将一个能输出 “智能感” 的大语言模型(LLM)助手 “塑形”,可类比为一个迭代式的黏土雕塑创作过程:从一块原始黏土开始,先捏出基础结构,再逐步雕琢细节,直至接近最终形态。越接近成品,细微之处的处理越关键
—— 这正是区分 “杰作” 与 “恐怖谷效应产物” 的核心。
在完成前期塑形前,无法着手细节雕琢;同理,若不对 LLM 架构进行预训练,直接投入偏好优化与推理训练,也无法达到预期效果。模型需要具备足够的基础能力,才能获得最低限度的奖励信号,从而朝着合理可控的方向迭代。
这种 “塑形” 过程仍是当前的活跃研究领域,我们尚未完全实现 “超对齐(superaligned)的求真型智能助手”
这一终极目标,但在对 LLM 训练方法论的集体认知上,已取得了巨大进展。
Kimi 与 DeepSeek 的技术论文向业界披露了大量宝贵信息,涵盖 LLM 预训练、监督微调(SFT)与强化学习(RL)的叠加应用
—— 这些技术层的组合能持续提升 LLM 的实用价值。
作为参考,DeepSeek V3 的训练数据量达 14.8 万亿 token,约相当于 1.23
亿本平均篇幅的小说文本总量。从规模上看,谷歌在 2010 年曾估算,人类历史上累计创作的书籍总量约为
1.29 亿本。
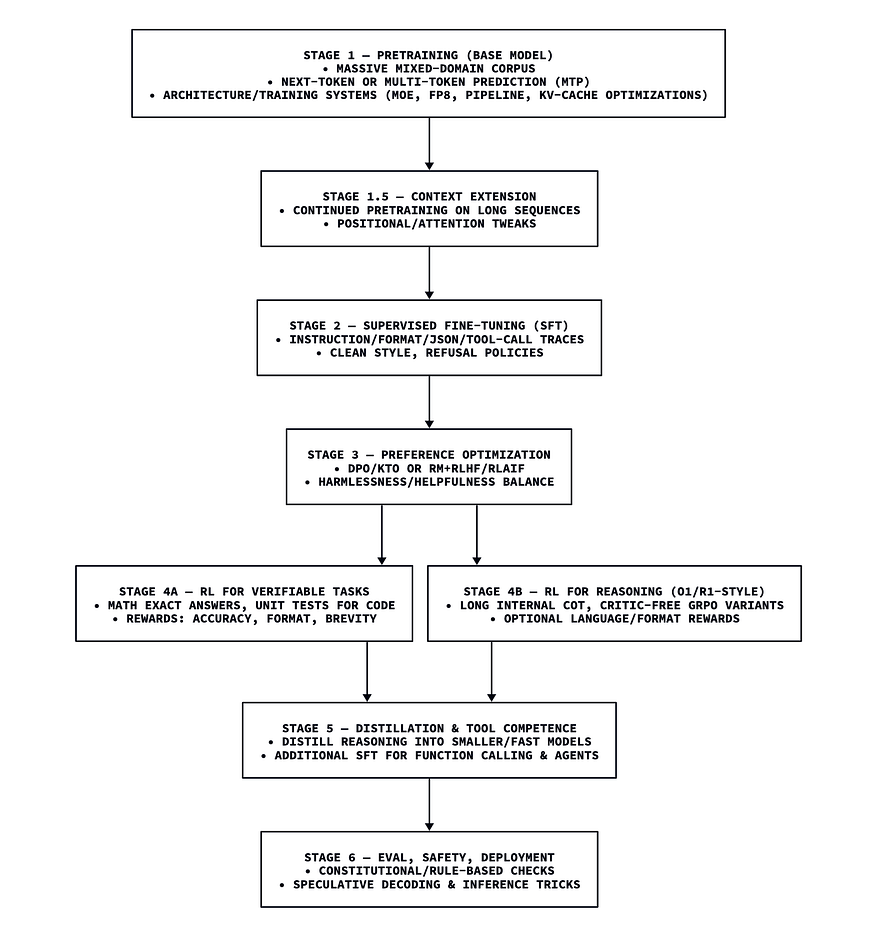
上图为大语言模型端到端训练的通用流程。并非所有模型都需经历全部阶段,但最完整的训练流程通常会在预训练后,包含一个或多个训练后阶段与对齐步骤。
模型训练技术:LLM 的 “雕塑工具”
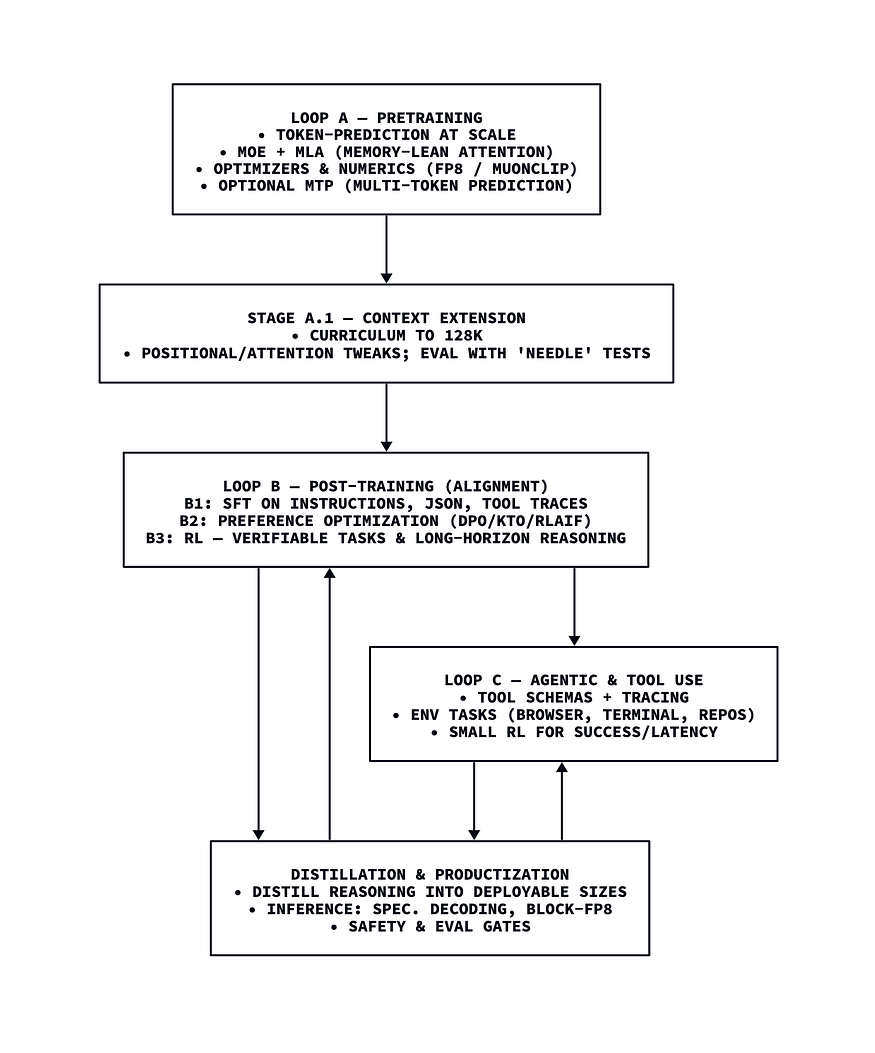
要让 LLM 具备链式推理(CoT)、工具使用等复杂能力,需通过三个相互关联的训练循环实现。
1. 自监督预训练
正如雕塑需先塑形,LLM 若未建立对人类语言的基础认知,便无法实现复杂推理。在引导模型生成对话式交互与推理内容前,需先让其从数据分布中学习生成连贯文本的能力。
第一个训练循环是预训练阶段:通过在跨领域数据上进行大规模自监督学习,为模型构建基础能力与通用先验。模型会摄入来自代码、百科全书、教科书、网页等多源的海量原始文本数据;通过
“文本填空” 式的自监督学习,模型需掌握补全文本的规律,进而理解人类语言的特性。
现代 LLM 训练栈会结合架构与系统层面的优化技巧:
混合专家模型(Mixture-of-Experts, MoE):在不增加稠密模型计算成本的前提下提升模型容量;
多头 latent 注意力(Multi-head Latent Attention, MLA):减少注意力机制的内存占用;
FP8/MuonClip:实现稳定的高吞吐量数值计算;
多 token 预测(Multi-Token Prediction, MTP):优化训练目标密度,支持更快的投机解码(speculative
decoding)。
这一阶段的核心是 “规模化教会模型‘语言如何工作’”,同时通过工程优化避免 GPU 过载或损失曲线异常。
2. 训练后微调
第二个训练循环是训练后阶段:为基础模型赋予 “可控性” 与 “风格特性”。团队通常先通过监督微调(SFT)
—— 在指令、JSON 格式、工具调用轨迹等数据上训练,让模型学会遵循指令、与用户交互。若不进行微调,LLM
只会无限续写文本、复述训练数据中的 token,无法形成简洁的用户交互;因此需构建 “脚本式对话数据集”,引导模型的
token 生成向 “指令响应” 格式靠拢,这一过程即 “指令微调(Instruction Fine-Tuning)”。
当模型具备对话式响应能力后,可进一步应用更精细的强化学习技术(如直接偏好优化 DPO、组相对策略优化
GRPO),塑造模型的语气、安全性与格式合规性 —— 这正是训练中的 “对齐环节”,目标是让模型输出符合人类需求的内容。
最终,还可针对特定行为施加强化学习:
可验证奖励强化学习
(适用于数学 / 代码 / 格式任务):通过自动评分器为模型的正确输出提供明确奖励;
链式推理(CoT)强化学习
(如 o1/R1 风格):引导模型生成类人类的思考过程与自我反思文本,通过更长的生成序列与推理时计算提升问题解决能力。
3. 工具使用训练
正如推理能力需通过强化学习引导,工具使用能力也是一种 “生成模式”—— 通过微调可让模型更自然地掌握这一能力。
要让 LLM 生成符合系统集成要求的工具调用输出,需进入智能体 / 工具训练循环:模型需学习 “在现实世界中执行任务”。实验室通常会扩大工具调用轨迹的覆盖范围、强制遵守严格格式,并在沙盒环境(浏览器、终端、代码仓库)中训练,填补
“认知” 与 “行动” 的差距。少量联合强化学习(joint RL)可提升工具调用成功率、降低延迟,但可靠性的核心仍依赖高质量轨迹数据与严谨的格式规范。
近期有报道称,OpenAI 的 o3 系列推理模型已成功结合 “工具调用训练循环” 与 “推理微调”,实现了
“推理文本与工具使用自发交替生成” 的能力。
开源领域的两个具体案例可提供实践参考:
DeepSeek-V3:采用 6710 亿参数 MoE 架构(每 token 激活约 370 亿参数),在
14.8 万亿 token 上预训练,结合 FP8 与 MTP 优化训练稳定性与推理速度;
Kimi K2:规模达 1.04 万亿参数 MoE(每 token 激活约 320 亿参数),预训练数据量
15.5 万亿 token,依赖 MuonClip 避免万亿参数 MoE 训练中的损失尖峰,同时通过大规模工具使用数据合成与联合强化学习,重点强化智能体能力。
实践总结:预训练让模型建立一致的语言理解,训练后微调则赋予模型工具使用、推理、对话角色扮演等行为属性。
微调 vs 提示工程
最后一个问题:既然可通过 “向指令微调后的模型提供完整指令集” 实现目标,为何还需额外微调?
核心原因是指令微调的能力存在上限:提示词中的潜在指令空间极其庞大,模型需平衡 “早期工具调用指令”
与 “新数据源的后续信息”,极易导致上下文混乱、注意力分配紧张。
若模型未学习 “如何合理理解所有信息” 及 “何时关注何种信息”,在智能体工具使用场景中会迅速失效。尽管可通过工程手段规避非工具调用模型的局限性,但从效率出发,直接使用
“在指令遵循、推理、工具使用联合场景中获得奖励” 的模型,通常是更优选择。
塑形的 “双手”:数据是什么样的?
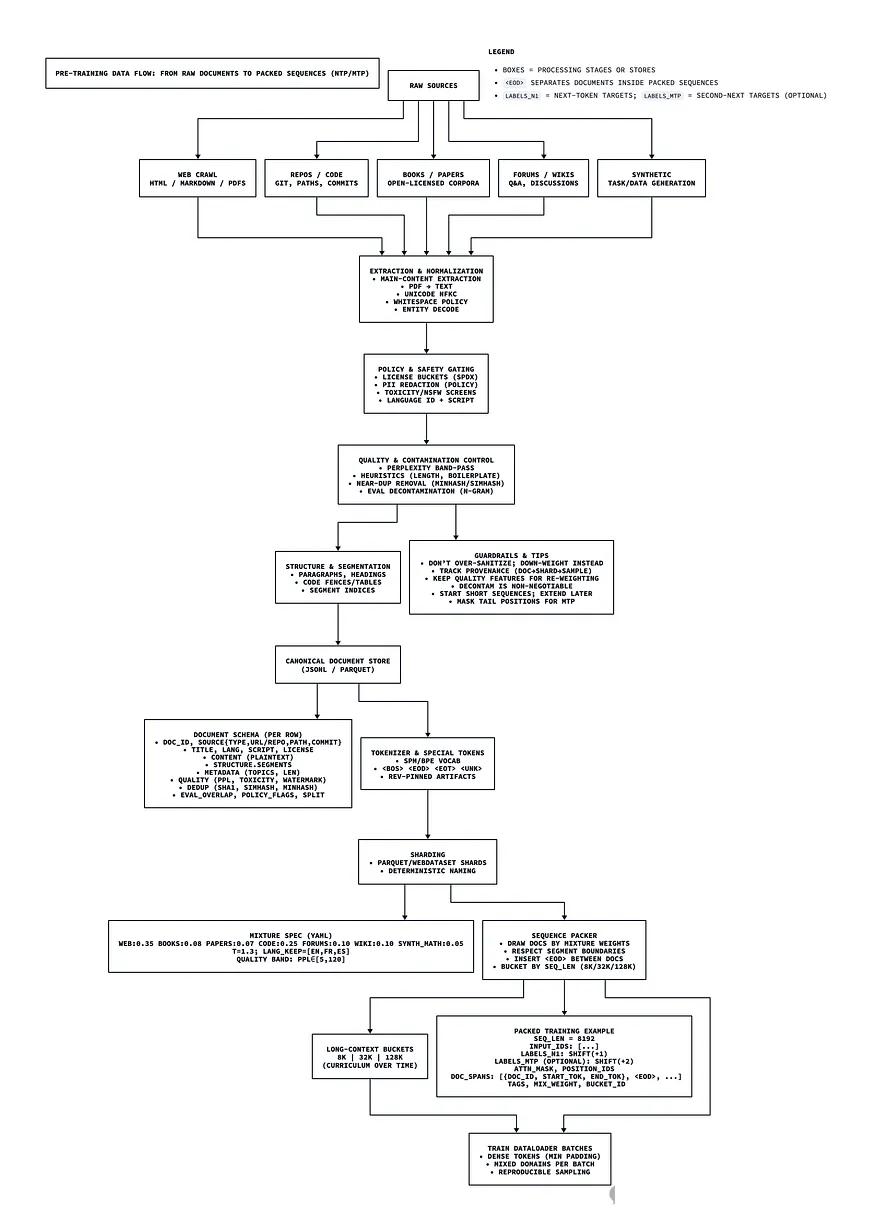
LLM 训练中最关键的环节无疑是数据。要实现 “用数据建模语言”,需经历复杂流程:数据获取、存储、标注、切分为固定长度序列后输入模型。
结合我在生物信息学领域的经验,这一过程与 DNA 测序存在机制上的相似性:要读取 DNA 序列,需先通过冗长的预处理流程;测序仪对序列长度与质量也有特定要求,否则无法有效读取数据。
LLM 的数据处理与之类似:为提升效率,需将文本语料切分、质控、标注为固定长度序列,才能在训练中利用规模化并行计算。
上图为数据处理的端到端流程:从 “原始来源” 的多格式数据,到最终转换为 “可载入 Python
DataLoader 的 token ID 固定长度序列”。
本文聚焦 “预训练前必需的关键数据处理阶段”:
数据获取(Sourcing):开发爬虫、购买授权、获取公开文本数据集。数据不会来自单一语料库,而是分散于多个来源;且需以
“时间快照” 形式捕获 —— 预训练开始后,模型仅能通过工具使用或上下文工程获取新信息。
提取、标准化与质量校验(Extraction, Normalization, QA):以尽可能高的质量提取文本,这是避免
“垃圾进、垃圾出” 的关键。通常会通过自动化算法从 PDF、HTML 网页、GitHub 代码等来源中提取文本,确保正文无噪声污染。完全无噪声无法实现,但需保证绝大多数数据逻辑通顺
—— 只有这样,模型才能在自监督学习下实现收敛(“稳定训练”)。
标注与结构化(Annotation and Structuring):通过自动化算法遍历清洗后的文本样本,进行标注与存储。通常会添加段落框架、文档长度、格式标注(Markdown、JavaScript、纯文本、HTML)等信息,这些标注既便于训练,也能为团队提供故障排查所需的统计摘要。
切分、分片与填充(Chunking, Sharding, Padding):将文本 “切割” 为带特殊标记的片段(如文档结束符<eod>),tokenize
为数值 ID 后进行填充,确保所有序列长度一致。等长序列便于批量对齐,可同时向训练循环输入多个样本,实现规模化并行训练。
示例 1:文档 schema
{
"doc_id": "01J2Y2G2F6X9S7J3SYZ3QW6W0N",
// ULID/UUID
"source": {
"type": "web|book|paper|code|forum|wiki|synthetic",
"url": "https://example.com/post",
// for web
"repo": "github.com/org/repo",
// for code
"commit": "0f3c1a...", //
for code
"path": "src/utils/math.py"
// for code
},
"title": "A Gentle Intro to FFT",
"lang": "en", // ISO 639-1
"script": "Latn", // ISO
15924
"license": "CC-BY-4.0",
// SPDX id or policy bucket
"created_at": "2023-04-12T09:21:37Z",
"collected_at": "2025-07-25T14:03:11Z",
"content": "Plaintext body
with paragraphs...\n\n## Section\nText continues...",
"structure": {
"format": "markdown|plaintext|html|latex|rst",
"segments": [
{"start_char":0,"end_char":128,"type":"paragraph"},
{"start_char":129,"end_char":180,"type":"heading","level":2},
{"start_char":181,"end_char":420,"type":"code","lang_hint":"python"}
]
},
"metadata": {
"domain": "example.com",
"topics": ["signal_processing","math"],
"reading_level": 11.2,
"length_chars": 4231,
"length_tokens_est": 950
},
"quality": {
"ppl_small_lm": 28.7, // perplexity
filter signal
"toxicity": 0.004, // [0,1]
"pii": {"email":1,"phone":0,"ssn":0},
// counts
"watermark_prob": 0.01 // LLM-written
detector
},
"dedup": {
"raw_sha1": "0e5b4...8f",
"text_sha1": "a1c2d...9a",
"simhash": "9b7a3f12",
"minhash": [121, 9981, 733, 4211,
5901] // 5× 64-bit or more
},
"policy_flags": {
"nsfw": false,
"copyright_sensitive": false,
"allowed_for_training": true
},
"eval_overlap": {
"mmlu": 0.0, "gsm8k":
0.0, "humaneval": 0.0 // n-gram/regex
decontamination
},
"split": "train|val|test"
}
|
示例 2:打包填充后的序列 schema
{
"sample_id": "01J2Y3AZ7X12P5...",
"seq_len": 8192,
"tokenizer": "sentencepiece_v5_en_32k",
"input_ids": [1017, 42, 1337, "..."],
"labels_n1": [42, 1337, 9001, "..."],
// next-token labels
"labels_mtp": { // optional for MTP
"depth": 2,
"n2": [1337, 9001, 7, "..."]
// second-next token labels
},
"attn_mask": "...",
"position_ids": "...",
"doc_spans": [
{"doc_id":"01J...W0N","start_tok":0,"end_tok":2500},
{"separator":"<eod>"},
{"doc_id":"01J...9KX","start_tok":100,"end_tok":5600},
{"separator":"<eod>"},
{"doc_id":"01J...2Q3","start_tok":0,"end_tok":92}
],
"tags": ["web","math","code_block_present"],
"mix_weight": 0.85, // used by sampler
"long_context_bucket": 0 // e.g.,
0:8k, 1:32k, 2:128k
}
|
预训练:捏塑黏土
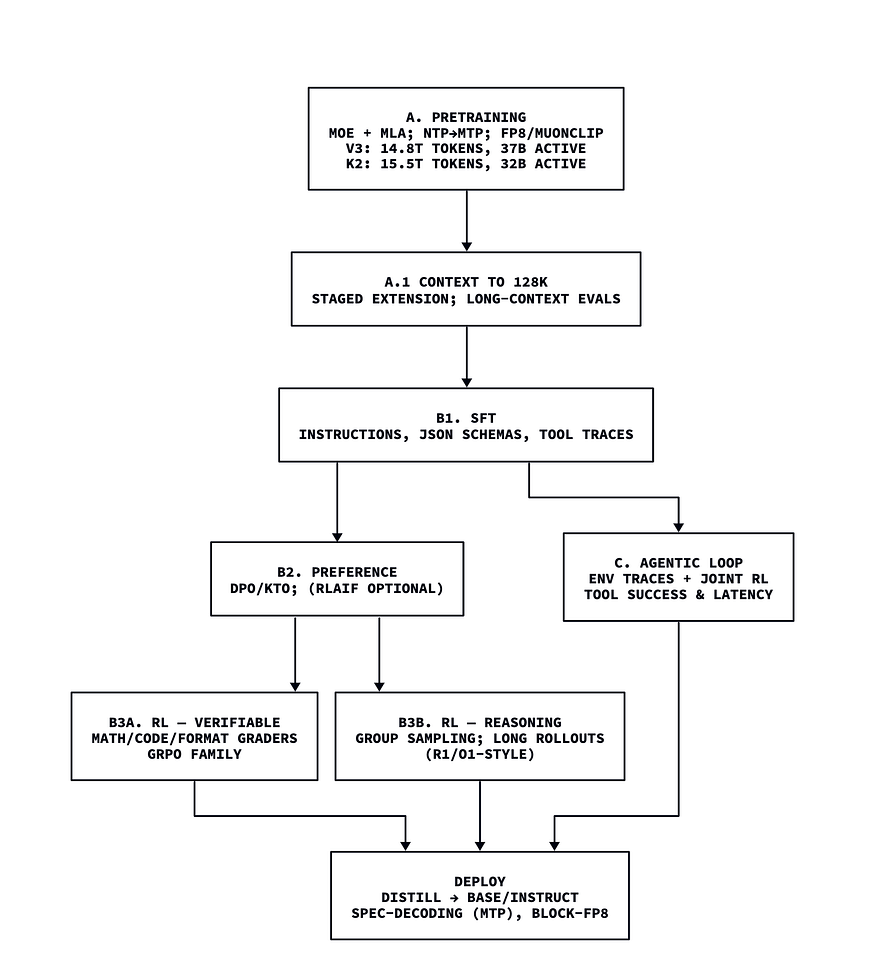
我们将通过两个公开预印本案例(DeepSeek 与 Kimi),解析预训练实践。
案例 1:DeepSeek-V3
DeepSeek V3 是6710 亿参数的 MoE 模型,每 token 激活约 370 亿参数。其核心技术特点包括:
MLA 注意力:减少键值对(KV)内存占用,提升内存 / 延迟效率;
无辅助损失的负载均衡(aux-loss-free load balancing);
FP8 混合精度训练:在超大规模下验证稳定性。
该模型的预训练数据量达 14.8 万亿 token;通过架构与工程协同优化,端到端训练总成本(含预训练、上下文扩展、训练后阶段)约为
278.8 万 H800 GPU 小时。
案例 2:Kimi K2
Kimi K2 是1.04 万亿参数的 MoE 模型,每 token 激活约 320 亿参数。其技术亮点包括:
同样采用 MLA 注意力:提升内存效率;
384 个专家节点:每 token 选择 8 个专家激活;
128K 上下文窗口:原生支持长文本处理。
Kimi K2 的预训练数据量为 15.5 万亿 token,通过MuonClip(Muon + QK-Clip)
机制消除万亿参数 MoE 训练中的损失尖峰,并将 “token 效率” 作为核心缩放系数。
与 DeepSeek V3 不同,Kimi K2 的训练后阶段明确聚焦 “智能体能力”:通过大规模工具使用数据合成,在真实与模拟环境中进行联合强化学习。
上下文扩展:应对 “感官过载”
我曾在之前的文章中提到,DeepSeek V3 架构的注意力机制采用旋转位置编码(RoPE) ,用于传递
token 位置的相对信息 —— 这种位置编码是模型区分 “相同 token 在不同输入位置” 的关键。
但 “基于相对距离的训练机制” 也带来一个问题:若输入文本长度超出训练时的最大长度,模型将无法可靠地关注超出范围的文本。
这一问题通过上下文扩展(Context Extension) 解决,可理解为一种 “训练课程”:模型先从短序列(如
8K token)开始学习,再逐步调整以处理更长序列(16K、32K token 及以上)。
前沿模型通常通过 “分阶段课程”(从短到长)扩展至 128K 及更长上下文,过程中需调整位置编码
/ 注意力机制,并通过 “针测试(needle test)” 避免长序列性能退化。DeepSeek
V3 技术论文提到,其上下文扩展分两阶段:从 8K 到 32K,再到 128K。
Kimi K2 则是一个反例:截至 2025 年 7 月,其技术论文显示,通过
MLA、长序列 RoPE 与 MuonClip,可实现 “128K 上下文原生训练”,无需分阶段扩展。这一一年内的训练创新,可能使此前的长上下文预训练范式过时。
训练后微调:雕琢细节
模型的 “行为特性” 正是在 “训练后阶段” 形成的。训练前,模型只是一个 “文本续写工具”,能 autoregressive(自回归)生成文本、预测下一个
token;训练后,通过监督学习与强化学习,可强制模型形成训练数据中未包含的行为 —— 指令遵循、对话角色扮演、推理、工具使用等能力均在此阶段涌现。
1. 监督微调(SFT)
SFT 本质是 “在精选对话与演示数据上进行教师强制(teacher-forced)的下 token
预测”。其 “奖励” 是隐性的:通过最小化 “期望输出 token” 的交叉熵损失,让模型生成与示例数据完全一致的文本时获得最大奖励。
通过以下方式控制模型的学习方向:
标签掩码
:指定哪些 token 需要标注(如按角色 / 字段掩码损失);
模式频率
:调整特定模式的出现频率(如混合权重、训练课程);
格式约束
:通过数据构建时的验证器,严格强制格式合规。
具体实践中,需将对话序列化为 token,并仅对 “希望模型模仿的部分” 计算损失 —— 通常是助手回复(及工具调用时的函数调用对象),而非用户文本或原始工具输出。
SFT 通常从指令微调开始:这是 SFT 的核心环节,目标是让模型具备 “助手属性”,遵循用户指令与系统提示。指令微调的
SFT 输入数据格式如下:
{
"id": "sft-0001",
"system": "You are a concise
assistant.",
"messages": [
{"role": "user", "content":
"Explain dropout in one paragraph."},
{"role": "assistant", "content":
"Dropout randomly zeros units ..."}
],
"loss_mask": {
"assistant": true, // label these
tokens
"user": false // don't compute loss
here
},
"tags": ["instruction",
"science.explain", "concise"]
}
|
训练时,结构化数据会被序列化为单一 token 序列,并对 “用户 token” 施加掩码 —— 让模型在对话中模仿助手的行为模式。
ChatML 风格的单字符串对话模板如下:
<BOS>
<|system|>
You are a concise assistant.
<|eot|>
<|user|>
Explain dropout in one paragraph.
<|eot|>
<|assistant|>
Dropout randomly zeros units ...
<|eot|>
|
需注意,“监督微调” 的命名源于:我们通过 “未掩码 token” 明确提供标签,要求助手生成与标签完全一致的
token,以最小化损失函数。
2. 偏好优化(低成本、稳定控制)
直接偏好优化(DPO) 是一种基于偏好的训练后方法,其学习目标是 “比较结果优劣”,而非 “学习标准答案”。
对每个提示,需提供 “优选回复(chosen)” 与 “弃选回复(rejected)”。训练目标是:让模型的策略(policy)下,优选回复的概率高于弃选回复
—— 且这一概率差需相对于 “固定参考策略(通常是 SFT checkpoint)” 有所扩大。此过程无需
Critic / 奖励模型,也无需 PPO 循环,仅依赖一个稳定的离线目标函数。
与 SFT“教模型‘说什么’” 不同,DPO“教模型‘哪类表达更好’”(如语气、安全性、简洁性、格式准确性)。其优势在于低成本、鲁棒性强、迭代高效。
由于稳定性、灵活性与成本优势,现代训练栈通常会在(或替代)完整的人类反馈强化学习(RLHF)前,优先使用
DPO(或其二元替代方案 KTO)。
DPO 的输入数据格式如下(每个样本):
{
"id": "dpo-00421",
"prompt": "<BOS>\n<|system|>\nYou
are a concise assistant.\n<|eot|>\n<|user|>\nExplain
dropout in one paragraph.\n<|eot|>\n",
"chosen": "<|assistant|>\nDropout
randomly masks units ... (clear, concise)\n<|eot|>\n",
"rejected": "<|assistant|>\nDropout
is a technique that was first... (rambling /
off-spec)\n<|eot|>\n",
"meta": {"reason": "conciseness/style",
"source": "human_label"}
}
|
可见,DPO 基于指令微调的基础 —— 提示词采用模型已理解的 ChatML 序列化格式。
以下 Python 伪代码进一步拆解 DPO 的实现逻辑:
import torch
import torch.nn.functional as F
# This is pseudocode, but require that these
exist for a real implementation:
# - dpo_loader: yields batches with fields
.prompt_ids, .chosen_ids, .rejected_ids, .assistant_mask
# - policy: trainable model (θ)
# - reference_policy: frozen reference model
(θ_ref), typically the SFT checkpoint
# - seq_logprob(model, prompt_ids, response_ids,
mask, length_normalize=True): returns
# the sequence log-prob over ONLY the masked
assistant tokens (optionally length-normalized)
beta = 0.1 # strength of preference separation
for batch in dpo_loader:
prompt_ids = batch.prompt_ids # [B, T_prompt]
chosen_ids = batch.chosen_ids # [B, T_answer]
rejected_ids = batch.rejected_ids # [B, T_answer]
assistant_mask = batch.assistant_mask # [B,
T_answer] bool (loss only on assistant tokens)
# --- Sequence log-probs under the current
policy (θ) ---
logp_chosen = seq_logprob(policy, prompt_ids,
chosen_ids, mask=assistant_mask)
logp_rejected = seq_logprob(policy, prompt_ids,
rejected_ids, mask=assistant_mask)
# --- Sequence log-probs under the frozen
reference (θ_ref) ---
logp0_chosen = seq_logprob(reference_policy,
prompt_ids, chosen_ids, mask=assistant_mask).detach()
logp0_rejected = seq_logprob(reference_policy,
prompt_ids, rejected_ids, mask=assistant_mask).detach()
# --- DPO margin: encourage policy to widen
the chosen-vs-rejected gap relative to the
reference ---
margin_current = (logp_chosen - logp_rejected)
# under θ
margin_reference = (logp0_chosen - logp0_rejected)
# under θ_ref (no grad)
z = beta * (margin_current - margin_reference)
# Numerically stable: -log σ(z) == BCEWithLogits(z,
target=1)
loss = F.binary_cross_entropy_with_logits(z,
torch.ones_like(z))
# Standard optimizer step
policy.zero_grad(set_to_none=True)
loss.backward()
torch.nn.utils.clip_grad_norm_(policy.parameters(),
max_norm=1.0) # optional but helpful
for p in policy.parameters():
if p.grad is not None and torch.isnan(p.grad).any():
raise RuntimeError("NaN in gradients")
policy.optimizer.step()
|
对每个样本,训练中的模型会因以下行为获得最大奖励:
生成与 “优选回复” 完全一致的文本;
不生成与 “弃选回复” 一致的文本;
生成风格与 “初始参考模型(指令微调后的 SFT checkpoint)” 无过大偏差。
经过足够多样本训练后,新模型 checkpoint 会 “遵循用户偏好” 而非 “仅模仿监督训练数据”,同时保留指令微调习得的核心行为。
通常,融入用户输入对 “打造开放场景下的实用助手” 至关重要 —— 因为指令微调数据集往往是团队内部合成或开源研究的
“预制对话”,而用户输入能让模型更贴合真实需求。
3. 强化学习(RL)
现代训练栈中,强化学习主要应用于两类场景:
可验证目标任务
(数学 / 代码 / 格式):通过自动评分器评估输出;
长程推理任务
(o 系列 / R1 风格):优化推理过程。
为提升效率,两者通常采用 “组相对策略优化(GRPO)” 家族的方法 —— 无需完整的近端策略优化(PPO)+
价值函数循环,而是通过 “无 Critic 的组相对更新” 实现。
(1)组相对策略优化(GRPO)
GRPO 的核心是 “让模型在自身生成的候选答案中自我评估”—— 通过奖励函数实现,无需提供特定标签。
与 PPO 不同,GRPO 无需单独的 Critic 模型评估性能:先让模型生成多个候选答案,通过自动检查器评分,对得分最高的答案给予奖励。检查器通常是
“作用于生成文本的函数”,例如检查 “是否包含精确答案”“是否通过单元测试”“是否符合数据格式”,有时也会加入
“长度 / 延迟惩罚” 等负奖励。
GRPO 的关键技巧是 “组内相对评分”:候选答案的得分在组内归一化,可 “免费” 获得低方差的优势信号(advantage
signal)。无需额外 LLM 计算,因此相比 PPO 大幅降低计算成本。
PPO 风格的裁剪步骤(clipping)可将更新限制在 “信任域(trust region)”
内;序列级、长度归一化的对数概率确保 “整个生成过程” 而非 “仅最后 token” 获得奖励。最终形成一个简洁稳定的可扩展循环:增大组大小可提升信号清晰度,模型会逐步向
“持续通过检查器” 的输出靠拢。
以下 Python 伪代码帮助理解 GRPO 的具体逻辑:
# Hyperparams
group_size = 8 # K
clip_epsilon = 0.2
temperature = 0.8
top_p = 0.95
for prompt in prompt_batch:
# 1) Propose K candidate completions from
the *old* policy
candidates = sample_candidates(old_policy,
prompt, group_size,
temperature=temperature, top_p=top_p)
# 2) Score each candidate with your programmatic
reward function
rewards = [compute_reward(prompt, completion)
for completion in candidates]
# 3) Group-relative advantages (z-score
within the K samples)
advantages = zscore(rewards) # (r_i - mean)
/ (std + eps)
# 4) Policy-gradient update with PPO-style
clipping (sequence-level, length-normalized)
for completion, advantage in zip(candidates,
advantages):
logprob_new = sequence_logprob(policy, prompt,
completion,
mask="assistant", length_normalize=True)
logprob_old = sequence_logprob(old_policy,
prompt, completion,
mask="assistant", length_normalize=True).detach()
likelihood_ratio = torch.exp(logprob_new
- logprob_old)
loss += -torch.clamp(likelihood_ratio, 1 -
clip_epsilon, 1 + clip_epsilon) * advantage
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 5) Trust-region bookkeeping (standard
PPO-style: refresh the old policy)
old_policy.load_state_dict(policy.state_dict())
|
(2)可验证奖励强化学习
若能编写 “自动判断答案是否‘正确’的程序”,便可低成本、安全地规模化 RL。通常,万亿参数的前沿模型需数百万样本、数亿次尝试(“候选轨迹”)、万亿
token 生成量,才能显著改变行为 —— 这意味着 “人工检查每个训练轨迹” 完全不可行。“可验证奖励”
的核心是 “通过自动化方式判断模型模拟任务的完成情况”。
与 SFT/DPO(纯离线训练)不同,RL 任务由 “提示词 + 评分器” 构成:每个样本包含 “任务提示”(如完成任务、解决问题),其结果可通过程序验证。
代码任务:生成的函数需通过单元测试、代码检查等程序化验证;
数学任务:答案中需包含特定表达式(如方程、引理、证明解释)的精确匹配。
以下为数学与代码任务的最小 JSON 样本示例:
数学任务
{
"id": "rl-math-0007",
"prompt": "<BOS>\n<|system|>Answer
with just the number.<|eot|>\n<|user|>What
is 37*91?<|eot|>\n",
"rewarders": [
{"type": "exact_answer",
"target": "3367"},
{"type": "format_regex",
"pattern": "^[0-9]+$"},
{"type": "length_penalty",
"alpha": 0.001}
]
}
|
代码任务
{
"id": "rl-code-1031",
"prompt": "<BOS>\n<|system|>Write
a Python function solve() that reads stdin and
prints the answer.<|eot|>\n<|user|>Given
N, output the sum 1..N.<|eot|>\n",
"rewarders": [
{"type": "unit_tests", "tests":
["tests/sum_to_n_*.txt"], "timeout_ms":
2000},
{"type": "runtime_penalty",
"beta_ms": 0.0005},
{"type": "format_regex",
"pattern": "def solve\\("}
],
"sandbox": {"image": "py3.11",
"mem_mb": 512}
}
|
奖励函数是 “作用于生成文本的程序”,目标是 “对符合人类预期的结果给予高奖励,对偏离预期的结果施加惩罚”。
需注意:模型对齐(model alignment) 研究的核心正是 “奖励函数与预期行为的匹配度”。实现
“真正对齐” 往往颇具挑战 —— 模型可能通过 “奖励黑客(reward hacking)” 获取高奖励,却未真正符合人类预期。例如:
数学任务中,模型仅记忆公式却不展示推导过程;
代码任务中,函数仅 “刚好通过单元测试”,但缺乏工程鲁棒性(如未处理边界情况)。
(3)链式推理强化学习(o 系列 / R1 风格)
要优化 “长程问题的最终正确性”(及基础格式约束),需让模型将 “深度内部计算” 内化为核心行为。实现方式是:仅对
“最终正确性” 给予奖励,让 LLM 自主学习复杂问题的结构化推理模式。
推理微调是 “可验证奖励 RL” 的子集 —— 不针对 “分步行为” 给予奖励,仅提供 “最终正确性信号”。这一阶段相当于
“撤去训练轮”:模型需自主学习 “如何到达最终奖励”,而非依赖分步指导。
通常会增加两个优化方向:
语言 / 格式奖励
:例如 “用英文回答;最后一行以‘Final Answer: ...’结尾”;
过程塑造(可选)
:对 “通过中间检查” 的行为给予小额奖励(如子目标完成、无工具推导),但推理时不暴露分步解决方案。
DeepSeek 的 R1 模型证明:基于 “强预训练基础”(无 SFT 冷启动)的纯推理 RL,可激发长程推理能力。后续团队通过
“小规模 SFT + 再一轮 RL” 优化模型,并将 R1 的推理能力蒸馏回对话模型。OpenAI
的 o1 系列模型也以 “大规模推理 RL” 为核心,强化隐性链式推理能力。
以下为 GRPO 框架下 CoT 训练的样本示例:
{
"id": "rl-reason-2203",
"prompt": "<BOS>\n<|system|>Provide
only the final numeric answer after thinking.\n<|eot|>\n<|user|>If
f(x)=..., compute ...<|eot|>\n",
"rewarders": [
{"type":"equality_modulo","target":"(2*sqrt(3))/5"},
{"type":"format_regex","pattern":"^Final
Answer: "},
{"type":"language","lang":"en",
"gamma": 0.05}
],
"sampling": {"K": 8, "temp":
0.9}
}
|
可见,其 schema 与 “可验证奖励 RL” 相似,但任务难度更高 —— 需模型通过 “内部逻辑”
自主推导最终答案。在可验证奖励场景中,模型可能 “直接生成答案而不推理”;但推理训练的目标是 “设计非标准长程任务”,迫使模型通过
“推理独白” 获取奖励。LLM 从未被 “明确教授如何生成推理过程”,但为了在这类任务中获得奖励,推理过程会自然涌现。
这类任务的数据集需更精细的筛选,且模型每样本生成的 token 量通常远多于 “可验证奖励数据集”。
需注意:你可能已发现 “推理 RL” 与 “可验证奖励 RL” 的诸多相似性。超对齐(superalignment)
研究的一个分支正是 “不可验证奖励”—— 即如何为 “新颖发现与推理” 设计奖励,而这类任务无法通过简单程序验证。要在数亿次轨迹中为数百万样本实现这一目标,现有方法仍存在显著局限,这也是当前训练后研究的前沿方向。
让 LLM 与现实世界交互:工具使用
“工具使用对齐” 的核心工作发生在 RL 之前:先教会模型 “格式与轨迹”,再通过强化学习优化细节。
首先需在 SFT 阶段植入 “工具使用直觉”:添加 “需生成特定工具调用格式(通常为 XML 或
JSON)” 的样本,并在对话中新增 “工具角色”,用于捕获工具的现实反馈。
总体目标是:让模型学会 “生成符合格式的结构化输出”,以与环境中的程序、集成系统或代码(即 “工具”)交互,并让这一能力泛化到
“任意工具与格式”。通过指令微调,模型需能基于 “用户自定义提示”,遵循特定业务场景的工具格式要求。
以下为 “外汇汇率查询” 工具的 SFT 样本示例(JSON 格式):
{
"id": "sft-tool-0219",
"system": "You can call tools.
Prefer JSON answers.",
"tools": [{"name":"fx.lookup","schema":"fx.lookup.input_schema"}],
"messages": [
{"role":"user","content":"What's
the EUR→CAD rate right now?"},
{"role":"assistant","tool_call":{"name":"fx.lookup","arguments":{"base":"EUR","quote":"CAD"}}},
{"role":"tool","name":"fx.lookup","content":{"rate":1.47,"timestamp":"2025-08-09T10:22:01Z"}},
{"role":"assistant","content":"{\"pair\":\"EUR/CAD\",\"rate\":1.47}"}
],
"loss_mask": {
"assistant.tool_call": true, // learn
name+args JSON
"assistant.text": true, // learn final
summary/JSON
"user": false,
"tool.content": false // don't memorize
raw tool output
}
}
|
该样本会被序列化为以下格式,模型需精确学习 “助手消息” 的生成:
<BOS>
<|system|> You can call tools. Prefer
JSON answers. <|eot|>
<|user|> What's the EUR→CAD rate right
now? <|eot|>
<|assistant|><|tool_call|>{"name":"fx.lookup","arguments":{"base":"EUR","quote":"CAD"}}<|eot|>
<|tool|><|fx.lookup|>{"rate":1.47,"timestamp":"2025-08-09T10:22:01Z"}<|eot|>
<|assistant|>{"pair":"EUR/CAD","rate":1.47}<|eot|>
|
随后,通过 “沙盒环境中的 GRPO 强化学习” 优化细节:
{
"id": "rl-tool-0817",
"prompt": "<BOS>\n<|system|>Use
tools only if needed. Respond in JSON.\n<|eot|>\n<|user|>What's
the current EUR→USD rate?\n<|eot|>\n",
"tools": ["fx.lookup"],
"environment": {
"sandbox": "http",
"rate_limits": {"fx.lookup":
5},
"secrets_policy": "none_leak"
},
"rewarders": [
{"type":"tool_success",
"name":"fx.lookup", "checker":"value_in_range",
"range":[1.3,1.7], "weight":1.0},
{"type":"schema_valid",
"target":"assistant_json",
"weight":0.2},
{"type":"latency_penalty",
"beta_ms":0.0003},
{"type":"no_op_penalty",
"delta":0.1}, // punish unnecessary
calls
{"type":"arg_semantics",
"rule":"base!=quote", "weight":0.2}
],
"limits": { "max_calls":
2, "max_tokens": 512 }
}
|
工具使用 RL 的最大挑战是 “为现实工具调用场景设计清晰可验证的奖励”—— 这并非总能实现。因此,奖励函数数量需增加,以
“约束模型行为”,使其符合人类对 “现实环境集成” 的预期。
现实世界的复杂性导致 “奖励黑客路径” 远多于 “合法完成路径”—— 用户常观察到模型的 “角色扮演式工具使用”:模型学会
“非真实路径获取奖励”,却未准确表达核心逻辑与环境约束。
这正是训练后研究的前沿:领域仍存在大量未知。个人观点是,AI 能力的下一次突破不会来自 “更多计算资源或预训练规模”,而在于
“持续优化训练后流程”—— 避免奖励黑客,引导模型通过 “对齐的真实路径” 获取奖励。
案例研究 1:DeepSeek-V3 的 RL 与蒸馏
DeepSeek-V3 是6710 亿参数 MoE 模型,每 token 激活约 370 亿参数,核心架构围绕
“多头 latent 注意力(MLA)” 设计,以实现内存高效的上下文处理,并采用 “多 token
预测(MTP)” 目标。MTP 的关键价值在于:模型可预测连续两个 token;投机解码时,第二个
token 的接受率约 85-90%,这意味着推理时的 token 生成速度可提升约 1.8 倍,且无质量损失。可类比为
“合法‘预判’未来 token,并兑现大部分收益”。
规模上,V3 的预训练数据量达 14.8 万亿 token,端到端训练总成本约 278.8 万 H800
GPU 小时(已包含长上下文扩展与训练后阶段)。训练栈采用 FP8 混合精度,在超大规模训练中平衡成本与稳定性。这并非简单
“调大参数”—— 论文强调 “训练稳定性”(无不可恢复的损失尖峰)与 “清晰的基础设施方案”,这是实现超大规模训练的关键。
训练后阶段是 V3 “个性与推理能力” 的来源:团队先进行监督微调与强化学习,再将 R1 系列模型的推理能力蒸馏回对话模型。具体流程是:直接在预训练基础模型上通过
RL 强化推理(无 SFT 冷启动),再将这些能力压缩回基础模型 —— 通过 “RL 优化基础模型→更优基础模型支持更复杂
RL” 的迭代循环,实现能力持续提升。
案例研究 2:Kimi K2 的智能体工具使用
Kimi K2 的定位是 “智能体模型”,而非纯对话模型。其底层是1.04 万亿参数 MoE,每 token
激活约 320 亿参数,采用 MLA 注意力;架构通过 “稀疏性优化” 平衡吞吐量与性能 —— 专家节点总数增至
384 个(每 token 激活 8 个),注意力头数减至 64 个(相较于 V3),这一权衡在 “稀疏性缩放律”
下可降低吞吐量损失,同时改善验证损失。K2 的原生上下文窗口为 128K token。
K2 的核心创新是MuonClip:结合 Muon 机制与 QK-Clip(查询 / 键投影重缩放),避免注意力
logit 爆炸,使其能在 15.5 万亿 token 上完成预训练,且无损失尖峰。若你曾经历过 “万亿规模训练因少量注意力头异常导致崩溃”,便知这一务实优化的价值
—— 既保留 Muon 的 token 效率,又确保训练稳定。
训练后阶段的核心是 “规模化工具使用”:
构建大规模 “合成 / 真实智能体数据集” 流水线,生成工具规范、多轮轨迹、评分标准;
应用 “联合 RL”:结合 “可验证奖励”(调用是否成功?JSON 是否合规?)与 “自我评估标准”,塑造静态轨迹无法覆盖的行为。
团队还公开了 “函数调用 token 模板”,并描述了 “约束解码器(enforcer)”—— 可确保生成时的工具调用严格符合声明格式,这对
“解决工具调用格式脆弱性” 极具参考价值。
最终,K2 的交付形态接近产品级:开源了基础模型与指令微调模型的 checkpoint(块 FP8
格式),并提供 vLLM、SGLang、TensorRT-LLM 的部署示例,缩短了 “验证 / 生产部署”
的路径。若现有技术栈支持 OpenAI/Anthropic 风格 API,其仓库还提供了兼容性细节与温度参数映射方案。
一页可视化总结
总结
若将 LLM 比作雕塑,预训练是 “捏塑黏土基础”,训练后微调是 “雕琢细节与赋予个性”。构建 LLM
绝非易事:需充足资源、数据访问权限、计算能力与人力投入。
LLM 训练的完整流程可概括为:
从多源(网页、代码、百科、书籍)采集多样化数据;
进行质量校验与预处理,组装为带标注的片段;
预训练阶段:通过自回归自监督学习,赋予模型语言建模能力;
监督微调阶段:通过指令微调,赋予模型对话与工具使用行为;
强化学习阶段:通过可验证奖励(如数学、代码)优化性能;
推理强化学习阶段:聚焦 “最终结果”,强化复杂推理与高级工具使用能力。
通过 “迭代循环 + 蒸馏优化基础模型”,可实现 LLM 行为的持续改进与细化。
尽管流程复杂,仍存在显著局限:
奖励黑客普遍存在
:超大规模下,数百万样本的鲁棒监督难以实现。我们依赖 “可验证奖励” 塑造复杂行为,但现实世界中 “人类预期的低可量化任务”
仍大量存在,模型在这些任务中的表现往往不佳。
长程任务的推理一致性问题
:通过 “最终结果奖励” 强制推理时,模型未必采用 “逻辑一致的推理路径”。尽管 “链式推理” 是常见涌现模式,但研究显示(参考此处与此处),CoT
推理在 “分布外任务” 中易失效 —— 推理可能陷入循环、逻辑流程不一致,甚至 “通过错误理由得出正确结论”,而超大规模训练中难以全面评估这类问题。
不可验证奖励的挑战
:要让模型 “拓展人类知识边界”,需为 “新颖发现与推理” 设计奖励。但在数亿次轨迹中为数百万样本实现这一目标,现有方法仍存在显著不足
—— 这是超对齐研究的活跃方向。
人类在智能机器开发上已取得巨大进展:仅几年前,“能处理多样化人类文本输入的对话机器人” 仍难以想象。前方的挑战是
“在大量次优代理模型中找到真正的对齐”。
当前 AI 用户的核心痛点是 “模型缺乏人类的‘求真意图’”—— 人类会 “深入探究问题本质,通过确凿证据验证解决方案”,而模型尚未具备这一特质。如何
“规模化定义奖励”,激励模型实现这一行为,仍是极具挑战性的课题。
令人振奋的是,现有架构已具备 “建模多模态输入与多语言文本” 的复杂能力 —— 这表明我们已达到
“实现突破的规模门槛”。后续工作需依赖 “人类智慧的持续探索”,通过创新逐步缩小 “万亿维空间中的搜索范围”,最终找到最优策略。
|







 订阅
订阅