| 编辑推荐: |
本文介绍了大模型入门知识Embedding相关内容。希望对你的学习有帮助。
本文来自于微信公众号智作工坊 ,由火龙果软件Alice编辑,推荐。 |
|
嵌入(Embedding)是一种固定长度的数值向量,可在连续向量空间中表示文本(词元、子词、单词、句子或文档),且语义相似的文本在向量空间中距离更近。嵌入维度因模型类型而异,常见维度包括256、512、768、1024、2048等。维度越大,可编码的语义细节越丰富,但会消耗更多CPU/内存资源,且向量索引规模也会增大
词元嵌入(Token Embeddings)
大模型的词汇表中,每个词元都对应一个嵌入向量。这是因为大模型基于深度学习构建,而深度学习系统需要接收连续的数组输入(以支持反向传播算法)。
以下是文本“I like spiking neural networks”的词元嵌入流程:
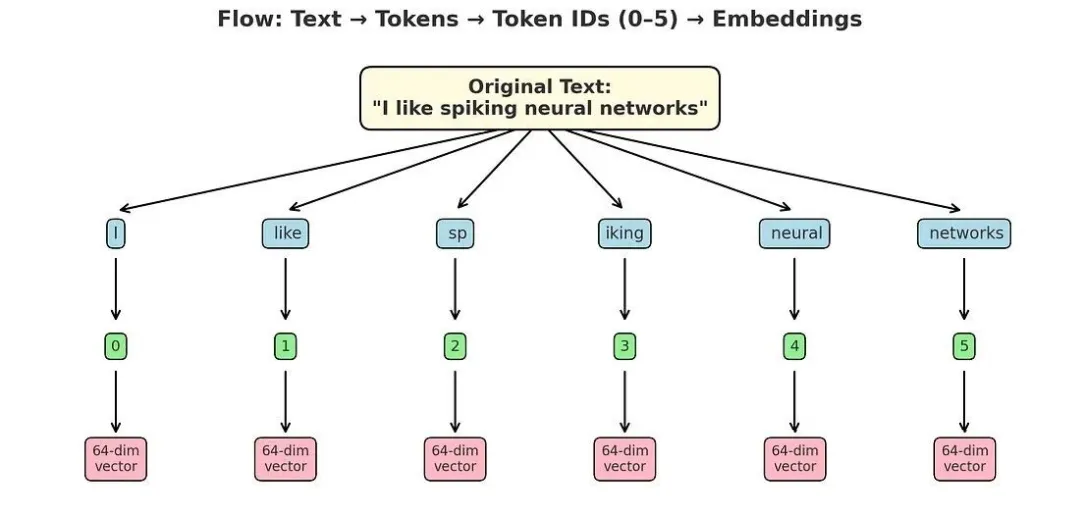
从流程中可看出,词元编号会被映射为64维向量,这些向量初始值为随机分配,该步骤标志着大型语言模型训练阶段的开始。以下为简易代码示例:
import torch
# 文本“I like spiking neural
networks”对应的简易词元编号
input_ids = torch.tensor([0,
1, 2, 3, 4, 5])
# 假设词汇表中仅包含上述6个词元
VOCAB_SIZE = 6
# 假设每个词元用64维向量表示
OUTPUT_DIMENSIONS = 64
# 在PyTorch中创建嵌入层
embedding_layer = torch.nn.Embedding(VOCAB_SIZE,
OUTPUT_DIMENSIONS)
print(f"嵌入层权重形状: {embedding_layer.weight}")
# 输出结果示例:
"""
Parameter containing:
tensor([[ 0.7002, 0.4290,
1.3862, -1.5815, 1.6330, -0.6623, 0.2679,
0.6456,
1.0483, 0.6294, -0.9557,
-0.5726, 1.0051, 0.2873, -0.9054, 0.3316,
-0.4677, -0.5486, -0.8192,
-2.0460, 1.5175, -1.5020, 0.9107, 0.1581,
-0.4463, 2.0166, -1.5837,
-1.7116, -0.6162, -0.9772, 0.4538, -0.3108,
0.9993, 2.3642, 1.0917, 0.5828,
-2.3568, -0.7938, 0.6395, 1.8878,
-0.5111, -1.3845, -1.1303,
-1.1223, -0.5168, 1.0638, 0.4835, 1.6578,
-1.1134, 1.0340, 1.5724,
-0.6231, -0.2462, -2.2726, 1.3705, -0.7802,
0.9564, 0.5715, -0.5970,
0.5837, 0.2946, -0.1596, -0.4342, -1.0636],
...])
"""
|
从上述代码可看出,我们创建了一个64维的随机值嵌入向量。这些随机值会在大模型的优化过程中逐步调整优化。
#
为词元生成嵌入向量
print(embedding_layer(input_ids))
# 输出结果示例:
"""
tensor([[-3.1833e+00, 2.3536e-03, 1.9959e-01,
2.1779e-01, 8.4182e-01,
1.3251e+00, 8.2953e-01, -1.7804e+00, -2.3302e-01,
-3.2135e-01,
2.4270e-01, 9.0952e-02, 1.5125e-01, -2.6915e-01,
4.2657e-01,
2.0562e-01, -5.5685e-01, -1.0964e+00, 5.7570e-01,
-1.3086e-01,
1.0584e+00, -9.4975e-01, -2.7249e-01, 5.5980e-01,
-5.2752e-01,
5.5470e-01, 1.0481e+00, -1.7590e-02, -1.8541e-02,
2.7386e+00,
-8.3513e-02, 4.4918e-01, -1.4070e+00, -2.4985e+00,
7.5528e-01,
...]])
"""
|
嵌入层的核心作用是查找(Lookup):从嵌入层的权重矩阵中,检索与词元编号对应的嵌入向量。词元嵌入是大型语言模型能够运行的关键基础。
位置嵌入(Positional Embeddings)
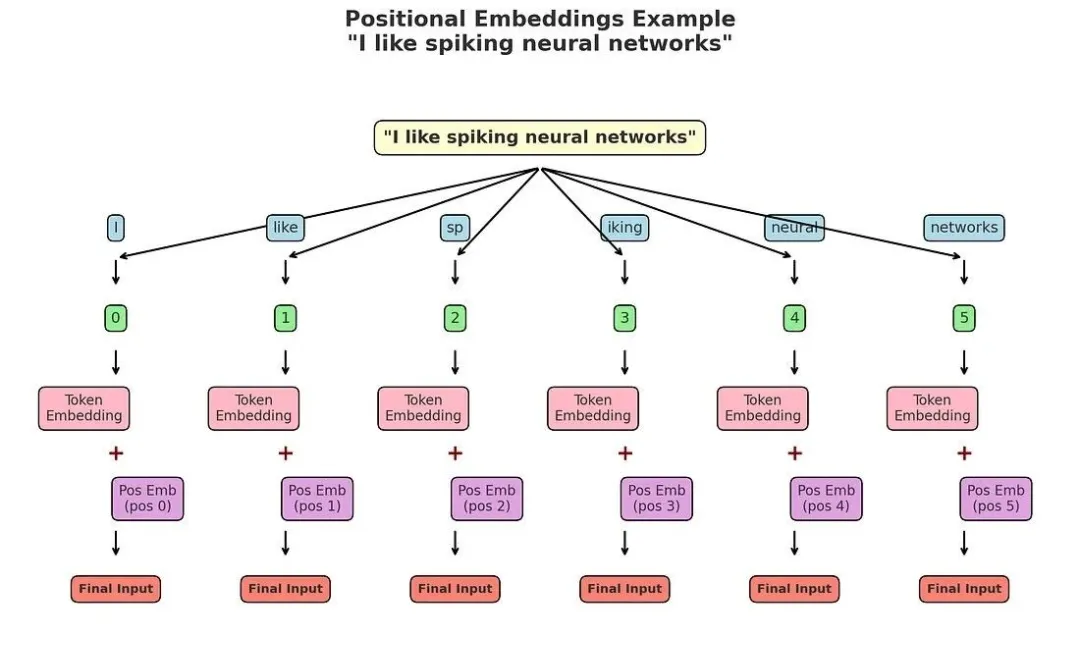
你可能会问:词元嵌入已经能正常工作,为何还需要额外的位置嵌入?
答案是:Transformer架构(如GPT模型)本身不具备识别单词顺序的能力。
对模型而言,“I”和“networks”仅是词元编号对应的嵌入向量。若不添加额外信息,“I like
spiking networks”与“networks spiking like I”在模型眼中会完全相同。
因此,我们需要添加位置嵌入向量:对于序列中的每个位置(0、1、2……),生成一个与词元嵌入维度相同的位置向量。最终输入到Transformer中的向量
= 词元嵌入向量 + 位置嵌入向量。
通过这种方式,模型既能识别“单词是什么”,也能识别“单词在句子中的位置”。
位置嵌入的两种类型:
1. 绝对位置嵌入(Absolute Positional Embeddings):为输入序列中的每个位置分配一个唯一的嵌入向量,并与词元嵌入相加,以传递单词的精确位置信息。该方式的优势在于:文本语义往往依赖于单词间的距离,而非仅依赖绝对索引。
2. 相对位置嵌入(Relative Positional Embeddings):不编码绝对位置,而是编码词元之间的相对距离。其核心优势是可泛化到训练阶段未见过的序列长度。例如,在文本“I
like spiking neural networks”中,“ sp”与“iking”两个词元关联性强,它们的相对距离得分(1)较小;而“I”与“
networks”关联性弱,它们的相对距离得分(5)较大。
GPT模型采用绝对位置嵌入,且会在大型语言模型的优化过程中对其进行调整——不同于原始Transformer模型中使用的固定位置嵌入。
绝对位置嵌入代码示例:
import
torch
import torch.nn as nn
# GPT风格的绝对位置嵌入模块
class GPTAbsolutePositionalEmbedding(nn.Module):
def __init__(self, vocab_size, embed_dim,
max_seq_len):
super().__init__()
self.token_embedding = nn.Embedding(vocab_size,
embed_dim) # 词元嵌入层
elf.position_embedding = nn.Embedding(max_seq_len,
embed_dim) # 位置嵌入层
def forward(self, input_ids):
batch_size, seq_len = input_ids.size()
# 生成词元嵌入向量,形状为(B, T, D),B=批量大小,T=序列长度,D=嵌入维度
tok_emb = self.token_embedding(input_ids)
# 生成位置编号(0到seq_len-1)
pos_ids = torch.arange(seq_len, dtype=torch.long,
device=input_ids.device)
pos_ids = pos_ids.unsqueeze(0).expand(batch_size,
seq_len) # 扩展为批量大小维度
# 生成位置嵌入向量,形状为(B, T, D)
pos_emb = self.position_embedding(pos_ids)
return tok_emb + pos_emb # 词元嵌入与位置嵌入相加
sentence = "I like spiking neural networks"
tokens = ["I", "like",
"sp", "iking", "neural",
"networks"]
# 简易词元编号
token_ids = torch.tensor([[0, 1, 2, 3, 4,
5]])
print("词元:", tokens)
print("词元编号:", token_ids.tolist())
# 定义简易嵌入层参数
vocab_size = 100 # 词汇表大小
embed_dim = 8 # 嵌入维度
max_seq_len = 10 # 最大序列长度
embedder = GPTAbsolutePositionalEmbedding(vocab_size,
embed_dim, max_seq_len)
# 前向传播(生成最终嵌入向量)
output = embedder(token_ids) # 输出形状为(1, 6,
8)
print("\n最终嵌入向量形状:", output.shape)
print("最终嵌入向量(词元嵌入 + 位置嵌入):")
print(output[0]) # 每个词元对应的最终嵌入向量
|
上述代码的输出结果如下:
"""
词元: ['I', 'like', 'sp', 'iking',
'neural', 'networks']
词元编号: [[0, 1, 2, 3, 4, 5]]
最终嵌入向量形状: torch.Size([1, 6,
8])
最终嵌入向量(词元嵌入 + 位置嵌入):
tensor([[ 0.1234, -0.5678,
... ],
[ 0.2345, -0.6789, ... ],
...
[ 0.5432, 0.1234, ... ]])
"""
|
文本嵌入(Text Embeddings)
目前,大多数大模型(LLM)可处理句子级、段落级乃至文档级的文本。这使得语言模型能够生成一种名为文本嵌入的输出,即一个可代表整个段落或文档语义信息的单一向量。
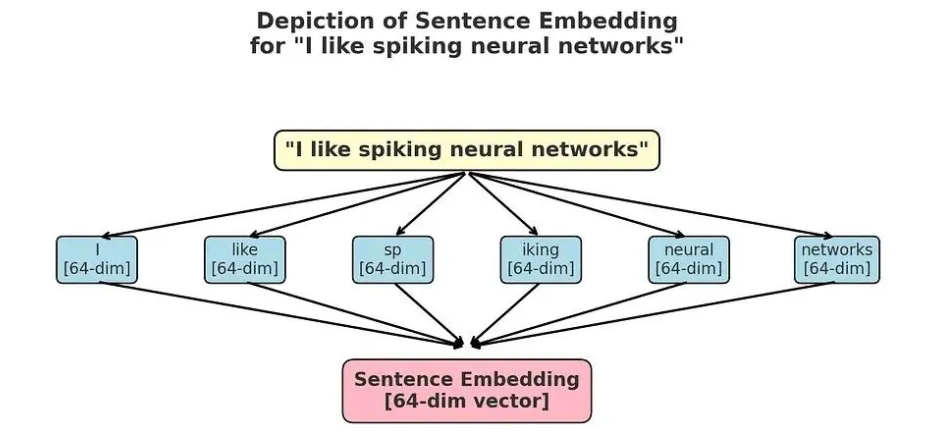
上图表明,生成句子嵌入(Sentence Embeddings)最简单的方法是对所有标记嵌入(Token
Embeddings)取平均值。
但如今,已有多款性能优异的文本嵌入模型,例如来自 sentence-transformers 库的系列模型。
from
sentence_transformers import SentenceTransformer
# 加载模型
model = SentenceTransformer("sentence-transformers/all-mpnet-base-v2")
# 将文本转换为文本嵌入
vector = model.encode("I like spiking
neural networks") # 中文释义:我喜欢脉冲神经网络
# 打印向量形状,向量维度会因模型不同而变化
print(f"向量维度为: {vector.shape}")
# 输出结果
"""
向量维度为: (768,)
"""
|
这类文本嵌入在语义搜索领域具有重要作用,可应用于检索增强生成(RAG,Retrieval Augmented
Generation)等场景。 |







 订阅
订阅