| 编辑推荐: |
本文介绍了大模型入门知识--注意力机制相关内容。希望对你的学习有帮助。
本文来自于微信公众号智作工坊 ,由火龙果软件Alice编辑,推荐。 |
|
GPT等生成式模型以文本为输入、文本为输出。从下图可见,该类模型不会一次性生成完整的输出结果,而是逐个生成token。
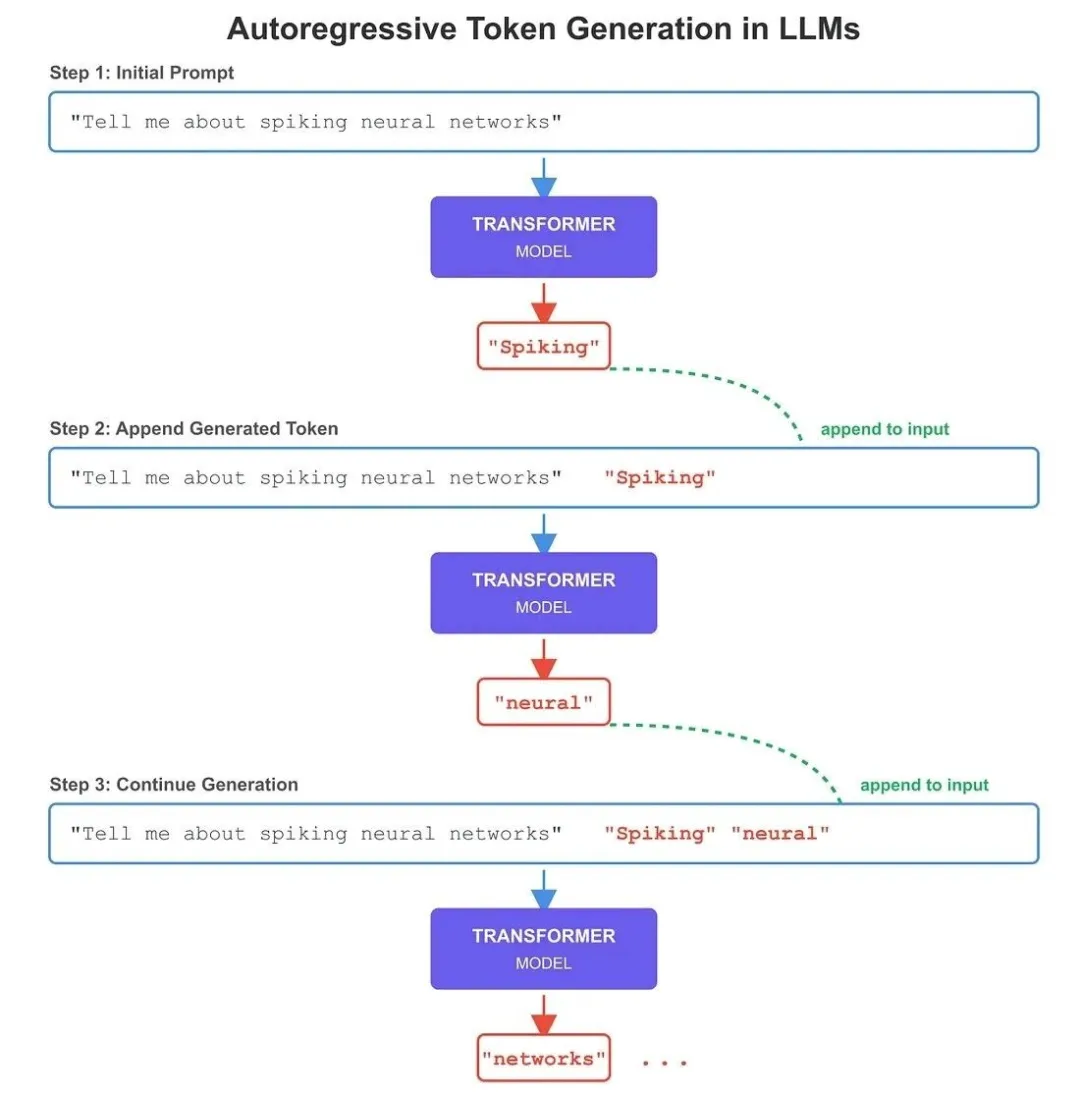
每生成一个token后,我们会将“此前生成的token”添加到“输入提示词末尾”,以此更新输入内容。这类利用“先前生成的token”来生成“新token”的模型,被称为自回归模型(以GPT系列为代表)。
接下来,我们拆解大语言模型的架构。从宏观层面看,大语言模型包含三部分:token解析器(Tokenizer)
、Transformer块(Transformer Blocks) ,以及名为语言建模头(LM Head)
的组件。

token解析器会将文本转换为嵌入向量(含“token嵌入向量”与“位置嵌入向量”),这些向量会在大语言模型的训练优化过程中同步优化。具体可参考下图。

若需深入了解token解析器与嵌入向量,可阅读之前的文章。
现在,我们深入探究Transformer块的内部结构——这是模型大部分数据处理工作的核心区域。每个Transformer块包含两大核心组件:自注意力组件(Self-Attention
Component) ,其后紧跟前馈神经网络组件(Feed-Forward Network Component)
。一个大模型中,此类Transformer块的数量最少为6个,最多可达上百个。
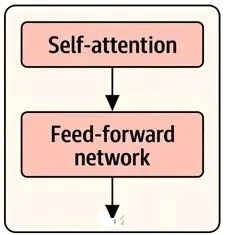
一、自注意力机制(Self-Attention)
自注意力组件的输入(可能是token解析器的输出,也可能是另一个Transformer块的输出;为便于理解,此处暂以“文本”和“单词”代指数学层面的输入)为单个单词,它会对自身提出一个问题:“要理解当前这个单词,我需要重点关注文本中的哪些其他单词?”
这种机制被称为“自注意力”,核心原因是每个单词都会关注文本中的所有其他单词。
为便于理解,我们先暂不考虑权重,拆解自注意力机制的基本逻辑:自注意力会通过“关注所有其他单词”并“融合其嵌入向量”,为每个单词生成一个上下文向量(Context
Vector) 。以下是“无可训练权重的自注意力”的实现步骤:
步骤1:生成嵌入向量

为文本“I like spiking neural networks”生成嵌入向量(示例中为3维的虚拟嵌入向量)。
步骤2:设定Q、K、V矩阵
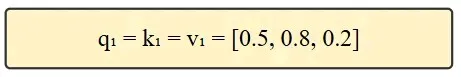
在无训练权重的场景下,设Q=K=V(Q=查询矩阵Query Matrix,K=键矩阵Key Matrix,V=值矩阵Value
Matrix),后续将进一步解释三者的作用。
步骤3:计算注意力得分

通过“当前单词的嵌入向量”与“所有其他单词的嵌入向量”进行点积运算(点积本质是“两个向量对应元素相乘后求和”),得到注意力得分。点积结果越高,说明两个单词的关联性越强;点积结果越低,说明关联性越弱。
此处,q(查询向量)代表当前单词(如示例中的“I”),k(键向量)代表所有单词的嵌入向量(包括当前单词自身,即“I”)。
此外,还可将点积结果除以“嵌入向量维度的平方根”进行缩放:在本示例的3维嵌入向量场景下,缩放作用不明显;但当嵌入向量维度超过1000时,缩放至关重要——若不缩放,下一步使用的softmax函数可能会生成接近0的值,影响模型效果。
步骤4:通过Softmax归一化注意力得分

对注意力得分应用Softmax函数,将其归一化为概率值(所有得分之和为1)。
这一步的核心作用是:明确“某个单词(如“spiking”)需要对另一个单词(如“neural”)投入多少注意力”。同时,Softmax函数能确保注意力权重始终为正值,使输出结果可解释为“概率”或“相对重要性”——权重越高,代表重要性越强。
步骤5:生成上下文向量

最终,通过“以注意力权重为权重,融合所有单词的值向量”,更新当前单词的表示:例如,“spiking”的新表示会融合所有其他单词的信息,这个输出结果就是上下文向量。
具体计算方式为:将“其他单词的嵌入向量”与“归一化后的注意力得分”相乘,再对所有结果求和。

关键特性:上下文向量的维度与输入嵌入向量的维度完全一致。
二、Q、K、V矩阵的核心作用
至此,你可能会疑问:Q(查询)、K(键)、V(值)三者的具体作用是什么?
1. Query(查询):代表模型当前试图理解的单词/令牌;
2. Key(键):每个单词/令牌都有对应的键向量,用于与查询向量匹配;
3. Value(值):代表单词/令牌的实际内容;
4. 匹配逻辑:当查询向量与某个键向量匹配时,模型会提取该键向量对应的“值向量”。
三、含可训练参数的自注意力机制
上述是“无任何可训练参数”的自注意力机制基础逻辑。在实际的Transformer块中,自注意力组件会使用可训练的Q、K、V投影矩阵——这些矩阵本质是“可学习的权重”,能将输入令牌的信息投影到三个不同的空间,从而实现注意力计算。
因此,同一个单词会生成三个不同的向量:Q(查询向量)、K(键向量)、V(值向量)。
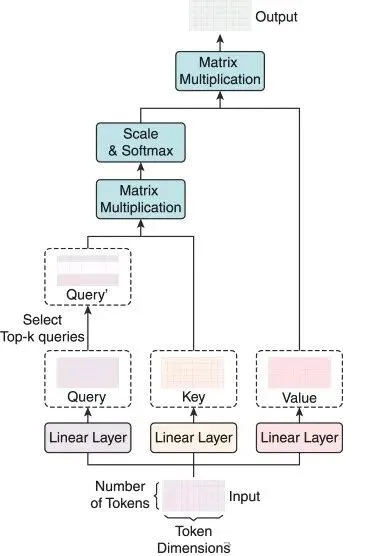
该架构与前文“无线性投影的自注意力”基本一致,区别仅在于:前文将投影矩阵设为“单位矩阵”(即Q=K=V,与输入嵌入向量完全相同),而实际架构中使用“可训练的线性投影矩阵”。
上图展示了Transformer块中“原始自注意力模块”的结构:
1. 首先计算Query矩阵与Key矩阵的点积;
2. 对结果进行缩放并归一化,得到注意力得分;
3. 将注意力得分与Value矩阵相乘并求和,最终输出包含丰富语义信息的上下文向量。
示例说明
以句子“I like spiking neural networks”(“我喜欢脉冲神经网络”)为例:
1. 若以“spiking”为查询向量(Query),它会通过“我需要哪些单词来定义自己?”的逻辑,与所有单词的键向量(Key)(I、like、spiking、neural、networks)进行匹配;
2. 匹配后,“spiking”与“neural”(神经)、“networks”(网络)的得分更高;
3. 因此,“spiking”的上下文向量会更多地融合“neural”和“networks”的值向量(Value)信息。
四、为何需要Q、K、V三个独立矩阵?
以多义词“bank”为例(可表示“银行”或“河岸”):
1. 当“bank”作为查询向量(Query)时,若要表达“银行”含义,需与“loan”(贷款)等单词的键向量匹配;
2. 当“bank”作为键向量(Key)时,需同时承载“银行”和“河岸”两种含义,以匹配不同场景的查询;
3. 若不区分Q、K、V,模型将失去这种“根据上下文灵活调整语义匹配”的能力。
此外,Q、K、V矩阵均为可训练参数,能将向量投影到不同的子空间:例如,查询向量(Q)可侧重“语义角色”,键向量(K)可侧重“语义关联”,值向量(V)可侧重“内容细节”——这种分工能大幅提升模型的表达能力。
结论:不区分Q、K、V的机制虽更简单、计算成本更低,但会失去Transformer模型核心的“强表达能力”,无法实现高效的语义理解与生成。
五、用Python代码直观理解自注意力机制
以下通过简洁的Python代码,复现含可训练参数的自注意力机制步骤:
import
torch
import torch.nn as nn
import torch.nn.functional as F
# 设置随机种子为25,确保结果可复现
torch.manual_seed(25)
"""步骤1:为文本生成嵌入向量"""
# 输入文本为“I like spiking neural networks”,嵌入向量维度设为4
# 张量形状:(序列长度=5, 嵌入维度=4)
X = torch.randn(5, 4)
print("输入嵌入向量:\n", X, "\n")
embed_dim = X.size(1) # 嵌入维度 = 4
d_k = d_v = embed_dim # 为简化计算,设键向量、值向量维度与嵌入维度一致
"""步骤2:初始化Q、K、V矩阵"""
# 初始化Q、K、V的权重矩阵
W_Q = torch.randn(embed_dim, d_k)
W_K = torch.randn(embed_dim, d_k)
W_V = torch.randn(embed_dim, d_v)
# 计算Q、K、V(通过输入嵌入向量与权重矩阵的矩阵乘法)
Q = X @ W_Q # 形状:(5, 4) @ (4, 4) → (5, 4)
K = X @ W_K # 形状:(5, 4)
V = X @ W_V # 形状:(5, 4)
print("查询矩阵Q:\n", Q, "\n")
print("键矩阵K:\n", K, "\n")
print("值矩阵V:\n", V, "\n")
"""步骤3:计算Query与Key的点积,得到注意力得分"""
# 计算注意力得分(Q与K的转置矩阵相乘)
scores = Q @ K.T # 形状:(5, 4) @ (4, 5) → (5,
5)
# 对得分进行缩放(除以键向量维度的平方根)
scores = scores / torch.sqrt(torch.tensor(d_k,
dtype=torch.float32))
print("原始注意力得分(Softmax前):\n", scores,
"\n")
"""步骤4:通过Softmax将注意力得分归一化为概率"""
# 应用Softmax函数,得到注意力权重(按最后一个维度归一化)
attn_weights = F.softmax(scores, dim=-1) #
形状:(5, 5)
print("注意力权重:\n", attn_weights,
"\n")
"""步骤5:注意力权重与Value矩阵相乘并求和,生成上下文向量"""
# 对值向量进行加权求和,得到上下文向量
context = attn_weights @ V # 形状:(5, 5) @ (5,
4) → (5, 4)
print("输出上下文向量:\n", context, "\n")
# 步骤5结束后,即可得到输入序列对应的上下文向量
|
| 






 订阅
订阅