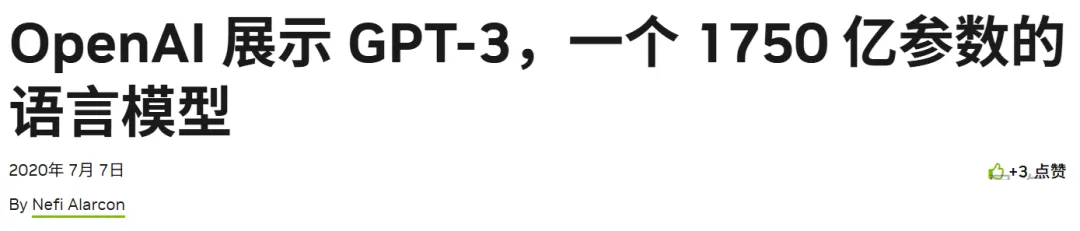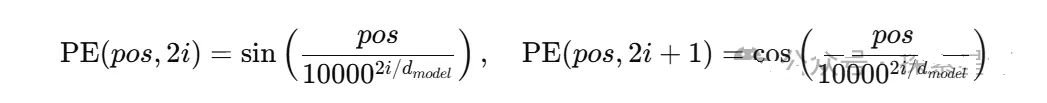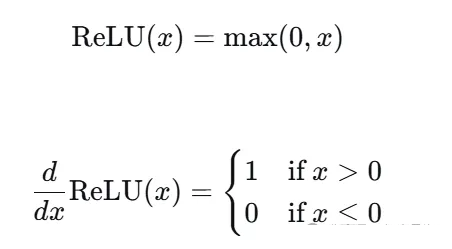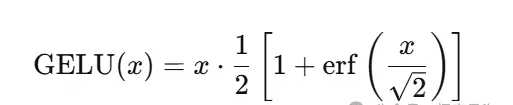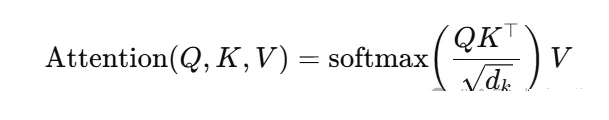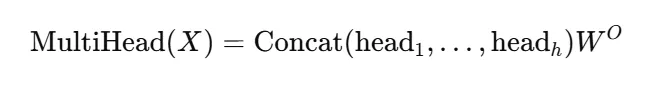| 编辑推荐: |
本文介绍了如何从零理解大语言模型(LLM)核心原理相关内容。希望对你的学习有帮助。
本文来自于微信公众号探索星海 ,由火龙果软件Alice编辑,推荐。 |
|
如果零散地看大语言模型的相关描述:有人说大模型是预测下一个词的模型,有人说大模型是将词转化为向量,有人说大模型运用了自注意力机制,还有人指出大模型采用无监督学习和强化学习……让人看得眼花缭乱。
这篇文章就把这些说法归归类,结构化地把大模型讲讲明白。
引言
当前几乎所有主流的大语言模型(LLM,Large Language Model)都基于 2017 年
Google 团队发表的一篇论文《注意力就是一切》(Attention Is All You Need)中提出的
Transformer 架构。像 GPT(Generative Pre-trained Transformer)这一类模型,则在训练流程上采用了「预训练
+ 微调」的范式,成为当代广泛使用的生成式模型家族。
多模态(Multimodal)是近年的热门方向,目标是让模型能够顺滑处理文本、图像、音频、视频等多种输入形式。本文主要讲解以文本为主的大模型基础原理,但这些底层机制在多模态模型中也是通用或可扩展的。
人工智能体(Artificial Intelligence Agent)指的是把大模型作为执行器,让它代替人类完成具体事务,而不只是聊天或给出建议。比如自动预订旅行的机票与酒店、搭建并部署可运行的网站、自动创作并发布自媒体内容等,这类是对底层模型的高级应用,但仍高度依赖底层模型提供的能力与接口。
大模型的本质
从产品角度看,豆包、DeepSeek、元宝等应用,或者基于它们背后模型的 API,都是大模型产品的不同呈现。
{
"model": "deepseek-chat",
"messages": [
{
"role": "system",
"content": "你是一个相声捧哏,请你不要让话掉在地上。"
},
{
"role": "user",
"content": "被门夹过的核桃,还能补脑吗?"
}
],
"temperature": 1,
"stream": false
}
|
(DeepSeek的API接口参数)
content:(一拍桌子)哎哟,这话说的,您这是跟核桃过不去啊!
|
(DeepSeek的API接口返回内容,部分结构已省略)
一个典型的大模型产品可以分为三层:底层的模型本身(海量参数)、中间的调用/服务框架(负责并行、分片、调度、缓存等),以及面向用户的上层应用界面(网页、App
或 API)。用户能看到的,一般只有最上层的界面。
从物理形态上讲,模型本身就是若干训练好的矩阵,矩阵元素是浮点数,这些参数在训练阶段被优化出来并保存在磁盘/内存中。
调用模型时,系统会把输入(文本或多模态信号)先转成数值向量,用一系列线性代数运算(矩阵乘法、激活函数、归一化等)与这些向量交互,最后把得到的向量再映射回人类可读的词或标记,形成输出。
大模型的原理
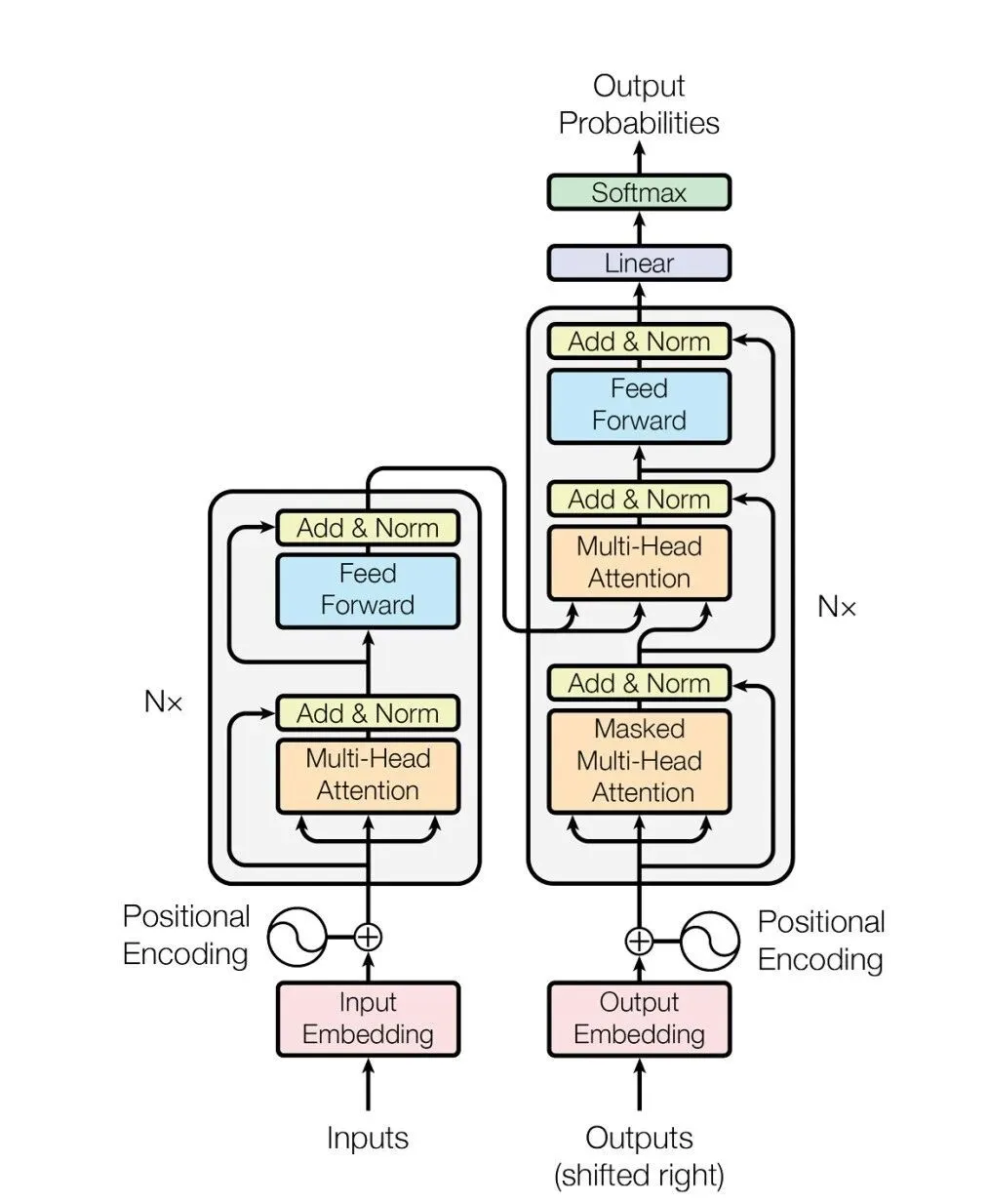
这是 Transformer 架构的原理图,我们从下往上重点关注输入(红)、注意力/解析(橙)与前馈/输出(蓝)三个部分。
1)词元输入
词元(Token)是大语言模型处理数据的基本单位。一句话在输入前会被分割为若干 token,且顺序被保留;模型接收到的就是这个有序
token 序列(例如“我比他更水”被输入成“我” -> “比” -> “他” ->
“更” -> “水”,而不会被输入成“他” -> “更” -> “我” ->
“水” -> “比”)。常见的计费单位“每百万 token”就是指这种 token 的数量。
早期的大语言模型,大多依赖卷积神经网络(CNN,Convolutional Neural Network)与循环神经网络(RNN,Recurrent
Neural Network),其缺点是无法在超大范围上理解和追溯词元之间的关联关系,但当序列长度增长到几百甚至几千时,RNN
在捕捉远距离依赖上会变弱,计算效率也受限。
Transformer 的自注意力机制能在理论上直接让任意两个 token 互相「看到」对方,从而把建模的范围从局部窗口扩展到整个输入序列(即模型的上下文窗口长度)。上下文窗口的具体长度可以是几千,甚至几十万
token,这标志着模型能同时考虑的文本范围大大提高。
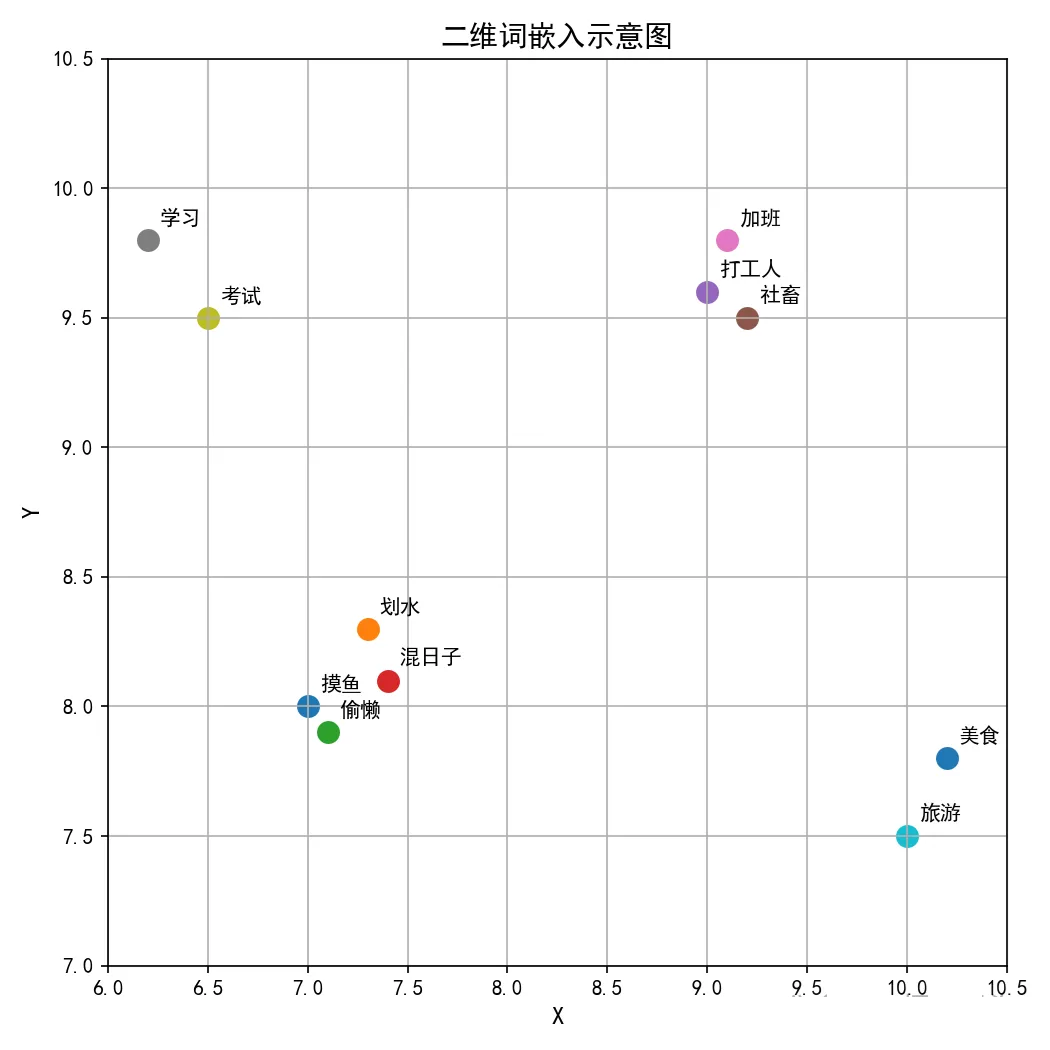
在进入模型前,每个 token 会被映射到高维向量空间,叫做词嵌入(Embedding)。在这个空间里,语义越近的词对应的向量距离也越近。以二维向量空间举例,点(7,
8)可能代表「摸鱼」,点(7.3, 8.3)可能代表「划水」,而代表「打工人」的点可能就在(9, 9.6)了。
(词嵌入的低维可视化展示,仅为部分聚类趋势,非实际情况)
二维示例便于理解,但实际维度往往很大——现代模型经常能够达到数千到上万维。
2)解析与回答
有了有序输入的 token 后,Transformer 对每个 token 计算三个向量:Query(Q,表示“我在找什么”)、Key(K,表示“我能提供什么”)和
Value(V,表示“我是什么”)。注意力机制通过比较 Q 与其它 token 的 K 来决定对哪些
token 赋予更多关注,然后把对应的 V 以加权和的方式聚合起来,形成当前 token 的上下文表示。
以前面那个例子“我比他更水”来说,对于“水”这个 token,模型可能会根据上下文更关注“我”而不是“他”。
在实现上,每一层注意力模块可视作若干矩阵乘法与一次输出变换(记作 Wq、Wk、Wv、Wo 的组合),矩阵尺寸等于
d_model × d_model。
内部语义上常把输入向量分成 num_heads 个子空间并行计算,叫做多头注意力(Multi-Head
Attention)。多头注意力的设计允许模型在不同子空间关注不同类型的关系,提升表达力与鲁棒性,不至于让模型“钻牛角尖”。若
d_model = 12288,num_heads = 64,则每个头的维度为 192(12288/64)。
在模型理解完输入序列想要干什么以后,就进入了回答的环节,这里会经过一个叫前馈神经网络(FFN,Feed
Forward Network)的结构,来对每个 token 做逐位置的非线性变换。常见做法是先将维度提升到
d_ff(通常为 4×d_model),再降回 d_model。维度提升后能容纳更多的信息进行复杂组合,来回答输入中的问题,比如“水是一种物体
→ 但在有些情况下水是形容词 → 水可以形容能力更弱 → 这种情况下水是贬义词”这样的知识,就是从
FFN 这里「拿」出来的。
这一套注意力 + FFN 的模块会堆叠 N 层(有的模型 N=96 或更高),形成深层网络,用来回答各种复杂问题。
3)结果输出
在经过了所有层级后,模型已经能给出一团混合的结果了,但此时的答案还只是每个位置上候选 token
的分数,需要进行线性处理(Linear)和归一化(Softmax)把分数转成概率分布,依次输出概率最高的
token,这样就是人类能理解的顺序答案了。这也是通常所说「大模型根据下一个词的概率分布生成文本」的含义:模型在每一步基于当前上下文预测下一个
token 的概率。
现在我们就可以回答这个问题:大模型的参数量如何计算?
每一层的主要权重来自注意力部分:
Wq、Wk、Wv、Wo四块矩阵,每块的大小均为 12288 × 12288,合并后大致相当于 4
× d_model^2
和 FFN 部分:
两块矩阵,约为 2 × d_model × d_ff,若 d_ff = 4 × d_model 则为
8 × d_model^2
因此一层权重近似为 12 × d_model^2。以 d_model = 12288、N = 96
为例,按上式计算得到的主要权重数量约为 :
12 × 12288^2 × 96 ≈ 1.739 × 10^11(约 1739.5 亿)
加上其他小量参数(嵌入、偏置、归一化等),就是 GPT-3 的实际参数规模(1750亿)。
大模型的训练
弄清架构以后,训练目标就是确定上述所有矩阵(权重)的数值。
GPT 系列常见的训练流程可以分三步:
1. 预训练(Pre-training)。通常采用自监督学习(Self-supervised Learning)方法:在大规模未标注语料上训练,让模型根据上下文预测缺失的
token(或者用下一句预测、因而构成“标签与输入来自同一文本”的一种学习方式)。自监督常被归入“无监督学习”范畴,但严格意义上自监督是通过构造伪标签来学习的一类特殊方式。
2. 指令微调(Instruction Fine-tuning)。用高质量、带任务指令的示例(人工标注数据)来训练模型,使其学会按照自然语言指令执行特定任务,从而在交互时更符合人类期望的回答形式。
3. 人类反馈强化学习(RLHF,Reinforcement Learning from Human
Feedback)。先收集人类对模型输出偏好的排序或评分,训练一个奖励模型来估计人类偏好,再用强化学习算法对基础模型进一步微调,使模型输出更符合人类偏好与安全规范。
此外还有蒸馏学习(Knowledge Distillation)等技术:通过让小模型模仿大模型的行为,把「教师模型」的知识迁移到「学生模型」,以在有限计算资源下尽量保留表现。很多
Mini , Nano 版本的模型就是经过更大模型蒸馏后的产物。
对于个人或小团队想训练小规模模型的情况,常见策略是采用开源的预训练模型做基础,然后用自有数据做指令微调或领域微调,这样可以在可承受的计算资源上获得实用性能。
大模型的调用
把训练好的静态模型部署完成后,面对新请求时就是运行前述的计算过程。由于参数规模庞大,实际运行需要计算框架配合(如对矩阵分片并行、分布式计算等)才能高效完成。
在推理阶段,把矩阵运算映射到合适的硬件(CPU、单卡 GPU、多卡分布式集群、或专用推理芯片)以提高吞吐与延迟表现。工程上通常要考虑模型并行、数据并行、流水线并行、分片、内存与带宽优化等问题,以让大模型在资源受限时仍能高效运行。
这就是大语言模型的主要原理了,各家公司会基于不同的数据源、模型设计与训练细节推出各自的模型,同时建立起多维的模型评测体系(例如准确性、鲁棒性、幻觉指数、安全性、细分领域性能等)。需要提醒的是:评测分数高并不意味着模型在每个具体场景都是「最好」的,对于每个用户来说:
适合自己的大模型才是最好的大模型
基于 Transformer 的架构,也催生了大量多模态模型:通过对不同模态输入给予合适的权重编码与注意力机制,使图像、视频与文本等跨模态信息能互相融合并用于生成或理解任务。
虽然核心原理相对直观,但落地实现涉及大量工程细节与挑战。全球大量顶尖的研究者与工程团队正持续投入这一领域,推动技术快速演进。或许
AI 的使用极限,只受限于我们人类的想象力了。
扩展内容
在讲解过程中,为避免分散注意力,我省略了一些对主干结构影响不大的内容,在此进行补充说明,有兴趣的朋友可以继续往下看:
位置编码(Positional Encoding)
Transformer 需要位置信息来保持序列顺序。原始论文采用了基于不同频率的正弦/余弦函数构造的固定位置编码(sin/cos),具体函数为:
后来许多实现改为可学习的位置嵌入(Learned Positional Embeddings),两者在不同场景下各有优劣。
激活函数(Activation Function)
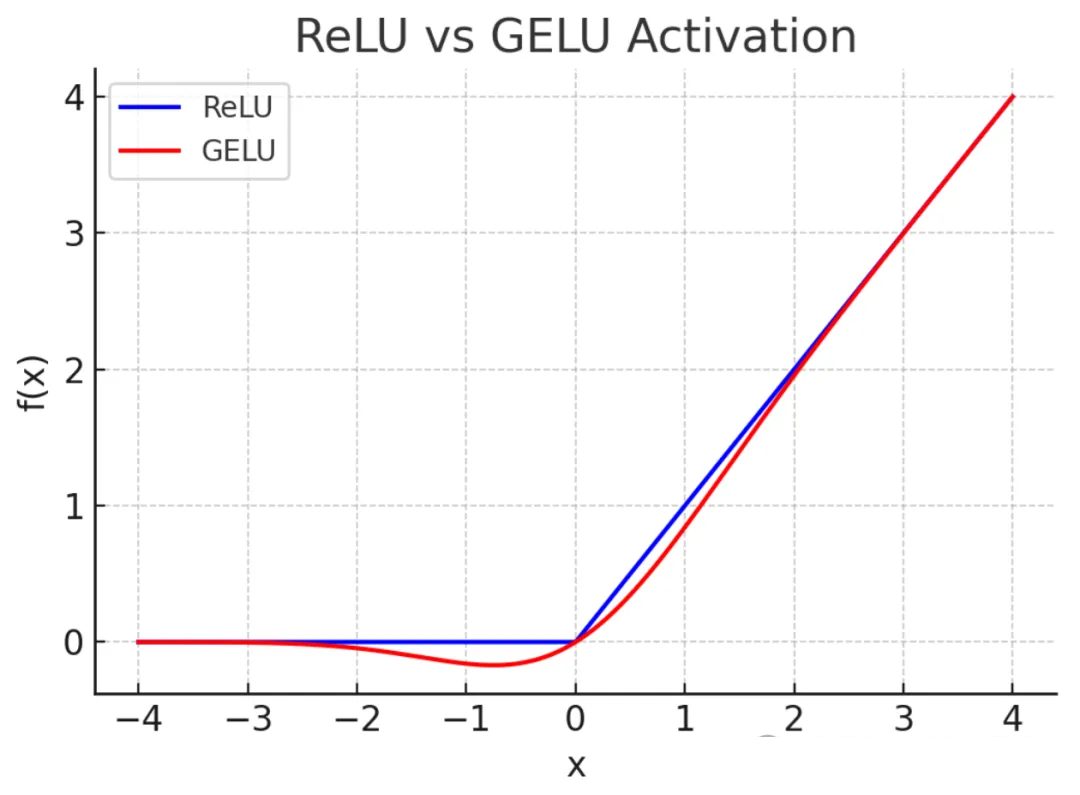
在两层(升维再降维)前馈神经网络 FFN 之间通常会加入非线性激活函数以赋予模型非线性表示能力。常见选择包括
修正线性单元(ReLU,Rectified Linear Unit)
高斯误差线性单元(GELU,Gaussian Error Linear Unit)
后者在许多 Transformer 实现中表现良好。
(两种函数的图像)
残差连接(Residual Connections)
为了稳定训练与缓解梯度问题,Transformer 在子层(注意力子层与 FFN 子层)后通常使用残差连接(把子层输入
x 与子层变换 F(x) 相加),并配合归一化操作来统一尺度与加速训练。
掩码多头注意力(Masked Multi-Head Attention)
在自回归预训练中,训练时要确保模型在预测某一位置的 token 时不能看到该位置之后的真实 token,因此使用掩码机制屏蔽未来位置。这保证了模型在生成时只基于已生成的上下文进行预测。
缩放点积注意力(Scaled Dot-Product Attention)
单头注意力的输出为:
对于多头注意力(h 个头),每个头在子空间上做上述计算,最后拼接各头输出再做一次线性变换:
| 






 订阅
订阅