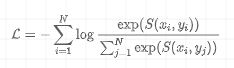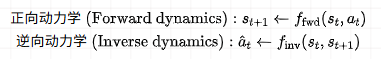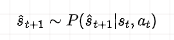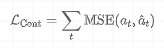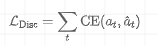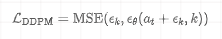| 编辑推荐: |
本文全面梳理VLA模型,描述VLA技术的全景蓝图,系统地剖析了其内部结构、关键技术和未来方向,希望对你的学习有帮助。
本文来自于具身智能与空间感知,由火龙果软件Alice编辑,推荐。 |
|
前言
近年来,人工智能(AI)的发展日新月异,从能与人对话的ChatGPT到能生成惊艳图片的Midjourney,AI似乎已经掌握了“看”和“说”的能力。然而,通往通用人工智能(AGI)的道路上,一个更艰巨的挑战摆在面前:如何让AI走出虚拟世界,进入物理世界,与环境真实互动——也就是“做”的能力。这便是 具身智能(Embodied AI) 的核心。
传统的机器人要么依赖于复杂的编程,要么受限于特定任务的强化学习,难以适应千变万化的现实世界。但随着大语言模型(LLM)和视觉语言模型(VLM)的成功,一个新的研究方向应运而生: 视觉-语言-动作模型(Vision-Language-Action Models, VLA) 。这类模型旨在将视觉感知、语言理解和物理动作融为一体,让机器人能够听懂人的指令(“把桌子上的苹果拿给我”),看懂当前的环境(识别出哪个是苹果、哪个是桌子),并自主生成一系列动作来完成任务。可以说,VLA正是未来通用机器人的“大脑”。
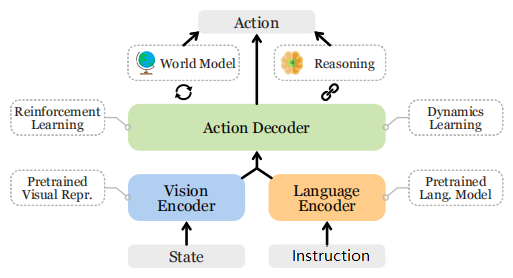
VLA模型通用架构图 。该图直观地展示了VLA模型的核心工作流程:它接收 状态(State) (如摄像头捕捉的图像)和 指令(Instruction) (如用户的语言命令)作为输入,通过 视觉编码器 和 语言编码器 进行处理,最终由 动作解码器(Action Decoder) 生成机器人需要执行的 动作(Action) 。整个系统还与强化学习、世界模型等重要相关技术紧密相连。
VLA的进化之路:从单兵作战到三位一体
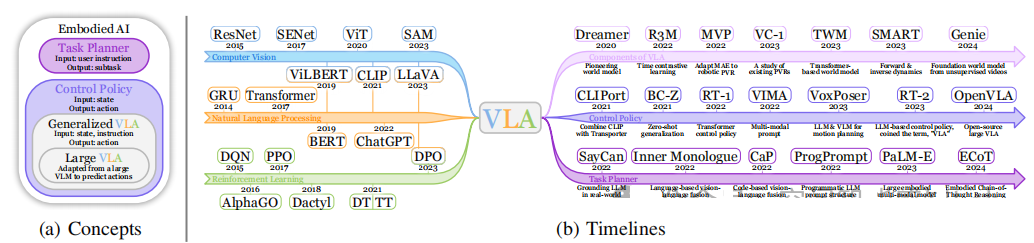
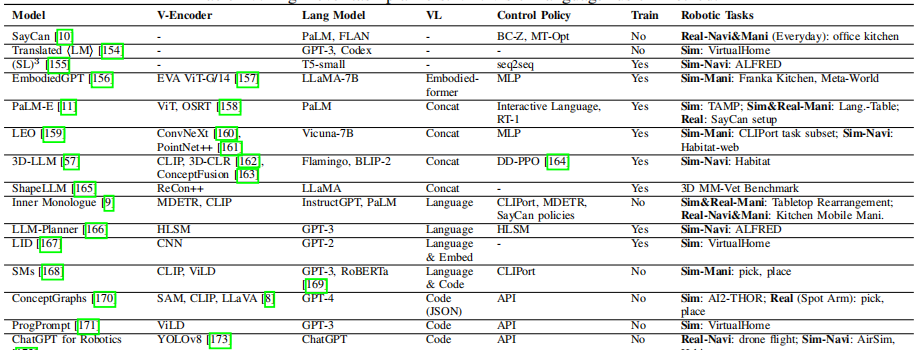
VLA模型并非横空出世,它的发展深深植根于计算机视觉(CV)、自然语言处理(NLP)和强化学习(RL)这三大领域的历史积淀。这篇综述通过一张时间线图,清晰地为我们勾勒出了这条从“单兵作战”到“三位一体”的进化之路。
图2(b):从单模态模型到VLA模型的发展时间线 。这张图谱展示了从2014年到2024年,AI模型如何一步步走向融合。
- 单模态模型的奠基 :
- 计算机视觉(CV) :从ResNet、ViT到SAM,CV模型提供了强大的视觉感知能力,让AI能“看懂”世界。
- 自然语言处理(NLP) :从GRU、Transformer到BERT、ChatGPT,NLP模型让AI能“听懂”人类语言。
- 强化学习(RL) :从DQN、AlphaGo到决策Transformer(DT),RL为AI提供了从试错中学习最优策略的理论框架。
- 多模态模型的兴起 :
- 视觉语言模型(VLM) :以CLIP、LLaVA为代表的VLM成功地将视觉和语言两种模态对齐,实现了看图说话、视觉问答等功能,为VLA的出现奠定了基础。
- VLA模型的诞生与发展 :
- 底层控制策略(Control Policy) :早期的工作如CLIPort将VLM的能力与机器人控制相结合。随后,RT-1、VIMA等模型利用Transformer架构,将机器人控制问题转化为序列预测问题,极大地提升了模型的泛化能力。
- 高层任务规划器(Task Planner) :像 SayCan 、PaLM-E这样的模型,则利用LLM强大的推理能力,将复杂的长时程任务(如“打扫房间”)分解为一系列简单的子任务(“拿起玩具”、“走到桌边”……),指导底层控制器逐步执行。
- VLA概念的正式提出 :2023年的RT-2模型正式提出了“VLA”这一术语,并展示了将一个庞大的VLM直接微调用于机器人控制的惊人潜力,标志着VLA研究进入了新阶段。
拆解VLA的大脑:核心组件全解析
一个强大的VLA模型离不开其背后众多精心设计的组件。论文将这些组件归纳为几个关键类别,它们共同构成了VLA的“感知与认知中枢”。
预训练视觉表征
视觉编码器的好坏直接决定了VLA模型对环境的感知能力。一个好的PVRs能从输入的图像中提取出物体的类别、姿态、几何形状等关键信息。
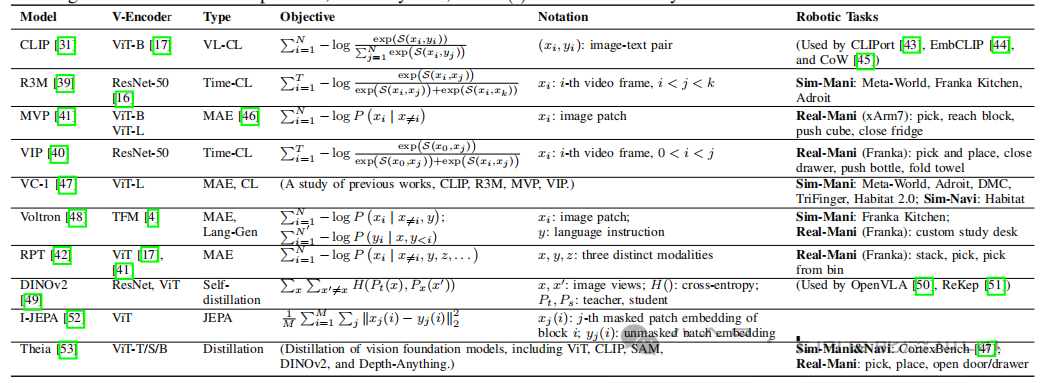
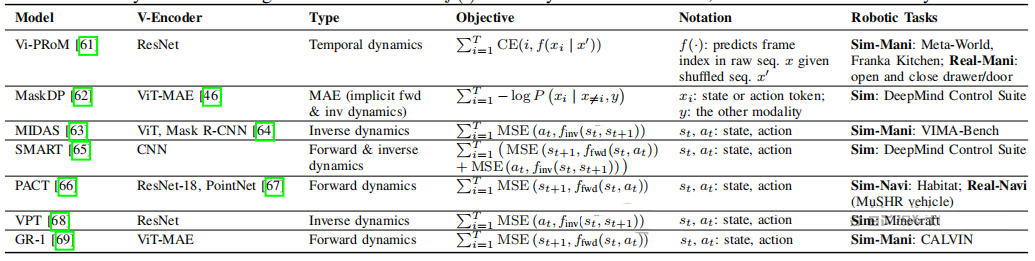
表I:预训练视觉表征方法对比 。该表详细列举了近年来机器人领域常用的PVRs方法,如CLIP、R3M、MVP、DINOv2等。表中对比了它们的 视觉编码器类型 (如ResNet、ViT)、 训练目标 (如视觉-语言对比学习VL-CL、时间对比学习Time-CL、掩码自编码器MAE)以及 应用场景 。
- CLIP :通过在海量图文对上进行对比学习,CLIP学习到了强大的图文对齐能力,使其成为许多VLA模型的首选视觉编码器。其目标函数可以简化为:
- 这个公式的含义是在一个批次(Batch)中,最大化正确图文对 的相似度 ,同时最小化不正确图文对的相似度。
- R3M & VIP :这类方法专注于从视频数据中学习。它们采用 时间对比学习(Time-contrastive learning) ,核心思想是:在同一段视频中,时间上相近的帧在表征空间中也应该相近,而时间上相远的帧则应该被推开。这使得模型能够学习到物体的动态变化和时间连贯性。
- MVP & MAE-based methods :这类方法借鉴了NLP中BERT的成功经验,采用 掩码自编码(Masked Autoencoding) 的方式进行自监督学习。它们随机遮挡输入图像的一部分(patches),然后训练模型去重建被遮挡的内容。这种方式迫使模型学习到图像的底层结构和细节,对于需要精细操作的机器人任务尤其有用。
- DINOv2 & I-JEPA :这些是最新的自监督学习方法,通过知识蒸馏等技术,在不依赖大规模标注数据的情况下学习到了媲美甚至超越有监督学习的视觉表征,展现了巨大的潜力。
动力学学习
动力学学习赋予模型理解世界“物理规律”的能力,即预测一个动作将会导致什么后果( 正向动力学 ),或者要达到某个状态需要执行什么动作( 逆向动力学 )。
- 和 分别代表当前和下一时刻的状态,** ** 代表当前执行的动作。
- 正向动力学模型 预测了在状态 下执行动作 后,环境会转移到哪个新状态 。
- 逆向动力学模型 则根据状态的转变(从 到 ),反推出最可能执行了哪个动作 。
表II:VLA的动力学学习方法 。该表总结了Vi-PROM、MaskDP、SMART等模型中使用的动力学学习方法,它们通过不同的目标函数(如MSE损失)来训练模型预测状态或动作。逆向动力学通常比正向动力学更容易学习,但正向动力学(即预测未来)对模型的性能提升往往更大。
世界模型
世界模型是动力学学习的延伸和升华。它不仅预测下一个状态,更是试图在模型内部构建一个可微分、可交互的“迷你世界”。
这个公式表示世界模型 学习到了一个关于世界状态转移的概率分布。有了这个内部世界,机器人就可以在“想象”中进行规划和推演,而无需在真实世界中进行昂贵且危险的试错。像 Dreamer 系列、 Genie 等模型都是这个方向的杰出代表。
VLA的底层控制策略
如果说核心组件是VLA的大脑,那么底层控制策略(Low-level Control Policy)就是连接大脑和身体的“神经-肌肉”系统。它的职责是根据大脑(高层规划器)的指令和当前的感知,生成具体、可执行的机器人动作。
一个控制策略 可以被形式化地定义为:
这里的 是语言指令, 是过去到现在的环境状态序列, 是过去执行的动作序列。策略模型的目标就是预测出当前最应该执行的动作 。
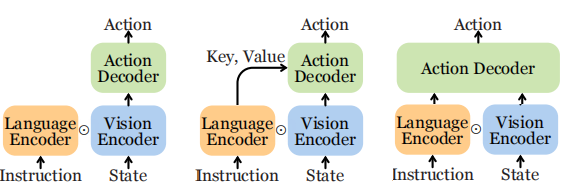
Transformer控制策略中常见的三种视觉-语言融合方法 。
- (a) FiLM (Feature-wise Linear Modulation) :这是一种轻量级的融合方式。语言编码器的输出被用来对视觉特征进行线性变换(缩放和偏置),从而实现对视觉信息的“调制”。 RT-1模型就采用了这种结构。
- (b) 交叉注意力 (Cross-attention) :这是一种更强大的融合方式。视觉特征作为Key和Value,语言特征作为Query,通过注意力机制让语言指令去“查询”视觉信息中与之相关的部分。
- (c) 拼接 (Concatenation) :这是最简单直接的方式,将视觉和语言的特征向量直接拼接在一起,然后输入到后续的Transformer层中进行深度融合。这种方式在大型VLA(LVLA)中最为流行。
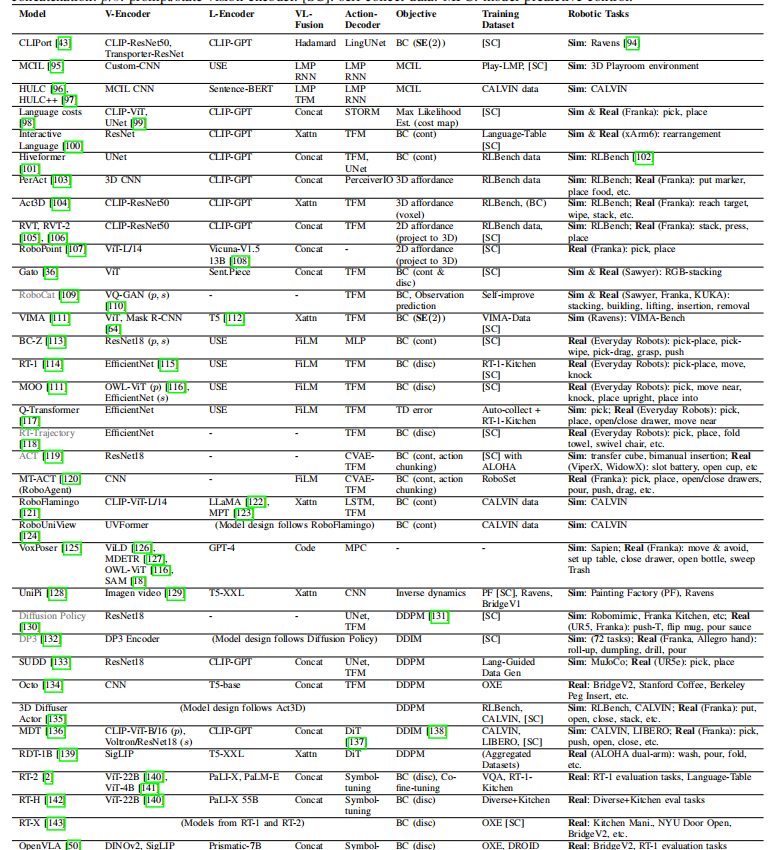
表III:底层控制策略模型汇总 。这张巨大的表格是综述的核心之一,它详细罗列了从CLIPort、HULC到RT-1、RT-2、Octo等数十个重要的控制策略模型。表中详细对比了它们的 视觉编码器 、 语言编码器 、 融合方式 、 动作解码器 、 训练目标 等技术细节。 从这张表中我们可以看出控制策略的几个发展趋势:
- 从非Transformer到Transformer :早期的模型(如CLIPort)使用定制化的网络结构,而后期模型(如RT-1)则普遍转向了表达能力更强的Transformer架构。
- 动作离散化 :像RT-1这样的模型,将连续的机器人动作空间(如七自由度手臂的关节角度)离散化为有限个“桶”(bins)。这样做的好处是可以将回归问题转化为分类问题,使用交叉熵损失进行训练,通常更稳定且效果更好。
- 扩散模型的兴起 :以Diffusion Policy、Octo、MDT为代表的模型,将最近在图像生成领域大放异彩的扩散模型(Diffusion Model)用于动作生成。扩散模型能够很好地学习复杂的多模态动作分布,在需要精细操作的任务上表现出色。
控制策略的训练目标 (Training Objectives):
- 连续动作(行为克隆) :通常使用均方误差损失(MSE Loss)来最小化模型预测动作与专家演示动作之间的差距。
- 离散动作(行为克隆) :使用交叉熵损失(Cross-Entropy Loss)。
- 扩散模型 :目标是训练一个噪声预测网络 ,让它能从加噪的动作中预测出所加的噪声 。
VLA的高层任务规划器
对于“泡一杯咖啡”这样复杂的长时程任务,底层控制策略往往难以一步到位。这时就需要一个“指挥官”——高层任务规划器(High-level Task Planner)——来运筹帷幄。
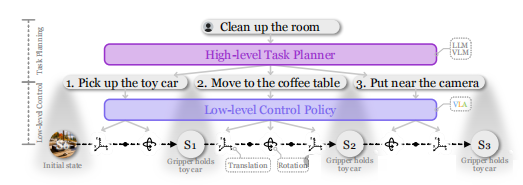
图4:分层机器人策略示意图 。这张图清晰地展示了“指挥官”和“执行者”的协同工作模式。
- 用户给出高层指令:“ 打扫房间 ”。
- 高层任务规划器 (通常是LLM或VLM)将这个复杂任务分解为一系列简单的子任务序列: [1. 拿起玩具车, 2. 移动到咖啡桌, 3. 放到相机旁边] 。
- 这些子任务作为语言指令,被逐一发送给 底层控制策略 (VLA)。
- 底层控制策略负责执行每一个具体的子任务,直到最终完成“打扫房间”的宏大目标。
任务规划器主要分为两大类:
- 整体式规划器 (Monolithic Planners) :通常是端到端的大型多模态模型,如 PaLM-E 。它们直接接收视觉和语言输入,生成任务计划。这类模型能力强大,但训练和部署成本高昂。
- 模块化规划器 (Modular Planners) :这类方法更加灵活,它将现成的LLM(如GPT-4)和VLM(如CLIP)等模块组合起来,无需大量重新训练。
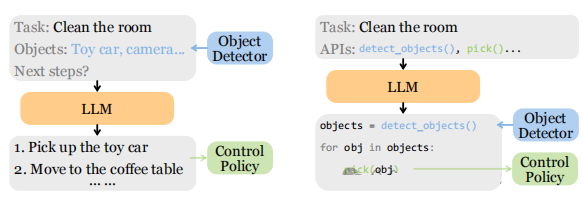
图6:模块化任务规划器的两种主流方法 。
- (a) 基于语言 (Language-based) :这种方法以自然语言作为不同模块间信息交换的“通用语”。例如,物体检测模块将检测到的物体(“玩具车”、“相机”)以文本形式告知LLM,LLM再根据这些信息生成下一步的自然语言指令。 Inner Monologue 就是这种方法的代表。
- (b) 基于代码 (Code-based) :这种方法利用LLM强大的代码生成能力。它将感知和控制模块封装成API函数(如 detect_objects() , pick(obj) )。LLM通过生成一段Python代码来调用这些API,从而完成任务规划。这种方法可控性强,易于调试。 ProgPrompt 和 CaP 是其中的代表作。
表IV:高层任务规划器汇总 。该表总结了SayCan、PaLM-E、3D-LLM等主流任务规划器,对比了它们的模型构成、控制策略和是否需要训练等特点。
VLA的数据集与基准
兵马未动,粮草先行。高质量、大规模的数据集是训练强大VLA模型的基石。然而,相比于互联网上取之不尽的图文数据,机器人交互数据的获取成本极高。
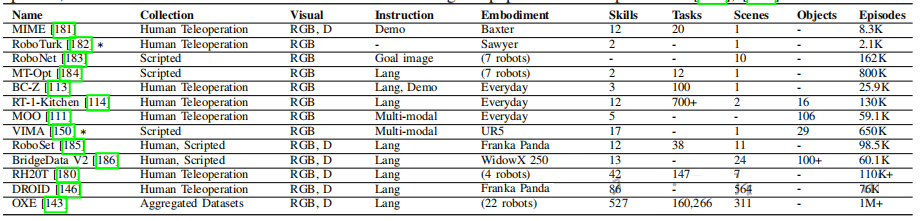
表V:近期机器人学习数据集 。该表展示了近年来具身智能领域常用的一些真实世界数据集,如BC-Z、RT-1-Kitchen、BridgeData V2等。我们可以看到,最新的 OXE (Open X-Embodiment) 数据集通过聚合来自22种不同机器人的数据,达到了百万级别的轨迹数量,极大地推动了通用机器人策略的发展。
为了解决真实世界数据采集难的问题,许多研究者转向了 仿真环境 。
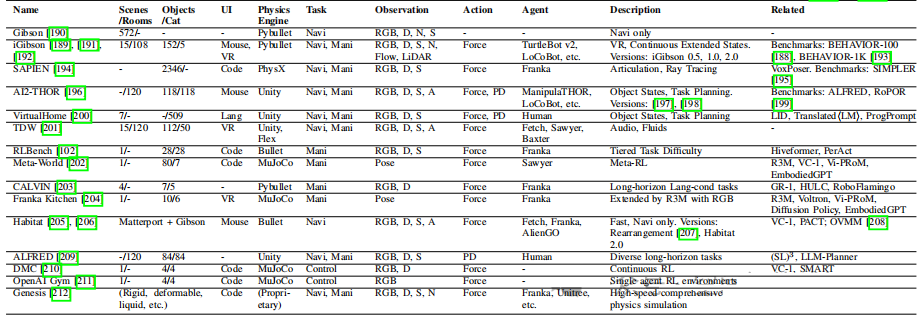
表VI:仿真器与仿真基准 。该表列出了如iGibson、AI2-THOR、RLBench、CALVIN等常用的仿真环境。仿真环境可以大规模、低成本地生成数据,并提供精确的评测指标,但也面临着 Sim-to-Real Gap (仿真到现实的鸿沟)的挑战。
VLA的挑战与未来
尽管VLA模型已经取得了令人瞩目的成就,但前路依然充满挑战。论文总结了几个关键的挑战和未来的研究方向:
当前挑战:
- 安全第一 :在物理世界中,安全是机器人应用的首要考量。
- 数据集与基准 :仍然缺乏覆盖多样化场景、任务和机器人的大规模、高质量数据集。
- 模型泛化 :如何训练出能够泛化到新物体、新环境、新任务的通用VLA基础模型,仍然是一个开放性问题。
- 实时性 :当前的大型VLA模型推理速度较慢,难以满足动态环境下的实时交互需求。
- 长时程任务 :现有的分层框架虽然实用,但增加了系统复杂性,容易出现故障。
未来趋势:
- 更强的基础模型 :构建规模更大、能力更强的VLA基础模型,类似NLP领域的GPT-4。
- 多模态融合 :不仅仅是视觉和语言,未来将融合触觉、听觉、力觉等更多模态的信息。
- 高效的实时推理 :研究模型压缩、量化、蒸馏等技术,在保证性能的同时提升模型的推理速度。
- 更广阔的应用场景 :从目前的家庭、工业场景,拓展到医疗(手术机器人)、特种服务(护理机器人)等更具挑战性的领域。
结论
视觉-语言-动作(VLA)模型通过整合感知、理解与行动,为构建能够与物理世界智能交互的通用机器人指明了一条清晰的道路。 这篇综述系统地剖析了VLA模型的三个核心层面: 关键组件 (认知基础)、 底层控制策略 (神经肌肉系统)和 高层任务规划器 (指挥官)。 它不仅为我们梳理了该领域的过去和现在,也为我们展望了充满希望的未来。从单模态的基石,到多模态的桥梁,再到VLA的三位一体,我们正在见证一个能够“眼观六路、耳听八方、心灵手巧”的通用智能体的诞生。这条路虽然道阻且长,但行则将至。VLA的研究无疑将继续推动人工智能的边界,引领我们走向一个更智能、更自动化的未来。
|