| 编辑推荐: |
本文主要介绍了如何使用知识图谱和向量数据库实现
Graph RAG 相关内容。希望对你的学习有帮助。
本文来自于微信公众号出行AI ,由火龙果软件Linda编辑,推荐。 |
|
在这篇文章中,我将重点讲解一种当前非常流行的 KGs 和 LLMs
联合使用方式:使用知识图谱的 RAG,有时也被称为 Graph RAG[2]、GraphRAG[3]、GRAG[4]
或语义 RAG[5]。
检索增强生成(RAG)是一种通过检索相关信息来增强传送至 LLM 的提示词(prompt),进而生成回应的方法。其核心思想是:与其直接向
LLM 发送提示词——而该 LLM 可能并未训练过你的特定数据,不如在提示词中补充相关信息,从而使
LLM 能更准确地回答问题。
由于知识图谱本身就是为存储知识而设计的,它非常适合用于存储企业内部数据,并为 LLM 提供附加上下文,从而提升回答的准确性和上下文理解能力。
一个重要但常被误解的点是:RAG 和基于知识图谱的 RAG(Graph RAG)实际上是一种技术组合方法论,而不是某种产品或技术本身。Graph
RAG 不是由某个人发明,也没有任何人拥有它的专利或垄断权。尽管如此,大多数人都能看到将这两种技术结合的巨大潜力,而且越来越多[6]的研究也在证实这种结合带来的好处。
RAG 中使用知识图谱的三种方式
通常,在 RAG 的检索部分使用知识图谱(KG)有三种方式:
1. 向量检索(Vector-based retrieval)
•将知识图谱向量化,并将其存储在向量数据库中。
•接着,将自然语言提示词向量化,可以在向量数据库中找到与该提示词最相似的向量。
•由于这些向量对应的是知识图谱中的实体,因此可以根据自然语言提示返回最“相关”的实体。
注意:
•向量检索不一定需要知识图谱。这种方法实际上是 RAG 最初实现的方式,有时被称为“基础 RAG”(Baseline
RAG)。
•你可以将 SQL 数据库或其他内容向量化,并在查询时进行检索。
2. 提示词转查询检索(Prompt-to-query retrieval)
•使用 大语言模型(LLM) 为你编写 SPARQL 或 Cypher 查询。
•将生成的查询应用于知识图谱,并使用返回的结果来增强提示词。
3. 混合方法(Hybrid:向量 + SPARQL)
•将上述两种方法结合起来,使用向量化进行初步检索,然后通过 SPARQL 查询 对结果进行精炼。
•本教程主要演示这种 混合方法,即 向量化用于初步检索,再使用 SPARQL 精细化结果。
将 向量数据库 和 知识图谱 结合起来用于搜索、相似度计算和 RAG 有很多方式。这只是一个简单的示例,用于展示每种方法的优缺点,以及它们结合使用的好处。
口头流传的有趣例子:
某大型家具制造商的员工分享说,向量数据库可能会向购买沙发的用户推荐粘毛刷,而 知识图谱则能理解材质、属性和关系,从而避免向购买皮沙发的用户推荐粘毛刷。
本教程的目标
在本教程中,我将:
1.将数据集向量化 存入向量数据库,用于测试 语义搜索、相似度搜索 和 RAG(基于向量的检索);
2.将数据转化为知识图谱,用于测试 语义搜索、相似度搜索 和 RAG(提示词转查询检索)。虽然这实际上更像是
直接查询检索,因为我直接使用了 SPARQL,而不是让 LLM 将自然语言提示转化为 SPARQL
查询;
3.将包含知识图谱标签和 URI 的数据集向量化 并存入向量数据库(我称之为“向量化的知识图谱”),然后测试
语义搜索、相似度搜索 和 RAG(混合方法)。
本教程的目标是说明知识图谱和向量数据库在这些能力方面的差异,并展示它们如何协同工作。
下图是一个高层次概览,展示了向量数据库和知识图谱如何结合起来执行高级查询操作。
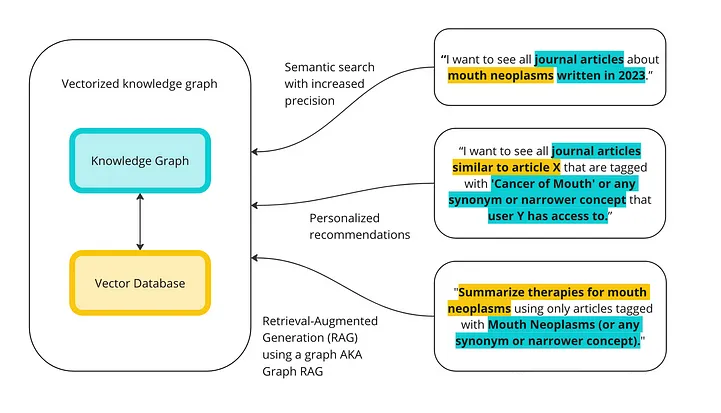
如果你不想继续往下读,这里是简要总结(TL;DR):
•向量数据库可以很好地进行语义搜索、相似度计算以及某些基本形式的 RAG,但有一些注意事项。第一个注意事项是:我使用的数据包含期刊文章的摘要,也就是说,它包含了大量非结构化文本。向量化模型主要在非结构化数据上训练,因此当实体关联的是文本块时,效果会更好。
•话虽如此,将数据导入向量数据库并准备好进行查询的成本非常低。如果你的数据集中包含一些非结构化内容,你可以在
15 分钟内完成向量化并开始搜索。
•不出意料地,单独使用向量数据库的最大缺点之一就是缺乏可解释性。返回的结果中可能有三个是很好的,但有一个却毫无意义,而且你没有办法知道为什么那个结果会被返回。
•向量数据库返回无关内容的可能性在搜索和相似度计算中可能只是个小麻烦,但在 RAG 中就是个大问题。如果你用四篇文章来补充提示词,其中有一篇是完全无关的内容,那么
LLM 的回答就会产生误导。这种情况通常被称为“上下文污染(context poisoning)”。
•上下文污染特别危险的一点是,LLM 的回答可能并没有事实错误,也不是基于错误的数据,而是基于“错误的数据类型”来回答你的问题。例如在本教程中的一个例子中,提示词是“mouth
neoplasms(口腔肿瘤)的治疗方法”,但检索到的一篇文章是关于直肠癌治疗的研究,随后被发送给
LLM 进行摘要。我不是医生,但我可以肯定直肠不属于口腔。LLM 准确地总结了该研究以及不同治疗方案对口腔和直肠癌的影响,但并不总是指出是哪种癌症。于是用户可能毫无察觉地在阅读一个
LLM 对直肠癌治疗方案的描述,而最初的问题是关于口腔癌的。
•知识图谱在语义搜索和相似度搜索中的效果,很大程度上取决于元数据的质量,以及这些元数据所连接的受控词汇。在本教程中的示例数据集里,期刊文章都已经用主题词进行了标注。这些主题词来自美国国立卫生研究院(NIH)提供的医学主题词表(MeSH)。正因为如此,我们可以非常轻松地进行语义搜索和相似度分析。
•将知识图谱直接向量化并导入向量数据库作为 RAG 的知识基础库,可能会带来一定好处,但我在本教程中并没有这样做。我只是将数据以表格格式向量化,并为每篇文章添加了一个
URI 列,以便可以将向量与知识图谱连接起来。
•使用知识图谱进行语义搜索、相似度计算和 RAG 的最大优势之一是可解释性。你总是可以解释某些结果为什么会被返回:因为它们被标注了某些概念,或者具有某些元数据属性。
•知识图谱的另一个我原本没有预料到的好处,有时被称为“增强数据丰富性”或“图谱即专家”——你可以用知识图谱来扩展或细化你的搜索词。例如,你可以找到与你的搜索词相关的同义词、更具体的词,或者有特定关系的词,从而扩展或精细化你的查询。例如,我可能一开始是搜索“口腔癌”,但根据知识图谱中的术语和关系,进一步细化为“龈部肿瘤(gingival
neoplasms)和腭部肿瘤(palatal neoplasms)”。
•使用知识图谱的最大障碍之一是:你需要先构建一个图谱。不过,好消息是现在有很多方法可以用 LLM 加快构建知识图谱的过程(如上文图
1 所示)。
•仅使用知识图谱的一个缺点是:你需要自己写 SPARQL 查询来完成所有操作。这也解释了上文所述提示词转查询检索方法的受欢迎程度。
•在知识图谱中使用 Jaccard 相似度来查找相似文章的效果很差。如果没有进行特别指定,图谱会返回一些具有标签重叠的文章,比如“老年人”、“男性”和“人类”,这些标签可能远不如“治疗方案”或“口腔肿瘤”相关。
•我遇到的另一个问题是,计算 Jaccard 相似度非常耗时(大概花了 30 分钟)。我不知道有没有更好的方法(欢迎建议),但我猜测在
1 万篇文章中寻找标签重叠是非常消耗计算资源的。
•在本教程中,我使用的提示词非常简单,例如“总结这些文章”——这意味着 LLM 的回答准确性(无论是向量检索还是图谱检索)更依赖于检索过程而非生成过程。换句话说,只要你给
LLM 提供了相关的上下文,它几乎不会搞错这种简单的“总结”类任务。当然,如果提示词是更复杂的问题,那情况就会不一样。
•使用向量数据库进行初步检索,再使用知识图谱进行筛选,是表现最好的方法。这其实也不奇怪——你不会通过筛选来让结果变差。但关键在于:知识图谱本身不一定能提高结果质量,它提供的是一种控制输出以优化结果的能力。
•利用知识图谱对结果进行筛选可以提高提示词相关性的准确度,也可以根据提示词提出者进行个性化定制。例如,我们可能希望用相似度搜索来找出适合向用户推荐的相关文章,但只希望推荐用户有权限访问的文章。知识图谱就可以实现查询时的访问控制。
•知识图谱还可以帮助减少上下文污染的可能性。在上文的 RAG 示例中,我们可以在向量数据库中搜索“mouth
neoplasms 的治疗方法”,但随后只保留那些被打上“mouth neoplasms”或相关标签的文章。
•本教程中我只演示了一种简单的实现方式:将提示词直接送入向量数据库,然后使用图谱对结果进行筛选。其实还有更好的方法。例如:
•从提示词中提取实体,与受控词表匹配后用知识图谱扩展(如同义词和更具体术语);
•将提示词解析为语义片段分别送入向量数据库;
•将 RDF 数据转为文本再进行向量化,以提升语言模型的理解力;
这些是我计划在未来的文章中继续探讨的内容。
第一步:基于向量的检索(Vector-based retrieval)
下图展示了整体的高层次计划。我们希望将期刊文章的摘要和标题向量化,存入向量数据库,以便运行不同类型的查询:语义搜索、相似度搜索,以及一个简单版本的
RAG。
•对于语义搜索,我们将测试像 “mouth neoplasms(口腔肿瘤)” 这样的术语 —— 向量数据库应该返回与该主题相关的文章。
•对于相似度搜索,我们将使用某一文章的 ID,在向量空间中查找其最近邻,也就是与这篇文章最相似的文章。
•最后,向量数据库还支持一种形式的 RAG,我们可以将类似“请像对一个没有医学学位的人解释这个”的提示词,与一篇文章一起提供给
LLM 来补充上下文。
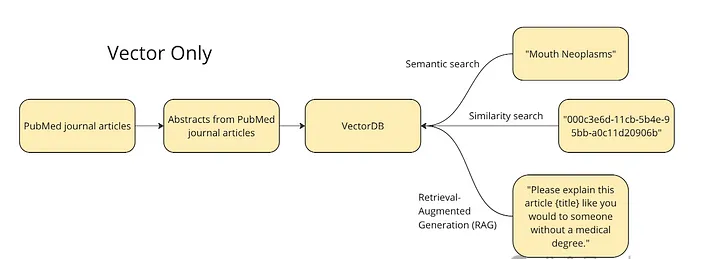
我决定使用 PubMed 仓库[7]中这份包含 50,000 篇研究文章的数据集(许可协议:CC0
公共领域[8])。该数据集包含文章标题、摘要,以及一个元数据标签字段。这些标签来自医学主题词表(MeSH)受控词汇表。
在本教程的这一部分中,我们仅使用摘要和标题。这是因为我们要比较向量数据库和知识图谱,而向量数据库的优势在于它能够在没有丰富元数据的情况下“理解”非结构化数据。
我只使用了前 10,000 条数据,以加快计算速度。
Weaviate 的官方快速入门教程[9]
我还发现这篇文章[10]对于入门很有帮助。
from weaviate.util import generate_uuid5
import weaviate
import json
import pandas as pd
# 读取 PubMed 数据
df = pd.read_csv("PubMed Multi Label
Text Classification Dataset Processed.csv")
|
接下来,我们可以建立与 Weaviate 集群的连接:
client
= weaviate.Client(
url ="XXX",# 替换为你的 Weaviate 端点地址
auth_client_secret=weaviate.auth.AuthApiKey(api_key="XXX"),#
替换为你的 Weaviate 实例的 API 密钥
additional_headers ={
"X-OpenAI-Api-Key":"XXX"#
替换为你的推理 API 密钥(如 OpenAI 的)
}
) |
在将数据向量化并写入向量数据库之前,我们需要先定义 schema(模式)。这里我们定义了要从 CSV
文件中向量化的列。 如前所述,在本教程的开始阶段,我只打算向量化标题(title)和摘要(abstract)这两列。
class_obj ={
# 类定义
"class":"articles",
# 属性定义
"properties":[
{
"name":"title",
"dataType":["text"],
},
{
"name":"abstractText",
"dataType":["text"],
},
],
# 指定使用的向量化器
"vectorizer":"text2vec-openai",
# 模块配置
"moduleConfig":{
"text2vec-openai":{
"vectorizeClassName":True,
"model":"ada",
"modelVersion":"002",
"type":"text"
},
"qna-openai":{
"model":"gpt-3.5-turbo-instruct"
},
"generative-openai":{
"model":"gpt-3.5-turbo"
}
},
}
|
然后,我们将这个 schema 推送到我们的 Weaviate 集群中:
client.schema.create_class(class_obj)
|
你可以通过查看 Weaviate 控制台界面来确认 schema 是否成功创建。
现在,我们已经定义好了 schema,就可以将所有数据写入向量数据库了。
import
logging
import numpy as np
# 配置日志记录
logging.basicConfig(level=logging.INFO, format='%(asctime)s
%(levelname)s %(message)s')
# 将无穷大替换为 NaN,然后再填充 NaN
df.replace([np.inf,-np.inf], np.nan, inplace=True)
df.fillna('', inplace=True)
# 将列转换为字符串类型
df['Title']= df['Title'].astype(str)
df['abstractText']= df['abstractText'].astype(str)
# 记录数据类型
logging.info(f"Title column type: {df['Title'].dtype}")
logging.info(f"abstractText column type:
{df['abstractText'].dtype}")
# 批量写入向量数据库
with client.batch(
batch_size=10,# 指定批大小
num_workers=2,# 启用并行处理
)as batch:
for index, row in df.iterrows():
try:
question_object ={
"title": row.Title,
"abstractText": row.abstractText,
}
batch.add_data_object(
question_object,
class_name="articles",
uuid=generate_uuid5(question_object)
)
exceptExceptionas e:
logging.error(f"Error processing row
{index}: {e}")
|
要检查数据是否成功写入集群,可以运行以下命令:
client.query.aggregate("articles").with_meta_count().do()
|
出于某种原因,我的 10,000 行数据中只有 9997 行被向量化了。
使用向量数据库进行语义搜索(Semantic search using vector database)
当我们谈到在向量数据库中进行“语义”搜索时,我们的意思是:术语会通过 LLM API 向量化映射到向量空间中,而这些
API 是在大量非结构化内容上训练得到的。这意味着向量会考虑术语的上下文关系。
例如,如果在训练数据中,“Mark Twain(马克·吐温)”多次出现在“Samuel Clemens(塞缪尔·克莱门斯)”附近,那么这两个术语的向量在向量空间中应当彼此接近。同样,如果“口腔癌(Mouth
Cancer)”在训练数据中经常与“口腔肿瘤(Mouth Neoplasms)”一起出现,那么一篇关于口腔癌的文章,其向量应当靠近一篇关于口腔肿瘤的文章的向量。
你可以通过运行一个简单的查询来验证是否有效:
response
=(
client.query
.get("articles",["title","abstractText"])
.with_additional(["id"])
.with_near_text({"concepts":["Mouth
Neoplasms"]})
.with_limit(10)
.do()
)
print(json.dumps(response, indent=4))
|
查询结果如下:
•文章 1:“Gingival metastasis as first sign of multiorgan
dissemination of epithelioid malignant mesothelioma.”
这篇文章讲述的是一项关于恶性间皮瘤(一种肺癌形式)扩散至牙龈的研究。研究测试了不同治疗方法(如化疗、胸膜剥脱术和放疗)对该癌症的影响。
这是一篇非常合适的返回结果 —— 它涉及牙龈肿瘤(gingival neoplasms),而牙龈肿瘤是口腔肿瘤(mouth
neoplasms)的一个子类。
•文章 2:“Myoepithelioma of minor salivary gland origin.
Light and electron microscopical study.”
这篇文章讲述的是从一个 14 岁男孩的牙龈中切除的一种肿瘤,该肿瘤已经扩散到上颌部分,由起源于唾液腺的细胞组成。
这同样是一个合适的返回结果 —— 它描述的是一个从口腔中切除的肿瘤。
•文章 3:“Metastatic neuroblastoma in the mandible. Report
of a case.”
这篇文章是关于一位 5 岁男孩下颌出现癌症的病例研究。它确实讲的是癌症,但严格意义上讲不属于口腔癌
—— 下颌肿瘤(mandibular neoplasms)不是 MeSH 词表中口腔肿瘤的子类。
这就是我们所说的语义搜索 —— 这些文章的标题和摘要中都没有出现“mouth(口腔)”这个词:
•第一篇文章讲的是牙龈肿瘤(gingival neoplasms),这是口腔肿瘤的一个子类;
•第二篇讲的是起源于唾液腺的牙龈肿瘤,唾液腺和牙龈肿瘤都属于口腔肿瘤的范畴;
•第三篇讲的是下颌肿瘤,虽然从解剖位置上接近口腔,但根据 MeSH 术语不属于口腔肿瘤。
尽管如此,向量数据库仍然“理解”了下颌与口腔在语义上的相似性,这正是其语义检索能力的体现。
使用向量数据库进行相似度搜索(Similarity search using vector database)
我们还可以使用向量数据库来查找相似的文章。我选择了一篇在上面“mouth neoplasms(口腔肿瘤)”查询中返回的文章,标题为:
“Gingival metastasis as first sign of multiorgan
dissemination of epithelioid malignant mesothelioma.”
使用这篇文章的 ID,我们可以在向量数据库中查询所有与之相似的实体:
response =(
client.query
.get("articles",["title","abstractText"])
.with_near_object({
"id":"a7690f03-66b9-5d17-b765-8c6eb21f99c8"#
给定文章的 ID
})
.with_limit(10)
.with_additional(["distance"])
.do()
)
print(json.dumps(response, indent=2))
|
返回结果按相似度排序。相似度是通过在向量空间中的“距离”来计算的。 正如你所见,排名第一的就是这篇“Gingival”文章
—— 毕竟,一篇文章与自身的相似度是最高的。
其他返回的相关文章包括:
•文章 4:“Feasability study of screening for malignant
lesions in the oral cavity targeting tobacco users.”
这篇文章与口腔癌相关,但重点在于如何让吸烟者参与癌症筛查,而不是研究治疗方法。
•文章 5:“Extended Pleurectomy and Decortication for
Malignant Pleural Mesothelioma Is an Effective and
Safe Cytoreductive Surgery in the Elderly.”
本文是关于在老年人中通过胸膜切除术和剥脱术治疗恶性胸膜间皮瘤(肺部癌症)的一项研究。
虽然它的主题是间皮瘤的治疗,因此在主题上与“牙龈肿瘤”文章有些相似,但它并不涉及牙龈或口腔癌。
•文章 3(上文提到):“Metastatic neuroblastoma in the mandible.
Report of a case.”
再次出现的是关于那位患下颌神经母细胞瘤的 5 岁男孩的病例。这确实是癌症相关,但严格来说不是口腔癌,也不是真正关于治疗效果的研究,和“牙龈肿瘤”文章的主旨不同。
可以说,这些文章与我们最初的“牙龈肿瘤”文章在某种程度上是相似的。但要判断它们具体有多相似、相似搜索的效果到底如何,其实很大程度上取决于用户对“相似”的定义:
•如果你关注的是其他关于间皮瘤治疗的文章,而原文中“癌症扩散到牙龈”这一点并不重要,那么文章 5是最相似的。
•如果你更关心任何形式的口腔癌,包括治疗和预防,那么文章 4会更相似。
向量数据库的一个缺点是:它像一个“黑箱” ——
我们无法知道这些文章为何被选中返回,也无法明确判断向量搜索是基于哪些特征做出“相似性判断”的。
使用向量数据库实现检索增强生成(RAG)
下面是一个使用向量数据库进行检索,然后将结果发送给大语言模型(LLM)进行摘要的示例 —— 这就是
RAG 的典型用法。
response =(
client.query
.get("articles",["title","abstractText"])
.with_near_text({
"concepts":["Gingival metastasis
as first sign of multiorgan dissemination of
epithelioid malignant mesothelioma"]
})
.with_generate(
single_prompt="Please explain this article
{title} like you would to someone without a
medical degree."
)
.with_limit(1)
.do()
)
print(json.dumps(response, indent=4))
|
你可以看到返回结果如下:
“当然!这篇文章讲述了一个人患有一种被称为上皮型恶性间皮瘤的癌症的案例。这种癌症通常起始于肺或腹部的膜层。但在这个案例中,癌症扩散到身体其他部位的首个迹象是出现在牙龈上(即牙龈转移)。
癌症转移意味着癌细胞已经从原始肿瘤扩散到了身体其他部位。在这个案例中,癌症先扩散到了牙龈,然后再扩散到其他器官。这很重要,因为这表明癌症在被发现之前已经是晚期,并且已经扩散到多个器官。
总体而言,这篇文章强调了癌症早期检测和监测的重要性,以及癌症可能会扩散到意想不到的身体部位。”
|
实际上,我对这个回答有些失望。 摘要中并没有体现文章的核心信息 —— 原文摘要明确说明这是一项针对
13 名患有转移性恶性间皮瘤患者的治疗研究,涵盖了不同治疗方法及其结果。 而生成的 RAG 输出却只说成是“一个人”的案例,完全没有提到这是一个研究性文章。
我们不要只总结一篇文章,而是尝试对多篇文章进行汇总。 在下一个示例中,我们使用相同的搜索关键词(Mouth
Neoplasms),然后将排名前 3 的文章连同以下提示词一起发送给 LLM:“请用项目符号列出这些文章的关键信息,使其对没有医学背景的人也容易理解。”
response =(
client.query
.get(collection_name,["title","abstractText"])
.with_near_text({"concepts":["Mouth
Neoplasms"]})
.with_limit(3)
.with_generate(
grouped_task="Summarize the key information
here in bullet points. Make it understandable
to someone without a medical degree."
)
.do()
)
print(response["data"]["Get"]["Articles"][0]["_additional"]["generate"]["groupedResult"])
|
返回结果如下:
-恶性间皮瘤转移至口腔较为罕见,且多发生在颌骨而非软组织
-这种类型癌症的平均生存期为9-12个月
-针对13名接受新辅助化疗与手术治疗的患者的研究表明,中位生存期为11个月
-一位患者以牙龈肿块作为多器官复发的首发症状
-对于有间皮瘤病史的患者,即使是在不常见部位的新生病变,也应进行活检
-起源于小唾液腺的肌上皮瘤可能表现出恶性潜能的特征
-下颌转移性神经母细胞瘤极为罕见,在儿童中可表现为颌骨溶骨性病变及乳磨牙松动 |
我认为这个结果比之前的回答要好得多 —— 它提到了第 1 篇文章中的研究内容、治疗方法和结局。
倒数第二条项目符号是对“起源于小唾液腺的肌上皮瘤(Myoepithelioma)”那篇文章的描述,看起来是准确的单句总结。最后一条是关于前面提到的第
3 篇文章(下颌神经母细胞瘤病例),同样是准确的一行摘要。
这一结果更符合我们期望的 RAG 输出,涵盖了多个结果并体现出其关键信息。
第 2 步:使用知识图谱进行数据检索
以下是我们如何使用知识图谱进行语义搜索、相似性搜索和 RAG 的高级概览:
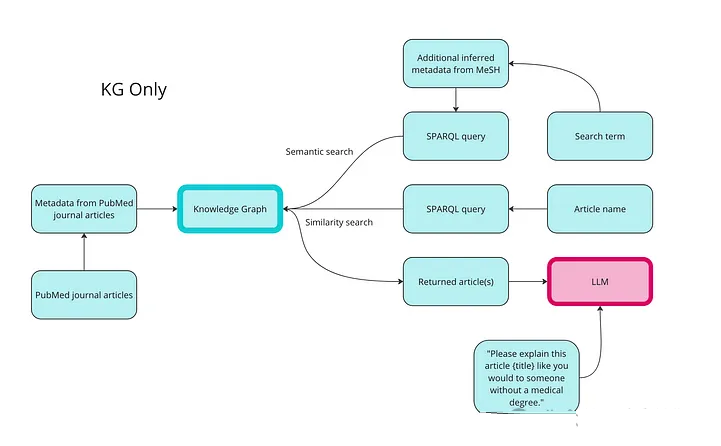
使用知识图谱检索数据的第一步是将数据转换为 RDF 格式。下面的代码会为所有数据类型创建类和属性,然后用文章和
MeSH 术语的实例进行填充。我还为发布日期和访问级别创建了属性,并为演示目的填充了一些随机值。
from rdflib importGraph, RDF,
RDFS,Namespace,URIRef,Literal
from rdflib.namespaceimport SKOS, XSD
import pandas as pd
import urllib.parse
import random
from datetime import datetime, timedelta
# 创建一个新的 RDF 图
g =Graph()
# 定义命名空间
schema =Namespace('http://schema.org/')
ex =Namespace('http://example.org/')
prefixes ={
'schema': schema,
'ex': ex,
'skos': SKOS,
'xsd': XSD
}
for p, ns in prefixes.items():
g.bind(p, ns)
# 定义类和属性
Article=URIRef(ex.Article)
MeSHTerm=URIRef(ex.MeSHTerm)
g.add((Article, RDF.type, RDFS.Class))
g.add((MeSHTerm, RDF.type, RDFS.Class))
title =URIRef(schema.name)
abstract=URIRef(schema.description)
date_published =URIRef(schema.datePublished)
access =URIRef(ex.access)
g.add((title, RDF.type, RDF.Property))
g.add((abstract, RDF.type, RDF.Property))
g.add((date_published, RDF.type, RDF.Property))
g.add((access, RDF.type, RDF.Property))
# 清洗和解析 MeSH 术语的函数
def parse_mesh_terms(mesh_list):
if pd.isna(mesh_list):
return[]
return[term.strip().replace(' ','_')for term
in mesh_list.strip("[]'").split(',')]
# 创建有效 URI 的函数
def create_valid_uri(base_uri, text):
if pd.isna(text):
returnNone
sanitized_text = urllib.parse.quote(text.strip().replace('
','_').replace('"','').replace('<','').replace('>','').replace("'","_"))
returnURIRef(f"{base_uri}/{sanitized_text}")
# 生成近五年内的随机日期的函数
def generate_random_date():
start_date = datetime.now()- timedelta(days=5*365)
random_days = random.randint(0,5*365)
return start_date + timedelta(days=random_days)
# 生成 1 到 10 之间随机访问值的函数
def generate_random_access():
return random.randint(1,10)
# 在此加载你的 DataFrame
# df = pd.read_csv('your_data.csv')
# 遍历 DataFrame 中的每一行,创建 RDF 三元组
for index, row in df.iterrows():
article_uri = create_valid_uri("http://example.org/article",
row['Title'])
if article_uri isNone:
continue
# 添加 Article 实例
g.add((article_uri, RDF.type,Article))
g.add((article_uri, title,Literal(row['Title'],
datatype=XSD.string)))
g.add((article_uri,abstract,Literal(row['abstractText'],
datatype=XSD.string)))
# 添加随机的发布日期和访问级别
random_date = generate_random_date()
random_access = generate_random_access()
g.add((article_uri, date_published,Literal(random_date.date(),
datatype=XSD.date)))
g.add((article_uri, access,Literal(random_access,
datatype=XSD.integer)))
# 添加 MeSH 术语
mesh_terms = parse_mesh_terms(row['meshMajor'])
for term in mesh_terms:
term_uri = create_valid_uri("http://example.org/mesh",
term)
if term_uri isNone:
continue
# 添加 MeSH 术语实例
g.add((term_uri, RDF.type,MeSHTerm))
g.add((term_uri, RDFS.label,Literal(term.replace('_','
'), datatype=XSD.string)))
# 将文章与 MeSH 术语关联
g.add((article_uri, schema.about, term_uri))
# 将图谱序列化为文件(可选)
g.serialize(destination='ontology.ttl', format='turtle')
|
使用知识图谱进行语义搜索(Semantic search using a knowledge graph)
现在我们可以测试语义搜索了。不过,“语义”这个词在知识图谱中的含义略有不同。
在知识图谱中,我们依赖的是文档所关联的标签(tags)及其在 MeSH 分类体系中的关系,来实现语义推理。例如,一篇文章可能是关于“唾液腺肿瘤”(Salivary
Neoplasms,指唾液腺的癌症),但仍然被标记为“口腔肿瘤”(Mouth Neoplasms)。
我们不会只查询所有被标记为“口腔肿瘤”的文章,还会寻找所有比“口腔肿瘤”更窄的概念。MeSH 词表中不仅包含术语定义,还包含如“上位词(broader)”和“下位词(narrower)”这样的关系。
fromSPARQLWrapperimportSPARQLWrapper,
JSON
def get_concept_triples_for_term(term):
sparql =SPARQLWrapper("https://id.nlm.nih.gov/mesh/sparql")
query = f"""
PREFIX rdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs:<http://www.w3.org/2000/01/rdf-schema#>
PREFIX meshv:<http://id.nlm.nih.gov/mesh/vocab#>
PREFIX mesh:<http://id.nlm.nih.gov/mesh/>
SELECT ?subject ?p ?pLabel ?o ?oLabel
FROM <http://id.nlm.nih.gov/mesh>
WHERE {{
?subject rdfs:label "{term}"@en.
?subject ?p ?o .
FILTER(CONTAINS(STR(?p),"concept"))
OPTIONAL {{?p rdfs:label ?pLabel .}}
OPTIONAL {{?o rdfs:label ?oLabel .}}
}}
"""
sparql.setQuery(query)
sparql.setReturnFormat(JSON)
results = sparql.query().convert()
triples =set()# 使用 set 来去重
for result in results["results"]["bindings"]:
obj_label = result.get("oLabel",{}).get("value","No
label")
triples.add(obj_label)
# 将术语本身也加入结果中
triples.add(term)
return list(triples)# 转为列表便于处理
def get_narrower_concepts_for_term(term):
sparql =SPARQLWrapper("https://id.nlm.nih.gov/mesh/sparql")
query = f"""
PREFIX rdf:<http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs:<http://www.w3.org/2000/01/rdf-schema#>
PREFIX meshv:<http://id.nlm.nih.gov/mesh/vocab#>
PREFIX mesh:<http://id.nlm.nih.gov/mesh/>
SELECT ?narrowerConcept ?narrowerConceptLabel
WHERE {{
?broaderConcept rdfs:label "{term}"@en.
?narrowerConcept meshv:broaderDescriptor ?broaderConcept
.
?narrowerConcept rdfs:label ?narrowerConceptLabel
.
}}
"""
sparql.setQuery(query)
sparql.setReturnFormat(JSON)
results = sparql.query().convert()
concepts =set()
for result in results["results"]["bindings"]:
subject_label = result.get("narrowerConceptLabel",{}).get("value","No
label")
concepts.add(subject_label)
return list(concepts)
def get_all_narrower_concepts(term, depth=2,
current_depth=1):
# 创建一个字典存储术语及其下位概念
all_concepts ={}
# 获取该术语的直接下位概念
narrower_concepts = get_narrower_concepts_for_term(term)
all_concepts[term]= narrower_concepts
# 如果未达到设定深度,递归查询下位概念的下位概念
if current_depth < depth:
forconceptin narrower_concepts:
child_concepts = get_all_narrower_concepts(concept,
depth, current_depth +1)
all_concepts.update(child_concepts)
return all_concepts
# 获取术语的同义词(替代名称)和所有下位概念
term ="Mouth Neoplasms"
alternative_names = get_concept_triples_for_term(term)
all_concepts = get_all_narrower_concepts(term,
depth=2)# 可根据需要调整深度
# 输出替代名称
print("Alternative names:", alternative_names)
print()
# 输出下位概念
for broader, narrower in all_concepts.items():
print(f"Broader concept: {broader}")
print(f"Narrower concepts: {narrower}")
print("---")
|
以下是“口腔肿瘤(Mouth Neoplasms)”的所有替代名称和下位概念。
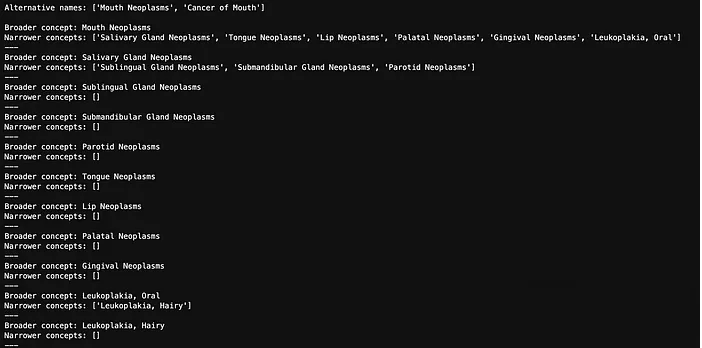
我们将其转化为一个平面的术语列表:
def flatten_concepts(concepts_dict):
flat_list =[]
def recurse_terms(term_dict):
for term, narrower_terms in term_dict.items():
flat_list.append(term)
if narrower_terms:
recurse_terms(dict.fromkeys(narrower_terms,[]))#
使用空字典递归
recurse_terms(concepts_dict)
return flat_list
# 扁平化概念字典
flat_list = flatten_concepts(all_concepts)
|
然后我们将术语转换为 MeSH URI,以便将其包含在我们的 SPARQL 查询中:
# 将 MeSH 术语转换为 URI
def convert_to_mesh_uri(term):
formatted_term = term.replace(" ","_").replace(",","_").replace("-","_")
returnURIRef(f"http://example.org/mesh/_{formatted_term}_")
# 将术语转换为 URI
mesh_terms =[convert_to_mesh_uri(term)for
term in flat_list]
|
接着,我们编写一个 SPARQL 查询,查找所有被标记为“口腔肿瘤(Mouth Neoplasms)”、其替代名称“口腔癌(Cancer
of Mouth)”或任何下位术语的文章:
from rdflib importURIRef
query ="""
PREFIX schema:<http://schema.org/>
PREFIX ex:<http://example.org/>
SELECT ?article ?title ?abstract?datePublished
?access ?meshTerm
WHERE {
?article a ex:Article;
schema:name ?title ;
schema:description ?abstract;
schema:datePublished ?datePublished ;
ex:access ?access ;
schema:about ?meshTerm .
?meshTerm a ex:MeSHTerm.
}
"""
# 用于存储文章及其关联的 MeSH 术语的字典
article_data ={}
# 针对每个 MeSH 术语运行查询
for mesh_term in mesh_terms:
results = g.query(query, initBindings={'meshTerm':
mesh_term})
# 处理结果
for row in results:
article_uri = row['article']
if article_uri notin article_data:
article_data[article_uri]={
'title': row['title'],
'abstract': row['abstract'],
'datePublished': row['datePublished'],
'access': row['access'],
'meshTerms':set()
}
# 将 MeSH 术语添加到该文章的术语集
article_data[article_uri]['meshTerms'].add(str(row['meshTerm']))
# 按照匹配的 MeSH 术语数量对文章进行排名
ranked_articles = sorted(
article_data.items(),
key=lambda item: len(item[1]['meshTerms']),
reverse=True
)
# 获取排名前 3 的文章
top_3_articles = ranked_articles[:3]
# 输出结果
for article_uri, data in top_3_articles:
print(f"Title: {data['title']}")
print("MeSH Terms:")
for mesh_term in data['meshTerms']:
print(f" - {mesh_term}")
print()
|
返回的文章包括:
•文章 2(来自上文):“起源于小唾液腺的肌上皮瘤。光学和电子显微镜研究。”
•文章 4(来自上文):“针对烟草使用者的口腔恶性病变筛查可行性研究。”
•文章 6:“胚胎致死异常视觉蛋白 HuR 与环氧化酶-2 在口腔鳞状细胞癌中的表达关系。”
这篇文章是关于一项研究,旨在确定一种叫做 HuR 的蛋白质的存在是否与环氧化酶-2(COX-2)水平的升高有关,后者在癌症发展和癌细胞扩散中起着作用。具体来说,研究重点在于口腔鳞状细胞癌,一种口腔癌。
这些结果与我们从向量数据库中得到的结果相似。每篇文章都与口腔肿瘤相关。知识图谱方法的好处在于我们能得到可解释性——我们确切知道为什么这些文章被选择。文章
2 被标记为“牙龈肿瘤”和“唾液腺肿瘤”;文章 4 和 6 都被标记为“口腔肿瘤”。由于文章 2 被标记了两个与我们查询术语匹配的术语,因此它被排名为第一。 | 







