| 编辑推荐: |
本文主要介绍了一种知识图谱与大模型的紧耦合新范式:Think-on-Graph
相关内容。希望对你的学习有帮助。
本文来自于微信公众号AI随想录 ,由火龙果软件Linda编辑,推荐。 |
|
一、研究背景
LLM 的局限性:大型语言模型虽在多种任务中表现出色,但存在幻觉问题,尤其在需要深度推理的场景中:
难以处理超出预训练知识范围的问题或多跳推理问题;
缺乏可解释性和知识溯源能力,且知识更新成本高、速度慢。
现有LLM与KG结合的不足:传统“LLM ⊕ KG”范式中,LLM仅将问题转换为KG搜索命令(如SPARQL),不直接参与图推理,其效果依赖
KG 的完整性。若KG存在缺失关系(如“多数成分”),则无法生成正确答案。
新范式的提出:针对上述问题,提出“LLM ⊗ KG”紧耦合范式:LLM 作为智能代理,与KG协同工作,在推理的每一步动态探索KG中的实体和关系,补充彼此能力(例如通过KG中的三元组和LLM固有知识共同补全缺失信息)。
二、核心方法
ToG是“LLM ⊗ KG”范式的具体实现,通过LLM在KG上迭代执行波束搜索,动态探索推理路径,具体流程如下:
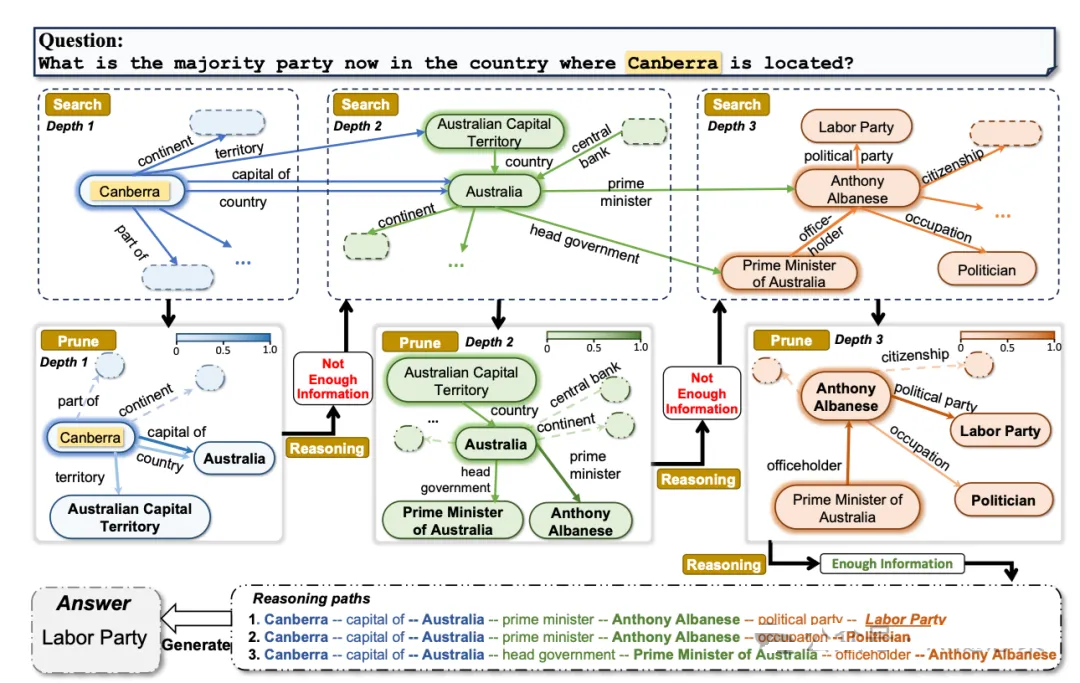
2.1 ToG核心步骤
初始化:给定问题,ToG利用底层大语言模型定位知识图谱上推理路径的初始实体,即自动提取问题中的主题实体,获取问题的Top-N主题实体(主题实体数量可能少于N)
,以此初始化Top-N推理路径。
探索:在第D次迭代开始时,每条路径由D-1个三元组组成(每完成1次迭代,推理路径会增加1个三元组;因此第D次迭代开始时,累计完成了(D-1)次迭代,路径长度为(D-1)个三元组)。探索阶段旨在利用LLM从当前顶级实体集的相邻实体中识别最相关的顶级实体,扩展顶级推理路径。该阶段包含关系探索和实体探索两个子步骤:
关系探索:深度为1、宽度为N的波束搜索过程,由搜索和剪枝组成。搜索时,为每个推理路径搜索链接到尾部实体的关系并聚合成集合;剪枝时,利用LLM根据问题文字信息从候选关系集中选择出新的以尾部关系结尾的Top-N推理路径。
问题:“姚明曾效力的NBA球队位于美国哪个州?”
当前推理路径:已有的一条路径为(姚明,曾效力于,休斯顿火箭队)(尾部实体是“休斯顿火箭队”)。
宽度N=2(即保留2个最相关的关系)。
搜索阶段:
查询“休斯顿火箭队”在知识图谱中的关联关系,得到候选关系集合:{“位于”“所属联盟”“主场馆”“成立时间”}。
剪枝阶段:
LLM结合问题“位于美国哪个州”,判断“位于”(直接关联地理位置)和“主场馆”(间接关联所在城市,进而关联州)最相关,筛选出这2个关系。
结果:
形成2条新的推理路径:
(姚明→曾效力于→休斯顿火箭队)→(休斯顿火箭队→位于→?)
(姚明→曾效力于→休斯顿火箭队)→(休斯顿火箭队→主场馆→?)
|
实体探索:同样由搜索和剪枝构成。搜索时,依据关系探索得到的新推理路径和尾部关系集,查询探索候选实体集并聚合;剪枝时,利用LLM选择新的以特定尾部实体结尾的Top-N推理路径。完成两个探索后,重建长度增加1的新顶级推理路径。
问题:“姚明曾效力的NBA球队位于美国哪个州?”
关系探索后得到的路径(尾部是关系):
(姚明→曾效力于→休斯顿火箭队)→(休斯顿火箭队→位于→?)
此时尾部关系是 “位于”,N=2,即计划保留2条路径。
搜索阶段:
针对关系“位于”和头部实体“休斯顿火箭队”,从知识图谱中查询候选实体集:{休斯顿市、德克萨斯州、美国、北美大陆}。
剪枝阶段:
LLM结合问题“位于美国哪个州”,判断“德克萨斯州”(直接对应“州”)和“美国”(虽不直接是州,但包含州)最相关,筛选出这2个实体。
结果:
形成2条新的推理路径(每条路径增加1个完整三元组):
(姚明→曾效力于→休斯顿火箭队)→(休斯顿火箭队→位于→德克萨斯州)
(姚明→曾效力于→休斯顿火箭队)→(休斯顿火箭队→位于→美国)
|
推理:LLM 评估当前推理路径是否足够回答问题。若足够,则生成答案;否则重复探索,直至达到最大深度或得出结论。若达到最大深度仍无结论,ToG仅依据LLM固有知识生成答案。
调用大模型次数:整个推理过程包含D个探索阶段、D个评估步骤和1个生成步骤,最多需要2ND(关系探索+实体探索)+D(评估)+1(生成)次调用LLM。
2.2 ToG-R核心步骤
初始化:给定问题后,ToG-R利用底层大语言模型定位知识图谱上推理路径的初始实体,即从问题中提取主题实体,以此作为推理的起点,形成初始关系链集合。与ToG不同,ToG-R探索的是由主题实体开始的前N个关系链,而非基于三元组的推理路径。
探索:
关系搜索:在第D次迭代开始时,根据第D-1次迭代的尾实体的链接,通过执行预定义的查询来获得关系候选集。接着,利用LLM从候选集中挑选出以某尾关系结束的top-N推理路径,完成关系剪枝,从而确定本轮迭代中较为重要的关系,为后续实体探索提供方向。
问题:“故宫的建造者是谁?”
当前推理路径:假设第1次迭代最终指向“故宫”,路径可能是“故宫→位于→北京”,尾实体为“故宫”。
搜索阶段:
以尾实体“故宫”为起点,在知识图中查询所有直接关联的关系,得到候选关系集合:{“建造于”“建造者”“类型”“面积”“别称”}。
剪枝阶段:
从候选集中挑出与“故宫的建造者是谁?”最相关的关系,保留前2条(N=2)路径。
结果:
形成2条新的推理路径:
(故宫→建造者)
(故宫→建造于)
|
实体搜索:依据关系探索得到的新推理路径和尾部关系集,查询探索候选实体集并聚合。与ToG不同的是,ToG-R在此处不会利用LLM进行筛选,而是随机从候选集中采样N个实体,作为新的以特定尾部实体结尾的推理路径,这是ToG-R与ToG的主要区别之一,通过随机采样来简化流程,减少LLM的调用次数。
问题:“故宫的建造者是谁?”
第2次迭代的“关系探索”已筛选出Top-2尾部关系:建造者和建造于(N=2,即保留2条路径)。
当前推理路径:假设第1次迭代最终指向“故宫”,路径可能是“故宫→位于→北京”,尾实体为“故宫”。
搜索阶段:
根据“关系探索”得到的“尾部关系集”(建造者、建造于),从知识图中查询每个关系对应的实体(即“关系的尾实体”),并汇总成候选实体集。
针对关系建造者:知识图中存在“故宫→建造者→朱棣”,因此候选实体为朱棣。
针对关系建造于:知识图中存在“故宫→建造于→明朝”,因此候选实体为明朝。
聚合后,候选实体集为:{朱棣, 明朝}。
随机采样阶段:
由于候选实体集正好有2个实体(朱棣、明朝),随机采样后保留这两个实体。
结果:
形成2条新的推理路径:
原路径(故宫)→建造者→朱棣(新尾实体:朱棣)
原路径(故宫)→建造于→明朝(新尾实体:明朝)
|
推理:使用LLM评估当前推理路径是否包含足够信息回答问题。若足够,则直接基于当前路径生成答案;否则继续执行关系探索、实体探索和推理步骤,直至路径长度达到最大深度。若达到最大深度仍无法回答问题,则基于语言模型的固有知识生成答案。
调用大模型次数:相较于ToG,ToG-R最多需要调用ND+D+1次LLM。
三、优缺点及改进方向
3.1 优点
增强深度推理能力:ToG通过多跳推理路径,显著提升了LLM在复杂知识密集型任务中的表现。例如,在GraiQA和Zero-Shot
RE数据集上,ToG的性能分别提升了51.8%和42.9%。
知识可追溯性:ToG提供了清晰的推理路径,使得推理过程可追溯、可解释,便于用户理解和修正错误,这种特性在需要高可信度的场景中尤为重要
。
灵活性和效率:ToG是一个插件式框架,可以与多种LLM和知识图谱兼容。它还通过波束搜索和剪枝策略,减少了不必要的计算开销,提高了推理效率
。
无需额外训练:ToG不需要对LLM进行额外的微调,即可在现有模型上部署,降低了部署成本 。
提升性能:在多个基准数据集上,ToG的性能显著优于传统方法,如Chain-of-Thought和Self-Consistency等。例如在CWQ数据集上,ToG的表现比CoT提高了17.47%。
3.2 不足
计算成本较高:尽管ToG通过波束搜索和剪枝策略优化了效率,但其多跳推理过程仍然需要较高的计算资源。特别是在大规模知识图谱上,推理路径的生成和评估可能非常耗时。
知识图谱的不完整性:ToG的性能依赖于知识图谱的质量和完整性。如果知识图谱中存在缺失或错误的信息,可能会导致推理路径的偏差或错误。
对LLM的依赖性:ToG的性能在很大程度上依赖于LLM的推理能力。如果LLM本身存在局限性(如幻觉问题),则ToG的输出也可能受到影响。
路径选择的不确定性:虽然ToG通过波束搜索生成多个推理路径,但最终答案的选择仍然依赖于评分模型。如果评分模型不够强大,可能会导致错误的答案被选中。
3.3 改进方向
优化评分模型:目前ToG使用的评分模型在某些情况下可能不够强大,导致错误的答案被选中。
引入外部反馈机制:ToG可以结合人工反馈或专家知识,进一步优化推理路径的选择。例如通过人工审核和修正知识图谱中的错误信息,可以提高推理的准确性和可信度
。
扩展知识图谱的覆盖范围:ToG的性能受限于知识图谱的完整性。未来可以探索如何动态更新和扩展知识图谱,以覆盖更多领域和场景。
结合其他推理方法:ToG可以与其他推理方法(如Chain-of-Thought、Tree of Thoughts等)结合,形成更强大的推理框架。例如,ToG可以作为主推理引擎,而其他方法作为辅助工具,以提高推理的多样性和鲁棒性。
优化计算效率:ToG的多跳推理过程可能较为耗时。未来可以探索更高效的图搜索算法,如基于采样的方法或近似推理技术,以减少计算开销。
四、总结
ToG通过“LLM ⊗ KG”范式实现了LLM与KG的深度协同,提升了LLM的深度推理能力、可解释性和知识更新效率。其免训练、低成本、高性能的特点,为解决LLM幻觉问题和知识密集型任务提供了新方案。 | 






 订阅
订阅