| 编辑推荐: |
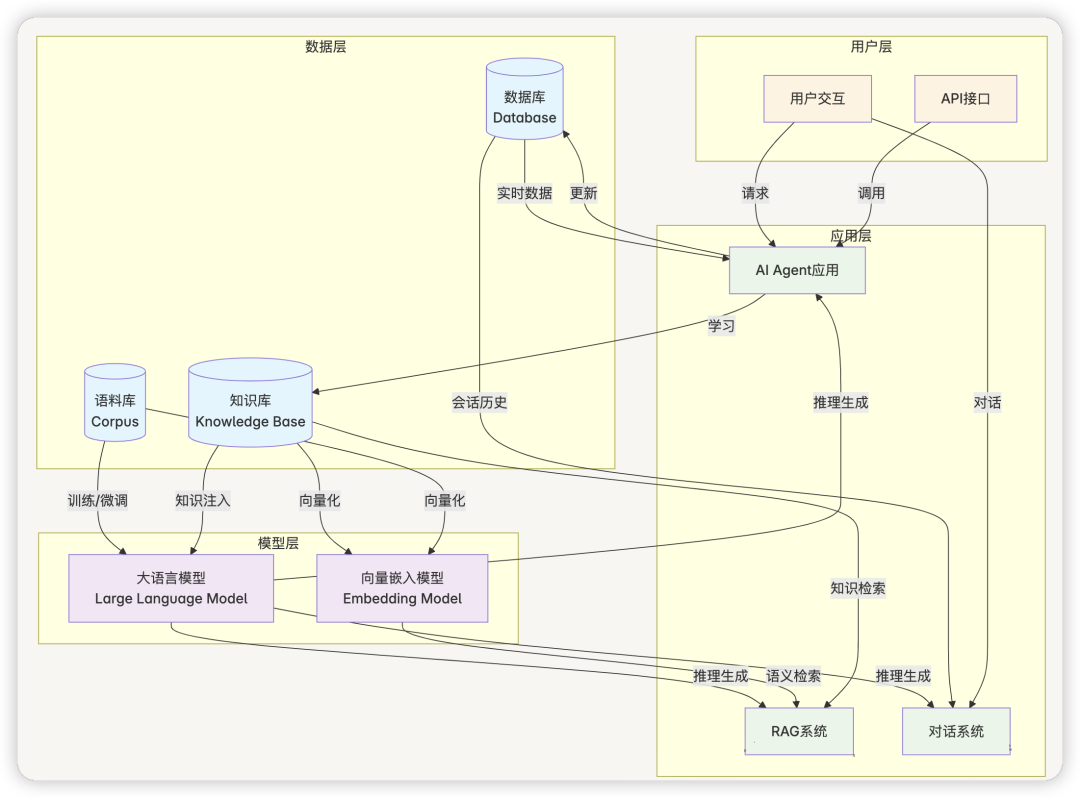
本文将探讨数据库、语料库、知识库和大语言模型应用之间的关系,及 AI Agent 技术架构,希望对你的学习有帮助。
本文来自于Hello Tech技术派 ,由火龙果软件Linda编辑,推荐。 |
|
一、核心概念定义
1. 数据库(Database)
定义 :结构化数据的存储和管理系统,支持高效的数据检索、更新和管理操作。
在 AI Agent 中的作用 :
- 存储用户交互历史
- 管理业务数据和配置信息
- 支持实时数据查询和更新
- 提供事务性数据操作保障
典型应用场景 :
- 用户会话管理
- 业务规则配置
- 实时数据查询
- 系统状态跟踪
2. 语料库(Corpus)
定义 :用于训练和微调大语言模型的原始文本数据集合,通常包含大量的自然语言文本。
在AI Agent中的作用 :
- 提供模型训练的基础数据
- 支持领域特定的模型微调
- 为模型提供语言理解能力
- 构建特定领域的语言表示
典型应用场景 :
- 模型预训练
- 领域适应性微调
- 语言风格学习
- 专业术语理解
3. 知识库(Knowledge Base)
定义 :结构化或半结构化的知识存储系统,包含事实、规则、概念及其关系的集合。
在AI Agent中的作用 :
- 提供准确的事实性信息
- 支持推理和决策过程
- 减少模型幻觉问题
- 实现知识的动态更新
典型应用场景 :
- RAG (检索增强生成)系统
- 专家系统构建
- 事实核查
- 领域知识查询
4. 大语言模型应用(LLM Application)
定义 :基于大语言模型构建的智能应用系统,能够理解和生成自然语言,执行复杂的认知任务。
核心能力 :
- 自然语言理解与生成
- 多轮对话管理
- 任务规划与执行
- 知识推理与应用
二、大语言模型的固有缺陷与挑战
1. 数据时效性问题
问题描述 :
- 训练数据截止时间 :大模型的知识更新存在时间滞后,无法获取最新信息
- 静态知识结构 :模型参数固化后难以实时更新
- 领域知识陈旧 :特定行业的快速变化无法及时反映
对ToB业务的影响 :
- 无法提供最新的市场信息和政策变化
- 产品信息、价格策略等实时数据缺失
- 法规合规要求的更新滞后
2. 幻觉问题( Hallucination )
问题描述 :
- 事实性错误 :生成看似合理但实际错误的信息
- 虚构细节 :编造不存在的数据、引用或案例
- 逻辑不一致 :在复杂推理中出现自相矛盾
对ToB业务的影响 :
- 客户服务中提供错误信息影响信任度
- 业务决策支持的准确性受到质疑
- 合规风险和法律责任问题
3. 领域专业性不足
问题描述 :
- 通用性与专业性矛盾 :通用模型在特定领域深度不够
- 行业术语理解偏差 :专业概念的理解可能不准确
- 业务流程认知缺失 :缺乏对企业具体业务流程的深度理解
对ToB业务的影响 :
- 无法满足行业专家级别的咨询需求
- 业务流程自动化的准确性不足
- 专业报告生成质量有限
三、AI Agent 介绍
1. AI Agent 的定义与特征
定义 :AI Agent 是一个能够感知环境、做出决策并采取行动以实现特定目标的智能系统。在大语言模型时代,AI Agent 通过整合 LLM 的语言理解能力、外部工具调用能力和环境交互能力,成为能够自主完成复杂任务的智能代理。
核心特征 :
- 自主性( Autonomy ) :能够在没有人类直接干预的情况下独立运行
- 反应性(Reactivity) :能够感知环境变化并及时响应
- 主动性(Proactivity) :能够主动采取行动以实现目标
- 社交性(Social Ability) :能够与其他 Agent 或人类进行交互协作
2. AI Agent 的架构模式
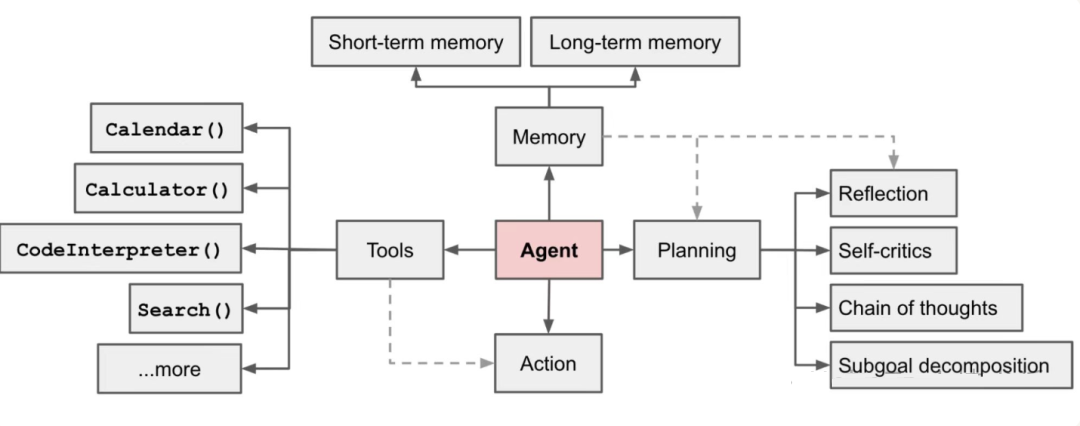
2.1 经典 Agent 架构
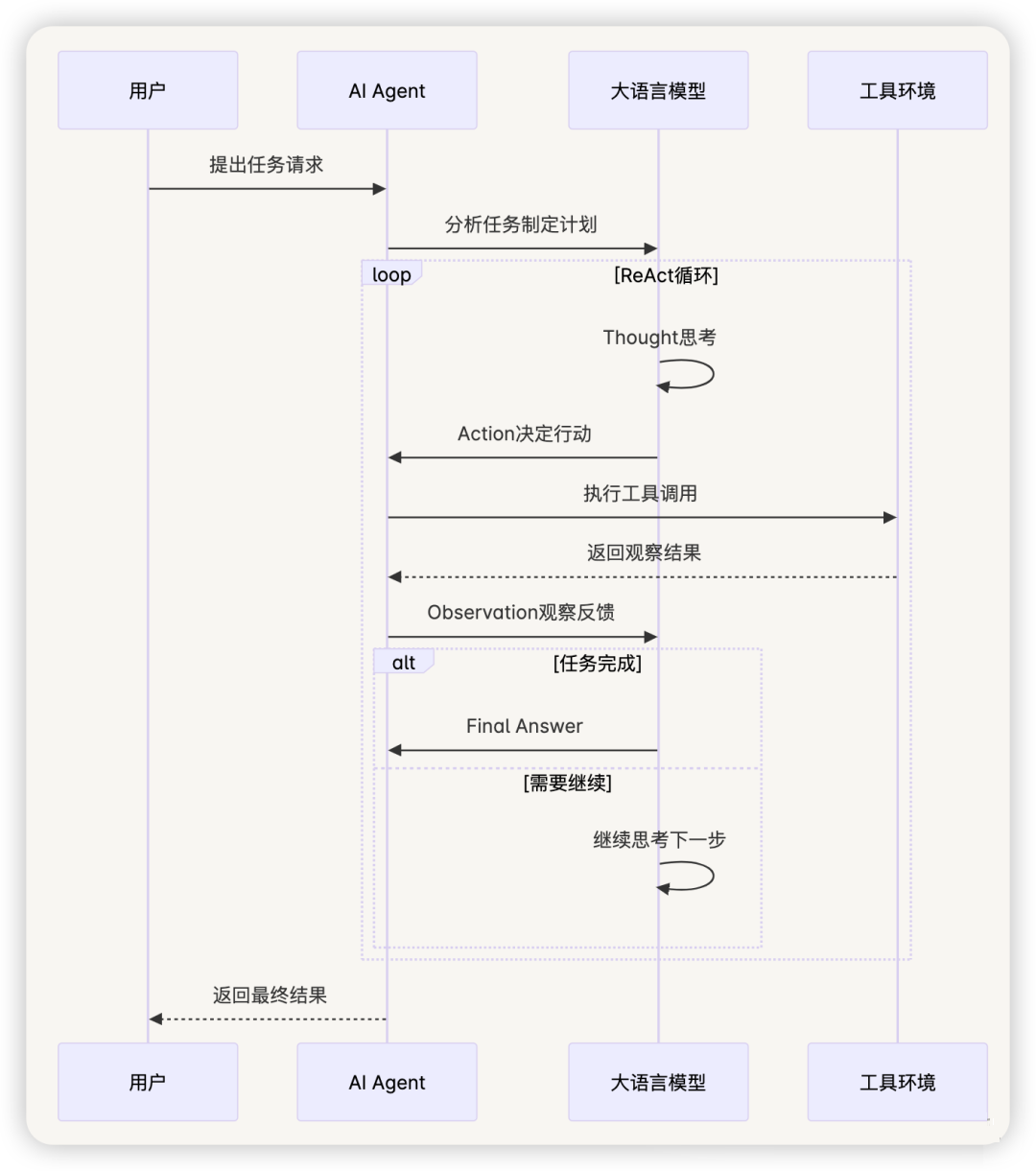
2.2 ReAct 架构模式
ReAct(Reasoning + Acting) 是当前最流行的 Agent 架构模式,结合了推理和行动:
3. AI Agent 的核心组件
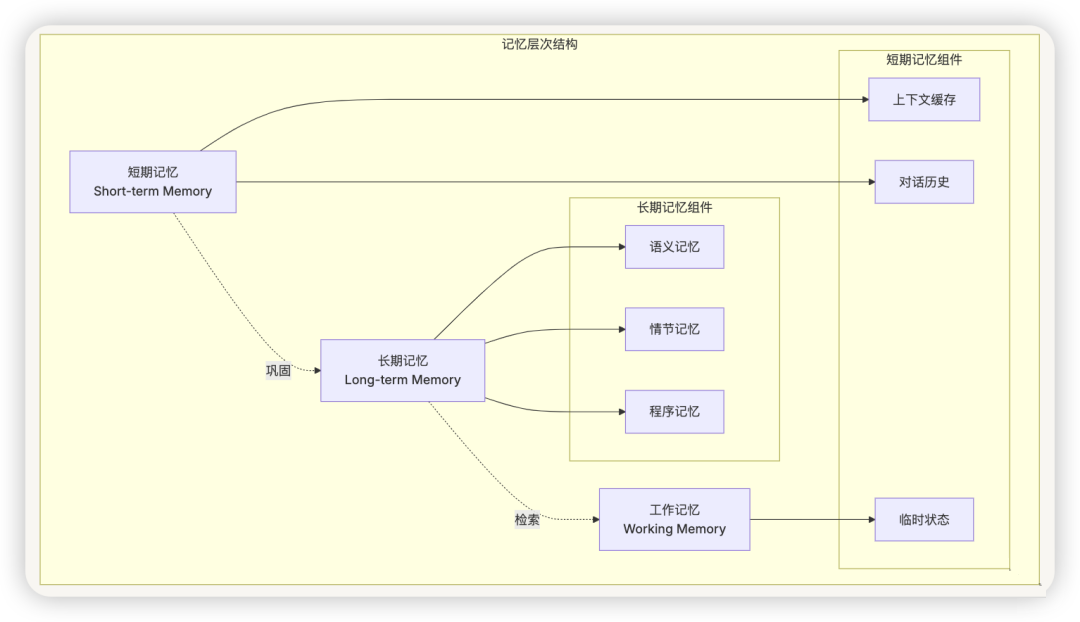
3.1 记忆系统(Memory System)
短期记忆 :
- 工作记忆 :当前任务的上下文信息
- 对话历史 :近期的交互记录
- 临时状态 :执行过程中的中间结果
长期记忆 :
- 语义记忆 :事实性知识和概念
- 情节记忆 :具体的经历和事件
- 程序记忆 :技能和操作流程
记忆架构 :
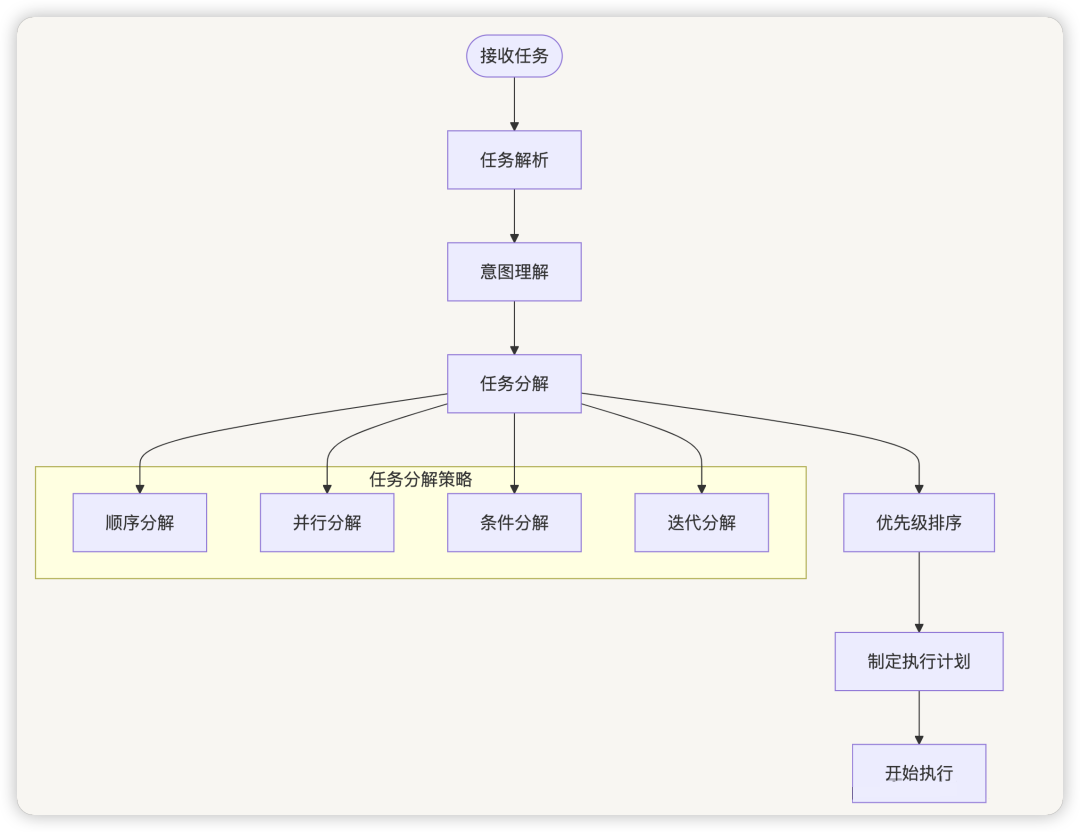
3.2 规划系统(Planning System)
层次化规划 :
- 战略层 :长期目标和总体策略
- 战术层 :中期计划和子任务分解
- 操作层 :具体的执行步骤
规划算法 :
- 分层规划 :将复杂任务分解为子任务
- 动态规划 :根据环境变化调整计划
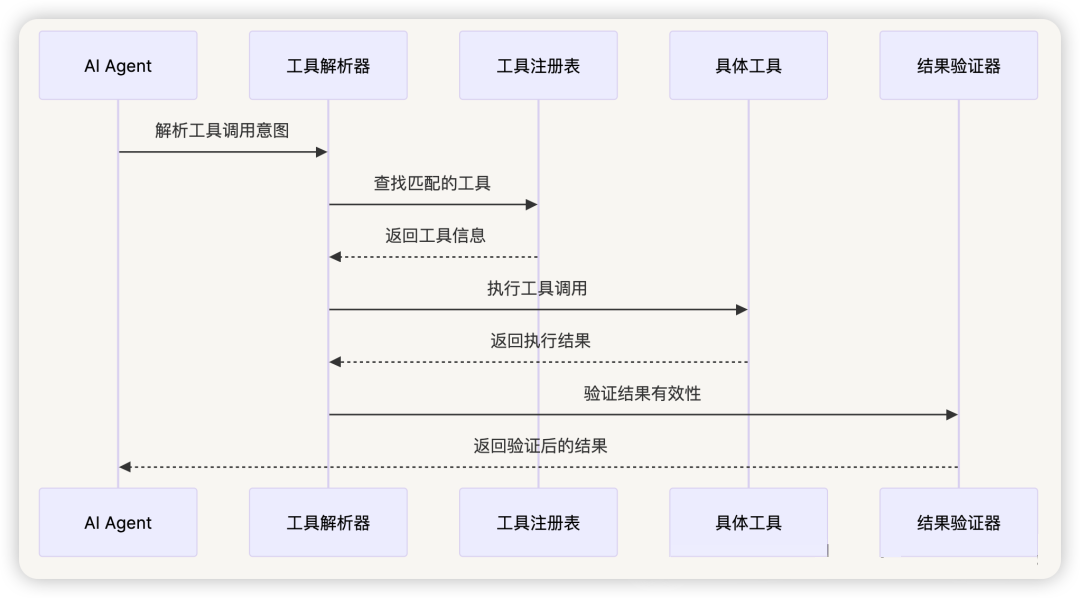
3.3 工具系统(Tool System)
工具分类 :
| 工具类型 | 功能描述 | 典型示例 |
| 信息检索 |
获取外部信息 |
搜索引擎、数据库查询、API调用 |
| 计算工具 |
数学和逻辑计算 |
计算器、代码执行器、数据分析 |
| 通信工具 |
与外部系统交互 |
邮件发送、消息推送、文件传输 |
| 创作工具 |
内容生成和编辑 |
图像生成、文档编辑、代码生成 |
| 控制工具 |
系统操作和控制 |
文件操作、系统命令、设备控制 |
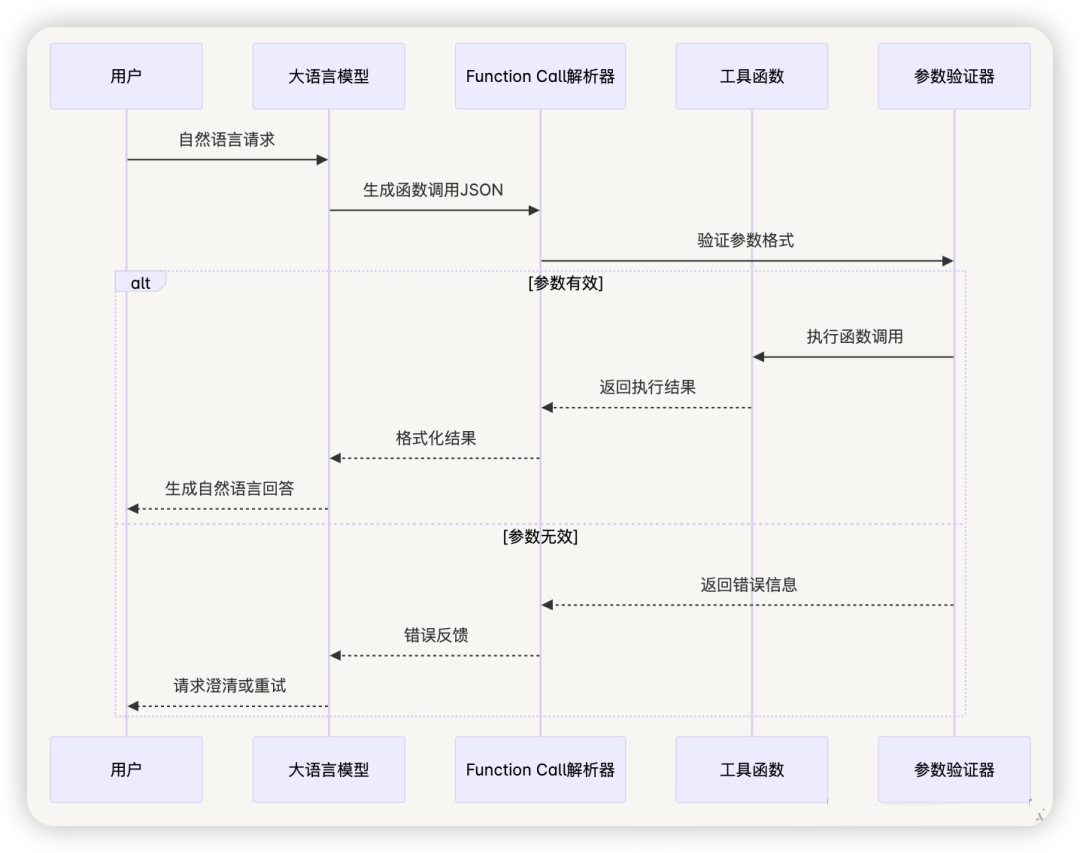
3.3.1 Function Call 机制
定义与原理 :
Function Call 是大语言模型与外部工具交互的标准化接口,允许模型以结构化的方式调用预定义的函数,实现从自然语言到程序化操作的转换。
核心特性 :
- 结构化输出 :模型输出标准化的JSON格式函数调用
- 类型安全 :支持参数类型验证和约束
- 并行调用 :支持同时调用多个函数
- 错误处理 :提供完整的错误反馈机制
Function Call 工作流程 :
Function Call 示例 :
{
"function_call": {
"name": "get_weather",
"arguments": {
"location": "北京",
"date": "2024-01-15",
"units": "celsius"
}
}
}
|
最佳实践 :
- 函数设计 :保持函数功能单一、参数明确
- 错误处理 :提供详细的错误信息和恢复建议
- 性能优化 :合理设计函数粒度,避免过度细分
- 安全控制 :实施权限验证和输入sanitization
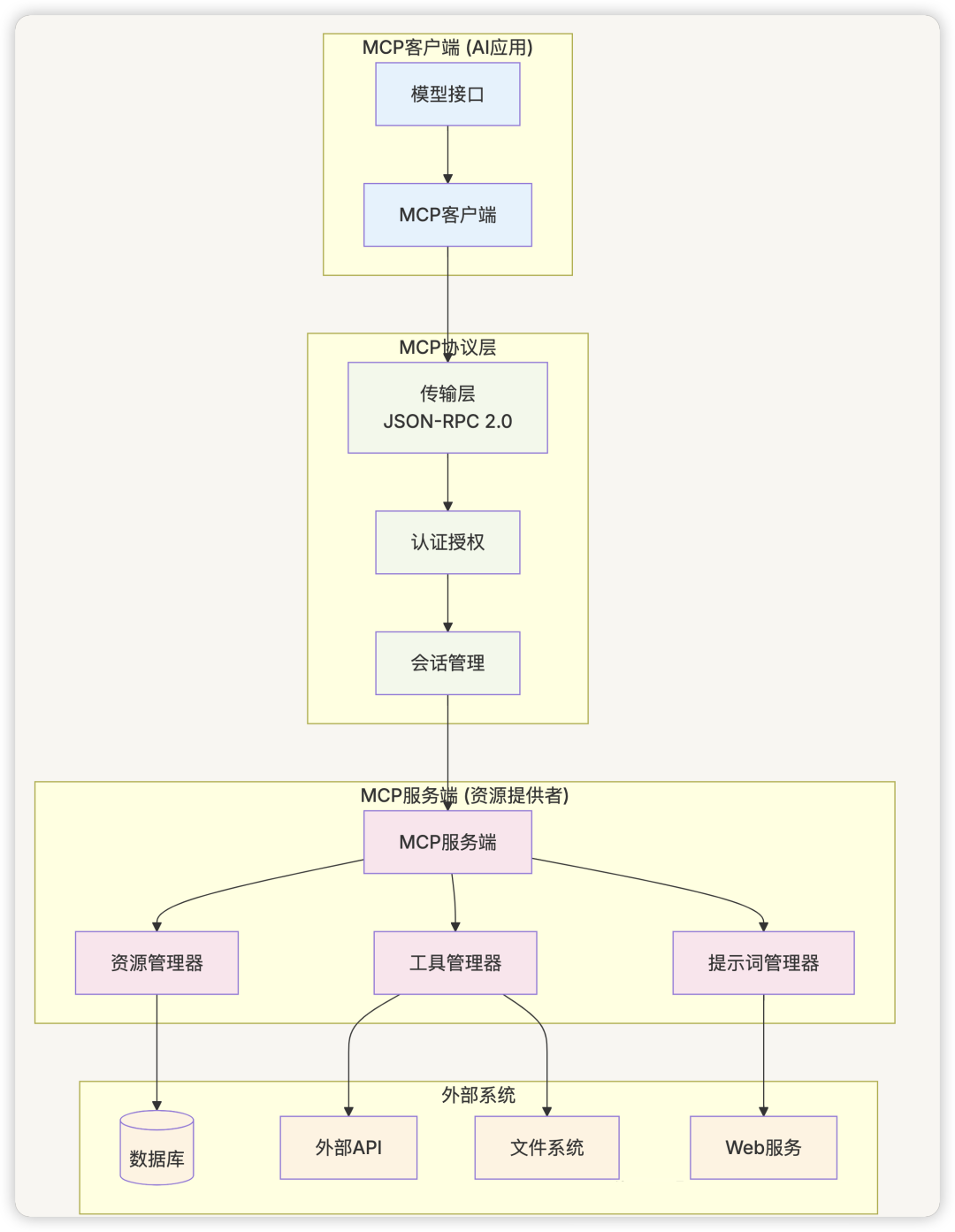
3.3.2 MCP(Model Context Protocol)
定义与背景 :
MCP是 Anthropic 提出的开放标准协议,旨在标准化 AI 模型与外部数据源和工具的连接方式,提供安全、可扩展的上下文集成解决方案。
核心架构 :
MCP 核心组件 :
-
资源(Resources) :
- 提供只读数据访问
- 支持URI标识和内容类型
- 实现数据的安全暴露
-
工具(Tools) :
- 执行特定操作的函数
- 支持参数验证和结果返回
- 提供操作的标准化接口
-
提示词(Prompts) :
- 预定义的提示词模板
- 支持参数化和动态生成
- 实现提示词的复用和管理
MCP 协议特性 :
| 特性 | 描述 | 优势 |
| 标准化 |
统一的协议规范 |
提高互操作性 |
| 安全性 |
内置认证和授权 |
保护敏感数据 |
| 可扩展 |
支持自定义扩展 |
适应不同需求 |
| 异步支持 |
支持长时间运行任务 |
提高系统响应性 |
| 版本管理 |
协议版本兼容性 |
确保向后兼容 |
MCP 实施示例 :
{
"jsonrpc": "2.0",
"method": "resources/read",
"params": {
"uri": "file:///path/to/document.pdf"
},
"id": 1
}
|
MCP vs 传统 API 对比 :
| 维度 | 传统API | MCP |
| 标准化程度 |
各自实现 |
统一标准 |
| 安全模型 |
自定义 |
内置安全 |
| 上下文管理 |
无标准 |
原生支持 |
| 开发复杂度 |
高 |
低 |
| 维护成本 |
高 |
低 |
工具调用流程 :
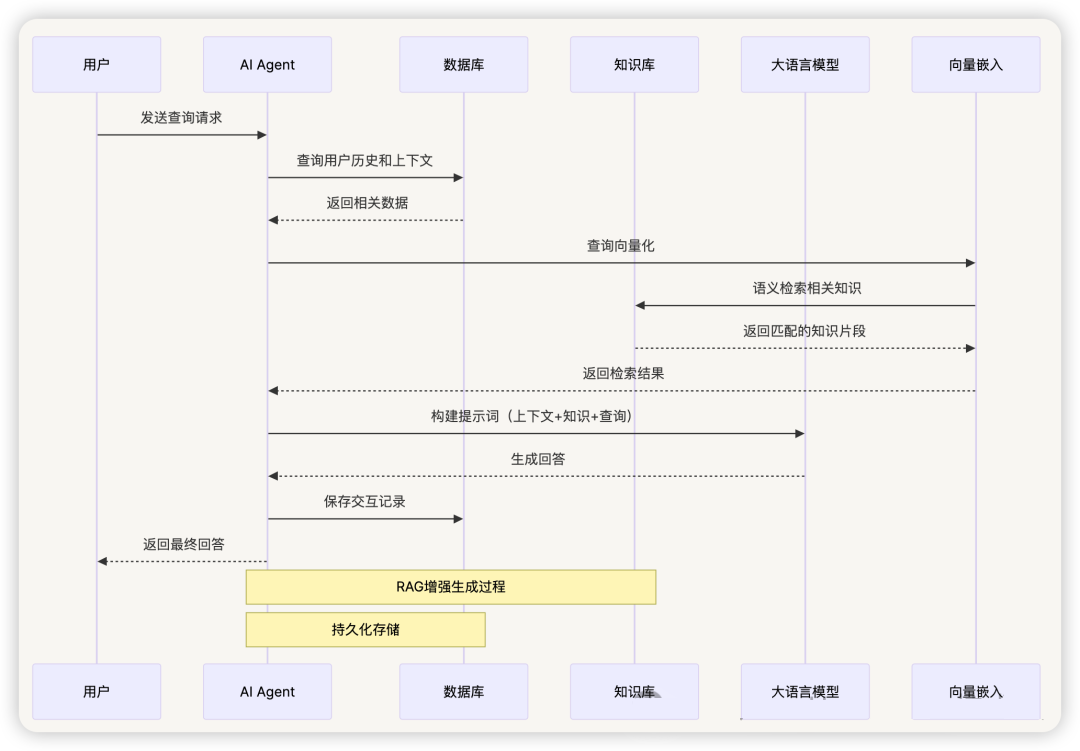
4. AI Agent 的工作流程
4.1 任务理解与分解
5. AI Agent 的类型与应用
5.1 按功能分类
对话型 Agent :
- 特点 :专注于自然语言交互
- 应用 :客服机器人、虚拟助手、教育辅导
- 技术要点 :对话管理、情感理解、个性化回应
任务型 Agent :
- 特点 :专注于特定任务执行
- 应用 :代码助手、数据分析、文档处理
- 技术要点 :工具集成、流程自动化、结果验证
决策型 Agent :
- 特点 :专注于复杂决策支持
- 应用 :投资顾问、医疗诊断、风险评估
- 技术要点 :多因素分析、不确定性处理、可解释性
创作型 Agent :
- 特点 :专注于内容创作和设计
- 应用 :文案写作、图像设计、音乐创作
- 技术要点 :创意生成、风格控制、质量评估
5.2 按架构分类
单体 Agent :
- 架构 :所有功能集成在一个系统中
- 优点 :简单直接、易于部署
- 缺点 :扩展性有限、维护复杂
多 Agent 系统 :
- 架构 :多个专门化 Agent 协作
- 优点 :模块化、可扩展、专业化
- 缺点 :协调复杂、通信开销
分层Agent :
- 架构 :按功能层次组织
- 优点 :清晰的职责分离、易于管理
- 缺点 :可能存在瓶颈、响应延迟
四、Context Engineering(上下文工程)
1. 定义与核心概念
定义 :Context Engineering 是一门专注于优化AI系统上下文处理的工程学科,通过系统性的方法设计、构建和管理AI模型的输入上下文,以提升模型理解能力、推理质量和输出准确性。
核心目标 :
- 提升理解精度 :通过精心设计的上下文帮助模型更准确理解任务需求
- 增强推理能力 :提供充分的背景信息支持复杂推理过程
- 减少幻觉现象 :通过事实性上下文约束模型输出的准确性
- 优化性能效率 :在有限的上下文窗口内最大化信息价值
2. 上下文的层次结构
3. 上下文工程的关键技术
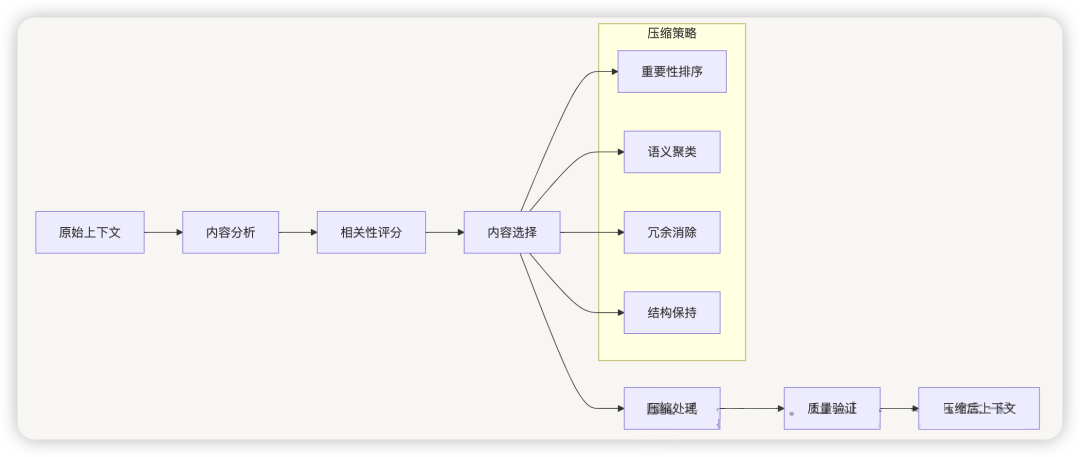
3.1 上下文压缩技术
技术原理 :在有限的上下文窗口内最大化信息密度和相关性。
主要方法 :
| 技术方法 | 原理 | 适用场景 | 压缩比例 |
| 语义摘要 |
提取关键信息点 |
长文档处理 |
70-90% |
| 关键词提取 |
保留核心概念 |
技术文档 |
80-95% |
| 结构化压缩 |
保持逻辑结构 |
代码和配置 |
60-80% |
| 动态裁剪 |
基于相关性裁剪 |
多轮对话 |
50-70% |
压缩流程 :
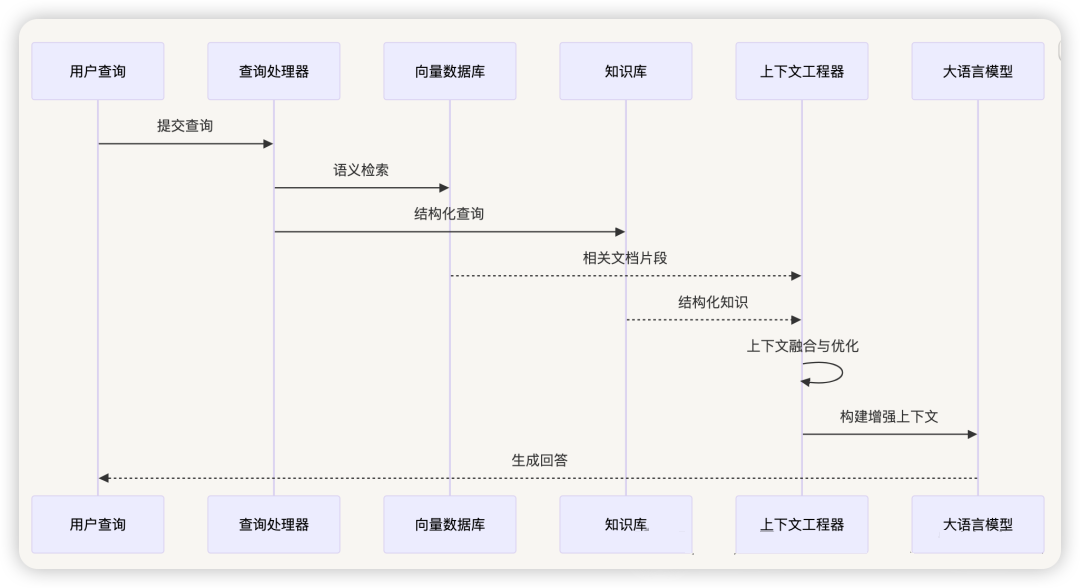
3.2 上下文检索与增强
RAG 增强策略 :
多源上下文融合 :
- 文档上下文 :来自知识库的相关文档
- 数据上下文 :来自数据库的实时信息
- 历史上下文 :用户的交互历史
- 环境上下文 :当前的系统状态和配置
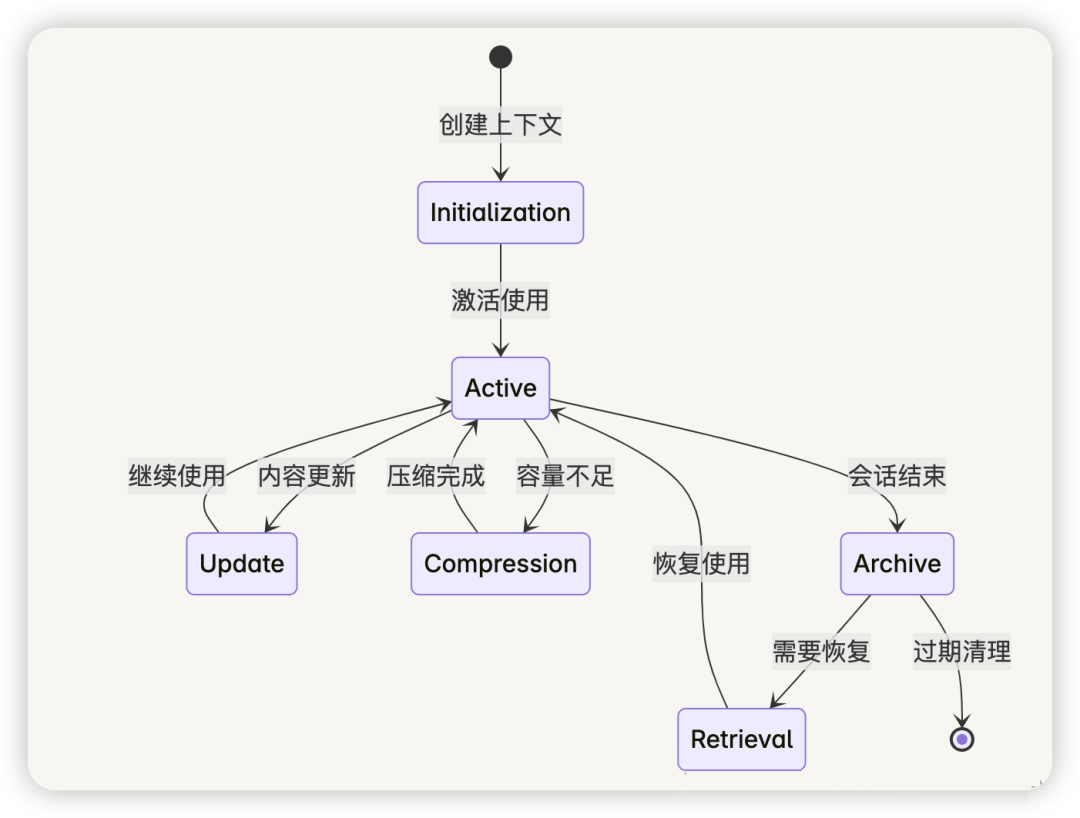
3.3 动态上下文管理
上下文生命周期管理 :
上下文窗口管理策略 :
| 策略类型 | 描述 | > 优点 | 缺点 |
| 滑动窗口 |
保持最近的N个 token |
简单高效 |
可能丢失重要历史信息 |
| 重要性保持 |
基于重要性保留内容 |
保留关键信息 |
计算复杂度高 |
| 分层管理 |
不同层次不同策略 |
灵活性强 |
管理复杂 |
| 语义聚合 |
合并相似内容 |
信息密度高 |
可能损失细节 |
4. 上下文质量评估
4.1 评估维度
相关性(Relevance) :
- 定义 :上下文内容与当前任务的关联程度
- 度量方法 :语义相似度、关键词匹配、专家评分
- 目标值 :>0.8(相似度分数)
完整性(Completeness) :
- 定义 :上下文是否包含完成任务所需的充分信息
- 度量方法 :信息覆盖率、缺失要素分析
- 目标值 :>90%(信息覆盖率)
一致性(Consistency) :
- 定义 :上下文内部信息的逻辑一致性
- 度量方法 :矛盾检测、逻辑验证
- 目标值 :<5%(矛盾率)
时效性(Timeliness) :
- 定义 :上下文信息的时间有效性
- 度量方法 :时间戳检查、更新频率分析
- 目标值 :<24 小时(信息延迟)
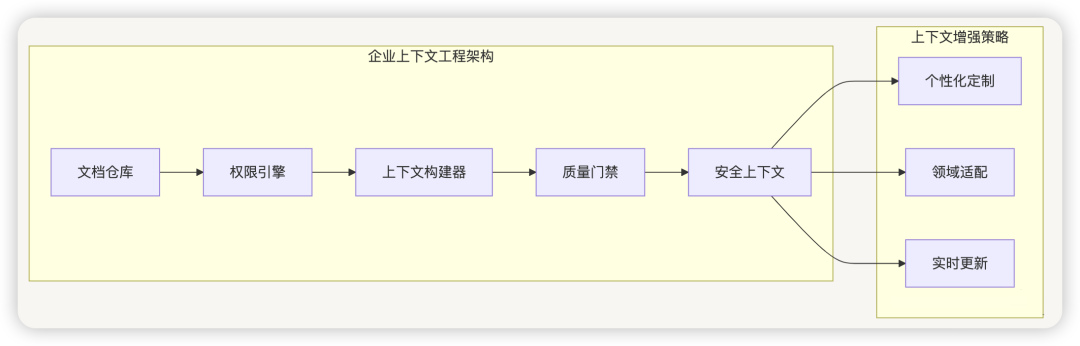
5. ToB 场景中的上下文工程实践
5.1 企业知识管理场景
挑战 :
- 企业文档数量庞大,信息分散
- 专业术语和业务流程复杂
- 权限控制和信息安全要求高
解决方案 :
关键技术 :
- 分层权限上下文 :基于用户角色动态构建上下文
- 领域术语增强 :集成企业词典和知识图谱
- 版本化上下文管理 :支持文档版本变更的上下文更新
5.2 智能客服场景
上下文构建策略 :
| 上下文类型 | 数据源 | 更新频率 | 权重 |
| 客户档案 |
CRM系统 |
实时 |
0.3 |
| 产品信息 |
产品数据库 |
每小时 |
0.25 |
| 历史对话 |
对话记录 |
实时 |
0.2 |
| 知识库 |
FAQ/文档 |
每日 |
0.15 |
| 政策法规 |
外部数据源 |
每周 |
0.1 |
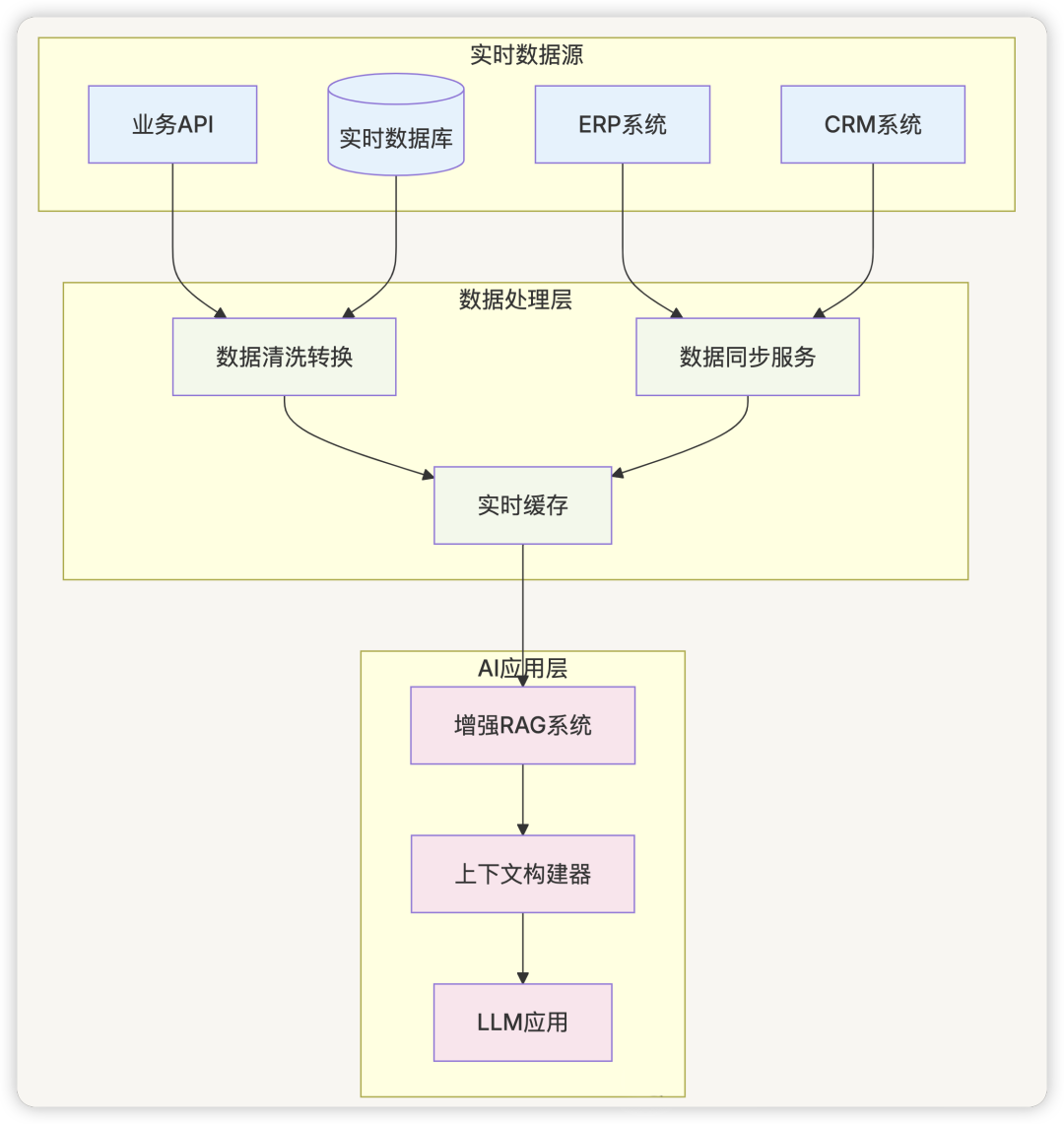
五、架构关系图
六、外部数据集成解决 ToB 业务挑战
1. 实时数据对接策略
2. ToB 场景的具体解决方案
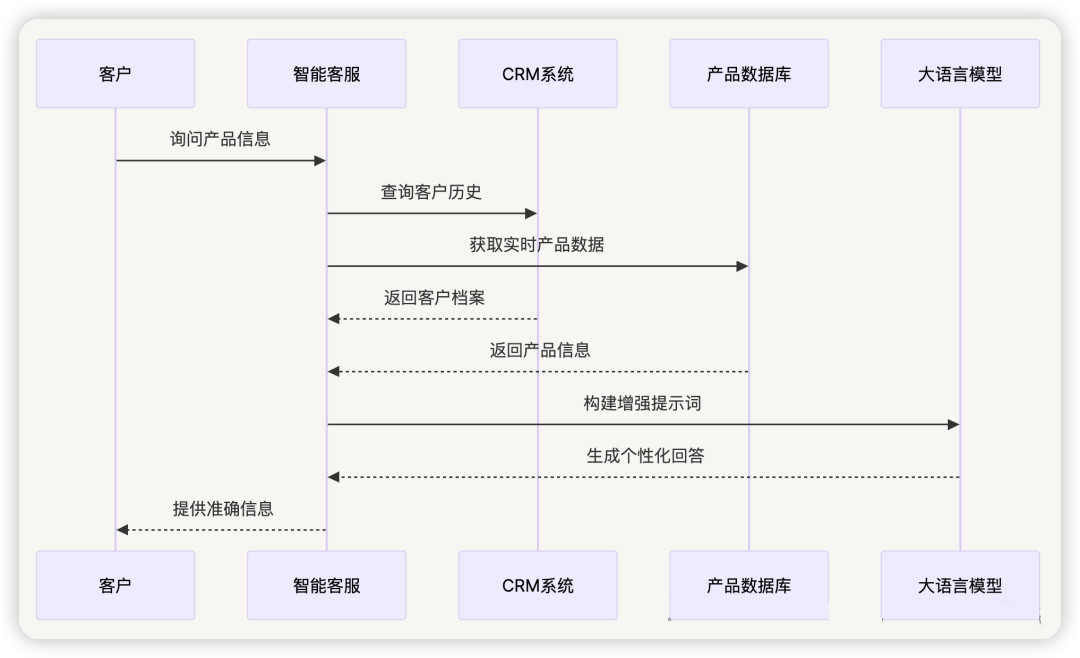
2.1 智能客服系统增强
问题解决 :
- 实时产品信息 :对接产品数据库,确保价格、库存信息准确
- 客户历史查询 :集成 CRM 系统,提供个性化服务
- 政策法规更新 :连接法规数据库,确保合规建议准确性
技术实现 :
2.2 企业知识管理系统
问题解决 :
- 内部文档检索 :建立企业私有知识库,避免信息泄露
- 专业术语理解 :基于企业词典进行模型微调
- 业务流程指导 :集成企业 SOP 和最佳实践
架构设计 :
- 文档向量化 :将企业文档转换为向量表示
- 权限控制 :基于角色的知识访问控制
- 版本管理 :文档更新的自动同步机制
- 审计追踪 :知识使用的完整记录
2.3 业务决策支持系统
问题解决 :
- 数据驱动决策 :集成 BI 系统,提供数据支撑
- 风险评估 :结合历史数据进行风险分析
- 合规检查 :自动化的合规性验证
关键技术 :
- 多源数据融合 :整合 ERP、CRM、财务等系统数据
- 实时分析引擎 :支持复杂查询和分析
- 可解释AI :提供决策依据和推理过程
- A/B测试框架 :验证 AI 建议的有效性
七、数据流转关系
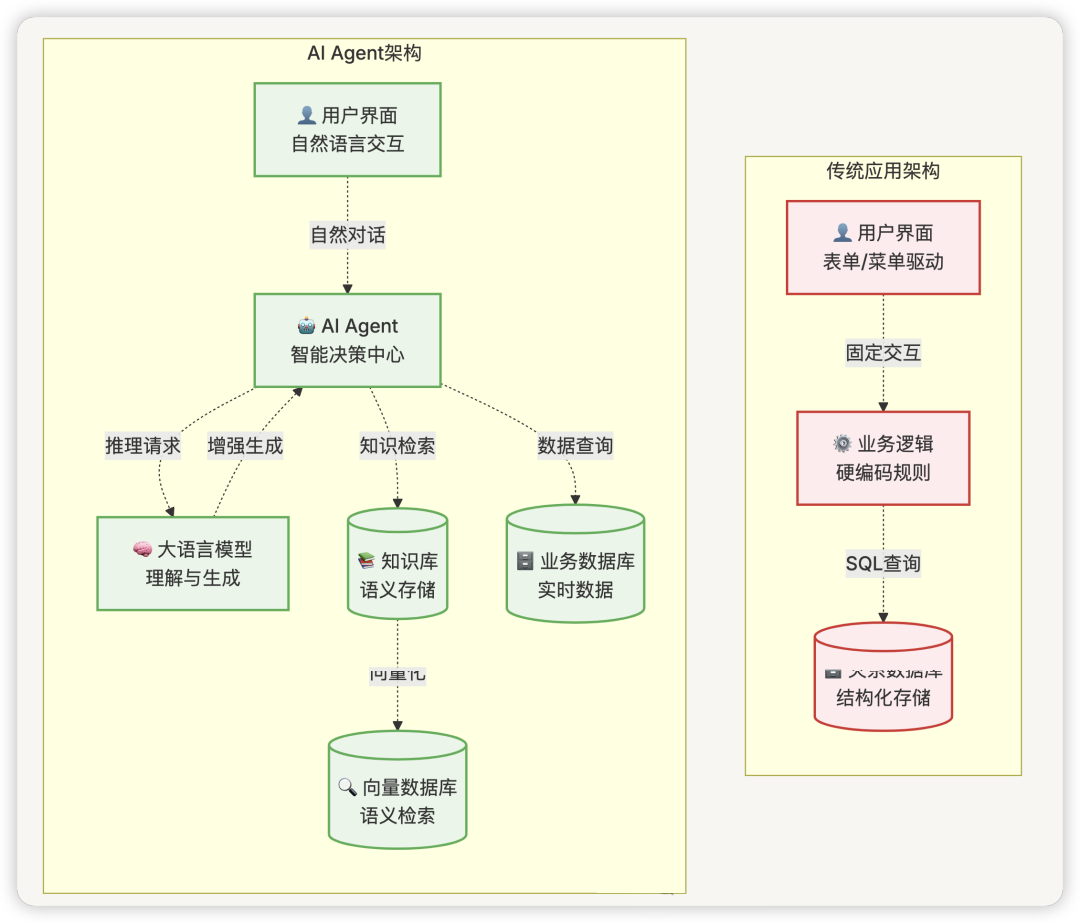
八、技术架构模式的变化
1. 传统模式 vs AI Agent 模式
| 维度 | 传统应用模式 | AI Agent 模式 |
| 架构复杂度 |
简单三层架构
• 用户界面
• 业务逻辑
• 数据库 |
多层智能架构
• 用户界面
• AI Agent层
• 大语言模型
• 知识库系统
• 向量数据库 |
| 数据处理方式 |
结构化查询
• SQL查询
• 预定义逻辑
• 固定流程 |
智能理解与推理
• 自然语言处理
• 语义检索
• 动态决策 |
| 交互模式 |
菜单驱动
• 表单填写
• 按钮点击
• 固定界面 |
对话式交互
• 自然语言输入
• 上下文理解
• 个性化响应 |
| 业务逻辑 |
硬编码规则
• 预设条件判断
• 静态工作流
• 人工维护 |
智能推理
• 动态规则生成
• 自适应流程
• 自主学习 |
| 知识管理 |
数据库存储
• 结构化数据
• 关系型查询
• 人工更新 |
多模态知识库
• 向量化表示
• 语义检索
• 自动更新 |
| 扩展性 |
垂直扩展
• 硬件升级
• 代码重构
• 人工适配 |
水平扩展
• 模型升级
• 知识增量
• 自动适配 |
| 维护成本 |
高维护成本
• 需求变更复杂
• 代码重写
• 测试周期长 |
低维护成本
• 配置化调整
• 知识更新
• 快速迭代 |
| 用户体验 |
学习成本高
• 操作步骤多
• 界面复杂
• 专业培训 |
自然交互
• 即问即答
• 智能引导
• 零学习成本 |
架构对比图 :
九、应用场景
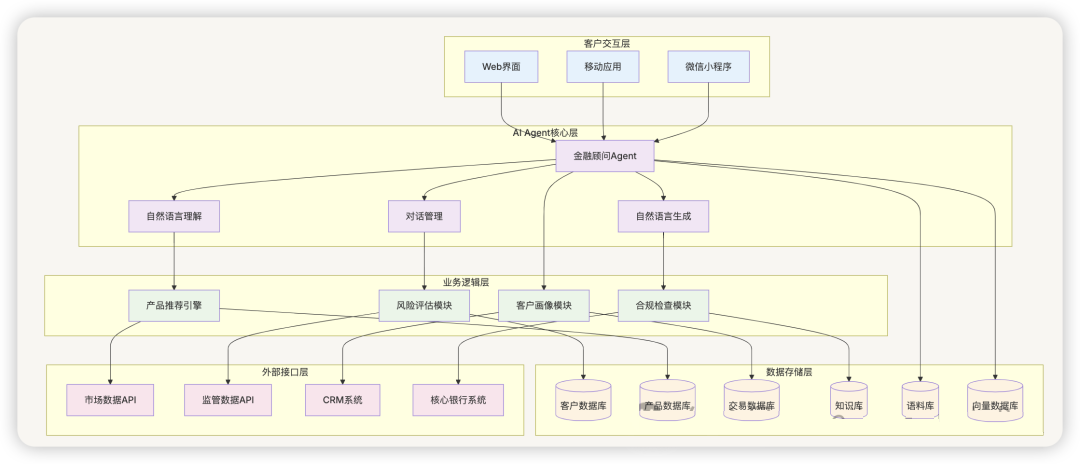
1. 金融产品销售系统
业务背景 :需要构建智能理财顾问系统,为客户提供个性化的金融产品推荐和投资建议。系统需要整合产品信息、市场数据、客户画像和监管要求,提供专业、合规的金融服务。
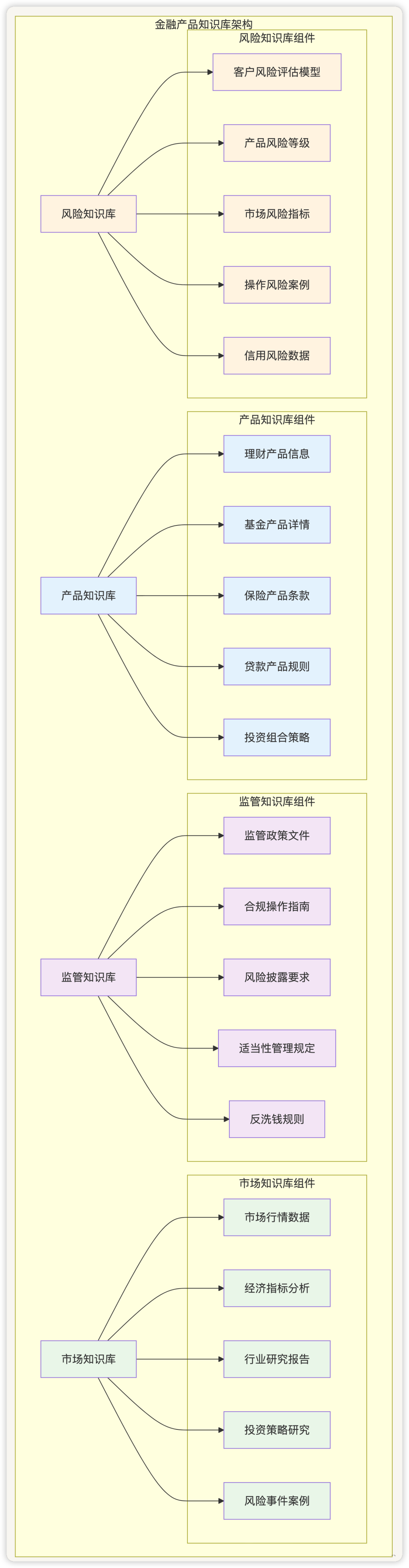
1.1 知识库设计
结构化知识库 :
知识库设计 :
| 知识库类型 | 数据来源 | 更新频率 | 存储格式 | 检索方式 |
| 产品知识库 |
产品说明书、条款文件 |
每日 |
结构化+向量化 |
语义检索+属性筛选 |
| 监管知识库 |
监管文件、政策解读 |
实时 |
文档+知识图谱 |
关键词+语义检索 |
| 市场知识库 |
研报、新闻、数据 |
实时 |
时序数据+文档 |
时间+主题检索 |
| 风险知识库 |
风控模型、历史案例 |
每周 |
模型+案例库 |
相似度匹配 |
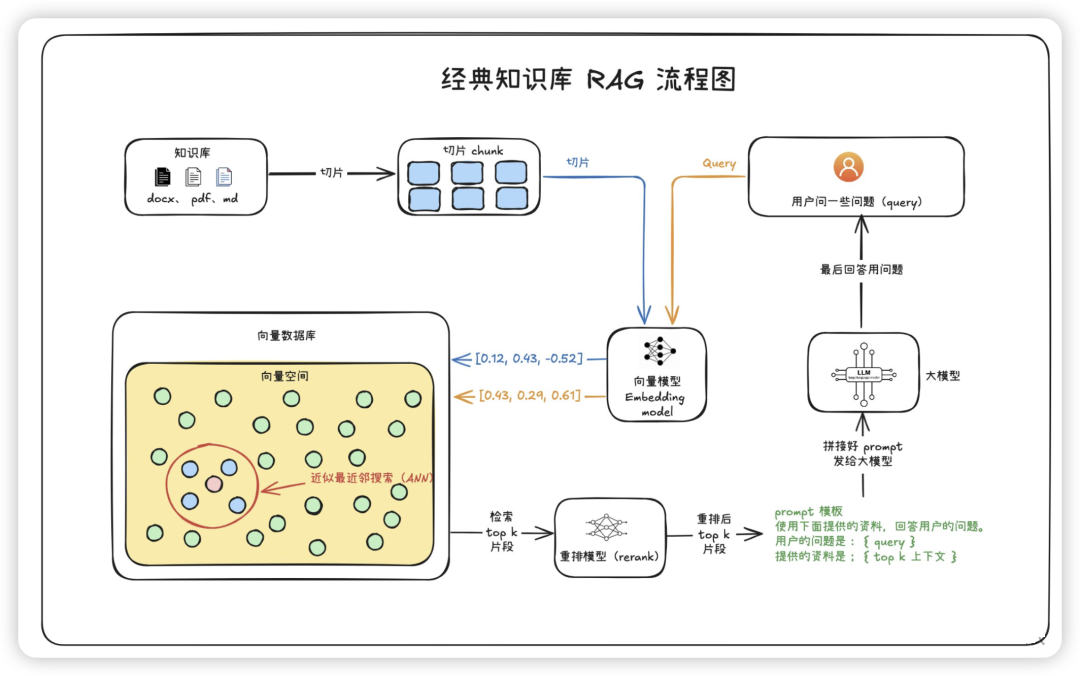
经典知识库 RAG 流程 :
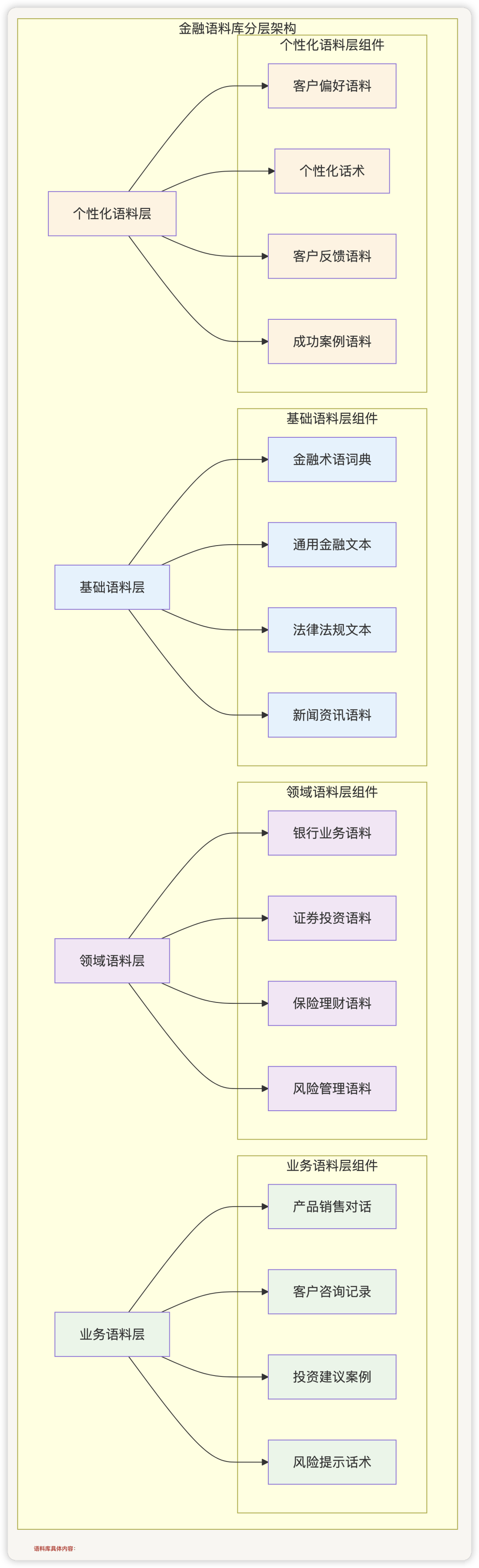
1.2 语料库设计
多层次语料库架构 :
语料库具体内容 :
| 语料类型 | 具体内容 | 数据量级 | 质量要求 | 应用场景 |
| 基础语料 |
金融教科书、监管文件、新闻资讯 |
100万+条目 |
权威准确 |
基础理解、术语解释 |
| 领域语料 |
行业报告、产品文档、专业论文 |
50万+文档 |
专业深度 |
专业咨询、深度分析 |
| 业务语料 |
销售话术、客服记录、成功案例 |
10万+对话 |
实用有效 |
销售推荐、问题解答 |
| 个性化语料 |
客户画像、偏好数据、历史交互 |
1万+客户 |
隐私合规 |
个性化推荐、精准营销 |
1.2.1 语料库数据示例
基础语料层示例 :
{
"金融术语词典": {
"净值型理财产品": {
"定义": "以净值形式展示的理财产品,产品收益以净值增长的形式体现",
"特点": ["收益浮动", "风险透明", "流动性较好"],
"风险等级": "中低风险",
"适用人群": "稳健型投资者"
},
"资产配置": {
"定义": "将投资资金在不同资产类别之间进行分配的投资策略",
"核心原则": ["分散风险", "收益最大化", "流动性平衡"],
"常见配置": "股票30% + 债券50% + 现金20%"
}
},
"监管文件语料": {
"资管新规要点": {
"发布机构": "中国人民银行",
"核心要求": ["打破刚性兑付", "消除多层嵌套", "统一监管标准"],
"影响产品": ["银行理财", "信托产品", "券商资管"]
}
}
}
|
领域语料层示例 :
{
"银行业务语料": {
"理财产品介绍": {
"产品名称": "稳健增利180天",
"产品类型": "净值型理财",
"投资期限": "180天",
"风险等级": "PR2(中低风险)",
"预期收益率": "3.8%-4.2%",
"起购金额": "1万元",
"投资方向": "债券、货币市场工具、同业存款",
"产品特色": "收益稳健、风险可控、流动性适中"
},
"基金产品解析": {
"基金代码": "000001",
"基金名称": "华夏成长混合",
"基金类型": "混合型基金",
"风险等级": "中高风险",
"历史业绩": "近一年收益率15.6%",
"基金经理": "张三(从业8年)",
"投资策略": "价值投资与成长投资相结合"
}
}
}
|
业务语料层示例 :
{
"销售话术模板": {
"产品推荐开场": {
"保守型客户": "根据您的风险偏好,我为您推荐几款稳健型理财产品,这些产品主要投资于债券和货币市场工具,风险相对较低...",
"平衡型客户": "考虑到您希望在控制风险的同时获得相对较好的收益,我建议您关注混合型基金产品...",
"积极型客户": "基于您的投资经验和风险承受能力,我为您筛选了几只优质的股票型基金..."
},
"风险提示话术": {
"理财产品": "请注意,理财产品不等同于银行存款,存在投资风险,可能出现本金损失。过往业绩不代表未来表现。",
"基金产品": "基金投资需谨慎,基金的过往业绩并不预示其未来表现,基金管理人管理的其他基金的业绩并不构成基金业绩表现的保证。"
}
},
"客服对话记录": {
"常见问题解答": {
"Q": "理财产品和定期存款有什么区别?",
"A": "主要区别在于:1)收益方式不同:定期存款收益固定,理财产品收益浮动;2)风险程度不同:定期存款受存款保险保护,
理财产品存在投资风险;3)流动性不同:定期存款可提前支取,理财产品通常有封闭期。"
},
"投资建议案例": {
"客户背景": "35岁,月收入2万,有房贷,风险承受能力中等",
"建议方案": "建议采用4-3-2-1资产配置:40%稳健型理财产品,30%混合型基金,20%货币基金作为应急资金,10%用于高风险高收益投资。"
}
}
}
|
个性化语料层示例 :
{
"客户画像语料": {
"客户ID_001": {
"基本信息": {
"年龄段": "30-40岁",
"职业": "IT工程师",
"收入水平": "中高收入",
"投资经验": "3年"
},
"风险偏好": {
"风险等级": "平衡型",
"投资期限偏好": "1-3年",
"流动性要求": "中等"
},
"历史交易": {
"购买产品": ["货币基金", "混合型基金", "银行理财"],
"投资金额": "10-50万",
"持有周期": "平均18个月"
},
"沟通偏好": {
"联系方式": "微信",
"沟通时间": "工作日晚上",
"信息接受度": "喜欢详细的产品分析"
}
}
},
"个性化话术": {
"针对IT从业者": "作为技术人员,您一定了解分散投资的重要性,就像系统架构需要冗余设计一样,
投资组合也需要多元化配置来降低风险...",
"针对医生群体": "医生的工作性质决定了您需要相对稳定的投资收益,建议您重点关注医疗健康主题基金,
这既符合您的专业背景,也有良好的发展前景..."
},
"成功案例语料": {
"案例1": {
"客户类型": "年轻白领",
"投资目标": "买房首付",
"推荐方案": "定投混合型基金 + 短期理财产品",
"实际效果": "3年累计收益率达到28%,成功实现购房目标",
"关键成功因素": "坚持定投、合理配置、及时调整"
}
}
}
|
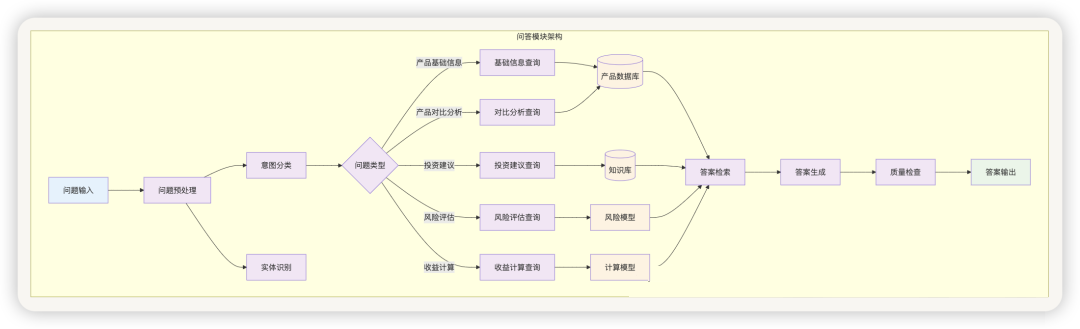
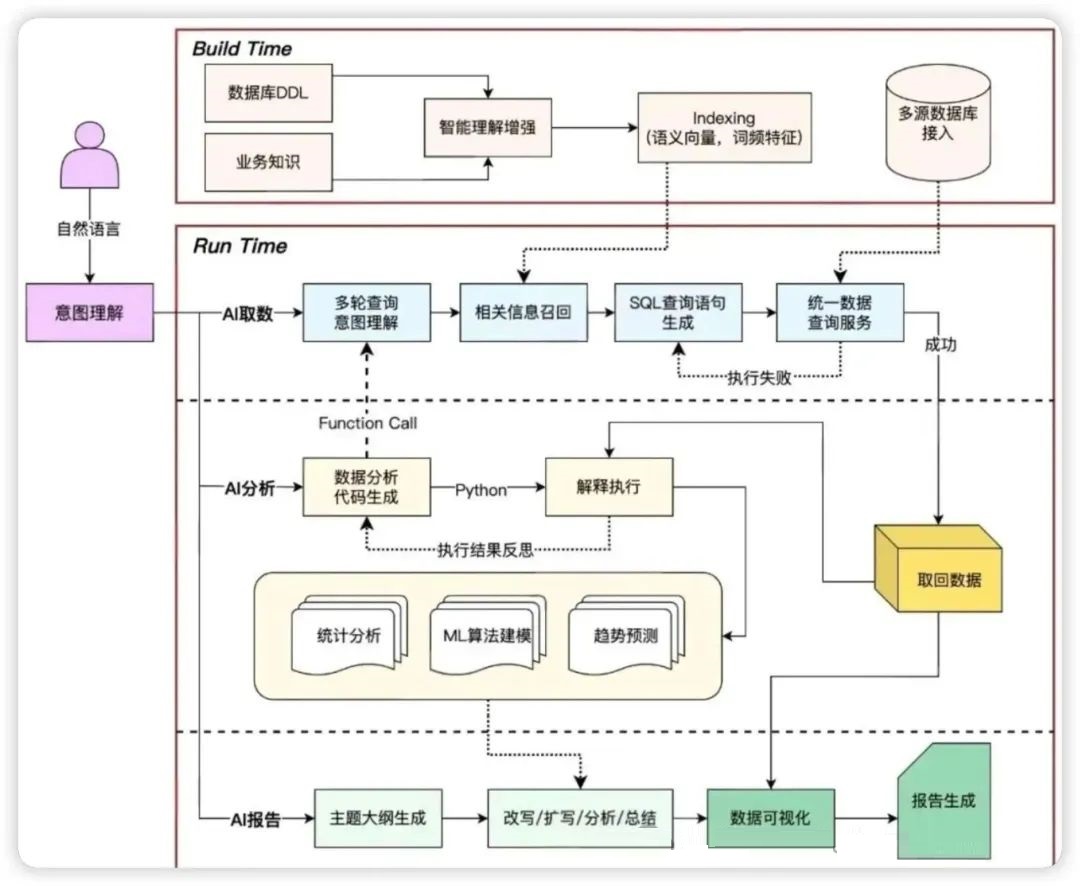
1.3 产品数据问答模块
模块概述 :
产品数据问答模块是金融产品销售系统的核心组件之一,专门负责处理客户对产品相关问题的智能问答。该模块通过结构化的产品数据库、智能检索算法和自然语言生成技术,为客户提供准确、及时、个性化的产品咨询服务。
核心功能架构 :
问答类型与处理逻辑 :
| 问答类型 | 典型问题 | 处理逻辑 | 数据来源 |
| 基础信息查询 |
"这个产品的起购金额是多少?" |
直接数据库查询 |
产品基础信息表 |
| 收益计算 |
"投资10万元一年能赚多少?" |
收益计算模型 |
产品收益率+计算公式 |
| 风险评估 |
"这个产品风险大吗?" |
风险评级+历史数据 |
风险信息+市场数据 |
| 产品对比 |
"A产品和B产品哪个更好?" |
多维度对比分析 |
多产品数据+评价模型 |
| 适合性判断 |
"这个产品适合我吗?" |
客户画像匹配 |
客户信息+产品特征 |
| 投资建议 |
"我应该怎么配置资产?" |
投资策略模型 |
客户画像+市场分析 |
基于数据库的问答处理逻辑 :
1.4 系统架构组成
完整架构设计 :
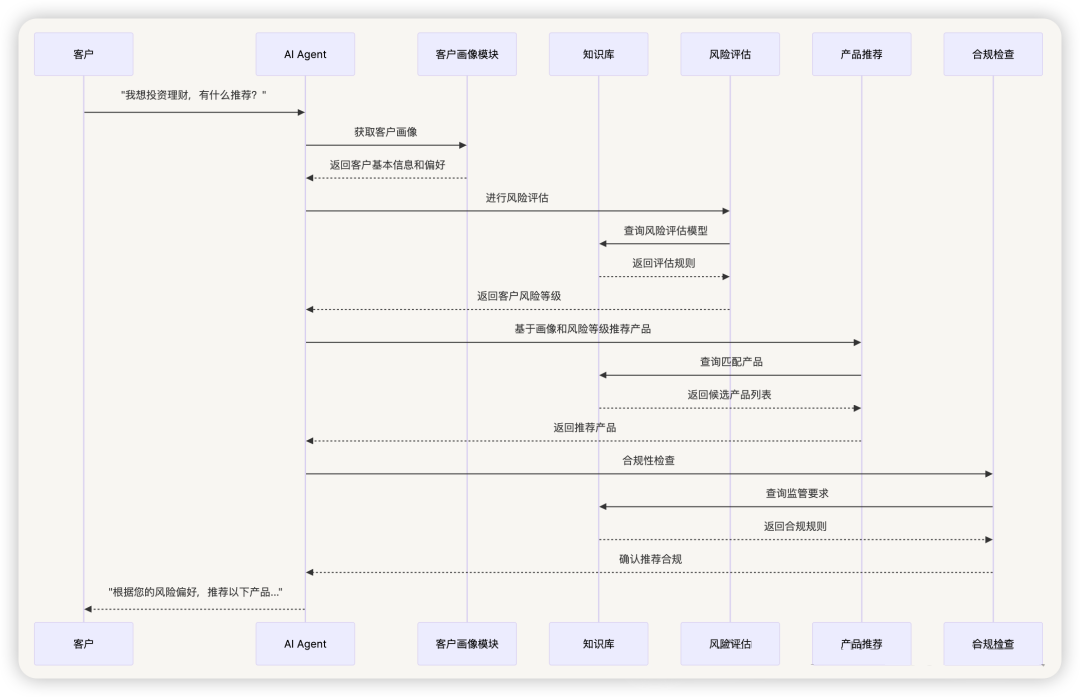
1.5 核心业务流程
智能推荐流程 :
1.6 数据流程设计
实时数据处理流程 :
-
客户输入处理 :
- 自然语言理解 → 意图识别
- 实体抽取 → 关键信息提取
- 上下文理解 → 对话状态管理
-
知识检索增强 :
- 语义检索 → 相关产品信息
- 规则匹配 → 监管合规要求
- 案例检索 → 相似客户经验
-
智能决策生成 :
- 风险评估 → 客户适当性判断
- 产品匹配 → 个性化推荐
- 合规验证 → 监管要求检查
-
个性化回答生成 :
- 语料库检索 → 专业话术模板
- 动态生成 → 个性化表达
- 风险提示 → 合规信息披露
-
反馈学习优化 :
- 客户反馈收集 → 推荐效果评估
- 模型参数调优 → 推荐精度提升
- 知识库更新 → 新产品信息同步
2. 智能客服系统
架构组成 :
- 数据库 :存储用户信息、工单历史、产品信息
- 知识库 :FAQ、产品文档、解决方案
- 语料库 :客服对话历史、产品说明书
- LLM应用 :理解用户问题、生成回答、情感分析
数据流程 :
- 用户提问 → 意图识别
- 知识库检索 → 相关信息获取
- 数据库查询 → 用户历史和产品信息
- LLM生成 → 个性化回答
- 结果存储 → 持续学习优化
3. 代码助手系统
架构组成 :
- 数据库 :项目配置、用户偏好、代码统计
- 知识库 :API 文档、最佳实践、代码模板
- 语料库 :开源代码、技术文档、编程教程
- LLM应用 :代码生成、bug 修复、代码解释
数据流程 :
- 代码上下文分析 → 理解当前项目
- 知识库匹配 → 相关 API 和模式
- 语料库参考 → 类似代码示例
- LLM生成 → 代码建议和解释
- 反馈学习 → 改进建议质量
十、技术选型建议
数据库选型
| 场景 | 推荐技术 | 理由 |
| 用户会话管理 |
Redis + PostgreSQL |
快速访问 + 持久化存储 |
| 实时数据查询 |
ClickHouse |
高性能分析查询 |
| 图谱关系存储 |
Neo4j |
复杂关系查询 |
| 文档存储 |
MongoDB |
灵活的文档结构 |
知识库选型
| 场景 | 推荐技术 | 理由 |
| 向量检索 |
Pinecone/Weaviate |
高效语义搜索 |
| 混合检索 |
Elasticsearch |
关键词+语义结合 |
| 知识图谱 |
Neo4j + RDF |
结构化知识表示 |
| 文档知识库 |
LangChain + Chroma |
快速原型开发 |
模型选型
| 场景 | 推荐模型 | 理由 |
| 通用对话 |
GPT-4/Claude |
强大的理解和生成能力 |
| 代码生成 |
CodeLlama/GitHub Copilot |
专业的代码理解 |
| 领域特化 |
微调的开源模型 |
成本控制和定制化 |
| 嵌入向量 |
text-embedding-ada-002 |
高质量语义表示 |
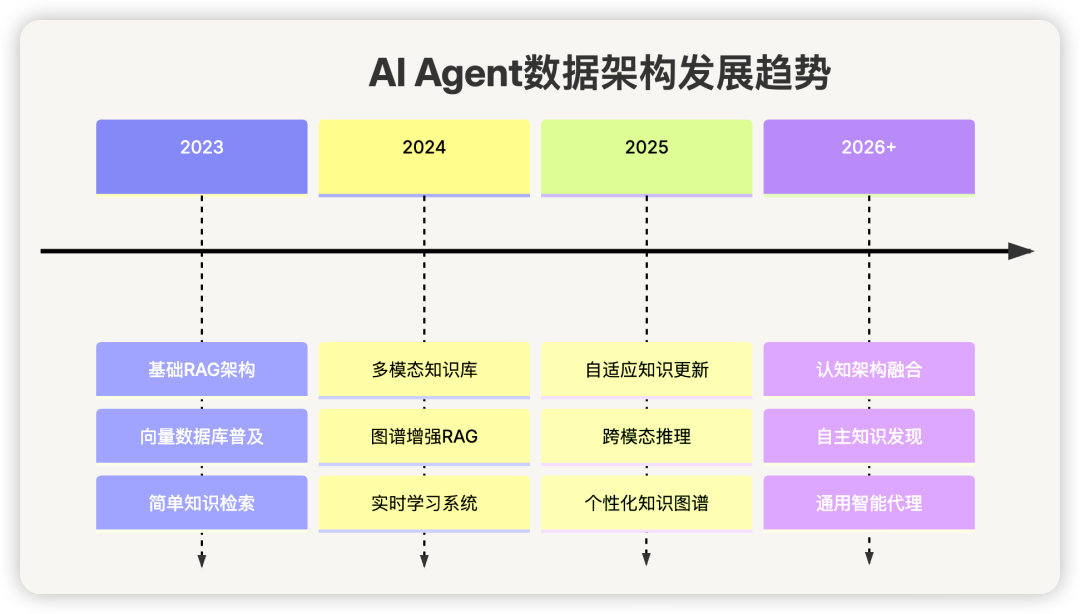
十一、发展趋势与展望
1. 技术发展趋势
2. 架构演进方向
- 统一数据层 :打通各类数据存储的边界
- 智能路由 :自动选择最优的数据源和模型
- 自适应学习 :基于用户反馈的持续优化
- 多模态融合 :文本、图像、音频的统一处理
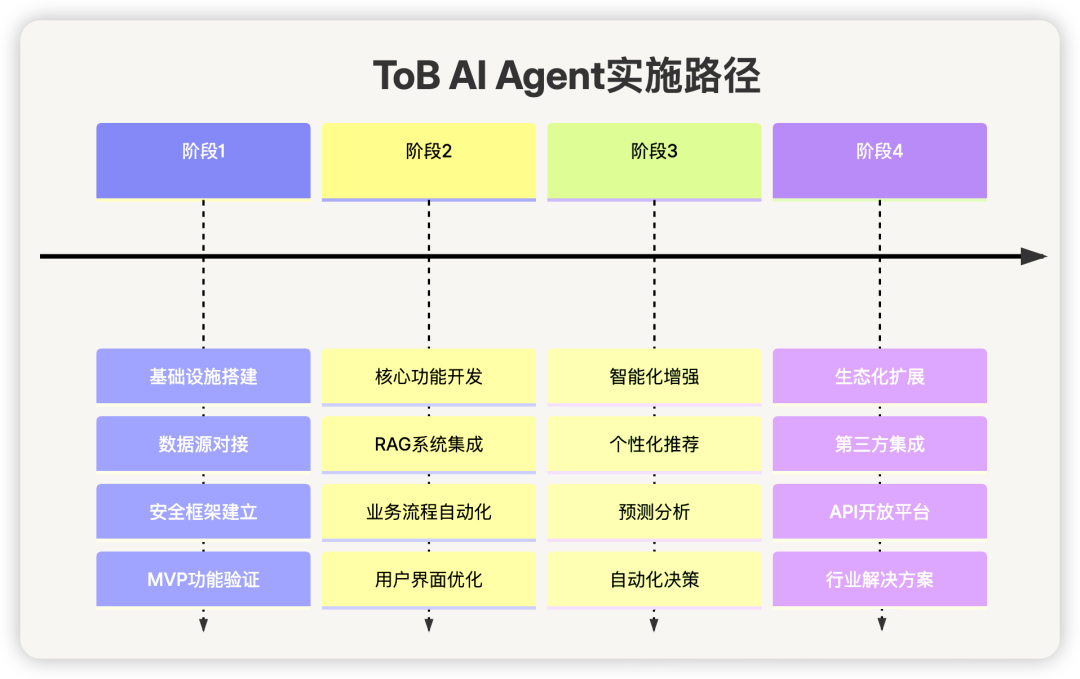
十二、ToB场景实施路径
分阶段实施策略
十三、小结
在 AI Agent 时代,数据库、语料库、知识库和大语言模型应用形成了一个有机的生态系统。理解它们之间的关系和协作模式,对于构建高效、可靠的 AI 应用至关重要。
| |






 订阅
订阅