| 编辑推荐: |
文章主要介绍了企业大模型场景落地的关注点和痛点及如何在
DeepSeek R1 时代更好地进行智能化转型等相关内容。希望对你的学习有帮助。
本文来自于微信公众号会飞的一十六 ,由火龙果软件Linda编辑,推荐。 |
|
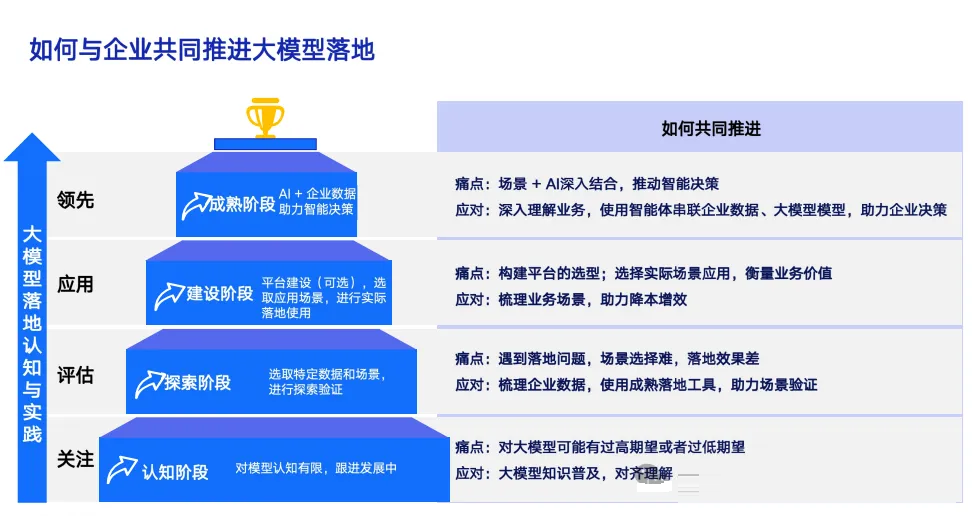
一、企业大模型场景落地的关注点和痛点
规划:前期如何规划?
如何统一规划整体架构?
- 并发支持、响应速度
- 租用还是自建
- 算力需求多大
- 商用还是开源?是否全部采用 DeepSeek R1?
- 本地还是云端
- 统一规划还是各自尝试
- 服务于哪些业务目标
- 目标
- 大模型
- 算力
- 性能
- 数据安全性考量
- 总体多少预算
选型:技术路线怎么选?
- 如何做合理的技术选型?
- 对大模型的要求
- 是不是只要大模型就够了
- 需要大模型做微调
- 构建行业大模型
- 各类场景分别选用什么样的大模型合适
- DeepSeek R1 适合哪些场景?
- 落地方法
- 使用各种 RAG 技术做落地,还是需要融入图技术
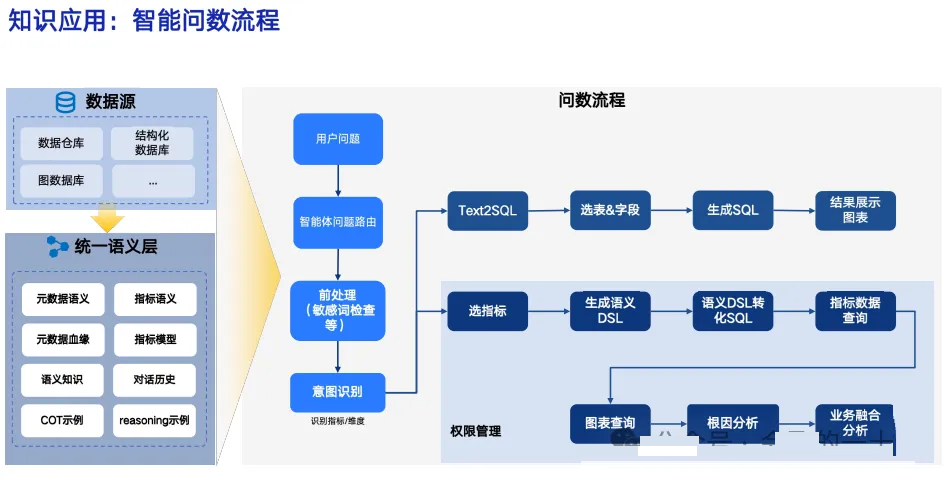
- 问数应该是 Text2SQL,还是 Text2 指标?
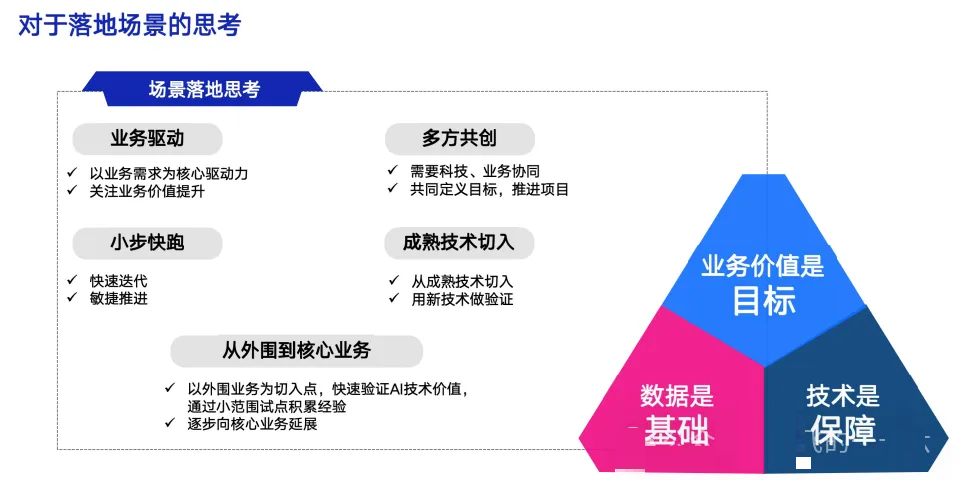
落地:如何有好的效果?
- 如何做到结果可信
- 如何做到效果好
- 为什么换一份数据效果不好
- 表格、图片效果如何
- 简单问题可以处理,复杂问题回答不了
- 可以做混合问答么,问答和问数融合在一起
- 如何保证数据安全性
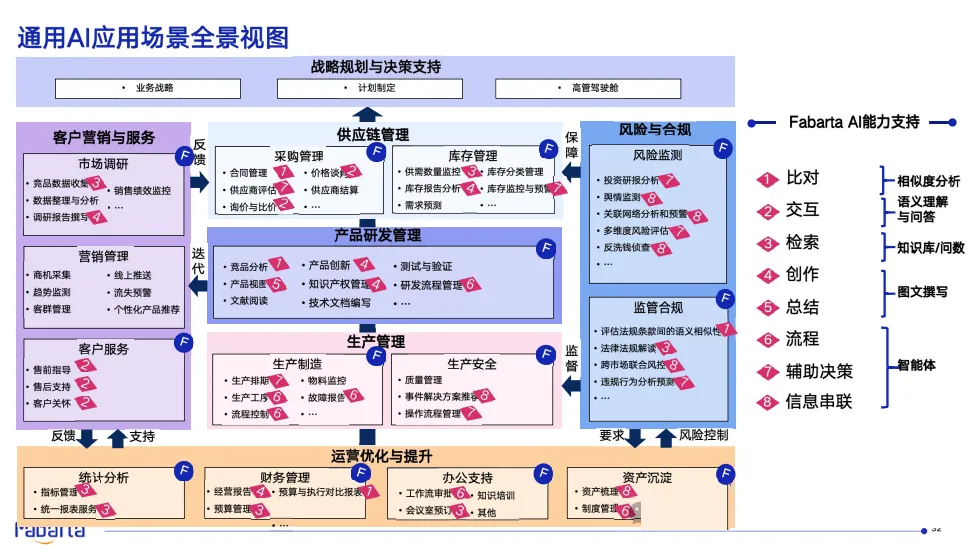
场景:如何选定高价值场景?
- 目标用户是谁,有什么痛点?
- 应该如何找场景?
- 需要哪些人参与
- 如何找到高价值场景
- 业务成熟度如何?
- 数据情况如何?
- 技术成熟度
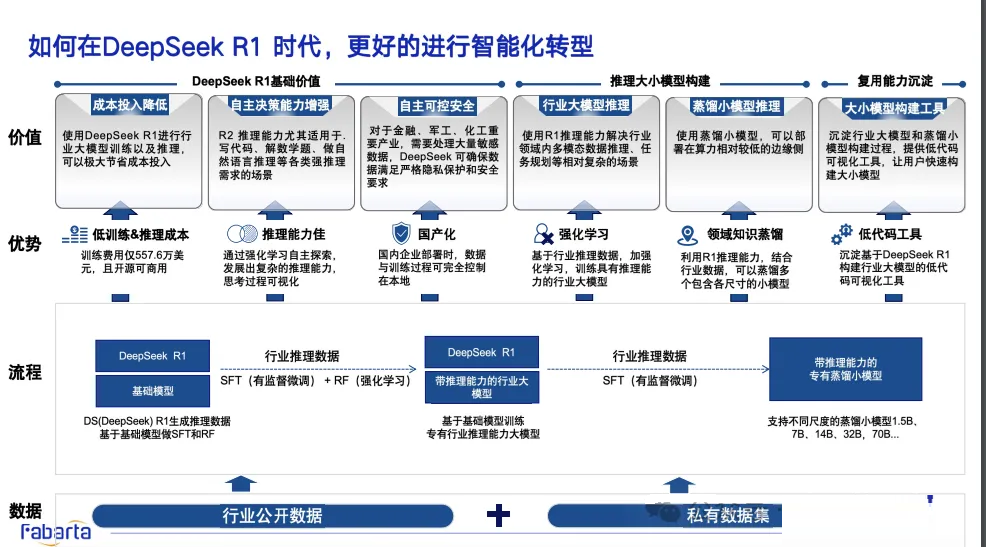
二、如何在 DeepSeek R1 时代更好地进行智能化转型
包括成本投入降低、自主决策能力增强、自主可控安全、行业模型推理、蒸馏小模型推理、复用能力沉淀。
有低训练 & 推理成本、推理能力佳、国产化、强化学习、领域知识蒸馏、低代码工具 。
从 DeepSeek R1 基础模型出发,经 SFT(有监督微调)和 RF(强化学习 ),利用行业推理数据,先构建带推理能力的行业大模型,再通过
SFT 得到带推理能力的专有蒸馏小模型。
涉及行业公开数据和私有数据集 。
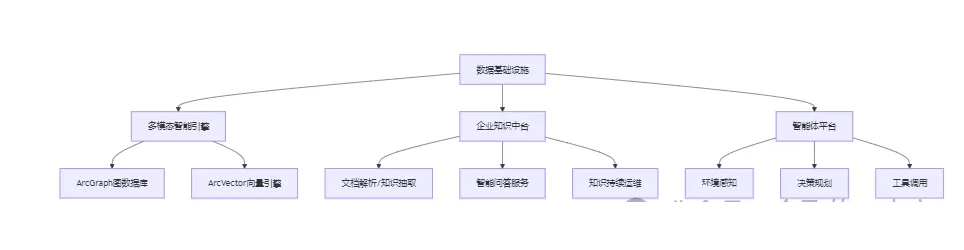
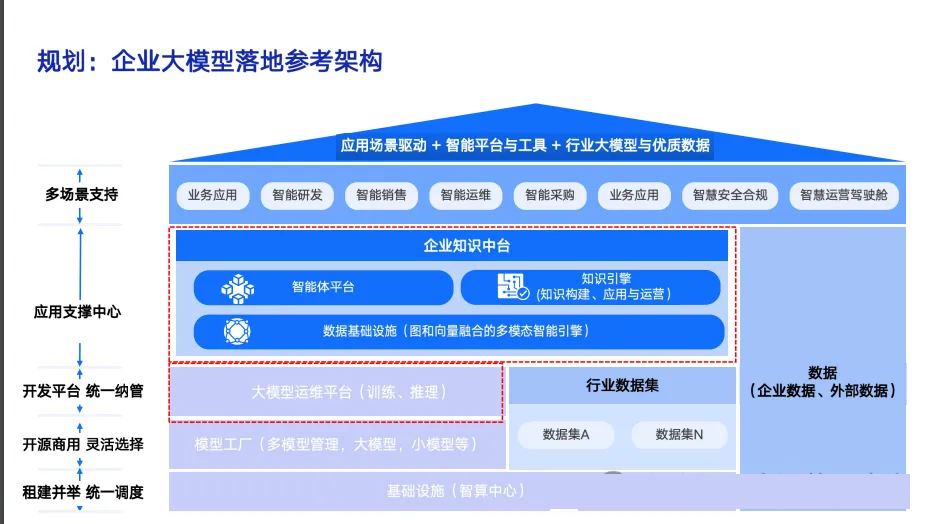
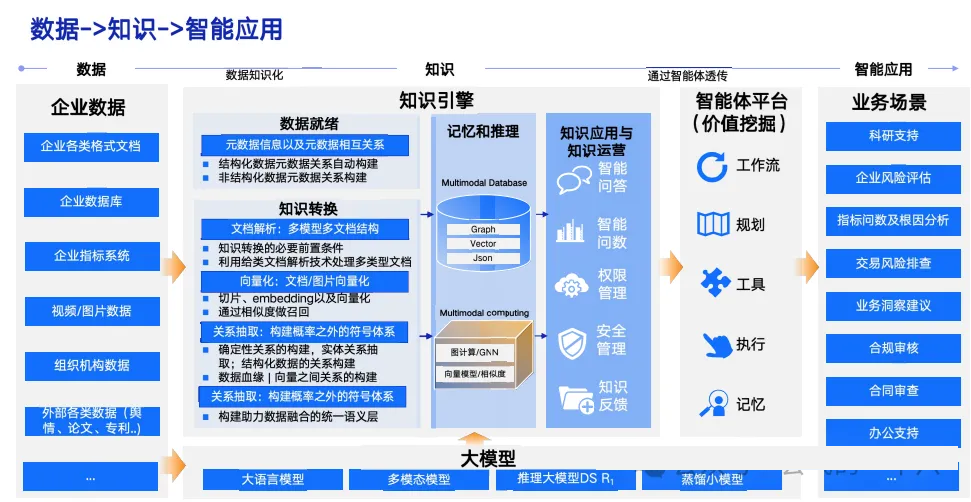
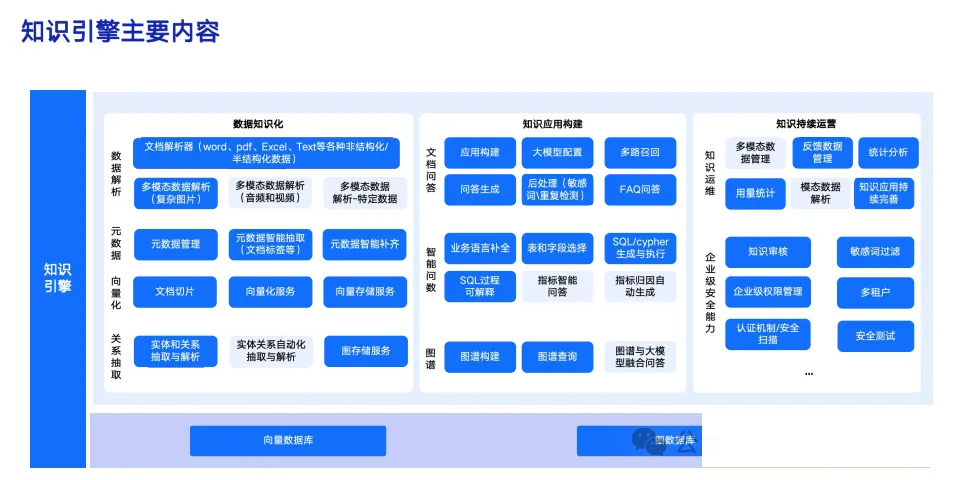
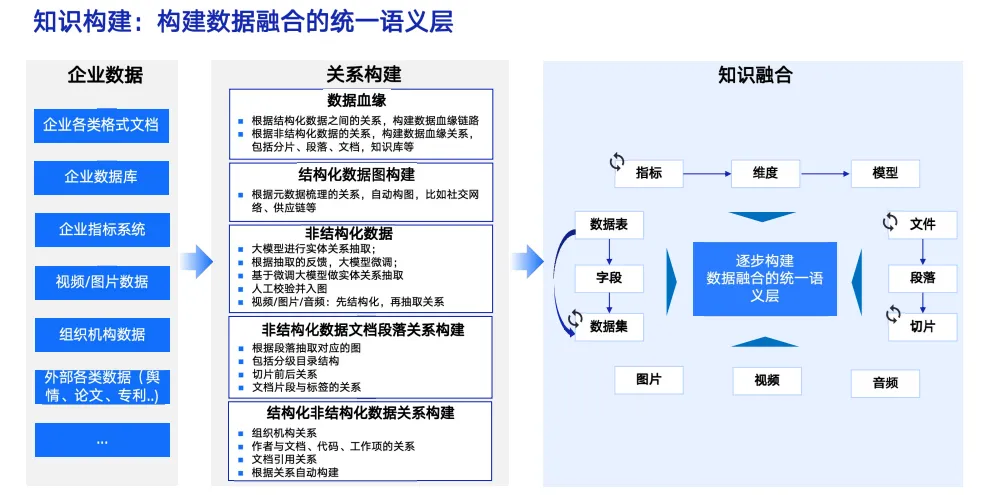
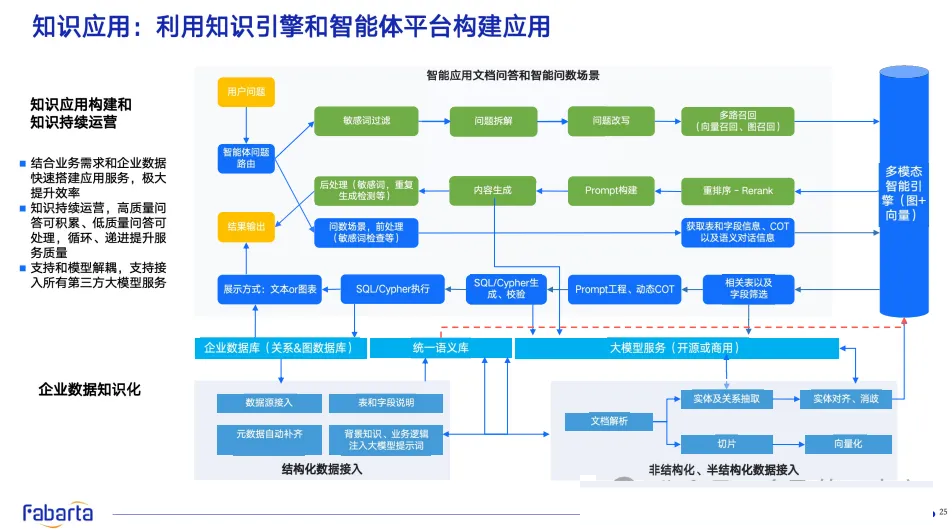
三、知识构建:构建数据融合的统一语义层
企业数据
- 企业各类格式文档
- 企业数据库
- 企业指标系统
- 视频 / 图片数据
- 组织机构数据
- 外部各类数据(舆情、论文、专利..)
- …
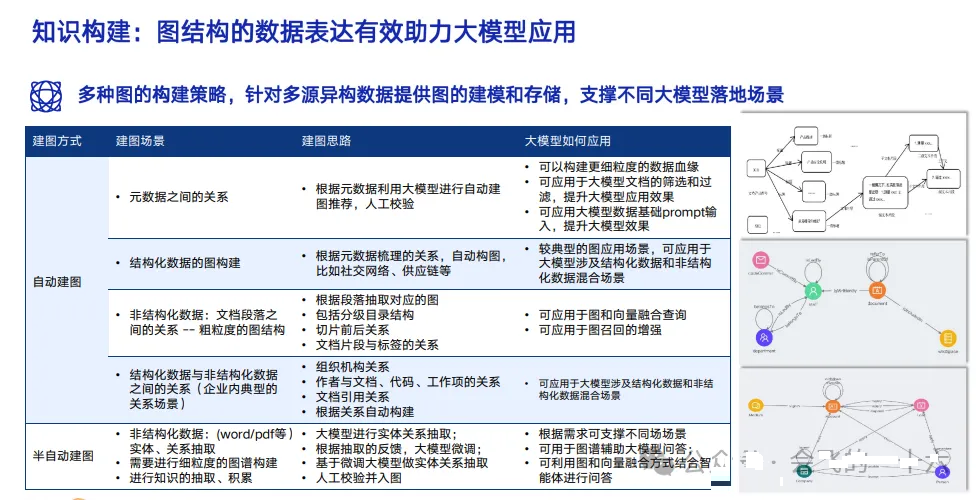
关系构建
数据血缘
- 根据结构化数据之间的关系,构建数据血缘链路
- 根据非结构化数据的关系,构建数据血缘关系,包括分片、段落、文档,知识库等
结构化数据图构建
非结构化数据
- 大模型进行实体关系抽取
- 根据抽取的反馈,大模型微调
- 基于微调大模型做实体关系抽取
- 人工校验并入图
- 视频 / 图片 / 音频:先结构化,再抽取关系
非结构化数据文档段落关系构建
- 根据段落抽取对应的图
- 包括分级目录结构
- 切片前后关系
- 文档片段与标签的关系
结构化非结构化数据关系构建
- 组织机构关系
- 作者与文档、代码、工作项的关系
- 文档引用关系
- 根据关系自动构建













| 






 订阅
订阅