| 编辑推荐: |
文章探讨了AI
Agent的发展趋势,并通过一个实际案例展示了如何基于MCP(Model Context
Protocol)开发一个支持私有知识库的问答系统。希望对你的学习有帮助。
本文来自于微信公众号阿里云开发者 ,由火龙果软件Linda编辑,推荐。 |
|
阿里妹导读
文章探讨了AI Agent的发展趋势,并通过一个实际案例展示了如何基于MCP(Model Context
Protocol)开发一个支持私有知识库的问答系统。
前言
业界推测 2025 年是 AI Agent 的元年,从目前的技术发展速度看确实是有这个趋势。从年初
DeepSeek 的爆火开始,目前开源大模型的能力基本与商业大模型拉齐甚至是超越,完全开放的开源策略让大模型的使用彻底平权。这个可以说在某种程度上改变了
AI 应用的商业模式,基于自训练的闭源模型的优势被显著削弱,商业竞争从模型性能转向对应用场景的创新。
AI 应用的形态不断演进,从早期的 Chat 到 RAG,再到现在的 Agent。参考 Web 2.0
和移动互联网时代的技术发展,当某种新形态的应用开发需求爆发式增长,会催生新的开发框架和新的标准的建立,AI
应用正在经历这个过程。
目前开发框架还处于百花齐放的状态,Python 是否会成为主流开发语言,哪个开发框架会成为主流,这些都还未知,有待观望。但是近期比较火热的
MCP(Model Context Protocol)看起来已成事实标准,特别是近期 OpenAI
也官宣了对 MCP 的支持。
关于 MCP 的介绍不在本文赘述,本着学习的目的,动手做了一个实践,主要为了体验如何基于 MCP
开发一个 Agent 应用。本次实践会实现一个目前最常见的一类 AI 应用即答疑系统,支持基于私有知识库的问答,会对知识库构建和
RAG 做一些优化。
整体流程设计
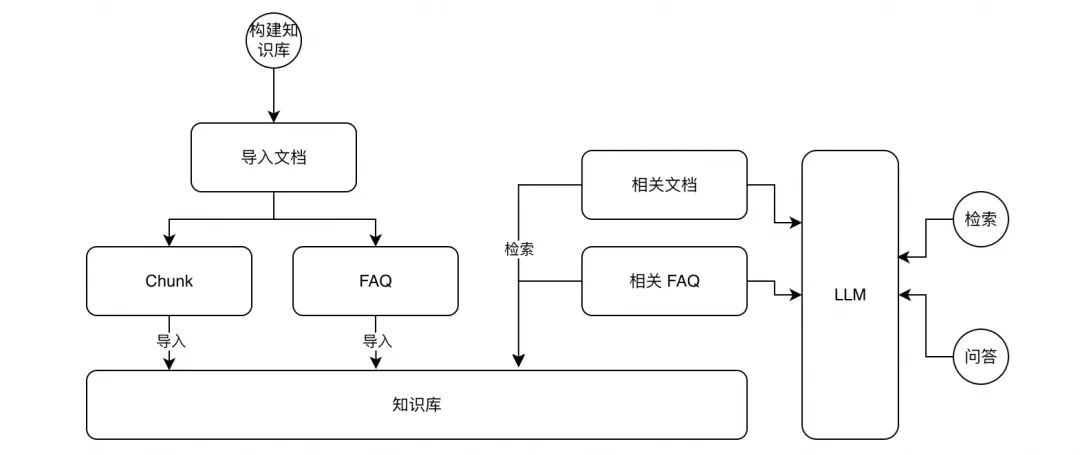
主要分为两部分:知识库构建和检索。
1.知识库构建
a.文本切段:对文本进行切段,切段后的内容需要保证文本完整性以及语义完整性。
b.提取 FAQ:根据文本内容提取 FAQ,作为知识库检索的一个补充,以提升检索效果。
c.导入知识库:将文本和 FAQ 导入知识库,并进行 Embedding 后导入向量。
2.知识检索(RAG)
a.问题拆解:对输入问题进行拆解和重写,拆解为更原子的子问题。
b.检索:针对每个子问题分别检索相关文本和 FAQ,针对文本采取向量检索,针对 FAQ 采取全文和向量混合检索。
c.知识库内容筛选:针对检索出来的内容进行筛选,保留与问题最相关的内容进行参考回答。
相比传统的 Naive RAG,在知识库构建和检索分别做了一些常见的优化,包括 Chunk 切分优化、提取
FAQ、Query Rewrite、混合检索等。
Agent 架构

整体架构分为三个部分:
1.知识库:内部包含 Knowledge Store 和 FAQ Store,分别存储文本内容和
FAQ 内容,支持向量和全文的混合检索。
2.MCP Server:提供对 Knowledge Store 和 FAQ Store 的读写操作,总共提供
4 个 Tools。
3.功能实现部分:完全通过 Prompt + LLM 来实现对知识库的导入、检索和问答这几个功能。
具体实现
所有代码开源在这里,分为两部分:
1.Python 实现的 Client 端:实现了与大模型进行交互,通过 MCP Client 获取
Tools,根据大模型的反馈调用 Tools 等基本能力。通过 Prompt 实现了知识库构建、检索和问答三个主要功能。
2.Java 实现的 Server 端:基于 Spring AI 框架实现 MCP Server,由于底层存储用的是
Tablestore,所以主体框架是基于这篇文章的代码进行改造。
知识库存储
知识库存储选择 Tablestore(向量检索功能介绍),主要原因为:
1.简单易用:仅一个创建实例步骤后即可开始使用,Serverless 模式无需管理容量和后续运维。
2.低成本:完全按量计费,自动根据存储规模水平扩展,最大可扩展至 PB 级。当然如果采用本地知识库肯定是零成本,但这里实现的是一个企业级、可通过云共享的知识库。
3.功能完备:支持全文、向量和标量等检索功能,支持混合检索。
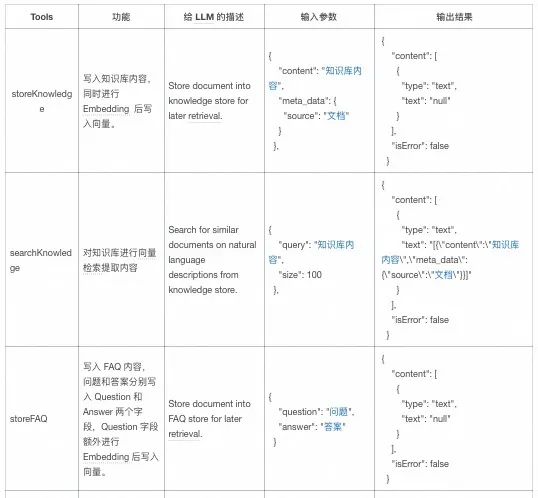
MCP Server
实现了 4 个 Tools(具体注册代码可参考 TablestoreMcp),相关描述如下:
知识库构建
1、对文本进行切段并提取 FAQ
完全通过提示词来完成,可根据自己的要求进行调优。


以上是一个示例,可以看到通过大模型能比较准确的对文本进行切段并提取 FAQ。这种方式的优势是切段的文本能保证完整性以及语义一致性,能够比较灵活的对格式做一些处理。提取的
FAQ 很全面,对于简单问题的问答通过直接搜索 FAQ 是最准确直接的。最大的缺点就是执行比较慢并且成本较高,一次会消耗大量的
Token,不过好在是一次性的投入。
2、写入知识库和 FAQ 库
这一步也是通过提示词来完成,基于 MCP 架构可以非常简单的实现,样例如下:

知识库检索
同样这一步也是通过提示词加 MCP 来实现,非常的简单,样例如下:
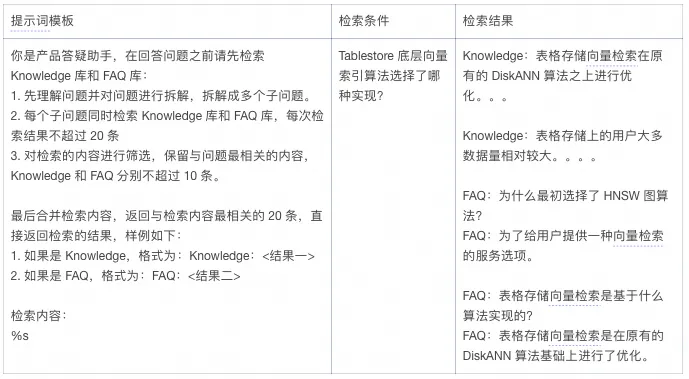
通过提示词描述实现了一个稍微复杂点的检索:
1.先对问题进行拆解,拆解为更原子的子问题。
2.每个子问题分别检索知识库和 FAQ,检索结果汇总后筛选留下与问题最相关的内容。
3.按照格式返回结果。
知识库问答
直接看下提示词和效果
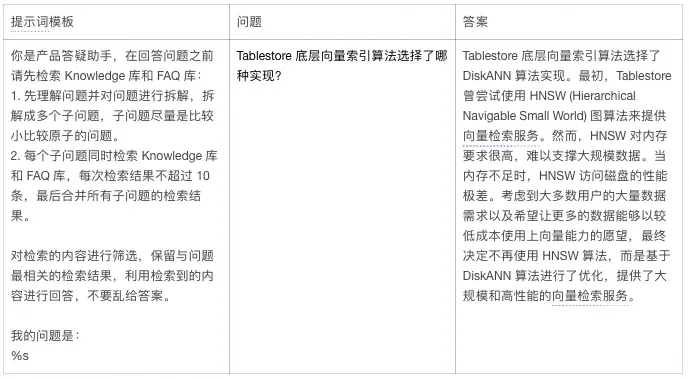
从 MCP Server 的 Log 内可以看到自动调用了知识库和 FAQ 的检索工具,并能根据之前导入的内容进行回答。
演示
1、创建知识库存储实例
可通过命令行工具(下载地址)来创建 Tablestore 实例,参考这个文档先进行配置。
配置成功后执行以下命令进行实例创建,实例名自行选择,需要保证 Region 内唯一。

2、启动 MCP Server
启动前需要在环境变量内配置如下几个参数:
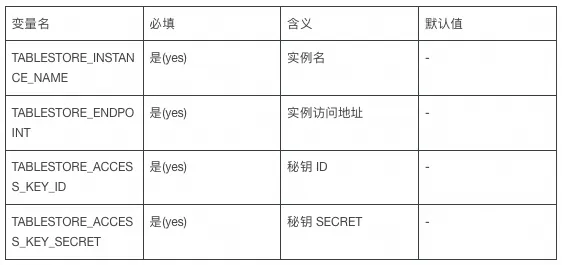
可参考代码库 README 内的步骤进行启动,也可将项目导入 IDE 后直接运行 App 这个类,启动后会自动初始化表和索引。
3、导入知识库
这一步需要执行代码库内的 knowledge_manager.py 工具,执行前需要先配置访问大模型的
API-KEY,默认采用 qwen-max。
export LLM_API_KEY=sk-xxxxxx
请自行准备知识库文档,使用 markdown 格式,执行如下:

4、检索知识库
执行如下:

5、基于知识库进行问答

最后
对应前言部分的观点,这一轮技术革命可以参考 Web 2.0 和移动互联网时代的技术发展,当某种新形态的应用开发需求爆发式增长,一定会催生新的开发框架和新的标准的建立。AI
应用的技术是能够完全构建在当前的技术框架之上,所以发展迭代的速度非常之快,很期待未来的发展。
构建OLAP全场景,揭秘实时/离线数仓一体化架构
随着企业的业务数据量和数据源不断增加,分析的难度和复杂度显著提升。AnalyticDB MySQL
提供了一个能整合多类型数据源,确保数据的一致性和完整性、高效的数据分析平台, 支持复杂查询和分析需求,能够快速洞察数据价值,更好地支撑业务决策。
| 






 订阅
订阅