| 编辑推荐: |
本文主要介绍了Transformer的工作原理相关内容。希望对你的学习有帮助。
本文来自于InfoQ,由火龙果软件Linda编辑,推荐。 |
|

目前,自然语言处理中,有三种特征处理器:卷积神经网络、递归神经网络和后起之秀 Transformer。Transformer
风头已经盖过两个前辈,它抛弃了传统的卷积神经网络和递归神经网络,整个网络结构完全是由注意力机制组成。准确地讲,Transformer
仅由自注意力和前馈神经网络组成。那么,Transformer 在自然语言处理中,是如何工作的?且听
Prateek Joshi 为我们娓娓道来。
概 述
自然语言处理中的 Transformer 模型真正改变了我们处理文本数据的方式。
Transformer 是最近自然语言处理发展的幕后推手,包括 Google 的 BERT。
了解 Transformer 的工作原理、它如何与语言建模、序列到序列建模相关,以及它如何支持 Google
的 BERT 模型。
引 言
现在,我喜欢做一名数据科学家,从事自然语言处理(Natural Language Processing,NLP)
方面的工作。这些突破和发展正以前所未有的速度发生。从超高效的 ULMFiT 框架到 Google 的
BERT,自然语言处理真的处于一个黄金时代。
这场革命的核心是 Transformer 的概念。它改变了我们数据科学家处理文本数据的方式,你很快就会在本文中理解这一点。
想看一个 Transformer 是多么有用的例子么?请看下面的段落:

标注高亮的单词指的是同一个人:Griezmann,一名受欢迎的足球运动员。对我们而言,要弄清楚文本中这些词之间的关系并不难。但对一台机器来说,这可就是一项相当艰巨的任务了。
对机器理解自然语言来说,掌握句子中这些关系和单词序列至关重要。这就是
Transformer 概念发挥主要作用之处。
序列到序列模型:背景
自然语言处理中的序列到序列模型(Sequence-to-sequence (seq2seq))用于将
A 型序列转换为 B 型序列。例如,将英语句子翻译成德语句子就是一个序列到序列的任务。
自 2014 年推出以来,基于递归神经网络的序列到序列模型得到了很多人的关注。目前世界上的大多数数据都是以序列的形式存在的,它可以是数字序列、文本序列、视频帧序列或音频序列。
2015 年增加了注意力机制(Attention Mechanism),进一步提高了这些 seq2seq
模型的性能。在过去的五年里,自然语言处理的进步如此之快,令人难以置信!
这些序列到序列模型用途非常广泛,可用于各种自然语言处理任务,例如:
机器翻译
文本摘要
语音识别
问答系统等等
基于递归神经网络的序列到序列模型
让我们以一个简单的序列到序列模型为例,请看以下如图所示:
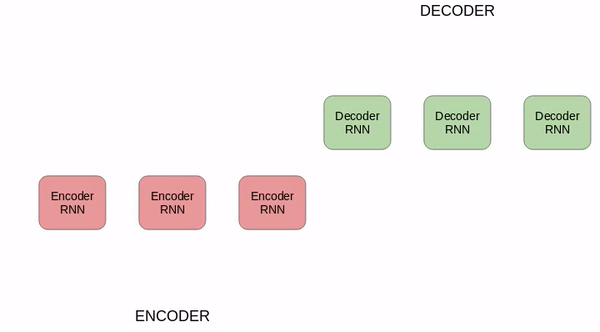
上图中的 seq2seq 模型将德语短语转换为英语短语。让我们把它分解一下:
编码器和解码器都是递归神经网络。
在编码器中的每个时间步骤,递归神经网络从输入序列获取词向量(xi),从前一个时间步骤中获取一个隐状态(Hi)。
隐状态在每个时间步骤中更新。
最后一个单元的隐状态称为语境矢量(context vector)。它包含有关输入序列的信息。
然后将该语境矢量传递给解码器,然后使用它生成目标序列(英文短语)。
如果我们使用注意力机制,则隐状态的加权和将作为语境矢量传递给解码器。
挑战
尽管 seq2seq 模型非常出色,但也存在一定的局限性:
处理长期依赖仍然是一个挑战。
模型架构的顺序特性阻止了并行化。这些挑战是通过 Google Brain 的 Transformer
概念得到解决的。
Transformer 简介
自然语言处理中的 Transformer 是一种新颖的架构,旨在解决序列到序列的任务,同时轻松处理长期依赖(long-range
dependencies)问题。Transformer 首次由论文 《注意力机制就是你所需要的》(Attention
Is All You Need)。对自然语言处理感兴趣的人都可以阅读这篇论文。
以下是论文引用:
“Transformer 是第一个完全依赖自注意力(self-attention)来计算输入和输出的表示,而不使用序列对齐的递归神经网络或卷积神经网络的转换模型。”
这里说的“转换”(transduction)是指将输入序列转换成输出序列。Transformer
背后的思想是使用注意力机制处理输入和输出之间的依赖关系,并且要完全递归。
让我们来看看 Transformer 的架构,它可能看上去令人生畏,但请别担心,我们会将其分解,一块一块地来理解它。
理解 Transformer 的模型架构
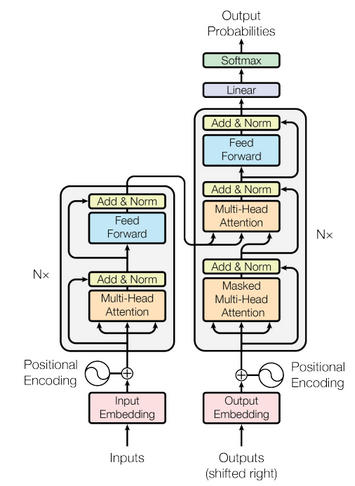
上图是 Transformer 架构的精湛图例。首先,让我们只关注编码器和解码器的部分。
现在,让我们观察下图。编码器块有一层多头注意力(Multi-Head Attention),然后是另一层前馈神经网络(
Feed Forward Neural Network)。另一方面,解码器有一个额外的掩模多头注意力(Masked
Multi-Head Attention)。
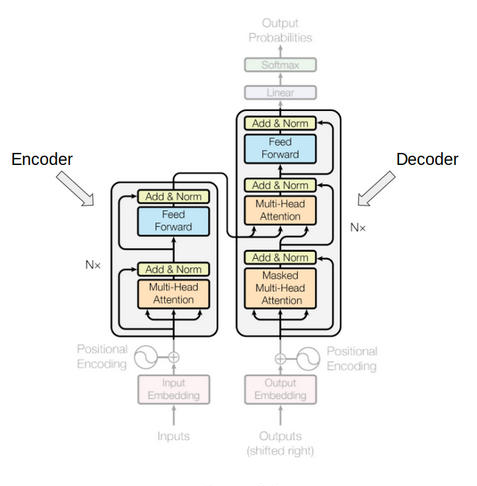
编码器和解码器块实际上是相互堆叠在一起的多个相同的编码器和解码器。 编码器堆栈和解码器堆栈都具有相同数量的单元。
编码器和解码器单元的数量是一个超参数。在本文中,我们使用了 6 个编码器和解码器。
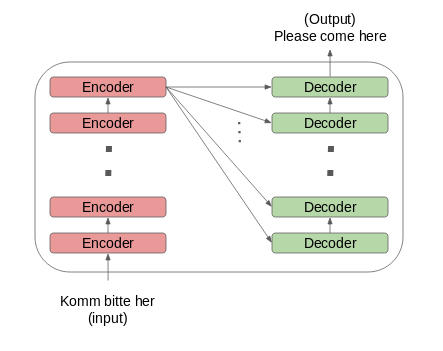
让我们看看编码器和解码器堆栈的设置是如何工作的:
将输入序列的词嵌入(word embeddings)传递给第一个编码器。
然后将它们进行转换并传播到下一个编码器。
编码器堆栈中最后一个编码器的输出将传递给解码器堆栈中所有的解码器,如下图所示:
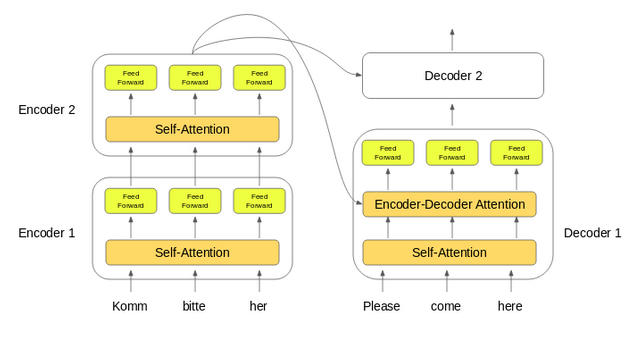
这里需要注意的一点是,除了自注意力和前馈层外,解码器还有一层解码器 - 解码器注意力层。这有助于解码器将注意力集中在输入序列的适当部分上。
你可能会想,这个“自注意力”层在 Transformer 中到底做了什么呢?问得好!这可以说是整个设置中最关键的部分,所以让我们来理解这个概念。
掌握自注意力的技巧
根据这篇论文所述:
“自注意力,有时也称为内部注意力(intra-attention),是一种注意力机制,它将一个序列的不同位置联系起来,以计算出序列的表示形式。”

请看上图。你能弄明白这句话中的“it”是指什么吗?
它指的是 street 还是 animal?这对我们来说是一个简单的问题,但对算法来说可不是这样的。当模型处理到“it”这个单词时,自注意力试图将“it”与同一句话中的“animal”联系起来。
自注意力允许模型查看输入序列中的其他单词,以便更好地理解序列中的某个单词。现在,让我们看看如何计算自注意力。
自注意力的计算
为便于理解,我将这一部分分为不同的步骤。
首先,我们需要从每个编码器的输入向量中创建三个向量:
查询向量
键向量
值向量
在训练过程中对这些向量进行训练和更新。完成本节之后,我们将进一步了解它们的角色。
接下来,我们将计算输入序列中每个单词的自注意力。
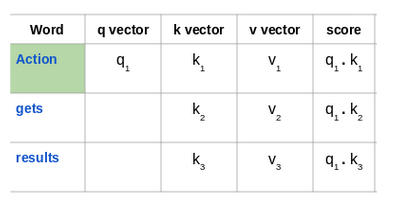
来看看这句话:“Action gets results”。为了计算第一个单词“Action”的自注意力,我们将计算短语中与“Action”相关的所有单词的得分。当我们在输入序列中编码某个单词时,该得分确定其他单词的重要性。
通过将查询向量(q1)的与所有单词的键向量(k1,k2,k3) 的点积来计算第一个单词的得分:
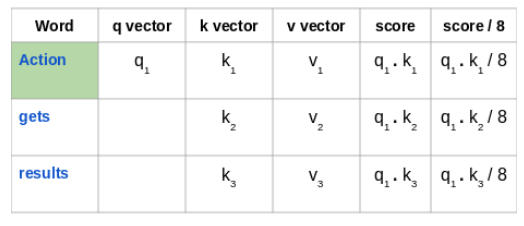
然后,将这些得分除以 8,也就是键向量维数的平方根:
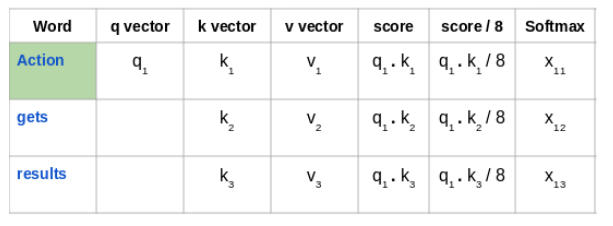
接下来,使用 softmax 激活函数对这些得分进行归一化:
然后将这些经过归一化的得分乘以值向量(v1,v2,v3),并将得到的向量求和,得到最终向量(z1)。这是自注意力层的输出。然后将其作为输入传递给前馈网络:
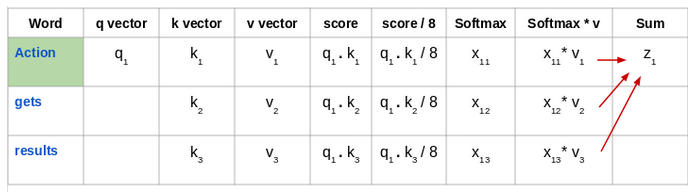
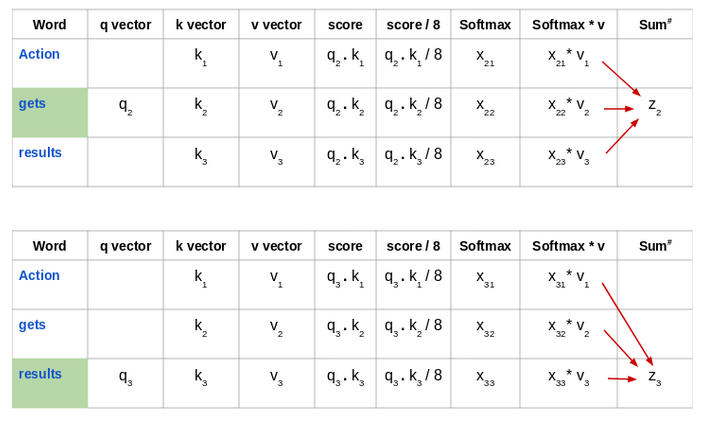
因此,z1 是输入序列“Action gets results”的第一个单词的自注意力向量。我们可以用同样的方式得到输入序列中其余单词的向量:
在 Transformer 的架构中,自注意力并不是计算一次,而是进行多次计算,并且是并行且独立进行的。因此,它被称为多头注意力。输出经过串联并进行线性转换,如下图所示。
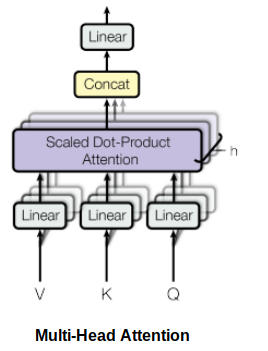
根据论文 Attention Is All You Need:
“多头注意力允许模型共同注意来自不同位置的不同表示子空间的信息。”
你可以查阅实现 Transformer 的代码:https://paperswithcode.com/paper/attention-is-all-you-need
Transformer 的局限性
Transformer 无疑是对基于递归神经网络的 seq2seq 模型的巨大改进。但它也有自身的局限性:
注意力只能处理固定长度的文本字符串。在输入系统之前,文本必须被分割成一定数量的段或块。
这种文本块会导致上下文碎片化。例如,如果一个句子从中间分隔,那么大量的上下文就会丢失。换言之,在不考虑句子或任何其他语义边界的情况下对文本进行分隔。
那么,我们如何处理这些非常重要的问题呢?这就是使用过 Transformer 的人们提出的问题。由此催生了
Transformer-XL。
理解 Transformer-XL
Transformer 架构可以学习长期依赖。但是,由于使用固定长度的上下文(输入文本段),它们无法扩展到特定的级别。为了克服这一缺点,这篇论文提出了一种新的架构:《Transformer-XL:超出固定长度上下文的注意力语言模型》(Transformer-XL:
Attentive Language Models Beyond a Fixed-Length Context)
在这种架构中,在先前段中获得的隐状态被重用为当前段的信息员。它支持对长期依赖建模,因为信息可以从一个段流向下一个段。
使用 Transformer 进行语言建模
“将语言建模看作是一个过程,在给定前面单词的情况下,估计下一个单词的概率。”
Al-Rfou 等人在 2018 年提出了将 Transformer 模型应用于语言建模的想法。根据这篇论文的观点,整个语料库可以被分割成规模可控的固定长度的段。然后,我们对
Transformer 模型进行分段独立训练,忽略了来自先前段的所有上下文信息:
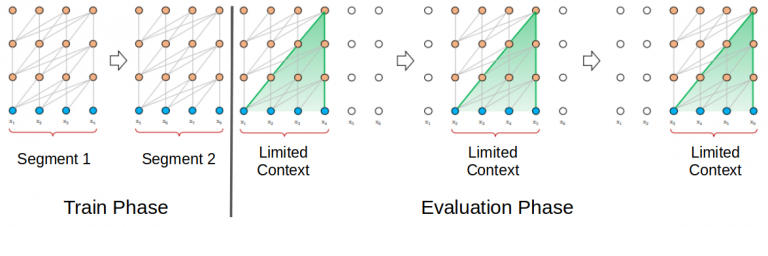
这种架构不存在梯度消失的问题。但上下文的碎片化限制了它的长期依赖学习。在评估阶段,该段仅向右移动一个位置。新段必须完全从头开始处理。然而不行的是,这种评估方法非常耗费计算量。
使用 Transformer-XL 进行语言建模
在 Transformer-XL 的训练阶段,为前一个状态计算的隐状态被用作当前段的附加上下文。Transformer-XL
的这种递归机制解决了使用固定长度上下文的局限性。
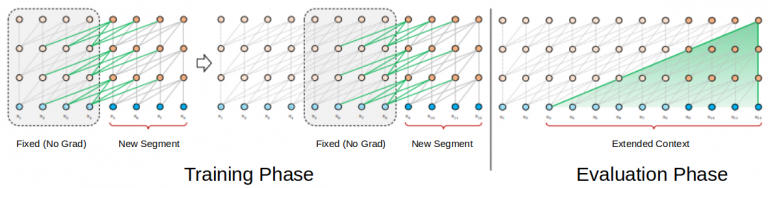
在评估阶段,可以重复使用来自先前段的表示,而不是从头开始计算(就像 Transformer 模型的情况一样)。当然,这也会增加计算速度。
自然语言处理的新感觉:Google 的 BERT
BERT,是来自来自 Transformer 的双向编码器表示(Bidirectional Encoder
Representations from Transformers)的缩写。
我们都知道迁移学习在计算机视觉领域的重要性有多高。例如,深度学习预训练模型可以针对 ImageNet
数据集上的新任务进行微调,并且在相对较小的标记数据集上提供不错的结果。
BERT 框架是 Google AI 的一个新的语言表示模型,它使用预训练和微调来为各种任务创建最先进的模型。这些任务包括问答系统、情感分析和语言推理等。
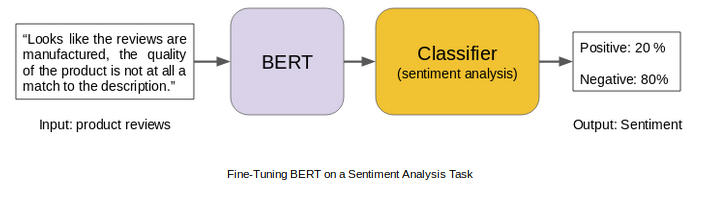
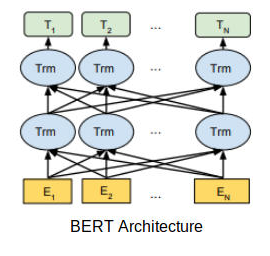
BERT 的模型架构
BERT 使用多层双向 Transformer 编码器。它的自注意力层在两个方向上都执行自注意力。Google
发布了该模型的两种变体:
BERT Base: Transformers 层数 = 12, 总参数 = 110M
BERT Large: Transformers 层数 = 24, 总参数 = 340M
BERT 使用使用双向性,通过对几个任务的预训练,掩码语言模型(Masked Language Model)和下一句的预测。让我们详细讨论这两个任务。
BERT 预训练任务
BERT 使用以下两个无监督预测任务对 BERT 进行预训练。
1. 掩码语言建模(Masked Language Modeling,MLM)
根据这篇论文:
“掩码语言建模从输入中随机掩盖一些标记,其目标是仅基于上下文预测被掩盖的单词的原始词汇 id。与从左到右的语言模型预训练不同,MLM
目标允许表示融合左和右上下文,这允许我们预训练深度双向 Transformer。”
Google AI 研究人员随机掩盖了每个序列中 15% 的单词。这个任务是什么?就是预测那些被掩盖的单词。此处需要注意的是,掩码单词并不总是被掩盖的标记
[MASK] [MASK] 标记在微调过程中永远不会出现。
因此,研究人员使用了以下技术:
有 80% 的单词被掩码标记 [MASK] 替换。
有 10% 的单词被随机单词替换。
有 10% 的单词保持不变。
2. 下一句的预测
一般来说,语言模型并不能捕捉连续句子之间的关系。BERT 也接受过这项任务的预训练。
对于语言模型的预训练,BERT 使用成对的句子作为训练数据。每对句子的选择非常有趣。让我们试着通过一个例子来理解它。
假设我们有一个包含 100000 条句子的文本数据集,我们想使用这个数据集来预训练 BERT 语言模型。因此,将有
50000 个训练样本或句子对作为训练数据。
对于 50% 的句子对来说,第二条句子实际上是第一条句子的下一条句子。
对于其余 50% 的句子对,第二条句子将是语料库中的一条随机句子。
对于第一种情况,标签是“IsNext”,第二种情况标签是“NotNext”。
像 BERT 这样的架构表明了,无监督学习(预训练和微调)将成为许多语言理解系统中的关键元素。资源较少的任务尤其可以从这些深度双向架构中获得巨大的好处。
如下图所示,是一些自然语言处理任务的快照,在这些任务重,BERT 扮演着重要角色:
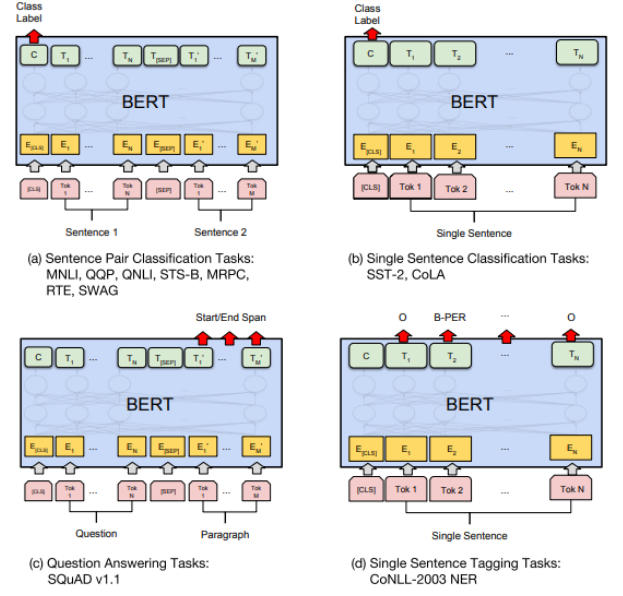
结 语
我们真的应该为自己感到幸运。因为自然语言处理技术以如此快的速度取得了最先进的进展。像
Transformer 和 BERT 这样的架构,正在为未来几年更先进的突破铺平了道路。
|







 订阅
订阅