| 编辑推荐: |
本文将讨论有关图像分类的所有内容
,希望对您的学习有所帮助。
本文来自于深度学习与计算机视觉 ,由火龙果软件Alice编辑、推荐。 |
|
介绍
本文将讨论有关图像分类的所有内容。
在过去的几年里,深度学习已经被证明是一个非常强大的工具,因为它能够处理大量的数据。隐藏层的使用超越了传统技术,尤其是在模式识别方面。最受欢迎的深度神经网络之一是卷积神经网络 (CNN)。
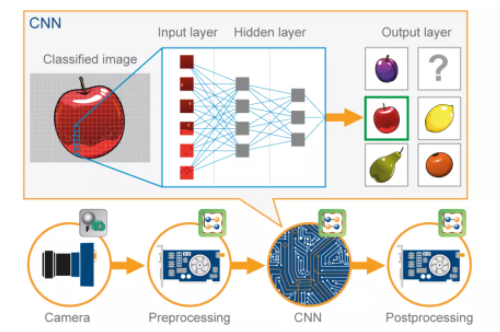
卷积神经网络(CNN)是一种用于图像识别和处理的 人工神经网络(ANN) ,专门用于处理数据(像素)。
在进一步研究之前,我们需要了解什么是神经网络.
神经网络
一个神经网络由几个相互连接的节点构成,称为**“神经元” 。神经元分为 输入层、隐藏层和输出层。**输入层对应于我们的预测器/特征,输出层对应于我们的响应变量。
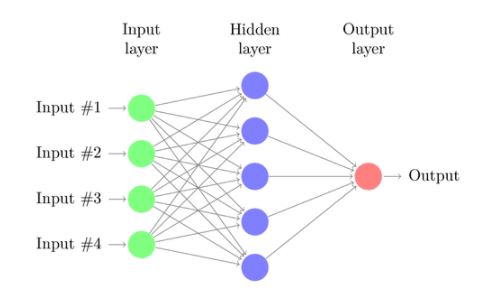
多层感知器(MLP)
具有输入层、一个或多个隐藏层和一个输出层的神经网络称为 多层感知器 (MLP)。 MLP 是 Frank Rosenblatt 在 1957 年发明的。下面给出的 MLP 有 5 个输入节点、5 个带有两个隐藏层的隐藏节点和一个输出节点
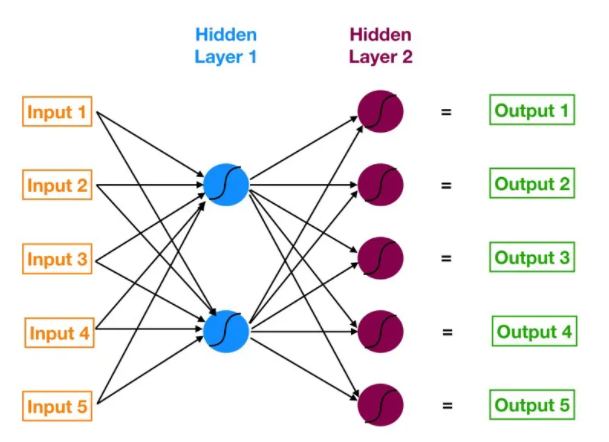
这个神经网络是如何工作的?
– 输入层神经元接收来自数据的传入信息,它们处理并分配给隐藏层。 – 该信息依次经过隐藏层处理,并传递给输出神经元。 – 该人工神经网络 (ANN) 中的信息根据一个 激活函数进行处理 。这个函数实际上模仿了大脑神经元。 – 每个神经元包含一个激活函数值和一个阈值。 – 阈值 是输入必须具有的最小值才能被激活。 – 神经元的任务是对所有输入信号进行加权求和,并对总和应用激活函数,然后再将其传递到下一个(隐藏或输出)层。
让我们了解什么是权重和?
假设我们有值a1、a2、a3、a4?4作为输入,权重为w1、w2、w3、w4作为隐藏层神经元??之一的输入,那么加权和表示为

其中bj :由节点引起的偏差
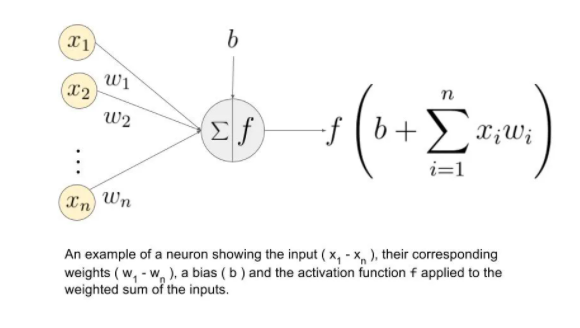
什么是激活函数?
需要这些函数来将非线性引入网络。应用激活函数并将该输出传递到下一层。 可能的函数 Sigmoid:Sigmoid 函数是可微的。它产生 0 到 1 之间的输出。 双曲正切:双曲正切也是可微的。它会产生 -1 和 1 之间的输出。 ReLU:ReLU 是最受欢迎的函数。ReLU 在深度学习中被广泛使用。 Softmax:softmax 函数用于多类分类问题。它是 sigmoid 函数的推广。它还产生 0 到 1 之间的输出 现在,让我们继续我们的话题 CNN……
CNN
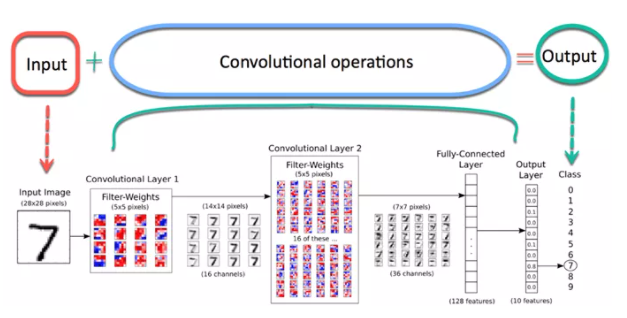
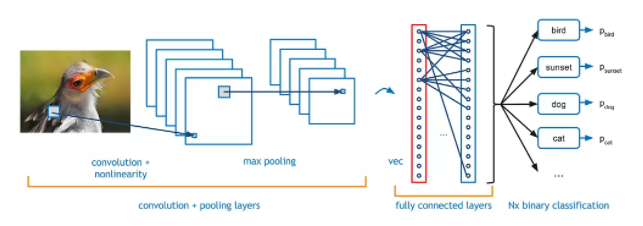
现在假设有一张鸟的图像,你想确定它是真的鸟还是其他什么东西。你应该做的第一件事是以数组的形式将图像的像素馈送到神经网络(用于对此类事物进行分类的 MLP 网络)的输入层。 隐藏层通过执行各种计算和操作来进行特征提取。有多个隐藏层,如卷积、ReLU 和从图像中执行特征提取的池化层。 最后,你可以看到一个全连接层,它可以识别图像中的确切对象。 你可以很容易的从下图理解:
卷积
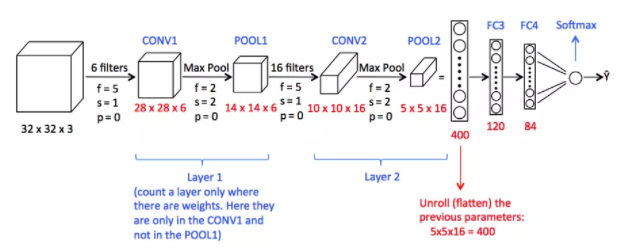
卷积运算涉及矩阵算术运算,每个图像都以值(像素)数组的形式表示。 让我们理解示例: a = [2,5,8,4,7,9] b = [1,2,3] 在卷积运算中,数组逐个元素地相乘,乘积被分组或求和以创建一个表示 a*b 的新数组。 矩阵 a 的前三个元素现在乘以矩阵 b 的元素。乘积相加得到结果并存储在一个新的 a*b 数组中**。** 这个过程一直持续到操作完成。
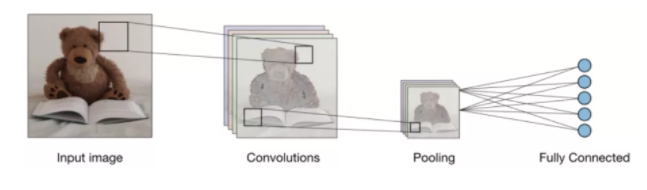
池化
在卷积之后,还有一个称为池化的操作。因此,在这个链中,卷积和池化依次应用于数据以从数据中提取一些特征。 在连续的卷积层和池化层之后,数据被展平成一个前馈神经网络,也称为多层感知器。
到目前为止,我们已经看到了对我们构建 CNN 模型很重要的概念。 现在我们将继续看 CNN 的案例研究。
1)在这里,我们将导入执行 CNN 任务所需的必要库。
import NumPy as np
%matplotlib inline
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import TensorFlow as tf
tf.compat.v1.set_random_seed( 2019 ) |
2)这里我们需要下面的代码来形成CNN模型
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D( 16 ,( 3 , 3 ),activation = "relu" ,
input_shape = ( 180 , 180 , 3 )) ,
tf.keras.layers.MaxPooling2D( 2 , 2 ),
tf.keras.layers.Conv2D( 32 ,( 3 , 3 ),activation = "relu" ) ,
tf.keras.layers.MaxPooling2D( 2 , 2 ),
tf.keras.layers.Conv2D( 64 ,( 3 , 3 ),activation = "relu" ) ,
tf.keras.layers.MaxPooling2D( 2 , 2 ),
tf.keras.layers.Conv2D( 128 ,( 3 , 3 ),activation = "relu" ),
tf.keras.layers.MaxPooling2D( 2 , 2 ),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense( 550 ,activation= "relu" ),
#Adding the Hidden layer
tf.keras.layers.Dropout( 0.1 ,seed = 2019 ),
tf.keras.layers.Dense( 400 ,activation = "relu" ),
tf.keras.layers.Dropout( 0.3 ,seed = 2019 ),
tf.keras.layers.Dense( 300 ,activation= "relu" ),
tf.keras.layers.Dropout( 0.4 ,seed = 2019 ),
tf.keras.layers.Dense( 200 ,activation = "relu" ),
tf.keras.layers.Dropout( 0.2 ,seed = 2019 ),
tf.keras.layers.Dense( 5 ,activation = "softmax" )
#Adding the Output Layer
]) |
一个卷积的图像可能太大了,因此在不丢失特征或模式的情况下将其缩小,即完成了池化。 这里创建一个神经网络就是使用Keras的Sequential模型来初始化网络。 Flatten() - Flattening 将二维特征矩阵转换为特征向量。
3)现在让我们看一下CNN模型的总结
它将打印以下输出
Model: "sequential"
Layer (type) Output Shape Param #
conv2d (Conv2D) ( None , 178 , 178 , 16 ) 448
max_pooling2d (MaxPooling2D) ( None , 89 , 89 , 16 ) 0
conv2d_1 (Conv2D) ( None , 87 , 87 , 32 ) 4640
max_pooling2d_1 (MaxPooling2 ( None , 43 , 43 , 32 ) 0
conv2d_2 (Conv2D) ( None , 41 , 41 , 64 ) 18496
max_pooling2d_2 (MaxPooling2 ( None , 20 , 20 , 64 ) 0
conv2d_3 (Conv2D) ( None , 18 , 18 , 128 ) 73856
max_pooling2d_3 (MaxPooling2 ( None , 9 , 9 , 128 ) 0
flatten (Flatten) ( None , 10368 ) 0
dense (Dense) ( None , 550 ) 5702950
dropout (Dropout) ( None , 550 ) 0
dense_1 (Dense) ( None , 400 ) 220400
dropout_1 (Dropout) ( None , 400 ) 0
dense_2 (Dense) ( None , 300 ) 120300
dropout_2 (Dropout) ( None , 300 ) 0
dense_3 (Dense) ( None , 200 ) 60200
dropout_3 (Dropout) ( None , 200 ) 0
dense_4 (Dense) ( None , 5 ) 1005
Total params: 6 , 202 , 295
Trainable params: 6 , 202 , 295
Non-trainable params: 0 |
现在我们需要指定优化器。
from tensorflow.keras.optimizers import RMSprop,SGD,Adam
adam=Adam(lr= 0.001 )
model.compile(optimizer= 'adam' ,
loss= 'categorical_crossentropy' , metrics = [ 'acc' ]) |
Optimizer - 优化器用于降低交叉熵计算的成本
loss - 损失函数用于计算误差
metrics - 度量项用于表示模型的效率
5)在这一步中,我们将看到如何设置数据目录和生成图像数据。
bs= 30 #Setting batch size
train_dir = "D:/Data Science/Image Datasets/
FastFood/train/" #Setting training directory
validation_dir = "D:/Data Science/Image Datasets/
FastFood/test/" #Setting testing directory
from tensorflow.keras.preprocessing.
image import ImageDataGenerator
# All images will be rescaled by 1./255.
train_datagen = ImageDataGenerator( rescale = 1.0 / 255. )
test_datagen = ImageDataGenerator( rescale = 1.0 / 255. )
# Flow training images in batches of 20 using train_datagen generator
#Flow_from_directory function lets the classifier
directly identify the labels from the name of
the directories the image lies in
train_generator=train_datagen.flow_from_directory
(train_dir,batch_size=bs,class_mode= 'categorical' ,
target_size=( 180 , 180 ))
# Flow validation images in batches of 20 using test_datagen generator
validation_generator = test_datagen.flow_from_directory
(validation_dir,
batch_size=bs,
class_mode = 'categorical' ,
target_size=( 180 , 180 )) |
输出将是:
Found 1465 images belonging to 5 classes.
Found 893 images belonging to 5 classes. |
6.拟合模型的最后一步。
history = model.fit(train_generator,
validation_data=validation_generator,
steps_per_epoch= 150 // bs,
epochs= 30 ,
validation_steps= 50 // bs,
verbose= 2 ) |
输出将是:
Epoch 1 / 30
5 / 5 - 4 s - loss: 0.8625 - acc: 0.6933 - val_loss:
1.1741 - val_acc: 0.5000
Epoch 2 / 30
5 / 5 - 3 s - loss: 0.7539 - acc: 0.7467 - val_loss:
1.2036 - val_acc: 0.5333
Epoch 3 / 30
5 / 5 - 3 s - loss: 0.7829 - acc: 0.7400 - val_loss:
1.2483 - val_acc: 0.5667
Epoch 4 / 30
5 / 5 - 3 s - loss: 0.6823 - acc: 0.7867 - val_loss:
1.3290 - val_acc: 0.4333
Epoch 5 / 30
5 / 5 - 3 s - loss: 0.6892 - acc: 0.7800 - val_loss:
1.6482 - val_acc: 0.4333
Epoch 6 / 30
5 / 5 - 3 s - loss: 0.7903 - acc: 0.7467 - val_loss:
1.0440 - val_acc: 0.6333
Epoch 7 / 30
5 / 5 - 3 s - loss: 0.5731 - acc:
0.8267 - val_loss: 1.5226 - val_acc: 0.5000
Epoch 8 / 30
5 / 5 - 3 s - loss: 0.5949 - acc: 0.8333 - val_loss:
0.9984 - val_acc: 0.6667
Epoch 9 / 30
5 / 5 - 3 s - loss: 0.6162 - acc: 0.8069 - val_loss:
1.1490 - val_acc: 0.5667
Epoch 10 / 30
5 / 5 - 3 s - loss: 0.7509 - acc: 0.7600 - val_loss:
1.3168 - val_acc: 0.5000
Epoch 11 / 30
5 / 5 - 4 s - loss: 0.6180 - acc: 0.7862 - val_loss:
1.1918 - val_acc: 0.7000
Epoch 12 / 30
5 / 5 - 3 s - loss: 0.4936 - acc: 0.8467 - val_loss:
1.0488 - val_acc: 0.6333
Epoch 13 / 30
5 / 5 - 3 s - loss: 0.4290 - acc: 0.8400 - val_loss:
0.9400 - val_acc: 0.6667
Epoch 14 / 30
5 / 5 - 3 s - loss: 0.4205 - acc: 0.8533 - val_loss:
1.0716 - val_acc: 0.7000
Epoch 15 / 30
5 / 5 - 4 s - loss: 0.5750 - acc:
0.8067 - val_loss: 1.2055 - val_acc: 0.6000
Epoch 16 / 30
5 / 5 - 4 s - loss: 0.4080 - acc: 0.8533 - val_loss:
1.5014 - val_acc: 0.6667
Epoch 17 / 30
5 / 5 - 3 s - loss: 0.3686 - acc: 0.8467 - val_loss:
1.0441 - val_acc: 0.5667
Epoch 18 / 30
5 / 5 - 3 s - loss: 0.5474 - acc: 0.8067 - val_loss:
0.9662 - val_acc: 0.7333
Epoch 19 / 30
5 / 5 - 3 s - loss: 0.5646 - acc: 0.8138 - val_loss:
0.9151 - val_acc: 0.7000
Epoch 20 / 30
5 / 5 - 4 s - loss: 0.3579 - acc: 0.8800 - val_loss:
1.4184 - val_acc: 0.5667
Epoch 21 / 30
5 / 5 - 3 s - loss: 0.3714 - acc: 0.8800 - val_loss:
2.0762 - val_acc: 0.6333
Epoch 22 / 30
5 / 5 - 3 s - loss: 0.3654 - acc: 0.8933 - val_loss:
1.8273 - val_acc: 0.5667
Epoch 23 / 30
5 / 5 - 3 s - loss: 0.3845 - acc: 0.8933 - val_loss:
1.0199 - val_acc: 0.7333
Epoch 24 / 30
5 / 5 - 3 s - loss: 0.3356 - acc:
0.9000 - val_loss: 0.5168 - val_acc: 0.8333
Epoch 25 / 30
5 / 5 - 3 s - loss: 0.3612 - acc: 0.8667 - val_loss:
1.7924 - val_acc: 0.5667
Epoch 26 / 30
5 / 5 - 3 s - loss: 0.3075 - acc: 0.8867 - val_loss:
1.0720 - val_acc: 0.6667
Epoch 27 / 30
5 / 5 - 3 s - loss: 0.2820 - acc: 0.9400 - val_loss:
2.2798 - val_acc: 0.5667
Epoch 28 / 30
5 / 5 - 3 s - loss: 0.3606 - acc: 0.8621 - val_loss:
1.2423 - val_acc: 0.8000
Epoch 29 / 30
5 / 5 - 3 s - loss: 0.2630 - acc: 0.9000 - val_loss:
1.4235 - val_acc: 0.6333
Epoch 30 / 30
5 / 5 - 3 s - loss: 0.3790 - acc: 0.9000 - val_loss:
0.6173 - val_acc: 0.8000 |
上述函数使用训练集训练神经网络,并在测试集上评估其性能。 函数为每个时期返回两个度量' acc '和' val_acc ',分别是在训练集中获得的预测的准确性和在测试集中获得的准确性。
结论
因此,我们看到已经达到了足够的精度。但是,任何人都可以通过增加时期数或任何其他参数来运行此模型。
|









