| 编辑推荐: |
本文主要介绍了AI在自动化测试领域的应用,主要从技术方案、测试框架的痛点、AI测试方向及取得的进展几个方面来介绍的。
本文来自于博客园,由火龙果软件Linda编辑、推荐。 |
|
一、技术方案
大家早上好,我是陈冠诚,很高兴有机会来到阿里的主场参加TICA2019-阿里巴巴质量技术创新大会。最近一两年随着深入学习技术浪潮的诞生,图像识别和自然语言处理领域技术的发展使得智能化测试成为可能,今天我想跟大家分享AI如何引领下一代测试的新航向。我们这一块的分享是抛砖引玉的,我相信不管是阿里,还是业界的同行在整个测试开发领域里面,大家都做了很多的实践,所以我今天希望跟大家分享一下我的观点。
二、测试框架的痛点
整个软件自动化诞生非常多的软件,不管是QTP,还是非常老的基于图形化的自动化测试的框架,这些框架都有非常多的痛点。
第一,学习成本高。需要一个具备测试开发能力的人写测试代码,我们知道测试分层,代码级的测试,服务级的测试,还有UI级的测试,我们把单元测试做得足够好,很多工作不用在接口层和UI层做,但是测试行业,因为人员结构的问题,不是所有的公司都是在阿里可以招聘很多有开发能力的测试工程师,作为初级或者说不太具备开发能力的从业人员,能否用一个简单的方法把自动化跑起来是一个问题。
第二个问题就是维护成本高,业务逻辑更新之后修改脚本花费的时间比较长,,脚本如何不用改,把维护成本尽可能降低到最低是第二个挑战。
第三个就是跨平台。测试脚本如何尽可能复用?我们看很多的APP,包括现在的小程序他们的业务逻辑是共通的地方。从技术角度上面去看未来,能不能实现跨平台和应用的复用,这一块是我们看到典型的问题。
三、AI测试方向
可喜的是,随着深度学习的这一波浪潮,我们确实看到有一些问题可以在我们的量变基础上开始产生一定的质变。目前能够看到是,整个自动化测试领域里面,深度学习在视觉相关的处理,比如说图像的处理、文字的处理,包括整个测试的自然语言的交互上面,确实有可取之处,能够把我们整个自动化的水平往上提升一个台阶。

我们把整个方向分为四大块,第一大块,是机器像人一样看懂人话,比如说你告诉他说,你帮我测试我的登录功能,他帮助你测试,你告诉他说测试我的转账功能,你告诉他的逻辑之后,他可以帮助你生成各种各样的用例,当然今天我们没有完全做到这点,但我觉得这是未来大的方向,就是机器像人一样看懂人话。
第二个环节,是机器怎么样像人一样理解图形。在整个应用里面,随着多媒体、短视频和长视频出现在应用里面,不管你是搜索图标,还是一个图片,还是一个APP里面有导航栏、文字、图文典型的场景,人可以识别哪些是图哪些是文,那有没有可能机械像人一样知道哪些是图,哪些是文,知道哪些是导航。从未来来讲,随着整个自动化程度的越来越高,机器应该可以像人一样理解整个图形,包括整个版面的逻辑关系。
第三个环节是自定义图标,人不可能穷举各种各样的图标:因为图标是带灵感和创造性的,不可穷举。机器有没有可能对自定义的图标可以比较好的理解它,这是我们想要解决的第三个问题。
第四个问题就是机器有没有可能像人一样执行测试用例,其实核心点是有没有可能在执行过程当中对图片文字或者是业务逻辑进行很好的识别。
四、取得的进展
跟大家分享我们取得的一些进展,第一个是自然语言的脚本,第二个是OCR文字识别,第三个是以图找图和通用图标的识别。
第一、自然语言脚本。在整个测试中有非常多的工作,我们核心目标是降低测试工程师编写脚本的难度,实现一个目标——会说中文,就能够写自动化测试。

如图所示,右边是我们可以做到的效果,左边这个大家都是熟悉的,写一段自动化测试代码,右边是我们iTestin实现的能力:比如说向下滑动的操作,只要写向下滑动这四个字就可以做向下滑动的操作。我们希望用纯中文的方式实现跨平台,无视控件变动,降低脚本维护成本,利用自然语言的优势,编写效率高,易理解,易维护。大家阅读别人阅读的自然语言的脚本,理解比较容易,维护难度也降低了。这是我们目前的语法规则,核心是会中文就会写测试程序,会用手机就理解别人写的测试程序。

第二块是在OCR上面做的事情。传统的OCR文字识别的方法,有很大的局限性,就是识别率不够高。我们面临的场景是应用的文字识别,首先是印刷字体。我们做测试的时候,很多时候基于业务功能做逻辑的回归,这个时候需要识别准确的对象,往往是核心功能的按纽,把这些按钮进行特征分析,会发现他们典型的特征是印刷字体。其次很多时候都是水平排列,或者是垂直排列,或者是带角度排列相对特别少。这牵扯到说我们做识别的时候,要做的任务存在哪个象限,就是在学界和工业界大家比较公认的OCR或者是文字识别的象限。最难就是右下角通用手写体的识别,你用手机拍的海报是毛笔字你怎么识别它,我们的手机截屏是属于右上角,属于第二个难度,不是属于最困难的一类。今年有一个专门的文字识别竞赛,这个场景下面目前来讲最高识别精度在70%左右。比较容易是左下角基于定制化的表格,他有很强的规则,比如说,身份证的文字有多少个字都是固定的。
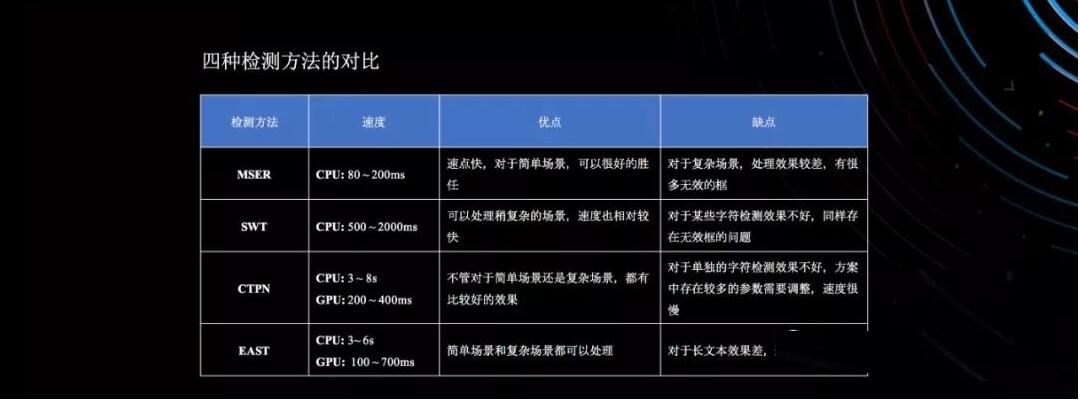
首先讲文字识别,现在做深度学习是讲端到端,端到端可以分为两个环节,第一个环节文字检测,你标注出来应用的截屏哪些是文字块,哪些不是文字块,这就是文字的检测,第二个阶段把检测出来的文字块进行识别,识别出来这个文字块里面有哪些单词,加上标点符号组成。
文字识别在深度学习浪潮起来之前,有基于传统机器学习的方法,有两种是典型的,基于非常多的规则,包括精巧算法的设计,相对不是这么通用,但是垂直领域的使用下精度还好。但是一旦遇到自然场景,带角度、旋转、光线,因为他们不是靠训练数据驱动的,它的识别效果不如CPTN或者是EAST这种算法这么好。
但是我们识别的时候需要做精度和性能之间的平衡,后面两种方案最大的问题是必须要求GPU才有一个比较好的性能,有好的GPU才能有500毫秒的性能。我们这个产品可以云端部署和私有化部署,私有化部署如果要求客户配置一个GPU才能跑起来,对于有的客户来讲不能承受,我们内部实现多个版本,CPU和GPU方案都支持,可以根据用户的场景和预算灵活配置。
下面讲讲识别。文字识别是基于CRNN的模型做的。这是业界里面相对通行的方法。基于CRNN的思想,最核心点就是使用CNN的方法提取图像的特征,通过循环神经网络,利用OCR典型的特征去识别,不是一个一个的字符去识别,而是识别一个词,词有上下文的关联关系,登录是有上下文,循环神经网络可以实现。
我们在整个深度学习和机器学习里面有算法和数据,还有算力。这里面又牵扯到另外一个问题,数据怎么来的问题。我们知道最简单的方法或者是最容易想到的方法是做大量APP界面截屏或者是人工做标注,但是你想要拿到千万级别的训练数据,用人工的方式效率非常低。
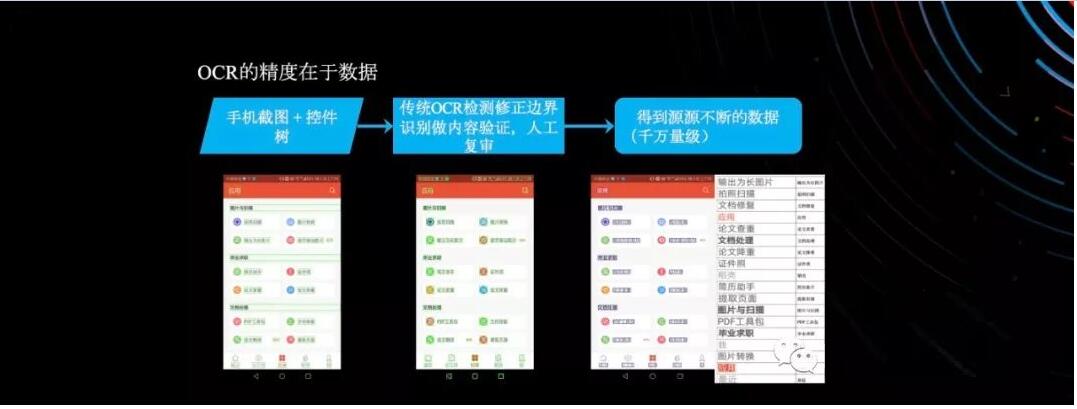
我们考虑一点是说从手机的角度来讲,包括APP的角度上面来讲,我们用自动化测试的引擎,做大量App的测试执行。比如说有5万台手机可以做大量的手机的截屏,先做第一步的筛选,用控件树的信息,把文字的内容和控件的内容进行关联。再用机器做校验,然后用人工做校验。用OCR做检测,主要是对他位置的框定。把自己的传统的OCR识别匹配上面的信息给对应起来做框定,可以拿到很多数据。其实靠数据做检测不一定准,我们还有人工复核,我们请Testin云测的AI数据标注部门来帮助我们做这事情,机器生成之后机器做二次校验,人工再做校验,得到源源不断的数据。
还有一个有意思的点就是数据的泛化,有很多场景数据模拟显示不全,不同的背景,模拟分辨率低,模拟立体可以通用机器的方法实现,可以通过数据的变形之后拿到大量训练的数据样本。
这些都是跟数据训练相关,还有一块是性能。很多客户不具备用GPU部署的能力,我们在想有没有办法在CPU上面跑更好,OpenVINO是英特尔基于自身现有的硬件平台开发的一个框架。这是我们跟某一家云厂商的付费OCR高精度版本在APP上的测试结果,我们比他们在App和Web场景下精度更高。

第三,以图找图和图标识别。我们想要实现三个目标,看左边第一个图,这是一个典型的图文场景,我们看到手机的截屏,不管任何一个图片在屏幕上面的位置会发生变化,甚至背景颜色也会不一样,我们希望实现在不同的背景颜色下面找到同一个图。
第二个就是常见的系统按纽,典型安卓三个按纽,返回,主页,还有系统功能,有很多图标是通用的,比如说,主页加一个搜索图标,通用图标能不能做更好的识别。
在这个图标里面有一个问题,不同的设备上面,分辨率不同,识别图标的大小不一样,第二个很多的图标是非常简约的设计,特征点非常小,不像做猫或者是狗,目标和整个轮廓性比较丰富,我们很多图标只有一个线,非常的抽象,这个特征非常少的情况下,你怎么样对他进行识别,给我们带来非常多的挑战。
第三个就是场景或者是背景会发生变化,比如说暂停按纽在不同播放音乐过程当中背景发生变化,但是人眼可以看出来是同一个图标,但是机器怎么样进行识别。我们用的算法很简单,我们不认为深度学习就是唯一的方法,我们发现特征工程+深度学习结合更好,因为传统算法很轻量,这是我们不为深度学习论的最核心的原因,因为他需要GPU才能跑起来。第二点我们在整个全屏搜索上面我们做了大量优化,优化全屏搜索效率。第三个相似度的判别器。我们和行业大厂的以图找图的工具做过对比,他们的精度在68-70%,我们的以图找图精度可以达到97%。
还有一类是通用图标,这里使用100W+图标标注数据做训练。国外有学者做开源的数据集,他们也是用机器控件进行识别和人工标注的方式结合。这里回到另外一个问题,我们讲深度学习或者是AI有多少人工才有多少智能。我们人工标100万的图标级,比如说,典型的前进,搜索,收藏等等典型的图标。举一个应用的例子,比如说自动在整个应用里面找出哪些是“个人中心”的图标,“更多”这样的图标,包括“主页”这样的图标,还有“返回”的相关图标。
举一个真实QQ音乐APP的应用场景。你点击搜索,他直接点击搜索,通过OCR直接找点击搜索音乐这四个字,这时我们说输入周杰伦,他就会输入周杰伦在输入框里面。点击周杰伦《说好不哭》,他就会通过OCR里面输入周杰伦《说好不哭》,点击第三个《说好不哭》,第三个是我们的关键字,他会被点击到,这里有一个相对位置,我们在移动目标的下侧找另外一个目标,这是点击下侧,输入画像向右滑动,点击暂停按钮。这个时候,暂停按纽是人工标注好,点击分享按纽,分享按纽是我们识别过的这是一个分享按纽。
数据在这个行业里面是最大的壁垒,为什么这么说呢,因为我们去讲算法、算力、数据这三个要素。我认为今天来讲,算法可以通过招到优秀的人才可以解决,包括今天很多算法大家分阶段学界发表相关的论文,但是数据这个事情,相对来说壁垒更高的一件事情。我们有大量的真机,做了各种各样的自动化测试,通过这些测试,确实有可能让整个门槛变得更高。
比如说OCR,前几天遇到识别错误的Bug,用户用非常艺术化的字体进行识别,我们训练的字库里面没有这个字体。因为我们见到了这个字体,所以我们想到要把这个字体拿到我们的训练数据里面来,加入到OCR文字识别里面,让整个文字识别的精度更高,这是我发现数据在AI应用里面最核心的一个场景,或者是最核心的一个壁垒。
五、总结
AI在自动化测试里面的一些工作,我觉得今天能够到测试的三大环节,一个是测试用例的生成,测试的执行,测试结果的生成。整个测试的执行环节,通过文字识别,图像的识别,图标的识别,让整个测试的执行变得更加稳定,兼容性更好,而不用基于传统机械控件的方式,因为OCR可以通过自动检测,哪怕你整个文字也好,包括你的控件在页面上换了位置,只要还在这个页面上,算法都可以自动进行检测,原来用控件的方式你要告诉整个脚本控件变成了什么,所以整个识别变得更加智能,包括说整个测试结果的解析上面,不管说自动进行UI异常的识别,兼容性的识别,崩溃的识别,还有各种数据的分享,把整个测试的结果变得更智能。
深度学习核心可以做的事情就是重复性的事情,比如说文字的识别,图标的识别,这些事情都是属于重复性的工作,什么是重复性的工作:汉字就10000个。我们对技术有深刻的信仰,相信技术能推动整个行业发展,不管是深度学习的突破或者是强化学习的突破,会在整个自动化测试行业上有更多的进展。我相信Testin云测也好,阿里也好,还是在座的各位同仁大家都应该做非常多的尝试,期待下一次有机会跟大家一起交流,向大家学习和分享AI怎么样把云测试变得更好。 |









