| 编辑推荐: |
本文主要介绍了大数据架构、Spark
MLib、Parameter Server、Tensorflow离线分布式训练。
本文来自于简书,由火龙果软件Anna编辑、推荐。 |
|
大数据架构
1.批处理
MapReduce无法应对实时不确定量的小样本处理,只能累积到一定数量再进行批处理。
2.流计算(Storm,Spark,Flink)
使用滑动窗口,在滑动窗口内的数据全部完成后再滑动到下一个时间窗口进行新一轮的数据处理,以分钟级别居多。对不同数据流还能join,并在同一个时间窗口内做整合处理。
还可以作为下游的输入。
灵活,延迟小。但是也有较短窗口下的日志乱序,join操作的数据遗漏的问题。
3.Lambda架构(流+批)
实时流计算(增量计算为主保证实时性)+离线批处理(全量计算保证一致性),在存入最终的数据库之前还会将实时流数据与离线数据合并。
4.Kappa架构(解决计算冗余)
很明显实时计算的代码逻辑其实可以跟离线计算部分共享。所以可以将批处理也以流的方式执行。比如批处理时间窗口设置为一天,流处理5分钟。
实现离线流计算的思路:
(1)原始数据存储:原封不动将未经流计算的数据丢到分布式文件系统中慢慢处理
(2)数据重播:按时间顺序重播,并用同样的流处理框架进行处理。
Spark MLib
分布式机器学习训练有三个主要的方案,分别是Spark MLlib,Parameter Server和TensorFlow,倒不是说他们是唯三可供选择的平台,而是因为他们分别代表着三种主流的解决分布式训练方法。
Spark,是一个分布式的计算平台。所谓分布式,指的是计算节点之间不共享内存,需要通过网络通信的方式交换数据。要清楚的是,Spark最典型的应用方式是建立在大量廉价计算节点上,这些节点可以是廉价主机,也可以是虚拟的docker
container;但这种方式区别于CPU+GPU的架构,或者共享内存多处理器的高性能服务器架构。
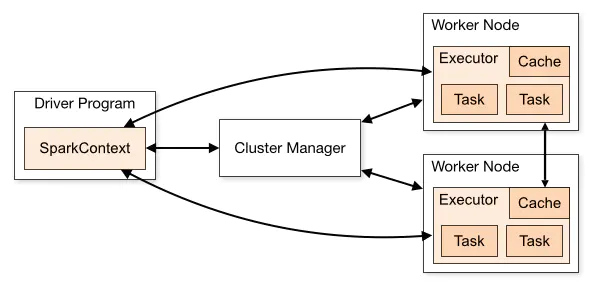
spark架构
Spark程序由Manager node进行调度组织,由Worker Node进行具体的计算任务执行,最终将结果返回给Drive
Program。在物理的worker node上,数据还可能分为不同的partition,可以说partition是spark的基础处理单元。
在执行具体的程序时,Spark会将程序拆解成一个任务DAG(有向无环图),再根据DAG决定程序各步骤执行的方法。如图2所示,该程序先分别从textFile和HadoopFile读取文件,经过一些列操作后再进行join,最终得到处理结果。
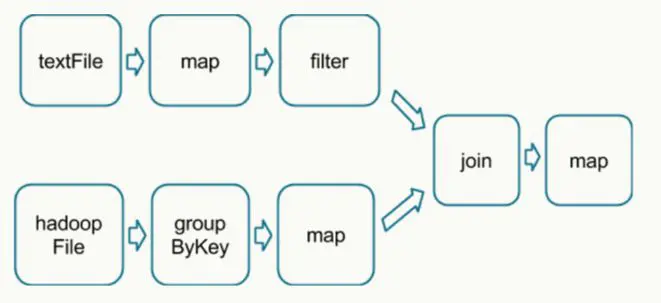
在得到最终的计算结果之前,程序需要进行reduce的操作,从各partition上汇总统计结果,随着partition的数量逐渐减小,reduce操作的并行程度逐渐降低,直到将最终的计算结果汇总到master节点上。
这里的shuffle指的是所有partition(数据分片)的数据必须进行洗牌后才能得到下一步的数据,最典型的操作就是图中的groupByKey和join操作。拿join操作来说,必须通过在textFile数据中和hadoopFile数据中做全量的匹配才可以得到join后的dataframe。而groupby操作需要对数据中所有相同的key进行合并,也需要全局的shuffle才能够完成。
所以可以说shuffle(混洗)和reduce操作的发生决定了纯并行处理阶段的边界。如下图所示,Spark的DAG被分割成了不同的并行处理阶段(stage)。
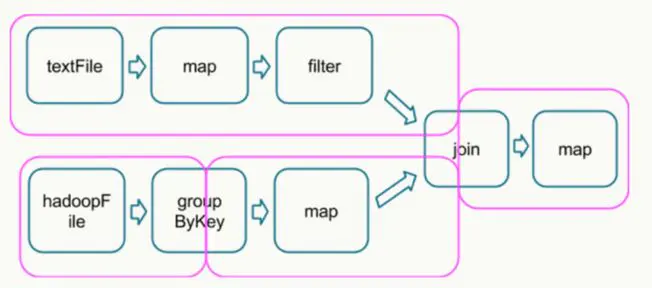
被shuffle操作分割的DAG stages
map,filter等操作仅需要逐条的进行数据处理和转换就可以,不需要进行数据间的操作,因此各partition之间可以并行处理。
需要强调的是shuffle操作需要在不同计算节点之间进行数据交换,非常消耗计算、通信及存储资源,因此shuffle操作是spark程序应该尽量避免的。一句话总结Spark的计算过程就是:Stage内部数据高效并行计算,Stage边界处进行消耗资源的shuffle操作或者最终的reduce操作。
代码示例:
while (i <=
numIterations) { //迭代次数不超过上限
val bcWeights = data.context.broadcast(weights)
//广播模型所有权重参数
val (gradientSum, lossSum, miniBatchSize) =
data.sample (false, miniBatchFraction, 42 + i).treeAggregate()
//各节点采样后计算梯度,通过treeAggregate汇总梯度
val weights = updater.compute (weights, gradientSum
/ miniBatchSize) //根据梯度更新权重
i += 1 //迭代次数+1
} |
经过精简的代码非常简单,Spark的mini batch过程制作了三件事:
把当前的模型参数广播到各个数据partition(可当作虚拟的计算节点)
各计算节点进行数据抽样得到mini batch的数据,分别计算梯度,再通过treeAggregate操作汇总梯度,得到最终梯度gradientSum
利用gradientSum更新模型权重
这样一来,每次迭代的Stage和Stage的边界就非常清楚了,Stage内部的并行部分是各节点分别采样并计算梯度的过程,Stage的边界是汇总加和各节点梯度的过程。这里再强调一下汇总梯度的操作treeAggregate,该操作是进行类似树结构的逐层汇总,整个操作流程如下图所示。
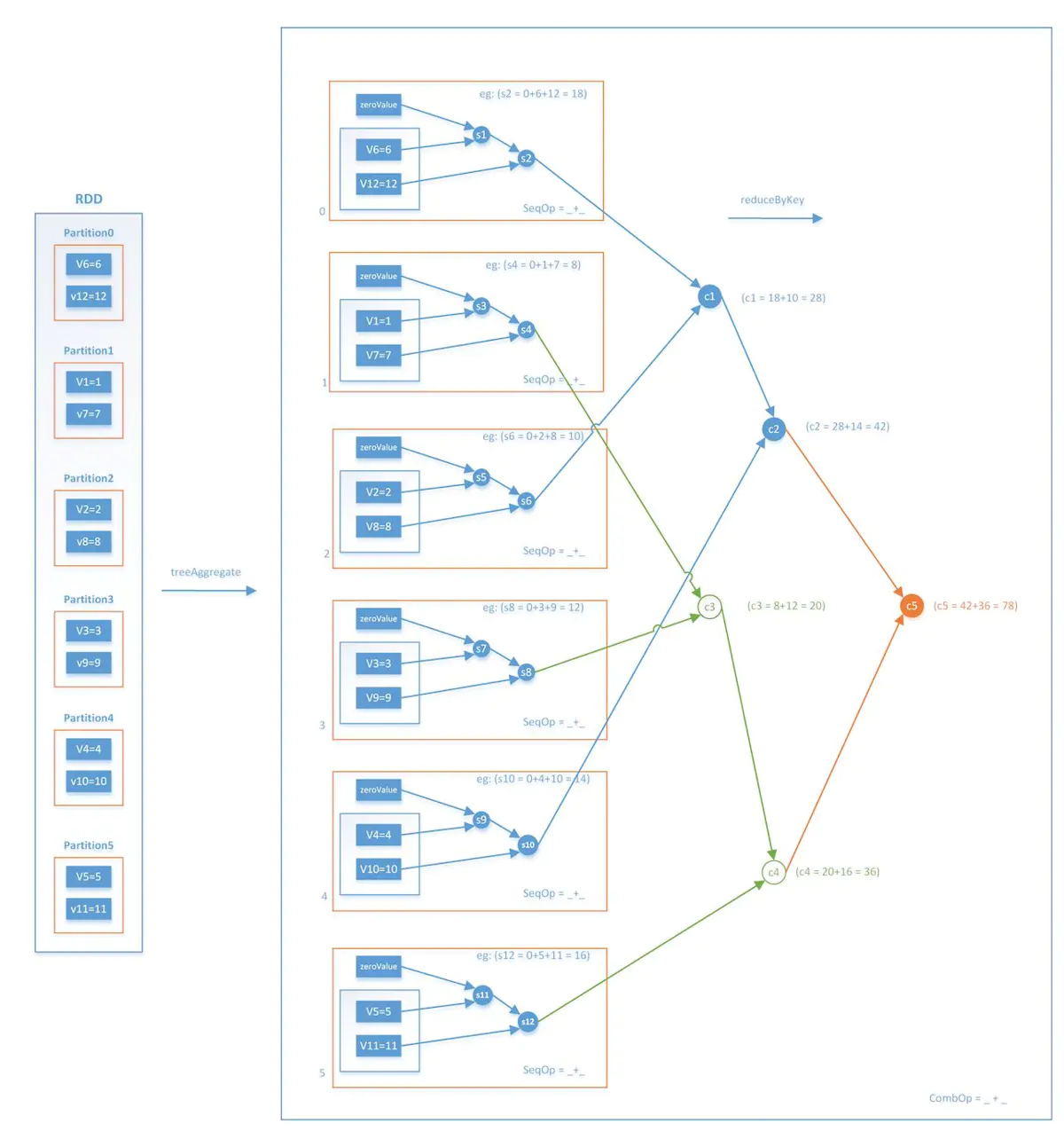
事实上,treeAggregate是一次reduce操作,本身并不包含shuffle操作,再加上采用分层的树形操作,在每层中都是并行执行的,因此整个过程是相对高效的。
在迭代次数达到上限或者模型已经充分收敛后,模型停止训练。这就是Spark MLlib进行mini batch梯度下降的全过程,也是Spark
MLlib实现分布式机器学习的最典型代表。
Spark MLlib并行训练的局限性
使用Spark MLlib训练复杂神经网络时,往往力不从心,不仅训练时间过长,而且在模型参数过多时,经常会存在内存溢出的问题。具体来讲,Spark
MLlib的分布式训练方法有下面几个弊端:
采用全局广播的方式,在每轮迭代前广播全部模型参数。众所周知Spark的广播过程非常消耗带宽资源,特别是当模型的参数规模过大时,广播过程和在每个节点都维护一个权重参数副本的过程都是极消耗资源的过程,这导致了Spark在面对复杂模型时的表现不佳;
采用阻断式的梯度下降方式(水桶效应),每轮梯度下降由最慢的节点决定。从上面的分析可知,Spark MLlib的mini
batch的过程是在所有节点计算完各自的梯度之后,逐层Aggregate最终汇总生成全局的梯度。也就是说,如果由于数据倾斜等问题导致某个节点计算梯度的时间过长,那么这一过程将block其他所有节点无法执行新的任务。这种同步阻断的分布式梯度计算方式,是Spark
MLlib并行训练效率较低的主要原因;
Spark MLlib并不支持复杂网络结构和大量可调超参。事实上,Spark MLlib在其标准库里只支持标准的多层感知机神经网络的训练,并不支持RNN,LSTM等复杂网络结构,而且也无法选择不同的activation
function等大量超参。这就导致Spark MLlib在支持深度学习方面的能力欠佳。
Spark的问题:
如果希望在Spark上训练深度学习模型,你有没有改进Spark的方法?使用第三方lib?还是修改Spark源码?还是自研Spark模型?(Intel的BigDL和腾讯的Spark
on Angel)
把worker当作tf中pserver的worker 通过spark做数据分发
在训练完成Spark模型后,应该使用什么方式将Spark模型deploy到线上环境,做线上的实时inference?
关于 spark 模型 deploy 到线上做实时 inference 的问题。我们有 xgboost4j
的 spark 版本训练 xgboost 模型,然后 dump 成单机的模型,线上直接加载模型到内存提供
serving 。不过这个模型不是 spark mllib 原生支持的,中间模型的序列化也是利用 xgboost
本身提供的语言无关的格式。更多的spark mllib 的场景还是离线训练 spark 模型,然后用来做离线
batch 预测的任务。
Spark对于高维离散特征支持不够,大概特征到了5千万,训练程序就会挂掉。大公司基本都是基于mpi的分布式机器学习训练的模型。Spark这种单master节点的架构,海量稀疏特征肯定会挂在梯度aggregate和参数broadcast的过程中。(最终还是得上多master)
Parameter Server
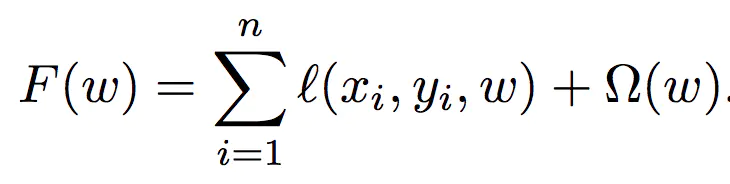
带正则化项的loss function
由于公式中正则化项的存在需要汇总所有模型参数才能够正确计算,因此较难进行模型参数的并行训练,因此Parameter
Server采取了和Spark MLlib一样的数据并行训练产生局部梯度,再汇总梯度更新参数权重的并行化训练方案。

Parameter Server由server节点和worker节点组成,其主要功能分别如下:
(1)server节点的主要功能是保存模型参数、接受worker节点计算出的局部梯度、汇总计算全局梯度,并更新模型参数
(2)worker节点的主要功能是各保存部分训练数据,从server节点拉取最新的模型参数,根据训练数据计算局部梯度,上传给server节点。
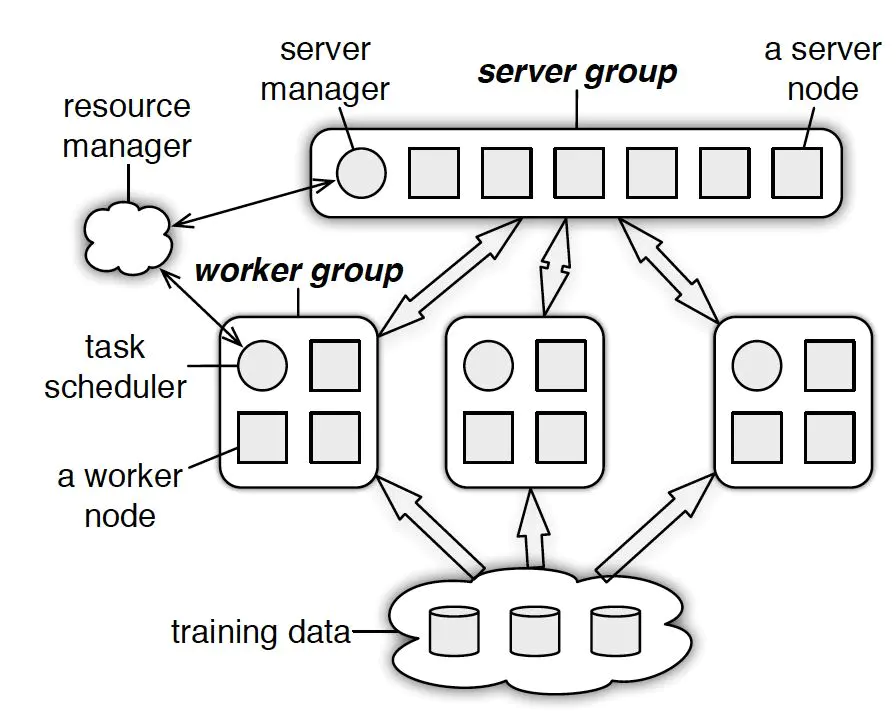
PS总流程:
(1)每个worker载入一部分训练数据
(2)worker节点从server节点pull最新的全部模型参数
(3)worker节点利用本节点数据计算梯度
(4)worker节点将梯度push到server节点
(5)server节点汇总梯度更新模型
(6)goto step2 直到迭代次数上限或模型收敛
对于稀疏LR这种模型,可以对它的参数pull环节进行选择性拉取非0参数。
实在等不及,能不能先算下一步?(一致性与并行效率之间的取舍)
PS异步非阻断式梯度下降:节点在做第11次迭代(iter11)计算时,第10次迭代后的push&pull过程并没有结束,也就是说最新的模型权重参数还没有被拉取到本地,该节点仍使用的是iter10的权重参数计算的iter11的梯度。
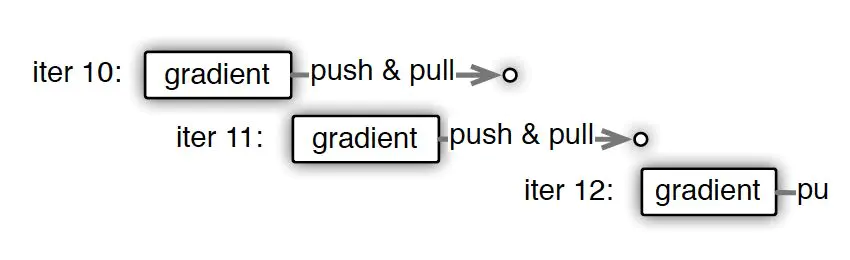
异步梯度更新
异步梯度更新的方式虽然大幅加快了训练速度,但带来的是模型一致性的丧失,也就是说并行训练的结果与原来的单点串行训练的结果是不一致的,这样的不一致会对模型收敛的速度造成一定影响。所以最终选取同步更新还是异步更新取决于不同模型对于一致性的敏感程度。这类似于一个模型超参数选取的问题,需要针对具体问题进行具体的验证。 
多server节点的协同和效率问题(一致性hash分配server)
单master节点作为一个瓶颈节点,受带宽条件的制约,发送全部模型参数的效率不高;同步地广播发送所有权重参数,使系统整体的网络负载非常大。
PS采用了server group内多server的架构,每个server主要负责一部分的模型参数。模型参数使用key
value的形式,每个server负责一个key的range就可以了。
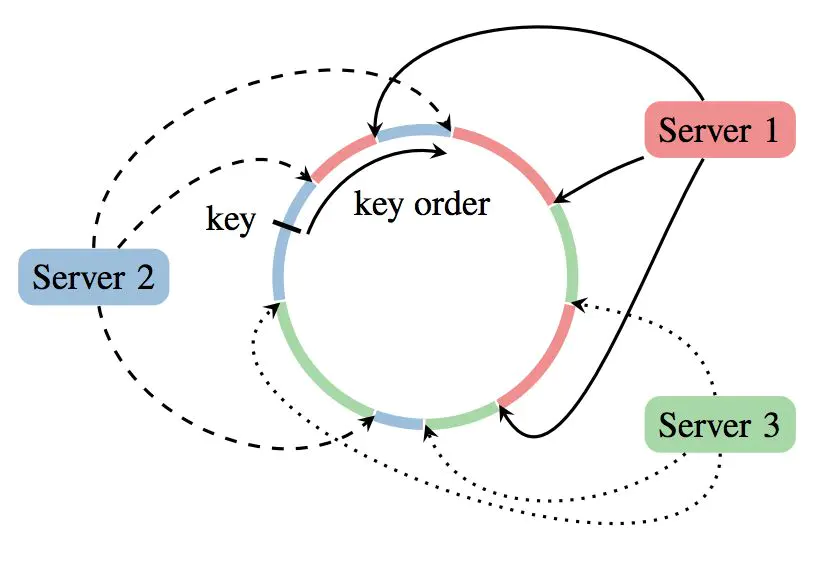
现在某worker节点希望pull新的模型参数到本地,worker节点将发送不同的range pull到不同的server节点,server节点可以并行的发送自己负责的weight到worker节点。
Tensorflow离线分布式训练
tf基于任务关系图进行任务调度和并行计算。
tf训练分两层,一层是分布式的PS架构,一层是单机的worker节点内部的CPU+GPU的并行计算架构。
|









