| 编辑推荐: |
本文主要介绍机器学习开发流程、特征工程是什么?特征抽取/提取、特征预处理、特征降维等相关内容。
本文来自于csdn,由火龙果软件Linda编辑、推荐。 |
|
机器学习开发流程概括
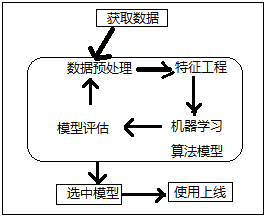
数据预处理:在python中使用pandas库,如:缺失值、异常值等的数据清洗、数据处理
Pandas数据处理
特征工程概括
特征工程:是使用专业背景知识和技巧处理数据,使得特征值(自变量)能在机器学习算法上发挥更好的作用的过程。
python的sklearn库,对于特征工程的处理提供了强大的接口
特征工程主要包含的内容:
特征抽取/提取:将任意数据(文本、图像等)转化为可以用作机器学习的数字特征
文本类型--->数值型;分类型数据:字符串--->数值型
特征预处理
特征降维
1、特征抽取/提取
1.1、 字典特征提取-类别->one-hot编码
sklearn.feature _extraction.DictVectorizer (sparse=True/False..)
- DictVectorizer.fit_transform(X) X:字典或者包含字典的迭代器返回值;返回sparse矩阵
- DictVectorizer.inverse_transform(X) X:array数组或者sparse矩阵返回值:转换之前数据格式
- DictVectorizer.get_feature_names()
返回类别名称
'''字典特征抽取取'''
from sklearn.feature_extraction import DictVectorizer
# 1、数据:字典或字典迭代器形式
data=[{"city":"北京","housing_price":250},
{"city":"上海","housing_price":260},
{"city":"广州","housing_price":200}]
#字典迭代器
# 2、实例化一个转换器类
transfer = DictVectorizer (sparse=True)
# 3、调用fit_transform()
data_new = transfer.fit_transform(data)
print(data_new) #非0值的坐标,值
'''
(0, 1) 1.0
(0, 3) 250.0
(1, 0) 1.0
(1, 3) 260.0
(2, 2) 1.0
(2, 3) 200.0
'''
print (transfer.get_feature_names()) #返回类别名称
# 2、实例化一个转换器类
transfer = DictVectorizer(sparse=False)
# 3、调用fit_transform()
data_new = transfer.fit_transform(data)
print(data_new) #二维数组
'''
[[ 0. 1. 0. 250.]
[ 1. 0. 0. 260.]
[ 0. 0. 1. 200.]]
'''
print (transfer.get_feature_names()) #返回类别名称
#['city=上海', 'city=北京', 'city=广州', 'housing_price'] |
1.2、文本特征提取
单词、词语:作为特征值
方法1: sklearn.feature_extraction.text
.CountVectorizer(stop_words=[]),
返回词语出现的次数,返回词频矩阵,stop_words=[]停用词列表
·CountVectorizer.fit_transform(X)X:文本或者包含文本字符串的可迭代对象返回值:返回sparse矩降
·CountVectorizer.inverse_transform(X)Xarray数组或者sparse矩阵返回值;转换之前数据格
·CountVectorizer.get_feature_names()
返回值;单词列表
import pandas
as pd
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
data=["Maybe it was better to just really
enjoy life. this is the life","享受生活,顺其自然。这就是生活"]
transfer = CountVectorizer() #实例化一个转换器类
data_new = transfer.fit_transform (data) #调用fit_transform()
#print(data_new)
print(transfer.get_feature_names())
print(data_new.toarray())
#构建成一个二维表:
data=pd.DataFrame(data_new.toarray(), columns=transfer.get_feature_names())
display(data)
#其实发现中文的分词效果并不好,原因:分词原理,根据空格、标点符号等特殊字符切分 |

中文文本的分词
需要借助jieba分词库
import pandas
as pd
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
import jieba #(jieba 分词,安装: pip install jieba)
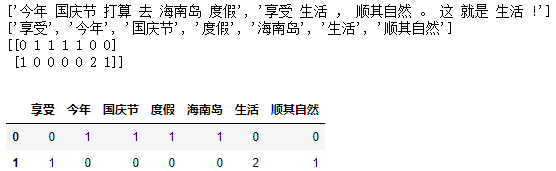
data=[u'今年国庆节打算去海南岛度假',"享受生活,顺其自然。这就是生活!"]
#分词
cut_data=[]
for s in data:
cut_s=jieba.cut(s)
l_cut_s=' '.join(list(cut_s))
cut_data.append(l_cut_s)
print(cut_data)
#统计特征词出现次数
transfer = CountVectorizer(stop_words=["打算","就是"])
#实例化一个转换器类,
# stop_words=["打算","就是"],去除不想要的词
data_new = transfer.fit_transform (cut_data) #调用fit_transform()
#print(data_new)
print(transfer.get_feature_names())
print(data_new.toarray())
#构建成一个二维表:
data=pd.DataFrame(data_new.toarray(), columns=transfer.get_feature_names())
display(data) |
方法2:sklearn.feature_extraction.text.
TfidfVectorizer(stop_words=None)
·TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。返回的值越高,找到这篇文章更为关键从词。
·TF-IDF作用:用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。

import pandas
as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
import jieba #(jieba 分词,安装:pip install jieba)
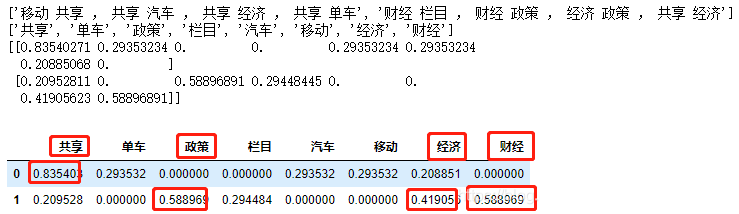
#数据
data=["移动共享,共享汽车,共享经济,共享单车","财经栏目,财经政策,经济政策,共享经济"]
#分词
cut_data=[]
for s in data:
cut_s=jieba.cut(s)
l_cut_s=' '.join(list(cut_s))
cut_data.append(l_cut_s)
print(cut_data)
#TF-IDF
transfer = TfidfVectorizer() #实例化一个转换器类
data_new = transfer.fit_transform (cut_data) #调用fit_transform()
#print(data_new)
print(transfer.get_feature_names())
print(data_new.toarray())
#构建成一个二维表:
data=pd.DataFrame (data_new.toarray(), columns=transfer.get_feature_names())
display(data) |
2、特征预处理
通过一些转换函数将特征数据转换成更加适合算法模型的特征数据。
包含内容:
数值型数据的无量钢化:
归一化
标准化
对于归一化来说:如果出现异常点,影响了最大值和最小值,那么结果显然会发生改变。
对于标准化来说:如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小。
特征预处理API:
sklearn.preprocessing
为什么我们要进行归一化/标准化?
·特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响(支配)目标结果,使得一些算法无法学习到其它的特征。
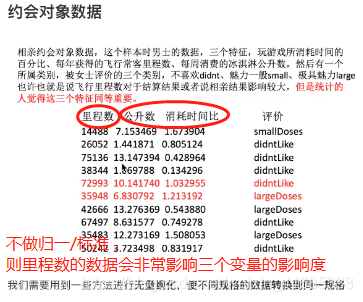

2.1、归一化:
归一化缺点:异常值(缺失等),如果最大值和最小值异常时不能处理


# 归一化处理
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
#归一化库
# 1.获取数据
df = pd.read_csv(r"E:\Normalization.txt", sep="
",encoding="utf-8")
display(df.sample(3))
x = df.iloc[:,:3]
display(x.head(3))
#2.实例化一个转换器类
transfer = MinMaxScaler(feature_range=(10,20))
#实例化一个转换器类
# feature_range=(10,20),设置归一化后的数据取值范围
#3.#调用fit_transform()
xi = transfer.fit_transform(x) #调用fit_transform()
print(xi)
#4、转化为二维表
data = pd.DataFrame (xi,columns=x.columns)
data["y"] = df['y']
display(data) |
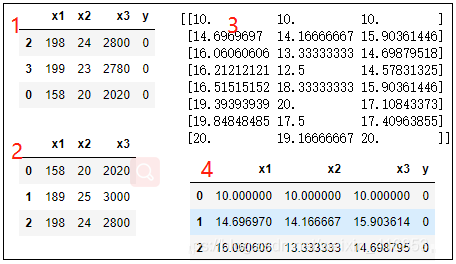
2.2、标准化:
标准化有效地避免了归一化的缺点(最大值和最小值带来的影响)

# 标准化处理(转化为均值为0,标准差为1
附近的值)
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
#归一化库
# 1.获取数据
df = pd.read_csv(r"E:\Normalization.txt", sep="
",encoding="utf-8")
display(df.sample(3))
x = df.iloc[:,:3]
display(x.head(3))
#2.实例化一个转换器类
transfer = StandardScaler() #实例化一个转换器类
#3.#调用fit_transform()
xi = transfer.fit_transform(x) #调用fit_transform()
print(xi)
#4、转化为二维表
data = pd.DataFrame(xi,columns=x.columns)
data["y"] = df['y']
display(data.tail(3)) |
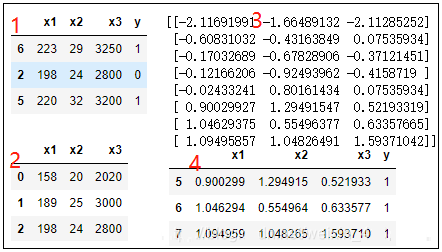
3、特征降维
降维是指在某些限定条件下,降低随机变量(特征变量、自变量)个数,得到一组“不相关”主变量的过程
目的:降维得到的特征变量之间是不相关的,去除冗余特征变量。
方法:特征选择、主成分分析
3.1、特征选择
数据中包含冗余或相关变量(或称特征、属性、指标等),旨在从原有特征中找出主要特征。
方法:
Filter(过滤式):主要探究特征本身特点、特征与特征和目标值之间关联
方差选择法:低方差特征过滤
相关系数
删除低方差的一些特征,前面讲过方差的意义。再结合方差的大小来考虑这个方式的角度。
相关性高的特征变量进行降维,可以去除不重要特征变量或者从新构造新的特征变量(如:加权求和主成分分析降维度)
Embedded(嵌入式):算法自动选择特征(特征与目标值之间的关联)
决策树:信息熵、信息增益
正则化:L1、L2?
深度学习:卷积等
方差选择法的python模块:sklearn.feature_selection
低方差特征过滤:
删除低方差的一些特征,前面讲过方差的意义。再结合方差的大小来考虑这个方式的角度。
·特征方差小:某个特征多样本的值比较相近
·特征方差大:某个特征很多样本的值都有差别

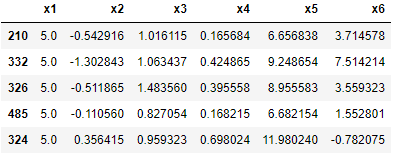
#构造一组特征值数据
import numpy as np
import pandas as dp
from scipy import stats
np.random.seed(10) # 先生成一个种子生成器,以后生成的随机数就是一样的,参数为任意数字
x1 = stats.norm.rvs (loc=5,scale=0.0,size=500)
#均值为5,标准差为0.0的正态分布,随机随机生成500个样本
x2 = stats.t.rvs(10, size=500) #生成服从t分布,自由度为10的500个随机数(rvs生成随机数)
x3 = stats.norm.rvs(loc=1,scale=0.5,size=500)
#均值为1,标准差为0.5的正态分布,随机随机生成500个样本
x4 = np.random.rand(500)
x5 = 10*x4+5 + stats.norm.rvs (loc=0,scale=0.0,size=500)
#stats.norm.rvs(loc=0,scale=0.0,size=500)用来构造残差
x6 = -5*x2 +1 + stats.norm.rvs (loc=0,scale=0.0,size=500)
#暂时不构造目标值y
data = pd.DataFrame ({"x1":x1,"x2":x2,"x3":x3, "x4":x4,"x5":x5,"x6":x6})
display(data.sample(5)) |
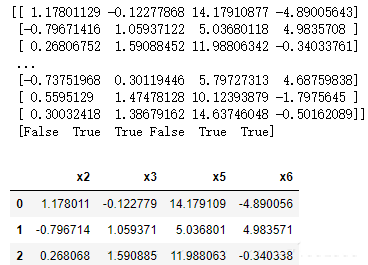
# 低方差特征过滤:
from sklearn.feature_selection import VarianceThreshold
#1、获取数据,上段代码构造的一组特征值数据data
#2.实例化一个转换器类
transfer = VarianceThreshold (threshold=0.25) #实例化一个转换器类
#threshold=0.25:用来设置方差的阀值,这里<=0.25的返回False,方差的阈值根据实际业务需求设定,默认为0.0
#3.#调用fit_transform()
xi = transfer.fit_transform(data) #调用fit_transform()
print(xi,"\n",transfer.get_support())
#4.输出过滤后的特征变量
data01=data.iloc [:,[False,True,True,False,True,True]]
display(data01.head(3))
#虽然x4是一组随机数,但方差<0.25,所以也被过滤掉了 |
相关性
相关系数(-1,1)
相关性高的特征变量进行降维,可以去除不重要特征变量或者从新构造新的特征变量(如:加权求和主成分分析降维度)
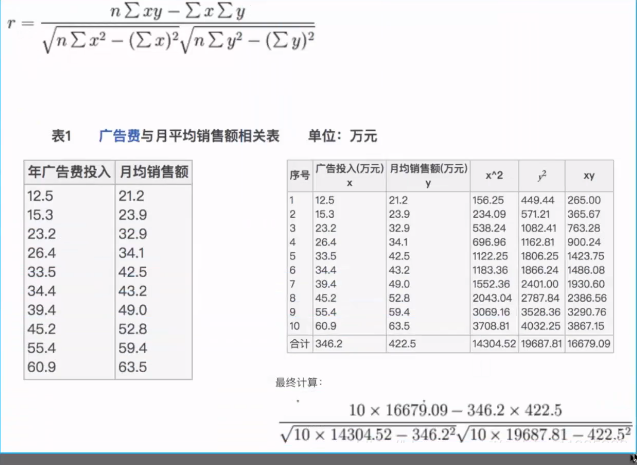
pearson:积差相关系数,反应两个变量之间的线性相关性
spearman:等级相关系数(Ranked data),计算公式和pearson一样(但先对所有变量进行排序,在做线性相关)
- - - 常用
Kendall’s Tau:非参数等级相关系数
tau=(P-Q)/sqrt((P+Q+T)*(P+Q+U))
P:同步数据对数,Q:异步,T:tie in x,U:tie in y
异同和选用:
spearman相关系数:先对所有变量进行排序,在做线性相关。与pearson不同,不假设变量为正态分布
如果有线性模式,也有一些离散点,spearman线性相关系数要大一些,因为离散点破坏了线性相关性,但是对rank排序影响不太大
pearson只能处理两组数据,spearman可以处理多组序列
Kendall’s tau-b(肯德尔)等级相关系数:用于反映分类变量相关性的指标,适用于两个分类变量均为有序分类的情况。对相关的有序变量进行非参数相关检验;取值范围在-1-1之间,此检验适合于正方形表格;
计算积距pearson相关系数,连续性变量才可采用;计算Spearman秩相关系数,适合于定序变量或不满足正态分布假设的等间隔数据;
计算Kendall秩相关系数,适合于定序变量或不满足正态分布假设的等间隔数据。
计算相关系数:当资料不服从双变量正态分布或总体分布未知,或原始数据用等级表示时,宜用 spearman或kendall相关。
总结:在大多数情况下选用spearman检验即可
# pearson只能检验两组数据的相关性
from scipy.stats import pearsonr
import pandas as pd
#1.数据使用上段代码生成的data01
print("x2-->x3:",stats.pearsonr (data01['x2'],data01['x3']))
print("x2-->x5:",stats.pearsonr (data01['x2'],data01['x5']))
print("x2-->x6:",stats.pearsonr (data01['x2'],data01['x6']))
print("x3-->x5:",stats.pearsonr (data01['x3'],data01['x5']))
print("x3-->x6:",stats.pearsonr (data01['x3'],data01['x6']))
print("x5-->x6:",stats.pearsonr(data01['x5'],data01['x6']))
# #返回线性相关度和P值
'''
x2-->x3: (-0.011882657685256122, 0.7909719957310081)
#不相关
x2-->x5: (0.04534181148083765, 0.31160663007500405)
#不相关
x2-->x6: (-1.0, 0.0) #相关,可以去除不重要特征变量或者从新构造新的特征变量(如:加权求和主成分分析降维度)
x3-->x5: (-0.07689352056728531, 0.08586381452347397)
#不相关
x3-->x6: (0.011882657685256105, 0.7909719957310081)
#不相关
x5-->x6: (-0.04534181148083762, 0.31160663007500405)
#不相关
''' |
# spearman:等级相关系数(Ranked
data)检验
from scipy.stats import spearmanr
import pandas as pd
correlation,pvalue=stats.spearmanr (data01) #可以直接传入二维表
#方便看可以构造为二维表
correlation= pd.DataFrame(correlation,index=data01.columns, columns=data01.columns)
pvalue= pd.DataFrame(pvalue,index=data01.columns, columns=data01.columns)
display(correlation,pvalue) |
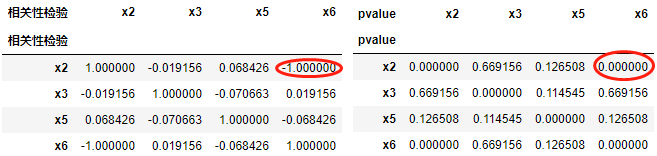
3.2、主成分分析
应用PCA实现特征的降维
·定义:高维数据转化为低维数据的过程,在此过程中可能会舍弃原有数据、创造新的变量
·作用:是数据维散压缩,尽可能降低原数据的维数(复杂度),损失少量信息。
·应用:回归分析或者聚类分析当中
APA:
·sklearn.decomposition.PCA (n_components=None)
- 将数据分解为较低维数空间
- n_components:
·小数:表示保留百分之多少的信息
·整数:减少到多少特征
- PCA.fit_transform(X)X :numpy array格式的数据[n_samples,n_features]
- 返回值:转换后指定维度的array
# 主成分分析,保留n.n%
的信息
from sklearn.decomposition import PCA
import pandas as pd
import numpy as np
# 1、数据:使用上面代码生成的data01
display(data01.head(3))
#2.实例化一个转换器类
transfer = PCA(n_components= 0.9) #实例化一个转换器类
# n_components: ·小数:表示保留百分之多少的信息 ·整数:减少到多少特征
#3.#调用fit_transform()
xi = transfer.fit_transform (data01) #调用fit_transform()
#查看构成新的几个变量,查看单个变量的方差贡献率
print (xi.shape,transfer.explained_variance_ratio_)
#4.输出新构造出来的主成分变量
Fi=[ ]
for i in range(1,xi.shape[1]+1):
F="F" + str(i)
Fi.append(F)
data02 = pd.DataFrame (xi,columns=Fi)
display(data02.head(3)) |
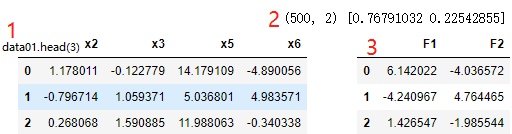
# 主成分分析,保留n个变量的信息
from sklearn.decomposition import PCA
import pandas as pd
import numpy as np
# 1、数据:使用上面代码生成的data01
display(data01.head(3))
#2.实例化一个转换器类
transfer = PCA (n_components=3) #实例化一个转换器类
# n_components: ·小数:表示保留百分之多少的信息 ·整数:减少到多少特征
#3.#调用fit_transform()
xi = transfer.fit_transform (data01) #调用fit_transform()
print (xi.shape,transfer.explained_variance_ratio_)
#查看单个变量的方差贡献率
#4.输出新构造出来的主成分变量
Fi=[ ]
for i in range(1,xi.shape[1]+1):
F="F" + str(i)
Fi.append(F)
data02 = pd.DataFrame (xi,columns=Fi)
display(data02.head(3)) |
4、特征工程之数据探索
单变量的样本分布检验
探索变量之间的关系
特征工程做完以后才能有效地发现样本是否适合做建模(机器学习),然后选择机器学习合适的算法,及不断评估和调优。
|









