| 编辑推荐: |
本文主要介绍了计算机视觉领域中研究的热点之一-- 目标跟踪有哪些主要分支?不同的跟踪算法是如何实现的,希望对您的学习有所帮助。
本文来自于搜狐,由火龙果软件Linda编辑、推荐。 |
|
|| 前言
目标跟踪是计算机视觉领域中研究的热点之一,分为单目标跟踪与多目标跟踪。前者跟踪视频画面中的单个目标,后者则同时跟踪视频画面中的多个目标,得到这些目标的运动轨迹。
基于视觉的多目标跟踪在近年来越来越多地成为计算机视觉领域的研究重点,主要是因为其在智能监控、动作与行为分析、自动驾驶、虚拟现实和娱乐互动等领域都有重要的应用。例如,在自动驾驶系统中,目标跟踪算法要对运动的车、行人、其他动物的运动进行跟踪,对它们在未来的位置、速度等信息作出预判;在虚拟现实领域里,需要根据摄像头捕捉到的人物动作和轨迹,实现人机交互的目的。
那么,跟踪算法有哪些主要分支?不同的跟踪算法是如何实现的呢?让我们带着这些问题开始多目标跟踪领域的奇幻之旅吧!
|| 须知
多目标跟踪算法按照轨迹生成的顺序可以分为离线的多目标跟踪和在线的多目标跟踪算法。
离线方式的多目标跟踪算法通常构造为图模型。其中,设计和计算检测之间的相似度或者距离度量是决定图模型构造正确性的关键。在线方式的多目标跟踪算法根据当前检测观测,计算与已有轨迹的匹配关系。
综上,计算合适的匹配度量决定了匹配的正确性。因此,无论是离线方式的多目标跟踪还是在线方式的多目标跟踪算法,学习检测结果的特征并计算匹配相似度或者距离度量都是多目标跟踪算法的关键步骤。
基于深度学习的多目标跟踪算法的主要任务是优化检测之间相似性或距离度量的设计。根据学习特征的不同,基于深度学习的多目标跟踪可以分为基于深度表观特征学习的多目标跟踪,基于深度相似性度量学习的多目标跟踪,以及基于深度高阶特征匹配的多目标跟踪,如图1所示。
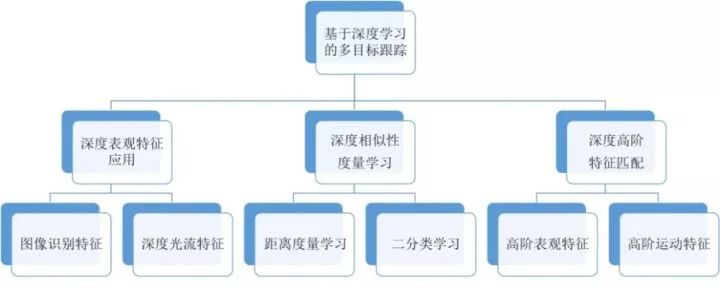
图1
深度表观特征:利用图像识别任务中学习到的深度特征直接替换现有多目标跟踪算法框架中的表观特征,或者采用深度神经网络学习光流运动特征,计算运动相关性。
深度相似性度量:学习检测之间的特征相似性,比如设计深度网络计算不同检测的距离函数,相同目标的检测距离小,不同目标的检测距离大,从而构造关于检测距离的代价函数。也可以设计二类分类代价,使相同目标的检测特征匹配类型为1,而不同目标的检测特征匹配类型为0,从而学习并输出(0,1)之间的检测匹配度。
深度高阶特征匹配:如果考虑已有轨迹与检测之间的匹配或者轨迹之间的匹配,采用深度学习方法可以用于设计并计算轨迹之间的匹配相似度,这种方法可以认为是基于深度学习的高阶特征匹配方法。采用深度学习计算高阶特征匹配可以学习多帧表观特征的高阶匹配相似性,也可以学习运动特征的匹配相关度。
下面我将对一些比较重要的基于深度学习的多目标跟踪算法进行概述,想要详细了解的小伙伴还是要多读源码、多看论文,细细体会这些算法背后的深刻含义了,文章的最后我会给出我看过的一些关键性的论文与源码传送门,莫慌!
|| 算法
基于Siamese对称网络的多目标跟踪算法
Siamese对称卷积网络是一种检测匹配度量学习方法,如图2所示。以两个尺寸相同的检测图像块作为输入,输出为这两个图像块是否属于同一个目标的判别。
原始的检测特征包括正则化的LUV图像I1和I2,以及具有x,y方向分量的光流图像O1和O2,把这些图像缩放到121x53,并且叠加到一起构成10个通道的网络输入特征。卷积网络由三个卷积层(C1、C2、C3)、三个全连接层(F4、F5、F6)以及一个2元分类损失层(F7)组成,如图2所示。
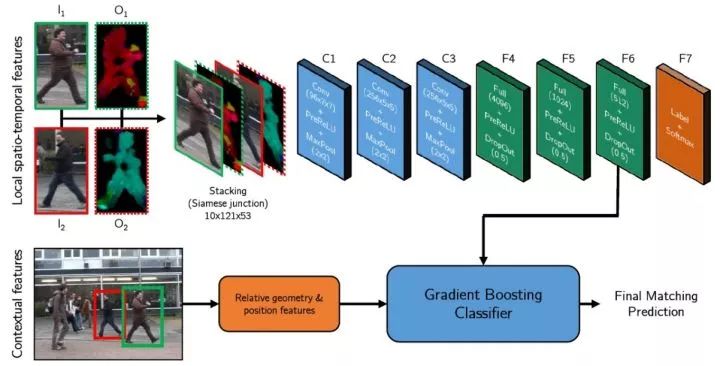
图2 Siamese对称网络结构
学习过程采用经典的带有动量的随机梯度反向传播算法。minibatch大小选择为128,学习率初始为0.01。通过50个回合的训练,可以得到较为优化的网络参数。在Siamese网络学习完成之后,作者采用第六层全连接网络的输出作为表观特征,为了融合运动信息,作者又设计了6维运动上下文特征:尺寸相对变化,位置相对变化,以及速度相对变化。
基于Siamese对称网络的多目标跟踪算法在计算机视觉跟踪领域有着十分重要的地位,由于采用孪生的网络结构,使得其能够更好地利用一套参数来对相似的图像进行拟合,达到快速学习跟踪的目的。这种网络结构为后续的研究工作提供了一个十分有效的网络模板与思路,推动了计算机视觉领域跟踪算法的发展。
基于全连接孪生(Siamese-FC)网络的目标跟踪
Siamese-FC与之前提到的Siamese CNN都采用了孪生结构,Siamese-FC的算法结构如图3所示。
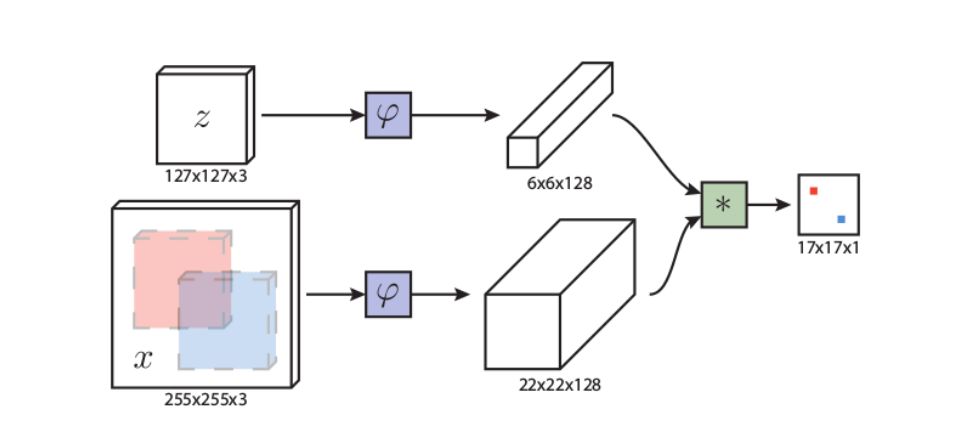
图3 Siamese-FC网络结构
图中z代表的是模板图像,算法中使用的是第一帧的groundtruth,x代表的是search region,即在后面的待跟踪帧中的候选框搜索区域,φ代表的是一种特征映射操作,将原始图像映射到特定的特征空间,文中采用的是CNN中的卷积层和pooling层,6×6×128代表z经过φ后得到的特征,是一个128通道6×6大小feature,同理,22×22×128是x经过φ后的特征,最后的*代表卷积操作,让22×22×128的feature被6×6×128的卷积核卷积,得到一个17×17×1的score
map,代表着search region中各个位置与模板的相似度值。
算法本身是比较搜索区域与目标模板的相似度,最后得到搜索区域的score map。从原理上来说,这种方法和相关性滤波的方法很相似。都是在搜索区域中与目标模板进行逐点匹配,Siamese-FC算法将这种逐点平移匹配计算相似度的方法看成一种卷积操作,然后在卷积结果中找到相似度值最大的点,作为新的目标中心。
MDNet的改进网络——Real-Time MDNet
首先简单介绍MDNet, MDNet是一个纯深度的目标跟踪方法,训练时首先在每一个视频中根据目标的位置用高斯分布,均匀分布和随机分布结合的方法采样取得ROI框,提取对应图像patch;然后输入网络最后一层(全连接层)后,利用softmax输出目标和背景的概率,然后根据groundtruth计算loss反传,训练时仅最后一层FC层根据不同类的视频而不同,即仅有前面的层共享参数,目的是学习到更鲁棒的参数,检测的时候去掉最后一层,用新的FC层使用第一帧的信息finetune,MDNet的缺点是太慢,FPS~
1。Real-TimeMDNet提升至FPS~40。
Real-Time MDNet[12]的贡献是:
1、受Mask R-CNN的启发,提出了一种自适应的ROIAlign;
2、对损失函数进行了改进,引入了一个内嵌实例的loss。
自适应的ROIAlign:
如果把MDNet比作tracking版的R-CNN,那么RT-MDNet就可以近似的认为是tracking版的Mask
R-CNN。
原始的MDNet像R-CNN一样,是先产生proposal,然后用proposal在原图上抠图提特征,这就会像R-CNN一样在提特征时产生很多冗余的部分,很自然的,可以像Faster那样,先提原图的特征,然后在featuremap上去找RoI,这样可以大大加快速度。但是普通的RoI
Pooling会在两次量化的过程中积累很多误差,这些误差再积累到tracking的时序上,最后很可能会让模型漂掉。所以自然的又想到了用RoI
Pooling的改进版,RoIAlign。
然而,当RoIAlign中的采样点间隔太大,会损失掉featuremap上一些有用的信息。比如,一个feature
map grid上是5×5的点,但是RoIAlign在每个grid上只采2×2共4个点,这必然会导致featuremap上的信息被丢失。所以作者根据feature
map grid的size自适应的调整网格里samplepoints的数量,来减少信息的损失。这就是自适应的ROIAlign。
对Loss的改进如图4所示,引入了内嵌实例的loss,使不同域的目标在特征空间的距离相互更远,这样能学到更有判别力的特征。MDNet仅仅是在每一个域中区分目标和背景,而当目标们有相似的外观时就不能有效判别不同域中的目标,所以作者loss中嵌入了其他视频中的目标来使相互之间更有判别力。
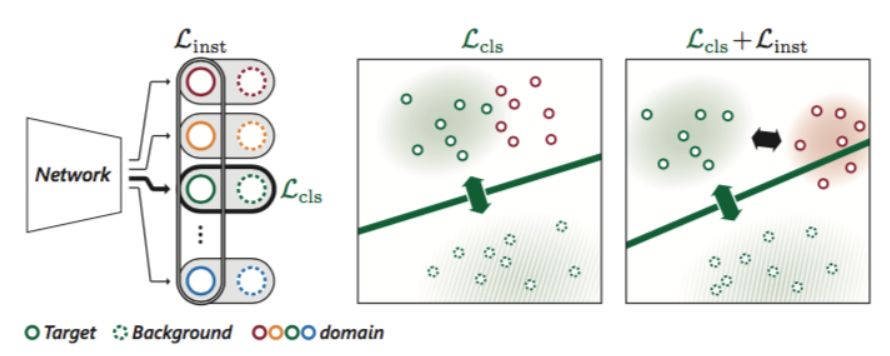
图4 内嵌实例的loss
基于时空域关注模型的多目标跟踪算法
除了采用解决目标重识别问题的深度网络架构学习检测匹配特征,还可以根据多目标跟踪场景的特点,设计合适的深度网络模型来学习检测匹配特征。Chu等人对行人多目标跟踪问题中跟踪算法发生漂移进行统计分析,发现不同行人发生交互时,互相遮挡是跟踪算法产生漂移的重要原因。如图5。
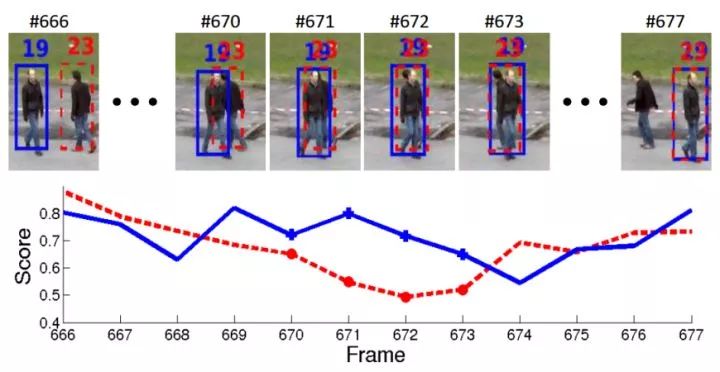
图5 互相遮挡导致识别不准
针对这个问题,他们提出了时空域关注模型(STAM)来学习遮挡情况,并判别可能出现的干扰目标。如图6所示,空间关注模型用于生成遮挡发生时的特征权重,对候选检测特征加权之后,通过分类器进行选择,得到估计的目标跟踪结果。时间关注模型加权历史样本和当前样本,从而得到加权的损失函数,用于在线更新目标模型。
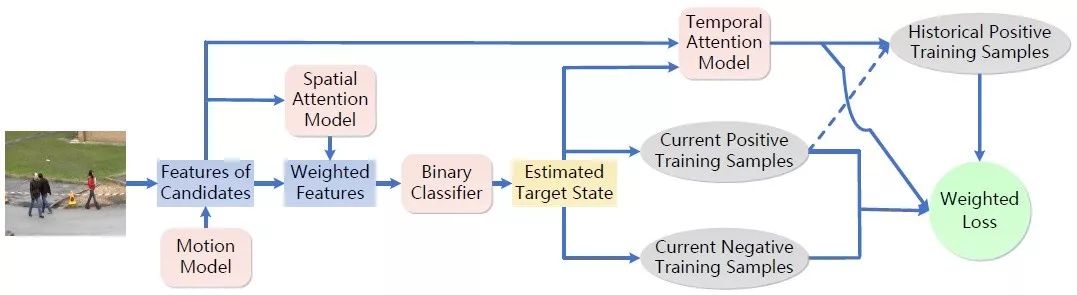
图6 基于时空域关注模型
在这个模型中每个目标独立管理并更新自己的时空域关注模型,并选择候选检测进行跟踪,因此本质上,这种方法是对单目标跟踪算法在多目标跟踪中的扩展。为了区分不同的目标,关键的步骤是如何对遮挡状态进行建模和区分接近的不同目标。
空间注意模型用于对每个时刻的遮挡状态进行分析,空间关注模型如图7所示。主要分为三步。第一步是学习特征可见图(visibility
map);第二步是根据特征可见图,计算空间关注图(Spatial Attention);第三步根据空间关注图加权原特征图。对生成的加权特征图进行卷积和全连接网络操作,生成二元分类器判别是否是目标自身。最后用得到分类打分,选择最优的跟踪结果。
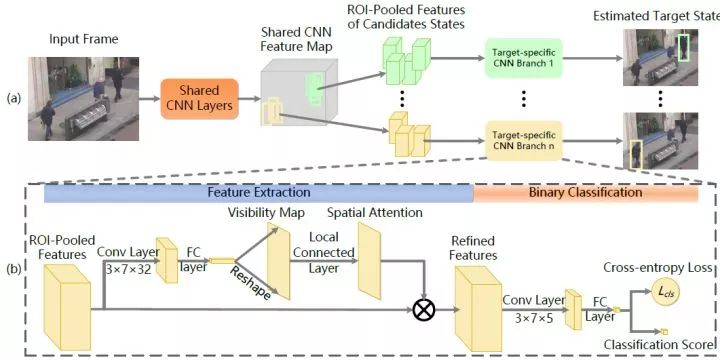
图7 空间关注模型步骤
基于LSTM判别融合表观的多目标跟踪算法
前面介绍的几个算法采用的深度网络模型都是基于卷积网络结构,由于目标跟踪是通过历史轨迹信息来判断新的目标状态,因此,设计能够记忆历史信息并根据历史信息来学习匹配相似性的网络结构,也是比较可行的算法框架。Sadeghian等人设计了基于长短期记忆循环网络模型(LSTM)的特征融合算法来学习轨迹历史信息与当前检测之间的匹配相似度。如图8,首先,轨迹目标与检测的匹配需要用到三种特征(表观特征、运动特征、交互特征)(左);然后,采用分层的LSTM模型(中)来实现三种特征的融合;最后,通过相似度的二部图匹配算法实现最终的匹配结果(右)。
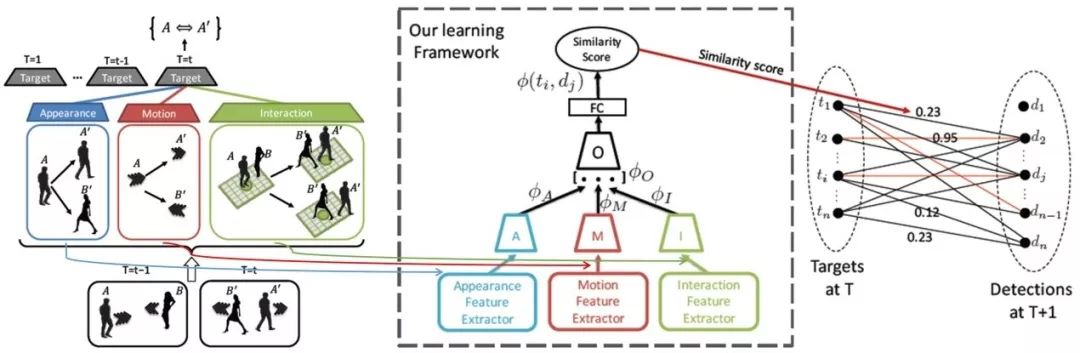
图8基于LSTM特征融合进行跟踪
对于表观特征,首先采用VGG-16卷积网络生成500维的特征,以这个特征作为LSTM的输入计算循环网络的输出,根据与当前时刻检测到的特征匹配的情况来学习分类器,并预训练这个网络,如图9所示。
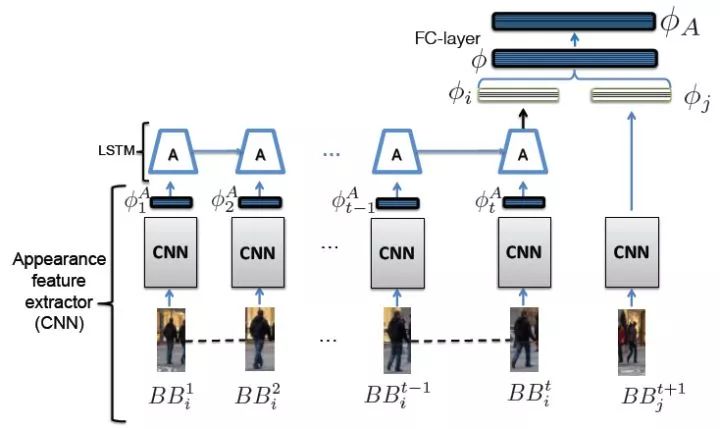
图9 基于CNN模型和LSTM模型的轨迹与检测表观特征匹配架构
对于运动特征,取相对位移为基本输入特征,直接输入LSTM模型计算每个时刻的输出。对于下一时刻的检测,同样计算相对位移,通过全连接网络计算特征,得到500维的特征,并利用二元匹配分类器进行网络的预训练。整个过程如图10所示。
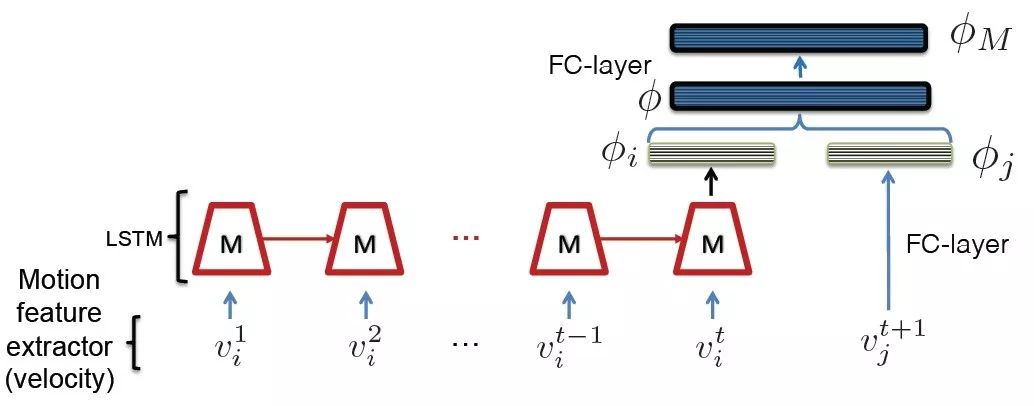
图10 基于LSTM模型的轨迹运动特征匹配架构
对于交互特征,取以目标中心位置周围矩形邻域内其他目标所占的相对位置映射图作为LSTM模型的输入特征,计算输出特征。同样通过全连接网络计算500维特征,进行分类训练,如图11所示。
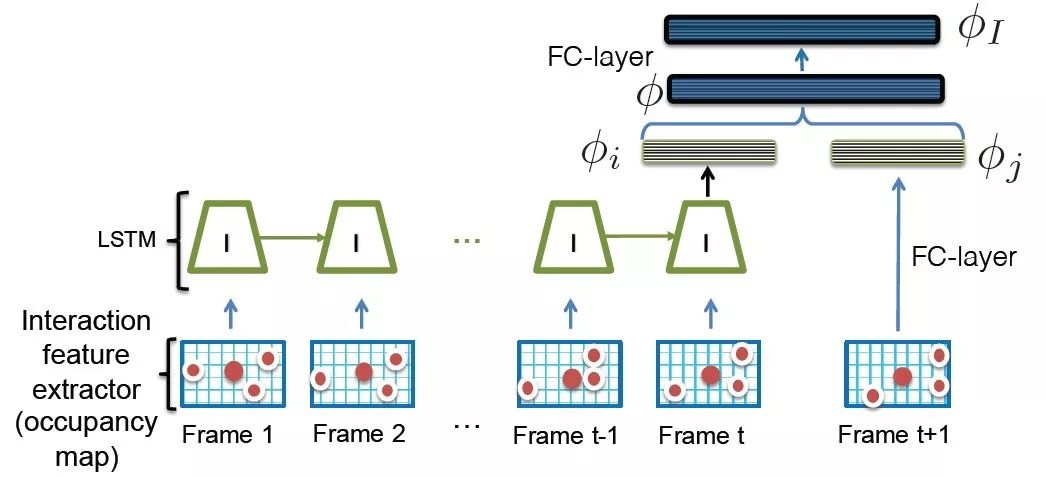
图11 基于LSTM模型的目标交互特征匹配架构
当三个特征都计算之后拼接为完整的特征,输入到上层的LSTM网络,对输出的向量进行全连接计算,然后用于匹配分类,匹配正确为1,否则为0。
|| 总结
目前的基于深度学习的多目标跟踪框架在以下两个方向取得了较好的进展:
(1)结合多目标跟踪场景对网络进行优化,这种考虑跟踪场景的网络设计对于跟踪结果有明显的提升效果。
(2)采用循环神经网络,利用历史信息来表达跟踪中的轨迹特征,这是研究跟踪问题的又一个重要的方向。
|









