| 编辑推荐: |
本文主要讲解了主成分分析是什么? 有什么及项目实战,希望本文对大家有所帮助。
本文来自于简书,由火龙果软件Anna编辑、推荐。 |
|
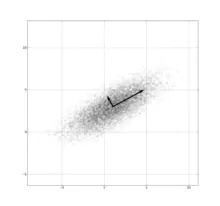
主成分分析实例:一个平均值为(1, 3)、标准差在(0.878, 0.478)方向上为3、在其正交方向为1的高斯分布。这里以黑色显示的两个向量是这个分布的协方差矩阵的特征向量,其长度按对应的特征值之平方根为比例,并且移动到以原分布的平均值为原点。
在多元统计分析中,主成分分析(英语:Principal components analysis,PCA)是一种分析、简化数据集的技术。主成分分析经常用于减少数据集的维数,同时保持数据集中的对方差贡献最大的特征。这是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。但是,这也不是一定的,要视具体应用而定。由于主成分分析依赖所给数据,所以数据的准确性对分析结果影响很大。
主成分分析由卡尔·皮尔逊于1901年发明,用于分析数据及建立数理模型。其方法主要是通过对协方差矩阵进行特征分解,以得出数据的主成分(即特征向量)与它们的权值(即特征值[3])。PCA是最简单的以特征量分析多元统计分布的方法。其结果可以理解为对原数据中的方差做出解释:哪一个方向上的数据值对方差的影响最大?换而言之,PCA提供了一种降低数据维度的有效办法;如果分析者在原数据中除掉最小的特征值所对应的成分,那么所得的低维度数据必定是最优化的(也即,这样降低维度必定是失去讯息最少的方法)。主成分分析在分析复杂数据时尤为有用,比如人脸识别。
PCA是最简单的以特征量分析多元统计分布的方法。通常情况下,这种运算可以被看作是揭露数据的内部结构,从而更好的解释数据的变量的方法。如果一个多元数据集能够在一个高维数据空间坐标系中被显现出来,那么PCA就能够提供一幅比较低维度的图像,这幅图像即为在讯息最多的点上原对象的一个‘投影’。这样就可以利用少量的主成分使得数据的维度降低了。
PCA跟因子分析密切相关,并且已经有很多混合这两种分析的统计包。而真实要素分析则是假定底层结构,求得微小差异矩阵的特征向量。
PCA,Principle Component Analysis,即主成分分析法,是特征降维的最常用手段。顾名思义,PCA
能从冗余特征中提取主要成分,在不太损失模型质量的情况下,提升了模型训练速度。
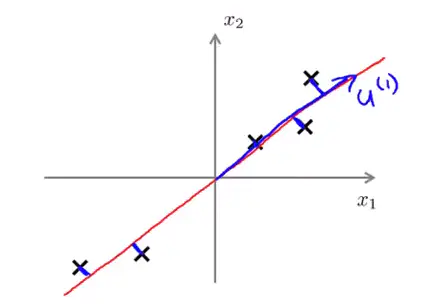
如上图所示,我们将样本到红色向量的距离称作是投影误差(Projection Error)。以二维投影到一维为例,PCA
就是要找寻一条直线,使得各个特征的投影误差足够小,这样才能尽可能的保留原特征具有的信息。
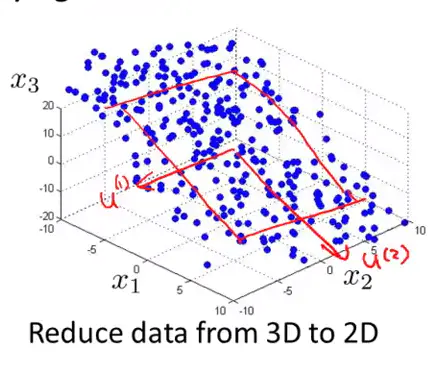
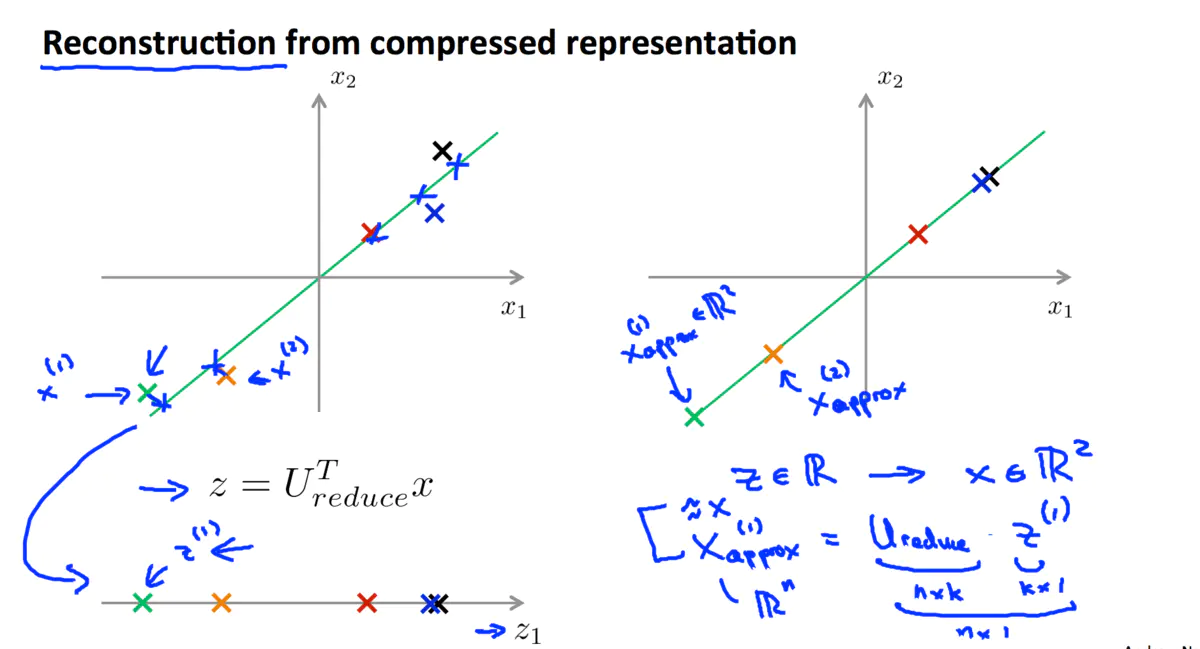
因为PCA仅保留了特征的主成分,所以PCA是一种有损的压缩方式.
降到多少维才合适?
从 PCA 的执行流程中,我们知道,需要为 PCA 指定目的维度 k 。如果降维不多,则性能提升不大;如果目标维度太小,则又丢失了许多信息。
不要提前优化
由于 PCA 减小了特征维度,因而也有可能带来过拟合的问题。PCA 不是必须的,在机器学习中,一定谨记不要提前优化,只有当算法运行效率不尽如如人意时,再考虑使用
PCA 或者其他特征降维手段来提升训练速度。
不只是加速学习
降低特征维度不只能加速模型的训练速度,还能帮我们在低维空间分析数据,例如,一个在三维空间完成的聚类问题,我们可以通过
PCA 将特征降低到二维平面进行可视化分析。
项目实战:利用 PCA 对葡萄酒分类
根据 13 个特征对葡萄酒分类(推销给不同品味的人),利用 PCA ,可以将数据从 13 维降到 2
维进行可视化。
import numpy
as np
import matplotlib.pyplot as plt
import pandas as pd |
# 导入数据
dataset = pd.read_csv('Wine.csv')
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 13].values
dataset.head(10) |
# 分成训练集与测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,
y, test_size = 0.2, random_state = 0)
X_train[:3]
|
array([[1.369e+01, 3.260e+00, 2.540e+00, 2.000e+01,
1.070e+02, 1.830e+00,
5.600e-01, 5.000e-01, 8.000e-01, 5.880e+00, 9.600e-01,
1.820e+00,
6.800e+02],
[1.269e+01, 1.530e+00, 2.260e+00, 2.070e+01, 8.000e+01,
1.380e+00,
1.460e+00, 5.800e-01, 1.620e+00, 3.050e+00, 9.600e-01,
2.060e+00,
4.950e+02],
[1.162e+01, 1.990e+00, 2.280e+00, 1.800e+01, 9.800e+01,
3.020e+00,
2.260e+00, 1.700e-01, 1.350e+00, 3.250e+00, 1.160e+00,
2.960e+00,
3.450e+02]])
# 特征缩放
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
X_train[:3]
|
array([[ 0.87668336, 0.79842885, 0.64412971,
0.12974277, 0.48853231,
-0.70326216, -1.42846826, 1.0724566 , -1.36820277,
0.35193216,
0.0290166 , -1.06412236, -0.2059076 ],
[-0.36659076, -0.7581304 , -0.39779858, 0.33380024,
-1.41302392,
-1.44153145, -0.5029981 , 1.70109989, 0.02366802,
-0.84114577,
0.0290166 , -0.73083231, -0.81704676],
[-1.69689407, -0.34424759, -0.32337513, -0.45327855,
-0.14531976,
1.24904997, 0.31964204, -1.52069698, -0.4346309 ,
-0.75682931,
0.90197362, 0.51900537, -1.31256499]])
# 测试 PCA
from sklearn.decomposition import PCA
pca = PCA(n_components = None)
X_train = pca.fit_transform(X_train)
X_test = pca.transform(X_test)
# explained_variance_ratio_,它代表降维后的各主成分的方差值占总方差值的比例,这个比例越大,则越是重要的主成分。
explained_variance = pca.explained_variance_ratio_
explained_variance |
array([0.36884109, 0.19318394, 0.10752862, 0.07421996,
0.06245904,
0.04909 , 0.04117287, 0.02495984, 0.02308855, 0.01864124,
0.01731766, 0.01252785, 0.00696933])
# 这里取前 2 个主成分,它可以解释
(0.3688+0.1931) 的方差
from sklearn.decomposition import PCA
pca = PCA(n_components = 2)
X_train = pca.fit_transform(X_train)
X_test = pca.transform(X_test)
explained_variance = pca.explained_variance_ratio_
print(explained_variance)
X_train[:3] |
array([[-2.17884511, -1.07218467],
[-1.80819239, 1.57822344],
[ 1.09829474, 2.22124345]])
# 逻辑回归拟合训练集
from sklearn.linear_model import LogisticRegression
classifier = LogisticRegression(random_state =
0)
classifier.fit(X_train, y_train) |
LogisticRegression(C=1.0, class_weight=None, dual=False,
fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr',
n_jobs=1,
penalty='l2', random_state=0, solver='liblinear',
tol=0.0001,
verbose=0, warm_start=False)
# 预测测试集
y_pred = classifier.predict(X_test)
y_pred[:5] |
array([1, 3, 2, 1, 2])
# 混淆矩阵
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
cm |
array([[14, 0, 0],
[ 1, 15, 0],
[ 0, 0, 6]])
# 预测正确的为正对角线的值,准确率为
(14+15+6) / (14+15+6+1)
print("准确率(精度)为 :", (14+15+6)/(14+15+6+1)) |
准确率(精度)为 : 0.9722222222222222
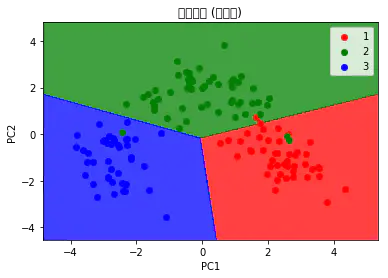
# 可视化训练集
from matplotlib.colors import ListedColormap
X_set, y_set = X_train, y_train
X1, X2 = np.meshgrid(np.arange(start = X_set[:,
0].min() - 1, stop = X_set[:, 0].max() + 1, step
= 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop
= X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(),
X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green',
'blue')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set
== j, 1],
c = ListedColormap(('red', 'green', 'blue'))(i),
label = j)
plt.title('逻辑回归 (训练集)')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.legend()
plt.show() |
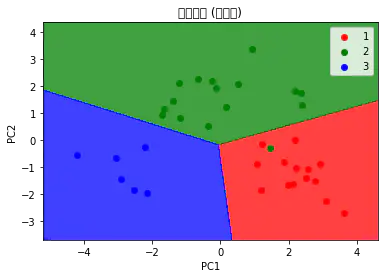
# 可视化测试集
from matplotlib.colors import ListedColormap
X_set, y_set = X_test, y_test
X1, X2 = np.meshgrid(np.arange(start = X_set[:,
0].min() - 1, stop = X_set[:, 0].max() + 1, step
= 0.01),
np.arange(start = X_set[:, 1].min() - 1, stop
= X_set[:, 1].max() + 1, step = 0.01))
plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(),
X2.ravel()]).T).reshape(X1.shape),
alpha = 0.75, cmap = ListedColormap(('red', 'green',
'blue')))
plt.xlim(X1.min(), X1.max())
plt.ylim(X2.min(), X2.max())
for i, j in enumerate(np.unique(y_set)):
plt.scatter(X_set[y_set == j, 0], X_set[y_set
== j, 1],
c = ListedColormap(('red', 'green', 'blue'))(i),
label = j)
plt.title('逻辑回归 (测试集)')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.legend()
plt.show() |
output_12_0.png
|









